MatrixCube揭秘101——MatrixCube的功能与架构
作为新一代的数据库系统,MatrixOne也是以当今流行的分布式架构为基础来设计的。除了存储引擎与计算引擎之外,分布式组件也已经成为现代数据库设计的必选项。数据库系统在分布式组件的支撑下展示出越来越强大的可扩展性和高可用性,但是同时也必须面对分布式环境中的一致性,可靠性等挑战。
MatrixOne中的MatrixCube正是一个这样的分布式组件,它可以将任意单机存储引擎扩展成分布式的存储引擎,存储引擎只需要关心单机的存储设计,而不需要去考虑分布式环境中的各种问题。MatrixCube是一个相当庞大的组件,MatrixOne社区将输出一系列文章与教程来进行全面揭秘。
本文作为第一篇文章,将首先从功能与概念上解释MatrixCube能做什么,以及它的架构是什么样的。
MatrixCube是什么
MatrixCube是一个Golang实现的基于Multi-Raft的自带调度能力的分布式强一致性存储框架。MatrixCube的设计目标是让开发人员能够轻松地实现各种强一致的分布式存储服务。我们可以使用MatrixCube来构建一些常见的分布式存储服务,比如:分布式Redis、分布式KV等等。而MatrixOne也是一个通过MatrixCube构建的分布式数据库,在没有MatrixCube的情况下,MatrixOne就是个单机的数据库,MatrixCube使得我们可以搭建一个小型的集群。但是MatrixCube并不与MatrixOne紧耦合,MatrixCube可以对接任意的其他存储引擎,使得其获得同样的分布式存储能力,比如我们可以让MatrixCube对接一个RocksDB,Pebble,或者Redis。
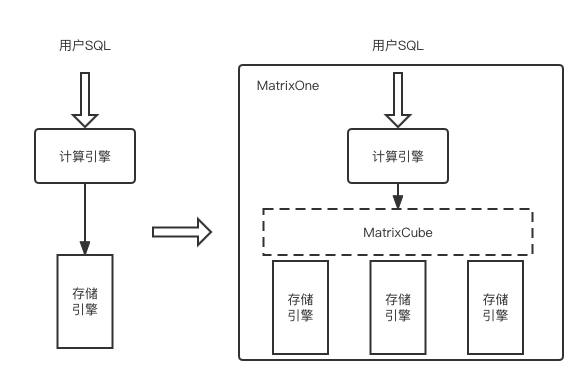
图-MatrixCube的作用
MatrixCube有以下几个功能特性:分布式,高可用,强一致,自动均衡,用户自定义。
分布式
这个很好理解,单机系统就是一台机器的系统,分布式系统就是很多机器组成的系统,所有分布式问题都是在解决协调多台机器共同完成一件事情的问题。与单机只需要操作一套硬件相比,分布式环境中的多台机器需要有大量的协调与沟通机制,同时需要对其中可能出问题的地方进行处理。比如让计算机处理两个数字的运算,在一台机器上直接一套代码就能运行了,但是在分布式环境中我们需要设计一套机制如何将这个运算拆成不同的子任务交给不同的机器,在每台机器完成自己的部分之后再将各自的结果通过某种机制合并到一起形成最终的结果。而这其中如果某台机器故障,或者由于网络通信的问题导致机器无法连接,这些异常情况都需要分布式组件进行处理,保证整个集群仍然能完成任务。MatrixCube就是为了实现多台机器的分布式数据存储而实现的一套分布式框架。
图-分布式系统
高可用
作为一个数据库系统,存数据是其最起码的职责。在一个分布式环境中,每台机器都会有一定的出问题概率,不管是硬件环境还是软件环境都有fail的可能性,为了能持续提供服务保证系统的可用性,我们往往会采用将同一份数据在复制多个副本的方式,将每个副本放在不同的机器上,以此来提升可用性,同时由于多副本的存在,在用户来访问数据的时候我们也可以通过多台机器同时提供服务来提升系统的吞吐能力。使用MatrixCube实现的存储服务支持高可用,由于Raft协议的选举机制,如果一个集群拥有2*N+1的副本数量,那么集群在N个副本故障的时候,还能够正常的提供读写服务。
