Laplace分布算子开发经验分享
摘要:Laplace 用于 Laplace 分布的概率统计与随机采样。
本文分享自华为云社区《Laplace分布算子开发经验分享》,作者:李长安。
1、任务解析
详细描述:
Laplace 用于 Laplace 分布的概率统计与随机采样, 此任务的目标是在 Paddle 框架中,基于现有概率分布方案进行扩展,新增 Laplace API,调用路径为:paddle.distribution.Laplace 。类签名及各个方法签名,请通过调研 Paddle 及业界实现惯例进行设计。要求代码风格及设计思路与已有概率分布保持一致。
实际上说了一大堆,就是一件事:实现Laplace分布算子,那么首先我们需要知道什么是 Laplace 分布,在概率论和统计学中,拉普拉斯分布是一种连续概率分布。由于它可以看作是两个不同位置的指数分布背靠背拼在一起,所以它也叫双指数分布。与正态分布对比,正态分布是用相对于μ平均值的差的平方来表示,而拉普拉斯概率密度用相对于差的绝对值来表示。如下面的代码所示,Laplace 分布的图像和正态分布实际上是有点类似的,所以它的公式也与正态分布的公式类似的。
%matplotlib inline
import matplotlib.pyplot as plt
import numpy as np
def laplace_function(x, lambda_):
return (1/(2*lambda_)) * np.e**(-1*(np.abs(x)/lambda_))
x = np.linspace(-5,5,10000)
y1 = [laplace_function(x_,1) for x_ in x]
y2 = [laplace_function(x_,2) for x_ in x]
y3 = [laplace_function(x_,0.5) for x_ in x]
plt.plot(x, y1, color='r', label="lambda:1")
plt.plot(x, y2, color='g', label="lambda:2")
plt.plot(x, y3, color='b', label="lambda:0.5")
plt.title("Laplace distribution")
plt.legend()
plt.show()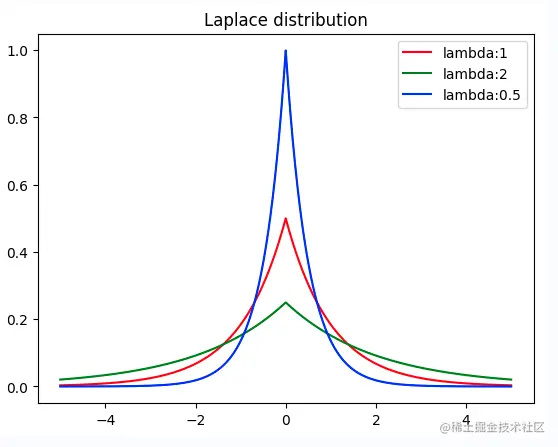
2、设计文档撰写
设计文档是我们API设计思路的体现,是整个开发工作中必要的部分。通过上述任务简介,我们可以知道此API的开发主要为Laplace分布的开发,需要包含一些相应的方法。首先我们需要弄清楚Laplace分布的数学原理,这里建议去维基百科查看Laplace分布的数学原理,弄明白数学原理。此外,我们可以参考Numpy、Scipy、Pytorch、Tensorflow的代码实现,进行设计文档的撰写。
首先,我们应该知道Laplace分布的概率密度函数公式、累积分布函数、逆累积分布函数,并且根据公式开发出代码,公式如下所示:
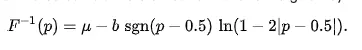

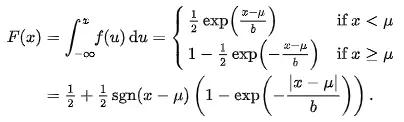
参考Numpy、Scipy、Pytorch、Tensorflow的代码实现,我们这里可以很容易的实现公式对应的代码,其实现方案如下3.1小节所示。
2.1 API 实现方案
该 API 实现于 paddle.distribution.Laplace。
基于paddle.distribution API基类进行开发。
class API 中的具体实现(部分方法已完成开发,故直接使用源代码),该api有两个参数:位置参数self.loc, 尺度参数self.scale。包含以下方法:
- mean 计算均值:
self.loc- stddev 计算标准差:
(2 ** 0.5) * self.scale;- variance 计算方差:
self.stddev.pow(2)- sample 随机采样(参考pytorch复用重参数化采样结果):
self.rsample(shape)- rsample 重参数化采样:
self.loc - self.scale * u.sign() * paddle.log1p(-u.abs())其中 u = paddle.uniform(shape=shape, min=eps - 1, max=1); eps根据dtype决定;
- prob 概率密度(包含传参value):
self.log_prob(value).exp()直接继承父类实现
- log_prob 对数概率密度(value):
-paddle.log(2 * self.scale) - paddle.abs(value - self.loc) / self.scale- entropy 熵计算:
1 + paddle.log(2 * self.scale)- cdf 累积分布函数(value):
0.5 - 0.5 * (value - self.loc).sign() * paddle.expm1(-(value - self.loc).abs() / self.scale)- icdf 逆累积分布函数(value):
self.loc - self.scale * (value - 0.5).sign() * paddle.log1p(-2 * (value - 0.5).abs())- kl_divergence 两个Laplace分布之间的kl散度(other–Laplace类的一个实例):
(self.scale * paddle.exp(paddle.abs(self.loc - other.loc) / self.scale) + paddle.abs(self.loc - other.loc)) / other.scale + paddle.log(other.scale / self.scale) - 1参考文献:https://openaccess.thecvf.com/content/CVPR2021/supplemental/Meyer_An_Alternative_Probabilistic_CVPR_2021_supplemental.pdf
