Tensorflow深度学习算法整理(二)
循环神经网络
序列式问题
- 为什么需要循环神经网络
首先我们来看一下普通的神经网络的样子
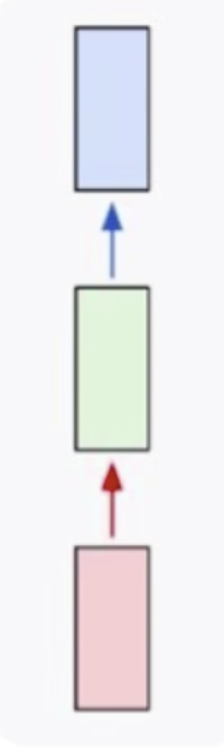
这里红色部分是输入,比如说图像;绿色部分是网络部分,比如说卷积部分和全连接部分;蓝色部分是输出,比如说最终得到的分类概率。这样的网络结构很适合做图像的分类,图像的检测,这种数据都是固定的数据。如果是变长的数据,比如说文本,它的长度是不一定的,这个时候我们该怎么做呢?
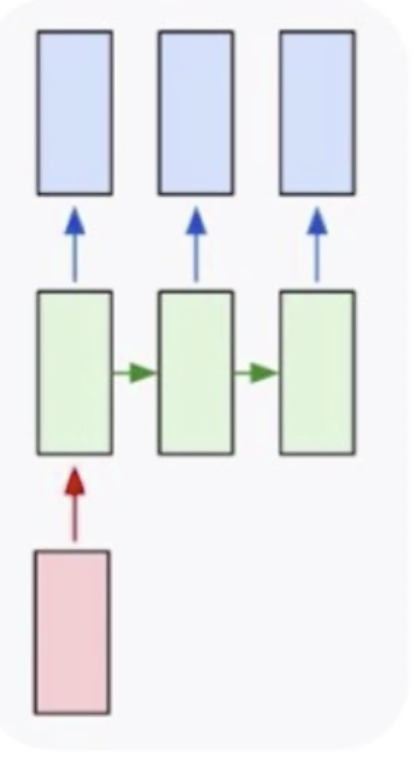
这个时候其实就需要循环神经网络,循环神经网络是专门用来处理序列式问题的。循环神经网络可以解决一对多问题,如上图所示,我们的数据集是一个输入,但是我们要形成多个输出,多个输出卷积神经网络是做不了的,它只能给出来一个输出。一个基本的场景就是给定一张图片,去生成一个描述,这个描述就是一个文本,文本是不定长的。我可以说这个图片风景优美,也可以说这个图片有一条小河,有一个孩童等等。
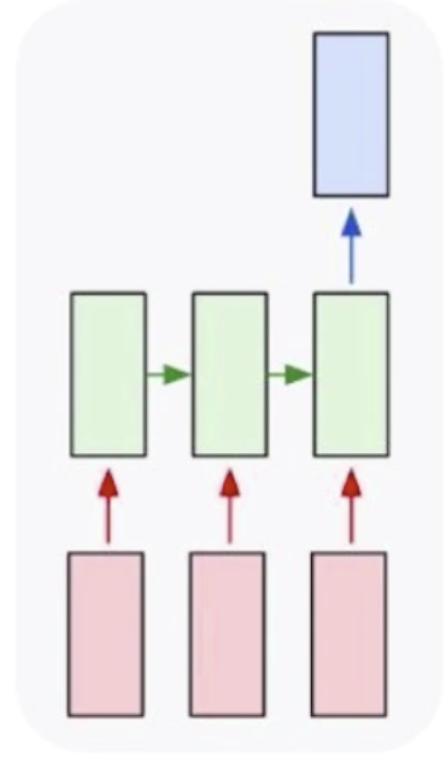
然后就是多对一的,多对一有一个很经典的问题就是文本分类(文本情感分析),分本分类的输出也只有一个,但是它的输入是不定长的。这种情况下卷积神经网络也无法处理。如果实在要处理的话,可以让输入强行变的对齐,这样才可以处理。但是在不定长情况下,只有循环神经网络可以做到。
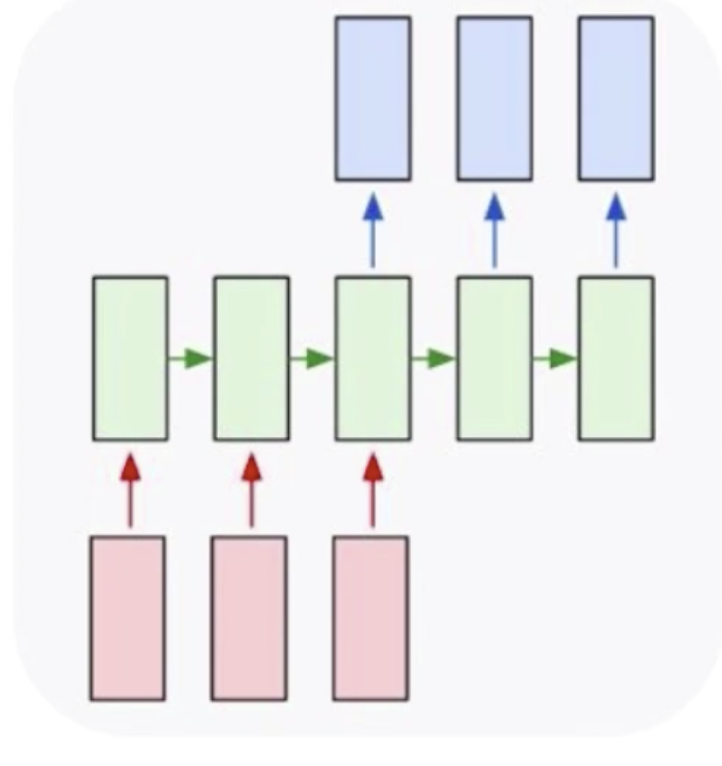
然后就是多对多,多对多有一个经典的问题就是机器翻译,比如说我知道一个中文的句子,想把它翻译成英文,在这个时候就需要用到循环神经网络去解决。可以通过把中文信息都编码到一个数据中去,再依据这个数据去生成新的英文句子。但是这种翻译不是一种实时翻译,实时翻译是一个词一个词的翻译。

实时多对多,如视频解说。比如说世界杯解说,现在一般都是人力解说,但其实也可以用机器来解说,虽然用机器解说还不能达到生动有趣的效果,但是生成基本的描述是没有问题的。视频解说的输入是视频中一帧一帧的图片,每一个输出都是一个不定长的句子。这就达到了一个视频解说的目的。
