大页 struct page 内存优化87%+ !HVO 最新优化进展与规划
欢迎关注【字节跳动 SYS Tech】公众号。字节跳动 SYS Tech 聚焦系统技术领域,与大家分享前沿技术动态、技术创新与实践、行业技术热点分析等内容。
大家下午好,今天给大家带来的主题是《HVO Progress and Plans》 ,即大页内存占用优化的进度与计划。
HVO 简介
Linux 内核一般以 4K 为单位来管理物理页面。每 4K 物理内存对应一个 struct page 结构体,每个 struct page 大约 64 字节,即 struct page 占据了 1.56% 的内存,那么每 1T 内存会有 16G 的空间用于 struct pages。
Linux 有大页的功能,每个大页会有 2M、1G 等不同大小,理论上一个大页只需要用一个 struct page 来表示,但实际上构成大页的每个 4K 物理页在内核中都依然要用一个 struct page 来表示。这些 struct pages 内容相同且用处很少,占用了大量内存,因此我们提出了 HVO 的特性来优化内存。
HVO 是 HugeTLB Vmemmap Optimization 的简称,可以降低大页内存所对应的 vmemmap 内存占用。其原理是把一个大页在 vmemmap 中所有 struct page 的虚拟地址都映射到同一个物理地址,以此释放 struct page 所占用的物理内存。该特性合入到 Kernel 社区之后,也有同学通过实验发现, HVO 不仅可以降低内存的占用,在 cache 的空间局部性表现上也更好。因为它将多个虚拟地址映射到了同一块物理地址,更多 struct page 读写操作就会在缓存中进行,相应地也提升了 cache 的访问效率。
当我们开启 HVO 特性之后,一个 2M 的大页能够节省大约 87.5% 的 struct page 内存占用。如果是 1G 的大页,可以节约的 struct page 内存占用近乎 100%。
- 以 2M 大页为例:每个 2M 大页需要 512 个 struct page 结构体来表示,即总共 512 * 64byte = 32KB 内存,占用 8 个 4KB 的 page,HVO 可以将后面的 7 个 page(28 KB) 全部释放,并统一映射到第一个 page 的物理地址中,所以达到了节约 87% 的效果。
- 以 1G 大页为例:每个 1G 大页,会有 262144 * 64byte = 16MB 的空间来存储 struct page。HVO 会将所有的 tail page 都释放掉,只保留一个 head page 存储元信息,因此达到节省近乎 100% 内存的效果。

HVO 最新特性

最近一年,我们团队在 HVO 上又增加了一些新特性:
- 节省更多内存:HVO 在最初合入社区的 patch 版本中,对于一个 2M 大页只能节省 75% 的内存,在今年 3 月份 Free the 2nd vmemmmap page 发布更新后,可以节省 87% 以上的内存,内存优化提高了12%。
- ARM64 适配:HVO 在原有仅支持 x86 架构的基础上,扩展支持了 ARM64 架构。虽然 HVO 代码是通用的,但不同架构在开启 HVO 时仍然需要注意本架构对 struct page 的特异性操作,如刷缓存等。
- Hotplug memmap_on memory 适配:适配了 memmap_on memory,HVO 与 memmap_on memory 在功能性上达到兼容。memmap_on memory 可以在热拔插的内存上预留一块内存,以填充这块内存的 struct page。在此之前, HVO 和 memmap_on memory 是互斥的,启用 memmap_on memory 就不能用 HVO,用了 HVO 就不能用 memmap_on。后来我们发现龙芯社区的代码中也开启了 HVO 特性的优化,非常乐于看到不同的架构适配 HVO,包括 RSIC-V 架构等。
- 提高被释放内存连续性: 在今年8月份的 patch 上,主要解决了 HVO 释放内存所产生的碎片化问题。
- 更多场景: 将 HVO 的思想应用在更多场景上,比如 device-dax 等。
如何使用 HVO
Compile HVO
