字节跳动算力监控系统的落地与实践
背景
随着字节跳动业务的快速发展,数据中心服务器规模增长迅速,以满足日益增长的算力需求。当规模到一定程度时,就需要平衡好机器成本与效率、资源之间的关系,有针对性地优化数据中心性能,以降低计算成本。
参考行业内的实践,从 2019 年起,STE 团队开始建设算力监控系统,希望从数据中心整体视角,建立起完整的数据中心资源使用分析体系,从而最大化地支持软硬件协同设计与优化。经过四年的迭代,当前已拥有成熟的产品形态和稳定的用户群体,为各业务性能分析优化工作提供了有力支撑。
本文将与大家分享字节算力监控系统方案的整体设计、工程实践落地经验,帮助大家理解如何对数据中心进行科学、准确地性能分析和画像,快速进行算力性能优化。
整体设计
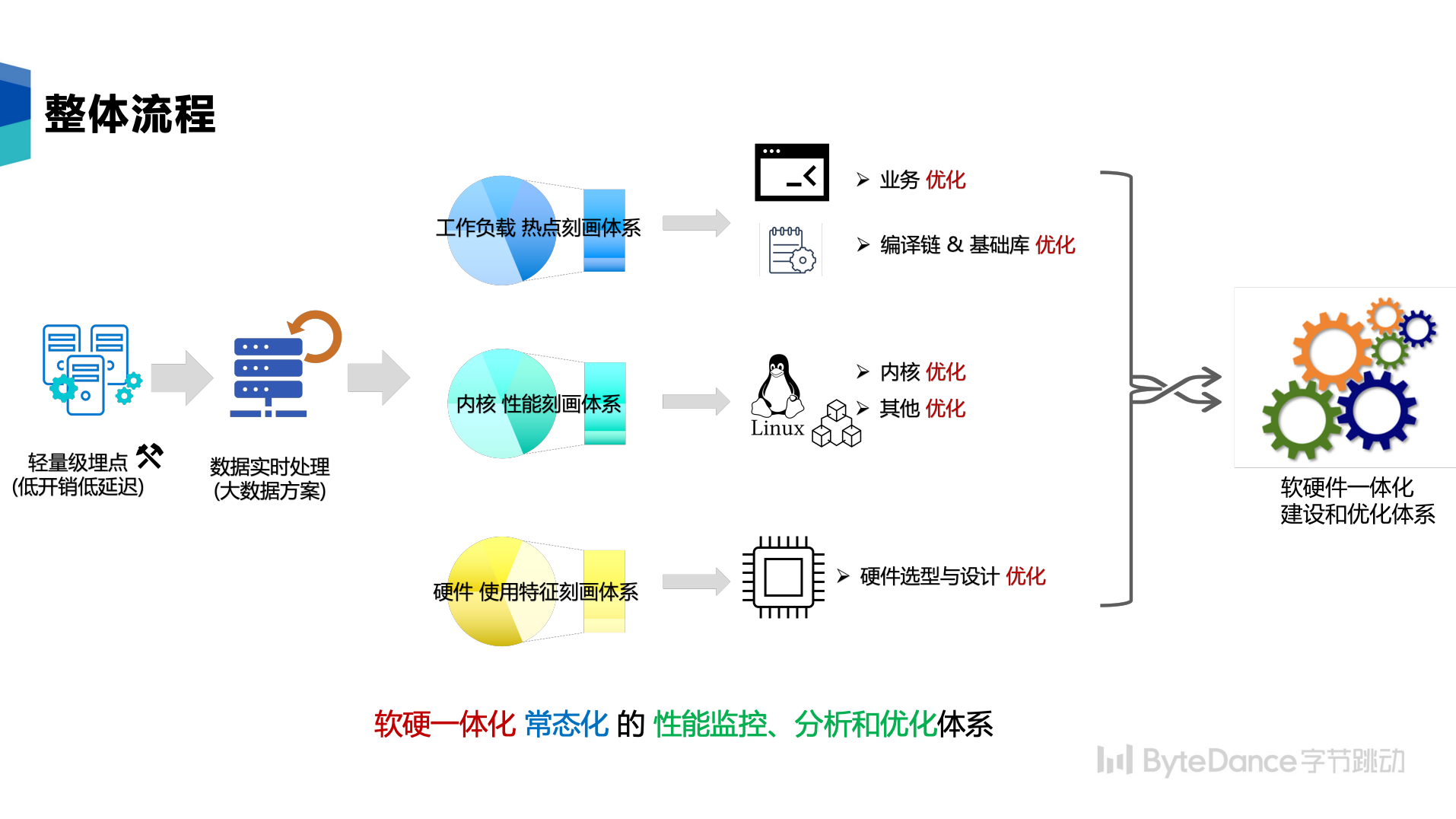
在设计之初,需要了解算力主要消耗在哪些系统组件、基础库、具体的函数与指令,因此我们需要构建一套数据中心资源使用分析体系,帮助我们了解各个运行在数据中心的不同业务,并对业务的工作负载进行了解和剖析。在构建资源使用分析体系时,需要重点关注四个功能关键点:
- 数据中心 ( Data Center / DC)视角:常见的运维工具一般都是单机视角,对单机、进程、实例进行性能分析,支持有限度的多机性能分析。单机视角在排查具体的机器问题时非常有用,但针对整个数据中心仅有单机视角是不够的,否则就会只见树木不见森林。
