马蜂窝毕博:分析完这9点工作原理,我们最终选择了 Apache SeaTunnel!
点亮 ⭐️ Star · 照亮开源之路
https://github.com/apache/incubator-seatunnel

讲师简介

毕博 马蜂窝 数据工程师
在10月15日,Apache SeaTunnel& IoTDB 联合 Meetup 期间,马蜂窝网数据工程师毕博给大家介绍了SeaTunnel的基本原理和相关企业实践思考、马蜂窝大数据开发调度平台典型场景下的痛点和优化思考,并分享了个人参与社区贡献的实践经验,希望同时能帮助大家快速了解SeaTunnel及参与社区建设的路径和技巧。
✦SeaTunnel的技术原理简介✦
SeaTunnel 是一个分布式、高性能的数据集成平台,用于海量数据(离线和实时)的同步和转换
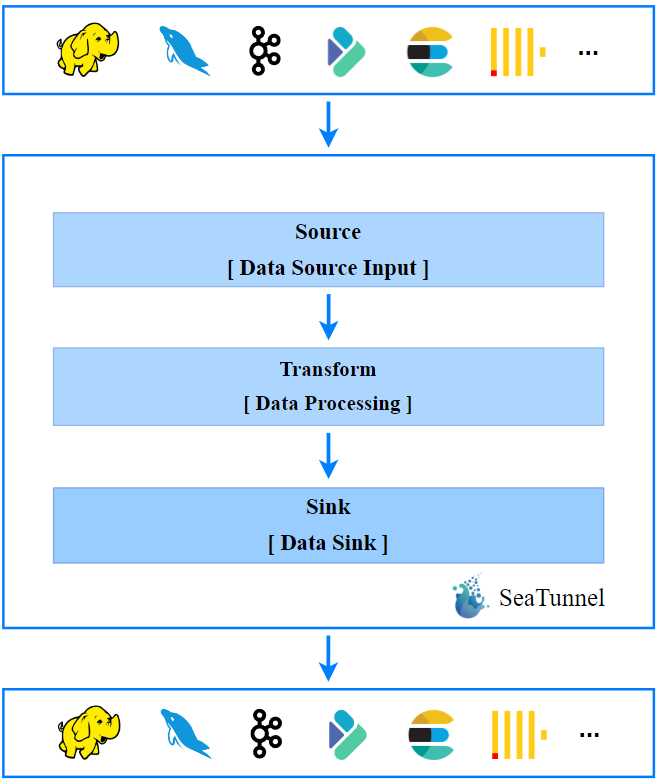
上面这张图展示的是 SeaTunnel 的工作流程,简单来说包含3个部分:输入、转换、输出;更复杂的数据处理,也无非是几种行为的组合。
**以一个同步场景为例,**比如将 Kafka 导入到 Elasticsearch ,Kafka 就是 流程中的 Source ,而 Elasticsearch 就是流程中的 Sink 。
如果在导入的过程中,字段列跟待写入的外部数据列不匹配需要做一些列或者类型的转换,或者需要多数据源的 Join,然后做一些数据打宽,扩展字段等处理,那么在这个过程中就需要增加一些 Transform,对应图片中间的部分。
由此可见 SeaTunnel 核心的部分就是 Source、Transform 和 Sink 流程定义。
在 Source 里面我们可以定义需要的读取数据源,在 Sink 定义数据 Pipeline 最终写出的外部存储,可以通过 Transform 进行中间数据的转换,可以使用 SQL 或者自定义的函数等方式。
1.1 SeaTunnel 连接器API V1版本 架构剖析
对于一个成熟组件框架来说,从设计模式到 API 的设计实现上,**一定有比较独特的地方,**从而使得框架有比较好的扩展性。
SeaTunnel的架构主要包括三部分:
1、SeaTunnel 基础 API ;
2、SeaTunnel基础 API 的实现;
3、 SeaTunnel 的插件体系;
1.2 SeaTunnel 基础API
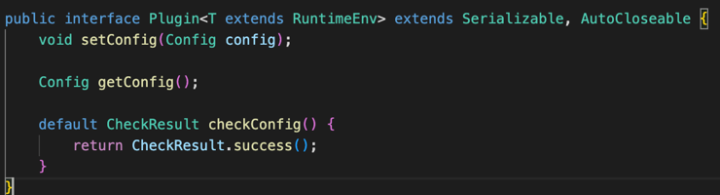
Plugin接口定义
上图为接口定义,Plugin 接口在 SeaTunnel 将数据处理的各种行为都抽象为 Plugin 。
