实战干货|Spark 在袋鼠云数栈的深度探索与实践

Spark 是一个快速、通用、可扩展的大数据计算引擎,具有高性能、易用、容错、可以与 Hadoop 生态无缝集成、社区活跃度高等优点。在实际使用中,具有广泛的应用场景:
· 数据清洗和预处理:在大数据分析场景下,数据通常需要进行清洗和预处理操作以确保数据质量和一致性,Spark 提供了丰富的 API,可以对数据进行清洗、过滤、转换等操作
· 批处理分析:Spark 适用于各种应用场景下的批处理任务,包括统计分析、数据挖掘、特征提取等,用户可以利用 Spark 强大的 API 和内置库进行复杂的数据处理和分析,从而挖掘数据中的内在价值
· 交互式查询:Spark 提供了支持 SQL 查询的 Spark SQL 模块,用户可以使用标准的 SQL 语句进行交互式查询和大规模数据分析
Spark 在袋鼠云的使用
在袋鼠云数栈离线开发平台,我们提供了三种使用 Spark 的方式:
● 创建 Spark SQL 任务
用户可以直接通过编写 SQL 的方式实现自己的业务逻辑。这种方式是目前数栈离线平台使用 Spark 最广泛的方式,也是最为推荐的一种方式。
● 创建 Spark Jar 任务
用户需要在 IDEA 上使用 Scala 或者 Java 语言实现业务逻辑,然后对该项目进行编译打包,并将得到的 Jar 包上传到离线平台,随后在创建 Spark Jar 任务的时候引用这个 Jar 包,最后将任务提交到调度运行即可。
对于使用 SQL 难以实现或表达的需求,或者用户有其他更深层次的需求,Spark Jar 任务无疑给用户提供了一种更为灵活的使用 Spark 的方式。
● 创建 PySpark 任务
用户可以直接编写对应的 Python 代码。在我们的客户群体中,有相当一部分客户,他们除了 SQL 之外,Python 可能是他们的主力语言。特别是针对有一定数据分析基础、算法基础的用户,他们往往会对处理好的数据进行更深层的分析,此时 PySpark 任务自然是他们的不二之选。
Spark 在袋鼠云数栈离线开发平台发挥着重要的作用,因此,我们内部对 Spark 做了也不少的优化,使客户在使用 Spark 提交任务时更加方便。我们还基于 Spark 做了一些工具来增强整个数栈离线开发平台的功能。
除此之外,在数据湖场景下,Spark 也发挥着相当重要的作用。在袋鼠云的湖仓一体模块中,已经支持了 Iceberg 和 Hudi 两大数据湖,用户可以使用 Spark 对湖表进行读写,湖表的治理底层也是通过使用 Spark 调用不同的存储过程实现。
下文就将从引擎侧和 Spark 本身两个方面来阐述袋鼠云内部所做的优化。
引擎端优化
袋鼠云内部引擎端的功能主要是用于任务提交、任务状态获取、任务日志获取、停止任务、语法校验等。每个功能点我们都做了不同程度的优化,下文通过两个例子进行简单介绍。
Spark on Yarn 提交速度提升
随着引擎端 Spark 插件上新功能的不断开发和完善,引擎端提交 Spark 任务所需的时间也在相应的增加,因此需要对提交 Spark 任务相关的代码进行优化,以缩短 Spark 任务提交的时长,提升用户体验。