- 重点侧重Profiling: Profiling 能力,即对 DC/业务整体进行工作负载特征、资源使用特征的刻画。除了持续增强系统 Tracing 能力外,还需要重点发展数据可视化、数据分析,需要充分理解业务和增强领域知识。
- 全面的分析服务:性能分析服务。在科学成熟的性能分析方法论指导下,开展标准化和定制化的性能分析服务。特别是要结合字节业务特点,加入业务线、微服务、集群等业务维度,细分应用和业务场景。除此之外,性能分析可以主动推送给服务,创造更大价值。
- 常态运行: 支持按计划常态开启(Continuous Profiling)。所采集的数据接入分析服务,源源不断产生分析报告。支持对性能问题的长期大跨度追踪,发挥长期作用。
整个体系的构建,包含主要包含数据采集、数据处理、数据分析三个环节,各个环节需要注意的是:
数据采集环节:
- Agent 需要轻量级, 需要覆盖全量机器,因此需要严格控制采集的开销。如果可能,先在内核中完成聚合再吐到用户空间。
- Agent 需要支持常态采集。支持每天定时采集,同时触发时间应尽可能的分散以避免峰值的影响。
- Agent 需要采集各种数据维度,从而支持单机、PSM 服务、机房、语言、基础库、CPU 微架构等各个角度的分析。
