Flink OLAP 在字节跳动的查询优化和落地实践
本文整理自字节跳动基础架构工程师何润康在 Flink Forward Asia 2022 核心技术专场的分享。Flink OLAP 是数据仓库系统的重要应用,支持复杂的分析型查询,广泛应用于数据分析、商业决策等场景。本次分享将围绕字节 Flink OLAP 整体介绍、查询优化、集群运维和稳定性建设、收益以及未来规划五个方面展开介绍。
一、字节 Flink OLAP 介绍
业务落地情况

字节 Flink OLAP 上线以来接入了包括 User Growth、飞书、电商和幸福里等 12 家以上核心业务方,集群规模达到 1.6 万 Core 以上,每天的查询规模超过 50w 次,单集群支持了复杂查询高峰期的 200 QPS,同时 Query Latency P99 控制在 5s 以内,较好的满足了业务的性能需求。
架构
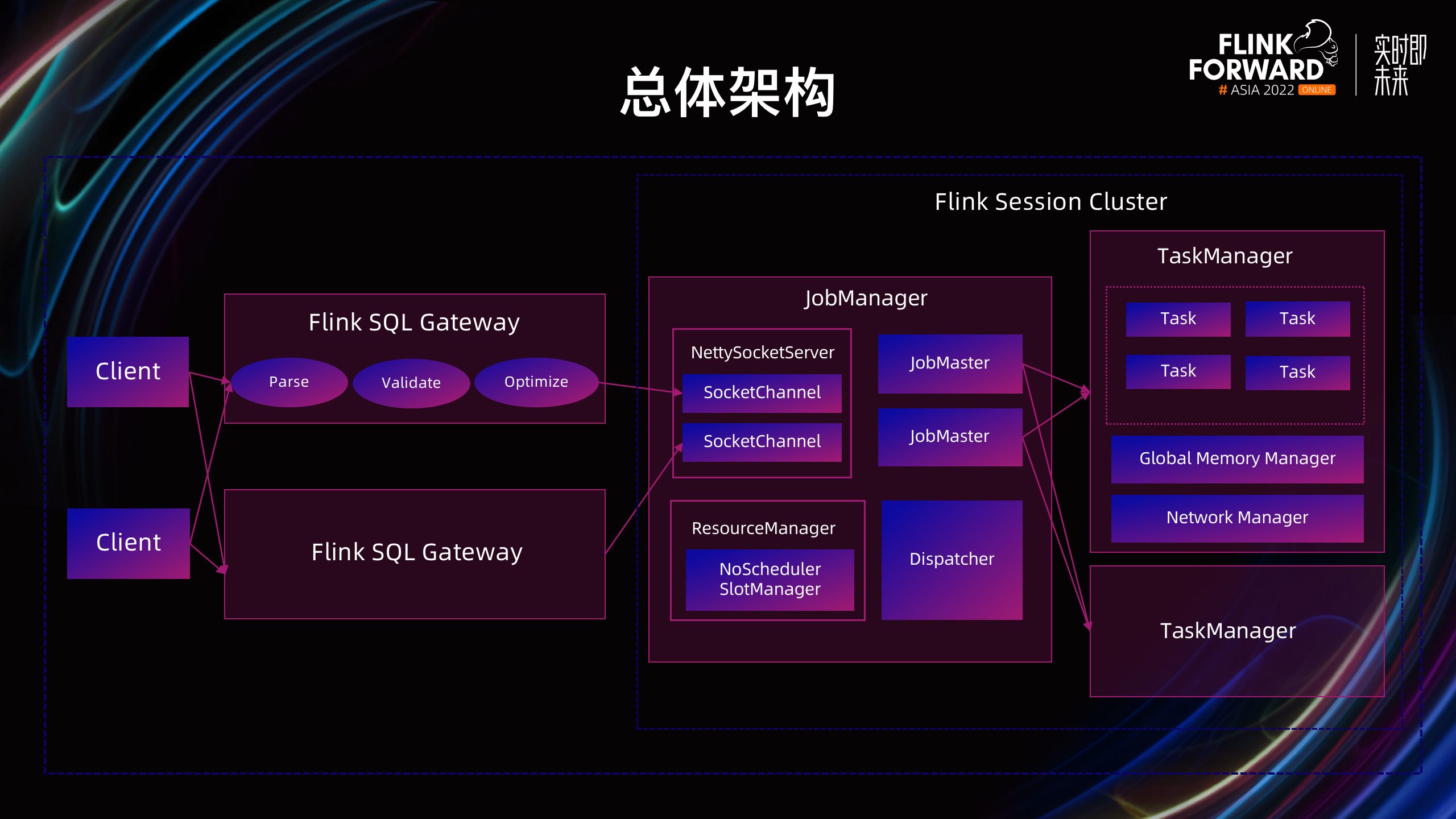
Flink OLAP 的总体架构分为 Flink SQL Gateway 和 Flink Session Cluster 两部分。
首先,用户通过 Client 提交一个 Query,先经过 Gateway 的 SQL 解析和优化过程,生成作业的执行计划,再提交给 Flink Session Cluster 的 JobManager,JobManager 的 Dispatcher 组件会创建一个对应的 JobMaster,并根据特定的调度规则将 Task 部署到对应的 TaskManager 上执行,最后将执行的结果返回给 Client。

Flink OLAP 是作为内部自研的高性能 HTAP 产品 -- ByteHTAP 的 AP 引擎,用于支持内部的核心业务。通过支持双机房部署提高容灾能力,每个新接入的业务可以在双机房垂直部署两套 AP 集群,在线上集群出现严重故障时,可以通过 Proxy 快速切流到另一个集群,从而提高服务的可用性。
业务落地挑战

Flink 在流式场景的应用已经十分成熟,在批式场景的应用也在逐步扩大,但是在 OLAP 场景下的打磨和使用则较少。字节 Flink OLAP 在真实的业务落地过程中遇到了很多问题和挑战,主要分为对性能和运维稳定性的挑战。
