什么是大模型?超大模型?Foundation Model?
目前Foundation Model或者是大模型,特别地火,接下来介绍什么是大模型,大模型的基本概念;接着看看大模型的实际作用,然后基于这些实际作用,我们简单展开几个应用场景。最后就是介绍支持大模型训练的AI框架。
在往下看之前,想抛出几个问题,希望引起大家的一个思考:
1)为什么预训练网络模型变得越来越重要?
2)预训练大模型的未来的发展趋势,仍然是以模型参数量继续增大吗?
3)如何预训练一个百亿规模的大模型?
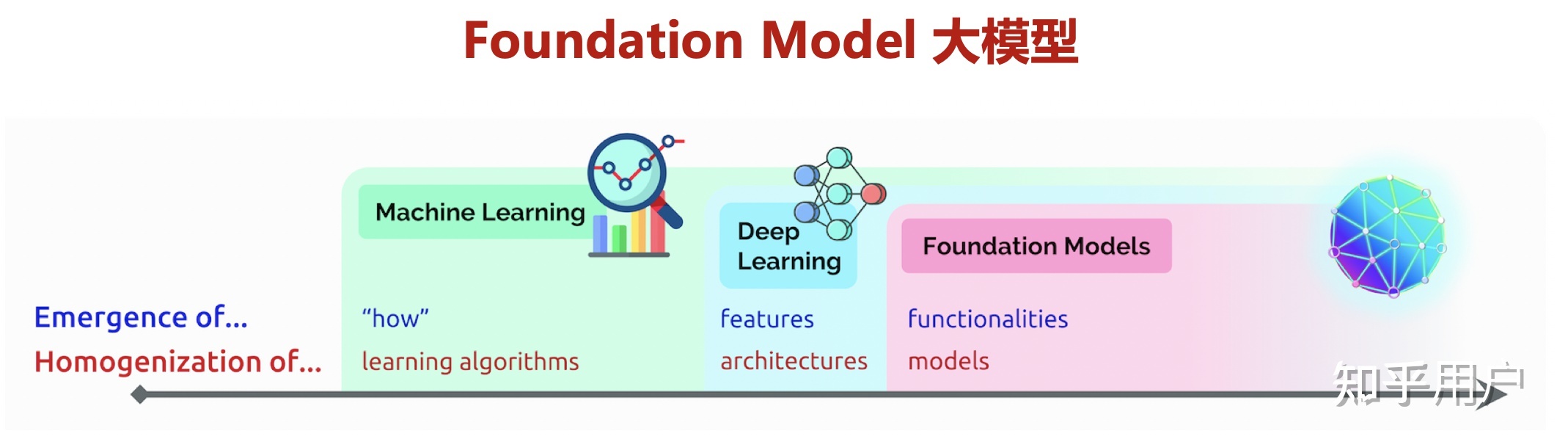
Foundation Model
2021年8月份,李飞飞和100多位学者联名发表一份200多页的研究报告《On the Opportunities and Risk of Foundation Models》,深度地综述了当前大规模预训练模型面临的机遇和挑战。

在文章中,AI专家将大模型统一命名为Foundation Models,可以翻译为基础模型或者是基石模型,论文肯定了Foundation Models对智能体基本认知能力的推动作用,同时也指出大模型呈现出「涌现」与「同质化」的特性。
所谓「涌现」代表一个系统的行为是隐性推动的,而不是显式构建的;「同质化」是指基础模型的能力是智能的中心与核心,大模型的任何一点改进会迅速覆盖整个社区,但其缺陷也会被所有下游模型所继承。