数据处理环节:
- 数据处理需要实现丰富的算子功能:为了降低采集端的压力,将数据关联和处理的动作,统一放在数据处理端实现。
- 数据处理需要支持大规模数据量:针对全量数据中心百万量级的机器,需要支持高并发。
数据分析环节: 通过对系统的数据分析,我们希望回答以下问题:
- 运行在数据中心的业务都是什么业务?如何刻画业务的工作负载特征?如何评估当前的工作负载是否充分利用了系统算力?
- 各个业务的工作负载都有哪些特征?根据这些特征,能够帮助业务的代码开发和运维进行针对性的优化指导?
- 有没有一些共同的特征?我们能否根据这些特征,从而针对性的进行公司级的系统优化?以数据中心为视角,进行业务工作负载优化,是否能带来新的思路?
工程实践
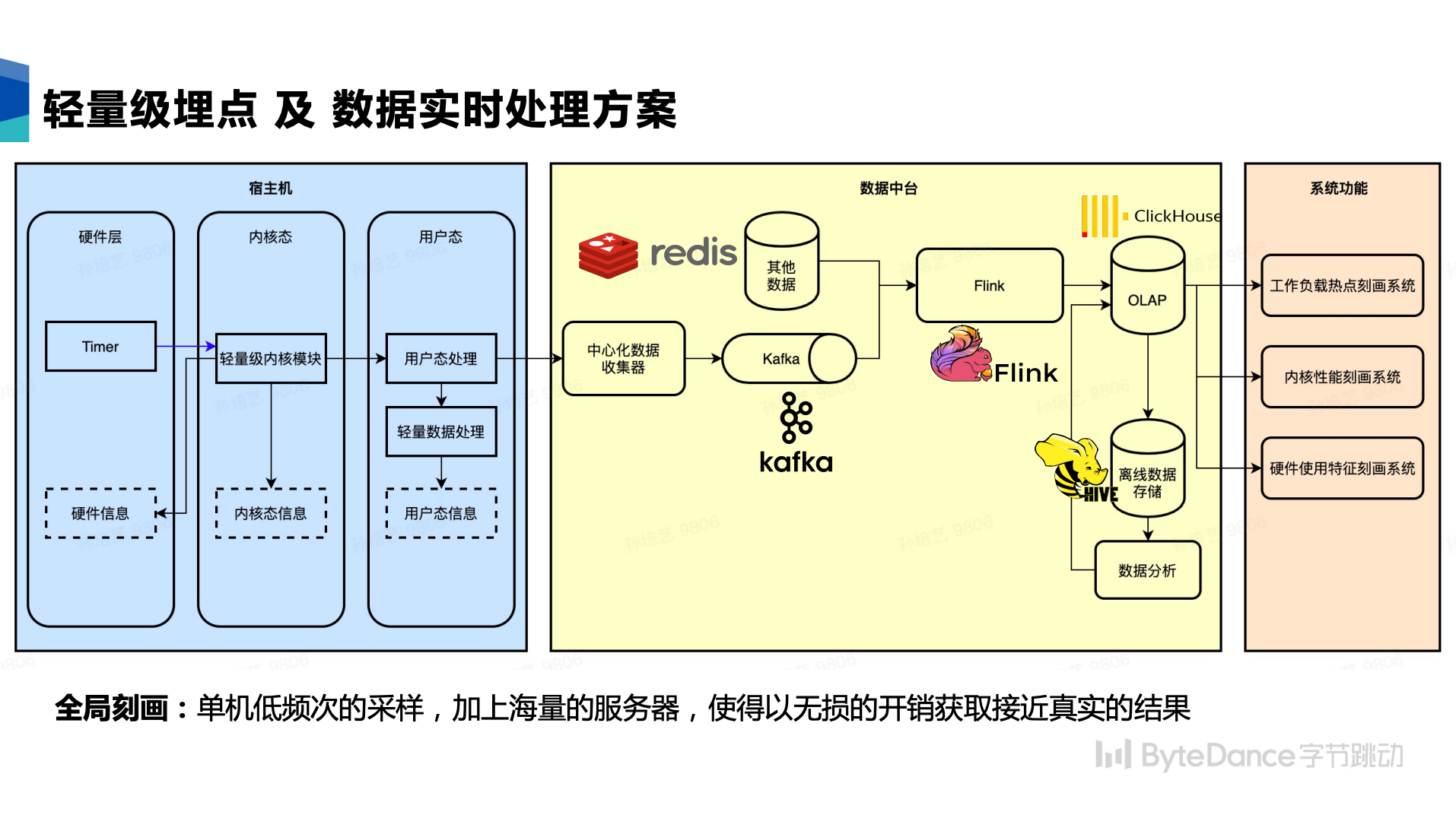
数据采集:轻量级埋点体系
当我们的目标是建设一套支持百万级数据中心规模的监控系统时,低成本低开销是我们需要重点解决的问题。
常见的监控、探针埋点、能力探测工具多是针对单机进行的设计,并不适合数据中心常态化采集和全量部署。字节业务类型复杂、服务器数量庞大。微小的设计缺陷都有可能造成 SRE 在线解决问题的巨大压力,甚至可能引发重大事故。业务侧期望常态化工具对业务无入侵,而业界这方面公开的资料较少。STE团队基于开源组件进行了一系列自研优化,实现了安全的轻量级埋点体系实践。