循环神经网络

循环神经网络类似于之前的架构,但是它多了一个自我指向的路径。这条自我指向的路径表达的是,输入可能是多个,然后需要保存一个中间状态,这个中间状态可以帮我们了解之前的输入的情况。维护一个状态作为下一步的额外输入。首先我们有一个输入x0(表示第0步)到RNN中去得到一个状态s0,这个状态经过一个变化输出到y0。下一次,由于我们得到一个中间状态s0,s0可以和后面的x1一块输入到RNN中去,得到s1,之后再输出y1。这个是它的一个基本思想。
循环神经网络每一步使用同样的激活函数和参数。我们的输入可能有x0,x1,x2....,它每一步的参数是共享的。
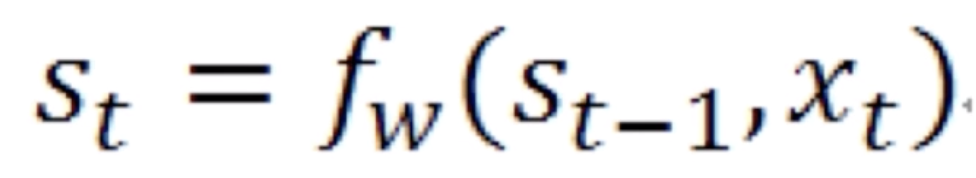
这里![]() 就是中间的状态,它等于上一步的状态
就是中间的状态,它等于上一步的状态![]() 和当前的输入
和当前的输入![]() 一起做一个拼接再经过一个变换就得到当前的状态。当前的状态
一起做一个拼接再经过一个变换就得到当前的状态。当前的状态![]() 再经过一个变换就能得到当前的输出
再经过一个变换就能得到当前的输出![]() 。这是最简单的循环神经网络。再将该公式展开就得到
。这是最简单的循环神经网络。再将该公式展开就得到
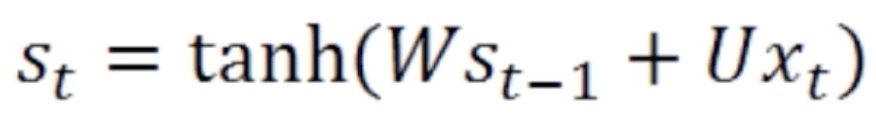
在这里![]() 用了一个激活函数叫tanh。
用了一个激活函数叫tanh。![]() 和
和![]() 是如何组合在一起的,在这里用了一个矩阵变换W和U,W和U都是矩阵参数。这两个矩阵参数分别对
是如何组合在一起的,在这里用了一个矩阵变换W和U,W和U都是矩阵参数。这两个矩阵参数分别对![]() 和
和![]() 做了变换之后再相加(关于矩阵变换的内容请参考线性代数整理(二) 中的线性变换)。然后再经过一个激活函数就得到了当前的状态值
做了变换之后再相加(关于矩阵变换的内容请参考线性代数整理(二) 中的线性变换)。然后再经过一个激活函数就得到了当前的状态值![]() 。
