来了来了!MatrixOne技术架构详解来了!

前一段时间在知乎上有个小伙伴吐槽说已放弃阅读MatrixOne源代码,想必是对MatrixOne的代码可读性与解释文档的缺乏不太满意。确实,MO在这些方面还需要做很多改进工作,作为一个开源项目,良好的代码和文档可阅读性是让大家来参与的基础。
社区中也有很多小伙伴问到MatrixOne是否有一个整体架构和模块说明的文档?那必须给大家安排上!本文将说明MatirxOne每个模块的现状与进展,希望通过技术架构详解,大家对MatrixOne能够有更清楚的了解,同时也欢迎大家贡献代码~
设计理念和初衷
MatrixOne的定位是超融合异构云原生数据库。
我们核心的设计初衷是由于观察到数据增长和应用的需求越来越强烈,但是数据处理的任务却变得越来越复杂,行业中充斥着使用多个数据库或者大数据的组件自己组合搭建一套数据平台的做法,这样的做法需要极强的IT能力、高昂的维护和使用成本。
对互联网企业而言,行业红利已经接近天花板,下半场的强监管与精细化运营必然对降低成本提出更高要求。而对大量还在数字化转型过程中的传统企业而言,在还未尝到数字化的甜头的时候,由于数据处理的复杂性和高IT门槛就已经足够劝退大量企业。
MatrixOne希望通过一套比较简洁的架构,能提供一套统一的满足大部分场景数据处理需求的平台,将复杂性包含在系统内部,让用户能够高效快速的处理和应用数据。
举一个例子来讲,现在的数据库产品就类似于一个个独立的电子设备,MP3,数码相机,收音机,电话,每个实现一部分相对突出的功能。而MatrixOne希望提供的是一个类似智能手机的产品,将大部分相对通用的功能集成在产品内部,极大的简化使用体验和维护成本。
关于我们的产品理念和初衷,请参见我们发布于InfoQ的《昂贵、复杂、低效... 中小型企业如何打破大数据技术栈困境?》一文。
架构特点
当前整体架构可以用NewSQL+MPP来定义,并且正在进化成为一个为OLAP增强的分布式HTAP数据库,今年下半年将开始向面向云边一体的场景进一步演进。
MatrixOne将极简易用作为重要的设计准则,尽管是分布式数据库,但在部署上只提供单一Binary,每个节点只运行完全同样的单一进程即可。
MatrixOne的NewSQL架构特点