项目预期中的埋点采集,经过了严格的论证、设计review、代码review、上线业务指标对比,最终确认对业务零干扰。埋点设计是建立在对硬件特性的掌握、内核及基础库的工作机制和原理的理解、业务对硬件使用模式的分析基础上整体考虑得出的。
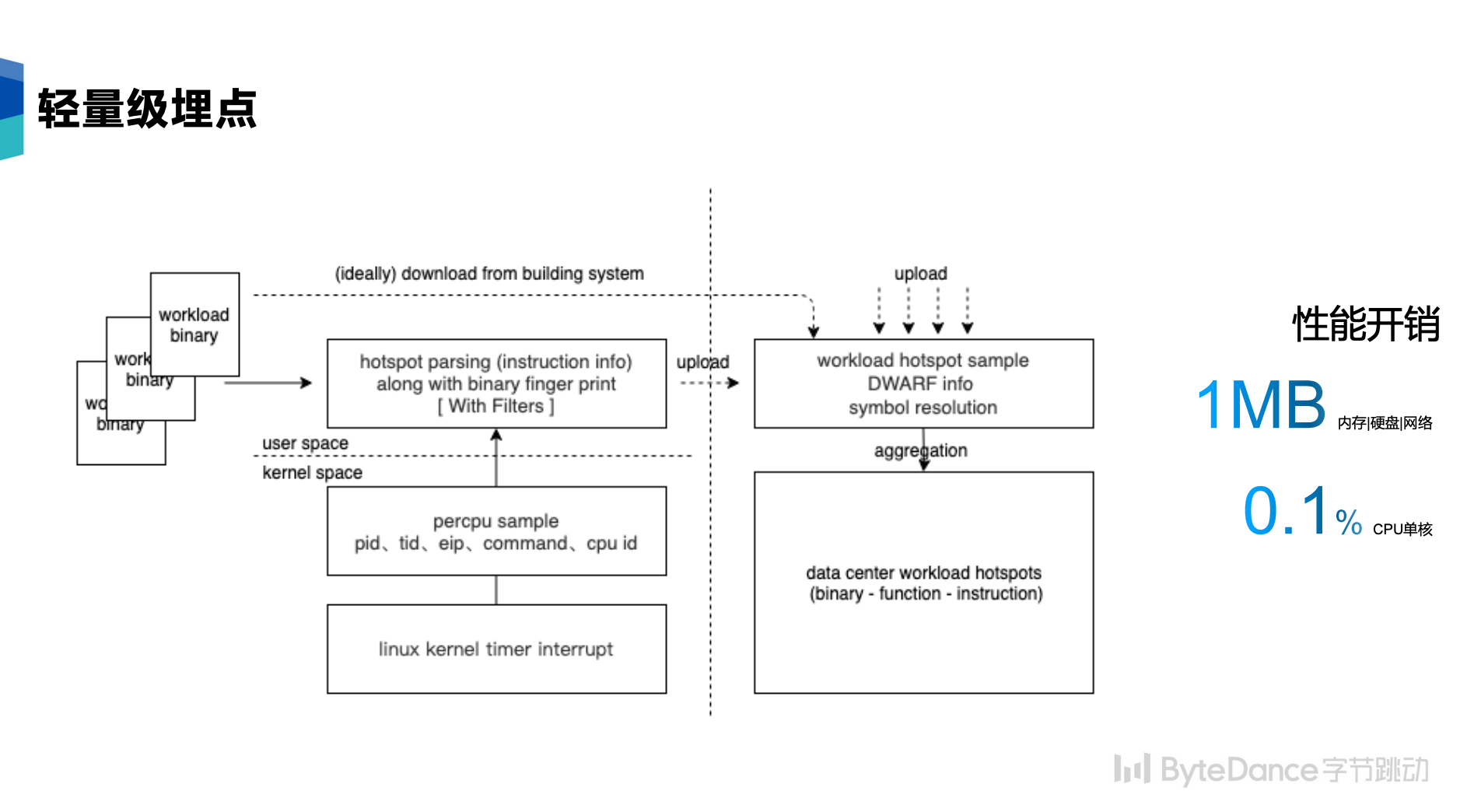
我们采用常态化采样的方式来采集,也就是采样每个时刻占用 CPU 的进程。
- 内核定时器:实现轻量化的内核模块,使用 percpu 的硬件定时器每 10s (时间可配,通常 小于 10Hz 采样会是比较安全的,当前使用 0.1 Hz) 向 CPU 发送一个硬件 Timer 中断。内核模块响应硬件中断记录当前 CPU 正在运行的进程 PID、TID、EIP 寄存器数值、CPU ID,存入 64 字节的内核 buffer,通过 /sys/kernel/debug 导出到用户态。Linux 系统自带的 perf 工具采样开销远高于这个方案。
- 用户态信息收集和上报:用户态会定时的采集由内核事件负责定时上报。结合 PID 对应到具体的 workload binary。为了节约带宽,我们对 workload 数量进行限制,重点筛选数据中心的热点进行分析(基于 top 命令识别数据中心层面的使用CPU较高的进程),过滤掉非热点的不关心的 workload。如果一些业务有特殊需求,如因业务密级问题不想被采集,我们支持“黑名单”机制,从而在根源上杜绝数据泄露的问题。