以GPT系列为例:
1)GPT-1是上亿规模的参数量,数据集使用了1万本书的BookCorpus,25亿单词量;
2)GPT-2参数量达到了15亿规模,其中数据来自于互联网,使用了800万在Reddit被链接过的网页数据,清洗后越40GB(WebText);
3)GPT-3参数规模首次突破百亿,数据集上将语料规模扩大到570GB的CC数据集(4千亿词)+WebText2(190亿词)+BookCorpus(670亿词)+维基百科(30亿词)。
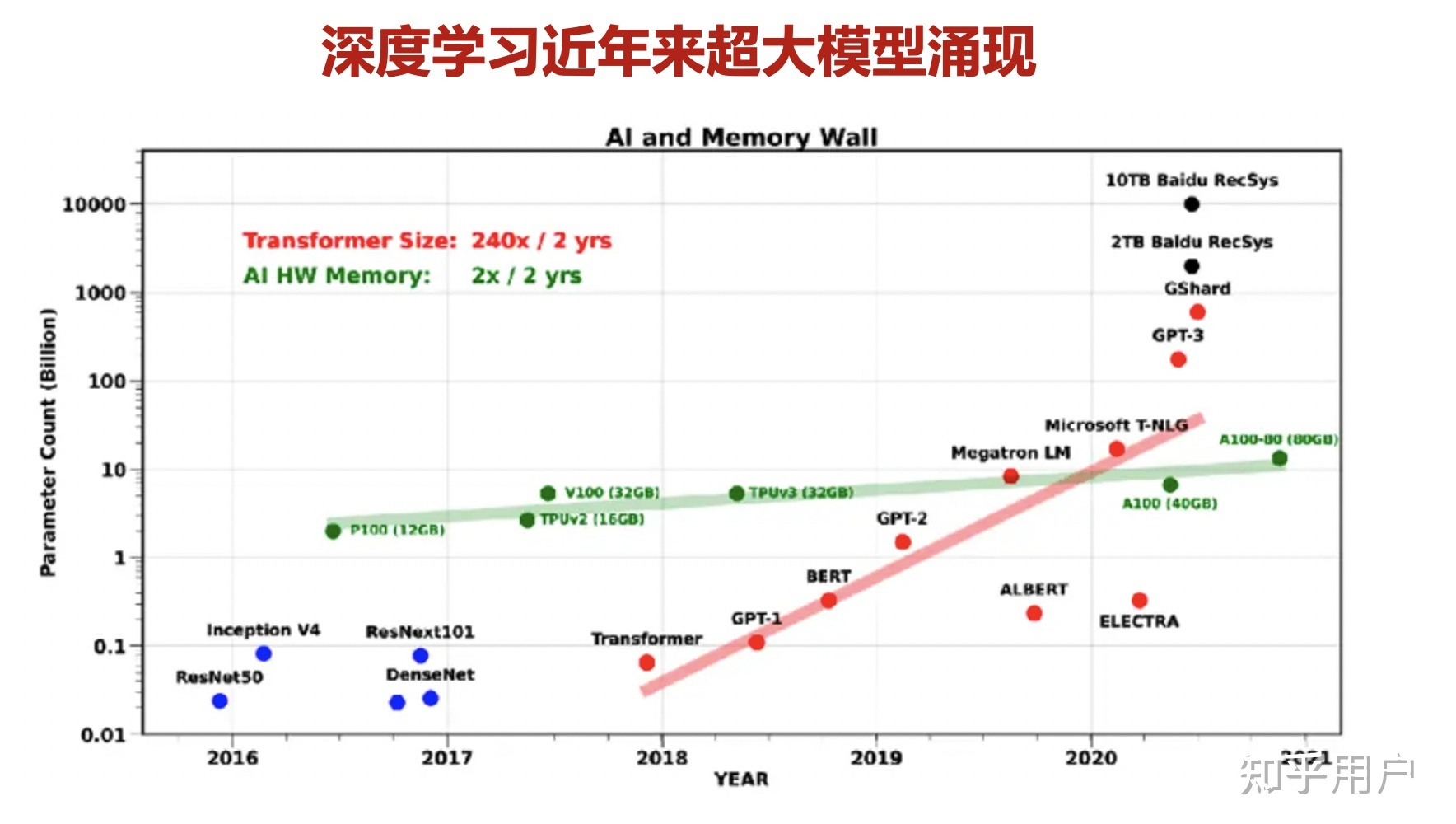
可以看到,数据上面,每一代均相比前一代有了数量级的飞跃,无论是语料的覆盖范围、丰富度上都是绝对规模的增长。可以预测到,下一代万亿模型,使用的数据如果相比GPT-3在质量、来源和规模上没有量级的变化,很难有质的提升。
大模型在产学各界掀起一阵阵巨浪,背后彰显的除了分布式并行和对AI算法的掌控能力,还是一次大公司通过AI工程的创举,利用大规模AI集群来进行掰手腕的故事。
随着网络模型越来越大,单机单卡、一机多卡、甚至多机多卡的小规模集群,只要网络模型参数量一旦超过十亿以上的规模,就很难用现有的资源训练了。于是有的研究者就会提出质疑:
- 一味的让模型变大、让参数量爆炸式增长,真的能让AI模型学习变得更好吗?
- 真的能带来真正的智能吗?