同时在paddle/distribution/kl.py 中注册_kl_laplace_laplace函数,使用时可直接调用kl_divergence计算laplace分布之间的kl散度。
2.2 测试和验收的考量
在我们开发完对应的代码后,我们应该如何证明我们所开发出来的代码是正确的呢?这时候就需要单元测试的代码来证明我们的代码是正确的。那么什么是单元测试呢?单元测试的用例其实是一个“输入数据”和“预计输出”的集合。你需要跟你输入数据,根据逻辑功能给出预计输出,这里所说的根据逻辑功能是指,通过需求文档就能给出的预计输出。而非我们通过已经实现的代码去推导出的预计输出。这也是最容易被忽视的一点。你要去做单元测试,然后还要通过代码去推断出预计输出,如果你的代码逻辑本来就实现错了,给出的预计输出也是错的,那么你的单元测试将没有意义。实际上,这部分可以说是整个工作中最重要的部分也是比较难的部分,我们需要想出预计输出,并且如何通过已经实现的代码去推导出预计输出,只有单元测试通过了,我们的开发任务才算基本完成了。
根据api类各个方法及特性传参的不同,把单测分成三个部分:测试分布的特性(无需额外参数)、测试分布的概率密度函数(需要传值)以及测试KL散度(需要传入一个实例)。
1、测试Lapalce分布的特性
- 测试方法:该部分主要测试分布的均值、方差、熵等特征。类TestLaplace继承unittest.TestCase,分别实现方法setUp(初始化),test_mean(mean单测),test_variance(variance单测),test_stddev(stddev单测),test_entropy(entropy单测),test_sample(sample单测)。
- 均值、方差、标准差通过Numpy计算相应值,对比Laplace类中相应property的返回值,若一致即正确;
- 采样方法除验证其返回的数据类型及数据形状是否合法外,还需证明采样结果符合laplace分布。验证策略如下:随机采样30000个laplace分布下的样本值,计算采样样本的均值和方差,并比较同分布下scipy.stats.laplace返回的均值与方差,检查是否在合理误差范围内;同时通过Kolmogorov-Smirnov test进一步验证采样是否属于laplace分布,若计算所得ks值小于0.02,则拒绝不一致假设,两者属于同一分布;
- 熵计算通过对比scipy.stats.laplace.entropy的值是否与类方法返回值一致验证结果的正确性。
- 测试用例:单测需要覆盖单一维度的Laplace分布和多维度分布情况,因此使用两种初始化参数
- ‘one-dim’: loc=parameterize.xrand((2, )), scale=parameterize.xrand((2, ));
- ‘multi-dim’: loc=parameterize.xrand((5, 5)), scale=parameterize.xrand((5, 5))。
2、测试Lapalce分布的概率密度函数
- 测试方法:该部分主要测试分布各种概率密度函数。类TestLaplacePDF继承unittest.TestCase,分别实现方法setUp(初始化),test_prob(prob单测),test_log_prob(log_prob单测),test_cdf(cdf单测),test_icdf(icdf)。以上分布在scipy.stats.laplace中均有实现,因此给定某个输入value,对比相同参数下Laplace分布的scipy实现以及paddle实现的结果,若误差在容忍度范围内则证明实现正确。
- 测试用例:为不失一般性,测试使用多维位置参数和尺度参数初始化Laplace类,并覆盖int型输入及float型输入。
- ‘value-float’: loc=np.array([0.2, 0.3]), scale=np.array([2, 3]), value=np.array([2., 5.]); * ‘value-int’: loc=np.array([0.2, 0.3]), scale=np.array([2, 3]), value=np.array([2, 5]);
- ‘value-multi-dim’: loc=np.array([0.2, 0.3]), scale=np.array([2, 3]), value=np.array([[4., 6], [8, 2]])。
3、测试Lapalce分布之间的KL散度
- 测试方法:该部分测试两个Laplace分布之间的KL散度。类TestLaplaceAndLaplaceKL继承unittest.TestCase,分别实现setUp(初始化),test_kl_divergence(kl_divergence)。在scipy中scipy.stats.entropy可用来计算两个分布之间的散度。因此对比两个Laplace分布在paddle.distribution.kl_divergence下和在scipy.stats.laplace下计算的散度,若结果在误差范围内,则证明该方法实现正确。
- 测试用例:分布1:loc=np.array([0.0]), scale=np.array([1.0]), 分布2: loc=np.array([1.0]), scale=np.array([0.5])
3、代码开发
代码的开发主要参考Pytorch,此处涉及到单元测试代码的开发,kl散度注册等代码,需要仔细阅读PaddlePaddle中其他分布代码的实现形式。
import numbers
import numpy as np
import paddle
from paddle.distribution import distribution