在性能方面的一大挑战是 OLAP 业务要求亚秒级的作业 Latency,这和流批有很大的不同,流式和批式主要关注数据的处理速度,而不需要关注 Plan 构建、Task 初始化等阶段的耗时。但是在 OLAP 场景下,优化这些阶段的耗时就变得非常重要。另外,字节 Flink OLAP 基于存算分离架构,有更加强烈的算子下推需求。
另一个挑战是,OLAP 业务要求较高的 QPS,所以当 OLAP 集群频繁地创建和执行作业,某些情况下会导致集群出现严重的性能问题,但是在流式和批式下只需要执行一次通常不会出现问题。因此,针对以上不同,在 OLAP 场景下进行了很多查询相关的优化,比如 Plan 的构建加速和初始化等相关优化。

在业务的落地过程中,OLAP 和流批场景有很大的不同,运维、监控和稳定性都需要针对 OLAP 场景单独构建。
在运维方面,OLAP 是在线服务,对可用性的要求很高,所以完善测试流程和测试场景是非常必要的,可以减少线上 Bug 的概率。另外在运维升级时,不同于流批作业的直接重启升级,OLAP 集群的运维升级因为不能中断用户使用,所以如何做到无感知升级是一个挑战。
在监控方面,为了保障在线服务的可用性,线上集群出现问题后,需要及时进行故障恢复和定位。因此针对 OLAP 下的监控体系就尤为重要。除了流批的集群状态监控外,OLAP 场景下特有的慢查询分析和监控,是需要额外构建的。
在稳定性方面,第一个挑战是建设 OLAP 容灾能力。流批和 OLAP 的故障恢复策略不同,流式作业通过 Failover 来恢复,批式作业通过作业重跑或 Failover 来恢复。在 OLAP 下,多个作业同时运行在一个在线集群上,单个作业失败可以重试,但是整个集群出现无法恢复的故障时,如果采用重启恢复,分钟级别的耗时对于线上服务是无法接受的。第二个挑战是 Full GC 的治理,流批作业对 Full GC 的容忍度相对较高,但是 OLAP 下业务对 Latency 非常敏感,而且 Full GC 还会导致同时运行的其它作业变慢,严重影响用户体验。
二、查询优化
Query Optimizer 优化
Plan 缓存

