机器学习算法整理(二)
scikit-learn中的PCA
from sklearn.decomposition import PCA import numpy as np import matplotlib.pyplot as plt if __name__ == "__main__": X = np.empty((100, 2)) X[:, 0] = np.random.uniform(0, 100, size=100) X[:, 1] = 0.75 * X[:, 0] + 3 + np.random.normal(0, 10, size=100) pca = PCA(n_components=1) pca.fit(X) print(pca.components_) X_reduction = pca.transform(X) print(X_reduction.shape) X_restore = pca.inverse_transform(X_reduction) print(X_restore.shape) plt.scatter(X[:, 0], X[:, 1], color='b', alpha=0.5) plt.scatter(X_restore[:, 0], X_restore[:, 1], color='r', alpha=0.5) plt.show()
运行结果
[[-0.78144234 -0.62397746]]
(100, 1)
(100, 2)
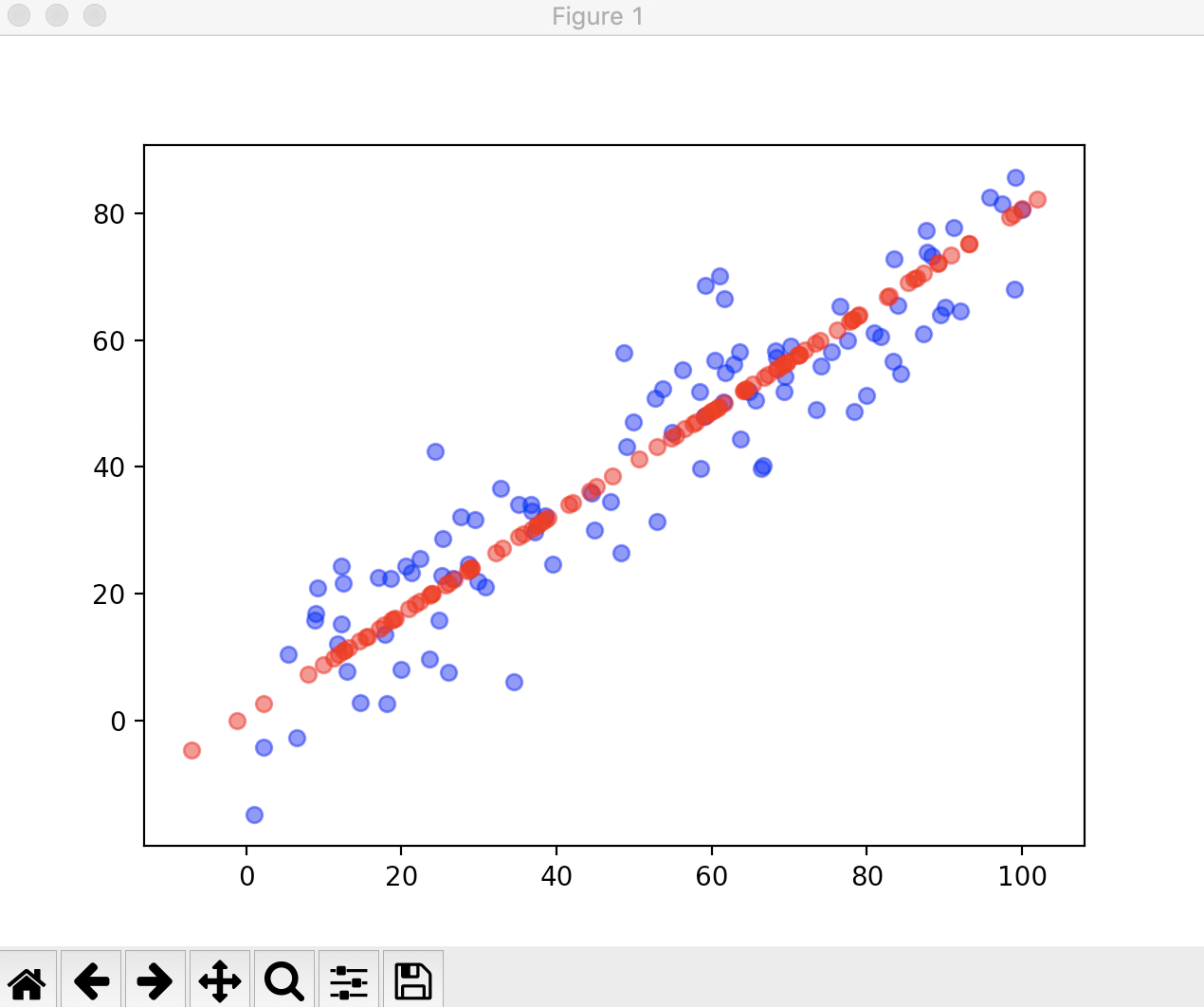
现在我们用真实的数据来看一下scikit-learn中的PCA的使用,我们要处理的是一组手写识别的数据分类。
import numpy as np import matplotlib.pyplot as plt from sklearn import datasets from sklearn.model_selection import train_test_split if __name__ == "__main__": digits = datasets.load_digits() X = digits.data y = digits.target # 对数据集进行训练数据和测试数据分类 X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=666) print(X_train.shape)
运行结果
(1347, 64)由结果我们可以看到我们的训练数据集有1347个样本数,每个样本有64个特征(维度)。我们先对原始的数据进行一下训练,看一看相应的识别率是多少。由于目前我们只用过一种分类算法——KNN算法,所以我们就使用KNN算法来进行分类。
import numpy as np import matplotlib.pyplot as plt from sklearn import datasets from sklearn.model_selection import train_test_split from sklearn.neighbors import KNeighborsClassifier import timeit if __name__ == "__main__": digits = datasets.load_digits() X = digits.data y = digits.target # 对数据集进行训练数据和测试数据分类 X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=666) print(X_train.shape) start_time = timeit.default_timer() knn_clf = KNeighborsClassifier() knn_clf.fit(X_train, y_train) print(timeit.default_timer() - start_time) print(knn_clf.score(X_test, y_test))
