一文带你入门图机器学习
本文主要涉及图机器学习的基础知识。
我们首先学习什么是图,为什么使用图,以及如何最佳地表示图。然后,我们简要介绍大家如何在图数据上学习,从神经网络以前的方法 (同时我们会探索图特征) 到现在广为人知的图神经网络 (Graph Neural Network,GNN)。最后,我们将一窥图数据上的 Transformers 世界。
什么是图?
本质上来讲,图描述了由关系互相链接起来的实体。
现实中有很多图的例子,包括社交网络 (如推特,长毛象,以及任何链接论文和作者的引用网络) 、分子、知识图谱 (如 UML 图,百科全书,以及那些页面之间有超链接的网站) 、被表示成句法树的句子、3D 网格等等。因此,可以毫不夸张地讲,图无处不在。
图 (或网络) 中的实体称为 节点 (或顶点) ,它们之间的连接称为 边 (或链接) 。举个例子,在社交网络中,节点是用户,而边是他 (她) 们之间的连接关系;在分子中,节点是原子,而边是它们之间的分子键。
-
可以存在不止一种类型的节点或边的图称为 异构图 (heterogeneous graph) (例子:引用网络的节点有论文和作者两种类型,含有多种关系类型的 XML 图的边是多类型的) 。异构图不能仅由其拓扑结构来表征,它需要额外的信息。本文主要讨论同构图 (homogeneous graph) 。
-
图还可以是 有向 (directed) 的 (如一个关注网络中,A 关注了 B,但 B 可以不关注 A) 或者是 无向 (undirected) 的 (如一个分子中,原子间的关系是双向的) 。边可以连接不同的节点,也可以自己连接自己 (自连边,self-edges) ,但不是所有的节点都必须有连接。
如果你想使用自己的数据,首先你必须考虑如何最佳地刻画它 (同构 / 异构,有向 / 无向等) 。
图有什么用途?
我们一起看看在图上我们可以做哪些任务吧。
在 图层面,主要的任务有:
- 图生成,可在药物发现任务中用于生成新的可能的药物分子,
- 图演化 (给定一个图,预测它会如何随时间演化) ,可在物理学中用于预测系统的演化,
- 图层面预测 (基于图的分类或回归任务) ,如预测分子毒性。
在 节点层面,通常用于预测节点属性。举个例子,Alphafold 使用节点属性预测方法,在给定分子总体图的条件下预测原子的 3D 坐标,并由此预测分子在 3D 空间中如何折叠,这是个比较难的生物化学问题。
在 边层面,我们可以做边属性预测或缺失边预测。边属性预测可用于在给定药物对 (pair) 的条件下预测药物的不良副作用。缺失边预测被用于在推荐系统中预测图中的两个节点是否相关。
另一种可能的工作是在 子图层面 的,可用于社区检测或子图属性预测。社交网络用社区检测确定人们之间如何连接。我们可以在行程系统 (如 Google Maps) 中发现子图属性预测的身影,它被用于预测到达时间。
完成这些任务有两种方式。
当你想要预测特定图的演化时,你工作在 直推 (transductive) 模式,直推模式中所有的训练、验证和推理都是基于同一张图。如果这是你的设置,要多加小心!在同一张图上创建训练 / 评估 / 测试集可不容易。 然而,很多任务其实是工作在不同的图上的 (不同的训练 / 评估 / 测试集划分) ,我们称之为 归纳 (inductive) 模式。
如何表示图?