- 甚至有的同学还会挑战,小学数学题都解不好?
- 生成的文字内容不合逻辑?
- 给出的医疗建议不靠谱!
这里值得澄清的一点是,目前类似于GPT-3这样的大模型,在零样本和小样本的学习能力,主要来源于预训练阶段对海量语料的大量记忆,其次是语义编码能力、远距离依赖关系建模能力和文本生成能力的强化,以及自然语言进行任务描述等设计。而在训练目标方面,并没有显式的引导模型去学习小样本泛化能力,因此在一些小众的语料、逻辑理解、数学求解等语言任务上出现翻车的现象也是能理解的。
虽然大模型刚提出的时候,质疑的声音会有,但不可否认的是,大模型做到了早期预训练模型做不到、做不好的事情,就好像自然语言处理中的文字生成、文本理解、自动问答等下游任务,不仅生成的文本更加流畅,甚至内容的诉实性也有了显著的改善。当然,大模型最终能否走向通用人工智能仍是一个未知数,只是,大模型真的是有希望带领下一个很重要的人工智能赛道。
大模型的作用
有了大模型的基本介绍,我们来看看大模型的具体作用。
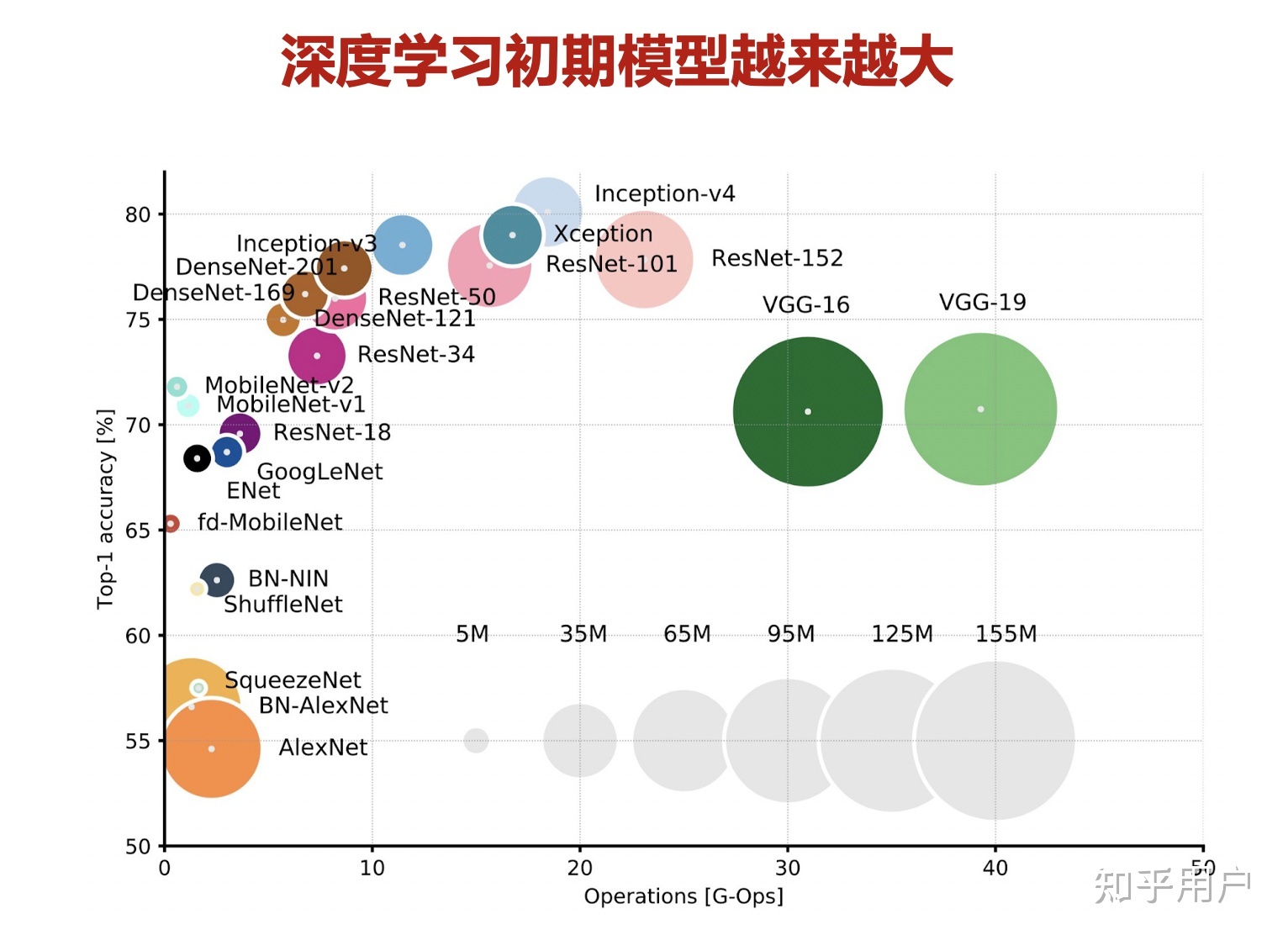
下面显示了深度学习技术在ImageNet图像数据集,随着新模型的提出,准确率不断取得突破的趋势。右图显示在网络预训练模型出来以后,机器对自然语言理解能力的不断提升。

虽然深度学习使得很多通用领域的精度和准确率得到很大的提升,但是AI模型目前存在很多挑战,最首要的问题是模型的通用性不高,也就是A模型往往专用于特定A领域,应用到领域B时效果并不好。
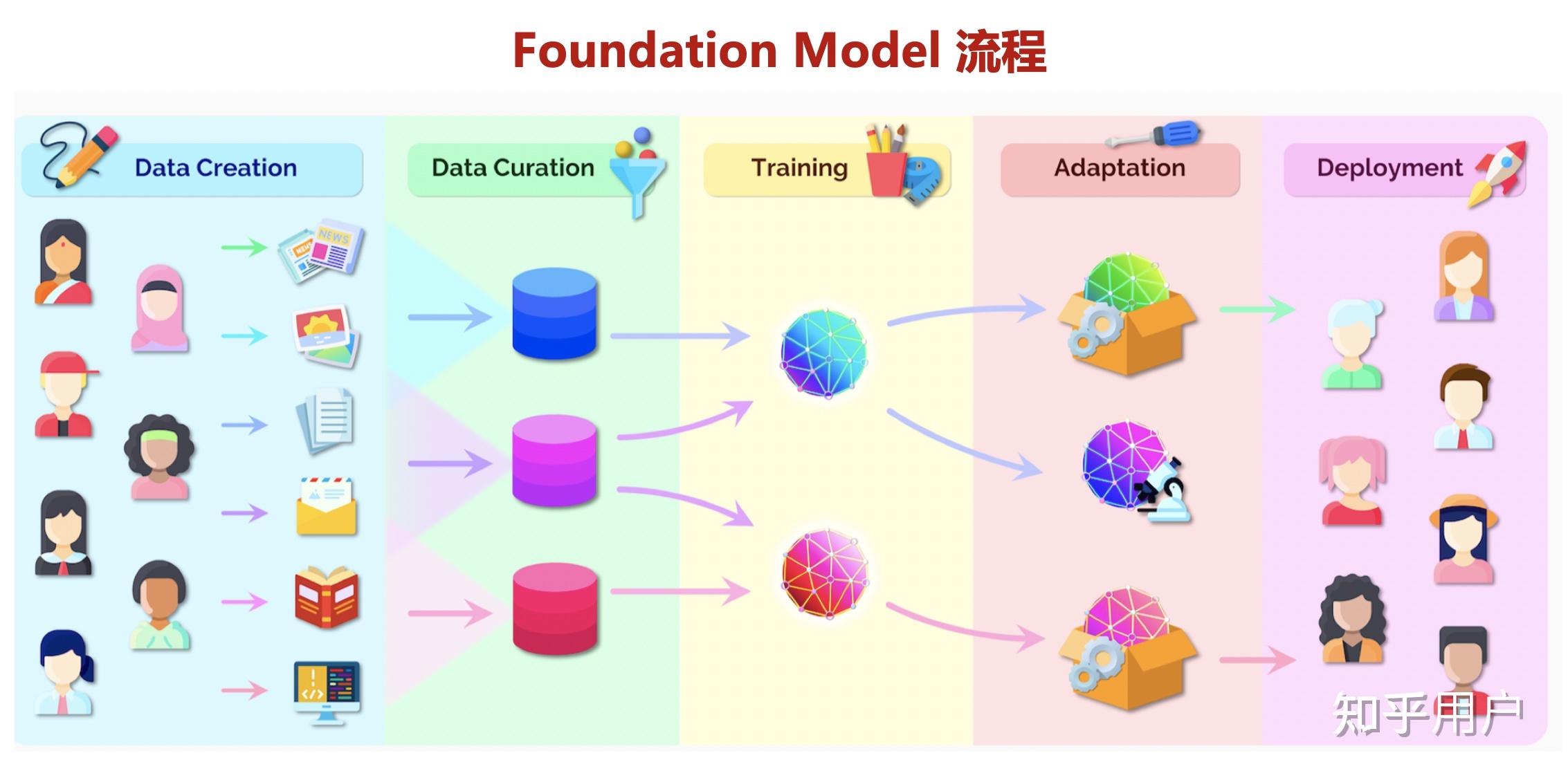
1) 模型碎片化,大模型提供预训练方案
目前AI面对行业、业务场景很多,人工智能需求正呈现出碎片化、多样化的特点。从开发、调参、优化、迭代到应用,AI模型研发成本极高,且难以满足市场定制化需求,所以网上有的人会说现阶段的AI模型研发处于手工作坊式。基本上一个公司想要用AI赋能自身的业务,多多少少也得招聘懂AI的研发人员。