强一致
由于多副本的存在,用户可以读取任意节点上的副本。而强一致就是为了保证这些副本之间的数据始终都是一致的,如果在某个副本数据有更新的时候也会先将其他副本同步更新之后才会响应用户来读取,这样用户能始终读到最新的数据。另外一个相对的概念就是最终一致性,区别在于写入之后马上就告诉用户可以读了,但是用户如果马上去读其他副本的时候可能还没有复制完成,所以仍然会读到老数据。Matrixcube提供强一致的读写接口,并且承诺一旦数据写入成功了,后续的读操作就不会读到一个陈旧的值,一定会读到之前写入的数据或者更新的数据。MatrixCube采用了Multi-Raft的方式。Raft是目前使用最广泛的分布式一致性协议,解释Raft协议和运作机制的文章行业内非常丰富,这里就不详细展开。简单的来说Raft协议通过Leader选举以及日志复制的方法,保证集群在出现如机器宕机或者故障的情况下可以始终保持对外提供数据的一致性,且始终维持最新的数据。
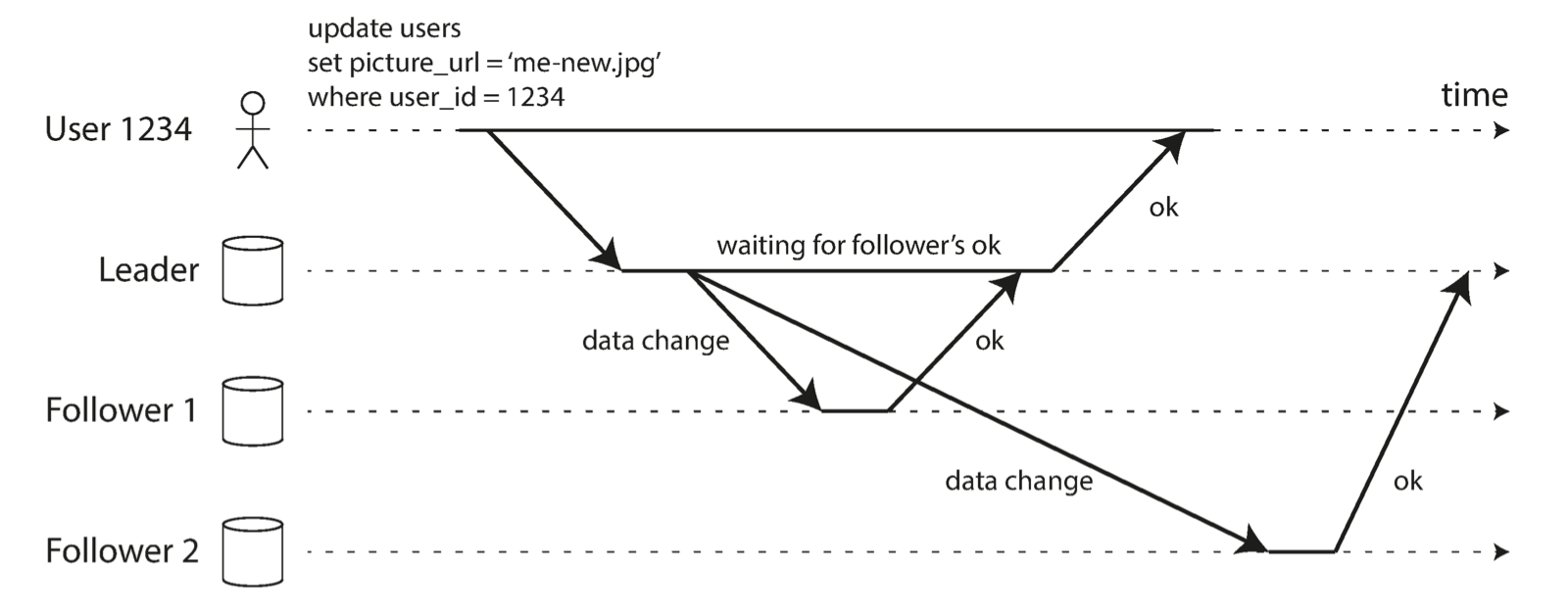
图-强一致(Follower1)与最终一致(Follower2)
自动均衡
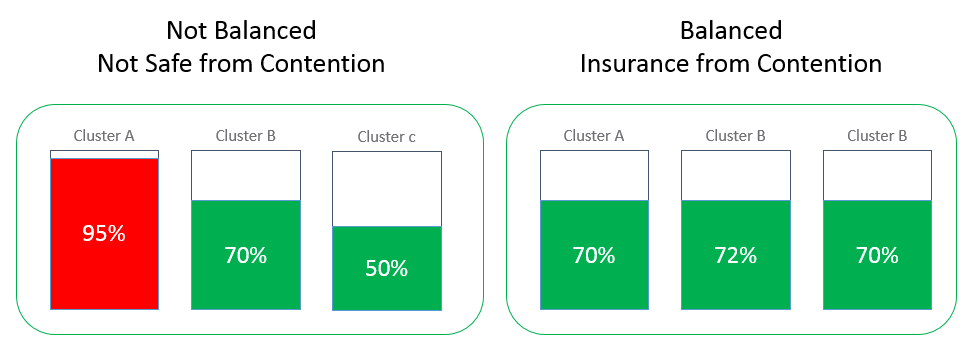
作为分布式存储系统,除了通过强一致的副本复制机制保证高可用性以外,我们还应该尽可能多地将多台机器的资源利用起来,以达到更高的使用效率。一个合格的分布式存储应该让每个节点之间的存储压力大致相同,同时对每个节点的访问压力大致相同,不至于在某些节点上面临过大的存储或者访问压力,这样整个系统的性能就会因此受到影响。而MatrixCube就具备这样的调度与自动均衡能力,可以在多节点间保持存储与负载的均衡,并且在节点发生变化时进行存储与访问负载的调度,以达到重新平衡。在MatrixCube中,我们提供了三种级别的自动均衡:
- 实现各节点存储空间的均衡,以高效利用各节点存储资源;
- 各节点的 Raft-Group Leader 的均衡,由于读写请求都需要从Leader经过,以此来达到读写请求的负载均衡;
- 各节点 Table 数据分布的均衡,由于某些表可能是热门数据会被频繁访问,以此来实现表级别的读写请求均衡。
用户自定义
MatrixCube提供相当灵活的用户自定义能力。MatrixCube不限制单机的数据存储引擎,并且定义了DataStorage接口,任何实现DataStorage的存储引擎都可以接入MatrixCube。而且MatrixCube支持自定义的读写请求,使用者只需要实现这些请求在单机上的逻辑,分布式相关的细节全部交给MatrixCube。因此用户可以非常方便地接入各种不同的单机存储引擎,以及自定义各种不同的读写请求命令。
MatrixCube的架构与运作机制
MatrixCube基本概念
我们需要先了解一些概念来帮助我们更好地理解MatrixCube。
- Store:MatrixCube是一个分布式存储的框架,所以我们的数据会存放在很多的节点上,我们把集群中的一个节点称为一个Store。