为此,我们做了以下工作,对于一些公用的配置文件,如 core-site.xml、yarn-site.xml、keytab 文件、spark-sql-application.jar 等,原来每次提交任务都需要预先从服务器下载并提交这些配置文件。现在经过优化后,上述文件仅仅需要在客户端 SparkYarnClient 初始化的时候下载一次,然后上传到指定的 HDFS 路径,后续提交 Spark 任务只需要通过参数的方式指定到对应的 HDFS 路径即可。通过这种方式大大缩短了每次 Spark 任务的提交时间。
在新版本的数栈中,对于临时查询,我们还会根据自定义的规则判断待执行 SQL 的复杂度,将复杂度不高的 SQL 发送到引擎端启动的 SparkSQLEngine 运行,以加快运行速度。这个内部的 SparkSQLEngine 在以前仅仅用于语法校验,现在也承担了一部分 SQL 执行的功能,并且 SparkSQLEngine 还可以根据运行的整体情况,动态扩缩资源,实现资源的有效利用。
语法校验
在较老的数栈版本,对于 SQL 进行语法校验,引擎端会先把 SQL 发送到 Spark Thrift Server。这个 Spark Thrift Server 是以 local 模式部署,不仅仅需要用于语法校验,其他平台上所有元数据的获取都是通过发送 SQL 到这个 Spark Thrift Server 执行来获取。这种方式弊端较大,为此我们做了一些优化。在 Engine 端以 local 模式启动了一个 Spark 任务,在进行语法校验的时候不再将 SQL 发送到 Spark Thrift Server,而是内部维护了一个 SparkSession,直接对 SQL 进行语法校验。
这种方式虽然可以不需要再跟外部的 Spark Thrift server 强关联,但是会给调度组件带来一定的压力,在实现的过程中 Engine-Plugins 的整体复杂度也增大了不少。
为了优化以上问题,我们做了更进一步的优化,调度组件在启动的时候,提交了一个 Spark 任务 SparkSQLEngine 到 Yarn 上。可以理解为是一个远程的运行在 Yarn 上的 Spark Thrift Server,引擎端时刻监控这个 SparkSQLEngine 的健康状态。这样,每次执行语法校验的时候,引擎端将 SQL 通过 JDBC 的形式发送给 SparkSQLEngine 进行语法校验。
通过上述的优化,使得离线开发平台与 Spark Thrift Server 解耦合,EasyManager 不需要额外部署 Spark Thrift Server,使部署更轻量化。调度侧也不用维护一个 local 模式的 Spark 常驻进程。也为离线开发平台上 Spark SQL 任务交互式查询增强做铺垫。
离线开发平台与 EasyManager 部署的 Spark Thrift Server 解耦合后会有以下好处:
· 能够真正意义上的实现 Spark 多集群多版本共存
· EasyManager 标准部署可以去除 Spark Thrift Server,为一线运维减负
· Spark SQL 语法校验变得更轻量,不用缓存 SparkContext,减少 Engine 的资源占用
Spark 功能优化
随着业务的发展深入,我们发现开源的 Spark 在一些场景并没有对应的功能实现。因此我们在开源 Spark 的基础上开发了更多新的插件,以支持数栈更多的功能应用。