下图的5个部分 Basesource、Basetransfform、Basesink、Runtimeenv和Execution 都继承了 Plugin 接口。
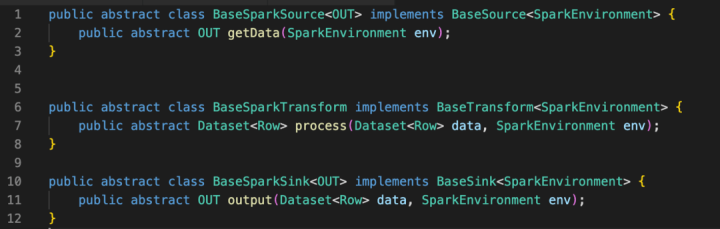
basesource、basetransfform、basesink接口定义
作为流程定义插件,Source 负责读数据,Transform负责转换,Sink 负责写入,Runtimeenv 是设置基础的环境变量。
SeaTunnel 基础 API 整体部分如下图
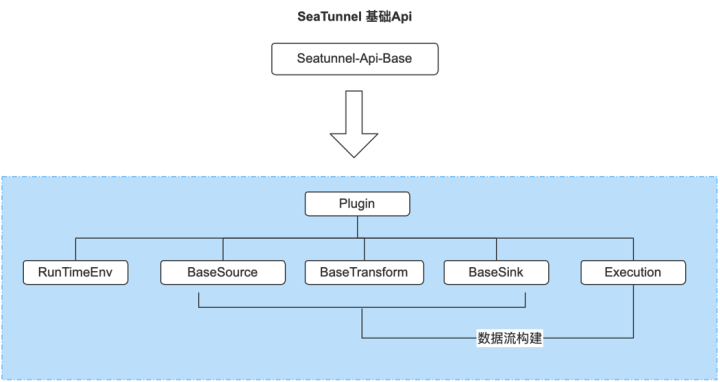
基于前三者用来构建整个数据流程的数据流构建器 Execution 也是基础 API 的一部分

Execution接口定义
1.3 SeaTunnel 基础API 实现
基于前面基础 API,SeaTunnel 分别针对不同计算引擎做了封装实现,目前有 Spark API 抽象和 Flink API 抽象,这一部分在逻辑上完成了数据 Pipeline 的构建流程。
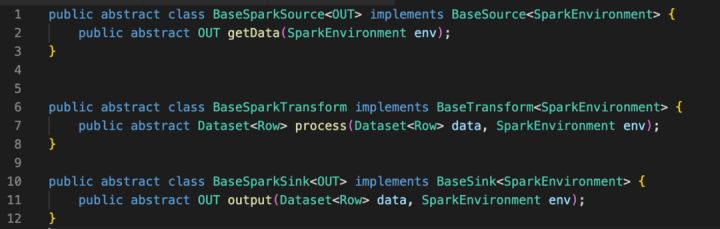
由于篇幅有限,这里主要以 Spark 批处理重点介绍。基于对前面基础 Api 的封装实现,首先是 Base spark source 实现了 Base source ,base Spark transform 实现了 Base transform , Base Spark sink 实现了 Base sink 。
方法定义中以 Spark 的 Dataset 作为数据的载体,所有的数据处理都是基于 Dataset ,包括读取、处理和导出。
其中关于 SparkEnvironment , 内部是将 Spark 的 Sparksession 封装在 Env 里面,方便各个插件使用。

上图是 SeaTunnel 基础Api 实现
Spark 批处理最后是 SparkBatchExecution(数据流构建器),图中截取了核心的代码片段,从功能上用来构建我们的数据流 Pipline ,也就是下图中左边最基础的数据流。

基于用户的对每一个流程组件的定义也就是 Source Sink、Transform 的配置。可以实现比较复杂的数据流的逻辑,例如多数据源 Join、多 Pipline处理等,都可以通过 Execution 来构建。
1.4 SeaTunnel 连接器 V1 API架构总结
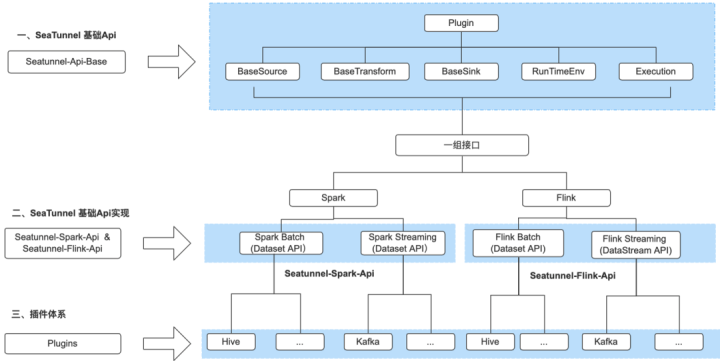
SeaTunnel 的 API 主要包括三个部分:
第一部分是 SeaTunnel 基础 API ,提供了 Source、Sink、Transform、Plugin 等基础抽象接口。
