机器学习算法整理(四)
决策树
什么是决策树

比方说我们在招聘一个机器学习算法工程师的时候,会依照这样的流程进行逐层的评选,从而达到一个树形结构的决策过程。而在这棵树中,它的深度为3.最多通过3次判断,就能将我们的数据进行一个相应的分类。我们在这里每一个节点都可以用yes或者no来回答的问题,实际上我们真实的数据很多内容都是一个具体的数值。对于这些具体的数值,决策树是怎么表征的呢?我们先使用scikit-learn封装的决策树算法进行一下具体的分类。然后通过分类的结果再深入的认识一下决策树。这里我依然先加载鸢尾花数据集。
import numpy as np import matplotlib.pyplot as plt from sklearn import datasets if __name__ == "__main__": iris = datasets.load_iris() # 保留鸢尾花数据集的后两个特征 X = iris.data[:, 2:] y = iris.target plt.scatter(X[y == 0, 0], X[y == 0, 1]) plt.scatter(X[y == 1, 0], X[y == 1, 1]) plt.scatter(X[y == 2, 0], X[y == 2, 1]) plt.show()
运行结果
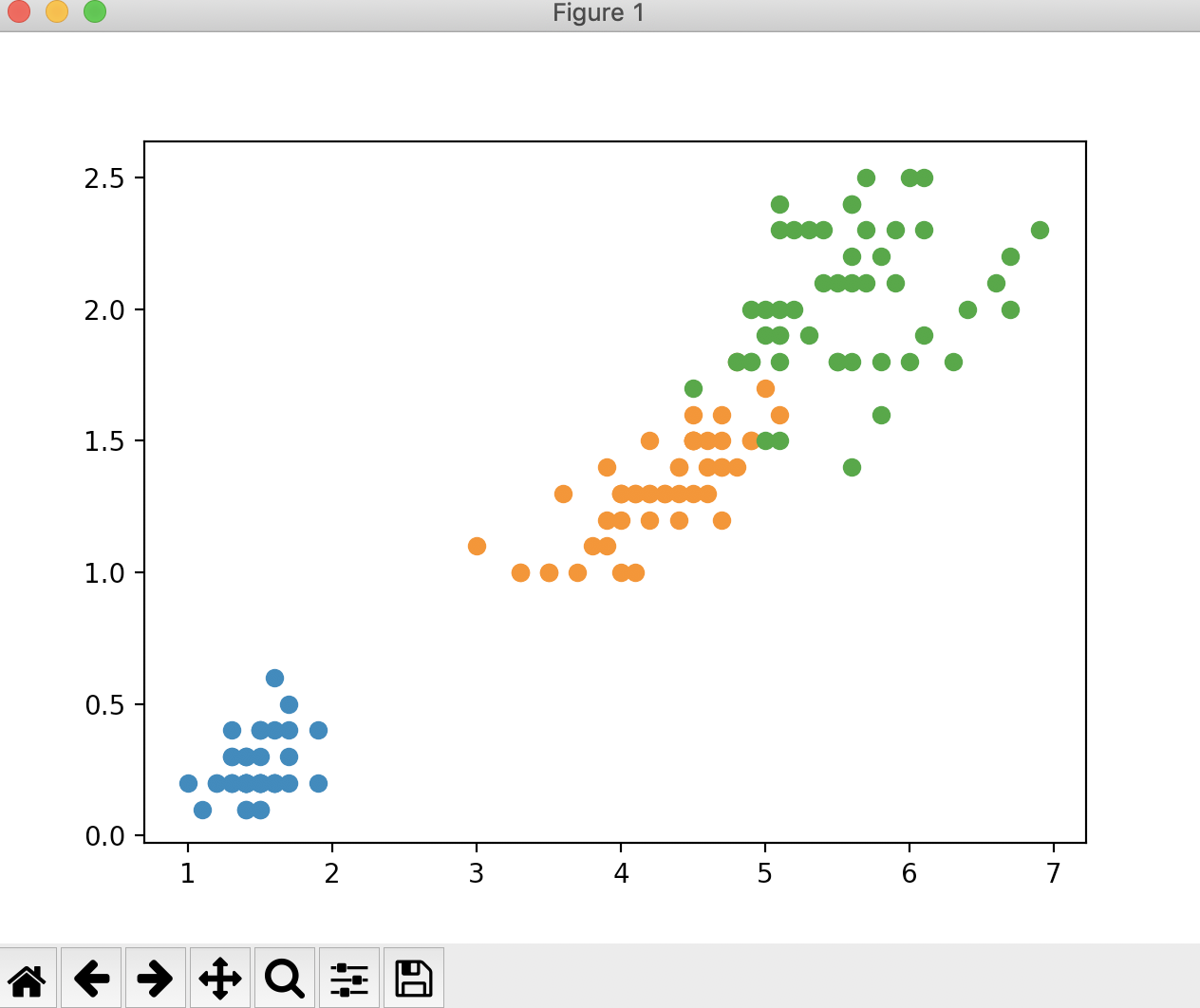
现在我们使用scikit-learn中的决策树来进行分类
import numpy as np import matplotlib.pyplot as plt from sklearn import datasets from sklearn.tree import DecisionTreeClassifier from matplotlib.colors import ListedColormap if __name__ == "__main__": iris = datasets.load_iris() # 保留鸢尾花数据集的后两个特征 X = iris.data[:, 2:] y = iris.target # plt.scatter(X[y == 0, 0], X[y == 0, 1]) # plt.scatter(X[y == 1, 0], X[y == 1, 1]) # plt.scatter(X[y == 2, 0], X[y == 2, 1]) # plt.show() dt_clf = DecisionTreeClassifier(max_depth=2, criterion='entropy') dt_clf.fit(X, y) def plot_decision_boundary(model, axis): # 绘制不规则决策边界 x0, x1 = np.meshgrid( np.linspace(axis[0], axis[1], int((axis[1] - axis[0]) * 100)).reshape(-1, 1), np.linspace(axis[2], axis[3], int((axis[3] - axis[2]) * 100)).reshape(-1, 1) ) X_new = np.c_[x0.ravel(), x1.ravel()] y_predict = model.predict(X_new) zz = y_predict.reshape(x0.shape) custom_cmap = ListedColormap(['#EF9A9A', '#FFF59D', '#90CAF9']) plt.contourf(x0, x1, zz, linewidth=5, cmap=custom_cmap) plot_decision_boundary(dt_clf, axis=[0.5, 7.5, 0, 3]) plt.scatter(X[y == 0, 0], X[y == 0, 1]) plt.scatter(X[y == 1, 0], X[y == 1, 1]) plt.scatter(X[y == 2, 0], X[y == 2, 1]) plt.show()
运行结果
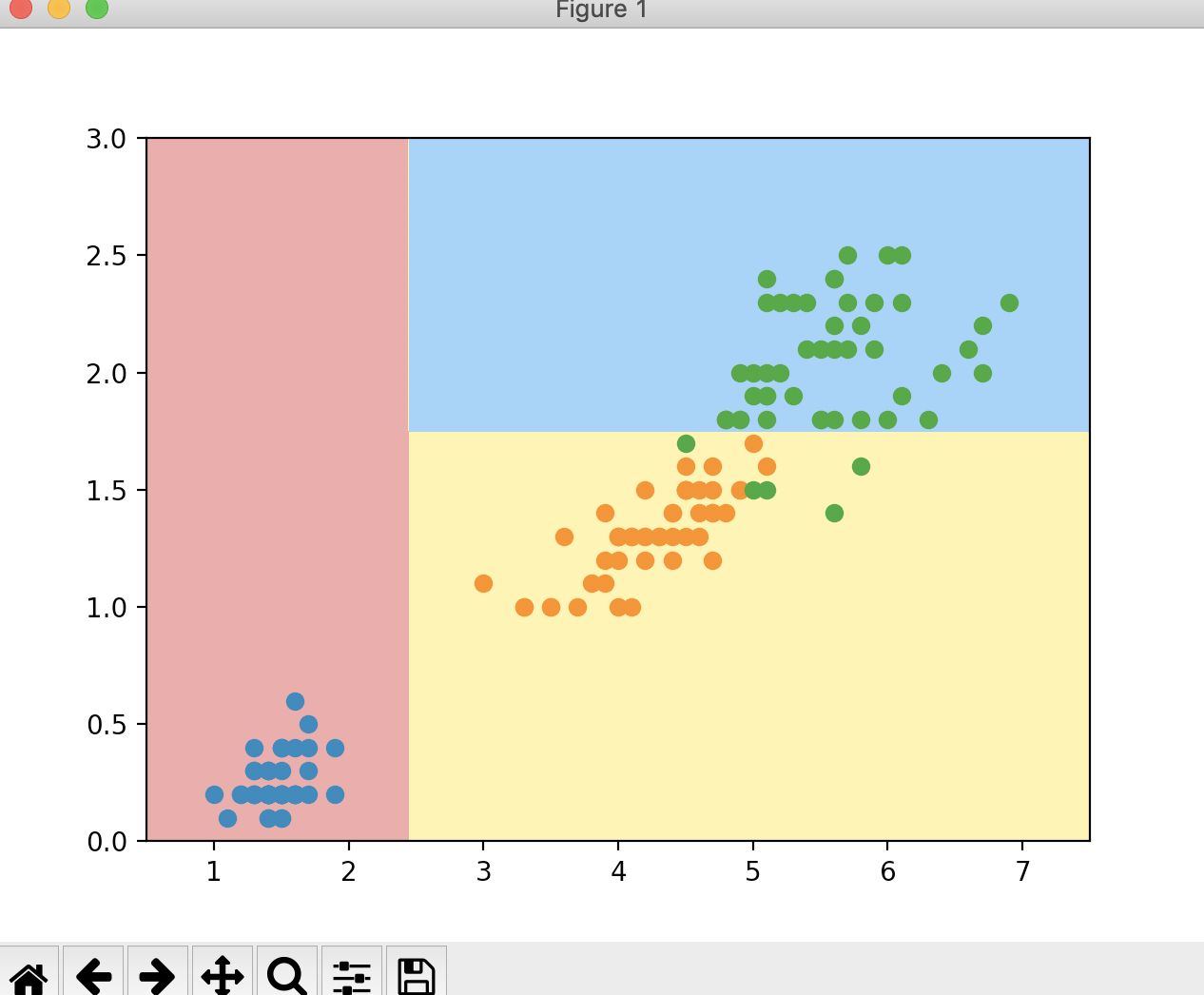
这就是决策树得到的决策边界。通过这个图,我们来画一个决策树,看看它是如何逐层决策的
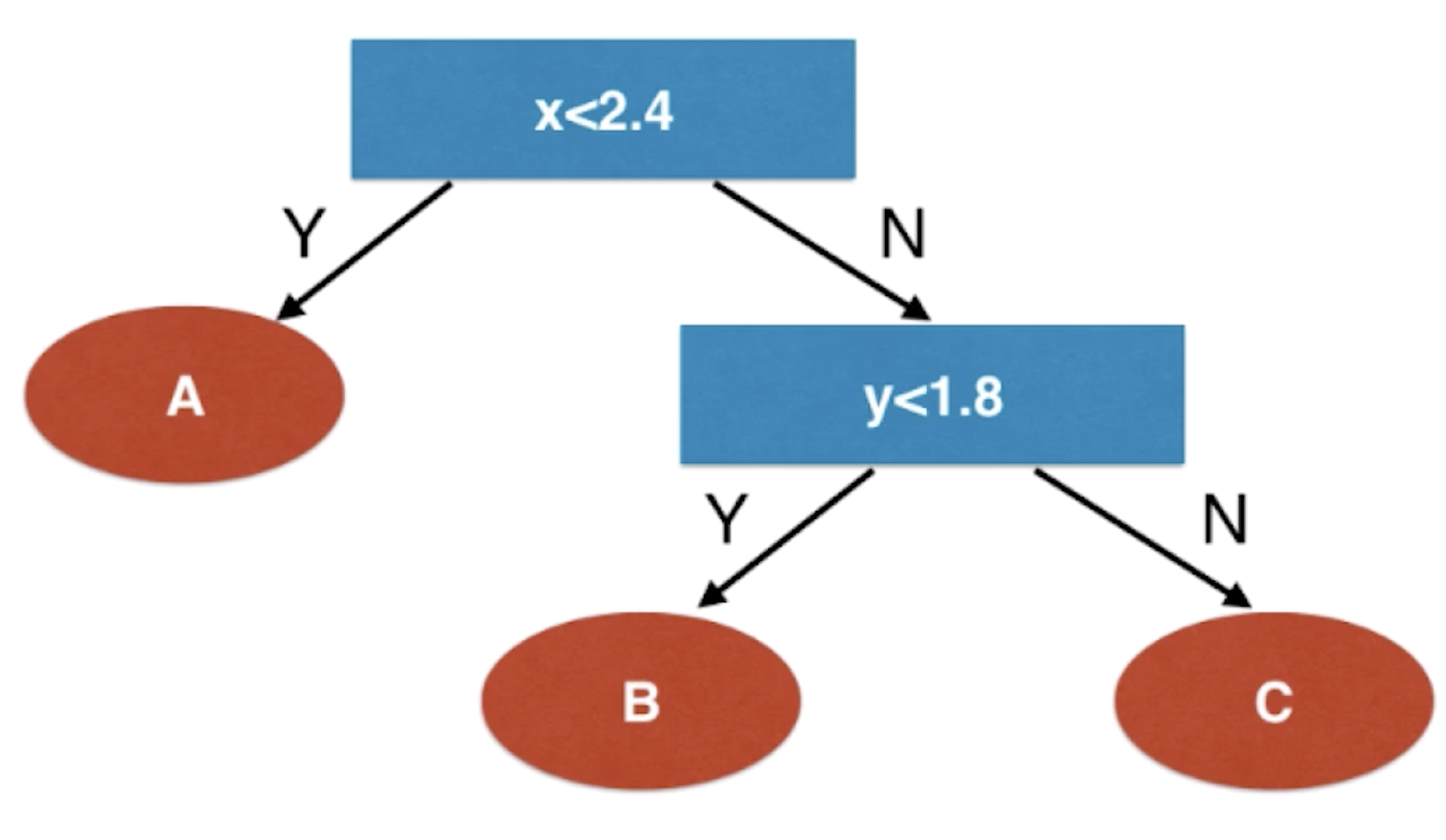
这就是决策树在面对属性是一种数值特征的时候是怎样处理的。在这里我们可以看到,在每一个节点上,它选择某一个维度,以及和这个维度相应的阈值,比如说在根节点的时候选的是x这个维度和2.4这个阈值。看我们的数据是大于等于2.4还是小于2.4分成两支。在右分支的子节点,选择了y这个维度和1.8这个阈值,看数据点到了这个节点的话是小于1.8还是大于等于1.8来进行分类。
