SeaTunnel 在天翼云数据集成平台的探索实践
点亮 ⭐️ Star · 照亮开源之路
https://github.com/apache/incubator-seatunnel

讲师简介

周利旺 天翼云大数据开发工程师
在11月26日,Apache SeaTunnel& APISIX 联合 Meetup 期间,天翼云科技大数据开发工程师周利旺给大家分享了天翼云数据集成平台引入 SeaTunnel 过程中的一些探索实践,希望对大家有所帮助!
天翼云数据集成平台基于 Apache Nifi 二次封装而成,但是对于一些特定的需求 Apache Nifi 不能够很好地满足,因此需要引入第三方的数据集成工具进行能力上的补足。**而SeaTunnel 恰是能用 Nifi 互补的好工具。**本次讲座介绍了 SeaTunnel 整合到天翼云数据平台在架构层面的设计与思考。
本文主要包括四个部分:
● Apache SeaTunnel 简介
● Apache Nifi 简介
● SeaTunnel 与 Nifi 整合方案
● 天翼云数据集成平台
● 参与开源经验与心得
✦01 SeaTunnel简介✦
我们平台主要是面向政企客户,目前是以 Apache Nifi 作为核心,辅之以原生的 Flink 应用,在此基础上进行封装和二次开发出各种各样的数据集成应用,提供面向不同行业的解决方案,目前Seatunnel在我们内部虽然没上生产实践,但是也做了不少的探索,所以本次议题主要讲下 SeaTunnel 和 Nifi 结合使用的一些经验。因为两者各有优劣,但是在能力上可以取长补短,从而可以对标更多的功能,满足客户的更多需求。
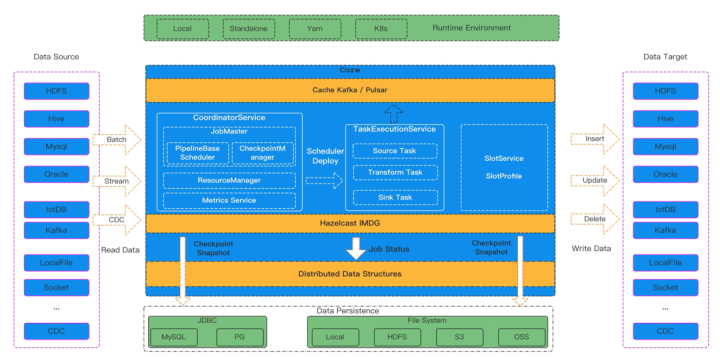
SeaTunnel 本质上是对 Spark 和 Flink 进行了一层封装,现在新版本又加入了自研的 SeaTunnel 引擎,用户可以通过编辑配置文件来快速构建工作流。
配置文件包括四个部分:
-
env 是配置整体的环境
-
source配置数据源的信息
-
transform 是配置数据处理相关的
-
sink 配置数据去向相关的。

与 kettle,Nifi 这种重量级的平台相比,SeaTunnel 更像 Datax 轻量级的数据传输工具,用户可以根据需要来安装 Source、Sink、Transform插件。
就数据源而言, SeaTunnel 支持关系型数据库像mysql、oracle,非关系型数据库 mongodb、redis 等等,文件类型的 ftp、hdfs、ossFile,网络通信的socket、http,消息队列、kafka、pulsar,数据湖等等,其中的种类非常多。
Transform 转换插件支持常见的大小写转换,替换、分割、sql、取uid这些,用户也可以根据自己的需求自定义插件。