第二部分是基于 SeaTunnel 基础 API 提供的一组接口Transform、Sink、Source、Runtime、Execution ,在 Flink 和 Spark 引擎的上分别做了相关封装和实现,也就是 Spark 引擎 API 层抽象和 Flink 引擎 API 层抽象。
Flink 和 Spark引擎都是支持流处理和批处理,因此 Flink API 抽象和 Spark 抽象 API 下还分别对应流/批的不同使用方式,如 Flink抽象 API 下游 Flinkstream 和 Flinkbatch,Spark 抽象 API 下有 Sparkbatch 和 Sparkstreaming 。
第三部分是插件体系,基于 Spark 抽象和 Flink API抽象,SeaTunnel 引擎实现了丰富的连接器和处理的插件,同时对于开发者也可以基于不同引擎 API 抽象、扩展实现自己的 Plugin 。
1.5 SeaTunnel 执行原理
目前SeaTunnel 提供 Flink、Spark 、FlinkSQL 多种使用方式,由于篇幅有限,介绍关于使用 Spark 方式的执行原理。
首先入口通过 Shell 启动命令 Start-seatunnel-spark.sh ,内部会调用 Sparkstarter 的 Class ,Sparkstarter 去对 Shell 脚本传递参数进行解析,同时还会解析 Config 文件,从而判断 Config 文件定义了哪些 Connector , 比如 Fake、Console等。

然后从 Connector plugin 目录去找对应的 Connector 路径,通过--jar拼接到 Spark-submit 启动命令里面,这样可以把找到的 Plugin jar 包作为依赖传递到 Spark cluster 。
对于 Connector plugin 来说,Spark的 Connector 所有的 Connector 都会统一打包到发行包的 plugin 目录里面(这个目录做统一管理)。
执行 Spark-submit 后,任务提交到Spark cluster ,Spark 作业的 Driver 的 Main class 通过数据流构建器 Execution 并结合 Souce、Sink、Transform,来构建数据流 Pipline ,至此整个链路串联起来了。
1.6 SeaTunnel 连接器V2 API架构
在社区最新发布的 SeaTunnel 2.2.0-beta 版本中,已经完成对 Connectorapi 重构,也就是现在的SeaTurnelV2 API !
我们为什么要重构?