在 OLAP 场景下,Query 有两个典型的特点:业务上重复的 Query 和亚秒级的查询耗时。通过分析发现,Plan 阶段的耗时为几十到几百毫秒,占比较高。因此支持了 Plan 缓存,避免相同 Query 的重复 Plan。此外也支持了 Catalog Cache,加速元信息的访问,还支持 ExecNode 的并行 Translate,使 TPC-DS Plan 的耗时降低了 10% 左右。
算子下推
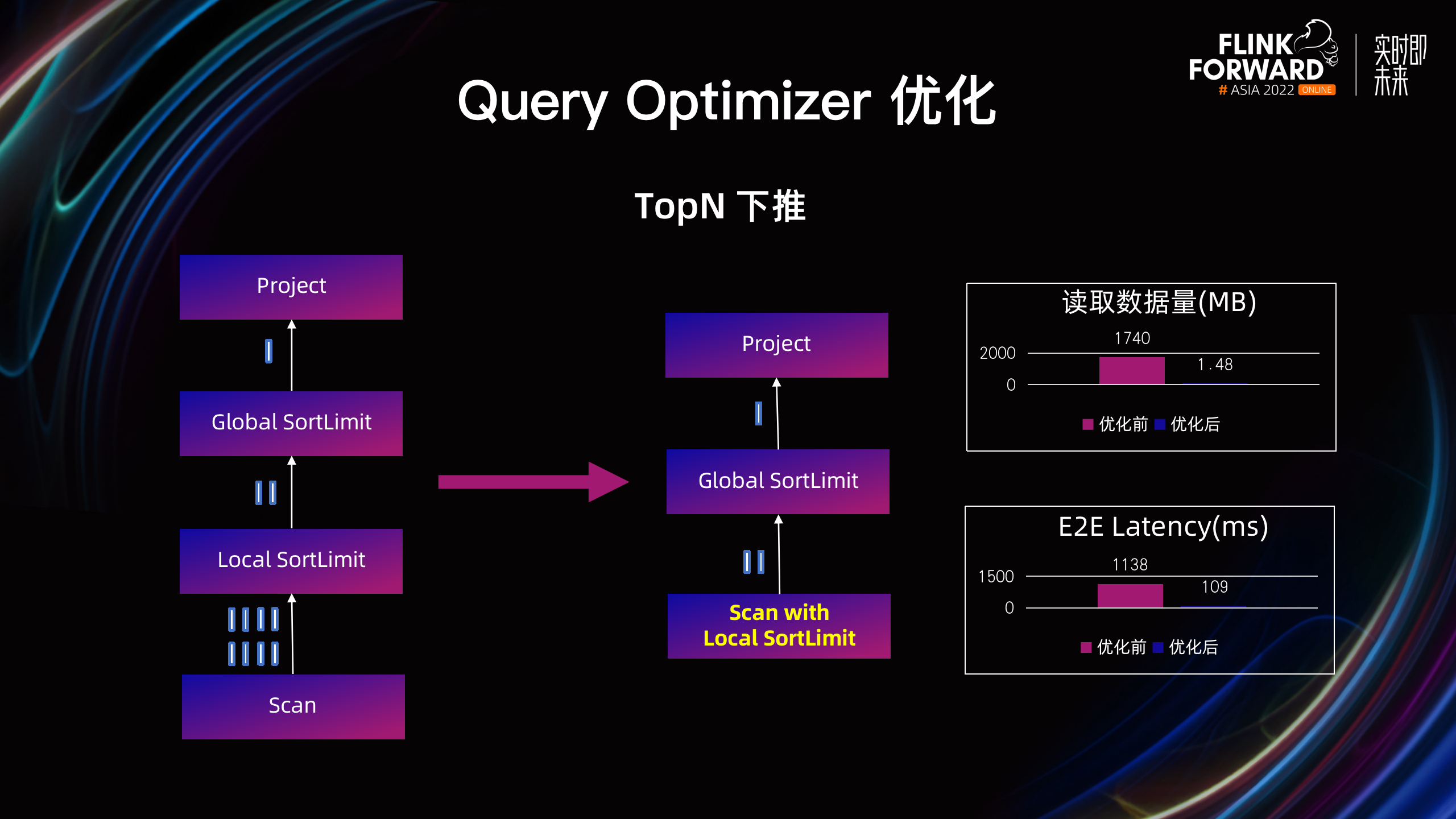
在存算分离架构下,算子下推是一类非常重要的优化。核心思路是尽可能的将一些算子下推到存储层进行计算,大幅减少 Scan 的数据量,降低外部的 IO,同时也能够减少 Flink 引擎需要处理的数据量,从而明显提升 Query 的性能。
TopN 下推:在字节内部的一个典型业务上,大部分 Query 都是取 TopN 的数据。通过支持 TopN 的下推优化,把 Local SortLimit 算子,也就是 Local 的 TopN 算子,下推到了 Scan 节点,最终在存储层做 TopN 计算,从而大幅降低从存储读取的数据量。经过优化后,读取数据量降低了 99.9%,业务 Query 的 Latency 降低了 90.4%。 除此之外,也支持了包括 Aggregate、Filter、Limit 等更多的算子下推。

跨 Union All 的常见算子下推:字节内部某个业务的数据是按照典型的分库分表存放的,在该场景下,用户如果需要查询全量数据,会对多张表进行 Union All 后再进行计算。目前,Flink Planner 缺乏对常用算子跨 Union All 下推的支持,导致用户查询会从 Source 读取大量的数据,并且处理这些数据也会占用大量的资源,最终导致资源消耗和 E2E Latency 都较高。因此支持了常用算子跨 Union All 下推的优化,包括 Aggregate,SortLimit 和 Limit 算子。
以 Aggregate 为例,从图中可以看出,在优化之前,Union All 节点的下游是一个 Local Aggregate 节点。由于当前 Flink Planner 不支持跨 Union All 的算子下推,导致这里的 Local Aggregate 节点无法下推到 Union All 的上游,也无法进一步下推到 Scan 节点,导致从存储读取了大量的数据。优化之后把 Local Aggregate 节点推到了 Union All 的上游,最终下推到了存储做计算。经过优化后,业务查询的 E2E Latency 降低 42%,Flink 集群的 CPU 消耗降低 30%。