运行结果
(1347, 64)
0.0025633269999999486
0.9866666666666667由结果可以看到,KNN算法对原始数据集的训练时间是2.5毫秒,训练结果对测试数据集进行打分为0.98分,识别准确率能达到98.66%。
现在我们对原始数据进行降维,再对降维后的数据进行训练
import numpy as np import matplotlib.pyplot as plt from sklearn import datasets from sklearn.model_selection import train_test_split from sklearn.neighbors import KNeighborsClassifier from sklearn.decomposition import PCA import timeit if __name__ == "__main__": digits = datasets.load_digits() X = digits.data y = digits.target # 对数据集进行训练数据和测试数据分类 X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=666) print(X_train.shape) start_time = timeit.default_timer() knn_clf = KNeighborsClassifier() knn_clf.fit(X_train, y_train) print(timeit.default_timer() - start_time) print(knn_clf.score(X_test, y_test)) # 将原始数据的特征降为2维 pca = PCA(n_components=2) pca.fit(X_train) X_train_reduction = pca.transform(X_train) X_test_reduction = pca.transform(X_test) # 对降维后的数据集进行KNN训练 start_time = timeit.default_timer() knn_clf = KNeighborsClassifier() knn_clf.fit(X_train_reduction, y_train) print(timeit.default_timer() - start_time) print(knn_clf.score(X_test_reduction, y_test))
运行结果
(1347, 64)
0.0021396940000000253
0.9866666666666667
0.0005477309999999402
0.6066666666666667通过结果我们可以看到,降维后的训练时间变成了0.54毫秒,说明训练时间减少了很多,但是识别准确率只有60.6%。由此我们想到的是原来有64个维度的信息,现在一下子降到了2维,识别准确率从98.66%变成了60.6%,是不是可以增加降低的维度,来提高识别准确率呢?但是这个维度又是多少合适呢?