为了解决手工作坊式走向工场模式,大模型提供了一种可行方案,也就是“预训练大模型+下游任务微调”的方式。大规模预训练可以有效地从大量标记和未标记的数据中捕获知识,通过将知识存储到大量的参数中并对特定任务进行微调,极大地扩展了模型的泛化能力。例如,在NLP领域,预训练大模型共享了预训任务和部分下游任务的参数,在一定程度上解决了通用性的难题,可以被应用于翻译,问答,文本生成等自然语言任务。

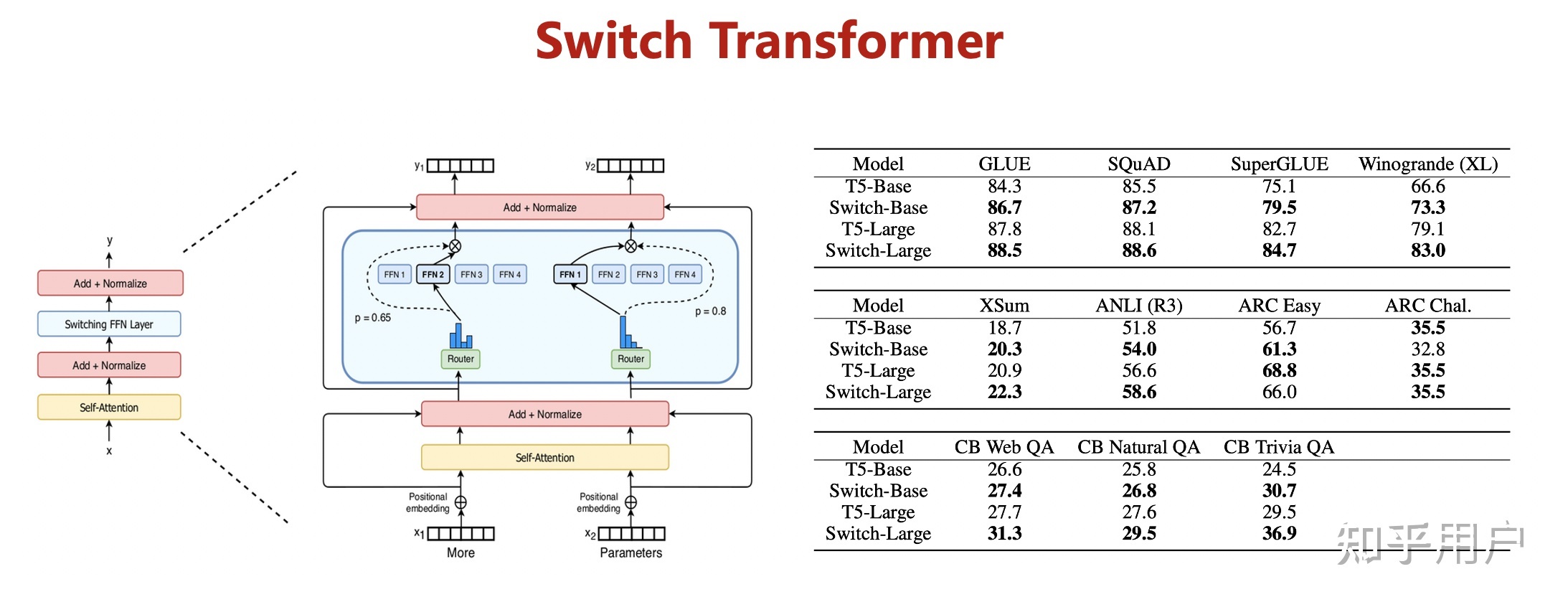
2)大模型具备自监督学习功能,降低训练研发成本
大模型的自监督学习方法,可以减少数据标注,在一定程度上解决了人工标注成本高、周期长、准确度不高的问题。由于减少了数据标准的成本,使得小样本的学习也能达到比以前更好的能力,并且模型参数规模越大,优势越明显,避免开发人员再进行大规模的训练,使用小样本就可以训练自己所需模型,极大降低开发使用成本。