- Shard:数据在MatrixCube集群中是分片存储的,每个数据分片我们称之为一个Shard。一个Store中可以管理多个Shard。
- Replica:为了保证存储服务的高可用,每个Shard的数据是存储多份的,并且分布在不同的Store上,Shard的一个数据副本我们称之为一个Replica。所以一个Shard会包含多个Replica,每个Replica中的数据都是一样的。
- Raft-Group:通过多副本我们保证了数据的高可用,为了保证数据的
一致性,我们采用Raft协议来做数据共识,一个Shard的多个Replica会组成一个Raft-Group。
MatrixCube功能组件
-
DataStorage: 使用MatrixCube就必须要定义一个DataStorage,用来存储单机数据。我们需要针对存储服务的特点来设计对应的DataStorage。MatrixCube默认提供了一个完整的基于KV的DataStorage,因为基于KV的存储可以满足大部分的场景。
-
Prophet: Prophet是一个调度模块,主要职责是负责Auto-Rebalance以及维持每个Shard的Replica个数。每个Store以及Shard的Leader Replica都会定期上报心跳信息给Prophet,Prophet会根据这些信息来做出调度决定。MatrixCube需要在集群中指定哪些节点承担调度的职责。
-
Raftstore: Raftstore是MatrixCube最核心的组件, 其中实现了Store,Shard,Raft-Log相关的元数据存储,对Multi-Raft协议的支持,全局路由表的构建以及每个节点上的读写Shard Proxy代理功能。
MatrixCube的整体架构

图- MatrixCube整体架构
MatrixCube的工作机制
系统启动与配置
在系统初始化的时候,MatrixCube会根据集群中每个节点的配置文件来进行初始化。在MatrixCube中,一共有两种类型的节点,一种是调度节点,也就是Prophet节点,另一种是数据节点,只存数据,没有调度功能。两种节点之间目前无法互相转换,都是在系统初始化的时候指定好的。MatrixCube的最初三个节点必须都是Prophet节点,这也是MatrixCube所能组成的最小规模集群。Prophet的三个节点构成一个Raft-Group,其中会选举出一个leader,所有的调度请求与信息上报都会到这个Prophet Leader上。Prophet的节点数可以进行配置,但是以Raft协议为基准,必须是2*N+1个节点(N为不小于0的整数)。
数据存储与分裂
在系统开始启动运行之后,用户开始往系统中导入数据。MatrixCube在初始化时已读入一个数据分片Shard的大小配置,比如1GB一个Shard。用户写入数据还没有达到1GB的时候,会持续写入同一个Shard,而同时每次写入的数据会同步在三个节点中更新Shard,这三个Shard会构成一个Raft-Group,其中也会选举出一个Leader,对这个Shard的读写请求与信息上报全部会由这个Leader来处理。直到一个Shard达到1GB时,此时MatrixCube会启动Shard分裂机制,也就是把一个Shard均匀拆分成两个Shard,也就是1个GB的分片变成了2个500MB的分片,而这个过程是同步在三个节点中发生的,也就是说同时将生成6个Shard,而他们将组成新的2个Raft-Group。