首先决策树是一个非参数学习算法。其次决策树可以解决分类问题,而且可以天然的解决多分类问题。不像逻辑回归和SVM需要使用OvR或者OvO才能解决多分类问题。同时决策树也可以解决回归问题,我们可以用最终落在这个叶子节点中的所有的样本数据的平均值来当作回归问题的预测值。决策树算法也是具有非常好的可解释性。比如说我们在给用户的信用进行评级,比如说他的信用卡超过3次拖延支付,并且他的驾照平均每年都会被扣去8分,满足这样的条件,他的信用评级就会评为C级。我们可以非常容易的描述出来把样本数据分成某一个类的依据。我们现在的问题就是每个节点到底在哪个维度做划分?我们的数据复杂起来的话可能有成百上千个维度。如果我们选好了一个维度,那么我们要在某个维度的哪个值上做划分?这些都是构建决策树的关键问题。
信息熵
对于处理上面提到的问题——节点到底在哪个维度做划分?某个维度的哪个值上做划分?我们有一种方式来进行处理,那就是信息熵。
信息熵是信息论的基础概念,熵在信息论中代表随机变量不确定度的度量。熵越大,数据的不确定性越高;熵越小,数据的不确定性越低。熵是从物理热力学中引申出来的概念,熵越大,在一个封闭的热力系统中,分子无规则运动越剧烈,即不确定性越高;熵越小,封闭的热力系统中,分子越倾向于静止状态,它们的状态就越确定,即不确定性越低。我们来看一下香农提出来的信息熵公式。
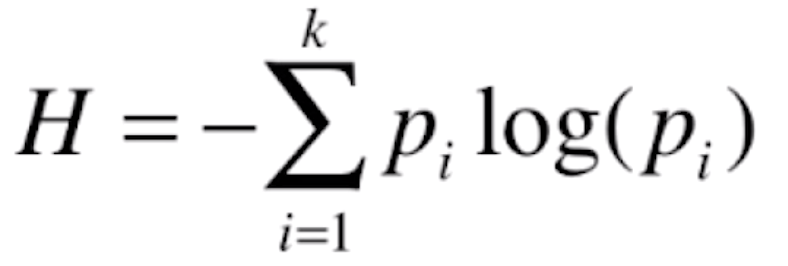
其中![]() 表示一个系统中有k类的信息,每一类信息所占的比例就叫做
表示一个系统中有k类的信息,每一类信息所占的比例就叫做![]() 。比如说在我们的鸢尾花数据集中一共有3种鸢尾花,每一种鸢尾花占的比例可能为1/3,则p1,p2,p3就分别等于1/3.由于
。比如说在我们的鸢尾花数据集中一共有3种鸢尾花,每一种鸢尾花占的比例可能为1/3,则p1,p2,p3就分别等于1/3.由于![]() 一定是小于等于1的,log(
一定是小于等于1的,log(![]() )是小于等于0的,那么H一定是大于等于0的。
)是小于等于0的,那么H一定是大于等于0的。
对于鸢尾花的这种各占1/3的分类,它的信息熵就为
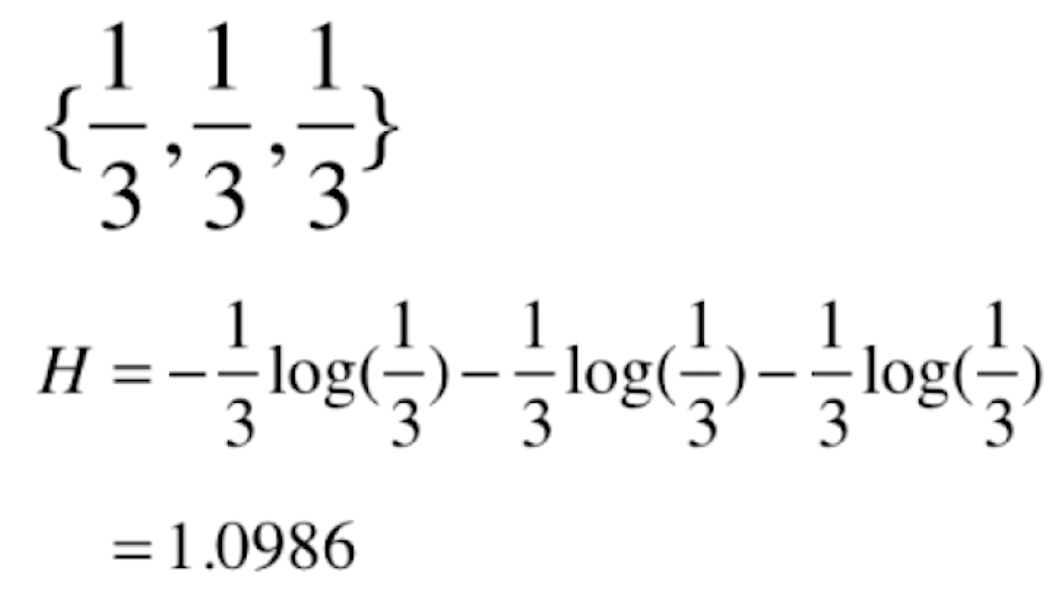
再比如有一种分类,其中一种分类占1/10,第二种占2/10,第三种占7/10,那么它的信息熵就为
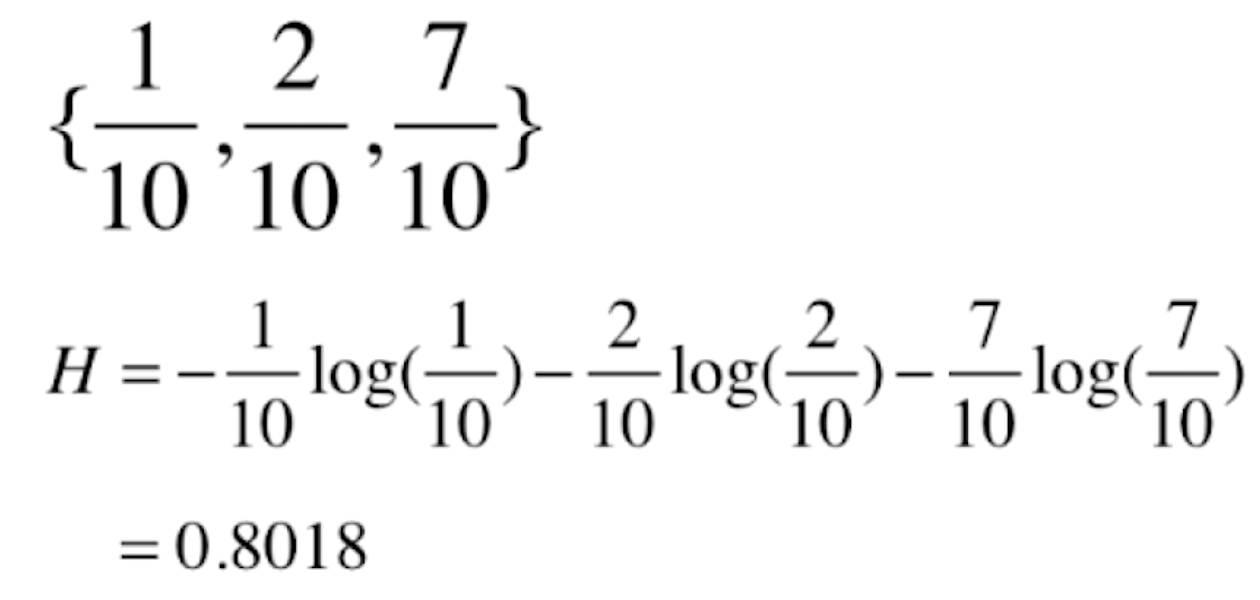
这种分类的信息熵比鸢尾花分类的信息熵要小,意味着这种分类比鸢尾花的分类更确定。这是因为这种分类第三种分类占了70%,所以这种分类是更确定的。而鸢尾花数据每一个类别各占了1/3,所以这个数据整体它的不确定性就越高。我们再来看一组更极端的数据,依然是三类,其中一类占100%。
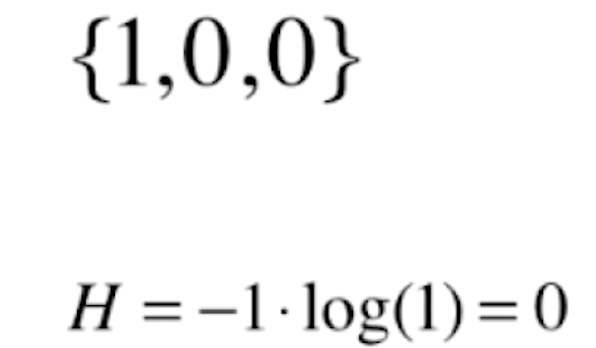
信息熵为0,说明它的不确定性是最低的,即最确定的。在代码上,我们以二分类为例来看一下这个公式的图像是什么样子的。对于二分类来说,该公式可以转化为
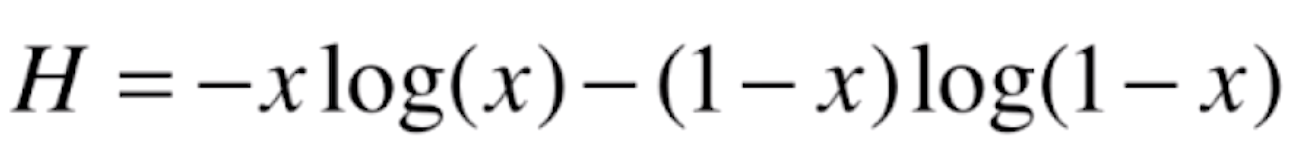
这里x和1-x表示一类和另一类。
import numpy as np import matplotlib.pyplot as plt if __name__ == "__main__": def entropy(p): # 计算二分类信息熵 return - p * np.log(p) - (1 - p) * np.log(1 - p) x = np.linspace(0.01, 0.99, 200) plt.plot(x, entropy(x)) plt.show()
运行结果
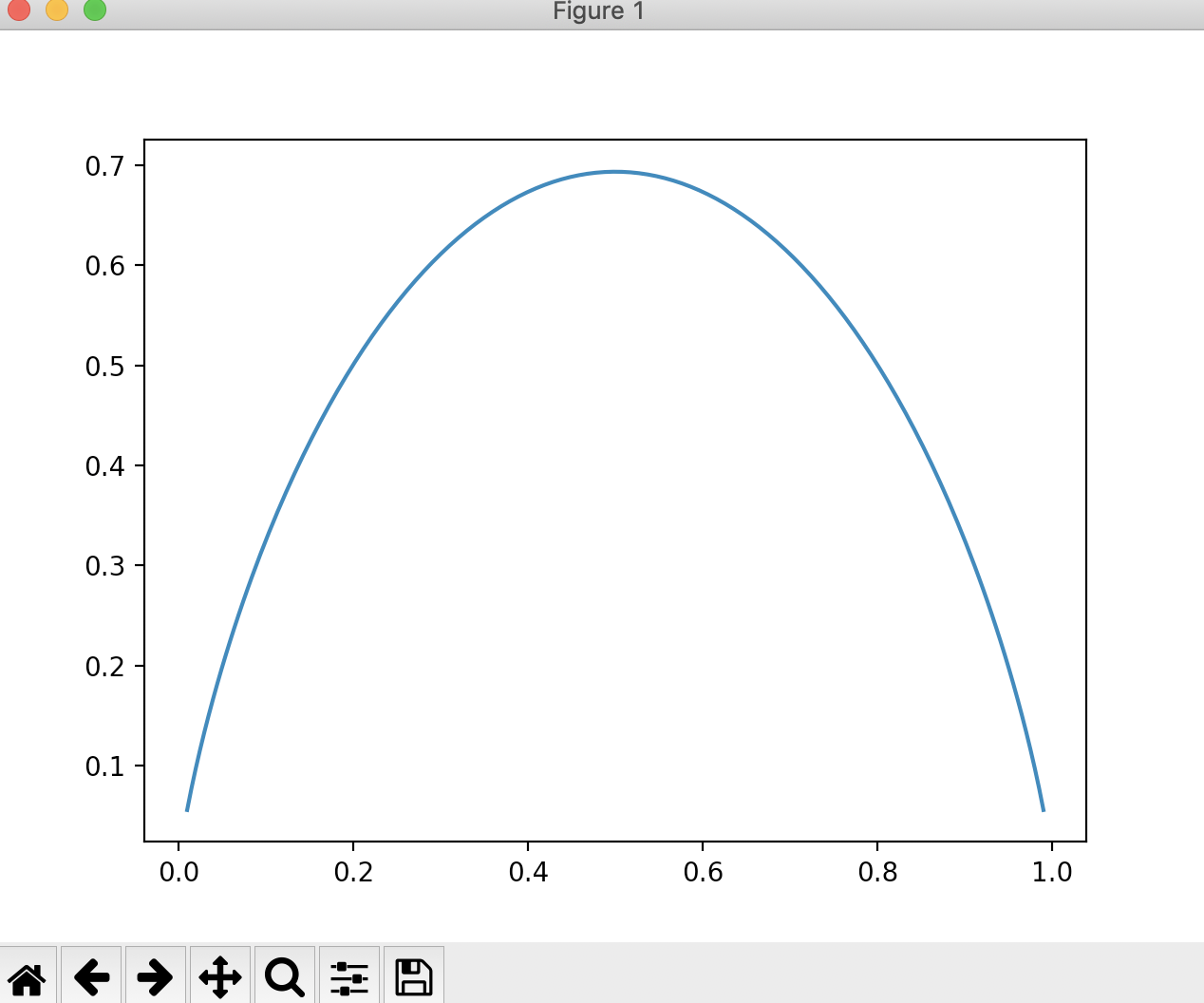
从这个图中,我们可以看出,当x=0.5的时候,我们的信息熵来说,如果我们的数据只有两个类别,当每个类别各占一半的时候,此时整个数据的信息熵就是最大的,此时我们整个数据是最不稳定的,确定性是最低的。在0.5两边,无论x值更小还是更大,整个信息熵都在降低,这里因为无论x变小还是变大,我们的数据都偏向于某一类,整体的确定性变高了,所以相应的信息熵就变低了。
明白了这个概念,那么这两个问题就好说了——节点到底在哪个维度做划分?某个维度的哪个值上做划分?我们要让我们的系统划分后使得信息熵降低,换句话说相应的让我们的系统变的更加确定。

比方说在极端情况下,在A、B、C这三个叶子节点的时候,每一个叶子数据都只属于A、B、C这三类的某一类的话,那么此时我们整个系统的信息熵就达到了0。所以我们就是要找在每一个节点上有一个维度,这个维度上有一个取值,根据这个维度和取值,对我们的数据进行划分,划分以后得到的信息熵是所有其他划分方式得到的信息熵的最小值,我们称这样的一个划分就是当前最好的划分。我们只需要对所有的划分可能性进行一次搜索就可以得到这个最好的划分。我们只需要将这方式递归下去就形成了决策树。
使用信息熵寻找最优划分
模拟使用信息熵进行划分
