提示词优化的自动化探索:Automated Prompt Engineering

编者按: 作者在尝试教授母亲使用 LLM 完成工作任务时,意识到提示词的优化并不像想象中简单。提示词的自动优化对于经验并不丰富的提示词撰写者很有价值,他们没有足够的经验去调整和改进提供给模型的提示词,这引发了对自动化提示词优化工具的进一步探索。
本文作者从两个角度分析了提示词工程的本质 —— 可将其视为超参数优化的一部分,也可将其视为一个需要不断尝试和调整的摸索、试错、修正过程。
作者认为,对于拥有比较明确的模型输入和输出的任务,比如解数学题、情感分类、生成SQL语句等。作者认为这种情况下的提示词工程更像是在优化一个"参数",就像机器学习里调节超参数一样。我们可以通过自动化的方法,不断尝试不同的提示词,看哪个效果最好。而对于相对比较主观和模糊的任务,比如写作邮件、诗歌、文章摘要等。因为没有非黑即白的标准来评判输出是否"正确",所以提示词的优化就不能简单机械地进行。
The original article link: https://towardsdatascience.com/automated-prompt-engineering-78678c6371b9
LinkedIn profile link: https://linkedin.com/in/ianhojy
Medium profile link for subscriptions: https://ianhojy.medium.com/
作者 | Ian Ho
编译 | 岳扬
在过去的几个月里,我一直都在尝试构建各种 LLM-powered apps。说实话,我有相当一部分时间都是在改进 Prompt ,以便从 LLM 那里获得我想要的输出结果。
有很多时候我都陷入于虚无和困惑中,问自己是否只是一名被美化的提示词工程师(glorified prompt engineer)。鉴于当前人类与 LLM(大语言模型)互动的现状,我仍倾向于给出“还没有”的结论,而且在大多数夜晚,我都能克服自己的 imposter syndrome。(译者注:是一种心理现象,指的是个体对自己的成就和能力持怀疑态度,常常觉得自己是一个骗子,认为自己并不配拥有或达到所取得的成就,担心被揭穿。)目前暂时不深入讨论这个问题。
但我还是经常在想,是否有一天,撰写 Prompt 的过程可以基本实现自动化。如何回答这个问题,关键在于能否搞清楚提示词工程(prompt engineering)的真正本质。
尽管浩瀚的互联网上有无数的提示词工程实践手册(prompt engineering playbooks),但我仍然无法确定提示词工程(prompt engineering)是一门艺术还是一门科学。
一方面,当我必须根据从模型输出中观察到的结果反复学习再润色我编写的 Prompt 时,感觉这像是一门艺术。随着时间的推移,我发现一些微小的细节也非常重要 —— 比如使用“must(必须)”而不是“should(应该)”,或者将 guidelines (译者注:提示词中的一些指导性的建议或规范)放在提示词的末尾而不是中间。根据任务的不同,人们可以有太多的方式来表达一系列 instructions (译者注:具体的操作指示)和 guidelines(译者注:一般性的规范建议),有时感觉就像是在不断地尝试和犯错。
另一方面,也有人可能会认为提示词只是一种超参数(hyper-parameters)。归根结底,LLM(大语言模型)其实只把我们编写的提示词看作是嵌入向量(embeddings),就像所有超参数一样。 如果我们有一组已经准备好并且被认可的用于训练和测试机器学习模型的数据集,就可以对提示词进行调整并客观地评估其性能。最近我看到了 HuggingFace 的 ML 工程师 Moritz Laurer[1] 的一篇帖子:
Every time you test a different prompt on your data, you become less sure if the LLM actually generalizes to unseen data… Using a separate validation split to tune the main hyperparameter of LLMs (the prompt) is just as important as train-val-test splitting for fine-tuning. The only difference is that you don’t have a training dataset anymore and it somehow feels different because there is no training / no parameter updates. Its easy to trick yourself into believing that an LLM performs well on your task, while you’ve actually overfit the prompt on your data. Every good “zeroshot” paper should clarify that they used a validation split for finding their prompt before final testing.