因为目前的 Container 是强耦合引擎的,也就是 Flink 和 Spark API ,假如对 Flink 或者是 Spark 引擎升级的话,Connector 也要进行调整,可能是参数或接口的改动。
这会导致开发一个新的 Connector 需要针对不同引擎多次实现,并且参数是不统一的。所以基于这些痛点,社区进行了 V2 版本 API 的设计和实现。
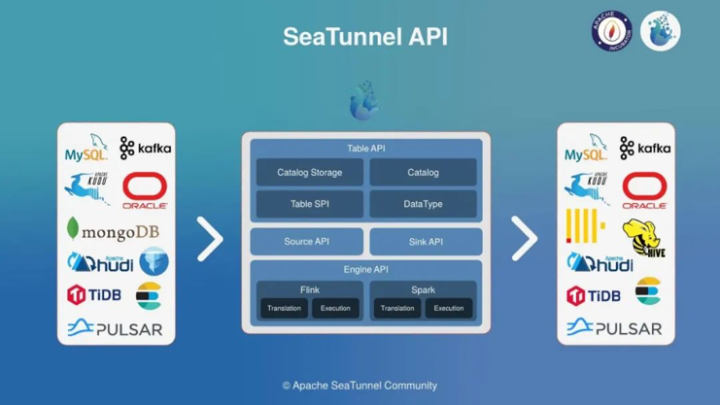
SeaTunnel V2 API 架构
Apache SeaTunnel(Incubating) API总体结构的设计如上图,分为4个部分;
1、Table API
-
DataType:定义SeaTunnel的数据结构SeaTunnelRow,用于隔离引擎
-
Catalog:用于获取Table Scheme、Options等;
-
Catalog Storage: 用于存储用户定义 Kafka 等非结构化引擎的 Table Scheme 等;
-
Table SPI:主要用于以 SPI 的方式暴露 Source 与 Sink 接口
2、Source & Sink API
定义 Connector 的核心编程接口,用于实现 Connector
3、Engine API
-
Translation: 翻译层,将Connector 实现的 Source 和 Sink API 翻译成引擎内部可运行的 API;
-
Execution: 执行逻辑,用于定义Source、Transform、Sink等操作在引擎内部的执行逻辑;
其中Source & Sink API 是实现连接器的基础 ,对于开发者来说是非常重要的。
下面着重介绍v2版本 Source & Sink API 的设计
1.7 SeaTunnel 连接器V2 Source API
SeaTunnel 当前版本的 API 设计借鉴了一些 Flink 的设计理念, Source API 比较核心的类如下图:

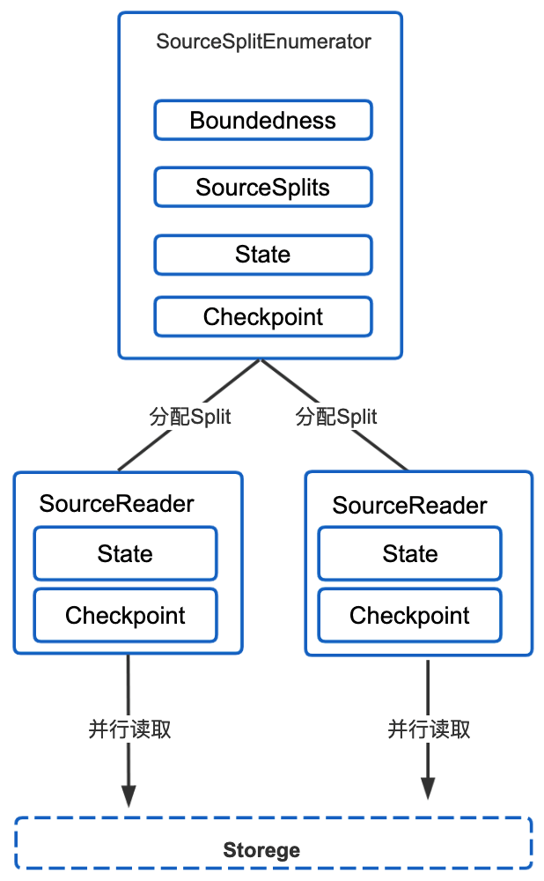
Source API 核心交互流程如上图,在并发读取的情况下,需要枚举器 SourceSplitEnumerator 实现任务的拆分,将SourceSplit下发给 SourceReader,Reader 接收这个 Split 并用于读取外部数据源。
同时为了支持断点续传和 Eos 语义,需要进行状态的保存和状态的恢复,例如在每一个 Reader 里通过Checkpoint state 和 Checkpoint 机制保存当前Reader的 Split 消费状态和失败后通过状态进行恢复,保证能从能从失败的地方继续读取数据。
1.8 SeaTunnel 连接器V2 Sink API

整体 Sink API交互流程如下图,目前 SeaTunnel sink设计支持分布式事务,基于两阶段事务提交。
首先 SinkWriter 持续去像外部数据源写数据,然后在引擎做 Checkpoint 的时候,会触发第一阶段提交。
SinkWriter 需要做 Prepare commit ,这是第一阶段提交。