实际上,PCA算法为我们提供了一个特殊的指标,我们可以使用这种指标非常方便的找到对于某一个数据集来说,我们保持降低的维度就够。PCA中的这个指标叫做解释的方差比例。我们来看一下降到2维时的这个比例。
import numpy as np import matplotlib.pyplot as plt from sklearn import datasets from sklearn.model_selection import train_test_split from sklearn.neighbors import KNeighborsClassifier from sklearn.decomposition import PCA import timeit if __name__ == "__main__": digits = datasets.load_digits() X = digits.data y = digits.target # 对数据集进行训练数据和测试数据分类 X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=666) print(X_train.shape) start_time = timeit.default_timer() knn_clf = KNeighborsClassifier() knn_clf.fit(X_train, y_train) print(timeit.default_timer() - start_time) print(knn_clf.score(X_test, y_test)) # 将原始数据的特征降为2维 pca = PCA(n_components=2) pca.fit(X_train) X_train_reduction = pca.transform(X_train) X_test_reduction = pca.transform(X_test) # 对降维后的数据集进行KNN训练 start_time = timeit.default_timer() knn_clf = KNeighborsClassifier() knn_clf.fit(X_train_reduction, y_train) print(timeit.default_timer() - start_time) print(knn_clf.score(X_test_reduction, y_test)) # 解释的方差比例 print(pca.explained_variance_ratio_)
运行结果
(1347, 64)
0.002134913000000016
0.9866666666666667
0.0005182209999999854
0.6066666666666667
[0.14566817 0.13735469]根据结果,我们降维后的两个维度,第一个维度可以解释14.5%原数据的方差,第二个维度可以解释13.7%原数据的方差。PCA就是为了寻找降维后方差最大,而这个指标就是说明了,降到某个维度后,维持了这个最大方差的百分比。而这两个维度的总百分比就是维持了最大方差的14.5%+13.7%=28.2%左右的比例,剩下的72%方差的信息就丢失了,这显然丢失的信息过多。