。

当前状态![]() 再经过一个变换V,再使用多分类归一化softmax,就得到了当前概率值
再经过一个变换V,再使用多分类归一化softmax,就得到了当前概率值![]()
现在我们来看一个例子
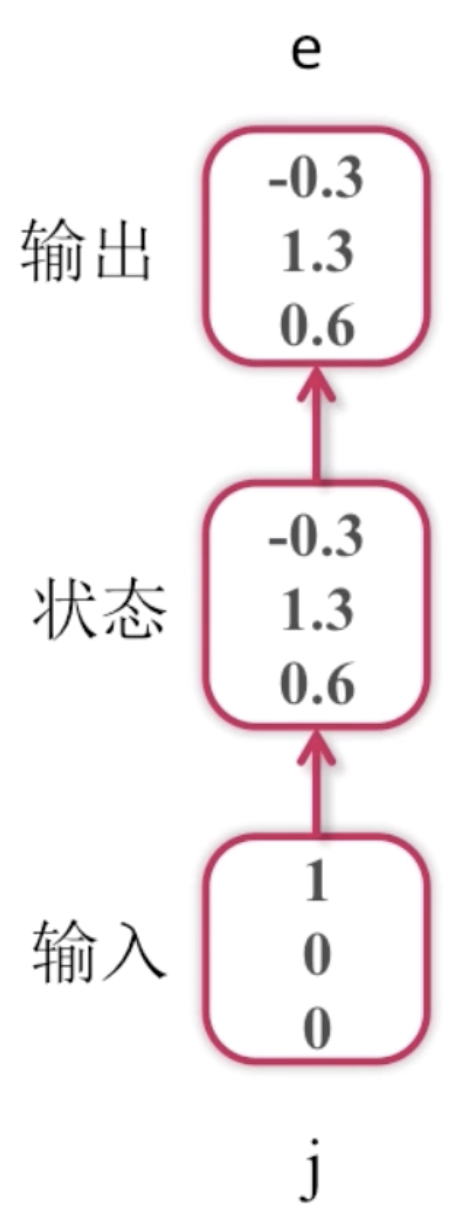
这是一个字符语言模型,它的目的是预测下一个字符,词典为[j, e, p],样本为jeep。语言模型是NLP(自然语言处理)领域里面常用的一个模型,它的模型的基本要素就是说我给定一个上下文context,我能预测下一个字或者词是什么。比如应用在输入法上的模型,它可以帮大家预测下一个要输入的词是什么。字符语言模型跟词语言模型不一样,词语言模型是预测下一个词是什么,字符语言模型是预测下一个字符是什么。比如说hello,我输入了he之后需要预测出下一个是l。
这里我们简化问题,字典里面只有j、e、p三个字符,首先我们的输入样本是j,此时我们并不知道后面的样本是什么。把j输入到循环神经网络中去,记录下一个状态,再经过一个变换,这里为了简化过程,我们就进行了等值变换,进入到输出,得到一组概率值。然后再计算概率分布。
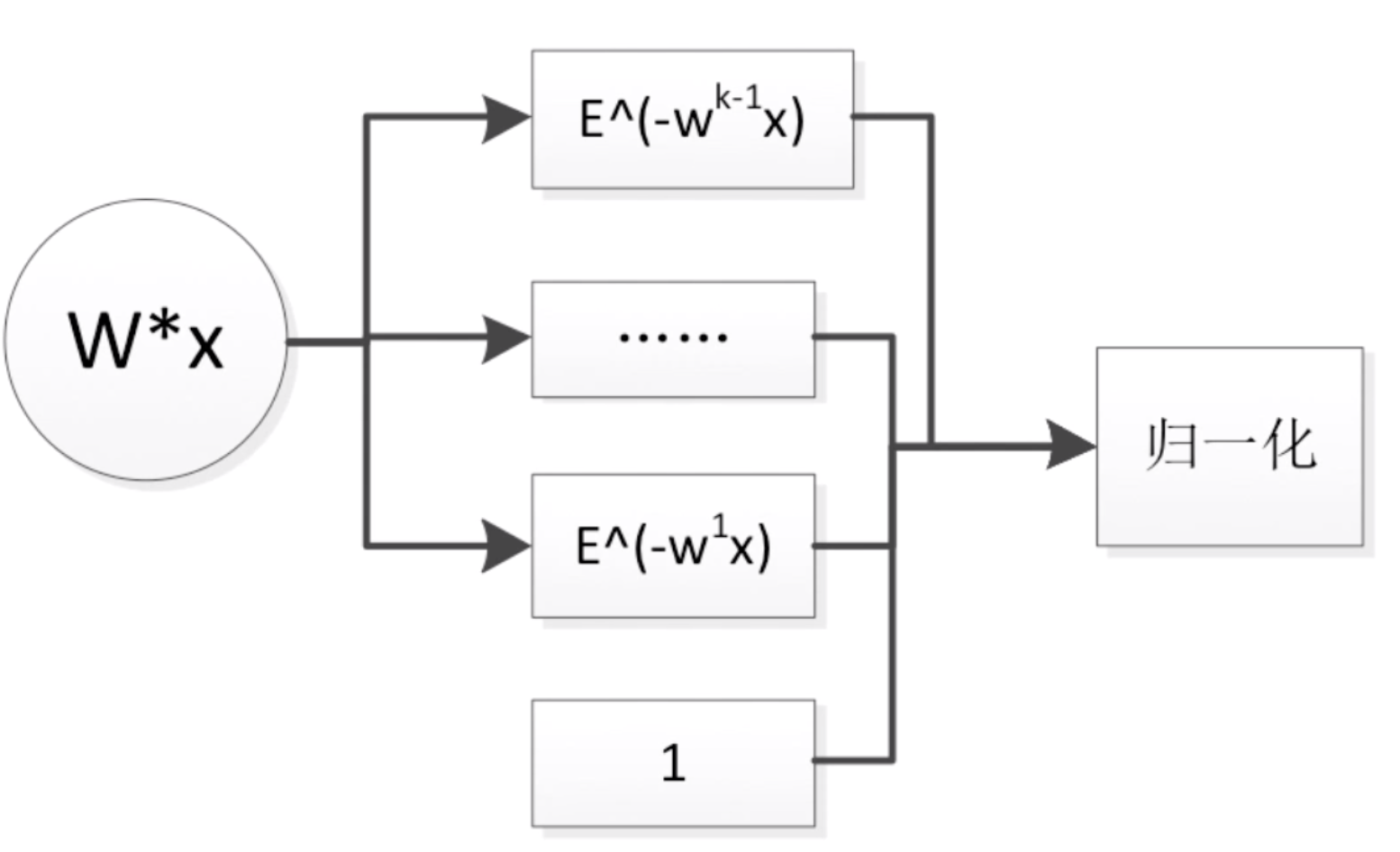
就是这个过程,这里概率分布中第1个位置的概率1.3是最大的,它代表是第1个位置,所以预测下一个字母是e(这里j排第0,e排第1,p排第2)。
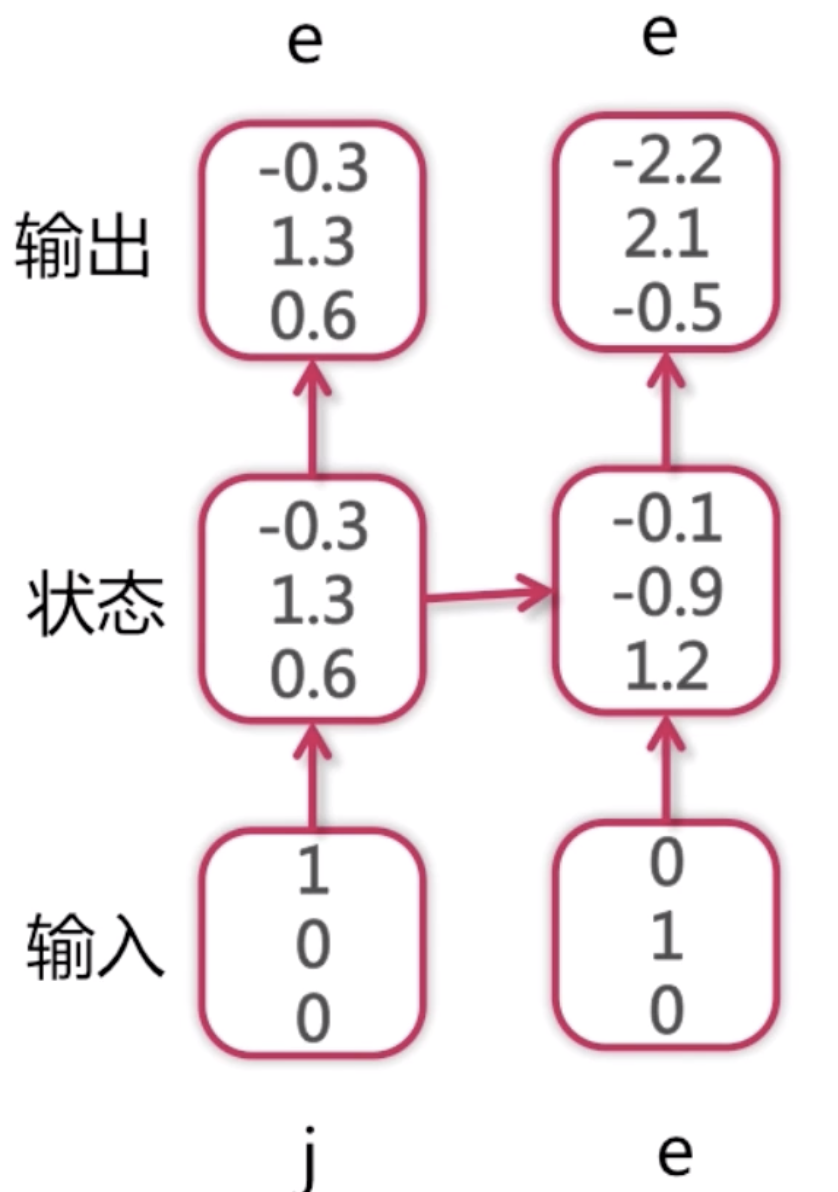
此时我们得到了第一个输出是e,再把e作为第二次输入,第一次输入j的时候得到了一个隐含状态,这个隐含状态和下一个e一块输入到下一个RNN中的深度神经单元中去,然后得到第二次的输出的概率分布。这个概率分布依然是第一个位置上的概率最大为2.1,所以第三个字符也是e。

同理,我们把第二次的输出e作为第三次的输入,在此之前,我们第一次输入的j以及第二次作为输入预测出来的e,它们都有一个隐含状态,这两个隐含状态都连接到了第三次输入的RNN神经网络,再加上第二次预测的e一块输入进去,得到了第三次输出的概率分布,这次最大值为第3个位置的4.5,所以预测出来的字符为p。