import numpy as np import matplotlib.pyplot as plt from sklearn import datasets from sklearn.tree import DecisionTreeClassifier from matplotlib.colors import ListedColormap from collections import Counter from math import log if __name__ == "__main__": iris = datasets.load_iris() # 保留鸢尾花数据集的后两个特征 X = iris.data[:, 2:] y = iris.target # plt.scatter(X[y == 0, 0], X[y == 0, 1]) # plt.scatter(X[y == 1, 0], X[y == 1, 1]) # plt.scatter(X[y == 2, 0], X[y == 2, 1]) # plt.show() dt_clf = DecisionTreeClassifier(max_depth=2, criterion='entropy') dt_clf.fit(X, y) def plot_decision_boundary(model, axis): # 绘制不规则决策边界 x0, x1 = np.meshgrid( np.linspace(axis[0], axis[1], int((axis[1] - axis[0]) * 100)).reshape(-1, 1), np.linspace(axis[2], axis[3], int((axis[3] - axis[2]) * 100)).reshape(-1, 1) ) X_new = np.c_[x0.ravel(), x1.ravel()] y_predict = model.predict(X_new) zz = y_predict.reshape(x0.shape) custom_cmap = ListedColormap(['#EF9A9A', '#FFF59D', '#90CAF9']) plt.contourf(x0, x1, zz, linewidth=5, cmap=custom_cmap) # plot_decision_boundary(dt_clf, axis=[0.5, 7.5, 0, 3]) # plt.scatter(X[y == 0, 0], X[y == 0, 1]) # plt.scatter(X[y == 1, 0], X[y == 1, 1]) # plt.scatter(X[y == 2, 0], X[y == 2, 1]) # plt.show() def split(X, y, d, value): ''' 划分 :param X: 特征 :param y: 输出 :param d: 维度 :param value: 阈值 :return: ''' index_a = (X[:, d] <= value) index_b = (X[:, d] > value) return X[index_a], X[index_b], y[index_a], y[index_b] def entropy(y): ''' 计算信息熵 :param y: :return: ''' # 建立类别和数量的字典 counter = Counter(y) res = 0 for num in counter.values(): p = num / len(y) res += - p * log(p) return res def try_split(X, y): ''' 搜索信息熵最小的维度和阈值 :param X: :param y: :return: ''' # 定义一个最好的信息熵,初始值为+∞ best_entropy = float('inf') # 定义在哪个维度,哪个阈值上进行划分,初始值都为-1 best_d, best_v = -1, -1 # 遍历所有的特征 for d in range(X.shape[1]): # 对d维度上的数据进行排序 sorted_index = np.argsort(X[:, d]) # 遍历所有的样本数(不包含第一个样本) for i in range(1, len(X)): # 拿取候选阈值,为d维的数据中每两个数的中间值,且这两个数不能相等 if X[sorted_index[i - 1], d] != X[sorted_index[i], d]: v = (X[sorted_index[i - 1], d] + X[sorted_index[i], d]) / 2 # 对候选维度和阈值尝试划分 X_l, X_r, y_l, y_r = split(X, y, d, v) # 获取对候选维度和候选阈值进行划分后的信息熵 e = entropy(y_l) + entropy(y_r) # 获取信息熵最小的维度和阈值 if e < best_entropy: best_entropy, best_d, best_v = e, d, v return best_entropy, best_d, best_v best_entropy, best_d, best_v = try_split(X, y) print("best_entropy =", best_entropy) print("best_d =", best_d) print("best_v =", best_v)
运行结果
best_entropy = 0.6931471805599453
best_d = 0
best_v = 2.45
根据结果,我们可以看出,我们对原始的数据进行划分,是在第0个维度,阈值在2.45的位置进行划分。划分以后信息熵变成了0.693。对照这个结果,我们看一下在scikit-learn中的划分结果
