Hudi Bucket Index 在字节跳动的设计与实践

由字节跳动数据湖团队贡献的 RFC-29 Bucket Index 在近期合入 Hudi 主分支,本文详细介绍 Hudi Bucket Index 产生的背景与实践经验。
文 | 字节跳动数据平台数据湖团队
Hudi 是一个流式数据湖平台,提供 ACID 功能,支持实时消费增量数据、离线批量更新数据,并且可以通过 Spark、Flink、Presto 等计算引擎进行写入和查询。Hudi 官方对于文件管理和索引概念的介绍如下:
Hudi提供类似 Hive 的分区组织方式,与 Hive 不同的是,Hudi 分区由多个 File Group 构成,每个 File Group 由 File ID进行标识。File Group 内的文件分为 Base File ( parquet 格式) 和 Delta File( log 文件),Delta File 记录对 Base File 的修改。Hudi 使用了 MVCC 的设计,可以通过 Compaction 任务把 Delta File 和 Base File 合并成新的 Base File,并通过 Clean 操作删除不需要的旧文件。 Hudi 通过索引机制将给定的 Hudi 记录一致地映射到 File ID,从而提供高效的 Upsert。Record Key和 File Group/File ID 之间的这种映射关系,一旦在 Record 的第一个版本确定后,就永远不会改变。简而言之,包含一组记录的所有版本必然在同一个 File Group 中。 在本文中,我们将重点介绍 Hudi 索引机制相关的作用和原理,以及优化实践。
Hudi索引的作用与类型
索引的作用
在传统 Hive 数仓的场景下,如果需要对一个分区数据做更新,整个更新过程会涉及三个很重的操作。举一个更直观的例子。假设一个 Hive 分区存在 100,000 条记录,分布在 400 个文件中,我们需要更新其中的 100 条数据。这三个很重的操作分别是:
- 从 400 个文件中读出 100,000 条数据
- 与 100 条更新的数据做分布式关联,取最新值
- 将更新后的 100,000 条数据写入临时目录,最后覆盖原先的数据
由此可以引出三个问题:
- 读那么多文件是必要的吗?
- 更新那么多文件是必要的吗?
- 分布式关联是必要的吗? 假设在数据分布最糟糕的情况下,需要被更新的 100 条数据分布在 100 个文件中。那我们实际需要读和更新的文件是多少个? 答案是 100 个,只占总量的 1/4。 因此,Hudi 为了消除不必要的读写,引入了索引的实现。在有了索引之后,更新的数据可以快速被定位到对应的 File Group,以下面的官方的示意图为例,
- 避免读取不需要的文件
- 避免更新不必要的文件 无需将更新数据与历史数据做分布式关联,只需要在 File Group 内做合并

索引的类型
索引是独立模块, 开源 Hudi 主要提供以下两种索引: 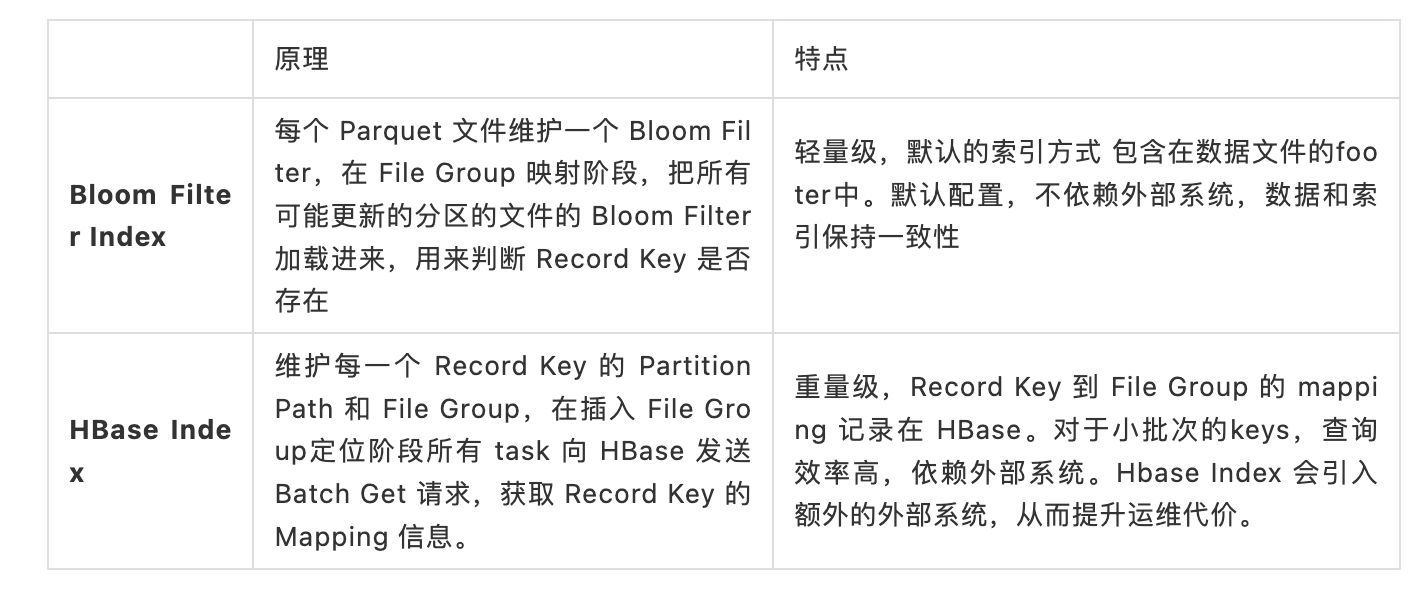 在本文中,我们将介绍一个新的 Hudi 索引模块 Bucket Index 在字节跳动的设计与实践。
在本文中,我们将介绍一个新的 Hudi 索引模块 Bucket Index 在字节跳动的设计与实践。
Bucket Index产生背景