当我们在这些数据集上测试越来越多不同的提示词(Prompt)后,会越来越不确定 LLM 是否真的对未见过的数据具有泛化能力... 将数据集中的一部分单独设置为验证集来调整 LLM 的主要超参数(Prompt)和使用 train-val-test splitting(译者注:将可用数据集划分为三个部分:训练集、验证集和测试集。) 方法来进行微调一样重要。唯一不同的是,这种过程不涉及训练模型(no training)或更新模型参数(no parameter updates),而是仅仅是在验证集上评估不同提示词的性能。这很容易欺骗自己,让自己相信 LLM 在目标任务上表现出色,而实际上可能经过调整的提示词在目前这个数据集上表现得非常好,但在更广泛或未见过的数据集上可能不适用。每篇优秀的“零样本(zeroshot)”论文都应该说明清楚他们在最终测试之前使用了验证集来帮助寻找最优秀的Prompt。
经过一番思考,我认为答案介于两者之间。提示词工程(prompt engineering)到底是科学还是艺术,取决于我们想让 LLM 做什么。在过去的一年里,我们看到 LLM 做出了许多令人惊叹的事情,但我倾向于将大家使用大模型的意图归类为两大类:解决问题(solving)和完成创造性的任务(creating)。
在解决问题(solving)这方面,我们让 LLM 解决数学问题、对情感进行分类、生成 SQL 语句、翻译文本,等等,不一而足。一般来说,我认为这些任务都可以归为一类,因为它们可以具有相对明确的input-output pairs(译者注:输入数据与相应的模型输出数据之间的关联关系)(因此,我们可以看到许多案例仅使用少量 Prompt 即可很好地完成目标任务)。对于这类具有 well-defined training data(译者注:训练数据集中输入和输出之间的关系是清晰明确的) 的任务,提示词工程(prompt engineering)在我看来更像是一门科学。因此,本文的前半部分将从把 Prompt 看作超参数的角度进行探讨,专门探讨 automated prompt engineering(译者注:使用自动化方法或技术来设计、优化和调整提示词) 的研究进展。
在创造性任务(creating)方面,要求 LLM 完成的任务更加主观和模糊(subjective and ambiguous)。写邮件、报告、诗歌、摘要。也正是在这一领域,我们遇到了更多模糊不清的问题 —— ChatGPT 写作的内容是否缺乏人情味?(根据我让它写过的成千上万篇文章,我目前的看法是肯定的)而且,由于我们往往缺乏一个更客观的标准来说明我们希望 LLM 如何回应,因此创造性任务的性质和需求通常不太适合将提示词看作是可以像超参数一样进行调整和优化的参数。
说到这里,有些人可能会说,对于创造性任务,我们只需要运用常识就可以了。说实话,我曾经也是这样想的,直到我尝试着教我的母亲如何使用 ChatGPT 来帮助她生成工作邮件。在这些情况下,由于提示词工程(prompt engineering)仍然主要是通过不断的试验和调整来进行改进,而非一次性完成的,如何将自己的想法用于改进 Prompt ,并仍保留 Prompt 的通用性(如前文引述内容所说),并不总是一目了然的。
总之,我四处寻找能够根据用户对大模型生成示例的反馈自动改进提示词(Prompt)的工具,但一无所获。因此,我建立了一个这类工具的原型(prototype),探索是否存在可行的解决方案。在本文的后半部分,将与大家分享我试验的这款工具,它可以根据实时用户反馈自动改进提示词。
01 第一部分 —— LLMs as Solvers:将 Prompt Engineering 视为超参数优化的一部分
业内很多人都熟悉《Large Language Models are Zero-Shot Reasoners》[2]一文中著名的 "Zero-Shot-COT" 术语(译者注:模型在没有学习过针对特定任务的显式训练数据的情况下,通过组合已有的知识来解决新的问题)。Zhou 等人(2022 年)决定在《Large Language Models are Human-Level Prompt Engineers》[3] 一文中更进一步探讨其改进版本是什么? —— "Let’s work this out in a step by step way to be sure we have the right answer"。以下是他们提出的 Automatic Prompt Engineer 方法的相关内容概述:

Source: Large Language Models are Human-Level Prompt Engineers[3]
总结一下这篇论文:
- 使用 LLM 根据给定的 input-output pairs(译者注:输入数据与相应的模型输出数据之间的关联关系) 生成候选的指导性提示词。
- 使用 LLM 为每个指导性提示词评分,可以根据使用该指导性提示词(instruction)生成的答案与期望答案的匹配程度进行评估,也可以根据通过该指导性提示词(instruction)获得的模型响应的对数概率来进行评估。
- 根据高评分的候选指导性提示词(instruction)迭代生成新的候选指导性提示词。
发现了一些有趣的结论:
- 除证明了(人类)提示词工程师(human prompt engineers)和之前提出的算法性能更优之外,作者指出:“与直觉相反,在上下文中添加示例会损害模型性能......因为所选的指导性提示词(instruction)过度拟合了零样本学习(zero-shot learning)场景,因此在小样本(few-shot)的情况下表现不佳” 。
- 迭代的蒙特卡洛搜索算法(Monte Carlo Search)在大多数情况下其效果会逐渐减弱,但当 original proposal space (译者注:可能指的是在蒙特卡洛搜索算法中,最初用来生成候选解的初始范围或方案。)不够合适或不够有效时,却会表现良好。
随后在 2023 年, Google DeepMind 的一些研究人员推出了一种名为 “Optimisation by Prompting (OPRO) ” 的方法。与之前的例子相似,meta-prompt(译者注:用来帮助构建或生成用户需要的提示词的 Prompt )中包含一系列 input/output pairs (译者注:描述特定任务或问题的输入和期望输出组合)。这里的关键区别在于,meta-prompt 还包含了之前训练过的提示词样本及其正确的解答或解决方案和模型对这些提示词的解答准确率是多少,以及详细说明 meta-prompt 不同部分之间关系的指导性提示词。
正如作者解释的那样,研究工作中的每一次提示词优化步骤都会生成新的提示词,旨在参考之前的学习轨迹,让模型可以更好地理解当前任务,从而产生更准确的输出结果。
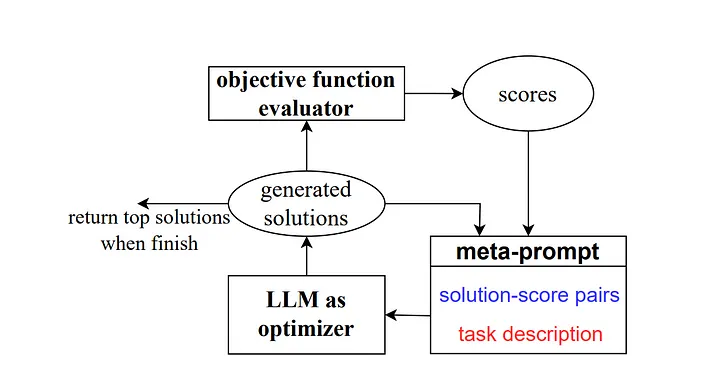
Source: Large Language Models as Optimizers[4]
针对 Zero-Shot-COT 这种场景,他们提出了 “Take a deep breath and work on this problem step-by-step” 这种提示词优化方法,并取得了很好的效果。
对此,我有几点想法:
- “不同类型的语言模型生成的指导性提示词(instructions)风格差异很大。一些模型,如 PaLM 2-L-IT 和 text-bison 生成的指导性提示词非常简洁明了,而另一些如 GPT 的指令则冗长又相当详细。”这一点值得我们引起重视。目前市面上许多提示词工程(prompt engineering)的玩法都是以 OpenAI 的语言模型为参考对象编写的,但随着越来越多不同来源的模型开始被使用,我们应当注意,这些通用的提示词工程指南可能并不那么管用。论文 5.2.3 节中就给出了一个例子,展示了模型性能对指导性提示词(instructions)对微小变化的高度敏感性。我们需要更多关注这一点。