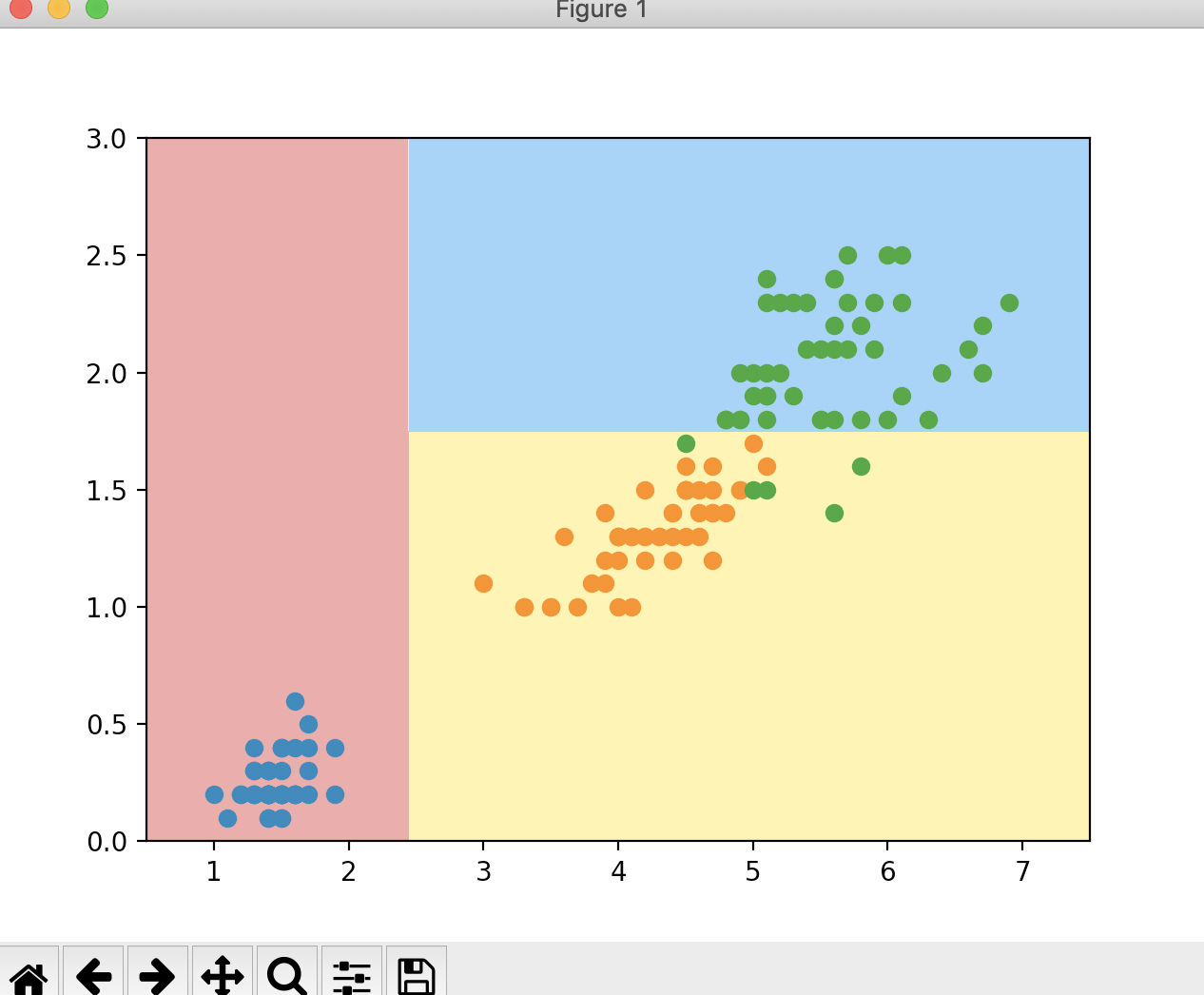
我们可以看到这个决策树第一次划分就是在横轴上,也就是第0个维度,位置大概就是2.45的位置进行的划分。现在我们将划分后的数据进行存储
import numpy as np import matplotlib.pyplot as plt from sklearn import datasets from sklearn.tree import DecisionTreeClassifier from matplotlib.colors import ListedColormap from collections import Counter from math import log if __name__ == "__main__": iris = datasets.load_iris() # 保留鸢尾花数据集的后两个特征 X = iris.data[:, 2:] y = iris.target # plt.scatter(X[y == 0, 0], X[y == 0, 1]) # plt.scatter(X[y == 1, 0], X[y == 1, 1]) # plt.scatter(X[y == 2, 0], X[y == 2, 1]) # plt.show() dt_clf = DecisionTreeClassifier(max_depth=2, criterion='entropy') dt_clf.fit(X, y) def plot_decision_boundary(model, axis): # 绘制不规则决策边界 x0, x1 = np.meshgrid( np.linspace(axis[0], axis[1], int((axis[1] - axis[0]) * 100)).reshape(-1, 1), np.linspace(axis[2], axis[3], int((axis[3] - axis[2]) * 100)).reshape(-1, 1) ) X_new = np.c_[x0.ravel(), x1.ravel()] y_predict = model.predict(X_new) zz = y_predict.reshape(x0.shape) custom_cmap = ListedColormap(['#EF9A9A', '#FFF59D', '#90CAF9']) plt.contourf(x0, x1, zz, linewidth=5, cmap=custom_cmap) # plot_decision_boundary(dt_clf, axis=[0.5, 7.5, 0, 3]) # plt.scatter(X[y == 0, 0], X[y == 0, 1]) # plt.scatter(X[y == 1, 0], X[y == 1, 1]) # plt.scatter(X[y == 2, 0], X[y == 2, 1]) # plt.show() def split(X, y, d, value): ''' 划分 :param X: 特征 :param y: 输出 :param d: 维度 :param value: 阈值 :return: ''' index_a = (X[:, d] <= value) index_b = (X[:, d] > value) return X[index_a], X[index_b], y[index_a], y[index_b] def entropy(y): ''' 计算信息熵 :param y: :return: ''' # 建立类别和数量的字典 counter = Counter(y) res = 0 for num in counter.values(): p = num / len(y) res += - p * log(p) return res def try_split(X, y): ''' 搜索信息熵最小的维度和阈值 :param X: :param y: :return: ''' # 定义一个最好的信息熵,初始值为+∞ best_entropy = float('inf') # 定义在哪个维度,哪个阈值上进行划分,初始值都为-1 best_d, best_v = -1, -1 # 遍历所有的特征 for d in range(X.shape[1]): # 对d维度上的数据进行排序 sorted_index = np.argsort(X[:, d]) # 遍历所有的样本数(不包含第一个样本) for i in range(1, len(X)): # 拿取候选阈值,为d维的数据中每两个数的中间值,且这两个数不能相等 if X[sorted_index[i - 1], d] != X[sorted_index[i], d]: v = (X[sorted_index[i - 1], d] + X[sorted_index[i], d]) / 2 # 对候选维度和阈值尝试划分 X_l, X_r, y_l, y_r = split(X, y, d, v) # 