索引带来的性能收益是非常巨大的, 尽管 Hudi 已支持 Bloom Filter Index、Hbase index类型,但在字节跳动大规模数据入湖、探索分析等场景中,我们仍然碰到了现有索引类型无法解决的挑战,因此在实践中我们开发了 Bucket Index 的索引方式。
业务场景挑战
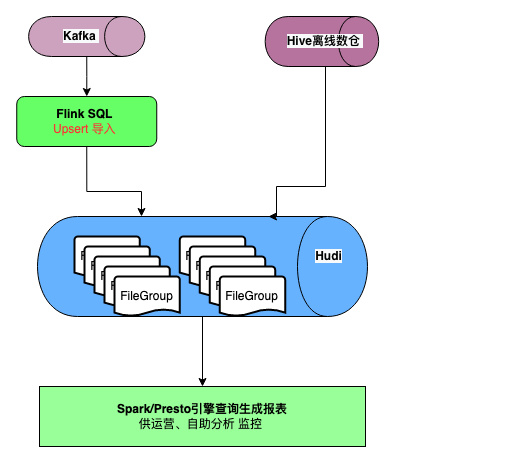
字节跳动某业务部门需要利用实时数据计算各种指标。在其业务场景中存在定期批量写入和流式写入场景,整个流程可以描述如下:
- 批量场景会先将 binlog 导入存储到 Hive 离线仓库中,再按照小时/天级粒度更新数据湖。
- 实时场景则通过 Flink 消费更新的 kafka 数据,写入数据湖,供下游业务使用。
- 当源头数据中的记录存在主键重复的情况下,需要保留最新一条数据即可。
- 在分析侧,业务会基于 Hudi 数据集,通过 Presto/Spark 查询引擎,构建可视化的 BI 报表看板,供运营或分析师自助进行近实时数据分析。 随着入湖的数据量增加,Hudi 中生成了约 40,000 个 File Group。虽然该业务部门使用了 Hudi 索引避免了全局合并操作,但是随着 File Group 的数量以及存储的数据量增加,定位 File Group 的时间也在增加,这造成了 Upsert 速度逐渐缓慢的情况,这严重影响了任务产出时间,甚至导致任务无法跑下去。
分析与对策
为了解决 Upsert 数据场景逐步缓慢的情况,字节跳动数据湖团队对整体的性能下降原因做了进一步分析,并针对性地提出了解决方案。
- 原先的业务场景使用了默认的 Bloom Filter Index 的索引方式。在观察中,团队发现最终在数据量约 30TB 的场景下,定位 Record 的性能会非常糟糕,此时一共产生了约 5 千亿条记录分布在40,000 个 File Group 中。
- 在 5 千亿条记录的数据规模下,团队发现定位缓慢的问题来自 Bloom Filter Index 的假阳性。当 Bloom Filter 发生假阳性时, Hudi 需要确定该 Record Key 是否真的存在。这个操作需要读取文件里的实际数据一条一条做对比,而实际数据量规模很大,这会导致查询 Record Key 跟 File ID 的映射关系代价非常大,因此造成了索引的性能下滑。
- 团队也调研了 Hudi 的另外一种索引方式 Hbase Index。这是一种 HBase 外置存储系统索引。但由于业务方不希望引入 HBase 这一额外依赖,且担心运维 Hbase 过程中存在新的问题,认为 Hbase Index 整体不够轻量,因此在整个业务场景中也无法作为 Bloom Filter 索引的替代。
在这样的场景下,字节跳动需要一个更加轻量且高效的索引方式,并且能够避免在大数据场景下的插入性能问题。
在不断实践中,字节跳动数据湖团队在逻辑层开发了一种基于哈希的索引,使得在插入过程中,定位传入 Record 的待写入文件位置信息时,无需读历史的 Record ,并贡献到了社区的 RFC-29。
改造过后,索引层变成了一层简单的哈希操作,可以直接通过对索引键的哈希操作来找到文件所在的位置。
Bucket Index 设计原理
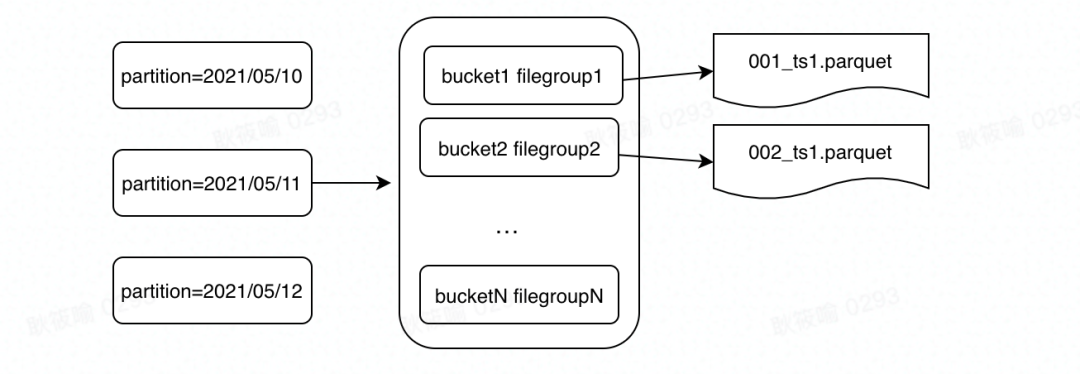