安装和启动 SeaTunnel 也很方便,下载压缩包解压后,根据你想运行的任务类型,运行对应的启动脚本。
Spark 和 Flink 都有v1和v2两个版本,现在还支持新的 SeaTunnel 引擎,启动方式都比较类似,这里支持提交任务到 local、yarn、k8s 三种环境上。
✦02 Nifi简介✦
Apache Nifi 是一个基于Web图形界面,通过拖拽、连接、配置完成基于流程的编程,它既可以单节点运行,也可以集群模式运行,集群的节点采用Zookeeper 进行协调。
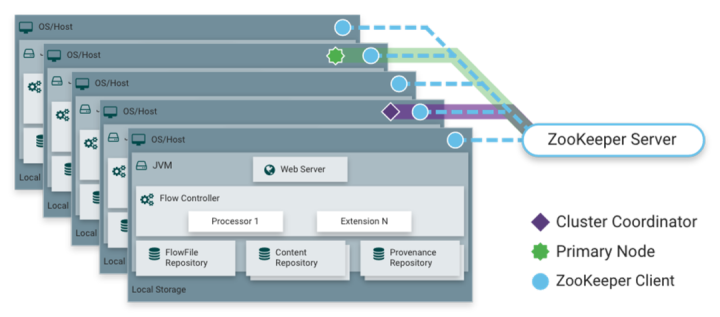
图上所示就是一个 Nifi 集群,然后每一个长方形相当于一个 Nifi 节点,在它最上层是以 web server 接收这种用户请求,每个节点的服务运行在一个 jvm 之上,由processor和flow controller支撑起业务逻辑的构建,flowfile是底层的数据结构,它会存储在 flowfile repository ,content repository。
Nifi 常用的组件主要包括五个部分
-
FlowFile
-
Processor
-
Connection
-
Process Group
-
ControllerService
2.1 FlowFile
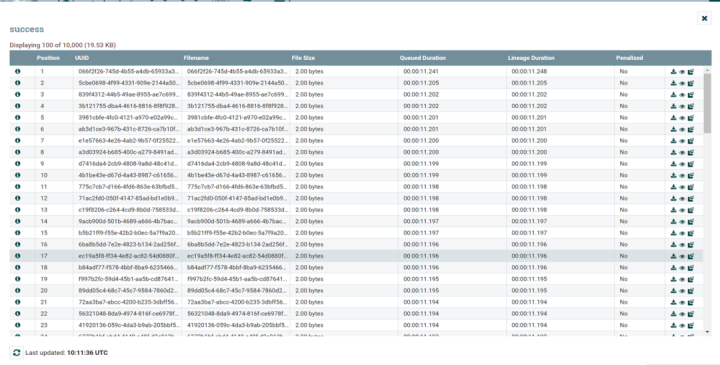
Flowfile 是 Nifi 底层的数据结构,它由属性和内容组成,它的属性可以用于描述数据,比如一个提供输出数据到本地的 putFile 组件,它输出的 FlowFile 的属性就可以是文件名,这个 Flowfile 是一个抽象概念,可以通过配置把它们放在内存里或者硬盘上,用户可以通过查看队列(可视化的形式)来看到 Flowfile(它的属性以及相关内容)。
2.2 Processor
它是 mapper 里面最核心的一个部分。Processor 可以通过编排连接来构建工作流。常用的 Processor 它也会包含这个读取数据转化数据、输入数据这几大类的。

Processor 是 Nifi 里面最核心的部分, Processor 可以通过编排连接来构建工作流。常用的 Processor 包含读取数据,转换数据、输出数据这几大类的,总的支持的组件数量大约有三四百个。
每个组件都支持配置单独的调度策略,支持定时调度和 cron 表达式调度。Nifi 虽然有这众多的组件,但是像 cdc 组件是比较单薄的,只有 mysqlcdc,然后像一些新型的数据源读写组件目前开源版本的Nifi 都没有支持,比如数据湖 hudi、iceberg 等等;
2.3 Connection

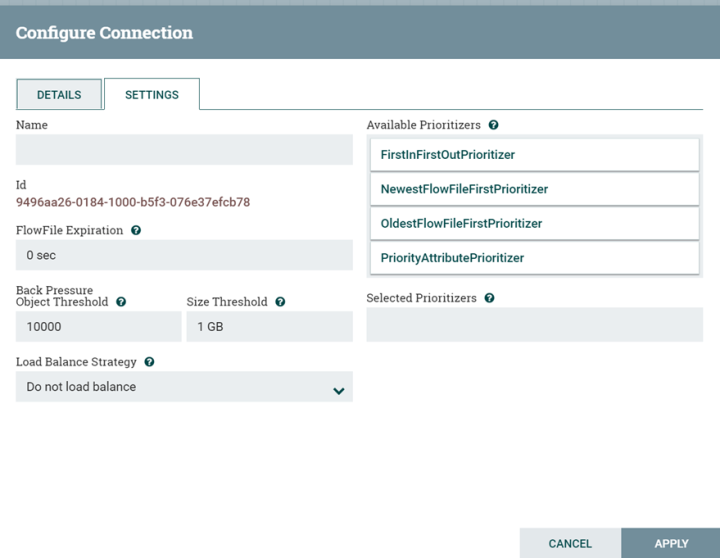