Join Filter 传递

在线上业务的查询中,带 Join 的查询是非常多的,其中大部分的查询是 Equal Join,并且带一个 Filter 条件。但是由于 Join 一侧的 Filter 没有传递到 Join 的另一侧,从而导致 Scan 的数据量较大,进而影响查询性能。
因此支持了 Join Filter 的传递。从上图中可以看出,t1 表的 Filter t1.id > 1,可以通过 Equal 的 Join 条件 t1.id=t2.id,推导出 t2.id>1。因此可以推到 t2 Scan 节点的上游,同时由于支持了 Filter 传递,最终 t2.id>1 会被下推到存储做计算,那么从 t2 的 Scan 节点读取的数据会大幅减少,从而提升查询性能。
Query Executor 优化
Classloader 复用优化
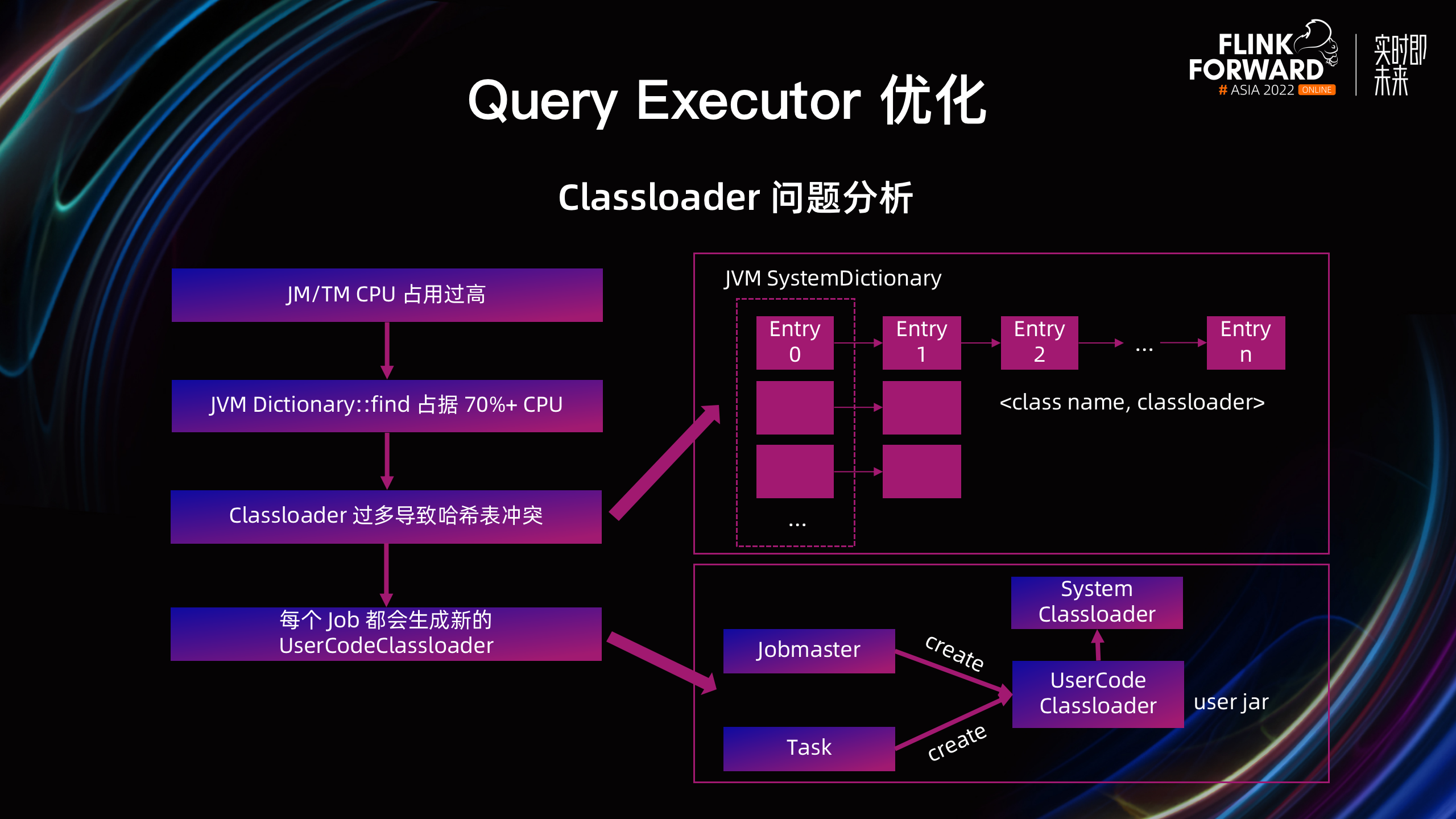
在线上集群持续运行的过程中,我们发现了JM / TM 进程频繁创建 Classloader,导致 CPU 占用过高的问题。通过火焰图分析,JVM Dictionary::find 占据了 70% 以上的 CPU,进一步分析 JVM 源码发现,JVM 在加载了 class 之后,为了加速从 class name 到 Classloader 的查找,会维护一个名叫 SystemDictionary 的哈希表。在 Classloader 数量非常多的时候,哈希表中存在大量的冲突,导致查找过程非常缓慢,同时整个 JM 大部分的 CPU 都消耗在这个步骤。
通过定位发现,这些 Classloader 都是 UserCodeClassloader,用于动态加载用户的 Jar 包。从图中看出,新 Job 的 JobMaster 和 TM 上该 Job 的 Task 都会创建新的 UserCodeClassloader,导致 JM 和 TM 上的 Classloader 过多。除此之外,Classloader 过多还会导致 JVM Metaspace 空间不足,进而频繁地触发 Metaspace Full GC。