Bucket Index 是一种基于哈希的索引,借鉴了数据库里的 Hash Index。给定 n 个桶, 用 Hash 函数决定某个记录属于哪个桶。最终所有分区被分成 N 个桶,每个桶对应一个 File Group。
相比较 Bloom Filter Index 来说,Hash Index 在逻辑层面提供了 Record Key 跟 File Group 的映射关系, 不存在假阳性问题。相同 key 的数据一定是落在同一个桶里面。最终一分区内的结构如下,目前一个 Partition 里面 Bucket 和 File Group 是一一对应的关系。
Bucket Index 数据写入原理
Bucket Index 的实际写入流程可以参考下面的过程示意图。以下面的实时插入场景为例,某业务批次新增了 5 条记录,并且需要 Upsert 到已有的分区 partition=20220203 中,对已有数据根据主键 Record 做一个更新,保留最新的数据。 整个过程可以用下面的示意图表示: 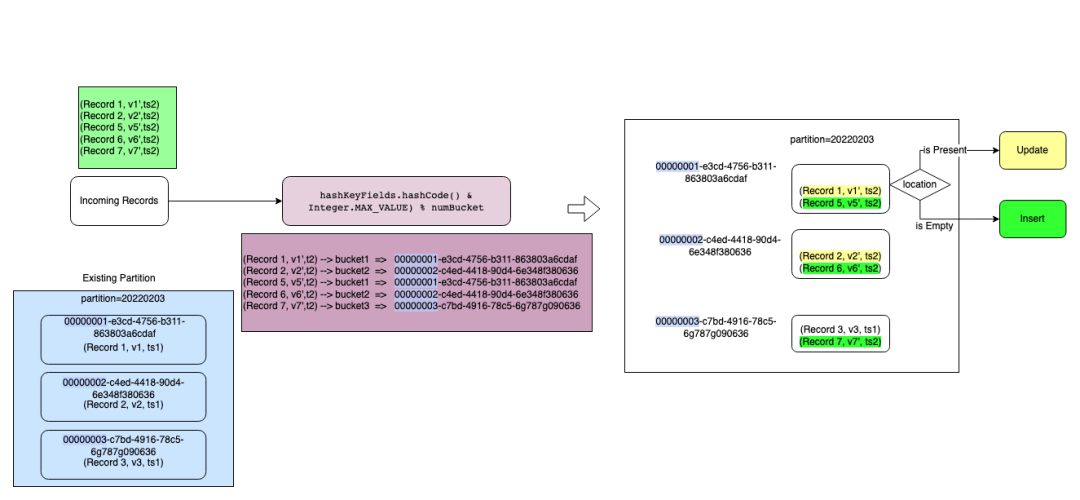
- 在建表时先预估表的单个分区数据存储大小,设置一个分桶数 numBuckets。
- 在数据插入前,首先生成 n 个 File ID, 将 File ID 的前8位替换成 bucketId 的数字:
00000000-e929-4327-8b0c-7d0d66091321 00000001-e3cd-4756-b311-863803a6cdaf 00000002-c4ed-4418-90d4-6e348f380636 00000003-c7bd-4916-78c5-6g787g090636
- 在插入过程中,最重要的一步就是标记每条新插入的记录属于哪个文件 File Group,然后找到对应的 File Group 去更新或者合并。在目前的设计中, 分桶数跟 File Group 是一一对应的映射关系,因此找到每条Record 对应的桶 ID ,即可确定 Record Key跟 File Group的映射关系。 在具体实现中,我们会对更新数据的索引键计算哈希,再对分桶数取模快速定位到每个 Record 对应的桶,整个过程如下面的 Hash 函数所示:
hashKeyFields.hashCode() & Integer.MAX_VALUE) % numBuckets
其中hashKeyFields可以由用户指定,是Record Key的一个子集,当默认不指定时,会以Record Key本身作为 hash 键。在计算好后,每条记录即可知道即将写入的桶。 4. 完成数据写入 经过索引层之后,每条数据都会带有一个 File ID,引擎会根据 File ID 进行一次 Shuffle,将相同File ID的数据导入到同一个子任务中。对于 COW 表而言,更新Update 部分需要和已有的 BaseFile 合并生成新的 BaseFile。而 MOR 表将 Update 的数据直接写入对应 File Group 的 delta log,Insert 部分生成新的 BaseFile,最终完成该批次数据的 Upsert。 由此可见,整个过程中 Bucket Index 不需要对现有的数据进行扫描组成类似 Bloom Filter 一样的过滤器,因此可以省去整个定位 File Group 的查询时间,定位 File Group 的时间也不会随着已有 Record 条数的增加而导致性能下降。同时分桶操作会在每个桶内对分桶列排序,排序后的数据一般能获得更高的压缩率,也能节省存储。