2018年Bert首次提出,便一举击败 11 个 NLP 任务的 State-of-the-art 结果,成为了 NLP 界新的里程碑,同时为模型训练和NLP领域打开了新的思路:在未标注的数据上深入挖掘,可以极大地改善各种任务的效果。要知道,数据标注依赖于昂贵的人工成本,而在互联网和移动互联网时代,大量的未标注数据却很容易获得。
3)大模型有望进一步突破现有模型结构的精度局限
第三点,从深度学习发展前10年的历程来看,模型精度提升,主要依赖网络在结构上的变革。 例如,从AlexNet到ResNet50,再到NAS搜索出来的EfficientNet,ImageNet Top-1 精度从58提升到了84。但是,随着神经网络结构设计技术,逐渐成熟并趋于收敛,想要通过优化神经网络结构从而打破精度局限非常困难。近年来,随着数据规模和模型规模的不断增大,模型精度也得到了进一步提升,研究实验表明,模型和数据规模的增大确实能突破现有精度的一个局限。
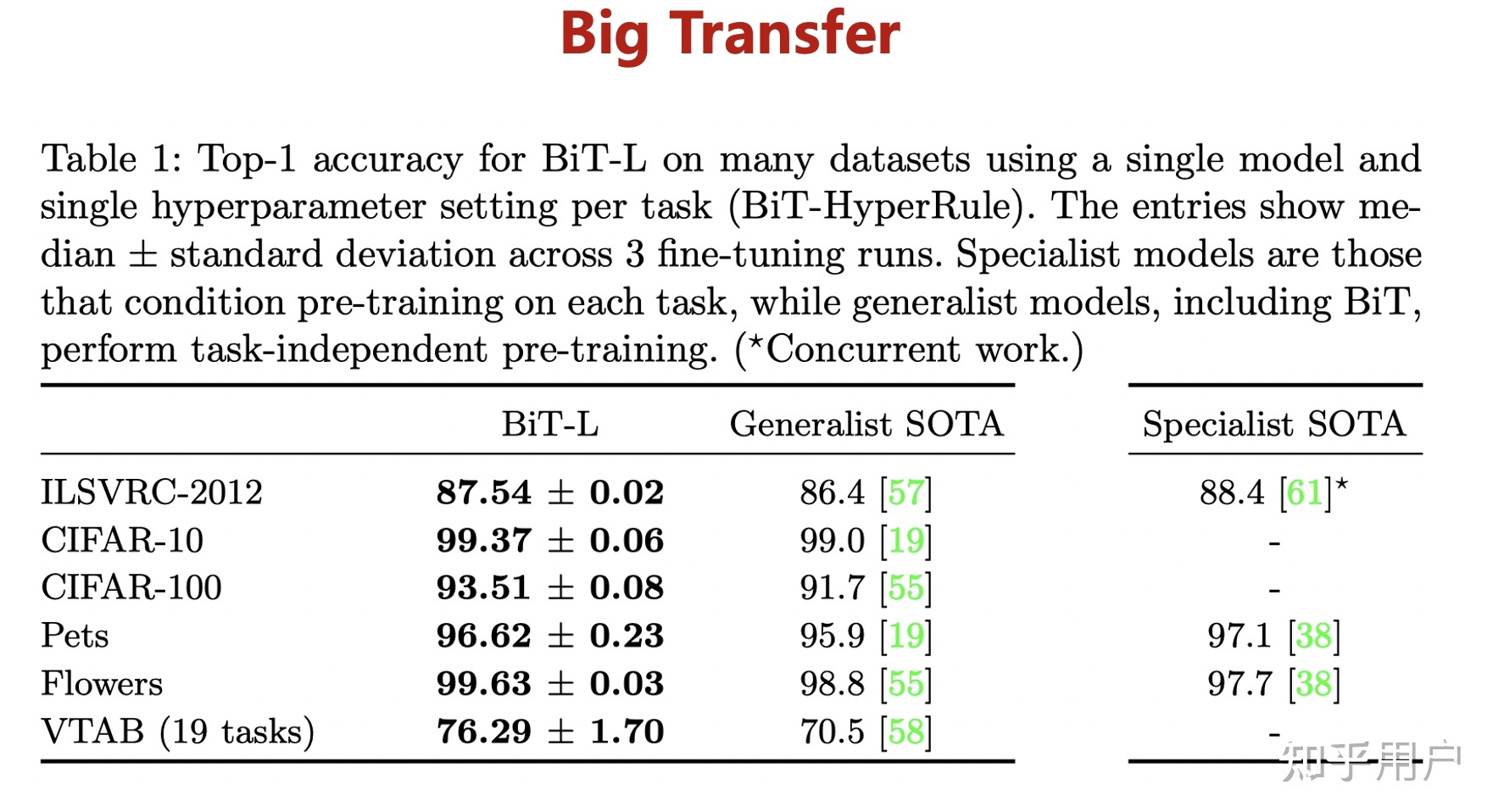
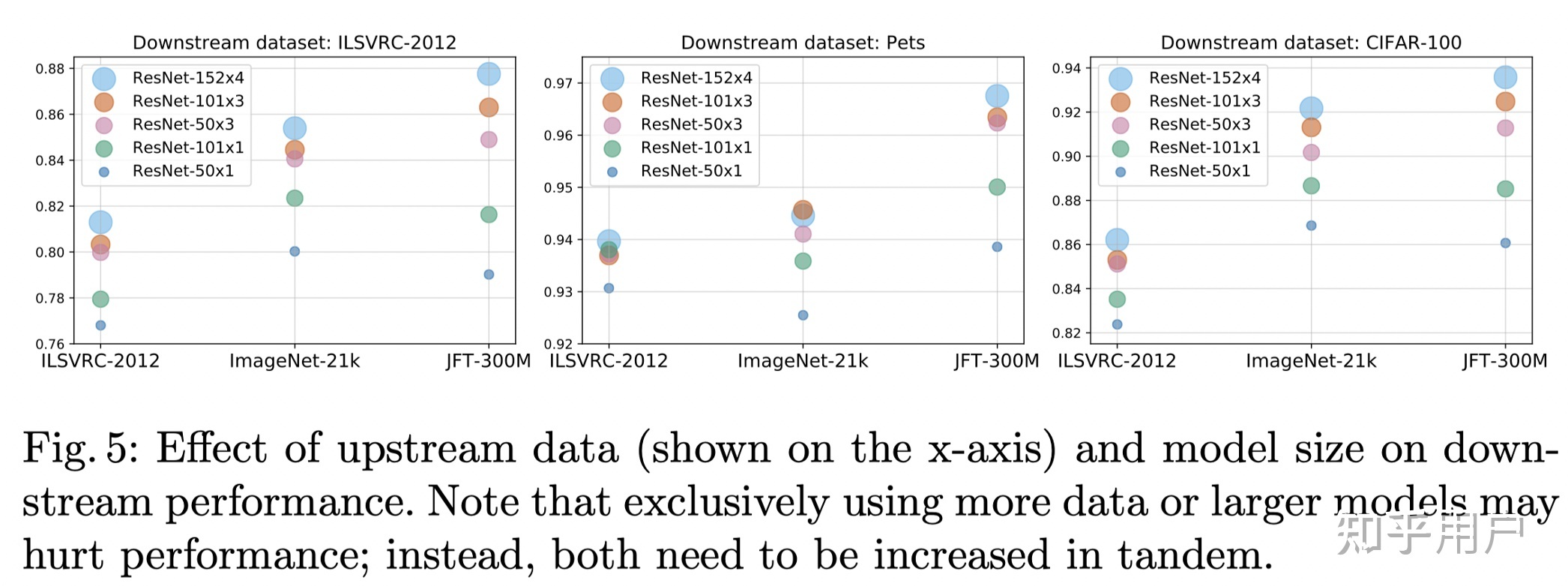
以谷歌2021年发布的视觉迁移模型Big Transfer,BiT为例。扩大数据规模也能带来精度提升,例如使用ILSVRC-2012(128 万张图片,1000 个类别)和JFT-300M(3亿张图片,18291个类别)两个数据集来训练ResNet50,精度分别是77%和79%。另外使用 JFT-300M训练ResNet152x4,精度可以上升到87.5%,相比ILSVRC-2012+ResNet50结构提升了10.5%。
大模型应用场景
既然大模型能突破训练精度的极限,还能够兼容下游任务。那有没有一些具体的应用场景介绍呢?