图-Shard分裂
用户读写响应与路由
用户以接口的形式与MatrixCube交互,从而来发起对数据的读写请求。由于Raft-Group的存在,只有每个Raft-Group的Leader才能响应读写请求。而用户的请求可能并不一定直接指向Raft Group Leader,因此我们就需要一个路由机制,来让用户的请求能被正确的转到它该去的地方。因此每个节点上都会有一个Shard Proxy,这些Proxy会定期接收Prophet给它的全局路由表。我们前面提到Prophet会接受各个Store与各个Shard的Leader给的心跳信息,因此Prophet是有一张全局的路由信息表的。这个时候Shard Proxy就会知道用户请求读写那份数据应该在哪个Store的哪个Shard中。这样的话用户无论向集群中哪个节点发起读写请求,最终得到的结果都是一样的,用户不需要关心Shard在内部存在什么地方。
假设我们有一个3个Store节点的集群,初始状态如下:
| Range | Store1 | Store2 | Store3 | |
|---|---|---|---|---|
| Shard1 | [key1-key10) | Leader | Follower | Follower |
| Shard2 | [key10-key20) | Follower | Leader | Follower |
| Shard3 | [key20-key30) | Follower | Follower | Leader |
用户分别向key1,key10和key20数据发送请求,下图说明了请求如何通过Shard Proxy路由组件并被转发。

图-Shard Proxy对用户请求的转发
节点变化与数据搬迁
在整个集群发生节点变化时,比如集群需要扩缩容,或者出现机器或者网络故障的时候,我们就要进行集群的调度。通常来讲,我们的Prophet会有一个超时机制,在某个节点超过我们规定的时间没有心跳上报的时候,我们这时就认为这个节点已经下线,我们将开始数据搬迁流程。在节点减少的情况下,Prophet会检测到一部分Shard没有足够的Replica组成一个完整的Raft-Group,这时就需要在现有的节点中找到存储空间比较富余的节点,在其中创建这一部分Shard的Replica。而在节点增加的情况下,Prophet会发现多出的节点存储空间比较富余,这时会将集群中的一部分Shard进行重新分配,以达到一个各节点相对均衡的状态。在节点变化的时候,除了Prophet会进行调度意外,每个被破坏的Shard组成的Raft-Group也会视情况进行调度,如果少了Raft-Group的follower,那在完成Shard的新Replica生成后会重新组成完整的Raft-Group;如果少了Raft-Group的Leader,那剩下的两份Replica就会先选举出新的Leader,再去新的节点上完成Replica与Raft-Group的生成。
在下图的例子中我们看到,初始状态的三节点在增加第四节点的情况下,每个节点的4个Shard被均摊到了4个节点上,而本来不均衡的Leader数量也均摊到了每个节点上