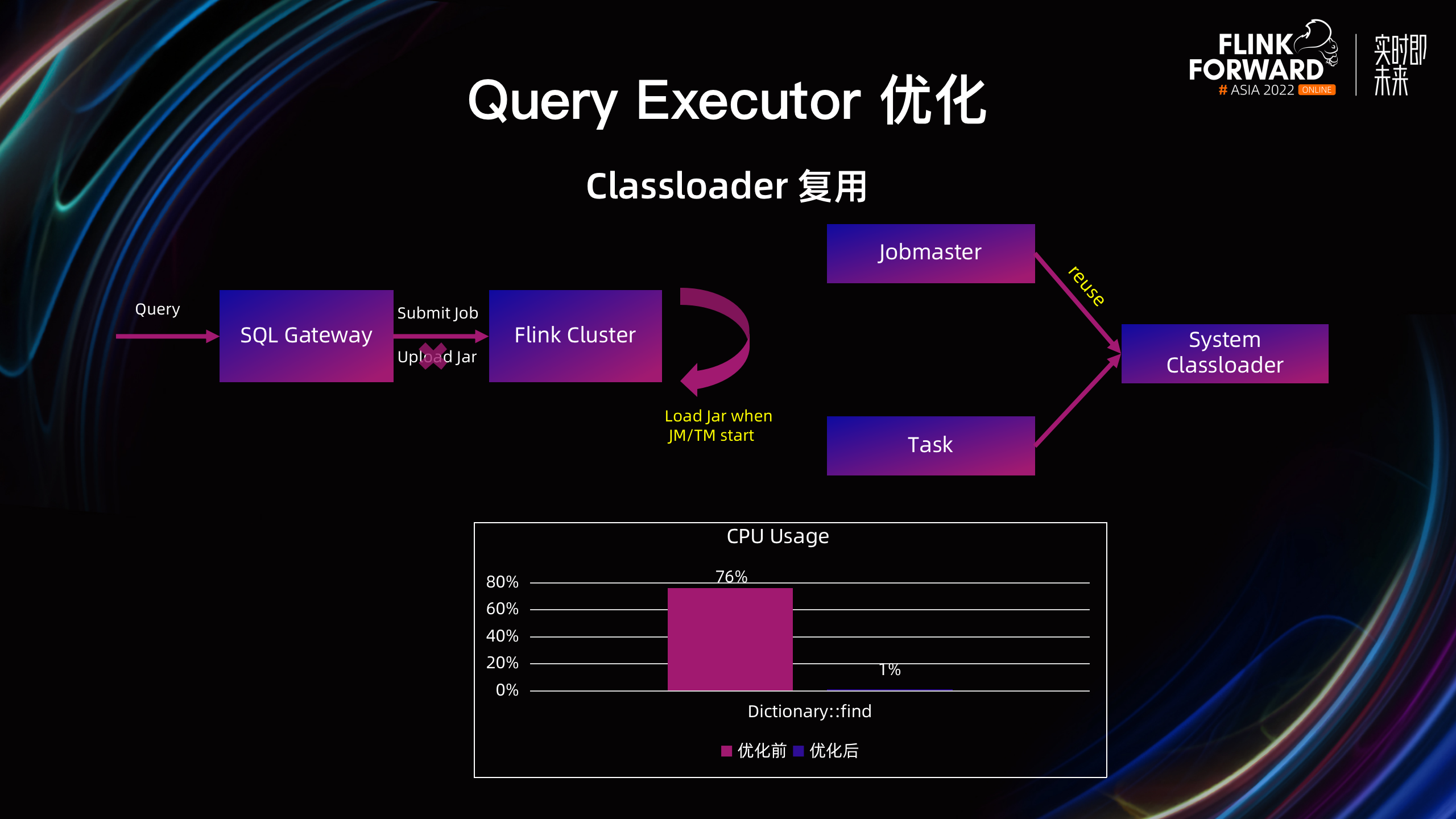
因此支持了 Classloader 复用的优化,分为两步:首先优化依赖 Jar 包的方式,由于 OLAP 场景下依赖的第三方 Jar 包是相对固定的,可以直接放在 JM 和 TM 启动的 Classpath 下,并不需要每个作业单独提交 Jar 包。其次,对于每个作业在 JobMaster 和 Task 初始化时,直接复用 System Classloader。经过优化后,JM 中 Dictionary::find 所占的 CPU 使用从 76% 下降到 1%,同时,Metaspace Full GC 的频率显著降低。
Codegen 缓存优化
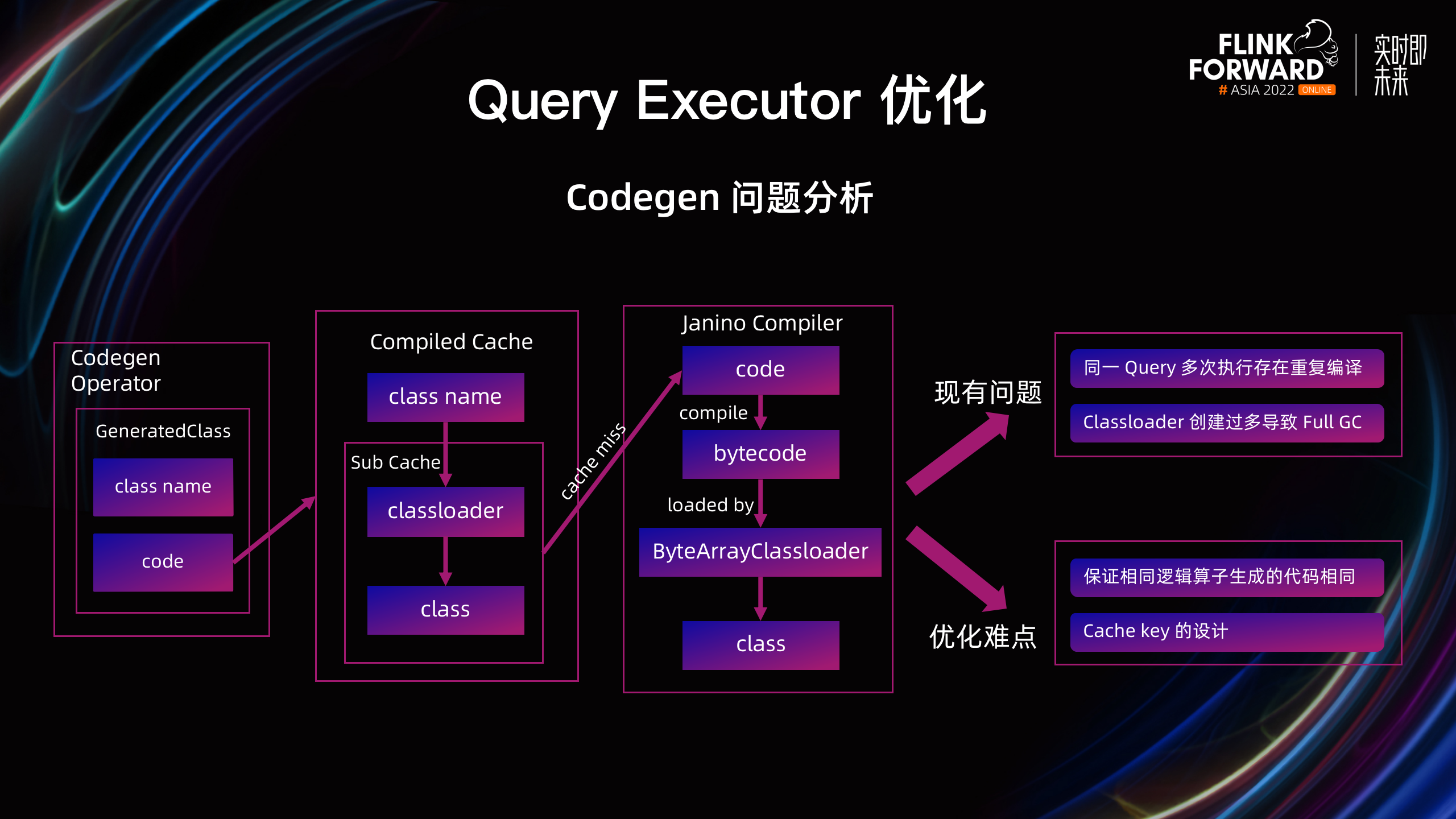
在 OLAP 场景下,Codegen 源代码编译的 TM CPU 占比较高,同时耗时较大。为了避免重复编译,当前的 Codegen 缓存机制会根据 Codegen 源代码的 Class Name 映射到 Task 所用的 Classloader,再映射到编译好的 Class 中,一定程度上缓解了该问题。但在当前缓存机制下,存在两个明显的问题:
- 当前的机制只实现了同一个作业内部,同一个 Task 不同并发的复用,但是对于同一个 Query 的多次执行,依然存在重复编译;
- 每次编译和加载 Class 都会创建一个新的 ByteArrayClassloader,频繁创建 Classloader 会导致 Metaspace 碎片严重,并引发 Metaspace Full GC,造成服务耗时的抖动。
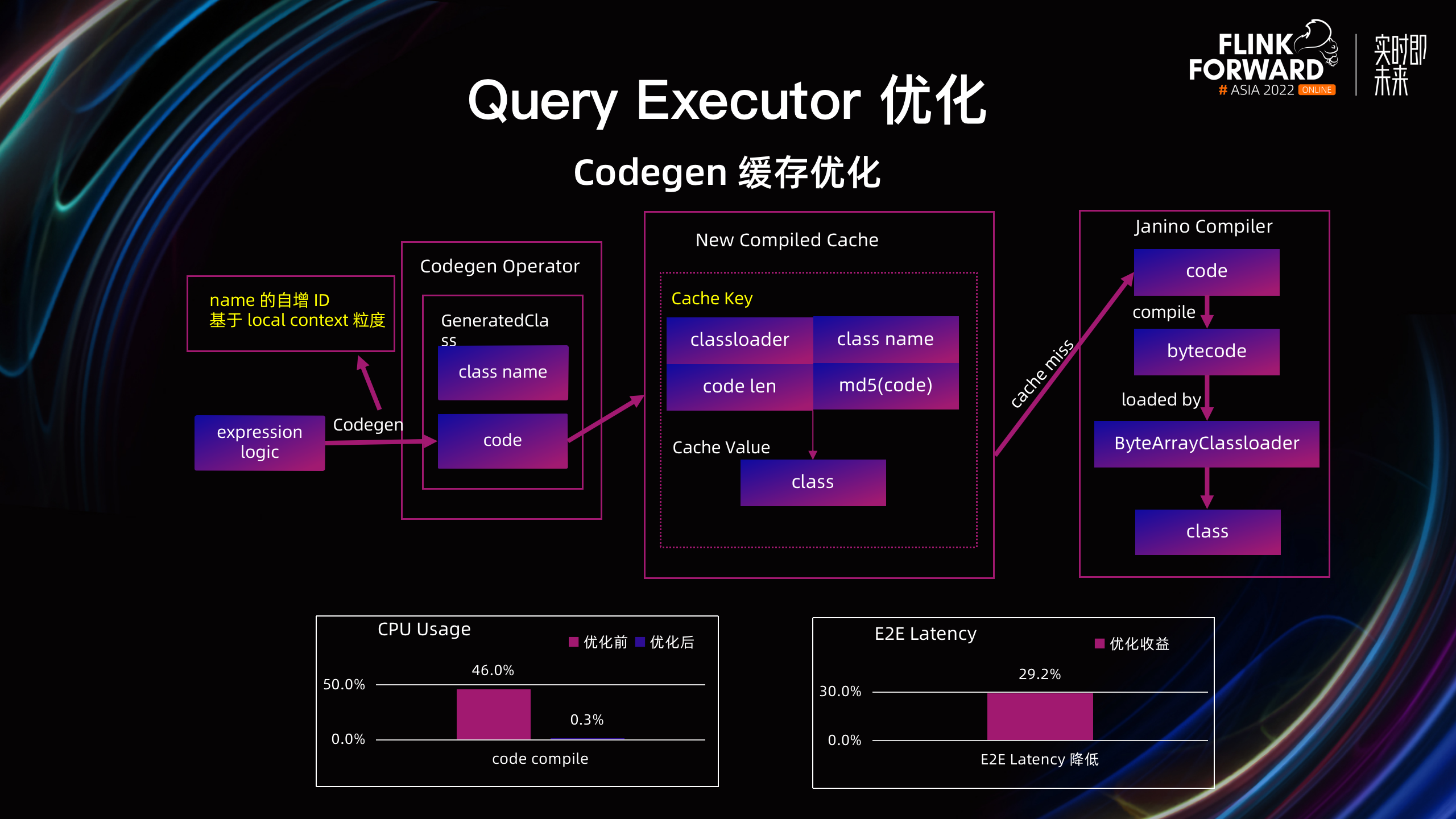
为了避免跨作业代码的重复编译,实现跨作业的 Class 共享,需要优化缓存逻辑,实现相同源代码到编译 Class 的映射。存在以下两个难点:
如何保证相同逻辑的算子所生成的代码相同?
在 Codegen 代码生成的时候,把类名和变量名中的自增 ID,从全局粒度替换为 local context 粒度,使相同逻辑的算子能生成相同的代码。
如何设计 cache key 唯一识别相同的代码?