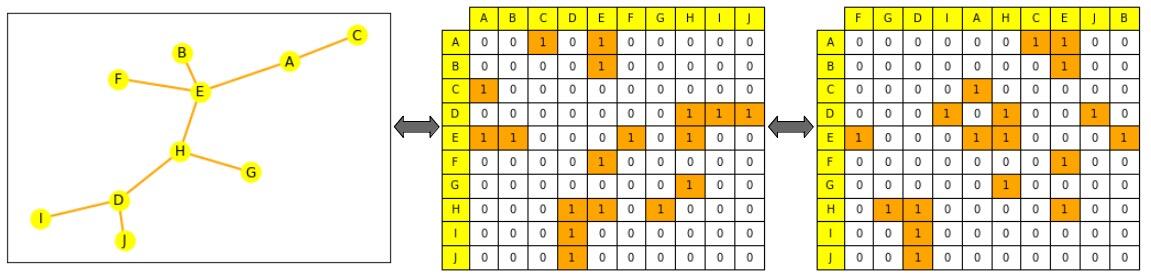
常用的表示图以用于后续处理和操作的方法有 2 种:
- 表示成所有边的集合 (很有可能也会加上所有节点的集合用以补充) 。
- 或表示成所有节点间的邻接矩阵。邻接矩阵是一个 $node_size \times node_size$ 大小的方阵,它指明图上哪些节点间是直接相连的 (若 $n_i$ 和 $n_j$ 相连则 $A_{ij} = 1$,否则为 0) 。
注意:多数图的边连接并不稠密,因此它们的邻接矩阵是稀疏的,这个会让计算变得困难。
虽然这些表示看上去很熟悉,但可别被骗了!
图与机器学习中使用的典型对象大不相同,因为它们的拓扑结构比序列 (如文本或音频) 或有序网格 (如图像和视频) 复杂得多:即使它们可以被表示成链表或者矩阵,但它们并不能被当作有序对象来处理。
这究竟意味着什么呢?如果你有一个句子,你交换了这个句子的词序,你就创造了一个新句子。如果你有一张图像,然后你重排了这个图像的列,你就创造了一张新图像。
但图并不会如此。如果你重排了图的边列表或者邻接矩阵的列,图还是同一个图 (一个更正式的叫法是置换不变性 (permutation invariance) ) 。
基于机器学习的图表示
使用机器学习处理图的一般流程是:首先为你感兴趣的对象 (根据你的任务,可以是节点、边或是全图) 生成一个有意义的表示,然后使用它们训练一个目标任务的预测器。与其他模态数据一样,我们想要对这些对象的数学表示施加一些约束,使得相似的对象在数学上是相近的。然而,这种相似性在图机器学习上很难严格定义,举个例子,具有相同标签的两个节点和具有相同邻居的两个节点哪两个更相似?
注意:在随后的部分,我们将聚焦于如何生成节点的表示。一旦你有了节点层面的表示,就有可能获得边或图层面的信息。你可以通过把边所连接的两个节点的表示串联起来或者做一个点积来得到边层面的信息。至于图层面的信息,可以通过对图上所有节点的表示串联起来的张量做一个全局池化 (平均,求和等) 来获得。当然,这么做会平滑掉或丢失掉整图上的一些信息,使用迭代的分层池化可能更合理,或者增加一个连接到图上所有其他节点的虚拟节点,然后使用它的表示作为整图的表示。
神经网络以前的方法
只使用手工设计特征
在神经网络出现之前,图以及图中的感兴趣项可以被表示成特征的组合,这些特征组合是针对特定任务的。尽管现在存在 更复杂的特征生成方法,这些特征仍然被用于数据增强和 半监督学习。这时,你主要的工作是根据目标任务,找到最佳的用于后续网络训练的特征。
节点层面特征 可以提供关于其重要性 (该节点对于图有多重要?) 以及 / 或结构性 (节点周围的图的形状如何?) 信息,两者可以结合。
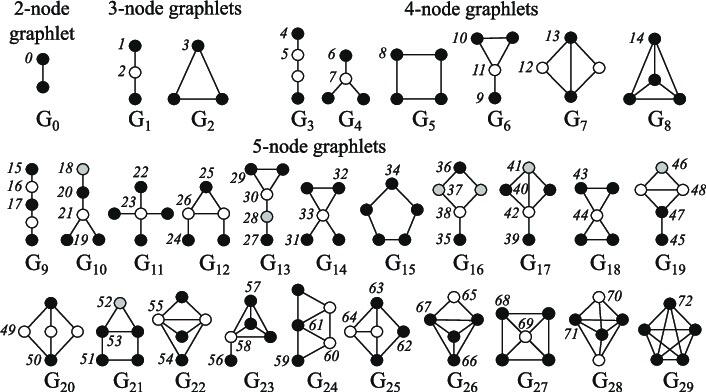
节点 中心性 (centrality) 度量图中节点的重要性。它可以递归计算,即不断对每个节点的邻节点的中心性求和直到收敛,也可以通过计算节点间的最短距离来获得,等等。节点的 度 (degree) 度量节点的直接邻居的数量。聚类系数 (clustering coefficient) 度量一个节点的邻节点之间相互连接的程度。图元度向量 (Graphlets degree vectors,GDV) 计算给定根节点的不同图元的数目,这里图元是指给定数目的连通节点可创建的所有迷你图 (如:3 个连通节点可以生成一个有两条边的线,或者一个 3 条边的三角形) 。
边层面特征带来了关于节点间连通性的更多细节信息,有效地补充了图的表示,有:两节点间的 最短距离 (shortest distance),它们的公共邻居 (common neighbours),以及它们的 卡兹指数 (Katz index) (表示两节点间从所有长度小于某个值的路径的数目,它可以由邻接矩阵直接算得) 。