获取对候选维度和候选阈值进行划分后的信息熵 e = entropy(y_l) + entropy(y_r) # 获取信息熵最小的维度和阈值 if e < best_entropy: best_entropy, best_d, best_v = e, d, v return best_entropy, best_d, best_v best_entropy, best_d, best_v = try_split(X, y) print("best_entropy =", best_entropy) print("best_d =", best_d) print("best_v =", best_v) # 将第一次划分后的数据进行存储 X1_l, X1_r, y1_l, y1_r = split(X, y, best_d, best_v) # 打印划分后左子树的信息熵 print(entropy(y1_l)) # 打印划分后的右子树的信息熵 print(entropy(y1_r))
运行结果
best_entropy = 0.6931471805599453
best_d = 0
best_v = 2.45
0.0
0.6931471805599453
通过跟图形对比,我们知道第一次划分,我们把所有属于第一类的数据全部划分了进去,它没有不确定性,所以第一次划分的第一类的信息熵为0;而除第一类外的信息熵为0.693
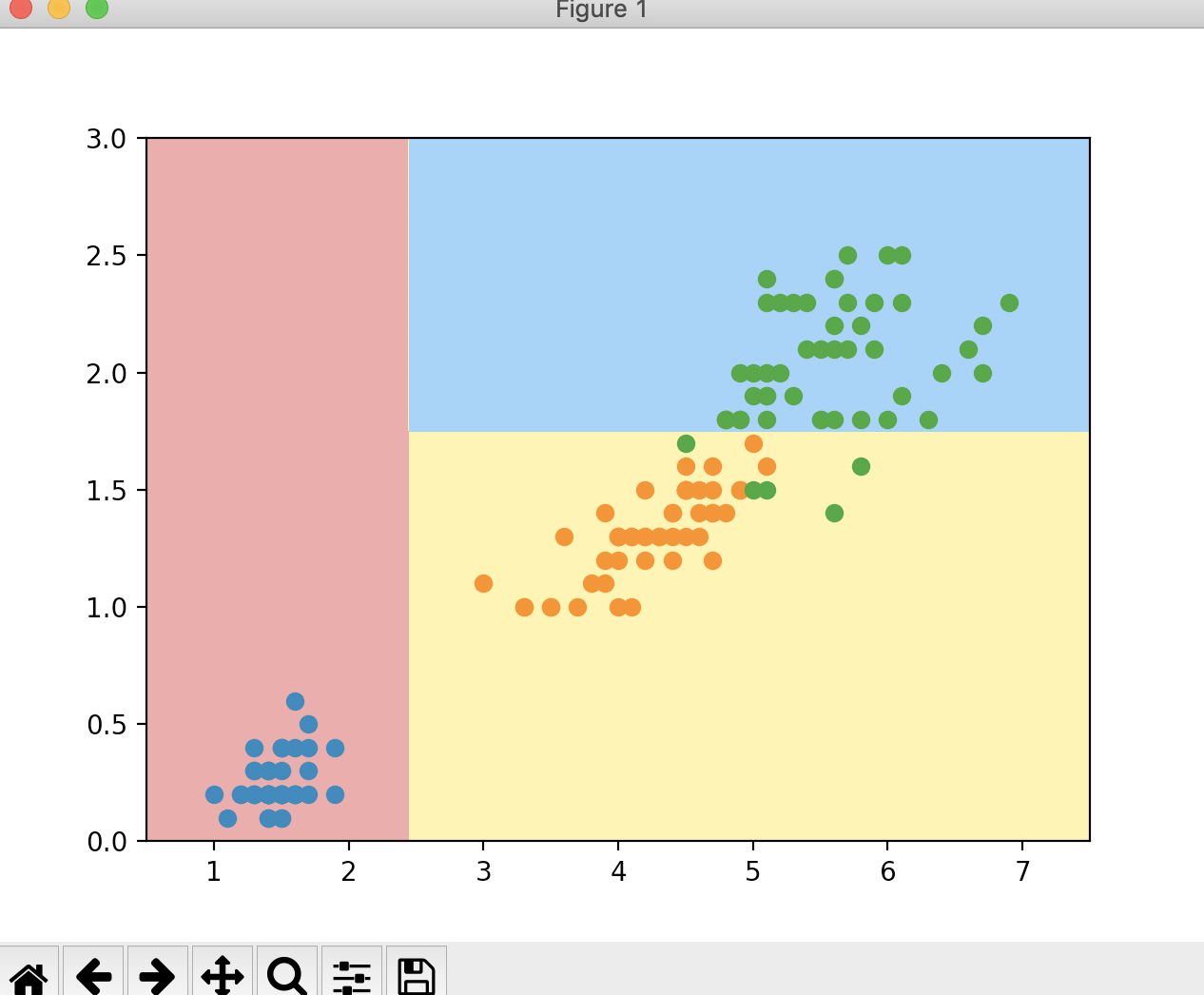
对于第一类我们已经不需要划分了,它的信息熵为0。而对于第一类之外的数据的信息熵为0.693,我们可以继续对其进行划分。
import numpy as np import matplotlib.pyplot as plt from sklearn import datasets from sklearn.tree import DecisionTreeClassifier from matplotlib.colors import ListedColormap from collections import Counter from math import log if __name__ == "__main__": iris = datasets.load_iris() # 保留鸢尾花数据集的后两个特征 X = iris.data[:, 2:] y = iris.target # plt.scatter(X[y == 0, 0], X[y == 0, 1]) # plt.scatter(X[y == 1, 0], X[y == 1, 1]) # plt.scatter(X[y == 2, 0], X[y == 2, 1]) # plt.show() dt_clf = DecisionTreeClassifier(max_depth=2, criterion='entropy') dt_clf.fit(X, y) def plot_decision_boundary(model, axis): # 绘制不规则决策边界 x0, x1 = np.meshgrid( np.linspace(axis[0], axis[1], int((axis[1] - axis[0]) * 100)).reshape(-1, 1), np.linspace(axis[2], axis[3], int((axis[3] - axis[2]) * 100)).reshape(-1, 1) ) X_new = np.c_[x0.ravel(), x1.ravel()] y_predict = model.predict(X_new) zz = y_predict.reshape(x0.shape) custom_cmap = ListedColormap(['#EF9A9A', '#FFF59D', '#90CAF9']) plt.contourf(x0, x1, zz, linewidth=5, cmap=custom_cmap) # plot_decision_boundary(dt_clf, axis=[0.5, 7.5, 0, 3]) # plt.scatter(X[y == 0, 0], X[y == 0, 1]) # plt.scatter(X[y == 1, 0], X[y == 1, 1]) # plt.scatter(X[y == 2, 0], X[y == 2, 1]) # plt.show() def split(X, y, d, value): ''' 划分 :param X: 特征 :param y: 输出 :param d: 维度 :param value: 阈值 :return: ''' index_a = (X[:, d] <= value) index_b = (X[:, d] > value) return X[index_a], X[index_b], y[index_a], y[index_b] def entropy(y): ''' 计算信息熵 :param y: :return: ''' # 建立类别和数量的字典 counter = Counter(y) res = 0 for num in counter.values(): p = num / len(y) res += - p * log(p) return res def try_split(X, y): ''' 搜索信息熵最小的维度和阈值 :param X: :param y: :return: ''' # 定义一个最好的信息熵,初始值为+∞ best_entropy = float('inf') # 定义在哪个维度,哪个阈值上进行划分,初始值都为-1 best_d, best_v = -1, -1 # 遍历所有的特征 for d in range(X.shape[1]): # 对d维度上的数据进行排序 sorted_index = np.argsort(X[:, d]) # 遍历所有的样本数(不包含第一个样本) for i in range(1, len(X)): # 拿取候选阈值,为d维的数据中每两个数的中间值,且这两个数不能相等 if X[sorted_index[i - 1], d] != X[sorted_index[i], d]: v = (X[sorted_index[i - 1], d] + X[sorted_index[i], d]) / 2 # 对候选维度和阈值尝试划分 X_l, X_r, y_l, y_r = split(X, y, d, v) # 获取对候选维度和候选阈值进行划分后的信息熵 e = entropy(y_l) + entropy(y_r) # 获取信息熵最小的维度和阈值 if e < best_entropy: best_entropy, best_d, best_v = e, d, v return best_entropy, best_d, best_v best_entropy, best_d, best_v = try_split(X, y) print("best_entropy =", best_entropy) print("best_d =", best_d) print("best_v =", best_v) # 将第一次划分后的数据进行存储 X1_l, X1_r, y1_l, y1_r = split(X, y, best_d, best_v) # 打印划分后左子树的信息熵 print(entropy(y1_l)) # 打印划分后的右子树的信息熵 print(entropy(y1_r)) # 对右子树继续划分 best_entropy2, best_d2, best_v2 = try_split(X1_r, y1_r) print("best_entropy =", best_entropy2) print("best_d =", best_d2) print("best_v =", best_v2) X2_l, X2_r, y2_l, y2_r = split(X1_r, y1_r, best_d2, best_v2) # 打印第二次划分后左子树的信息熵 print(entropy(y2_l)) # 打印第二次划分后的右子树的信息熵 print(entropy(y2_r))
运行结果
best_entropy = 0.6931471805599453
best_d = 0
best_v = 2.45
0.0
0.6931471805599453
best_entropy = 0.4132278899361904
best_d = 1
best_v = 1.75
0.30849545083110386
0.10473243910508653
对于第二次划分,我们可以看信息熵降到最低是0.413,是在第1个维度,阈值在1.75的位置进行划分。对比图形,我们可以看到第二次划分是在纵轴上,也就是第1个维度,位置大概就是在1.75的地方进行划分的。并且划分后,两边的信息熵都没降为0,我们可以向更深的方向继续划分。
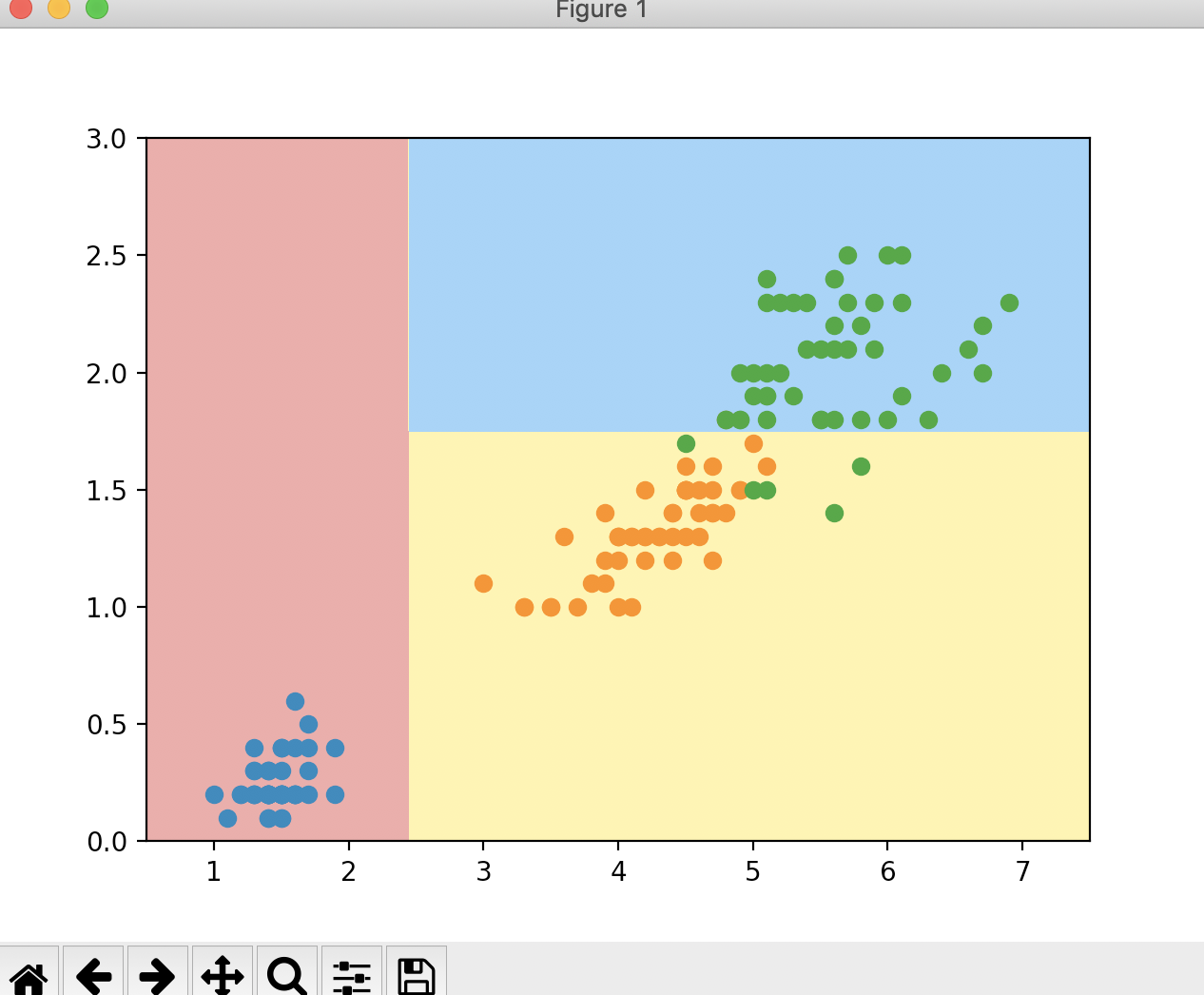
我们之前在scikit-learn中,max_depth=2,也就是深度值设为了2,也是划分到此为止。当然我们已经知道了使用信息熵来构建决策树,可以使用二叉树的方式来建立这个决策树,并打印这颗二叉树,关于建立的方式可以参考数据结构整理 中关于二分搜索树的内容来进行建立。
基尼系数
除了信息熵可以对决策树的指标进行划分,还有另外一个指标可以对决策树进行划分,这个指标就是基尼系数。基尼系数的公式如下
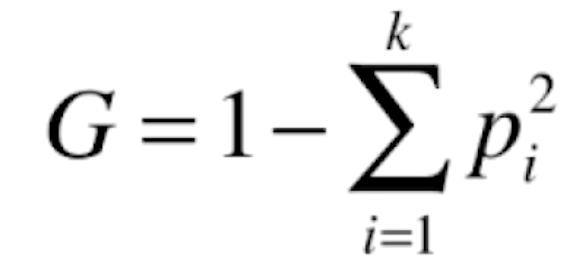
这个式子和信息熵对应的式子是有同样的性质的,跟信息熵一样,我们先使用几个例子来看一下基尼系数。
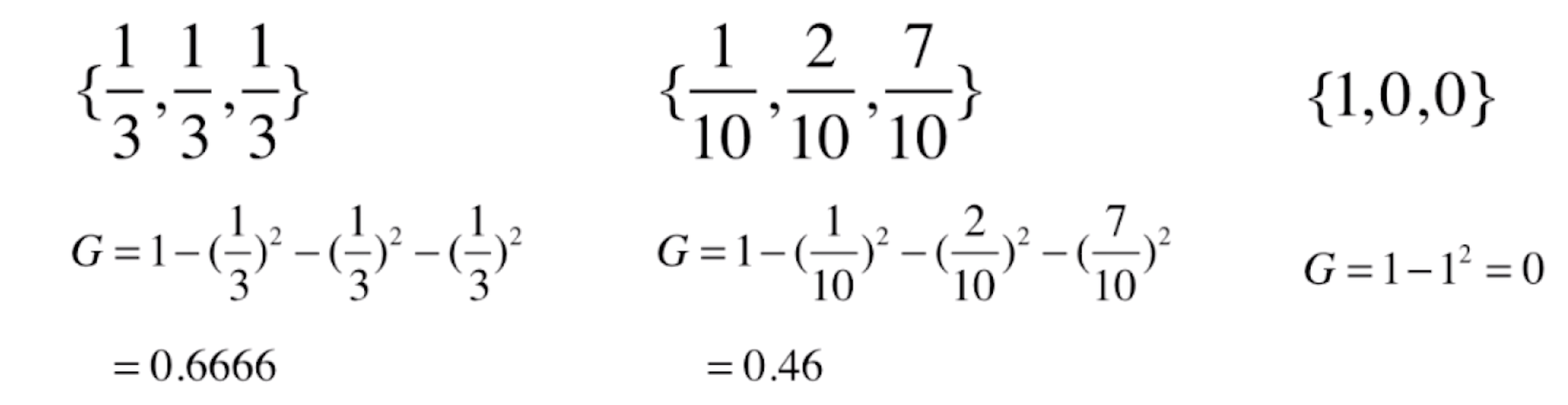
通过这三个例子,我们可以看出,基尼系数和信息熵一样可以用来作为数据不确定性的一个度量。我们同样来看一下基尼系数的曲线是什么样子的。对于二分类来说,基尼系数的式子就可以化为
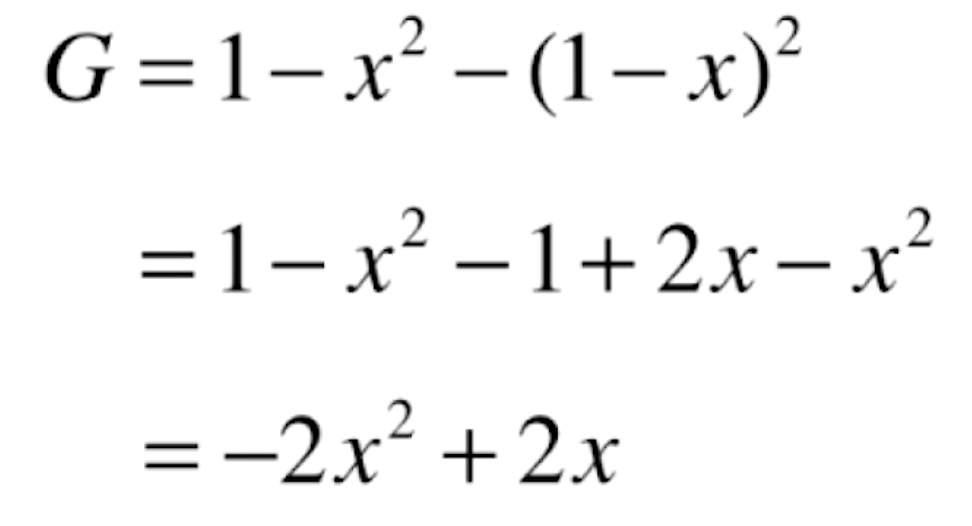
import numpy as np import matplotlib.pyplot as plt if __name__ == "__main__": def gini(p): # 计算二分类基尼系数 return - 2 * p**2 + 2 * p x = np.linspace(0, 1, 200) plt.plot(x, gini(x)) plt.show()