Bucket Index 查询优化原理
在查询时,Bucket Index 的查询优化会充分利用主流计算引擎的特性。例如 Spark 会利用表的 Bucket 分布做查询优化,例如提升查询性能。从 Bucket Index 表中读取数据时,由于数据分布已经按照按索引字段进行聚类和排序。Spark 可以通过在优化器中应用规则来匹配这种模式,来避免一些 Shuffle 操作。 目前的优化规则主要有下面两种:
-
Bucket Pruning,利用表的 Bucket 分布对读取数据进行剪枝。 例如,如下的T1表的 bucket column 为 city ,在执行下面查询时:
select * from T1 where city = beijing在针对索引列 city 的某个值进行查询时,实际上只需读取一个分桶数据 ( bucket pruning ) , 因为city= beijing 的 Record 在一个分区中必然是 Hash 到同一个 Bucket,这样对于每个分区来说,被 Scan 读取的 Hudi 数据量会大大减少。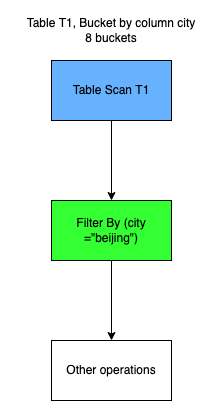
-
Bucket Join,利用表的 Bucket 分布减少 Aggregate/Join 带来的 shuffle 操作。 对于 Group by 的场景,例如 city 是其中的一个索引列,在进行下面的聚合操作时:
select city from T1 group by city由于相同A的取值必然是落在同一个 bucket 桶中,因此寻找 city='beijing' 时,不需要去访问其它的 bucket 中去获得,因此可以在 window 操作时可以省去一次 Shuffle 操作。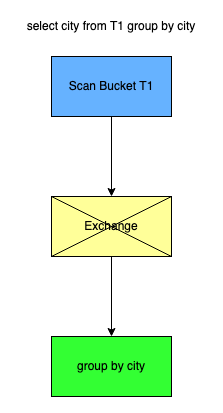
同理在 Join 的过程中,假如 T1 是一张 bucket 表并且 bucket index 的索引键为 city。而 T2 是一张非 bucket 表。 在 join 时,对于开启 bucket index 的表 T1 可以避免一次额外的 exchange 操作:
select count(*) from T1 join T2 where T1.city = T2.city
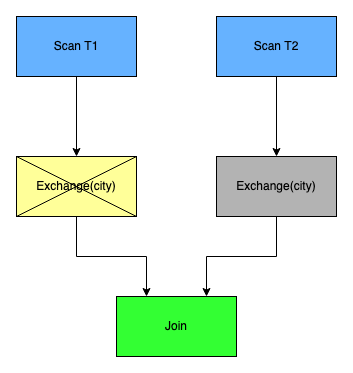
总体而言,所以利用 Bucket Index 的 Hudi 表可以做到提升过滤速度和提高查询效率。
Bucket Index 的实践与未来规划
在实践过程中,我们也发现了 Bucket Index 的一些实践建议以及未来的方向。一个关键的问题,是如何确定 numBuckets 的值,目前 Bucket Index 的桶数量 ,需要根据预估的数据量提前在建表时进行确定,且建表后不可更改,对于这种限制,我们目前有下面的解决方案。
要设置合理的桶数量,需要预测表的目标大小和未来数据增长情况。
-
桶的数量过小会降低整体引擎的并行速度,原因不难理解:当数据量增大时, 单个 File Group 对应的数据将增大,而 Hudi 表是以 File Group 为单位将数据切割生成 inputSplit 的,单个 File Group 数据过大将导致查询并发降低,性能下降。 一般说来建议单个桶的大小控制在 3GB 左右。