- 在采集端对 workload 进行简单解析,并且上报到远端的中心处理服务器,之后繁重的解析和处理任务,由远端的服务器继续处理。
性能评估:
- 方案使用 0.1Hz 的采集频率(每逻辑 CPU 10s 一个样本),且中断处理轻量于内核目前任何一个系统调用和中断实现,仅记录最小化的进程信息,每样本数量量 64 字节。
- 用户采集工具行为简单,仅为单线程,开销可控。以 5min 为周期,CPU 使用单核心的时间远小于 0.1%,内存使用小于 1MB,磁盘读写与网络传输总量大约 1MB。其他数据处理完全在服务器远端完成。
- 性能评估:单机低频次的采样,加上海量的服务器使得以无损的开销获取接近真实的结果(每 100K 服务器,每秒平均约 100K 采样样本输入)。
数据处理 & 实时数据处理体系
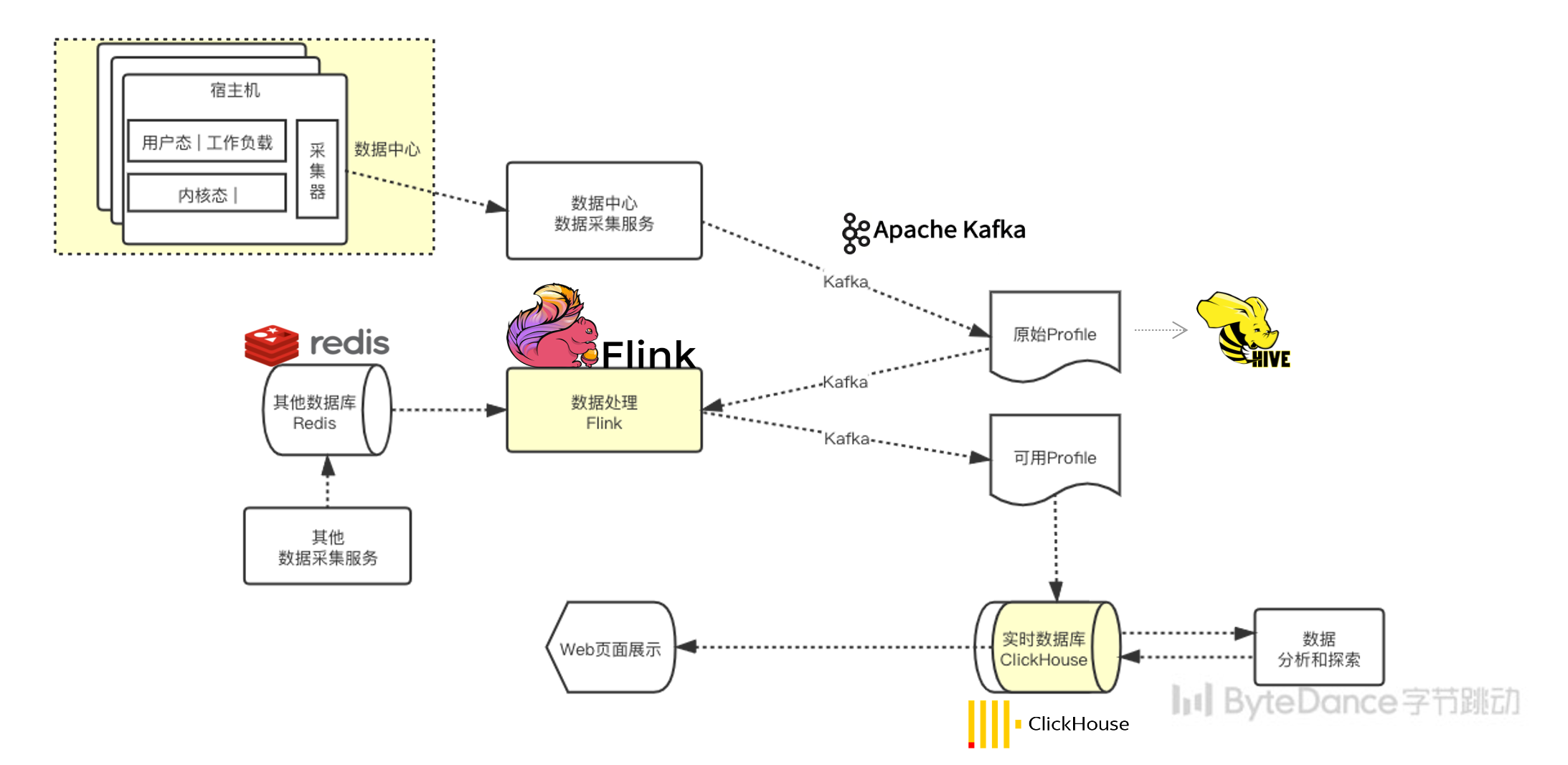
通过轻量级埋点及监控,我们获得了数据中心全量主机的实时数据,这部分数据储存在 Kafka 消息队列中,并被大数据处理部分实时消费。
我们的数据处理部分基于 Flink 大数据处理引擎实现,支持海量高吞吐的数据清洗和关联。