Connection用于连接不同处理器,它相当于一个队列,从上游传下来的数据来会进入这个队列,直到被下游组件把数据消费,Connection 可以配置不同的优先级策略,以及数据过期时间,存储容量等;
2.4 Processor group

用于将一组处理器组织在一起,外部数据可以通过 Nifi 端口组件进行输入输出,remote processor group 是用户接收远程进程的数据(Nifi 实例)。
2.5 Controller Service

它相当于是运行在后台的服务,我理解它的作用是把处理器要用到的一些公共属性抽取出来,比如连接数据库的 jdbc 连接池,kerberos 认证服务, 达到复用的目的。
✦ 03 SeaTunnel 与 Nifi 整合方案✦
3.1 Nifi Execute Process组件封装 SeaTunnel
第一种结合方式是可以用 Nifi 的 Execute Process 组件封装 SeaTunnel ,利用Nifi 的调度能力,使其可以定时运行 SeaTunnel 任务。通常想先要调度 SeaTunnel 任务,需要依赖像 Apache DolphinScheduler 或者其他的调度工具,现在 SeaTunnel 有个web平台(ui还在开发)也是把任务提交到 DolphinScheduler 去调度,使用 Nifi 在这里相当于提供了一种新的思路。
构建Nifi 工作流
将 SeaTunnel 和 Nifi 部署到一个节点上,可以通过 executeProcess 这个组件来运行 SeaTunnel 启动脚本, SeaTunnel 的运行日志会通过头节点传到下游组件,它可以通过这个投机节点,下游传播的日志里面会包含任务相关的一些信息。
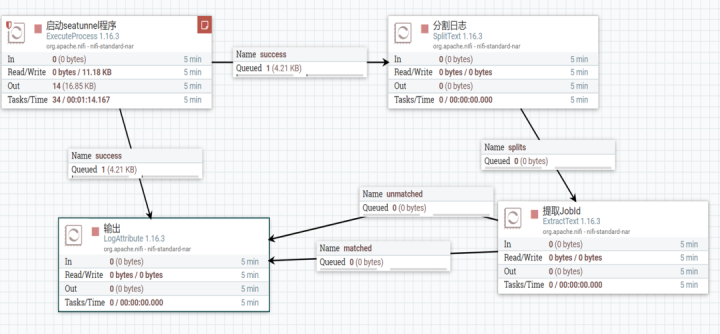
如果这个任务启动成功的话,我们可以过滤出它的任务 id,拿到任务 id 之后就可以进一步地对任务进行控制,比如封装停止任务,取消一些任务的接口功能。
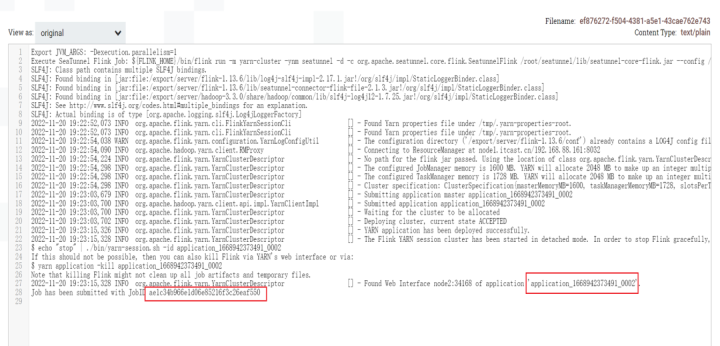
上图是在队列中查看到的 SeaTunnel 运行日志, SeaTunnel 启动成功之后可以在其中看到任务id,像 Flink job ID、 applicationID 都可以获取。
3.2 基于Nifi Site-To-Site 协议构建
SeaTunnel -Nifi -Connector
基于Nifi Site-To-Site 协议构建 SeaTunnel -Nifi -Connector
Nifi 实例之间的首选通信协议是 Nifi 站点到站点(S2S)协议。S2S可以轻松,高效,安全地将数据从一个 Nifi 实例传输到另一个实例,或者其他应用程序或设备中,通过S2S协议与 Nifi 进行通信。S2S中支持以 socket 的协议和 HTTP(S)协议作为底层传输协议.