同时会返回 Commit info 给引擎,引擎会去判断是否所有的 Wirter 的第一阶段都能成功, 如果都成功,引擎会结合 Subtask 的 Commit info 并通过 Commiter 的Commit 方法,去做实际的事务提交,去操作数据库进行 Commit 也就是第二阶段的提交。
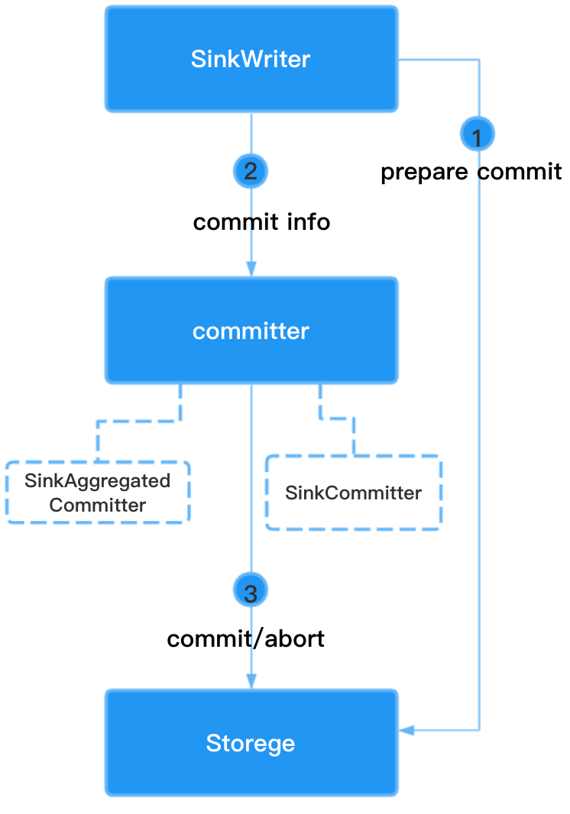
Sink API交互流程
对于 Kafk sink connector 实现来说,第一阶段通过调用 KafkaProducerSender.prepareCommit()去做预提交。
第二段提交通过 Producer.commitTransaction(); 进行事务提交。再通过 Producer.flush();将 Broker 端系统缓存的数据数据,强制刷新到磁盘.
最后值得注意的是!
SinkCommitter和 SinkAggregatedCommitter都可以进行第二阶段提交替换图中 Commiter 的位置,区别在于 SinkCommitter 只能做单个 Subtask 的 CommitInfo 的部分事务提交,有可能部分成功部分失败,不能全局处理。
SinkAggregatedCommitter 是单并行,汇总所有 Subtask 的 CommitInfo,可以整体做第二阶段提交,要么都成功要么都失败,可以避免阶段二部分失败导致状态不一致的问题。
所以建议优先使用 SinkAggregatedCommitter。
1.9 SeaTunnel V1与V2 API处理流程对比
我们可以从数据处理角度看 V1 V2 升级前后的变化,这样更为直观,**Spark批处理为例:**SeaTunnel V1:整个数据处理过程都是基于 Spark dataset API 的 ,并且 Connector 和计算引擎强耦合。

SeaTunnel V2: 得益于引擎翻译的工作,在数据转换时,通过翻译层将 Connector API 和通过连接器接入的 SeaTunnel 内部数据结构的数据源 SeaTunnelRow ,翻译成引擎内部可识别可运行的Spark api和spark dataset 。
在数据写出时,通过翻译层将 Spark API 和 Spark dataset 翻译为 SeaTunnel 连接器内部可执行的连接器 API 和可以使用的 SeaTunnel 内部结构的数据源。
✦ ✦✦ ✦✦ ✦✦ ✦
总体来说,在 API 层和计算引擎层增加了翻译层,实现了 Connector API 和引擎的解耦,Connector 实现不再依赖于计算引擎,使扩展和实现更加灵活。
从社区规划来看,后面发展会以 V2 API为主,更多的功能特性会在V2上支持,V1 趋于稳定不再维护,因此建议开发者和使用者将重心放在新版 API 上。
✦离线开发调度平台实践思考✦
2.1 离线开发调度平台简介
马蜂窝大数据开发平台,主要是提供一站式大数据开发与调度服务,帮助业务解决离线场景下数据开发管理、任务调度、任务监控等复杂问题。
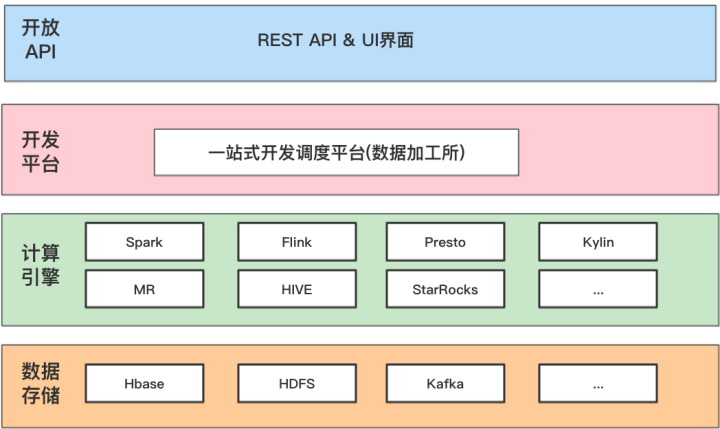
从定位看离线开发调度平台主要起到承上启下的作用,呈上就是提供开放接口 API 和 UI 对接各个数据应用平台以及业务,启下就是驱动各个计算 、存储,然后按照任务的依赖关系和调度时间有条不紊的运行。
平台能力
-
数据开发 任务配置、质量测试、 发布上线
-