-
同时我们也应该避免桶的数量过多,过多的桶数量则会造成单个桶的数据量太小,造成小文件情况。基于这样的范围,当目标表的大小可以被预测时,我们可以比较容易得到一个合适的 Bucket Index 的桶数量值。
当然,我们也意识到这样的做法并不是一个灵活的方法。在未来,我们将推出可扩展的 Hash Index 桶方法来彻底解决这个问题。我们将支持已有的 Hudi 表在建表后直接扩展桶的数量,以避免当业务数据暴增时单个文件太大,影响查询以及 Compaction 性能。我们的后续优化将利用 Hashmap 的扩容过程,将分桶数按倍数做到轻量级扩容。当桶的数量在初期预测设置较小时,今后也能动态扩容,可以彻底解决预估桶数量不准确带来的烦恼。
总结
总结而言,Hudi Bucket Index 作为一种基于哈希的索引,充分做到了轻量级。对更新数据的主键计算哈希,再对分桶数取模快速定位到 File Group,可以稳定的保证导入性能。相比 Bloom Filter Index 而言,在大数据导入 Upsert 场景下有一定的优势,帮助字节跳动的业务部门解决了导入性能随着数据量增长而下降的难题。 同时在查询时,也能充分跟计算引擎结合,利用表的 Bucket 分布对读取数据进行剪枝,并且利用 Bucket 分布特性减少 Aggregate/Join 带来的 Shuffle 操作,提升了查询性能。 对于 Hudi 使用用户来说,也不需要改变原有的习惯,只需以插拔的方式指定 Hudi 表想使用的索引类型和桶的数量配置即可,充分做到了易用性与便捷。 目前 Hudi Bucket Index (RFC-29) 的实现已经合入社区最新的主分支,因此,我们非常推荐广大 Hudi 社区用户在实践中使用,并且欢迎各位同行在 Hudi 社区进行技术交流与深入讨论,后续我们也会基于 Bucket Index 的反馈持续贡献新特性。
产品介绍
火山引擎湖仓一体分析服务LAS
湖仓一体分析服务 LAS(Lakehouse Analytics Service)是面向湖仓一体架构的Serverless数据处理分析服务,提供一站式的海量数据存储计算和交互分析能力,完全兼容 Spark、Presto、Flink 生态,帮助企业轻松完成数据价值洞察。地址
火山引擎 E-MapReduce
支持构建开源Hadoop生态的企业级大数据分析系统,完全兼容开源,提供 Hadoop、Spark、Hive、Flink集成和管理,帮助用户轻松完成企业大数据平台的构建,降低运维门槛,快速形成大数据分析能力。地址
欢迎关注字节跳动数据平台同名公众号
|








- 上一条: 二叉树解题思维 2022-02-28
- 下一条: 掌握这些招数,你也能写出HR眼中的高分简历 2022-02-28
- 字节跳动基于 Apache Hudi 的多流拼接实践方案 2022-03-30
- Presto 在字节跳动的内部实践与优化 2022-01-10
- 基于MRS-Hudi构建数据湖的典型应用场景介绍 2021-12-09
- 字节跳动数据湖技术选型的思考与落地实践 2022-01-24
- 从hudi持久化文件理解其核心概念 2022-02-18