运行结果
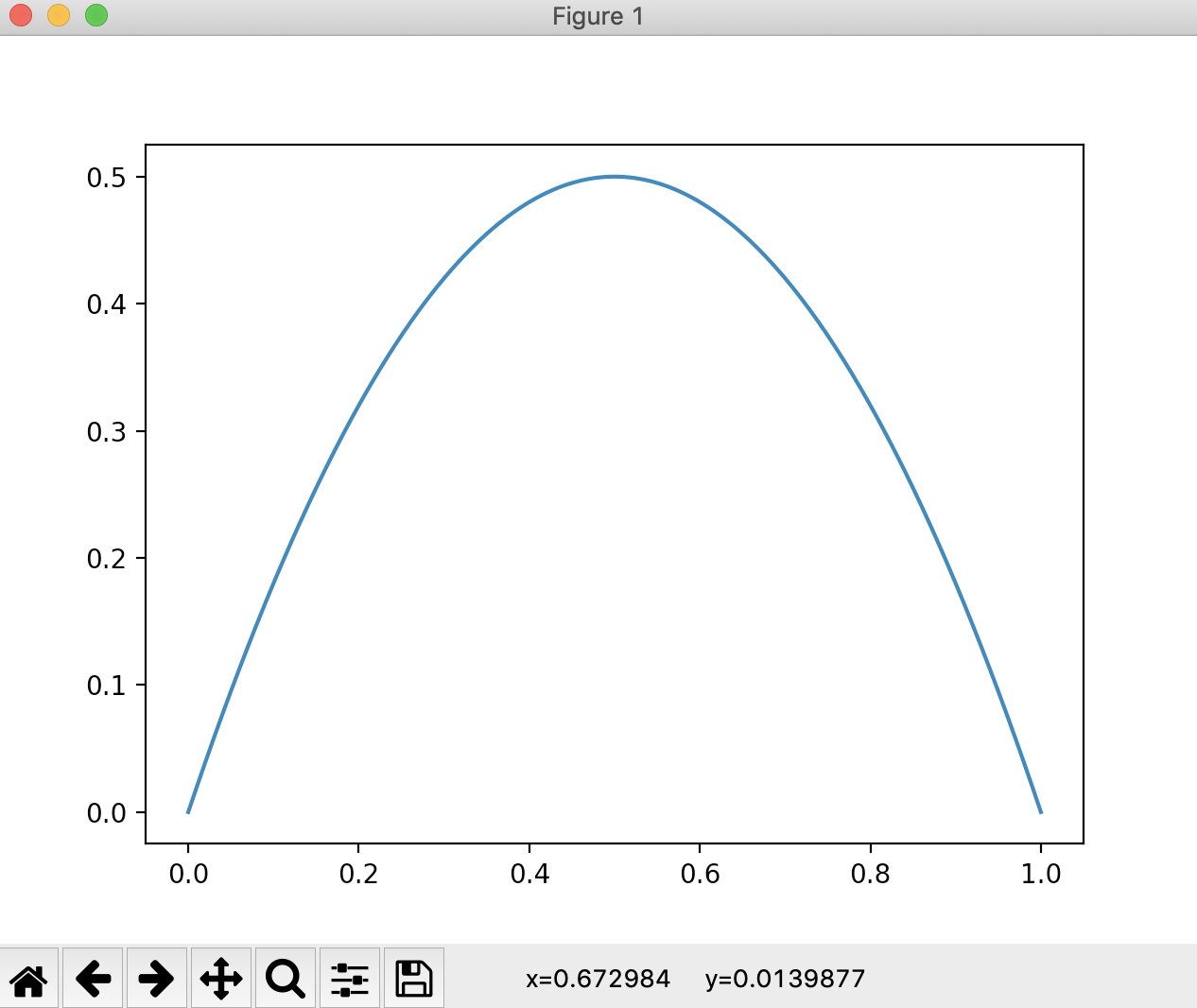
现在我们模拟一下使用基尼系数进行划分,看看结果是怎样的。我们依然先使用scikit-learn来绘制一下使用基尼系数的决策树的决策边界。
import numpy as np import matplotlib.pyplot as plt from sklearn import datasets from sklearn.tree import DecisionTreeClassifier from matplotlib.colors import ListedColormap if __name__ == "__main__": iris = datasets.load_iris() # 保留鸢尾花数据集的后两个特征 X = iris.data[:, 2:] y = iris.target dt_clf = DecisionTreeClassifier(max_depth=2, criterion='gini', splitter='best') dt_clf.fit(X, y) def plot_decision_boundary(model, axis): # 绘制不规则决策边界 x0, x1 = np.meshgrid( np.linspace(axis[0], axis[1], int((axis[1] - axis[0]) * 100)).reshape(-1, 1), np.linspace(axis[2], axis[3], int((axis[3] - axis[2]) * 100)).reshape(-1, 1) ) X_new = np.c_[x0.ravel(), x1.ravel()] y_predict = model.predict(X_new) zz = y_predict.reshape(x0.shape) custom_cmap = ListedColormap(['#EF9A9A', '#FFF59D', '#90CAF9']) plt.contourf(x0, x1, zz, linewidth=5, cmap=custom_cmap) plot_decision_boundary(dt_clf, axis=[0.5, 7.5, 0, 3]) plt.scatter(X[y == 0, 0], X[y == 0, 1]) plt.scatter(X[y == 1, 0], X[y == 1, 1]) plt.scatter(X[y == 2, 0], X[y == 2, 1]) plt.show()
运行结果
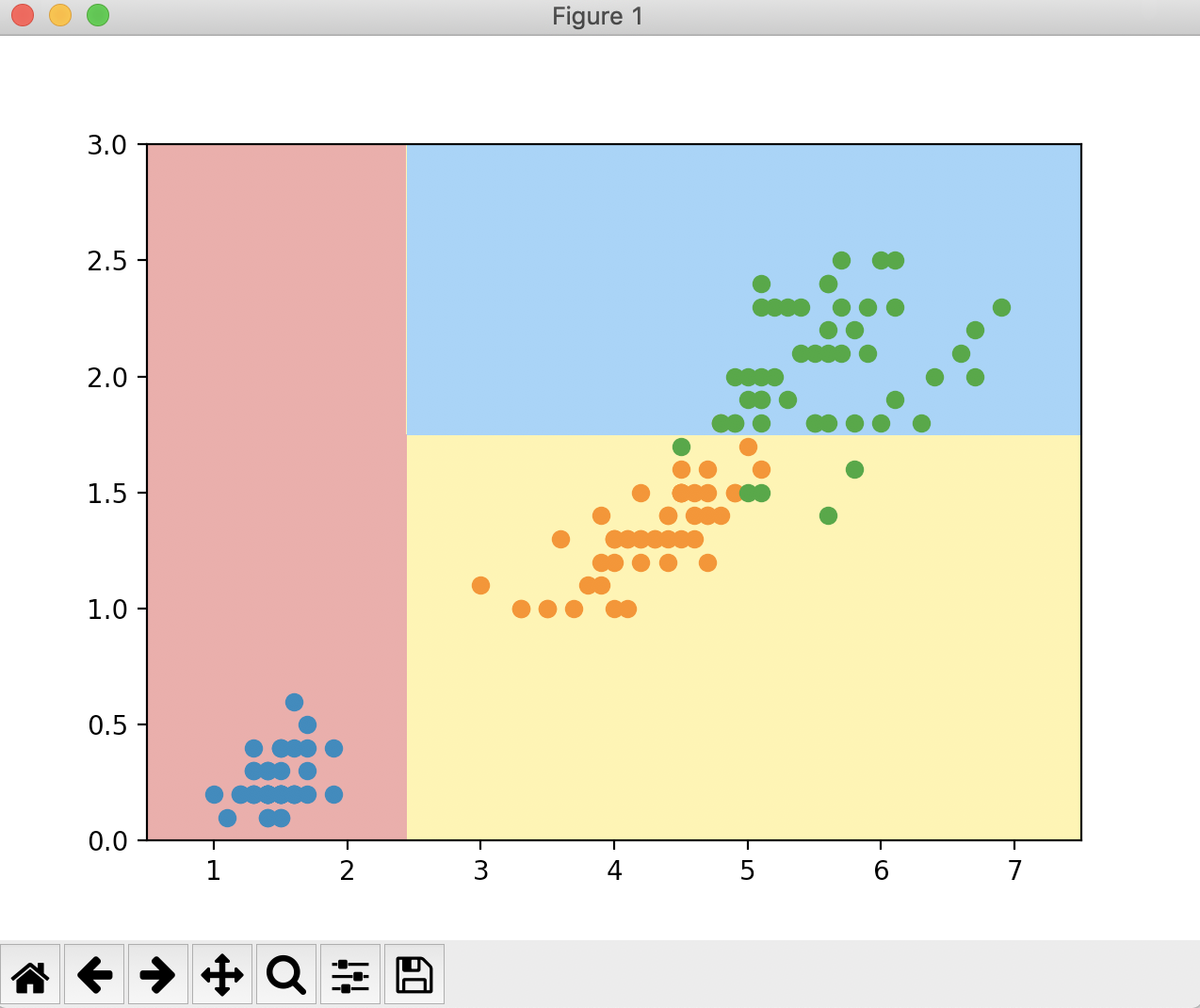
现在我们再使用基尼系数来进行最优划分
import numpy as np import matplotlib.pyplot as plt from sklearn import datasets from sklearn.tree import DecisionTreeClassifier from matplotlib.colors import ListedColormap from collections import Counter if __name__ == "__main__": iris = datasets.load_iris() # 保留鸢尾花数据集的后两个特征 X = iris.data[:, 2:] y = iris.target dt_clf = DecisionTreeClassifier(max_depth=2, criterion='gini', splitter='best') dt_clf.fit(X, y) def plot_decision_boundary(model, axis): # 绘制不规则决策边界 x0, x1 = np.meshgrid( np.linspace(axis[0], axis[1], int((axis[1] - axis[0]) * 100)).reshape(-1, 1), np.linspace(axis[2], axis[3], int((axis[3] - axis[2]) * 100)).reshape(-1, 1) ) X_new = np.c_[x0.ravel(), x1.ravel()] y_predict = model.predict(X_new) zz = y_predict.reshape(x0.shape) custom_cmap = ListedColormap(['#EF9A9A', '#FFF59D', '#90CAF9']) plt.contourf(x0, x1, zz, linewidth=5, cmap=custom_cmap) # plot_decision_boundary(dt_clf, axis=[0.5, 7.5, 0, 3]) # plt.scatter(X[y == 0, 0], X[y == 0, 1]) # plt.scatter(X[y == 1, 0], X[y == 1, 1]) # plt.scatter(X[y == 2, 0], X[y == 2, 1]) # plt.show() def split(X, y, d, value): ''' 划分 :param X: 特征 :param y: 输出 :param d: 维度 :param value: 阈值 :return: ''' index_a = (X[:, d] <= value) index_b = (X[:, d] > value) return X[index_a], X[index_b], y[index_a], y[index_b] def gini(y): ''' 计算基尼系数 :param y: :return: ''' # 建立类别和数量的字典 counter = Counter(y) res = 1 for num in counter.values(): p = num / len(y) res -= p**2 return res def try_split(X, y): ''' 搜索信息熵最小的维度和阈值 :param X: :param y: :return: ''' # 定义一个最好的基尼系数,初始值为+∞ best_g = float('inf') # 定义在哪个维度,哪个阈值上进行划分,初始值都为-1 best_d, best_v = -1, -1 # 遍历所有的特征 for d in range(X.shape[1]): # 对d维度上的数据进行排序 sorted_index = np.argsort(X[:, d]) # 遍历所有的样本数(不包含第一个样本) for i in range(1, len(X)): # 拿取候选阈值,为d维的数据中每两个数的中间值,且这两个数不能相等 if X[sorted_index[i - 1], d] != X[sorted_index[i], d]: v = (X[sorted_index[i - 1], d] + X[sorted_index[i], d]) / 2 # 对候选维度和阈值尝试划分 X_l, X_r, y_l, y_r = split(X, y, d, v) # 获取对候选维度和候选阈值进行划分后的信息熵 e = gini(y_l) + gini(y_r) # 获取信息熵最小的维度和阈值 if e < best_g: best_g, best_d, best_v = e, d, v return best_g, best_d, best_v best_g, best_d, best_v = try_split(X, y) print("best_g =", best_g) print("best_d =", best_d) print("best_v =", best_v) # 将第一次划分后的数据进行存储 X1_l, X1_r, y1_l, y1_r = split(X, y, best_d, best_v) # 打印划分后左子树的基尼系数 print(gini(y1_l)) # 打印划分后的右子树的基尼系数 print(gini(y1_r)) # 对右子树继续划分 best_g2, best_d2, best_v2 = try_split(X1_r, y1_r) print("best_g =", best_g2) print("best_d =", best_d2) print("best_v =", best_v2) X2_l, X2_r, y2_l, y2_r = split(X1_r, y1_r, best_d2, best_v2) # 打印第二次划分后左子树的基尼系数 print(gini(y2_l)) # 打印第二次划分后的右子树的基尼系数 print(gini(y2_r))
运行结果
best_g = 0.5
best_d = 0
best_v = 2.45
0.0
0.5
best_g = 0.2105714900645938
best_d = 1
best_v = 1.75
0.1680384087791495
0.04253308128544431
这里通过第一次划分,第一类的基尼系数为0,达到了一个最小值。除第一类的其他类的基尼系数为0.5。第一次划分的维度为0,划分的阈值为2.45。第二次划分的最小基尼系数为0.21,第二次划分的维度为1,划分的阈值为1.75。对于剩下的两个节点,它们的基尼系数依然没有到0,我们可以对这两个节点继续向下划分。
信息熵 vs 基尼系数
通过它们两个的式子,我们可以看出来,信息熵的计算比基尼系数稍慢。在sikit-learn中的决策树默认为基尼系数。在大多数时候,这二者没有特别的效果优劣。对于决策树有其更重要的参数,对比不必纠结这两个参数。
|








- 上一条: 如何借助 JuiceFS 为 AI 模型训练提速 7 倍 2021-09-18
- 下一条: 容器神话 Docker 是如何一分为二的 2021-09-22
- 机器学习算法整理(二) 2021-08-30
- 机器学习算法整理(三) 2021-09-13
- 机器人自主学习新进展,百度飞桨发布四足机器人控制强化学习新算法 2021-10-08
- Tensorflow深度学习算法整理(二) 2021-10-15
- 0基础都能看懂的算法图解 2021-07-19