例如,在 GSM8K 测试集上使用 PaLM 2-L 评估模型时,“Let’s think step by step.” 的准确率达到了71.8%,“Let’s solve the problem together.”的准确率为60.5%,而前两个指导性提示词(instructions)的语义组合,“Let’s work together to solve this problem step by step.”的准确率仅为49.4%。
这种行为既增加了单步指导性提示词(single-step instructions)之间的差异,也增加了优化过程中出现的波动,促使我们在每个步骤生成多个指导性提示词(single-step instructions),以提高优化过程的稳定性。
论文的结语中还提到了另一个要点:“我们目前将算法应用于实际问题中的一个局限是,用于优化提示词的大语言模型,未能有效地利用训练集中的错误案例来推断有希望的提示词改进方向。在实验中,我们尝试在 meta-prompt 中加入模型在训练或测试时出现的错误案例,而非在每个优化步骤中从训练集中随机抽样,但结果大同小异,这表明仅凭这些错误案例的信息量不足以让 optimizer LLM(用于优化提示词的大语言模型) 了解产生错误预测的原因。” 这一点确实值得强调,因为尽管这些方法有力地证明了提示词的优化过程与传统 ML/AI 中的超参数优化过程类似,但我们往往会偏向于使用正面、积极的例子,无论是我们想要向 LLM 提供什么样的内容输入,还是我们如何指导 LLM 改进提示词。然而,在传统的 ML/AI 中,这种偏好通常没有这么明显,我们更注重如何利用错误的信息来优化模型,而非过多关注错误本身的方向或类型(即我们对 -5 和 +5 的误差大多一视同仁)。
如果你对 APE(Automated Prompt Engineering)感兴趣,可以前往https://github.com/keirp/automatic_prompt_engineer 下载使用。
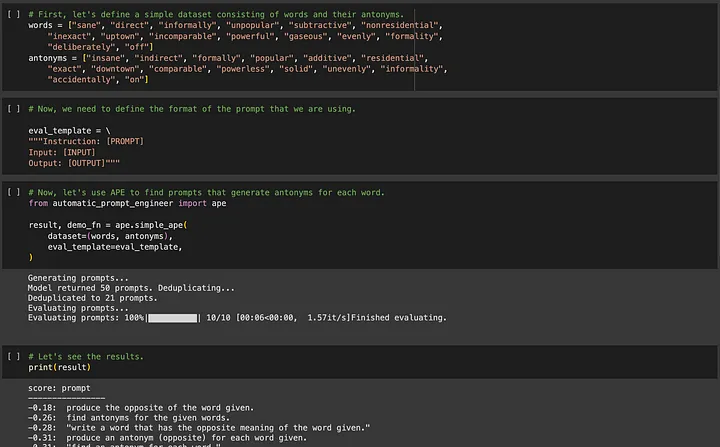
Source: Screenshot from Example Notebook for APE[5]
在 APE 和 OPRO 这两种方法中都有一个关键要求,需要有训练数据来帮助优化,并且数据集需要足够大,以确保经过优化的提示词的通用性。
现在,我想谈谈另一类 LLM 任务,在这类任务中,我们可能没有现成的数据。
02 第 2 部分 —— LLMs as Creators:将 Prompt Engineering 视为不断尝试和调整逐步、改进的过程
假如我们现在要构思一些短篇小说。
而我们根本没有小说文本示例来训练模型,并且编写一些合格的小说文本示例需要的时间又太长。此外,我并不清楚让大模型输出一个“所谓正确”的回答是否有意义,因为可能有很多种模型输出都是可以接受的。因此,对于这类任务来说,使用 APE 等方法实现提示词工程的自动化几乎是不切实际的。
但是,有些读者可能会有疑问,为什么我们甚至需要将写提示词的过程自动化呢?可以从任意一个简单的提示词开始调整,比如 “provide me with 3 short story ideas about {{issue}} in {{country}}” ,将 {{issue}} 用 “inequality” 填充,将 {{country}} 替换为 “Singapore” ,观察模型响应结果,发现问题,调整提示词,再观察此次调整是否有效,反复执行这个流程。
但在这种情况下,谁能从提示词工程中获益最多呢?恰恰是那些经验并不丰富的提示词编写初学者,他们没有足够的经验去调整和改进提供给模型的提示词。我在教妈妈使用 ChatGPT 完成工作任务时,就亲身体会了这一点。
我妈可能不太擅长把她对 ChatGPT 输出内容的不满转化为对提示词的进一步改进,但我意识到,无论我们的提示词工程技术如何,我们真正擅长的是表达我们所看到的问题(即抱怨)的能力。因此,我尝试构建了一个工具来帮助用户表达他们的抱怨,并让 LLM 为我们改进提示词。对我来说,这似乎是一种更自然的交互方式,似乎让我们这些尝试使用 LLM 完成创造性任务的人能够更加轻松自如。
需要提前声明一下,这只是一个概念验证(proof-of-concept),所以如果读者有任何好主意,都可以随时与作者分享!