如果作为测试数据集,我们可能只知道第一个j,后面的字符都不知道。由于每一步的输入都依赖于上一步的预测值,如果中间的某个地方预测错了,那么很可能从中间到往后的预测值都是错的。如果模型训练的比较好的话,数据量比较大,它还是可以有一定的兼容性的,比如中间错了,但是后面的预测依然是对的。对于p来说,因为之前的状态都是加权过来的,越往前的状态值对最后结果的预测值就越没有影响力,当前的输入对当前的输出是有最大影响的,越往前的输入对最后的预测越没有影响。所以这种兼容性还是可以训练出来的。
循环神经网络的正向传播
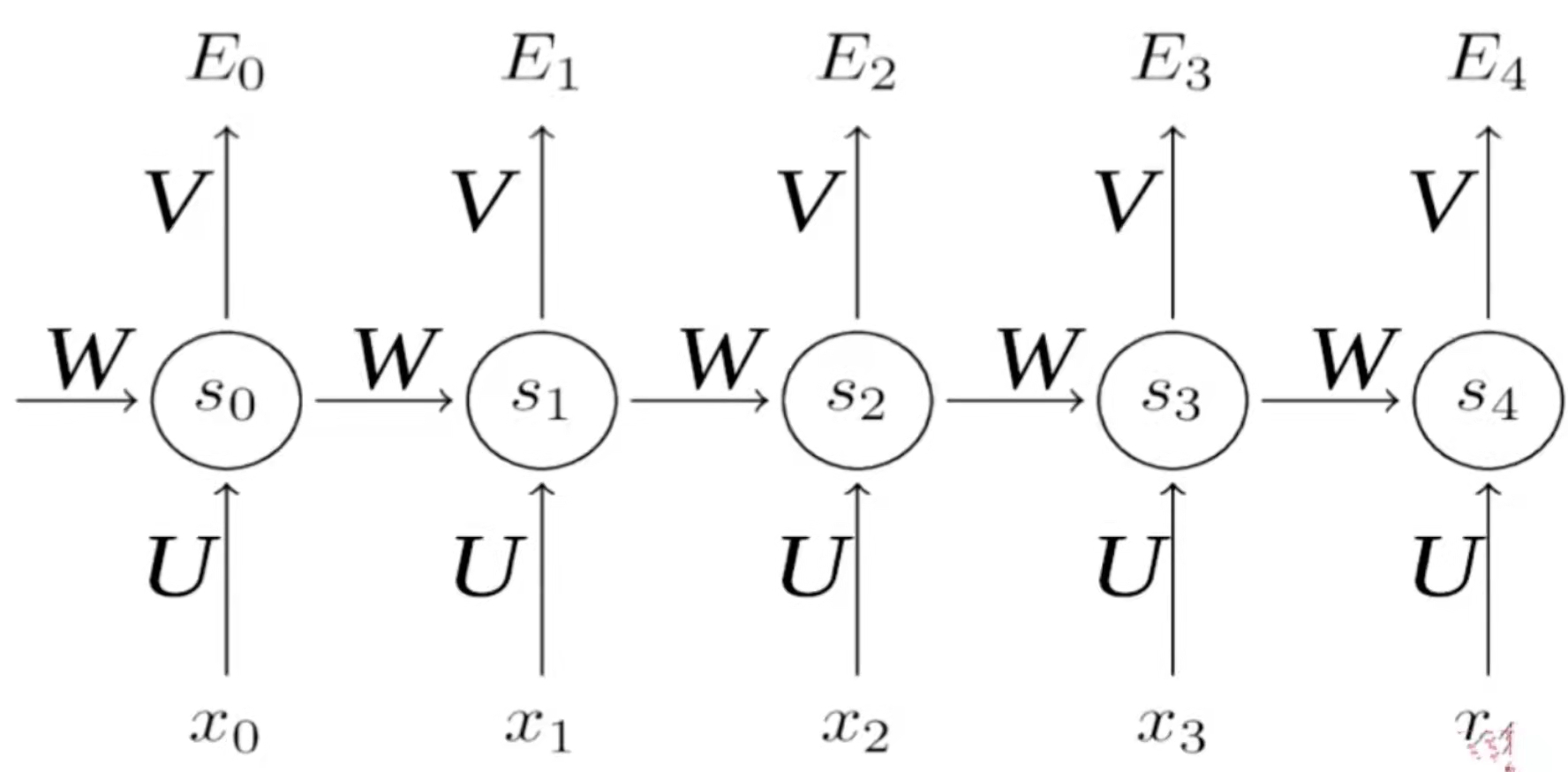
我们在讲普通的卷积神经网络的正向传播是先计算低层的,再计算高层的。但是在循环神经网络中只有一层,它的正向传播是序列式的,后输入的状态依赖于先输入的状态,所以它需要先计算第一个位置上的值,然后再去计算第二个位置上的值,然后再去计算第三个、第四个、第五个位置上的值。循环神经网络的正向传播就是序列式的,按照输入顺序去进行计算的一个过程。在每个位置上都得到了一个预测值之后,可以在每个位置上去计算损失函数。最后的损失函数是所有的中间步骤的损失函数的和。当然这个循环神经网络是最基础的循环神经网络,它是实时多对多的那个神经网络结构,后面可以做一些微小的变换,就可以使得它去面对多对一的问题或者一对多的问题以及不实时多对多的问题。如果要应对多对一的问题,那么只需要让前四步的输出都为0就可以了,就是前四步都不输出,只输出第五步的值,然后在第五步上去做损失函数,它也会反向传播去更新所有的W。
循环神经网络的反向传播
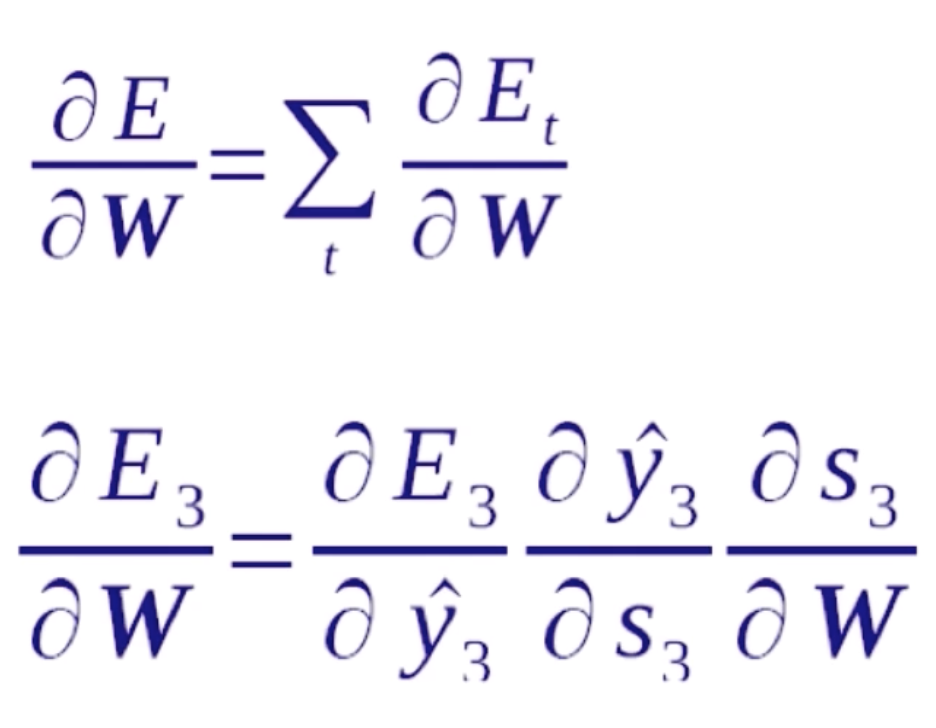
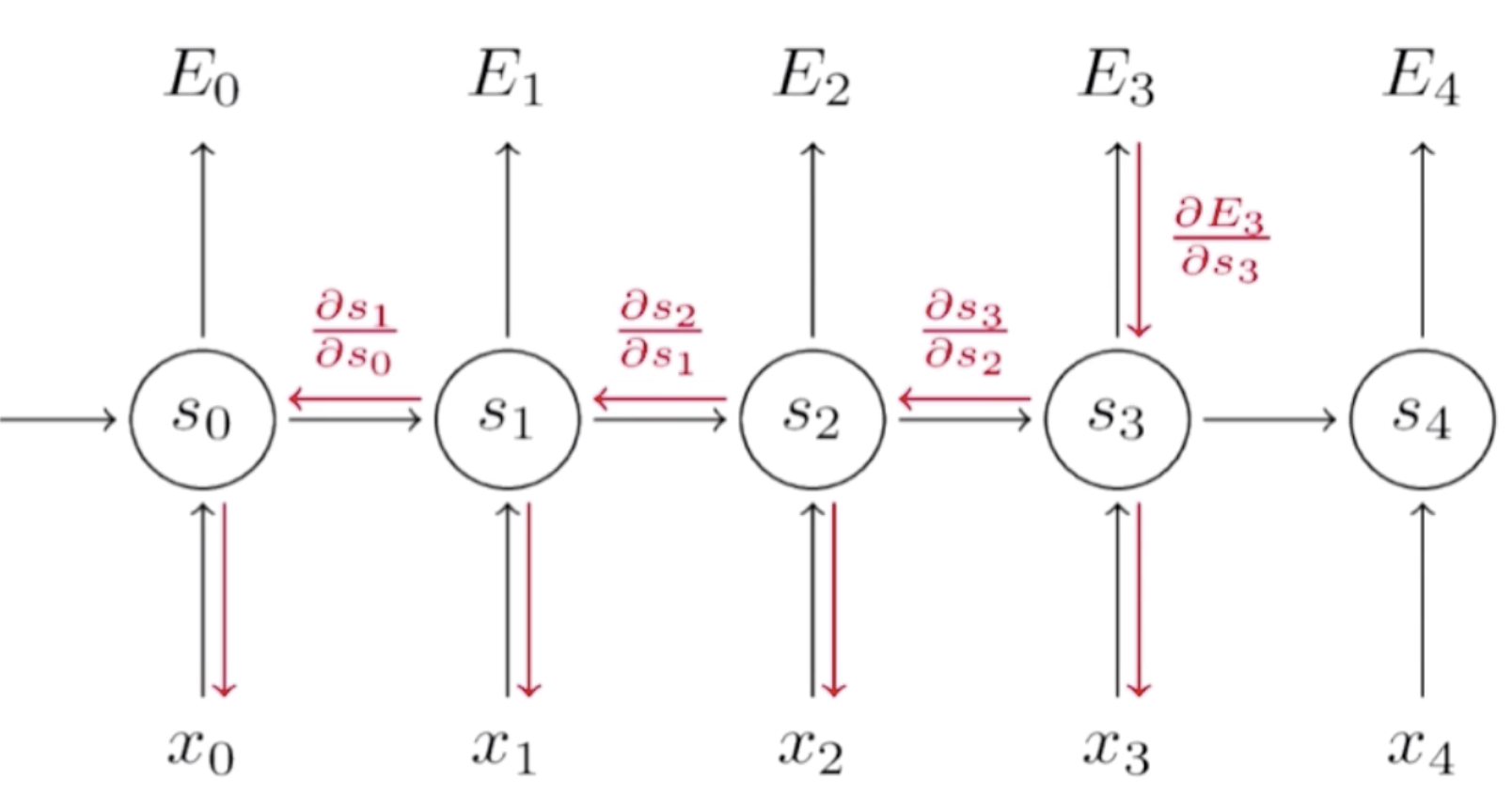