通过设计基于 Classloader 的 Hash 值 + Class Name + 代码的长度 + 代码的 MD5 值的四元组。并将其作为 cache key 来唯一识别相同的代码。
Codegen 缓存优化的效果非常明显,TM 侧代码编译的 CPU 使用率 46% -> 0.3%,Query 的 E2E Latency 降低了 29.2%,同时 Metaspace Full GC 的时间也降低了 71.5%。
反序列优化
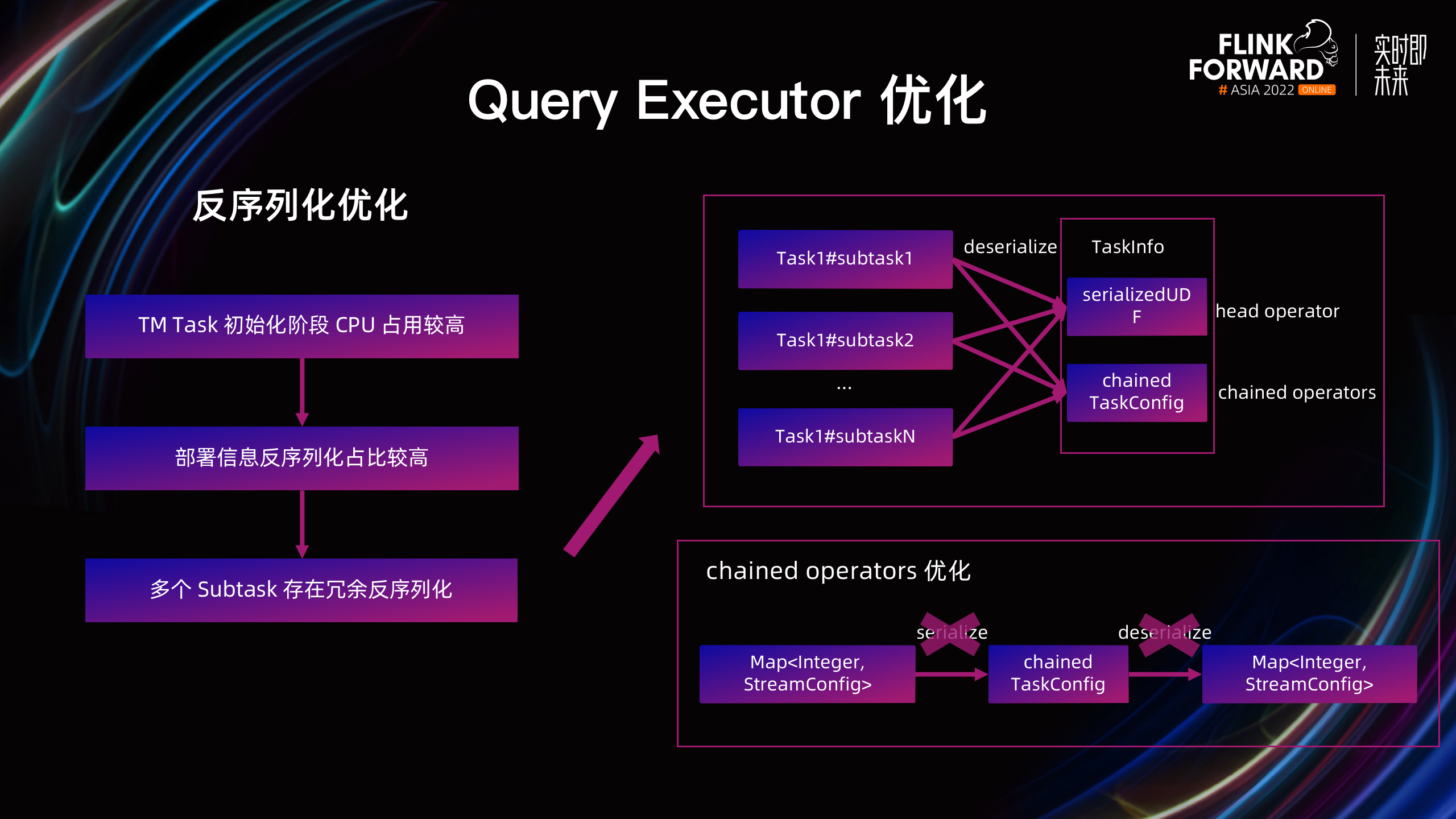
在优化 Task 部署性能时,通过火焰图发现,TM Task 初始化阶段的 CPU 占用比较高,进一步分析发现在做 Task 部署信息的反序列化时,同一个 Task 的多个 Subtask 存在冗余的反序列化。Task 部署信息 TaskInfo 主要包含 Head Operator、Chained Operators 信息,在作业构建时会分别被序列化为 TaskInfo 中的 SerializedUDF 和 ChainedTaskConfig。为了减少冗余的反序列化,有以下两个可优化的方向:
其一是 Chained Operators 的嵌套序列化结构,主要是去掉对 Map 结构不必要的序列化和反序列化,使得同一 Task 的多个 Subtask 可以复用同一个反序列化后的 Map。
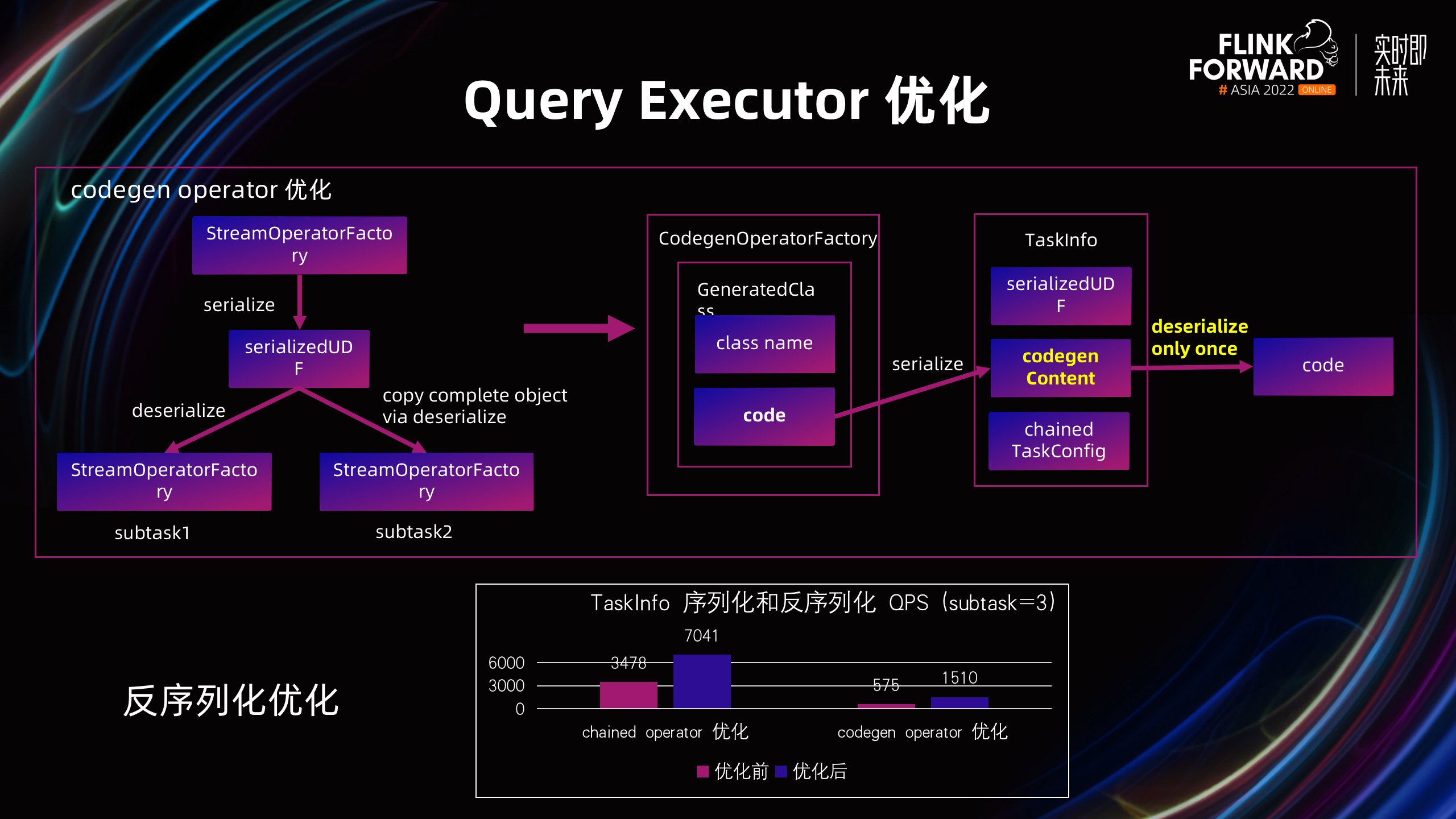
其二是 Codegen 算子的优化。在占比较大的 Codegen 算子在初始化时,也存在较高的反序列化开销。经过分析,该类算子部署信息主要包含 Codegen 源代码,但是一个 TM 上的多个 Subtask 都需要反序列化一遍同样的源代码,存在大量的冗余,因此把 Codegen 源代码拆分出来,单独反序列化一遍后,给所有 Subtask 共享。
以上反序列化优化的效果非常明显,在同一个 Task 的 Subtask 个数等于 3 的时候,TaskInfo 整体的序列化和反序列化 QPS 分别提升了 102% 和 163%。
其他更多优化
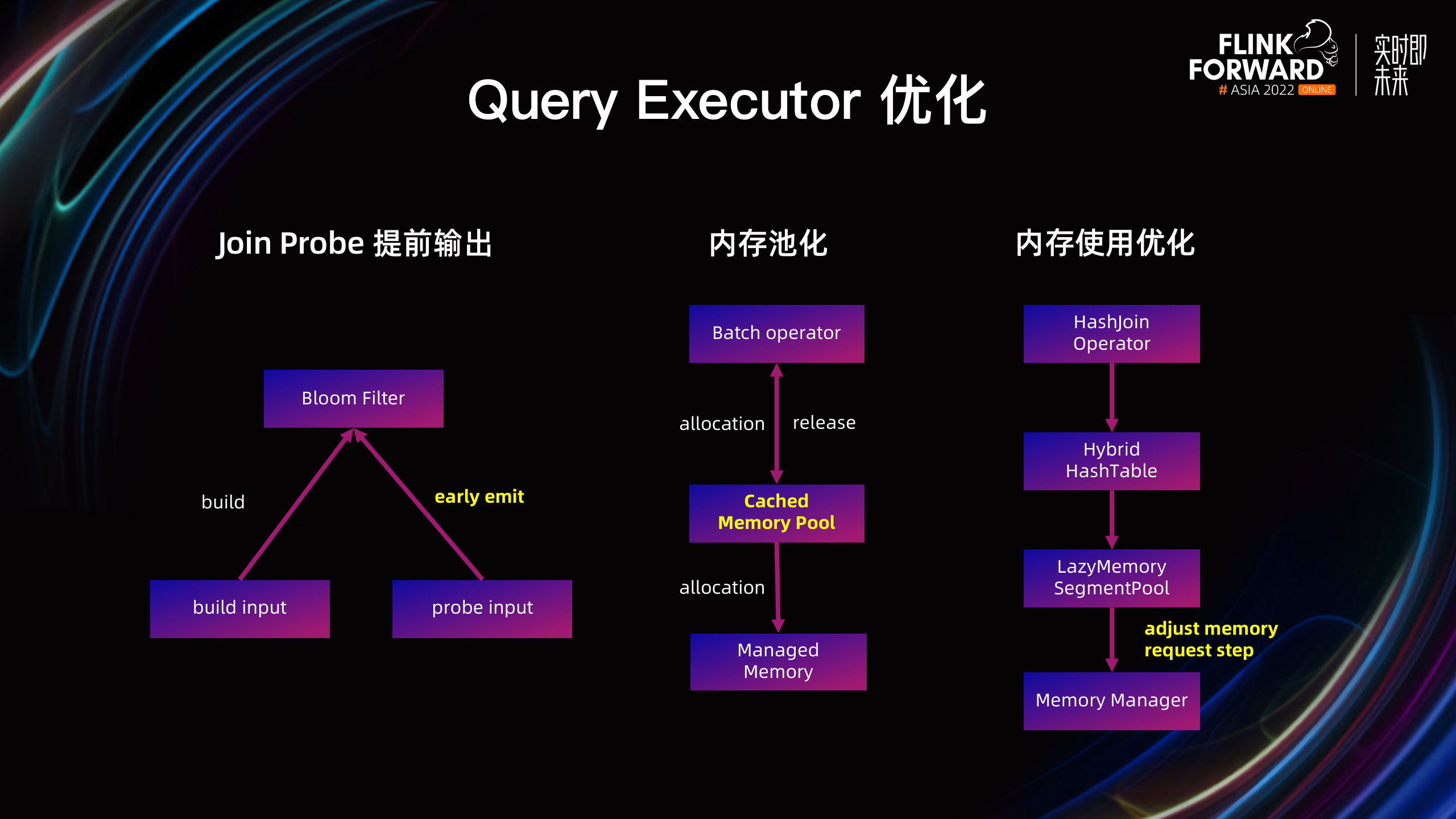
- Join Probe 提前输出:Probe / Full Outer Hash Join 支持在 Probe 阶段,基于 Build 端的 Bloom Filter 提前输出结果,减少 Probe 端数据的落盘,从而提升性能。
- 内存池化:在算子启动的时候,从 Managed Memory 申请内存,并初始化内存分片。在 OLAP 场景下,这部分的时间和资源消耗占比较大,因此支持了 Cached Memory Pool,即在 TM 维度内共享内存池,而不需要在算子启动的时候初始化内存。