from paddle.fluid import framework as framework
class Laplace(distribution.Distribution):
r"""
Creates a Laplace distribution parameterized by :attr:`loc` and :attr:`scale`.
Mathematical details
The probability density function (pdf) is
.. math::
pdf(x; \mu, \sigma) = \frac{1}{2 * \sigma} * e^{\frac {-|x - \mu|}{\sigma}}
In the above equation:
* :math:`loc = \mu`: is the location parameter.
* :math:`scale = \sigma`: is the scale parameter.
Args:
loc (scalar|Tensor): The mean of the distribution.
scale (scalar|Tensor): The scale of the distribution.
name(str, optional): Name for the operation (optional, default is None). For more information, please refer to :ref:`api_guide_Name`.
Examples:
.. code-block:: python
import paddle
m = paddle.distribution.Laplace(paddle.to_tensor([0.0]), paddle.to_tensor([1.0]))
m.sample() # Laplace distributed with loc=0, scale=1
# Tensor(shape=[1], dtype=float32, place=Place(cpu), stop_gradient=True,
# [3.68546247])
"""
def __init__(self, loc, scale):
if not isinstance(loc, (numbers.Real, framework.Variable)):
raise TypeError(
f"Expected type of loc is Real|Variable, but got {type(loc)}")
if not isinstance(scale, (numbers.Real, framework.Variable)):
raise TypeError(
f"Expected type of scale is Real|Variable, but got {type(scale)}"
)
if isinstance(loc, numbers.Real):
loc = paddle.full(shape=(), fill_value=loc)
if isinstance(scale, numbers.Real):
scale = paddle.full(shape=(), fill_value=scale)
if (len(scale.shape) > 0 or len(loc.shape) > 0) and (loc.dtype
== scale.dtype):
self.loc, self.scale = paddle.broadcast_tensors([loc, scale])
else:
self.loc, self.scale = loc, scale
super(Laplace, self).__init__(self.loc.shape)
@property
def mean(self):
"""Mean of distribution.
Returns:
Tensor: The mean value.
"""
return self.loc
@property
def stddev(self):
"""Standard deviation.
The stddev is
.. math::
stddev = \sqrt{2} * \sigma
In the above equation:
* :math:`scale = \sigma`: is the scale parameter.
Returns:
Tensor: The std value.
"""
return (2**0.5) * self.scale
@property
def variance(self):
"""Variance of distribution.
The variance is
.. math::
variance = 2 * \sigma^2
In the above equation:
* :math:`scale = \sigma`: is the scale parameter.
Returns:
Tensor: The variance value.
"""
return self.stddev.pow(2)
def _validate_value(self, value):
"""Argument dimension check for distribution methods such as `log_prob`,
`cdf` and `icdf`.
Args:
value (Tensor|Scalar): The input value, which can be a scalar or a tensor.
Returns:
loc, scale, value: The broadcasted loc, scale and value, with the same dimension and data type.