首先确保内核为 5.14 主线之后的版本,如果想用其他的版本,可以 backport 一下。然后要确认启用配置文件: CONFIG_HUGETLB_PAGE_OPTIMIZE_VMEMMAP = y;重新编译内核再进入系统,内核启动日志会说明当前已开启哪些类型的大页,以及 HVO 针对这种大页会节约多少内存。例如下图中的内核启动日志表明:一个 2 M的大页,HVO 可以节约 28 KB 的 vmemmap 内存。
[ 1.047319] HugeTLB: registered 2.00 MiB page size, pre-allocated 0 pages
[ 1.052204] HugeTLB: 28 KiB vmemmap can be freed for a 2.00 MiB page
需要注意的是:如果打印出下列信息,则表示当前机器无法启用 HVO,原因是 struct page 没有对齐到 64 字节,以致于不能使用 HVO 将多个 vmemmap 页映射到同一个物理地址。
Not support: [ 0.933198] HugeTLB: 0 KiB vmemmap can be freed for a 2.00 MiB page
Enable HVO
虽然已经编译,但系统并不会默认的开启 HVO 特性,我们可以通过下面三种方法开启 HVO。开启 HVO 之后,每一个大页会节约大约 87% 到 99% 的 struct page 内存。
- 第一种方法:在配置文件中设置一个默认值,即可默认开启 HVO ,该方法最为简单易用。
CONFIG_HUGETLB_PAGE_OPTIMIZE_VMEMMAP_DEFAULT_ON=y
- 第二种方法:在 command line 中传入 hugetlb_free_vmemmap = on 的参数
hugetlb_free_vmemmap=on
- 第三种方法: 通过 systemctl 命令动态地开启或者关闭 HVO 的优化。需要注意的是:当关闭之后,HVO 优化不会立即消失,如果想要彻底关闭 HVO 优化,需要先用 systemctl 关闭 HVO 特性,然后将所有已经申请的大页都释放掉,这样才会在内核彻底地关闭 HVO 特性。
echo 1 > /proc/sys/vm/hugetlb_optimize_vmemmap
Balance space & time
HVO 虽然能够大幅度节省内存,但同时也存在一定性能问题。这是因为 HVO 每次需要从 buddy 里面申请 hugetlb,然后再对 vmemmap 重新进行地址映射,所以性能稍微差一些。那么,如何做好空间与时间的动态平衡呢?
echo 1 > /proc/sys/vm/hugetlb_optimize_vmemmap
echo $RESERVE > /proc/sys/vm/nr_hugepages
echo 0 > /proc/sys/vm/hugetlb_optimize_vmemmap
echo $OVERCOMMIT > /proc/sys/vm/nr_overcommit_hugepages
解决办法就是先开启 HVO 预申请 huge page ,可以达到节约内存的目的。然后关闭 HVO 后设置 overcommit。overcommit 的部分虽然不会节约内存,但是运行效率较高。也就是前段节省空间,后段提高性能。
支持更多架构
HVO 在原有仅支持 x86 架构的基础上,扩展支持了 ARM64 架构。HVO 将 vmemmap 中的一段虚拟地址都指向一个物理页面,复用了原来头部的 struct page,tail struct page 都被回收了。
所以当代码要操作大页中的某个小页,修改 tail page,实际上修改的是 head page 所对应的物理地址,由于 HVO 将 tail page 的虚拟地址空间设置为只读,一些代码可能会报写错误。
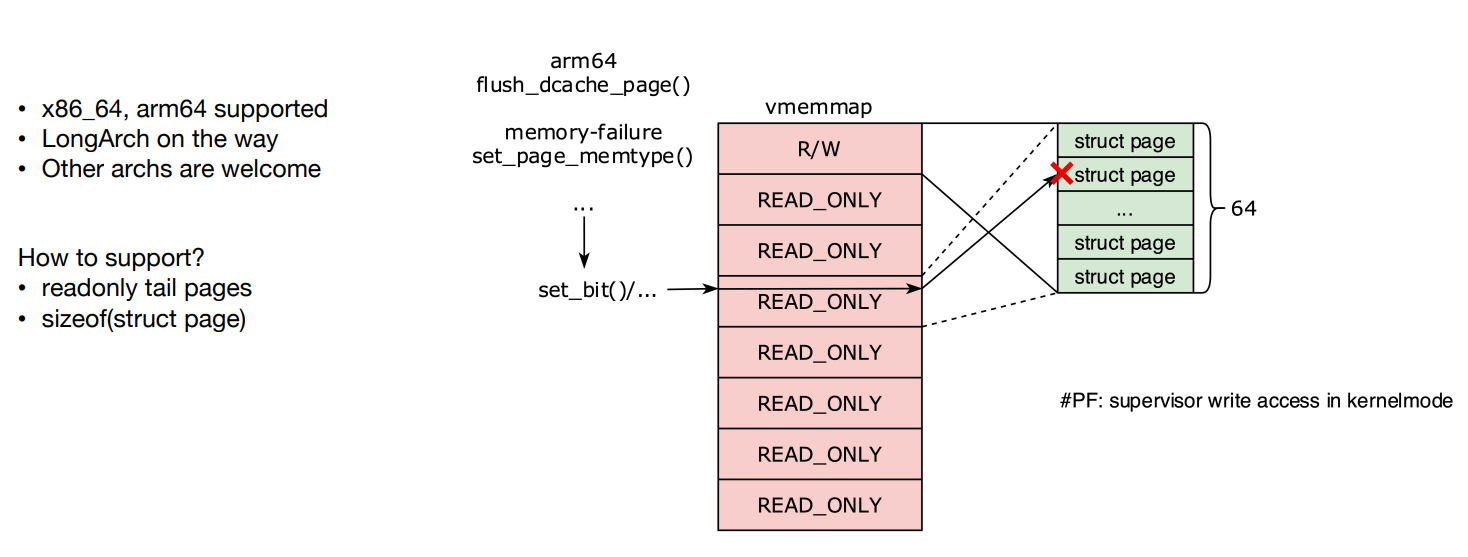
如上图,对 tail page 的虚拟地址发起的读写请求,会触发写保护。
