【案例回顾】春节一次较波折的MySQL调优
春节长假某日,阳光明媚,春暖花开,恰逢冬奥会开幕,想着一定是一个黄道吉日,必能顺风顺水。没想到却遇到一个有点小波折的客户报障。
01
故障起因
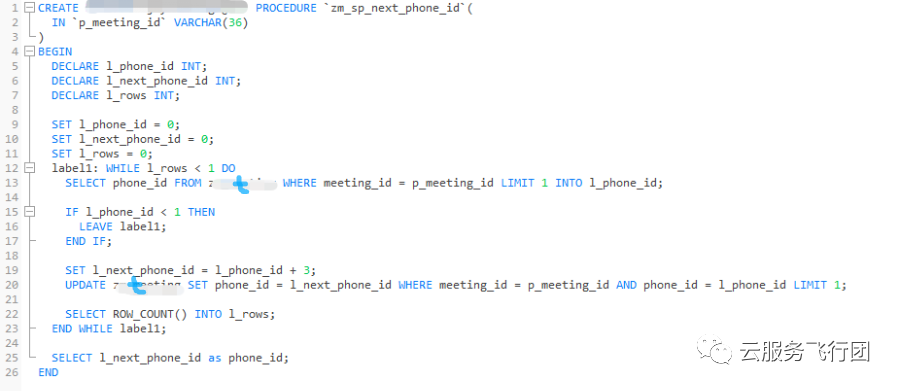
故障起因是客户前一天从自建MySQL迁移到云上RDS,在执行某个并发较高的业务时出现了大量锁等待,客户当时升级了实例到最高规格,但故障依旧。客户反馈升级后的实例规格比自建实例高了一倍,自建实例上从未发生过类似情况。后客户根据当时的业务故障模拟了现场,主要是并发执行如下存储过程的时候性能很差:
02
初步诊断
从存储过程的逻辑看,比较简单,主要涉及两个SQL,一个从表t(隐藏了真实表名)中meeting_id根据传入参数值查询,具体的入参由字符型变量p_meeting_id带入;另外一个根据meeting_id和刚查出的phone_id去更新t中的phone_id为phone_id+3。表t数据量约40w左右。
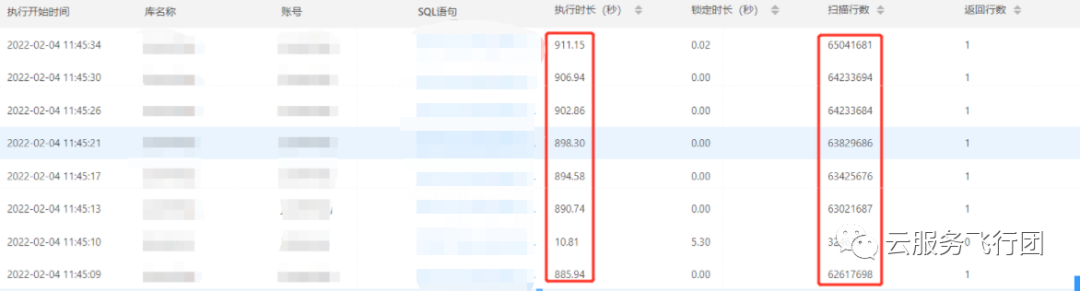
第一感觉这是个简单问题,估计两个SQL的meeting_id索引没有生效,查询表上索引后果然发现meeting_id和phone_id上没有索引,建议客户在两个字段上分别创建了索引,且meeting_id为主键。此时用户执行模拟的并发脚本反馈速度有了明显提升,200个并发最高执行时间40s左右,但模拟500个并发的时候,超过了8分钟还没有执行完。用户反馈在自建MySQL上并发500执行都是秒级完成。此时在控制台看,这个存储过程在慢查询日志中批量出现,且扫描行数巨大,客户端已经完全hang住:
03
进一步优化
虽然优化有了初步的效果, 但距离客户自建环境性能描述还差距很大,由于并发高, 从监控看测试期间CPU到了100%,怀疑参数innodb_thread_concurrency的设置可能不当。此参数的作用是控制 InnoDB 的并发线程上限。也就是说,一旦并发线程数达到这个值,InnoDB 在接收到新请求的时候,就会进入等待状态,直到有线程退出。RDS默认值为0,也就是没有限制上限,在高并发的场景下可能会产生较多的上下文切换,导致CPU升高。和客户咨询了一下,他们自建环境的值设置为32,建议他们将RDS的值也改为32再看看效果。客户很快反馈,修改后的确有效果,500个并发在3分钟内完成,没有再发生hang住不动的情况,性能有了进一步的提升。但参数innodb_thread_concurrency进一步调整效果不明显。
04
加trace诊断
客户看到性能不断提升也很有信心,但和自建环境差距还是很大,还有哪里可能有问题?突然想到,创建索引后,在控制台的慢查询列表中看到很多存储过程的调用sql,且扫描记录数巨大,如果是走meeting_id唯一索引,应该扫描很少的记录数才对,难道没有走索引?或者没有走meeting_id主键索引?联系客户,希望提供测试环境登陆测试。
在测试环境,首先希望验证一下两个SQL的执行计划到底是怎么样的。登陆实例后,分别对两个存储过程中的SQL执行explain,发现走的确实是主键(meeting_id):