Nifi 可以基于 Site-To-Site 协议与外部的 Nifi 节点或集群通信,也可以与外部的应用进行通信。该协议底层基于 socket 和 http 协议实现。可以利用 Nifi 的端口组件,从外部接收数据或者发送数据给外部系统。
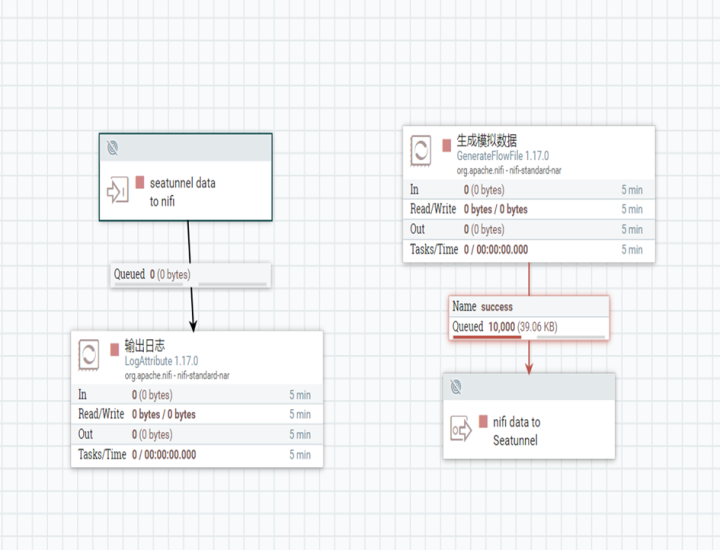
如图所示,左边这个流程是外部数据通过输入端口传到 Nifi ,右边这个是 Nifi 数据通过端口传到外部。
3.2.1 SeaTunnel Nifi Connector Sink

这个是我做的 SeaTunnel connector sink demo,基于 SeaTunnel flink v1 connector,目前还比较粗糙,所以还没提交到社区,后面完善了会提交。
因为 Nifi 的数据是流式的,首先我们实现 FlinkStreamSink 接口,重写 outputStream 方法来输出数据到Nifi ,需要在配置中指定 Nifi 的 url 以及目标端口,然后利用 Flink 内置的 Nifi Sink 组件来输出数据, Nifi 的数据结构实际上是由 content 和 attribute 组成,这里的 attribute 设成了空,实际上我们是可以按需将一些附加信息放到 attribute 中。这里 Nifi 用到了 Nifi data packet 数据结构,实际上底层是基于 Site To Site 协议进行一个实现。
3.2.2 SeaTunnel Nifi Connector Source
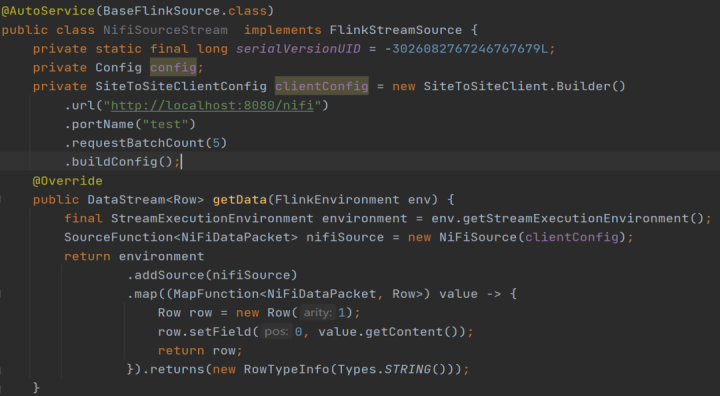
Nifi connector source 实现方式其实和sink差不多,是基于 Flink 的 Nifi Source 组成,通过 FlinkStreamSource 接口重写 getData 方法来实现。
对于基于 Spark 引擎的 Connector,也可以用类似的实现。
通过 SeaTunnel 的 Nifi Connector,Nifi 和 SeaTunnel 之间的数据就可以方便地传输,可以在一些场景下替代用kafka作为消息传输中间件的方案
✦ 03 天翼云数据集成平台 ✦
SeaTunnel V1与V2 Api处理流程对比