比如 ARM64 中的 flush_dcache_page() 函数,传一个 struct page 就会设置其标志位。但如果传一个大页中的 tail page 进去,flash 的仍然是整个大页的内存空间。它其实可以做到把所有的 page 都视作一个大页,只修改 head page 即可,但它却还是修改了 tail page,所以我们给它做了一个重定向,把它所有对 tail page 的写操作都重定向到 head page 上去。
使用 HVO 特性的前提条件是:每个 struct page 必须需要 64 字节或 2 的 N 次幂,否则 struct 的配置就会跨越物理页的边界,HVO 无法优化它。未来我们也可以开发一个特性,填充 struct page 到 64 字节,方便用户启用 HVO。这样做的好处在于:虽然在填充会占用一些内存,但是 HVO 还是在某些场景下节约更多的内存。
应用HVO到其他场景上
优化 device-dax
HVO 并不仅仅是一个特性,也是一种思想,可以应用到其他类似的场景中。比如说持久内存,当它作为内存使用时,需要向用户提供 device-dax 设备文件,以便用户将其持久内存映射到自己的虚拟内存空间,对相应的地址范围进行读写操作。device-dax 设备也需要用 struct page 表示各个页面。所以后来甲骨文做 device-dax 的同学借鉴了 HVO 的优化思路,提出了针对 device-dax 的优化。
当然 device-dax 只会在加载时进行 HVO 的操作,所以不需要考虑动态分配对性能的影响。
具体可参考:https://lore.kernel.org/all/20220420155310.9712-1-joao.m.martins@oracle.com/
优化 buddy
类似的,HVO 的思想也可以应用在 buddy 系统中。比如 buddy 中 order 大于 7 ,由 128+ 个 page 组成的 block,其 struct page 会占据两个以上的页。可以用 HVO 的思路,把 vmemmap 的 tail page 全部映射到 head page 所对应的物理地址,以此来优化内存占用。或者可以添加一个 flag ,从 buddy 申请内存时指定我们是否需要这样优化。
当 buddy 要拆分order 而取消 HVO 优化时,需要用一些 page 将原来释放的内存填充起来,填充内存时如果出现内存不够的情况,还要从 buddy 中申请内存,如此一来就产生冲突:释放内存的动作需要申请内存。
优化透明大页
再比如透明大页也可以优化,这是更复杂的场景,因为它们对用户进程是透明的,可以被随意分割与合并,这是透明大页与大页最大的区别。
当然我们这里只是提出一种想法,如果有人感兴趣的话,可以去尝试在 buddy 、大页上进行修改。
HVO 未来计划
碎片化优化
HVO 碎片化的产生原因:内核采用一种 Sparse Vmemmap 的内存管理模式,把内存分为一个个的 section,每个 section 是 128 M。HVO 在释放内存时,每隔几页会留一个 head page 映射 tail page 的虚拟地址。tail page 会分割空闲空间,导致释放的页是碎片化,无法重新组成一个连续的页面。不利于 buddy 回收内存,也不利于 slab 申请 order 比较大的页。
针对碎片化的问题,我们在 kernel 社区提了一个 patch :在用户在释放内存时,重新申请一个 page ,把原来的 head page 拷贝进去,以释放出一块连续的物理内存。如果内存足够大,可以构成一个新的大页。
兼容性优化
在 kernel 社区中还有一个 patch : vmemmap 和 HVO 的兼容性,但是做的并不彻底,因为 hot plug 的内存拔掉之前,需要把所有分配出去的内存都回收回来,包括 HVO 节省出来的内存。但这块还没有做,感兴趣的同学可以去思考一下。
|








- 上一条: 大页 struct page 内存优化87%+ !HVO 最新优化进展与规划 2023-01-30
- 下一条: 没有了
- Linux透明大页机制在云上大规模集群实践介绍 2022-07-07
- Redis 内存优化神技,小内存保存大数据 2022-07-13
- 文盘Rust -- struct 中的生命周期 2022-10-08
- 理论+实例,带你掌握Linux的页目录和页表 2021-10-13
- Redis 内存优化在 vivo 的探索与实践 2022-05-05