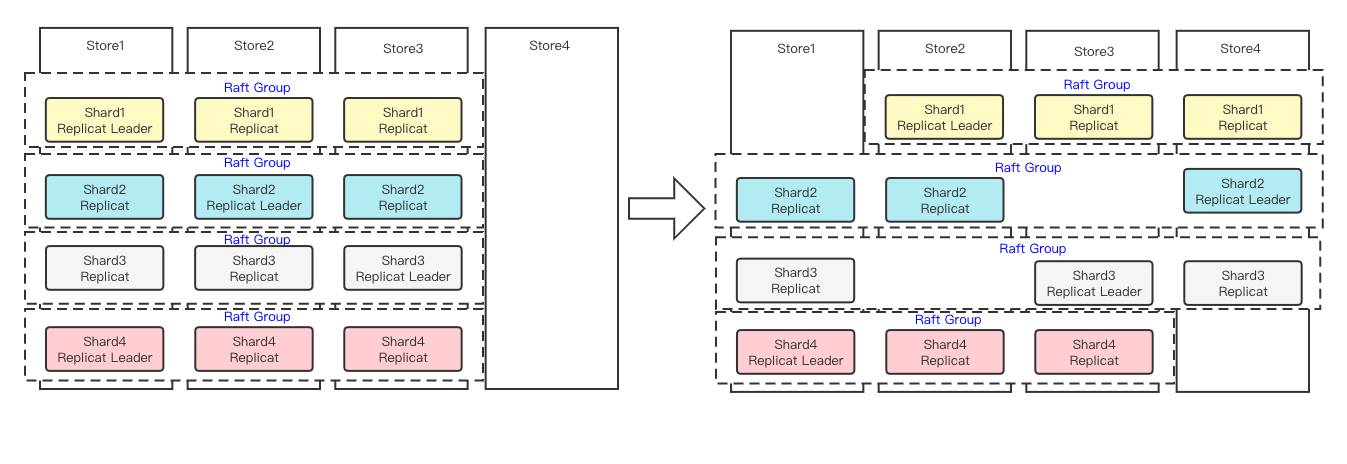
图-节点增加时的数据搬迁
在这些机制的组合工作下,MatrixCube就可以将一个单机的存储引擎扩展到一个分布式场景中来使用。
MatrixCube与TiKV的区别
很多社区的小伙伴在之前都接触过TiDB分布式数据库的架构,以及其中负责提供分布式能力的组件TiKV以及负责调度的模块Placement Driver。实际上MatrixCube的功能基本相当于TiKV与PD的结合,MatrixCube除了还在开发中的分布式事务能力以外,其他的高可用,强一致以及调度的能力与TiKV+PD基本保持一致。
MatrixCube与TiKV+PD主要有三点区别:
- TiKV+PD是一个完整的服务,所有的读写细节都已经在内部封装完成,用户通过与其定义好的接口与其进行交互。而MatrixCube是一个Library,无法单独运行,必须与存储引擎一起工作。而且MatrixCube将读写的请求命令交给了用户定义,使用者可以自行去实现各自不同存储引擎的读写请求命令,只需要实现MatrixCube提供的存储引擎接口即可与MatrixCube对接,由MatrixCube负责各自分布式的相关细节。
- PD的调度功能主要体现在存储空间的调度与Raft Group的Leader的调度,可以在副本级别达到负载均衡。而MatrixCube除了在实现这两点外,还实现了表级别的数据分布均衡,从而使得对表的读写请求也能达到相对均衡的状态。
- TiKV由Rust实现,而PD是由Go实现。因此这套结构在对接过程中需要一定的中间层接口。而MatrixCube整体都是由Go所实现,因此不存在这样的问题。
总的来说MatrixCube更加看重开发灵活性,开发者可以非常灵活的应用MatrixCube去实现不同地分布式存储引擎。
下期预告
为了向开发者展示MatrixCube的使用,MatrixOne社区准备了一个非常简单的KV存储的例子,用MatrixCube对接Pebble存储引擎实现了一个分布式存储系统。
MatrixOne 社区
欢迎添加 MO 小助手微信 → ID:MatrixOrigin001,加入 MatrixOne 社群参与讨论!
源码:github.com/matrixorigin/matrixone
Slack:matrixoneworkspace.slack.com
知乎 | CSDN | 墨天轮 | InfoQ | SegmentFault:MatrixOrigin
|








- 上一条: 追根问底:Objective-C关联属性原理分析 2022-07-18
- 下一条: 得物基于Attach to Process的实时调试实践 2022-07-18
- 怎么提高自己的系统架构水平 2021-07-21
- 揭秘华为云GaussDB(for Influx)最佳实践:hint查询 2022-05-30
- 给Arm生态添把火,腾讯Kona JDK Arm架构优化实践 2021-08-17
- 实时音频抗弱网技术揭秘 2021-10-11
- 来了来了!MatrixOne技术架构详解来了! 2022-03-18