- 内存使用优化:在并行执行包含大量 Aggregate / Join 算子的 Query 时,发现即使数据量非常小,TM 的Managed Memory 使用也很高。经过排查,对于需要使用 Managed Memory 的算子,每次申请内存的步长是 16 MB,因此这些算子的每个并发都至少需要申请 16 MB 内存,导致内存的实际利用率很低,因此支持了可配置步长,并设置较小的默认值以节省大量内存。
三、集群运维和稳定性建设
运维体系完善

构建运维发版流程:在进行完善的测试后,使用自动化流水线,对上下游依赖的所有组件统一发版,最后对线上集群进行平滑的升级。
完善测试方式:支持 CI、准确性测试、性能测试、长稳和故障测试。CI 可以及时发现 UT 失败的问题;准确性测试选择 Query 丰富的 TPC-DS 测试集;性能测试主要包括 TPC-H 性能测试和调度 QPS 性能测试;此外,由于在线服务对稳定性要求比较高,因此支持了长稳和故障测试,在服务长时间运行,并注入各种故障场景的情况下,判断集群的状态、测试 Query 的执行结果等是否符合预期。其中故障测试包含了丰富的故障场景,包括异常 SQL,JM / TM 退出和网络故障等,帮助发现内存泄露等问题,提高了服务的稳定性。
平滑升级线上集群:支持 SQL Gateway 滚动升级。具体的实现过程是通过先启动一个新版本的 Flink 集群,再把线上的多个 Gateway 实例逐个滚动地切流到新的集群,实现无感升级,使得服务中断时间从之前的 5 min 降低到接近为 0。同时在滚动切流时,会进行小流量验证,在发现问题后能够快速回滚,降低上线风险。
监控体系完善

监控体系的完善过程中,除了流批的集群监控,比如对 CPU 等资源使用的监控、GC 时间等进程状态的监控外,还增加了细粒度的 CPU 监控,用于明确在短 Query 的情况下,集群是否存在 CPU 瓶颈。与此同时,通过增加查询负载监控,判断业务负载和 Flink 集群的负载是否正常。
在集群监控之外,又增加了 OLAP 下所特有的作业监控,完善了全链路的 Latency,方便快速定位慢查询出现耗时问题的阶段,比如 Parse、Optimize、Job 执行阶段等。此外,还增加了更多的慢查询和失败查询的监控,以及对依赖的外部 IO 的监控等。
稳定性治理

Flink OLAP 作为在线服务对稳定性要求很高,但是在落地初期,由于服务缺乏容灾、JM / TM FGC 频繁等问题,线上稳定性较差。我们分别从 HA、限流、GC 优化和 JM 稳定性提升四个方面进行治理。
- HA:支持双机房热备,提高在线服务的可用性。支持双机房容灾后,可以通过切流快速恢复。其次,通过支持 JM HA,解决 JM 单点的问题,提升线上服务的可用性。
- 限流和熔断:虽然在流式和批式下,没有作业的限流需求,但在 OLAP 场景下,用户会持续提交 Query。为了避免查询高峰集群被打挂,支持了 SQL Gateway 的 QPS 限流。为了避免多作业同时运行导致的 JM 和 TM 的负载过高、查询过慢的问题,我们限制了 Flink 集群最大运行的作业数。除了限流之外,还支持了在 OLAP 下,使用 Failfast 的 Failover 策略,避免失败作业堆积,造成集群雪崩。