任务诊断
首先,我们对 Spark 的 metric sink 做了增强。Spark 内部提供了各种 Sink,除了 ConsoleSink 之外,还有 CSVSink、JmxSink、MetricsServlet、GraphiteSink、Slf4jSink、StatsdSink 等。在 Spark3.0 之后还新增了 PrometheusServlet,但这些还不能满足我们的需求。
在开发任务诊断功能的时候,我们需要通过把 Spark 内部的指标统一推送到 PushGateway,由 Prometheus Server 周期性的从 PushGateway 中拉取指标,最后通过调用 Prometheus 提供的查询接口可以近实时地查询到 Spark 内部的指标。

但是 Spark 并没有实现将内部指标 sink 到 PushGateway。因此我们新增了 spark-prometheus-sink 插件,并且自定义了 PrometheusPushGatewaySink 用于将 Spark 内部的指标 push 到 PushGateway。
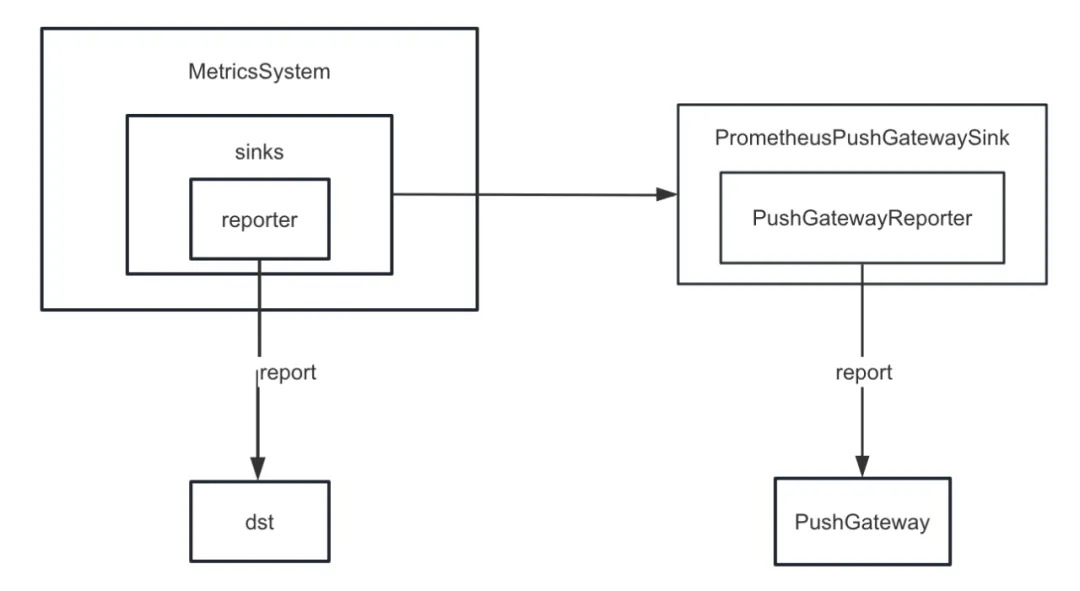
除此之外,我们还自定义了一个新的指标用来描述 Spark SQL 临时查询展示任务执行进度。具体步骤如下:
· 通过自定义 JobProgressSource 来新增用于描述离线任务进度的指标,将该指标注册到 Spark 内部管理系统中的指标管理系统中
· 自定义 JobProgressListener,并将 JobProgressListener 注册到 Spark 内部管理系统中的 ListenerBus。其中,JobProgressListener 的 onJobStart 方法的逻辑是计算当前 Job 下所有的 Task 数量;onTaskEnd 方法的逻辑是在每个 Task 完成后计算并更新当前离线任务进度;onJobEnd 方法的逻辑是在每个 Job 完成后计算并更新当前离线任务进度
对接商业版 Hadoop 集群
随着袋鼠云客户越来越多,客户的环境也是各不相同。有的客户使用的是开源版本的 Hadoop 集群,也有相当一部分客户使用的是 HDP、CDH、CDP、TDH 等。我们在对接这些客户的集群的时候,开发侧往往需要进行新的适配,运维侧每次部署升级的时候也需要配置额外的参数或者有其他额外的操作。
以 HDP 为例,在对接 HDP 的时候,我们使用的 Spark 是 HDP 自带的 Spark2.3,并且我们还需要在运维侧新增一些参数,并将 HDP 自带的 Spark 的所有 Jar包 移动到指定目录。这些操作其实会给运维带来一定的困惑和麻烦,不同类型的集群,运维需要维护不同的运维文档,部署的过程也比较容易出错。并且我们其实对 Spark 的源码做了功能增强和 bug 的修复,如果使用的是 HDP 自带的 Spark,那么就享受不到我们内部维护的 Spark 带来的所有好处。
为了解决上面这些问题,我们内部的 Spark 对现有市场上已有的、常见的发行商都做了适配。换句话来说,我们内部的 Spark 可以在所有不同的 Hadoop 集群上运行。这样,无论对接哪一种类型的 Hadoop 集群,运维只需要部署同一个 Spark 即可,这大大减轻了运维部署的压力。更重要的是,客户可以直接使用我们内部的 Spark 稳定版本,享受到更多的新特性和更大的性能提升。