现在我们来看一下训练数据集所有特征的方差比例。
import numpy as np import matplotlib.pyplot as plt from sklearn import datasets from sklearn.model_selection import train_test_split from sklearn.neighbors import KNeighborsClassifier from sklearn.decomposition import PCA import timeit if __name__ == "__main__": digits = datasets.load_digits() X = digits.data y = digits.target # 对数据集进行训练数据和测试数据分类 X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=666) print(X_train.shape) start_time = timeit.default_timer() knn_clf = KNeighborsClassifier() knn_clf.fit(X_train, y_train) print(timeit.default_timer() - start_time) print(knn_clf.score(X_test, y_test)) # 将原始数据的特征降为2维 pca = PCA(n_components=2) pca.fit(X_train) X_train_reduction = pca.transform(X_train) X_test_reduction = pca.transform(X_test) # 对降维后的数据集进行KNN训练 start_time = timeit.default_timer() knn_clf = KNeighborsClassifier() knn_clf.fit(X_train_reduction, y_train) print(timeit.default_timer() - start_time) print(knn_clf.score(X_test_reduction, y_test)) # 解释的方差比例 print(pca.explained_variance_ratio_) # 查看所有特征的方差比例 pca = PCA(n_components=X_train.shape[1]) pca.fit(X_train) print(pca.explained_variance_ratio_)
运行结果
(1347, 64)
0.0023309580000000496
0.9866666666666667
0.0005462749999999295