核心的 Connector 是基于 Apache Nifi 封装而成,原生的 Nifi 对于用户而言很不友好,用户的使用成本很高。
组件虽然多但是非专业人士也很难将其玩转,但是它的能力还很强大的,比如工作流编排,调度,统计监控,版本管理,血缘分析等能力都有,甚至 mini Nifi 还支持从边缘端采集物联网数据,因此我们就在原生的 Nifi 之上,做了大量的封装,开发了很多常见的数据集成应用。
我们的数据总线部分,底层采用 Flink 。Flink 消费 kafka 的数据来写入 hive 或者其他目标。而上层的应用中,会封装 Connector 发送数据到 kafka,再由数据总线写入数据中台的数仓之中的任务,接收 Kafka 数据,写入到数据中台中。
✦ ✦✦ ✦✦ ✦✦ ✦
在探索过程中,我们也考虑引入 SeaTunnel ,**引入 SeaTunnel 有什么好处呢?**首先 SeaTunnel ,它是可以补足原有系统的一些 cdc 能力的。
1、因为 Nifi 的 cdc 组件仅支持 mysql 数据源,cloudera 官方也不推荐用 Nifi 做 cdc,即便是 Nifi 提供了二次开发能力,用 Nifi 定制 cdc 组件从开发成本上而言也不够经济。
2、正好 SeaTunnel 是一个轻量级的工具,支持的组件类型丰富,且依托于 Flink 生态,适合 cdc 的场景。另外,我们的数据总线部分,设计之初只是想服务于中台产品的内部数仓 hive,在新版本中后面也希望能够支持写入更多的目标,同时还希望能够做些简单的 ETL。
当然,我们可以自己通过开发更多的 Flink 程序来满足这种需求,但是发现 SeaTunnel 只要进行简单地对解析配置的部分改造,就可以整合到我们原有的体系之中。
✦ ✦ ✦ ✦ ✦ ✦ ✦ ✦
基于这两点,我来说说我们是如何做的。
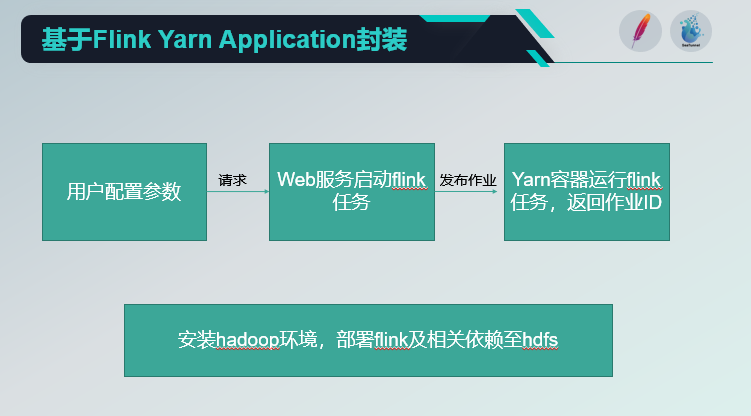
这是整个数据平台的业务调用逻辑,用户在前端填写好配置参数之后,参数被发送到 web 服务上, web 服务用 Flink Yarn API 起一个 Flink 应用。
当然在这之前,我们需要部署好 Hadoop 等相关环境,以及 Flink 需要依赖相关的包传到 HDFS 上面。
那我们怎么把最开始的 Flink 程序改造成 SeaTunnel 内核的呢?总共有6个步骤!