智源研究院针对2021年北京冬奥会,提出了“悟道”大模型用于冬奥手语播报数字人,提供智能化的数字人手语生成服务,方便听障人士也能收看赛事专题报道,提升他们的社会参与度和幸福感。这个项目还得到了北京市残疾人联合会和市残联聋人协会的大力支持。


当然也缺少不了最近双十一,双十一是淘宝系统服务最繁忙的一天,如何有效地应对成千上亿的用户咨询?基于达摩院开发的M6大模型智能生成内容文案,方便智能客服进行上下文理解和问题回答生成。另外大模型的多模态特征提取能力,也能进行商品属性标签补充、认知召回等下游任务。
大模型训练框架
目前部分深度学习框架,例如Pytorch和Tensorflow,没有办法满足超大规模模型训练的需求,于是微软基于Pytroch开发了DeepSpeed,腾讯基于Pytroch开发了派大星PatricStar,达摩院同基于Tensoflow开发的分布式框架Whale。像是华为昇腾的MindSpore、百度的PaddlePaddle,还有国内的追一科技OneFlow等厂商,对超大模型训练进行了深度的跟进与探索,基于原生的AI框架支持超大模型训练。


下面展开DeepSpeed和MindSpore来简单了解下。
2021年2月份微软发布了DeepSpeed,最核心的是显存优化技术ZeRO(零冗余优化器),通过扩大规模、内存优化、提升速度、控制成本,四个方面推进了大模型训练能力。基于DeepSpeed微软开发了拥有170亿参数的图灵自然语言生成模型(Turing-NLG)。(2021年5月份发布的ZeRO-2,更是支持2000亿参数的模型训练),另外微软联手英伟达,使用4480块A100组成的集群,发布了5300亿参数的NLP模型威震天-图灵(Megatron Turing-NLG)。
当然,作为国内首个支持千亿参数大模型训练的框架MindSpore这里面也提一下。在静态图模式下,MindSpore融合了流水线并行、模型并行和数据并行三种并行技术,开发者只需编写单机算法代码,添加少量并行标签,即可实现训练过程的自动切分,使得并行算法性能调优时间从月级降为小时级,同时训练性能相比业界标杆提升40%。
动态图模式下,MindSpore独特的函数式微分设计,能从一阶微分轻易地扩展到高阶微分,并进行整图性能优化,大幅提升动态图性能;结合创新的通讯算子融合和多流并行机制,较其它AI框架,MindSpore动态图性能提升60%。
最后就是针对大模型的训练,网上很多人会说,大模型需要“大数据+大算力+强算法”三驾马车并驾齐驱。
ZOMI并不是非常认同这个观点,大模型首先是需要规模更大的海量数据,同时需要庞大的算力去支撑这个说没错。但是整体来说,这是一个系统工程,从并行训练到大规模并行训练,其中就包括对AI集群调度和管理,对集群通讯带宽的研究,对算法在模型的并行、数据的并行等策略上与通讯极限融合在一起考虑,求解在有限带宽前提下,数据通讯和计算之间的最优值。
目前在大模型这个系统工程里面,最主要的竞争对手有基于英伟达的GPU+微软的DeepSpeed,Google的TPU+Tensorflow,当然还有华为昇腾Atlas800+MindSpore三大厂商能够实现全面的优化。至于其他厂商,大部分都是基于英伟达的GPU基础上进行一些创新和优化。最后就是,核心技术在市场上并不是最重要的,谁能够为客户创造更大的价值,才是最后的赢家。

作者:知乎ZOMI酱
链接:https://www.zhihu.com/question/498275802/answer/2221187242
来源:知乎
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
|








- 上一条: 完整过一遍axios,再也不怕写请求 2021-12-01
- 下一条: 我的截图插件被Gitee使用了 2021-12-01
- Java内存模型辟邪剑谱之JVM-Java Memory Model 2021-11-29
- props/$emit、v-model、.sync的适用场景 -- vue组件通信系列 2021-10-21
- 一个成功的 Git 分支模型 2021-08-01
- 推理加速性能超越英伟达FasterTransformer 50%,开源方案打通大模型落地关键路径 2022-05-31
- Nacos配置中心交互模型是 push 还是 pull ? 2021-07-08