0.6066666666666667
[0.14566817 0.13735469]
[1.45668166e-01 1.37354688e-01 1.17777287e-01 8.49968861e-02
5.86018996e-02 5.11542945e-02 4.26605279e-02 3.60119663e-02
3.41105814e-02 3.05407804e-02 2.42337671e-02 2.28700570e-02
1.80304649e-02 1.79346003e-02 1.45798298e-02 1.42044841e-02
1.29961033e-02 1.26617002e-02 1.01728635e-02 9.09314698e-03
8.85220461e-03 7.73828332e-03 7.60516219e-03 7.11864860e-03
6.85977267e-03 5.76411920e-03 5.71688020e-03 5.08255707e-03
4.89020776e-03 4.34888085e-03 3.72917505e-03 3.57755036e-03
3.26989470e-03 3.14917937e-03 3.09269839e-03 2.87619649e-03
2.50362666e-03 2.25417403e-03 2.20030857e-03 1.98028746e-03
1.88195578e-03 1.52769283e-03 1.42823692e-03 1.38003340e-03
1.17572392e-03 1.07377463e-03 9.55152460e-04 9.00017642e-04
5.79162563e-04 3.82793717e-04 2.38328586e-04 8.40132221e-05
5.60545588e-05 5.48538930e-05 1.08077650e-05 4.01354717e-06
1.23186515e-06 1.05783059e-06 6.06659094e-07 5.86686040e-07
1.71368535e-33 7.44075955e-34 7.44075955e-34 7.15189459e-34]现在我们可以看到这64个维度所有的方差比例,它是按照从大到小依次排列的。现在我们来绘制出前n个维度能解释的方差的和的图形。
plt.plot([i for i in range(X_train.shape[1])], [np.sum(pca.explained_variance_ratio_[: i + 1]) for i in range(X_train.shape[1])]) plt.show()
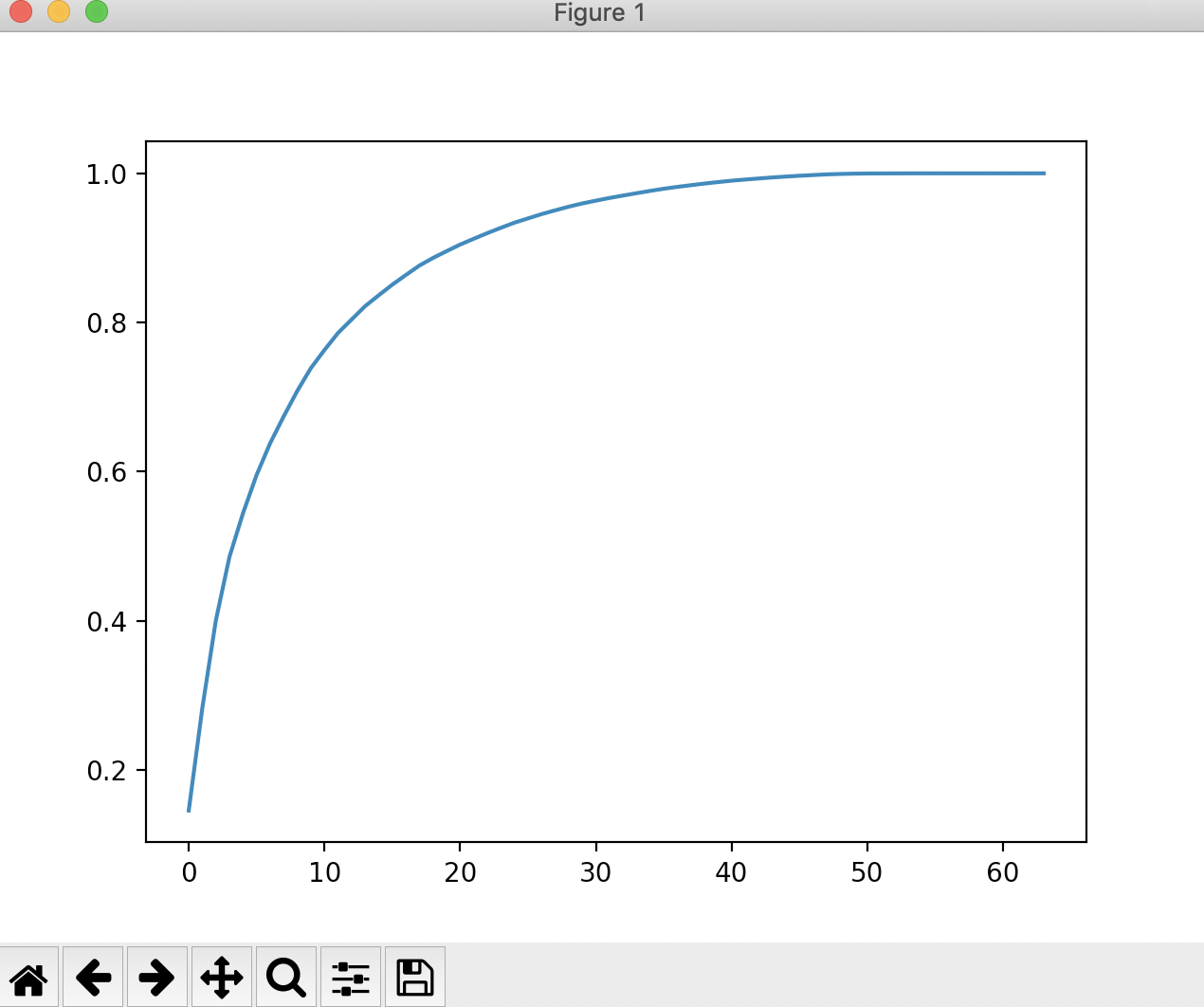