图层面特征 包含了关于图相似性和规格的高层信息。总 图元数 尽管计算上很昂贵,但提供了关于子图形状的信息。核方法 通过不同的 “节点袋 (bag of nodes) ” (类似于词袋 (bag of words) ) 方法度量图之间的相似性。
基于游走的方法
基于游走的方法 使用在随机游走时从节点j访问节点i的可能性来定义相似矩阵;这些方法结合了局部和全局的信息。举个例子,Node2Vec模拟图中节点间的随机游走,把这些游走路径建模成跳字 (skip-gram) ,这与我们处理句子中的词很相似,然后计算嵌入。基于随机游走的方法也可被用于加速 Page Rank方法,帮助计算每个节点的重要性得分 (举个例子:如果重要性得分是基于每个节点与其他节点的连通度的话,我们可以用随机游走访问到每个节点的频率来模拟这个连通度) 。
然而,这些方法也有限制:它们不能得到新的节点的嵌入向量,不能很好地捕获节点间的结构相似性,也使用不了新加入的特征。
图神经网络
神经网络可泛化至未见数据。我们在上文已经提到了一些图表示的约束,那么一个好的神经网络应该有哪些特性呢?
它应该:
-
满足置换不变性:
- 等式:
 ,这里 f 是神经网络,P 是置换函数,G 是图。
,这里 f 是神经网络,P 是置换函数,G 是图。 - 解释:置换后的图和原图经过同样的神经网络后,其表示应该是相同的。
- 等式:
-
满足置换等价性
- 公式:
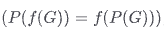 ,同样 f 是神经网络,P 是置换函数,G 是图。
,同样 f 是神经网络,P 是置换函数,G 是图。 - 解释:先置换图再传给神经网络和对神经网络的输出图表示进行置换是等价的。
- 公式:
典型的神经网络,如循环神经网络 (RNN) 或卷积神经网络 (CNN) 并不是置换不变的。因此,图神经网络 (Graph Neural Network, GNN) 作为新的架构被引入来解决这一问题 (最初是作为状态机使用) 。
一个 GNN 由连续的层组成。一个 GNN 层通过 消息传递 (message passing) 过程把一个节点表示成其邻节点及其自身表示的组合 (聚合 (aggregation)) ,然后通常我们还会使用一个激活函数去增加一些非线性。
与其他模型相比:CNN 可以看作一个邻域 (即滑动窗口) 大小和顺序固定的 GNN,也就是说 CNN 不是置换等价的。一个没有位置嵌入 (positional embedding) 的 Transformer 模型可以被看作一个工作在全连接的输入图上的 GNN。
聚合与消息传递
多种方式可用于聚合邻节点的消息,举例来讲,有求和,取平均等。一些值得关注的工作有:
- 图卷积网络 对目标节点的所有邻节点的归一化表示取平均来做聚合 (大多数 GNN 其实是 GCN) ;
- 图注意力网络 会学习如何根据邻节点的重要性不同来加权聚合邻节点 (与 transformer 模型想法相似) ;
- GraphSAGE 先在不同的跳数上进行邻节点采样,然后基于采样的子图分多步用最大池化 (max pooling) 方法聚合信息;
- 图同构网络 先计算对邻节点的表示求和,然后再送入一个 MLP 来计算最终的聚合信息。
选择聚合方法:一些聚合技术 (尤其是均值池化和最大池化) 在遇到在邻节点上仅有些微差别的相似节点的情况下可能会失败 (举个例子:采用均值池化,一个节点有 4 个邻节点,分别表示为 1,1,-1,-1,取均值后变成 0;而另一个节点有 3 个邻节点,分别表示为 - 1,0,1,取均值后也是 0。两者就无法区分了。) 。
GNN 的形状和过平滑问题
每加一个新层,节点表示中就会包含越来越多的节点信息。
一个节点,在第一层,只会聚合它的直接邻节点的信息。到第二层,它们仍然只聚合直接邻节点信息,但这次,他们的直接邻节点的表示已经包含了它们各自的邻节点信息 (从第一层获得) 。经过 n 层后,所有节点的表示变成了它们距离为 n 的所有邻节点的聚合。如果全图的直径小于 n 的话,就是聚合了全图的信息!