数据同步 数据接入、数据加工、数据分发
-
调度能力 支持定时调度、触发式调度
-
运维中心 作业诊断、任务运维、实例运维
-
管理 库表管理、权限管理、API管理、脚本管理
概括来说,离线开发调度平台核心能力体现为开放能力、通用性、一站式。通过标准化流程,对整个任务开发周期进行管理、提供一站式的服务体验。
2.2 离线开发调度平台架构
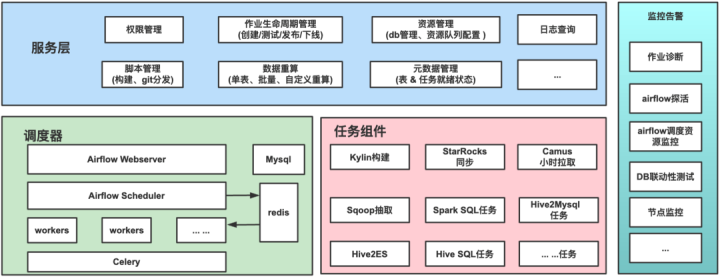
马蜂窝大数据开发调度平台主要由任务组件层、调度层、服务层和监控层4个模块组成。
服务层主要负责作业的生命周期管理(如作业的创建、测试、发布、下线);airflow dagphthon文件构建生成,任务血缘依赖管理,权限管理、api(提供数据就绪、任务执行状态的查询);
调度层是基于 Airflow的 ,负责所有离线任务的编排调度;
任务组件层,使用户可以通过已支持的组件进行数据开发,这些组件包括 SparkSQL/、HiveSQ、LMR)、StarRocks 导入等工具,直接对接底层HDFS、MySQL等存储系统;
监控层负责对调度资源、计算资源、任务执行等进行全方位监控和预警。
2.3 开放数据同步能力场景
开放能力下的挑战: 需要支持多业务场景,满足灵活数据 Pipline 需求(即扩展支持更多的任务组件,如hive2clickhourse、clickhourse2mysql 等)
基于 Airflow 扩展任务组件: 扩展维护成本比较高,需要降本增效(基于 Airflow 提供的providers有限,从使用需求上不太适用,Airflow 是 Python 技术栈,而我们团队主要以 Java 技术栈为主,所以技术栈差异带来的是较高的迭代成本)
自研任务组件: 平台融合成本高、开发周期长、任务组件使用配置成本高。(调研或自己实现任务组件,在服务层针对组件的参数进行不同方式的适配,没有的统一的参数配置化方式)
我们希望调研一款数据集成工具,首先支持的组件要丰富,提供开箱即用的能力,易扩展、提供统一的参数配置化和统一使用方式方便平台集成和维护。
2.3.1 数据集成工具的选型

为了解决上面提到的痛点,我们积极探索寻求解决方案,对多个业界主流数据集成产品进行选型分析。从上图的对比可以看出,Datax 和 SeaTunnel 提供了都具有扩展性好、高稳定性的特点,支持丰富的连接器插件,提供了脚本化、统一配置化的使用方式,并且社区活跃也很高。
但是Datax受限于受限于分布式,在海量数据场景下不太适合。相较而言,SeaTunnel 可以提供分布式执行、分布式事务的能力,能够处理的数据量级可扩展,还具有在数据同步场景下的统一技术解决方案的能力。
除了上面介绍的优势特点及适用场景,更重要的是目前大数据的离线计算资源统一由yarn来管理,对于后续扩展的任务也希望在 Yarn 上执行,最终针对我们的使用场景,我们倾向于SeaTunnel。
后期我们可能会对 SeaTunnel 进行进一步的性能测试和数据开放调度平台集成 SeaTunnel 的开发工作,逐步推广使用。
2.4 出仓场景:Hive数据同步到StarRocks
简单介绍一下背景,目前大数据平台完成 OLAP 引擎层的统一,使用 StarRocks 引擎替换了之前的 Kylin 引擎,作为 OLAP 场景下的主要查询引擎。