循环神经网络的反向传播也是依照序列来做的,正向传播是从序列的头到序列的尾,而反向传播是从序列的尾到序列的头。首先我们要明确一点,在正向传播中每一步用到的W、U、V都是一样的,所以我们在计算梯度的时候,在任何一步上计算梯度,它们的梯度是要相加起来统一去更新W,因为它们本质上就是一个变量。对于一个循环神经网络来说,它有一个递归性在里面,比如说在E3的位置去算W的梯度,它就等于E3就先对s3的一个梯度,s3是它的隐含状态值,这个隐含状态值经过一个变换就得到了y3,y3再经过变换就得到了E3。这里在s上存在循环性,所以 是可以直接计算出来的,而
是可以直接计算出来的,而![]() 就比较复杂。因为s3对W是一个递归的过程。我们看一下它是如何递归的。
就比较复杂。因为s3对W是一个递归的过程。我们看一下它是如何递归的。
![]()
这里我们知道最新的状态值s3跟之前的状态值s2和最新的输入x3是这样一个关系。由于是对W求导,我们就可以把Ux3看成一个常数,剩下的就是Ws2,s2并不是一个常数,它跟W是有关系的,假设它的关系为v(W),那么求导就变成了两个函数相乘对W求导(可以参考高等数学整理 中的求导公式),这里W可以看成是它自身u(W)。
那么我们对![]() 做展开,首先我们知道s3是s2的函数,s2是s1的函数,s1是s0的函数,所以可得s3分别是s2、s1、s0的函数。根据上面的公式就有(这里的计算比较复杂,我们给出一个结果)
做展开,首先我们知道s3是s2的函数,s2是s1的函数,s1是s0的函数,所以可得s3分别是s2、s1、s0的函数。根据上面的公式就有(这里的计算比较复杂,我们给出一个结果)
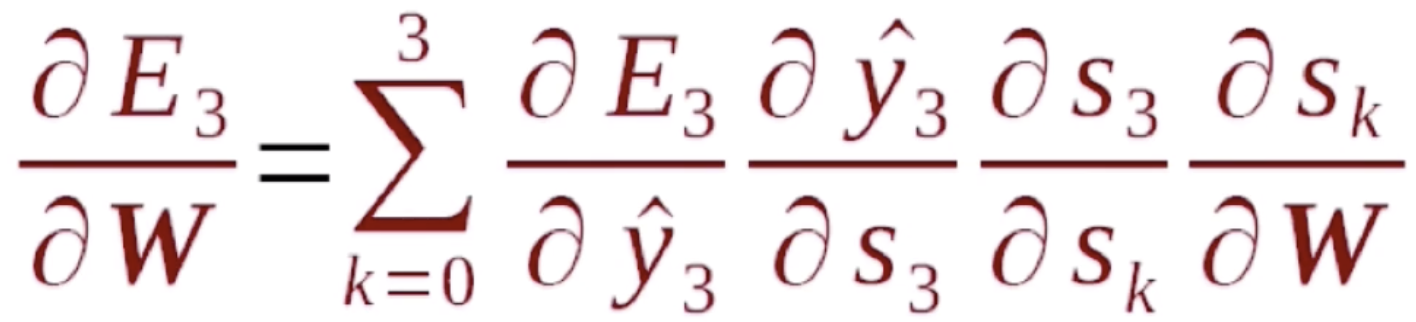
这里s3对sk的导数可以简化为
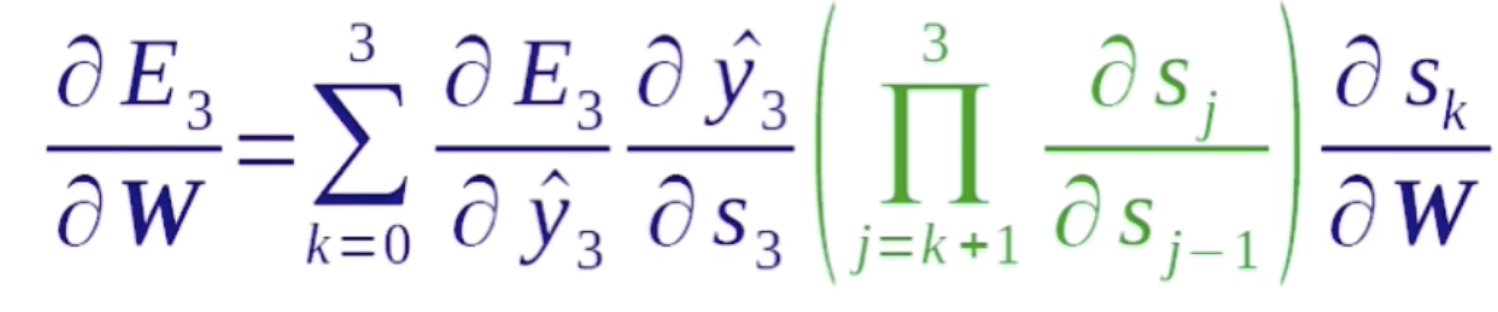
在这个做计算的过程中可以去简化计算步骤,比如s3对s2求了导数之后,在求s4的时候,我们可以复用这一效果。所以在这里做了一个拆分,s3对于s0的导数可以看成是s3对s2的导数乘以s2对s1的导数乘以s1对s0的导数。这个乘积的作用就是说可以复用中间的计算结果,因为这是一个递归的过程,如果能存下来中间的计算结果的话,那么可以很大的加快这一计算速度。这就循环神经网络反向传播的计算公式。