如果你的网络层数过多,就有每个节点都聚合了全图所有节点信息的风险 (并且所有节点的表示都收敛至相同的值) ,这被称为过平滑问题 (the oversmoothing problem)。
这可以通过如下方式来解决:
- 在设计 GNN 的层数时,要首先分析图的直径和形状,层数不能过大,以确保每个节点不聚合全图的信息
- 增加层的复杂性
- 增加非消息传递层来处理消息 (如简单的 MLP 层)
- 增加跳跃连接 (skip-connections)
过平滑问题是图机器学习的重要研究领域,因为它阻止了 GNN 的变大,而在其他模态数据上 Transformers 之类的模型已经证明了把模型变大是有很好的效果的。
图 Transformers
没有位置嵌入 (positional encoding) 层的 Transformer 模型是置换不变的,再加上 Transformer 模型已被证明扩展性很好,因此最近大家开始看如何改造 Transformer 使之适应图数据 (综述) 。多数方法聚焦于如何最佳表示图,如找到最好的特征、最好的表示位置信息的方法以及如何改变注意力以适应这一新的数据。
这里我们收集了一些有意思的工作,截至本文写作时为止,这些工作在现有的最难的测试基准之一 斯坦福开放图测试基准 (Open Graph Benchmark, OGB) 上取得了最高水平或接近最高水平的结果:
- Graph Transformer for Graph-to-Sequence Learning (Cai and Lam, 2020) 介绍了一个图编码器,它把节点表示为它本身的嵌入和位置嵌入的级联,节点间关系表示为它们间的最短路径,然后用一个关系增强的自注意力机制把两者结合起来。
- Rethinking Graph Transformers with Spectral Attention (Kreuzer et al, 2021) 介绍了谱注意力网络 (Spectral Attention Networks, SANs) 。它把节点特征和学习到的位置编码 (从拉普拉斯特征值和特征向量中计算得到) 结合起来,把这些作为注意力的键 (keys) 和查询 (queries) ,然后把边特征作为注意力的值 (values) 。
- GRPE: Relative Positional Encoding for Graph Transformer (Park et al, 2021) 介绍了图相对位置编码 Transformer。它先在图层面的位置编码中结合节点信息,在边层面的位置编码中也结合节点信息,然后在注意力机制中进一步把两者结合起来。
- Global Self-Attention as a Replacement for Graph Convolution (Hussain et al, 2021) 介绍了边增强 Transformer。该架构分别对节点和边进行嵌入,并通过一个修改过的注意力机制聚合它们。
- Do Transformers Really Perform Badly for Graph Representation (Ying et al, 2021) 介绍了微软的 Graphormer, 该模型在面世时赢得了 OGB 第一名。这个架构使用节点特征作为注意力的查询 / 键 / 值 (Q/K/V) ,然后在注意力机制中把这些表示与中心性,空间和边编码信息通过求和的方式结合起来。
最新的工作是 Pure Transformers are Powerful Graph Learners (Kim et al, 2022),它引入了 TokenGT。这一方法把输入图表示为一个节点和边嵌入的序列 (并用正交节点标识 (orthonormal node identifiers) 和可训练的类型标识 (type identifiers) 增强它) ,而不使用位置嵌入,最后把这个序列输入给 Tranformer 模型。超级简单,但很聪明!