众所周知,关系型数据库自SystemR确立了关系模型+SQL+事务处理“老三样”以来,已经存在了超过30年,直到NewSQL的出现。NewSQL是指以Google Spanner为起点,CockroachDB、TiDB、YugabyteDB等作为开源代表出现的分布式数据库,采用以复制状态机(Replicate State Machine)为核心,同时解决传统单机数据库伸缩性和高可用问题的分布式架构。
在计算机领域,复制状态机是实现容错服务的主要方式。状态机开始于给定的起始状态。每个收到的输入都通过状态转移机制来产生一个新的状态以及相应的输出。在复制状态机中,一组Server的状态机计算相同状态的副本,即使有一部分Server宕机了,它们仍然能够继续运行。一致性协议是复制状态机背景下提出的,用来保证复制日志的一致性,常用的一致性协议有Paxos,Raft等。在复制状态机架构下,通过挂载Key Value存储引擎进而实现OLTP能力,就是以上NewSQL的主要构型。
MatrixOne的当前架构,跟以上NewSQL数据库的区别在于,它是可以挂载多种存储引擎的。当前的0.2版本已经挂载了一个Key-Value存储引擎,用来存放Catalog等元数据。以及一个列存引擎,提供OLAP分析能力。当然,根据需要,它也可以挂载任意存储引擎,包括但不限于行存,图,专用时序,专用NoSQL等多模引擎。不同的存储引擎可以去满足不同场景中的应用,也非常欢迎社区的开发者来贡献想法和代码。
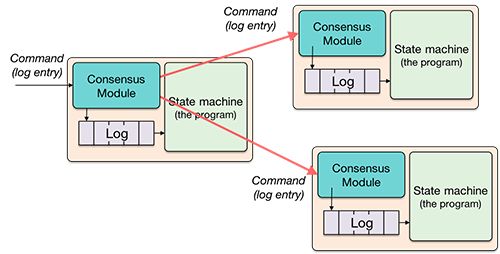
图:Raft的复制状态机实现
MatrixOne的MPP架构特点
MPP(Massively Parallel Processing)大规模并行处理是一种针对大规模的数据分析的计算架构。简单来说,MPP是将任务并行的分散到多个服务器和节点上,在每个节点上计算完成后,将各自部分的结果汇总在一起得到最终的结果。这个架构最早被Teradata和Greenplum等第一代OLAP数据库采用,后来为Hadoop体系奠基的MapReduce也借鉴了MPP架构的做法。但是两者在处理的数据体量,SQL的支持程度,数据处理类型及效率上有较大差别。用今天的概念来讲,Hadoop方案更偏数据湖,可以存储和处理上百PB数据,可以在读取的时候再定义schema,可以放大量的非结构化和半结构化数据,但是SQL支持,查询性能和实时流式处理不太理想。基于MPP架构的数据库方案更像是大幅强化了查询能力的关系型数据库,仍然兼具良好的SQL支持和ACID事务属性。新一代的开源MPP计算引擎代表有Clickhouse,Presto,Impala,GreenPlum,Apache Doris等。