1.main 函数将 args 参数组织成 map;
2.FlinkCommandArgs 增加 map 类型的成员变量;
3.FlinkApiTaskExecuteCommand 接收 FlinkCmmandArgs ,在 execute()中,设法传入 map 给 ConfigBuilder;
4.修改 SeaTunnel -core-base中的ConfigBuilder ,增加 loadByMap方法 ;
5.loadByMap 方法内部调用 ConfigFactory.parseMap 方法,返回 Config ;
6.重新打包 SeaTunnel-core-flink 模块;
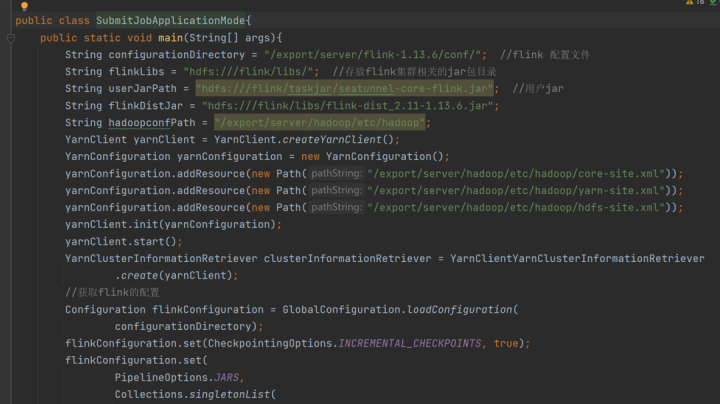
这个图是一个简单的 demo ,首先可以配置 SeaTunnel -core-flink.jar ,把它放在 HDFS 上的一个路径替换原有的 app ,替换相关的 lib 将用到的 SeaTunnel 插件也放到 lib 目录下。
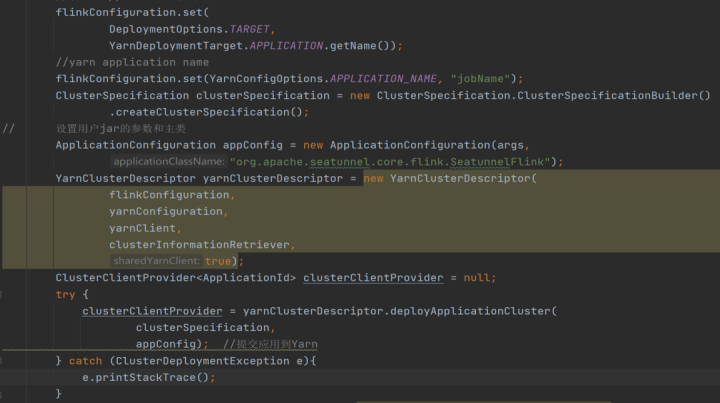
我这里改的是程序运行的一个主类,把它改成org.apache.seatunnel.core.flink.SeatunnelFlink,这样就可以替换掉原生数据总线部分 Flink 的部分。
另外一种形式是Nifi 可以二次开发来封装 SeaTunnel 组件,最后结果是生成 nar 包(类似于 jar 包),放置于 Nifi 的 lib 目录下即可生效。生成的组件可以于Nifi 其他组件进行连接。这种方式与之前提到的用executeProcess组件来启动 SeaTunnel 不同,它可以达到更深层次的定制。比如重新 Nifi 处理器的 onStop 方法,来控制 Spark 或者 Flink 任务的停止,或者重写 OnTrigger 方法来处理数据,也可以定义新的连接关系来处理异常数据。
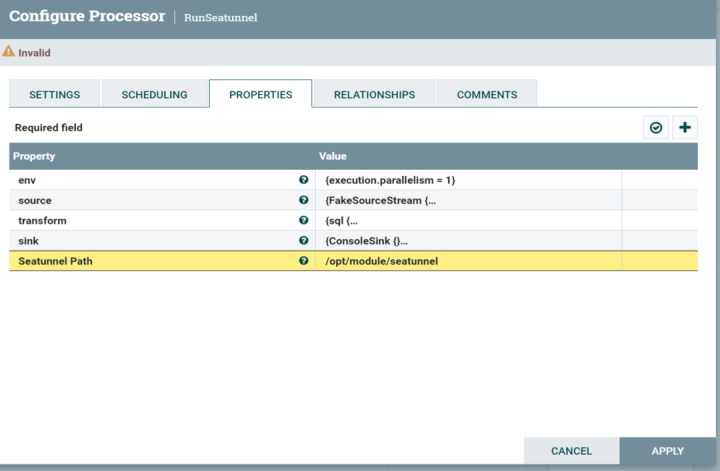
这个组件展示出来效果如图所示。它可以把 SeaTunnel 所需要的环境信息,传到组件里面去,同时可以定自定义组件上的 SeaTunnel 的参数,包括env,source,transform,sink,也可以针对不同的数据源类型再对 参数细分,而这些参数通过 Nifi api是很容易从前端传给 Nifi 的,因此采用这种形式能够很容易地将 SeaTunnel 置于 Nifi 的体系内,使其两者能力结合。
✦ 04 参与开源经验与心得 ✦
在工具调研到参与到开源项目贡献的过程中,有过很多小故事,当然在这里要非常感谢 SeaTunnel 社区的同学们,他们非常热情,而且社区非常活跃,最开始也从公司的一些大佬那里听到他们对SeaTunnel的评价很不错。
我们团队看了官网的介绍之后,发现引入 SeaTunnel 可以为后续平台开发节省不少工作量,于是自己开始弄 demo 进行验证,也尝试开发了插件。正好碰上社区出了 “Connector ” 开发者激励计划,于是我就尝试把自己开发出的插件提交给社区。
第一次提交 PR 遇到的坑比较多,因为你想在开源社区提交代码,不仅需要在代码风格单元测试,还要遵守相关的 license ,这个过程中所有的代码检验花了大概四天的时间左右。
在社区的交流过程中,我开始加了社区运营人员的微信,运营小助手非常热情,有问题就直接会积极帮我协调,一起解决,我觉得这个氛围不管是对于用户还是贡献者,都是特别友好,体验也特别好的。