我们将配合分析使用的其他数据放在分布式缓存 Redis 中,通过 Flink 实时进行关联。对数据进行流式分析或者阶段性定时分析,抽取清洗出价值含量较高的中间数据产物。
最后,我们将数据实时/准实时地导入数据仓储,基于人为运维经验的知识仓库总结中的模型,对中间产物进行多维度纵向横向分析,并给出优化建议。从硬件到上层业务,多层次多维度地进行分析和优化。并指导业务基于优化建议持续迭代,达到软硬件协同的最佳实践。
数据分析:全面的刻画维度
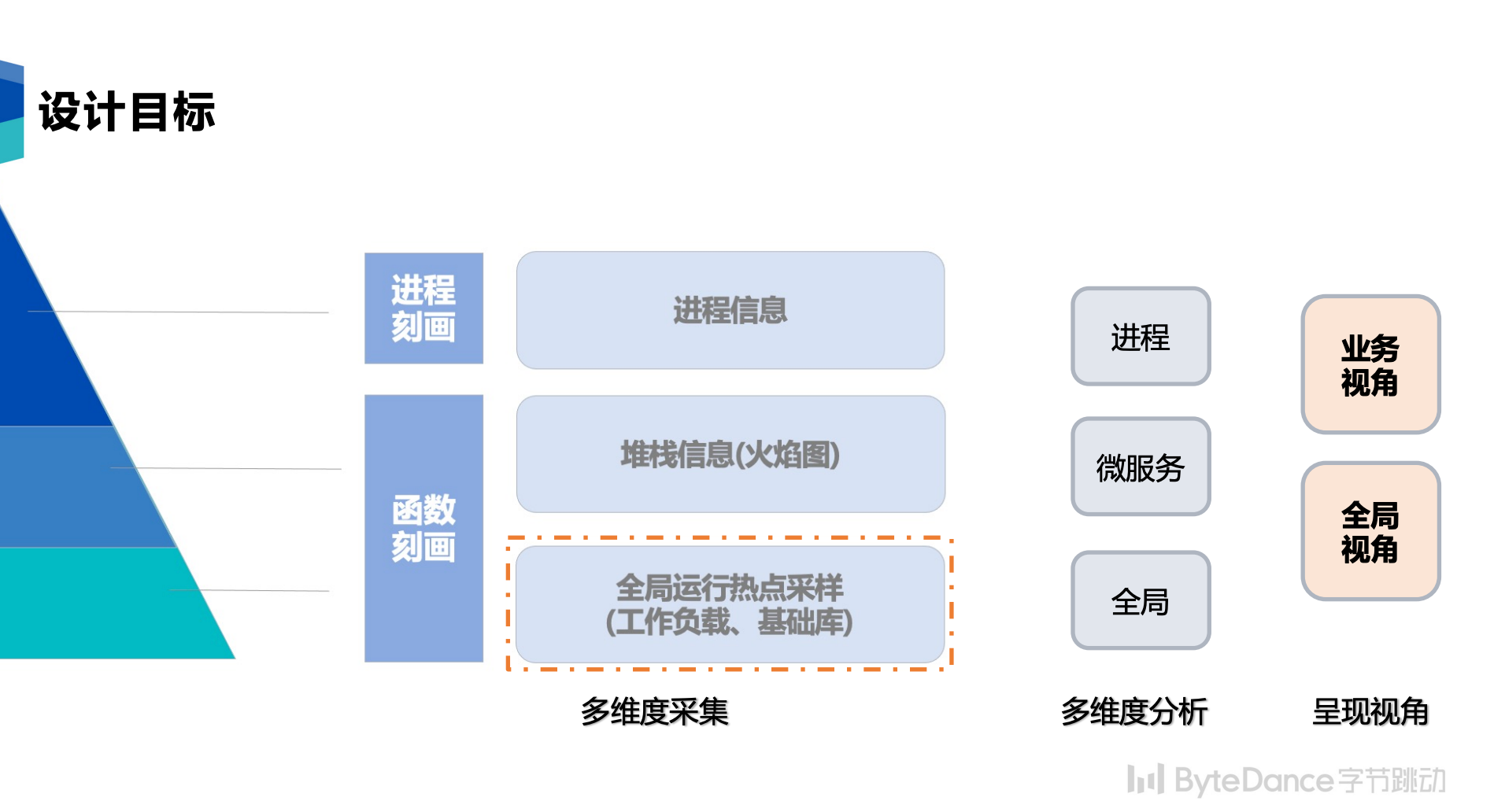
自下而上,我们从两个层级、三个维度进行数据的收集和分析。这三个维度的定位目标不同:
- 热点函数的统计:可以帮助我们了解计算中心实际占用 CPU 最多的热点函数和分布,能最精确地提供全局视角。这部分的采集是最轻量的,因此采集频率也最高,最能刻画整个数据中心的数据。
- 进程和堆栈信息:堆栈采集的开销相对较大,而进程信息采集使用 top 和 ps 工具,其开销中等,这两项作为更细粒度的补充维度。堆栈采集技术上使用改良的 Linux 的 perf 工具 ,物理机上使用 CPU cycles 数 PMU 事件,虚拟机不支持 vPMU 则使用标准的时钟中断,记录样本的函数调用量链栈回溯(FP与LBR结合的方式)。perf 工具的采集频次在小时级,每次采集持续 5s,采集期间每 CPU 采样样本频率 10 Hz,对于 100 vCPU 的服务器,一次采集大约在 2000~4000 样本数。