Spark3.2 新特性-AQE
较老的数栈版本中,默认的 Spark 版本是 2.1.3,后来我们将 Spark 的版本升级到 2.4.8,从数栈6.0开始,Spark3.2 也可以使用了。这里着重介绍一下 AQE,这也是 Spark3.x 中最重要的新特性。
AQE 概述
Spark3.2 之前,AQE 默认是关闭的,需要通过将 spark.sql.adaptive.enabled 设置为 true,才能开启 AQE。Spark3.2 之后,AQE 默认是开启的,任务在运行过程中只要满足 AQE 的触发条件,即可享受 AQE 带来的优化。
需要注意的是,AQE 的优化只会发生在 shuffle 阶段,如果 SQL 在运行过程中并没有涉及到 shuffle 操作,那么即使 spark.sql.adaptive.enabled 的值为 true,AQE 也不会发挥作用。更准确来说,只有物理执行计划包含 exchange 节点或者包含子查询,AQE 才会生效。
AQE 在运行期间,会收集 shuffle map 阶段所生成的中间文件的信息,并将这些信息进行统计,结合已有的规则动态的调整尚未执行的 Optimized Logical Plan 和 Spark Plan,从而对原来的 SQL 语句进行运行时优化。
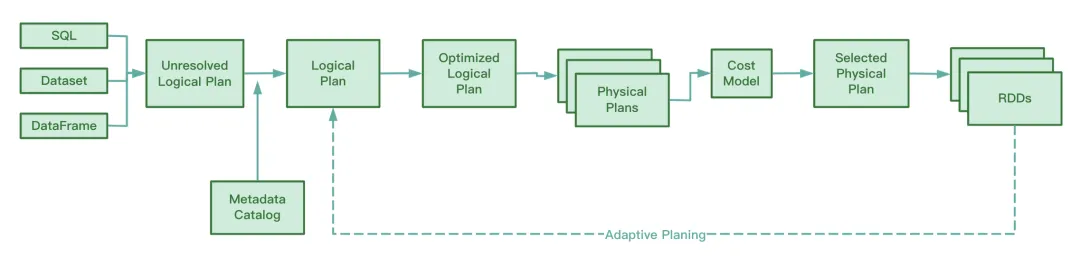
从 Spark 源码来看,AQE 涉及到以下4个优化规则:
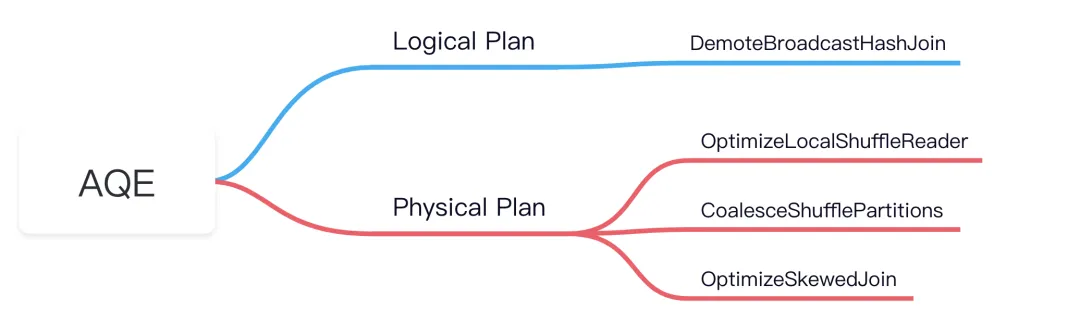
我们知道,RBO 是根据一系列的规则(rule)来对 SQL 进行优化,包括谓词下推、列剪枝、常量替换等。这些静态规则本身已经内置在 Spark 中,Spark 在执行 SQL 的过程中,这些 rule 会一一作用到 SQL 中。
AQE 的优势
CBO 这个特性是 Spark2.2 之后才有的,相比于 RBO,CBO 会结合表的统计信息,并根据这些统计信息和代价模型(Cost Model)选择出较为优化的执行计划。
但是,CBO 仅仅支持注册到 Hive Metastore 的表。对于存储在分布式文件系统的 parquet、orc 等文件,CBO 是不支持的。并且,如果 Hive 表缺少元数据信息,CBO 收集统计信息的时候就会收集不到,这可能会导致 CBO 失效。
CBO 的另外一个劣势在于 CBO 在优化之前需要先执行 ANALYZE TABLE COMPUTE STATISTICS 来收集统计信息。该语句在执行过程中如果碰到大表则会较为耗时,收集效率较低。
无论是 CBO 还是 RBO,它们都属于静态优化。在物理执行计划提交后,如果任务在运行过程中,数据量、数据分布情况发生变化,CBO 也不会对已有的物理执行计划进行优化。
与 CBO、RBO 不同的是,AQE 在运行过程中,会对 shuffle map 过程中所产生的中间文件进行分析,动态的调整并优化尚未开始执行的逻辑执行计划和物理执行计划,相对静态优化的 CBO 和 RBO 而言,AQE 的处理能得到更加优化的物理执行计划。
AQE 三大特性