我们来看一下反向传播的特点,激活函数Tanh是一种S型函数,输出在-1和1之间,容易梯度消失。当输出值接近-1或者是1的时候,它的梯度值非常的小。当序列非常长的时候,从一个比较长的末端往前传梯度的时候,每次都需要乘一个(-1,1)之间的一个数,这个数就会导致梯度消失。因为乘以10个这样的数,就相当于整个值就变成了10^(-n),在这样一个级别下,梯度就消失了。所以说较远的步骤梯度贡献很小。基于这样的特点,我们需要在循环神经网络梯度下降的时候做一定的优化。比如说较远的步骤对当前梯度的贡献非常小,就可以把较远的步骤给忽略掉,节省很多的计算资源。切换其他激活函数后(不使用tanh,改成relu),可能也会导致梯度爆炸。因为梯度类似于卷积中的层次,它在循环神经网络反映出来是输入需要的长度,比如说一段文本有成百上千上万个词,如果切换了其他函数,而不是tanh之后,它每一步梯度可能会被放大,大于1的就会有放大的效果,就会导致比较后的步骤对于比较前的步骤的影响,每一步放大的话会导致梯度的爆炸,tanh是每一步梯度都会被缩小。
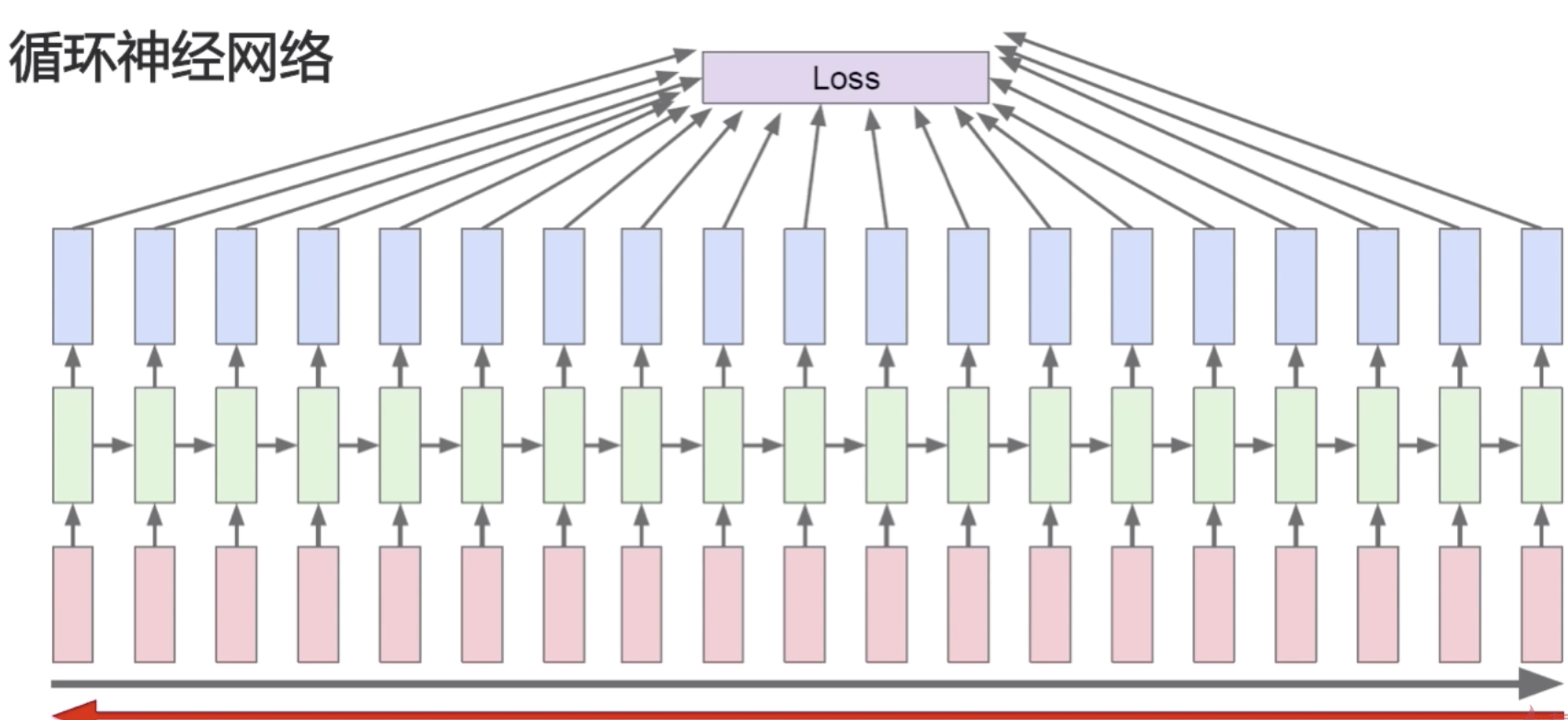
损失函数的计算是每一步的损失函数都加到最后的loss上来,然后去做梯度下降。

不过我们刚才也说了,因为较远的步骤,比如说第一的步骤,它可能对最后一步的梯度计算是很有限的,所以我们可以做一个优化,可以分区的去计算损失函数,把序列分成几个大的块,然后再分别去计算梯度。这一块计算完梯度之后,我们就认为它再往前的序列值就不会有影响。
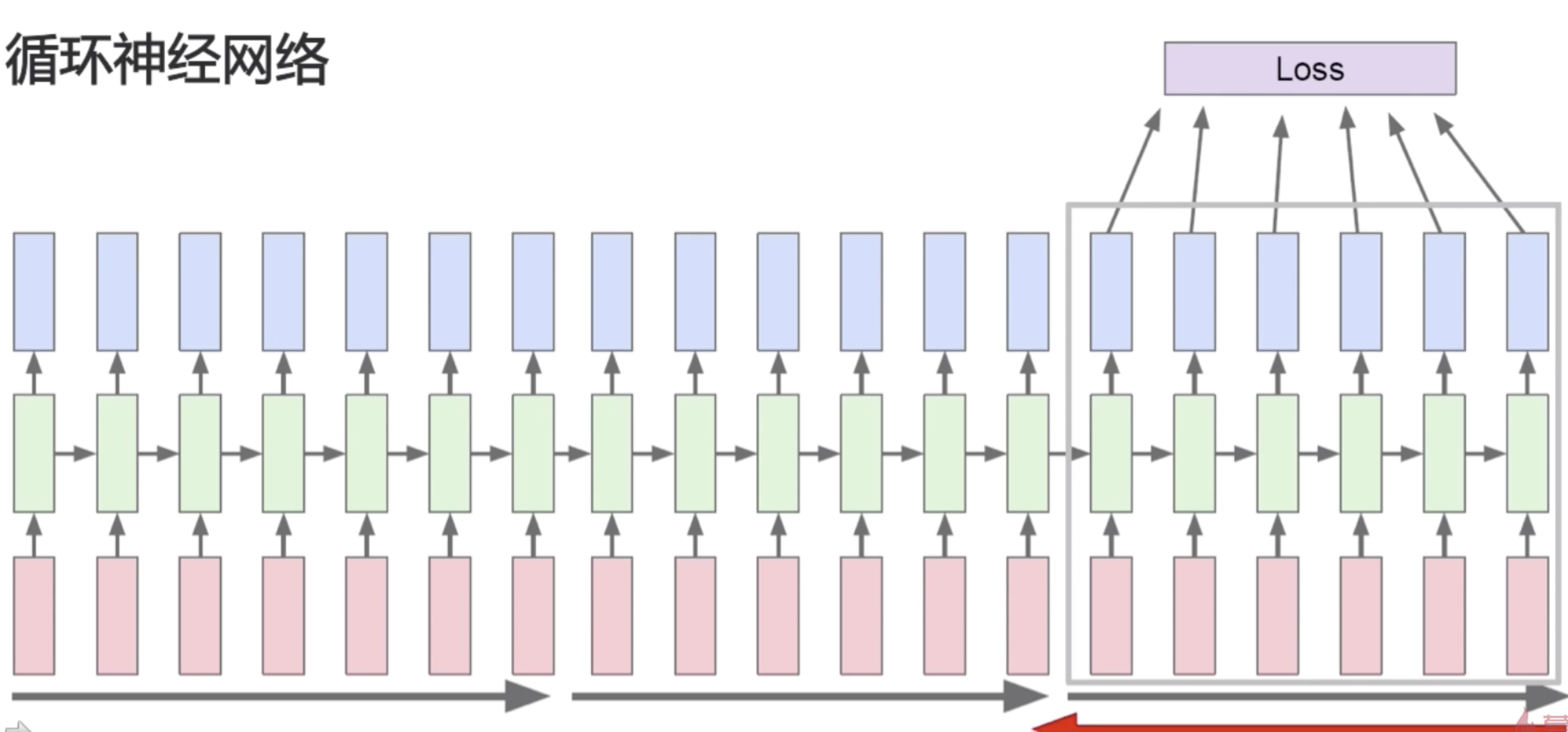
计算完一部分序列的梯度之后再去计算下一部分的梯度。
多层网络与双向网络
多层网络:底层输出作为高层输入

我们之前讲的都是单层的循环神经网络,在这里,我们可以像卷积神经网络一样,把层次都叠加在一起,形成一个多层的网络,底层作为高层的输入,同层之间依旧递归。增加网络拟合能力。和之前的卷积神经网络类似,加了多层之后,因为每一层都是非线性的变换,可以增加网络的拟合能力。一般隐层的维数是逐渐递增的,64 - 128 - 256.