周老师的文章到这里结束了,感谢大家的阅读,也欢迎来社区跟技术同学取得交流,最后希望更多的同学加入到 SeaTunnel 社区,在这里不仅可以深切感受到Apache 的开源精神和文化,还能了解 Apache 项目的管理流程,学习到优秀的代码设计思想。
希望通过大家的努力,共同成长,将 SeaTunnel 打造成为顶级的数据集成平台。
Apache SeaTunnel
Apache SeaTunnel(Incubating) 是一个分布式、高性能、易扩展、用于海量数据(离线&实时)同步和转化的数据集成平台
仓库地址: https://github.com/apache/incubator-seatunnel
**网址:**https://seatunnel.apache.org/
**Proposal:**https://cwiki.apache.org/confluence/display/INCUBATOR/SeaTunnelPro
**Apache SeaTunnel(Incubating) 下载地址:**https://seatunnel.apache.org/download
衷心欢迎更多人加入!
我们相信,在**「Community Over Code」(社区大于代码)、「Open and Cooperation」(开放协作)、「Meritocracy」**(精英管理)、以及「**多样性与共识决策」**等 The Apache Way 的指引下,我们将迎来更加多元化和包容的社区生态,共建开源精神带来的技术进步!
我们诚邀各位有志于让本土开源立足全球的伙伴加入 SeaTunnel 贡献者大家庭,一起共建开源!
**提交问题和建议:**https://github.com/apache/incubator-seatunnel/issues
**贡献代码:**https://github.com/apache/incubator-seatunnel/pulls
订阅社区开发邮件列表 : dev-subscribe@seatunnel.apache.org
**开发邮件列表:**dev@seatunnel.apache.org
**加入 Slack:**https://join.slack.com/t/apacheseatunnel/shared_invite/zt-1cmonqu2q-ljomD6bY1PQ~oOzfbxxXWQ
关注 Twitter: https://twitter.com/ASFSeaTunnel
|








- 上一条: Rancher RFO 正式 GA 2022-12-26
- 下一条: vivo 游戏中心低代码平台的提效秘诀 2022-12-26
- 可视化任务编排&拖拉拽 | Scaleph 基于 Apache SeaTunnel的数据集成 2022-07-05
- SAP RFC 接口基于 SeaTunnel 开发实践,打通企业内部数据采集的最后一个壁垒 2022-09-09
- Apache SeaTunnel (Incubating) 2.1.0 发布,内核重构、全面支持 Flink 2022-03-22
- 对话来自韩国 Kakao 的海外贡献者 | 我为什么要为 SeaTunnel 做贡献? 2022-09-20
- 马蜂窝毕博:分析完这9点工作原理,我们最终选择了 Apache SeaTunnel! 2022-11-04