- GC 优化:OLAP 场景下,业务对 Latency 非常敏感,Full GC 会导致耗时抖动。因此优化了 JM 和 TM 的 Full GC。首先移除 Task / Operator 级别的 Metric,使 JM 的 Full GC 频率降低 88%。其次,支持 Codegen 缓存优化,使 TM 的 Metaspace Full GC 次数降低为接近 0。
- JM 稳定性提升:在 OLAP 场景下,支持 JobMaster 去除 ZK 依赖,因为在高 QPS 下,ZK 依赖会导致作业的 Latency 抖动。同时限制 Flink UI 展示的作业数,因为在 OLAP 场景下持续提交大量的作业,会使整个 JM 的内存过大,影响 JM 的稳定性。与此同时,关闭 Flink UI 的自动刷新,避免自动刷新导致 JM 负载上升引起页面的卡顿。
四、收益

Benchmark 收益:通过上述对 Query Optimizer 和 Query Executor 的查询优化,在 TPCH 100G 的Benchmark 中,Query Latency 降低了50.1%。其次对三类不同复杂程度的小数据量查询(点查类 Source-Sink、较复杂的 WordCount 和更加复杂的三表 Join),进行了 E2E Benchmark,优化效果非常明显,E2E QPS 平均提升 25 倍,E2E Latency 平均降低 92%,降低了超过 10倍。

业务收益:性能和稳定性都有明显的提高。性能方面,Job 平均 Latency 降低了 48.3%,TM 平均 CPU 降低了27.3%;稳定性方面,JM Full GC 频率降低了 88%,TM Full GC 时间降低了 71.5%。
五、未来规划
- 产品化完善:包括 History Server 的支持和慢查询的智能分析。
- 向量化引擎:充分利用 CPU 的并行化能力,提升计算性能。
- 物化视图:对于大数据量的计算,现查现算的耗时和资源开销都非常大,所以未来考虑引入物化视图加速用户的查询,节省资源使用。
- Optimizer 演进:持续跟进业界和学术界的最新进展,比如基于 Learning-based 实现 SQL Optimization 的 AI4DB 等。
|








- 上一条: 虚拟云网络系列 | Antrea 应用于 VMware 方案功能简介(八) 2023-04-12
- 下一条: Flink OLAP 在字节跳动的查询优化和落地实践 2023-04-12
- Flink OLAP 在资源管理和运行时的优化 2023-03-16
- Flink 在字节跳动数据流的实践 2022-01-11
- 字节跳动流式数据集成基于Flink Checkpoint两阶段提交的实践和优化 2022-03-21
- 字节跳动 Flink 大规模云原生化实践 2023-03-31
- Flink OLAP 助力 ByteHTAP 亮相数据库顶会 VLDB 2022-09-14