RNN+残差链接
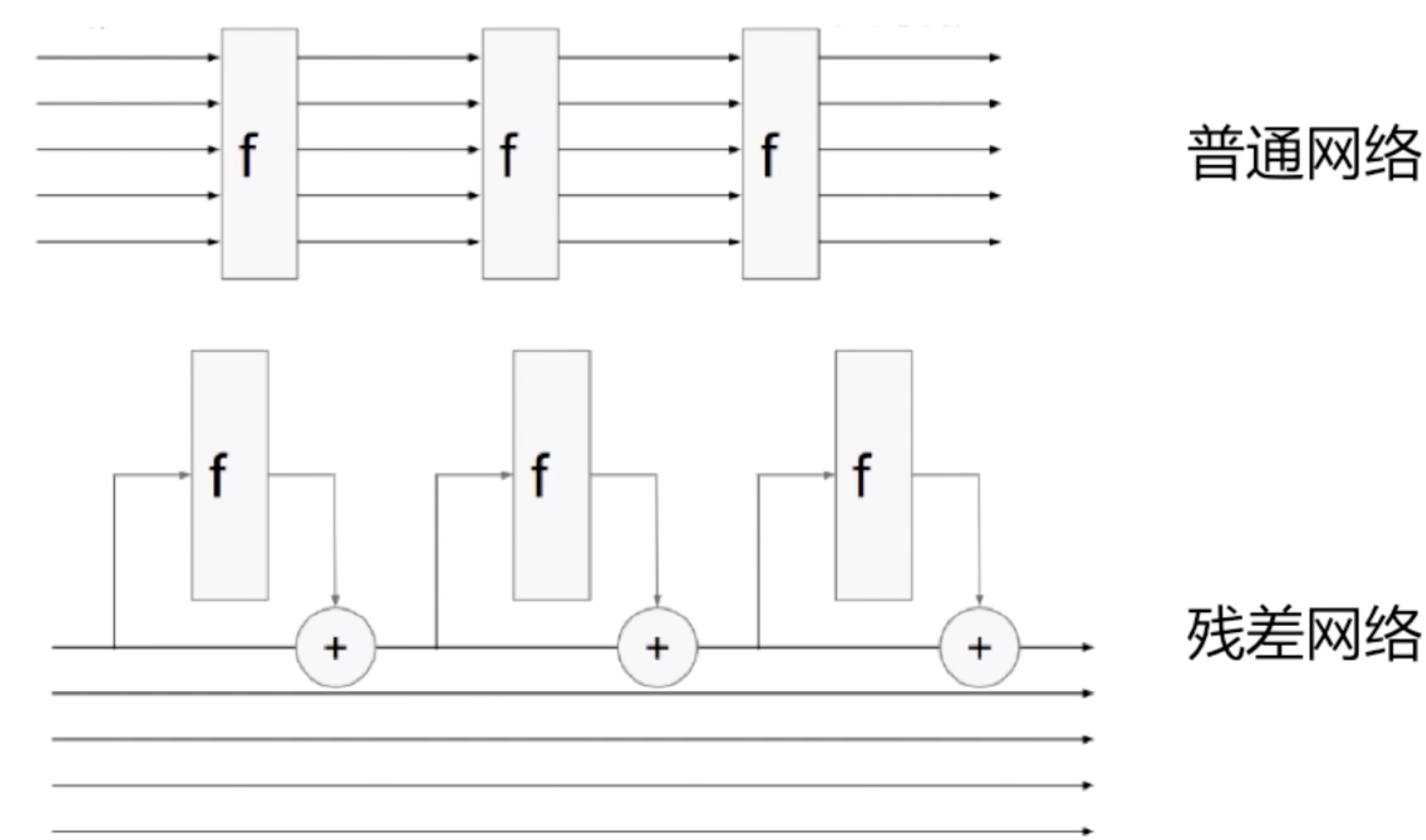
同样有了多层的循环神经网络,自然之前的卷积神经网络的设置也可以用到循环神经网络中,比如残差网络。我们让网络去学剩余的东西,而把原来的值给加到网络中来。
双向网络

另一路以未来状态为输入。对于循环神经网络和卷积神经网络的不同在于它的输入是一个序列,一个序列可以正向的做输入,也可以反向去做输入。在上图中我们可以看到,深绿色的是一个正向的循环神经网络结构,而浅绿色是一个逆向的循环神经网络结构。这样的网络结构就可以使得它学到上下文的信息。对于正向循环神经网络结构,我可以学到上文的信息,对于还没有输入的肯定还不知道,加了另外一路连接之后,就可以用到下文的信息。两个状态拼接后进入输出层,进一步提高表达能力。但是这样就无法实时的输出结果了,双向网络运用的问题的空间会比较小。但是对于非实时的机器翻译,是可以使用双向神经网络结构的,而且会比单向获得更好的效果。
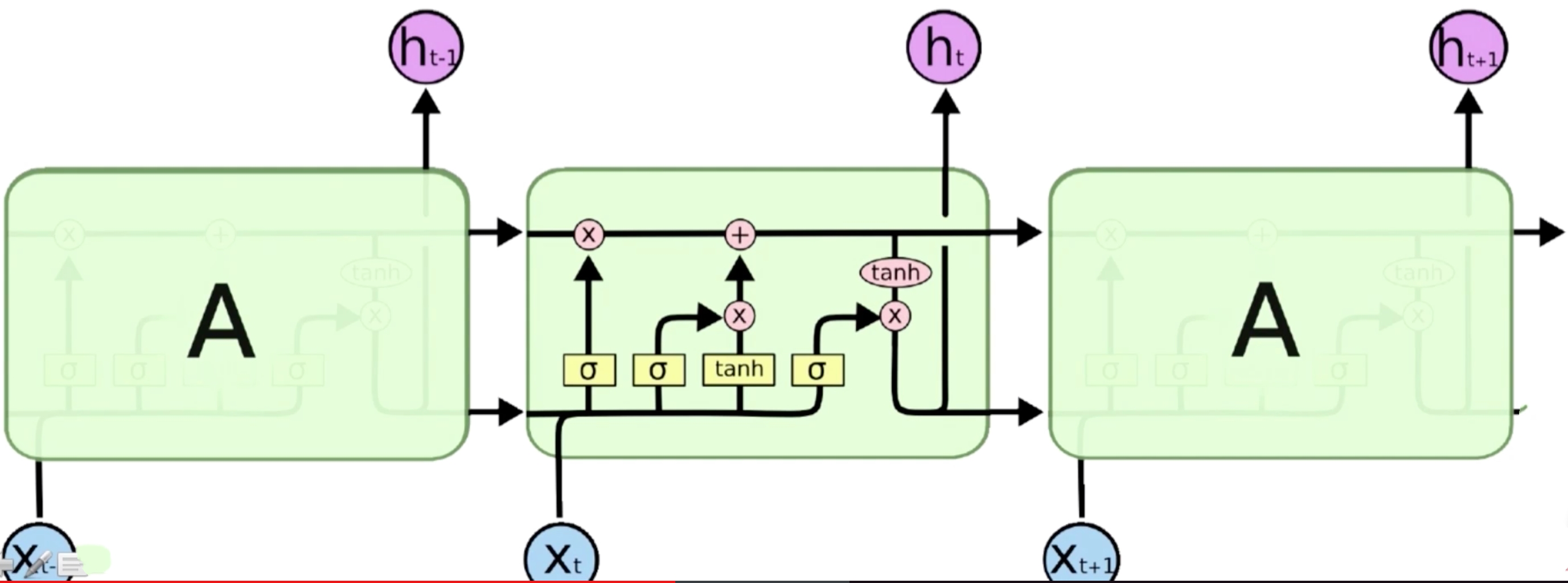
长短期记忆网络
为什么需要LSTM
- 普通RNN的信息不能长久传播(存在于理论上)
循环网络只有一个隐含状态,然后一个隐含状态可以对待一个序列不停的往下面的步骤里传数据,传到最后,就可以保存上下文的信息。如果是单向的话,就只能保存上文的信息。对于这样一个网络,它的缺点就在于它对序列中的信息没有任何的甄别,而是要神经网络靠参数去进行甄别。而它的参数只有一个,在每一步的循环状态中,只有一个W,这相当于就是我们中间需要学很多的规则,比如新开了一句话,而之前有一句话,那么下面这句话换个主语,这个时候就需要知道需要把这个主语的上文信息给更换一下,把之前的忘掉,用这个新的。需要越来越多的这种规则。但是对于参数只有一个W,而这个W只是一个矩阵,它承载了太多,相当于在卷积神经网络中层次过多的时候,参数就会很多,容量就会很大,就会导致过拟合。但是在循环神经网络这个例子中,参数只有一个W,如果加多层就是多个W,但是需要学到的信息很多,对于一个特别长的句子,要删掉什么信息,要记住什么信息,要更新什么信息。这相当于是W过载了,它无法记住那么多的信息,所以就导致了普通RNN的信息只在理论上存在着可以长久传播的方法。不然的话,它还是只能记住最近的一些信息。