为了进一步确认SQL在存储过程中的实际执行计划,修改了一下测试的存储过程逻辑,加入了SQL执行的explain结果和实际执行的trace,过程中主要增加的代码如下:

执行计划结果如下:

从结果看,两个SQL居然真的没有走主键meeting_id索引,而是都走了phone_id这个普通的二级索引,其中第一个查询SQL走的索引全扫描,扫描记录数rows为397399,和表的记录数一致,显然走了全索引扫描,虽然比全表扫描好一些,但效率仍然低下;另外一个update的SQL走了正常的索引扫描,rows只有2,性能高效。为什么两个SQL没有走meeting_id这个主键索引呢?看trace打印的部分内容:

trace显示两个SQL在优化器分析时,将meeting_id做了隐式转换,转换函数为convert('meeting_id' using utf8mb4),也就是将meeting_id做了字符集的转换,熟悉索引机制的同学都清楚,这种情况下优化器是不会走meeting_id索引的。这也可以解释了客户第一次创建索引的时候为啥有性能提升,但效果并不明显,原因就是只有update语句真正用到了索引带来的性能提升,而且是phone_id索引带来的提升,不是性能更高的主键meeting_id。
05
真相大白
现在聚焦到最关键的问题,meeting_id为啥要做字符集的隐式转换?查看了一下实例相关字符集的设置:
- 表和列的字符集都为utf8;
- 表所在库的字符集为utf8mb4;
- server字符集((character_set_server))为utf8
- character_set_client/character_set_connection/character_set_results为utf8mb4
果然,server、database、table的字符集不完全一致,猜想一下实际流程应该是这样的:存储过程中传入的字符参数字符集为utf8mb4,和表中字符集为utf8的字段meeting_id比较时,meeting_id做了字符集的隐式转换,转换为utf8mb4后再和输入参数比较,从而导致meeting_id上的索引无法使用。
根据这个猜测,建议用户将表的字符集更改为utf8mb4,这样应该可以避免字符集的转换。由于这个功能还未上线,用户直接对 表做了字符集的修改:
alter table zm_meeting convert to character set utf8mb4;修改后让用户再次测试,预期效果终于出现,并发500测试在秒级完成,trace查看执行计划,都走了meeting_id的主键索引,隐式转换也随之消失,性能问题得到了彻底解决。
06
后续思考
存储过程的入参为啥使用了utf8mb4?这是本次案例的核心,查阅mysql文档,存储过程介绍里面有一段描述:

简单说,就是存储过程的字符型参数,如果没有显式指定字符集,默认将会使用所在数据库的字符集,而本案例中表所在的数据库字符集为utf8mb4,所以参数默认使用了utf8mb4,导致了匹配过程的隐式转换。存储过程外直接写SQL为什么没有这种情况发生,我猜测比较的字符串应该会自动匹配‘=’左边表字段的字符集。
既然这样,理论上直接修改参数的字符集应该也可以达到同样结果,简单测试下,将存储过程参数加上表上的字符集属性:
CREATE PROCEDURE `zm_sp_next_phone_id`(IN `p_meeting_id` VARCHAR(36) character set utf8)测试结果如我们预期,不会产生隐式转换,执行计划正确。
问题虽然解决了,原因也找到了,但反思一下整个过程,如果用户的server、库、表字符集能够保持一致,将完全可以避免这个故障。与字符集相关的类似故障也可以大概率避免,所以客户侧还是要有一定的设计规范;产品侧如果有一定的检查规则可以帮客户发现类似的隐患,对提升客户体验也是一种很有价值的服务。
作者:翟振兴
|








- 上一条: 深度干货!一篇 Paper 带您读懂 HTAP | StoneDB 学术分享会第①期 2022-08-31
- 下一条: K8S优雅升级系列(中) | 如何“优雅”滚动发布?看这篇就够了 2022-09-01
- 一次“不负责任”的 K8s 网络故障排查经验分享 2021-06-27
- MySQL 表数据多久刷一次盘? 2022-04-07
- RocketMQ调优心得总结 2021-07-23
- 一次 MySQL 误操作导致的事故,高可用都不顶不住! 2022-06-24
- 【案例分享】一次客户需求引发的K8S网络探究 2022-08-22