"""
if isinstance(value, numbers.Real):
value = paddle.full(shape=(), fill_value=value)
if value.dtype != self.scale.dtype:
value = paddle.cast(value, self.scale.dtype)
if len(self.scale.shape) > 0 or len(self.loc.shape) > 0 or len(
value.shape) > 0:
loc, scale, value = paddle.broadcast_tensors(
[self.loc, self.scale, value])
else:
loc, scale = self.loc, self.scale
return loc, scale, value
def log_prob(self, value):
"""Log probability density/mass function.
The log_prob is
.. math::
log\_prob(value) = \frac{-log(2 * \sigma) - |value - \mu|}{\sigma}
In the above equation:
* :math:`loc = \mu`: is the location parameter.
* :math:`scale = \sigma`: is the scale parameter.
Args:
value (Tensor|Scalar): The input value, can be a scalar or a tensor.
Returns:
Tensor: The log probability, whose data type is same with value.
Examples:
.. code-block:: python
import paddle
m = paddle.distribution.Laplace(paddle.to_tensor([0.0]), paddle.to_tensor([1.0]))
value = paddle.to_tensor([0.1])
m.log_prob(value)
# Tensor(shape=[1], dtype=float32, place=Place(cpu), stop_gradient=True,
# [-0.79314721])
"""
loc, scale, value = self._validate_value(value)
log_scale = -paddle.log(2 * scale)
return (log_scale - paddle.abs(value - loc) / scale)
def entropy(self):
"""Entropy of Laplace distribution.
The entropy is:
.. math::
entropy() = 1 + log(2 * \sigma)
In the above equation:
* :math:`scale = \sigma`: is the scale parameter.
Returns:
The entropy of distribution.
Examples:
.. code-block:: python
import paddle
m = paddle.distribution.Laplace(paddle.to_tensor([0.0]), paddle.to_tensor([1.0]))
m.entropy()
# Tensor(shape=[1], dtype=float32, place=Place(cpu), stop_gradient=True,
# [1.69314718])
"""
return 1 + paddle.log(2 * self.scale)
def cdf(self, value):
"""Cumulative distribution function.
The cdf is
.. math::
cdf(value) = 0.5 - 0.5 * sign(value - \mu) * e^\frac{-|(\mu - \sigma)|}{\sigma}
In the above equation:
* :math:`loc = \mu`: is the location parameter.
* :math:`scale = \sigma`: is the scale parameter.
Args:
value (Tensor): The value to be evaluated.
Returns:
Tensor: The cumulative probability of value.
Examples:
.. code-block:: python
import paddle
m = paddle.distribution.Laplace(paddle.to_tensor([0.0]), paddle.to_tensor([1.0]))
value = paddle.to_tensor([0.1])
m.cdf(value)
# Tensor(shape=[1], dtype=float32, place=Place(cpu), stop_gradient=True,
# [0.54758132])
"""
loc, scale, value = self._validate_value(value)
iterm = (0.5 * (value - loc).sign() *
paddle.expm1(-(value - loc).abs() / scale))
return 0.5 - iterm
def icdf(self, value):
"""Inverse Cumulative distribution function.
The icdf is
.. math::
cdf^{-1}(value)= \mu - \sigma * sign(value - 0.5) * ln(1 - 2 * |value-0.5|)
In the above equation:
* :math:`loc = \mu`: is the location parameter.
* :math:`scale = \sigma`: is the scale parameter.
Args:
value (Tensor): The value to be evaluated.
Returns:
Tensor: The cumulative probability of value.
Examples:
.. code-block:: python
import paddle
m = paddle.distribution.Laplace(paddle.to_tensor([0.0]), paddle.to_tensor([1.0]))
value = paddle.to_tensor([0.1])
m.icdf(value)
# Tensor(shape=[1], dtype=float32, place=Place(cpu), stop_gradient=True,
# [-1.60943794])
"""
loc, scale, value = self._validate_value(value)
term = value - 0.5
return (loc - scale * (term).sign() * paddle.log1p(-2 * term.abs()))
def sample(self, shape=()):
"""Generate samples of the specified shape.
Args:
shape(tuple[int]): The shape of generated samples.
Returns:
Tensor: A sample tensor that fits the Laplace distribution.
Examples:
.. code-block:: python
import paddle
m = paddle.distribution.Laplace(paddle.to_tensor([0.0]), paddle.to_tensor([1.0]))
m.sample() # Laplace distributed with loc=0, scale=1
# Tensor(shape=[1], dtype=float32, place=Place(cpu), stop_gradient=True,
# [3.68546247])
"""
if not isinstance(shape, tuple):
raise TypeError(
f'Expected shape should be tuple[int], but got {type(shape)}')
with paddle.no_grad():
return self.rsample(shape)
def rsample(self, shape):
"""Reparameterized sample.