● 自动分区合并
Shuffle 过程分为 Map 阶段和 Reduce 两个阶段,Reduce 阶段会将 Map 阶段产生的中间临时文件拉取到对应的 Executor 下,如果 Map 阶段所处理的数据分布非常不均匀,有很多 key 其实仅仅只有几条数据,数据经过处理后可能会形成比较多的小文件。
为了避免上述情况,可以开启 AQE 的自动分区合并功能,可以避免启动过多的 reduce task 去拉取 Map 阶段生成的小文件。
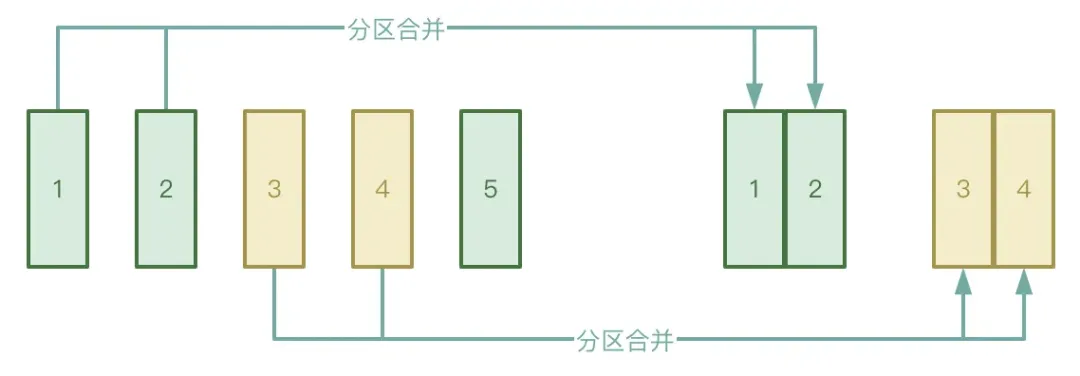
● 自动数据倾斜处理
应用场景主要在 Data Joins 中,当发生数据倾斜,AQE 能够自动检测到倾斜分区,并对倾斜分区按照一定的规则进行拆分。目前,在 Spark3.2 中,对 SortMergeJoin 和 ShuffleHashJoin 都支持自动数据倾斜处理。
● Join 策略调整
AQE 会动态的将 Hash Join、Sort Merge Join,降级调整为 Broadcast Join。
我们知道,Spark 任务一旦开始执行,并行度就已经确定。比如说,shuffle map 阶段,并行度为分区的个数;shuffle reduce 阶段并行度则为 spark.sql.shuffle.partitions 的值,默认为200。如果 Spark 任务在运行的过程中数据量变小导致大部分的分区的大小变小,这时如果仍然启动那么多的线程去处理小的数据集就会导致资源的浪费。
而 AQE 在执行过程会根据 shuffle 后生成的中间临时结果,在一定条件下,通过应用 CoalesceShufflePartitions 规则,结合用户提供的参数自动合并分区,其实就是调整 reducer 的数量。原来一个 reduce 线程只会拉取一个处理后的分区的数据,现在一个 reduce 线程会根据实际情况拉取更多的分区的数据,这样就能减少资源的浪费,提高任务执行效率。 《行业指标体系白皮书》下载地址:https://www.dtstack.com/resources/1057?src=szsm
《数栈产品白皮书》下载地址:https://www.dtstack.com/resources/1004?src=szsm
《数据治理行业实践白皮书》下载地址:https://www.dtstack.com/resources/1001?src=szsm
想了解或咨询更多有关大数据产品、行业解决方案、客户案例的朋友,浏览袋鼠云官网:https://www.dtstack.com/?src=szkyzg
|








- 上一条: 什么是IPD项目管理模式?聊聊IPD下的产品研发流程 2024-04-26
- 下一条: 实战干货|Spark 在袋鼠云数栈的深度探索与实践 2024-04-26
- 实战讲解|Trino 在袋鼠云数栈的探索与实践 2024-01-19
- 袋鼠云数栈基于CBO在Spark SQL优化上的探索 2022-06-10
- Spark SQL知识点大全与实战 2021-11-26
- 干货分享|袋鼠云数栈离线开发平台在小文件治理上的探索实践之路 2023-03-29
- 性能提升30%!袋鼠云数栈基于 Apache Hudi 的性能优化实战解析 2023-06-21