首先,编写带有 {{}} 变量的提示词。该工具将检测到这些占位符,供我们后续填写,在此还是使用上文的这个样例,要求大模型输出一些关于新加坡不平等现象的创意故事。
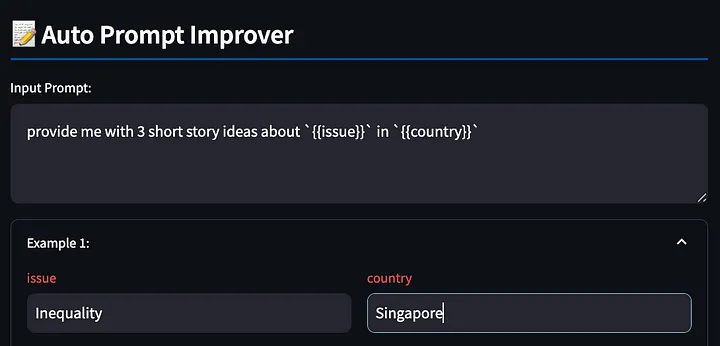
接下来,该工具会根据填写的提示词生成模型响应。

然后给出我们的反馈意见(想对模型输出表达的抱怨):
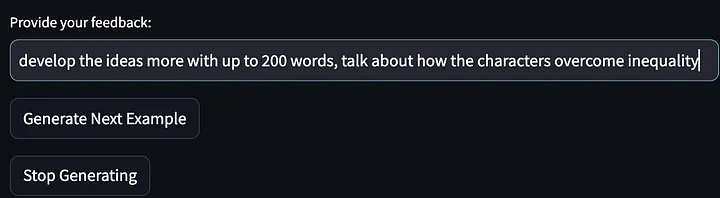
然后要求模型停止生成更多的故事创意示例,并输出第一次迭代改进的提示词。请注意,下文给出的提示词经过了改进并泛化了,要求 "描述克服或应对这些挑战的相关策略....(describe the strategies…to overcome or engage with these challenges)"。而我对第一次模型输出的反馈意见是 "谈谈故事主角是如何解决不平等现象的"。

然后,我们使用改进后的提示词,要求大模型再次构思短篇小说。
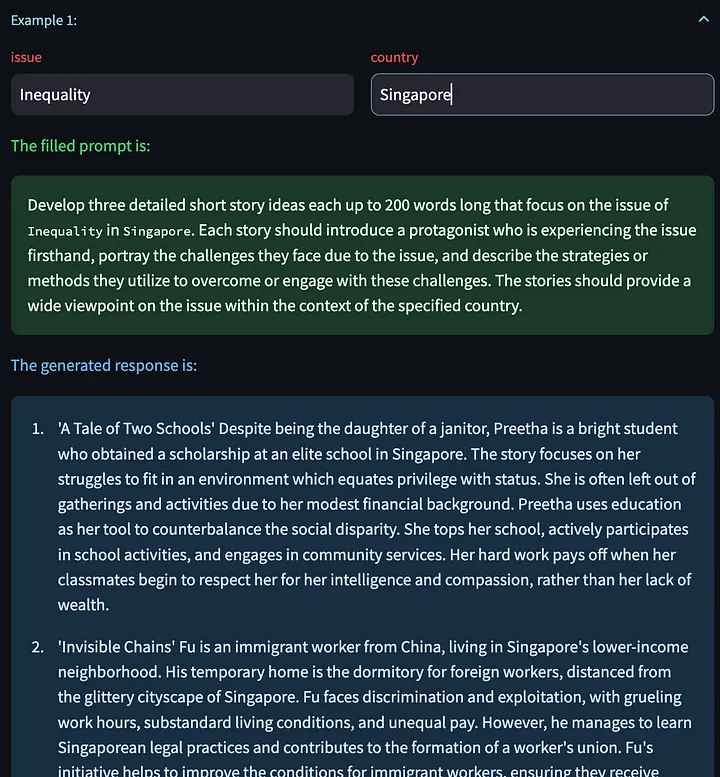
我们也可以选择点击““Generate Next Example”,可以让我们基于其他输入变量生成新的模型响应。下面是生成的一些关于中国裁员问题的创意故事:

然后对上述模型输出给出反馈:
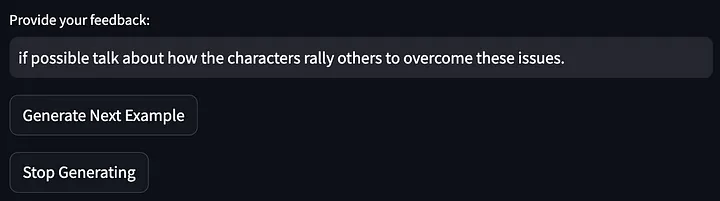
然后,对提示词进行了进一步的优化:

这次的优化结果看起来还不错,毕竟最初这只是一句简单的提示词,经过不到两分钟(虽然有些随意)的反馈,经过三次迭代后得到了这个优化后的提示词。现在,我们只需坐下来对 LLM 的输出结果表达不满,就能持续对提示词进行优化。
这个功能的内部实现方式就是从 meta-prompt 开始,不断根据用户的动态反馈优化生成新的提示词。没有什么花里胡哨的东西,肯定还有进一步改进的空间,但已经是一个不错的开端了。
prompt_improvement_prompt = """
# Context #
You are given an original prompt.
The original prompt was used to generate some example responses. For each response, feedback was provided on how to improve the desired response.
Your task is to review all the feedback and then return an improved prompt that addresses the feedback, making it better at generating responses when prompted against the GPT language model.
# Guidelines #
- The original prompt will contain placeholders within double curly brackets. These are values for input that you will see in the examples.
- The improved prompt should not exceed 200 words
- Just return the improved prompt and nothing else before and after. Remember to include the same placeholders with double curly brackets.
- When generating the improved prompt, refrain from writing the entire prompt as one paragraph. Instead, you should use a combination of task descriptions, guidelines (in point form), and other sections to the prompt as appropriate.
- The guidelines should be in point form, and should not be a repetition of the task. The guidelines should also be distinct from one another.
- The improved prompt should be written in normal English that is best understood by the language model.
- Based on the feedback provided, you must rephrase the desired behavior of the response into `must`, imperative statements, instead of `should` suggestive statements.
- Improvements made to the prompt should not be overly specific to one single example.