在数据加工过程中,数据通过数仓建模后,需要将上层模型导入到 OLAP 引擎中,进行查询加速,因此每天会有大量的任务将数据从 Hive 推送到 StarRocks 里面,目前我们方式是通过前置任务将 ETL 后的数据 Load 到 Hive 临时表,再通过 Hive2StarRocks 任务(基于StarRocks Broker Load导入方式的封装)批量导入到 基于 StarRocks 表中。
当前痛点有两个:
-
数据同步链路长: Hive2StarRocks加工链路,至少需要两个任务,相对来说比较冗余。
-
出仓提效: 从出仓提效的角度看,很多Hive模型本身通过Spark SQL进行加工,基于加工之后 内存中的Spark Dataset 可以直接推送到StarRocks里面不进行落盘,提升模型的区域时间。
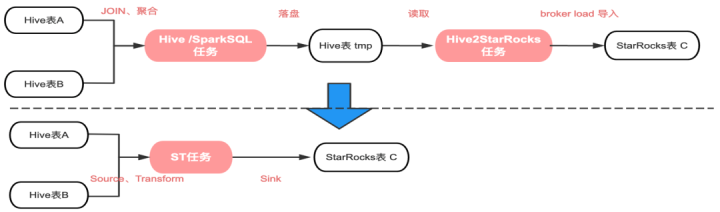
StarRocks 目前也是支持 Spark Load,基于Spark批量导入数据方式,但是我们etl比较复杂,需要支持数据转换多表Join、 数据聚合运算等,所以暂时不能满足。
从SeaTunnel 社区了解到,目前有计划支持 StarRocks Sink Connector,同时我们也在做这部分工作,所以后面会跟社区持续沟通共建。
✦如何参与社区建设✦
3.1 SeaTunnel 社区贡献
前面提到了,社区完成了V1 到 V2 API的重构,需要在基于V2版本 连接器API 去实现更多的连接器的插件,我有幸参与其中去贡献。
我目前负责大数据基础架构的工作,很多主流的大数据组件大数据也在使用,所以当社区提出 connector 的 isuue 后,自己也是非常感兴趣。
因为平台也在调研 SeaTunnel ,并且通过学习并能向社区贡献 pr 也是了解 SeaTunnel 的一种很好的方式。
因为我刚入社区, 所以前期选择了由易到难的方式,我记得最开始提了一个难度比较低的 pr,实现 wechat sink connector,但是在贡献的过程中遇到了很多问题,编码风格不好,出现 codestyle 没有考虑到扩展支持丰富输出格式等情况,虽然过程没那么顺利,但是当 pr 被 mrege 后,真的非常兴奋并且有成就感。
在逐渐熟悉了整个流程之后,我提交 pr 的效率提高了很多,也有信心尝试高难度的 issue 。
3.2 如何快速参与社区贡献
Goodfirst issue
Goodfirst issue #3018 #2828 如果你是第一次参加社区贡献的话,建议先关注Goodfirst issue,因为这里面基本上都是比较简单并且对新人比较友好的 issue。
通过Good first issue,可以去熟悉参与githup 开源社区贡献的整个流程,比如首先 fork 项目,然后再把改动提交上去,最后再提交 pull request,等待社区同学review,社区的同学会针对性给你提出一些改善建议,直接会在下面留言,直到当你的 pr 被 merge 进去,这就走完了一个完整的贡献的流程,你在这个过程中也会学习到很多东西。
订阅社区邮件
对贡献 pr 的流程熟悉之后,你可以订阅社区邮件,实时的了解社区动态,比如社区当前在做什么功能、后续规划迭代的事情是什么?如果对某个功能感兴趣,可以结合自己的情况,就可以参与到贡献中来啦!