项目收益
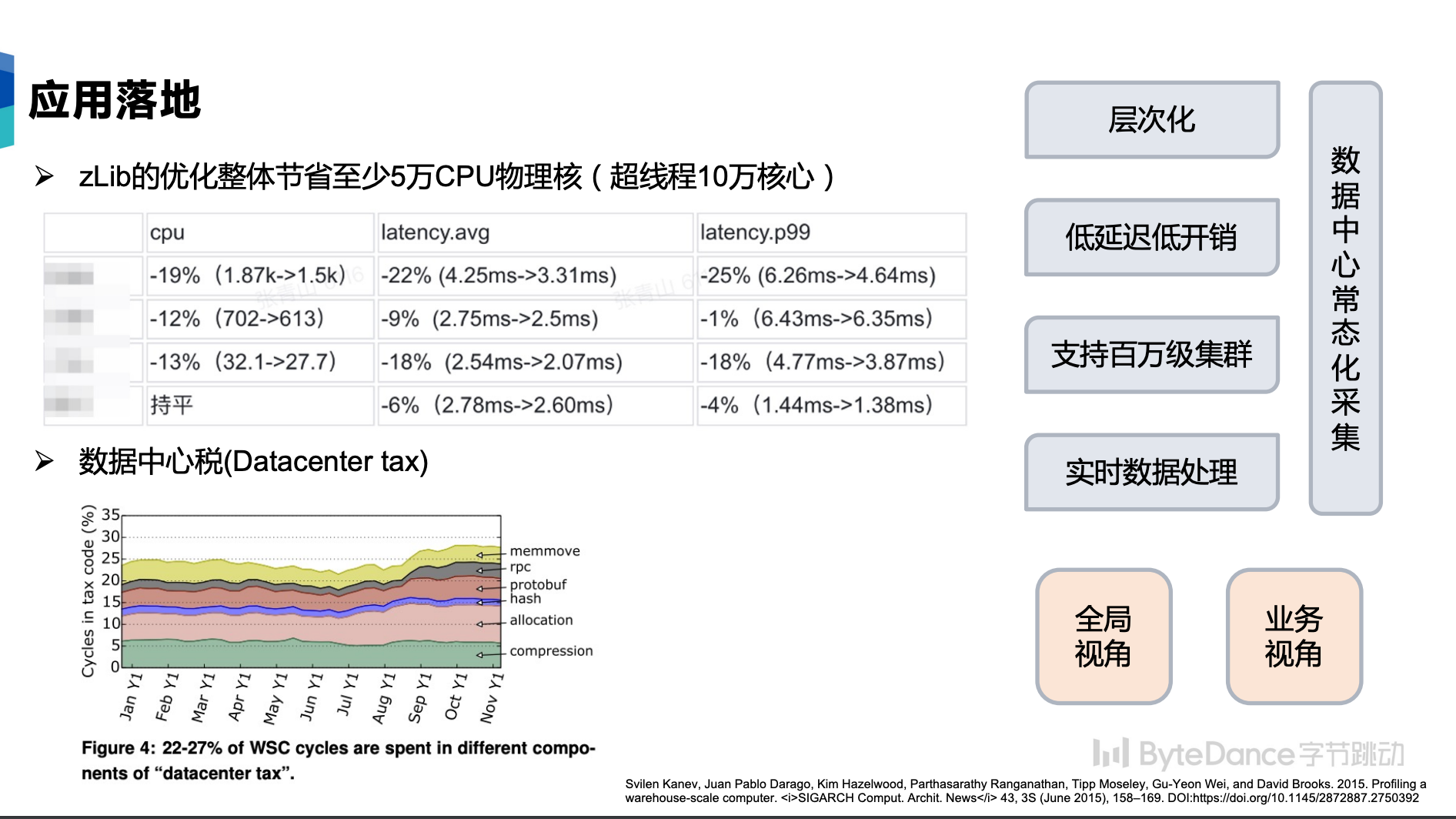
通过算力监控系统,我们可以获得业务最新的数据和指标,从而进行针对性的优化。上图左上角显示了某几个业务在性能优化前后的指标对比情况。在某区域数据中心zlib的基础库的优化中,整体节省了至少 ****5万的 绝对 CPU 物理核(10万 vCPU 超线程)。目前,STE团队还在持续优化更多的基础库,帮助业务团队提高算力,节省物理成本。
另外,通过算力监控系统,我们还试图发现更多的数据中心使用特征。字节内部也实现类似公开文献中“数据中心税”的刻画。通过大盘数据,我们可以发现集群中的业务特征,从而指导我们更好地优化基础组件,指导软硬件协同设计。
总结
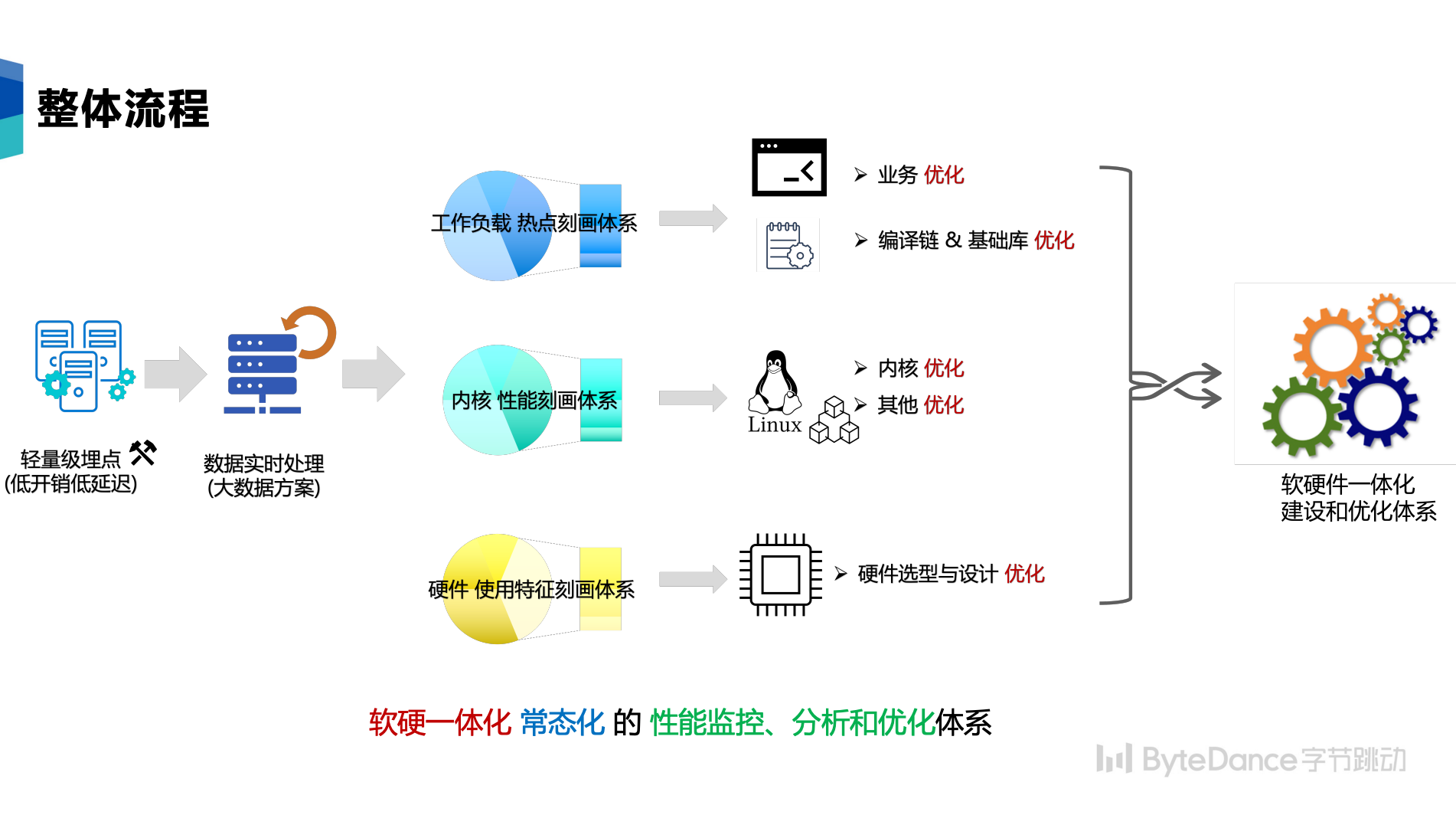
在算力监控系统中,我们构建了轻量级埋点及监控体系,并构建了实时的数据链路,经过流式分析或者阶段性定时分析,并最终得出热点函数的全局统计,帮助业务和基础技术的同学持续进行分析和优化。
针对业务,找到业务的性能瓶颈并优化;针对数据中心,从基础库及编译链的视角进行优化。另外我们可以对 PMU(Performance Monitoring Unit 微架构的性能监控单元)数据特征的精细化分析,对硬件选型进行更多指导。