稍有不同的是,Recipe for a General, Powerful, Scalable Graph Transformer (Rampášek et al, 2022) 引入的不是某个模型,而是一个框架,称为 GraphGPS。它允许把消息传递网络和线性 (长程的) transformer 模型结合起来轻松地创建一个混合网络。这个框架还包含了不少工具,用于计算位置编码和结构编码 (节点、图、边层面的) 、特征增强、随机游走等等。
在图数据上使用 transformer 模型还是一个非常初生的领域,但是它看上去很有前途,因为它可以减轻 GNN 的一些限制,如扩展到更大 / 更稠密的图,抑或是增加模型尺寸而不必担心过平滑问题。
更进阶的资源
如果你想钻研得更深入,可以看看这些课程:
- 学院课程形式
- 视频形式
- 相关书籍
不错的处理图数据的库有 PyGeometric (用于图机器学习) 以及 NetworkX (用于更通用的图操作)。
如果你需要质量好的测试基准,你可以试试看:
- OGB, 开放图测试基准 (the Open Graph Benchmark) :一个可用于不同的任务和数据规模的参考图测试基准数据集。
- Benchmarking GNNs: 用于测试图机器学习网络和他们的表现力的库以及数据集。相关论文特地从统计角度研究了哪些数据集是相关的,它们可被用于评估图的哪些特性,以及哪些图不应该再被用作测试基准。
- 长程图测试基准 (Long Range Graph Benchmark): 最新的 (2022 年 10 月份) 测试基准,主要关注长程的图信息。
- Taxonomy of Benchmarks in Graph Representation Learning: 发表于 2022 年 Learning on Graphs 会议,分析并对现有的测试基准数据集进行了排序。
如果想要更多的数据集,可以看看:
- Paper with code 图任务排行榜: 公开数据集和测试基准的排行榜,请注意,不是所有本排行榜上的测试基准都仍然适宜。
- TU 数据集: 公开可用的数据集的合辑,现在以类别和特征排序。大多数数据集可以用 PyG 加载,而且其中一些已经被集成进 PyG 的 Datsets。
- SNAP 数据集 (Stanford Large Network Dataset Collection):
外部图像来源
缩略图中的 Emoji 表情来自于 Openmoji (CC-BY-SA 4.0),图元的图片来自于 Biological network comparison using graphlet degree distribution (Pržulj, 2007)。
英文原文: https://huggingface.co/blog/intro-graphml
译者: Matrix Yao (姚伟峰)
|








- 上一条: 一文带你入门图机器学习 2023-01-30
- 下一条: 没有了
- 一文带你认知定时消息发布RocketMQ 2022-09-08
- 各行各业都在关注的“密评”到底是啥?一文带你读懂! 2022-09-22
- 玩转集群配置中心,一文带你了解Taier控制台 2022-05-24
- 一文带你熟知ForkJoin 2021-12-16
- 一文了解 Java 中的构造器 2022-09-14