熟悉git使用
开发中,常用的git 命令主要包括 git clone、git pull、git rebase和git merge。在社区开发规范中,推荐使用git rebase ,相较于git merge不会产生额外的commit 提交记录.
熟悉github项目协作流程
开源项目是多人协作开发的,github上的协作方式 核心概括 fork 例如apache st项目,他在apache空间下面, 首先要把项目fork 到我们githup自己的空间下面
然后修改实现,提一个pull request,提交的pullrequest 要关联到issue,在提交时,如果我们改了很久,在往上提交的话,目标分支有很多新的的commit尽来这个时候需要我们做一个pull& merge或者 rebase 。
源码编译项目
熟悉源码编译很重要,通过本地源码编译,可以证明 项目添加的代码 是可以编译通过,可以在提交pr前做一个初步的检验。还有就是源码编译一般比较慢,可以使用 mvn -T 多线程并行编译加速.
编译检查
编译前检查相关包括**Licence header 、Code checkstyle、Document checkstyle,**这些在 Maven 编译期间都会去检查,并且失败的话 CI 是不能通过的.所以建议在 idea 中使用一些插件工具进行提效,例如 Code checkstyle 有自动检查代码规范的插件、Licence header 可以在 idea 添加代码模板,这些之前有社区同学也有分享过怎么做!
添加完整的E2E
添加完整的E2E测试 ,并保证在 Pull request 之前E2E是通过的,通过E2E可以测试你添加的功能、减少社区 Code review 成本,同时提高你贡献PR效率
我的分享到这里结束了,感谢大家的阅读,也欢迎来社区跟我取得交流,最后希望更多的同学加入到 SeaTunnel 社区,在这里不仅可以深切感受到Apache 的开源精神和文化,还能了解 Apache 项目的管理流程,学习到优秀的代码设计思想。
希望通过大家的努力,共同成长,将 SeaTunnel 打造成为顶级的数据集成平台。
Apache SeaTunnel(Incubating) 是一个分布式、高性能、易扩展、用于海量数据(离线&实时)同步和转化的数据集成平台
仓库地址: https://github.com/apache/incubator-seatunnel
**网址:**https://seatunnel.apache.org/
**Proposal:**https://cwiki.apache.org/confluence/display/INCUBATOR/SeaTunnelProposal
衷心欢迎更多人加入!
能够进入 Apache 孵化器,SeaTunnel(原 Waterdrop) 新的路程才刚刚开始,但社区的发展壮大需要更多人的加入。我们相信,在**「Community Over Code」(社区大于代码)、「Open and Cooperation」(开放协作)、「Meritocracy」**(精英管理)、以及「**多样性与共识决策」**等 The Apache Way 的指引下,我们将迎来更加多元化和包容的社区生态,共建开源精神带来的技术进步!
我们诚邀各位有志于让本土开源立足全球的伙伴加入 SeaTunnel 贡献者大家庭,一起共建开源!
**提交问题和建议:**https://github.com/apache/incubator-seatunnel/issues
**贡献代码:**https://github.com/apache/incubator-seatunnel/pulls
订阅社区开发邮件列表 : dev-subscribe@seatunnel.apache.org
**开发邮件列表:**dev@seatunnel.apache.org
**加入 Slack:**https://join.slack.com/t/apacheseatunnel/shared_invite/zt-1cmonqu2q-ljomD6bY1PQ~oOzfbxxXWQ
关注 Twitter: https://twitter.com/ASFSeaTunnel
|








- 上一条: 如何通过机器学习赋能智能研发协作? 2022-11-04
- 下一条: 马蜂窝毕博:分析完这9点工作原理,我们最终选择了 Apache SeaTunnel! 2022-11-04
- Apache SeaTunnel (Incubating) 2.1.0 发布,内核重构、全面支持 Flink 2022-03-22
- 可视化任务编排&拖拉拽 | Scaleph 基于 Apache SeaTunnel的数据集成 2022-07-05
- 对话来自韩国 Kakao 的海外贡献者 | 我为什么要为 SeaTunnel 做贡献? 2022-09-20
- SAP RFC 接口基于 SeaTunnel 开发实践,打通企业内部数据采集的最后一个壁垒 2022-09-09
- 从启动到关闭 | SeaTunnel2.1.1源码解析 2022-10-08