# Details #
The original prompt is:
```
{original_prompt}
```
These are the examples that were provided and the feedback for each:
```
{examples}
```
The improved prompt is:
```
"""
使用该工具过程中得到的一些观察:
- GPT4 在生成文本时倾向于使用大量词语(“多言”特性)。因为这个原因,可能存在两点影响。首先,这种"多言"特性可能会助长对特定示例的过拟合。** 如果给 LLM 提供过多词汇,它就会利用这些词汇来修正用户做出的具体反馈。其次,这种"多言"特性可能会损害提示词的有效性,特别是在冗长的提示词中,一些重要的指导性信息可能会被掩盖。 我认为第一个问题可以通过写好 meta-prompts 来解决,以促使模型根据用户反馈实现泛化。但是第二个问题比较棘手,在其他使用案例中,当提示词过长时指导性 Prompt 往往会被忽略。我们可以在 meta-prompt 中添加一些限制条件(例如上文提供的 prompt 样例那样对字数进行限制) ,但这确实比较随意,而且提示词中的某些限制或规则可能会受到底层大模型的特定属性或行为的影响。
- 改进后的提示词有时会忘记之前对提示词所进行的优化。 解决这一问题的一种方法是向系统提供更长的改进历史记录,但这样做会导致改进的提示词变得过于冗长。
- 这种方法在初次迭代中的一个优势是,LLM 可能会提供不属于用户反馈内容的改进指南。 例如,在上文的第一词优化时,该工具添加了“对所讨论的问题提供更广阔的视角......(Provide a broader perspective on the discussed issue…)”,即使我提供的反馈只是要求提供拥有可靠来源的相关统计数据。
我还没有部署这个工具,因为我仍在研究 meta-prompt ,看看哪种方法效果最好,并解决一些 streamlit 框架存在的问题,然后处理程序中可能出现的其他错误或异常。但该工具应该很快就会上线了!
03 In Conclusion
整个提示词工程(prompt engineering)领域都专注于为解决任务提供最佳的提示词。APE 和 OPRO 是该领域中最为重要、最为优秀的例子,但并不代表全部,对未来我们能够在该领域取得多大进步感到兴奋和期待。评估这些技术在不同模型上的效果,可以揭示这些模型的工作倾向或工作特点,也能帮助我们了解哪种 meta-prompt 技术是有效的,因此我认为这些都是非常重要的工作,有助于我们在生活生产实践中使用 LLM。
但是,对于希望将 LLM 用于完成创造性任务的其他人来说,这些方法可能并不适用。就目前而言,现有的很多学习手册都可以可以带领我们入门,但没有什么能胜过反复不断地尝试和试验。因此,在短期内,我认为最有价值的是我们如何高效地完成这个符合我们人类优势的实验过程(给予反馈),并让 LLM 完成剩下的工作(改进提示词)。
我也会在我的 POC(Proof of Concept) 上多下功夫,如果你对此感兴趣,欢迎联系我(https://www.linkedin.com/in/ianhojy/) !
Thanks for reading!
END
参考资料
[1]https://www.linkedin.com/in/moritz-laurer/?originalSubdomain=de
[2]https://arxiv.org/pdf/2205.11916.pdf
[3]https://arxiv.org/pdf/2211.01910.pdf
[4]https://arxiv.org/pdf/2309.03409.pdf
[5]https://github.com/keirp/automatic_prompt_engineer
[6]https://arxiv.org/abs/2104.08691
[7]https://medium.com/mantisnlp/automatic-prompt-engineering-part-i-main-concepts-73f94846cacb
[8]https://www.promptingguide.ai/techniques/ape
本文经原作者授权,由 Baihai IDP 编译。如需转载译文,请联系获取授权。
原文链接:
https://towardsdatascience.com/automated-prompt-engineering-78678c6371b9
|








- 上一条: 提示词优化的自动化探索:Automated Prompt Engineering 2024-04-25
- 下一条: 没有了
- 如何写好大模型提示词?来自大赛冠军的经验分享(进阶篇) 2024-01-22
- AI Native工程化:百度App AI互动技术实践 2023-12-22
- iOS自动化测试驱动工具探索 2022-03-02
- 你真的会写 Prompt ? 剖析 RAG 应用中的指代消解 2023-12-20
- BeautifulPrompt:PAI推出自研Prompt美化器,赋能AIGC一键出美图 2023-06-13