字节跳动算力监控系统帮助业务部门成功落地性能优化近百万 vCPU 核心,也精确的量化了 STE团队编译与基础库方向在数据中心范围内基础库优化侧的收益。我们将基于优化建议持续迭代,达到软硬件协同的最佳实践,帮助更多业务和数据中心进行优化和升级,最终完成构建软硬件一体化的建设和优化体系。
热门招聘
金三银四的季节,字节跳动STE团队诚邀您的加入!团队长期招聘,北京、上海、深圳、杭州、US、UK 均设岗位,以下为近期的招聘职位信息,有意向者可直接扫描海报二维码投递简历,期待与你早日相遇,在字节共赴星辰大海!若有问题可咨询小助手微信:sys_tech,岗位多多,快来砸简历吧!

|








- 上一条: 蚂蚁安全科技 Nydus 镜像加速实践 2023-04-26
- 下一条: 一文详解多模态认知智能 2023-04-26
- 字节跳动数据湖技术选型的思考与落地实践 2022-01-24
- 美团外卖广告智能算力的探索与实践(二) 2022-05-11
- Hudi Bucket Index 在字节跳动的设计与实践 2022-02-28
- Flink OLAP 在字节跳动的查询优化和落地实践 2023-04-12
- 字节跳动流式数仓和实时服务分析的思考与实践 2022-10-27