为了解决这个问题,引入了LSTM(长短期记忆网络),L是Long,S是Short,T是Term,M是Memory。它引入了选择性机制。
- 选择性输出
- 选择性输入
- 选择性遗忘
相当于在网络结构中对输入和输出都做了一个控制,如果一个输入没什么用的话,就不输入进来;如果当前信息还不需要输出出去,而需要记在当前状态里面,这个时候就控制不让它输出。比如换了一句新的主语,可以需要忘掉之前的主语,在这个时候选择性遗忘的机制就可以帮我们把之前的主语给忘掉。LSTM是普通循环神经网络的扩展,它把中间的RNN的单元给扩展了。对于一个多层网络上,它相当于是在每一层网络上都做了一个子结构的细分。这个子结构的细分就是引入了选择性的机制,这个机制的实现
选择性-> 门,Sigmoid函数[0,1],这个门的计算相当于从某个地方传过来一个值,这个值是0到1之间的一个数,因为是0到1的一个数,我们用σ函数去做最后的变换,0到1之间的就是它需要记住或者是需要遗忘的成分,比如说一个数是10,经过这个门之后,可能门里面的数是0,10*0,就需要把这个数给忘掉。如果门里面的数是1,10*1,就需要把这个数给记住。门里面的数是0.5,10*0.5,就只需要把这个数记住50%。这个门是用来实现选择性机制的。
LSTM模型结构Overview
|








- 上一条: 【核心技术】Apache Flink CDC 批流融合技术原理分析 2021-10-15
- 下一条: 低复杂度 - 服务网格的下一站 2021-10-15
- 机器学习算法整理(二) 2021-08-30
- 机器学习算法整理(四) 2021-09-19
- 机器学习算法整理(三) 2021-09-13
- 0基础都能看懂的算法图解 2021-07-19
- 机器学习和深度学习的区别 2022-02-18