通过这个图,我们可以看出,当取的特征数越接近于原始数据特征数的时候,它能解释的方差的比例是越来越大的。此时如果我们需要保留95%以上的方差比例的时候,我们只需要在该图中纵轴0.95对应的图像的横轴是多少就可以了。这个功能scikt-learn中已经帮我们封装好了。
pca = PCA(0.95) pca.fit(X_train) print(pca.n_components_)
运行结果
28说明当我们需要保留95%的最大方差比例的时候,我们需要降低的维度就是28维。我们可以求出此时的降维后的数据集和训练时间,训练后测试数据集的识别准确率。
pca = PCA(0.95) pca.fit(X_train) print(pca.n_components_) X_train_reduction = pca.transform(X_train) X_test_reduction = pca.transform(X_test) start_time = timeit.default_timer() knn_clf = KNeighborsClassifier() knn_clf.fit(X_train_reduction, y_train) print(timeit.default_timer() - start_time) print(knn_clf.score(X_test_reduction, y_test))
运行结果
28
0.0014477489999999982
0.98结果显示,KNN训练时间为1.4毫秒,这比用全维度的原始数据集要快了一倍左右,识别准确率为98%,比原始数据集只少了0.66%的识别准确率。这完全是可以接受的,在数据集非常巨大的情况下,我们进行这样的降维可以大大减少训练时间,识别准确率也是非常高的。
最后,我们把原始数据降到2维也不是完全没有意义的,它的意义就在于可以方便我们进行可视化。
pca = PCA(n_components=2) pca.fit(X) X_reduction = pca.transform(X) print(X_reduction.shape) for i in range(10): # 一次绘制一个数据在二维平面中的点 plt.scatter(X_reduction[y == i, 0], X_reduction[y == i, 1], alpha=0.8) plt.show()
运行结果
(1797, 2)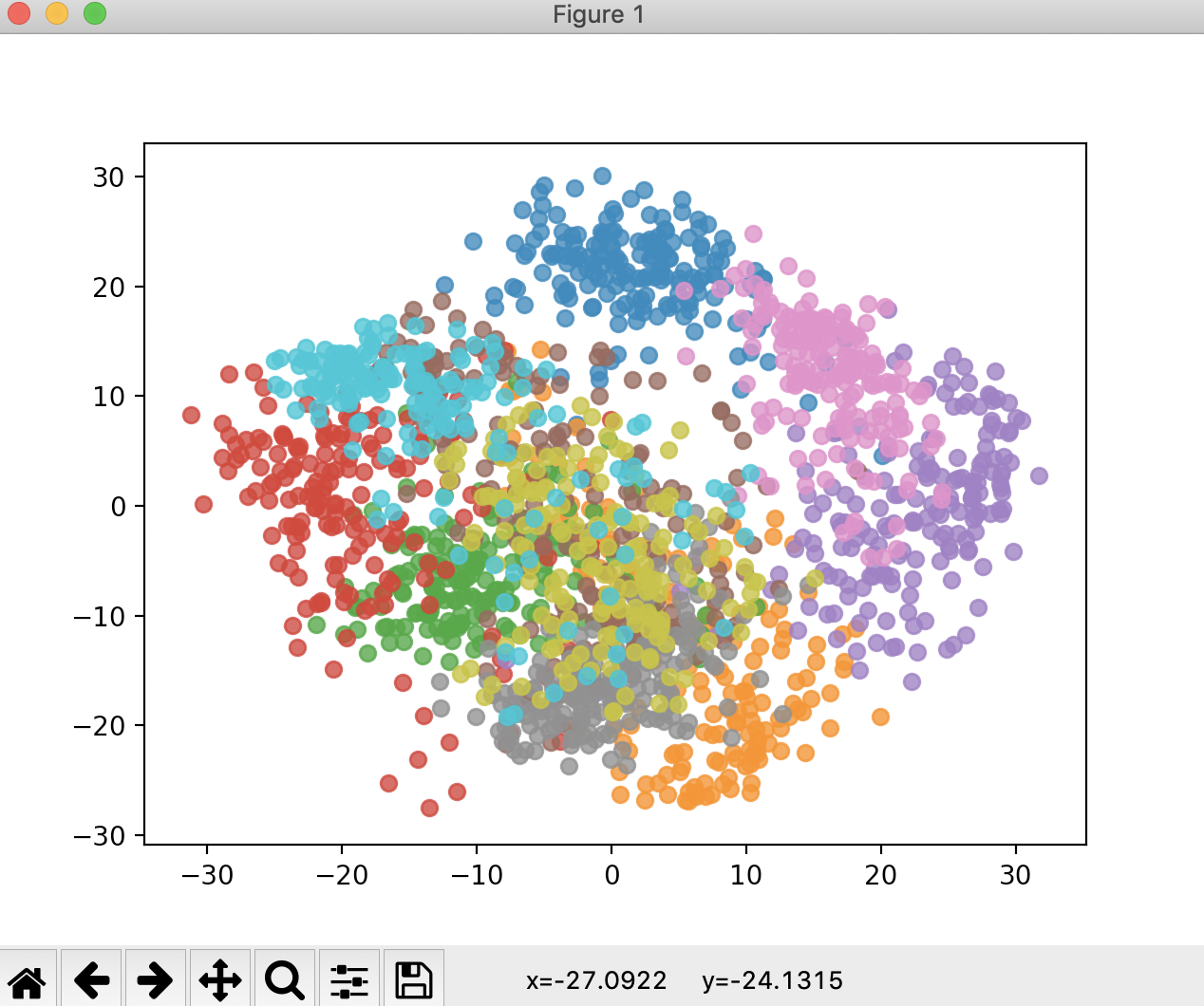
从图中可以看出(此时不做训练数据集和测试数据集的区分),每一个数据,它们的区分度也是非常高的。
|








- 上一条: 【HMC Core 6.0全球上线】图形计算服务新插件,助力高画质3D手游创新 2021-08-30
- 下一条: AI为啥能读懂说话人的情感? 2021-08-30
- 机器学习算法整理(三) 2021-09-13
- 机器学习算法整理(四) 2021-09-19
- Tensorflow深度学习算法整理(二) 2021-10-15
- 0基础都能看懂的算法图解 2021-07-19
- 机器学习和深度学习的区别 2022-02-18