Args:
shape(tuple[int]): The shape of generated samples.
Returns:
Tensor: A sample tensor that fits the Laplace distribution.
Examples:
.. code-block:: python
import paddle
m = paddle.distribution.Laplace(paddle.to_tensor([0.0]), paddle.to_tensor([1.0]))
m.rsample((1,)) # Laplace distributed with loc=0, scale=1
# Tensor(shape=[1, 1], dtype=float32, place=Place(cpu), stop_gradient=True,
# [[0.04337667]])
"""
eps = self._get_eps()
shape = self._extend_shape(shape) or (1, )
uniform = paddle.uniform(shape=shape,
min=float(np.nextafter(-1, 1)) + eps / 2,
max=1. - eps / 2,
dtype=self.loc.dtype)
if len(self.scale.shape) == 0 and len(self.loc.shape) == 0:
loc, scale, uniform = paddle.broadcast_tensors(
[self.loc, self.scale, uniform])
else:
loc, scale = self.loc, self.scale
return (loc - scale * uniform.sign() * paddle.log1p(-uniform.abs()))
def _get_eps(self):
"""
Get the eps of certain data type.
Note:
Since paddle.finfo is temporarily unavailable, we
use hard-coding style to get eps value.
Returns:
Float: An eps value by different data types.
"""
eps = 1.19209e-07
if (self.loc.dtype == paddle.float64
or self.loc.dtype == paddle.complex128):
eps = 2.22045e-16
return eps
def kl_divergence(self, other):
"""Calculate the KL divergence KL(self || other) with two Laplace instances.
The kl_divergence between two Laplace distribution is
.. math::
KL\_divergence(\mu_0, \sigma_0; \mu_1, \sigma_1) = 0.5 (ratio^2 + (\frac{diff}{\sigma_1})^2 - 1 - 2 \ln {ratio})
.. math::
ratio = \frac{\sigma_0}{\sigma_1}
.. math::
diff = \mu_1 - \mu_0
In the above equation:
* :math:`loc = \mu`: is the location parameter of self.
* :math:`scale = \sigma`: is the scale parameter of self.
* :math:`loc = \mu_1`: is the location parameter of the reference Laplace distribution.
* :math:`scale = \sigma_1`: is the scale parameter of the reference Laplace distribution.
* :math:`ratio`: is the ratio between the two distribution.
* :math:`diff`: is the difference between the two distribution.
Args:
other (Laplace): An instance of Laplace.
Returns:
Tensor: The kl-divergence between two laplace distributions.
Examples:
.. code-block:: python
import paddle
m1 = paddle.distribution.Laplace(paddle.to_tensor([0.0]), paddle.to_tensor([1.0]))
m2 = paddle.distribution.Laplace(paddle.to_tensor([1.0]), paddle.to_tensor([0.5]))
m1.kl_divergence(m2)
# Tensor(shape=[1], dtype=float32, place=Place(cpu), stop_gradient=True,
# [1.04261160])
"""
var_ratio = other.scale / self.scale
t = paddle.abs(self.loc - other.loc)
term1 = ((self.scale * paddle.exp(-t / self.scale) + t) / other.scale)
term2 = paddle.log(var_ratio)
return term1 + term2 - 14、总结
目前,该API已经锁定贡献。回顾API的开发过程,实际上该API的开发并不难,主要的问题在于如何进行单元测试,证明开发的API是正确的,并且还有一些相关的细节点,比如KL散度的注册等。还有就是最开始走了弯路,参照了Normal的开发风格,将API写成了2.0风格的,影响了一些时间,并且在最后的单测中,发现了Uniform实现方式的一些Bug,此处Debug花费了一些时间,整体来看,花时间的部分是在单测部分。
|








- 上一条: OpenTiny 的这些特色组件,很实用,但你应该没见过 2023-04-09
- 下一条: GaussDB(DWS)集群中寻找节点CPU占用高的语句 2023-04-10
- 一次“不负责任”的 K8s 网络故障排查经验分享 2021-06-27
- 分布式事务的十大神坑 2021-07-18
- 每一个程序员,都渴望成为一名分布式系统架构师 2021-07-11
- 备份的 “算子下推”:BR 简介丨TiDB 工具分享 2021-12-16
- CANN AICPU算子耗时分析及优化探索 2021-09-18