MatrixOne也在MPP架构的基础上提供强大的OLAP能力,与其他项目不同的是,目前MatrixOne的MPP SQL计算引擎目前是用Golang实现的最快SQL引擎,相比C++的计算引擎,也可以在性能上一较高下。而且通过向量化和因子化加速之后,在如非主键join,多表复杂join等方面表现更优。
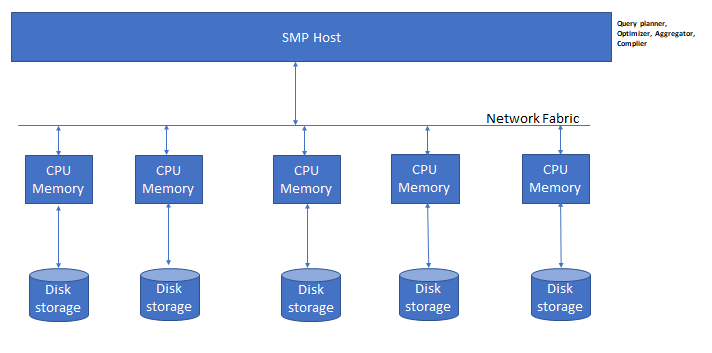
![]() 图:MPP架构
图:MPP架构
整体架构
MatrixOne整体分为前端、计算层、元数据层、分布式框架和存储层这几个层次。
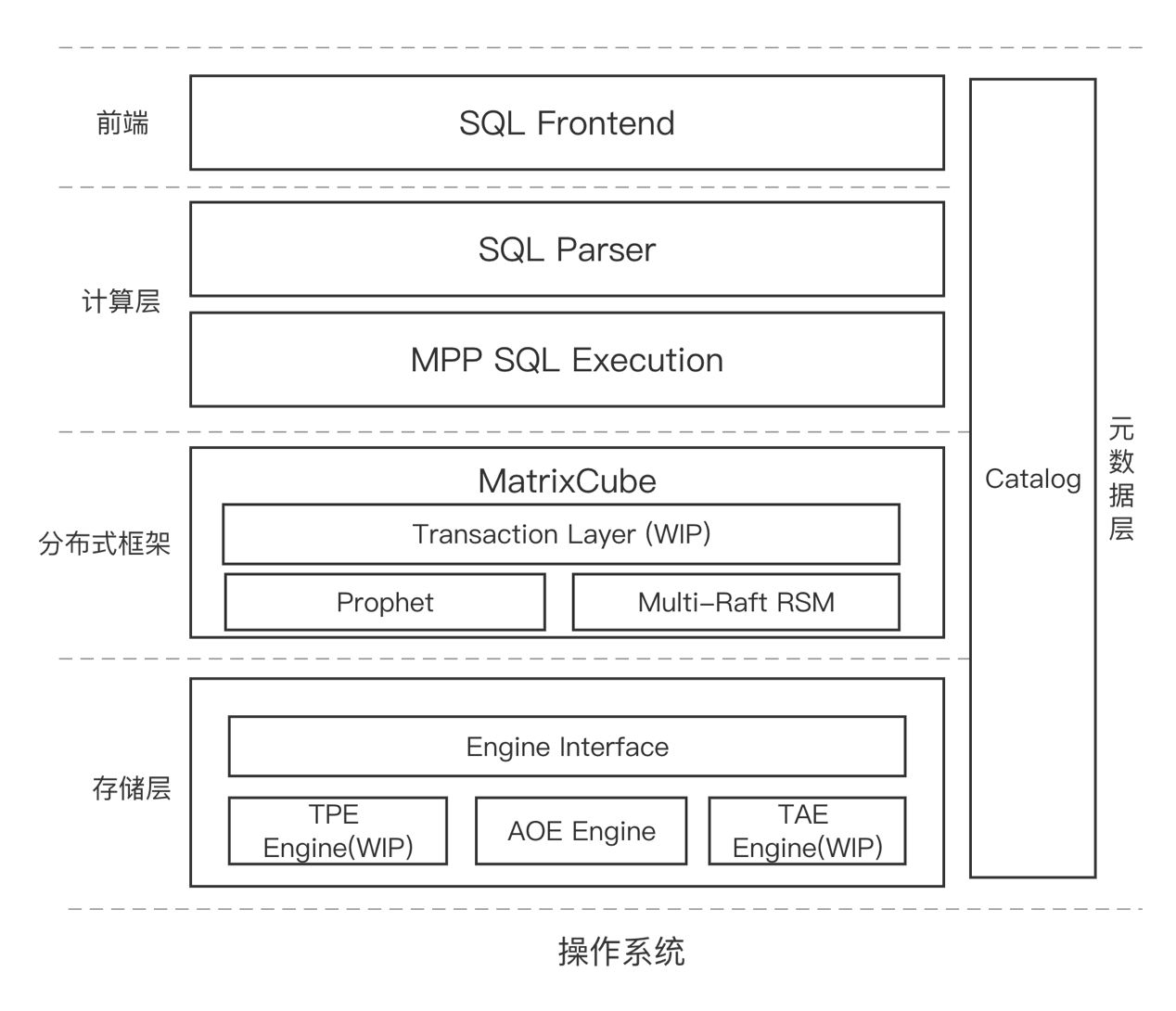
![]()
图:MatrixOne的整体架构
组件介绍:
前端SQL Frontend:这是MatrixOne的入口,目前MatrixOne提供MySQL兼容协议,以及MySQL语法(部分兼容)。SQL Frontend接收来自MySQL客户端的请求,解析后转到下一层。
计算层Query Parser: 接收到来自SQL Frontend的请求之后,SQL Parser负责将其解析并转化为抽象语法树。尽管提供 MySQL语法,但MatrixOne并没有采用流行的开源Query Parser,如TiDB,Vitess的Parser等。事实上,在2021 年10月发布的MatrixOne 0.1版本中,就采用的TiDB Parser,但在0.2版本中,我们自研了一个新的Parser,这主要是因为:
- MatrixOne致力于提供超融合数据库,未来会有很多的自定义语法,这并没有必要完全跟MySQL保持一致。此外, MatrixOne未来还有提供多方言协议兼容的计划,包括PostgreSQL,Hive,ClickHouse等,因此MatrixOne需要 有自己的Query Parser,可以任意定制,并为多方言语法兼容提供基础。
- MatrixOne当前更突出OLAP能力,而目前开源的Parser,基本的都是服务OLTP场景的,对一些OLAP的场景,如大批量插入等,性能开销较大。
计算层MPP SQL Execution:这是MatrixOne的MPP计算引擎,该引擎由Golang实现,其中针对SQL计算引擎的一些基础操作的向量化加速,部分操作采用了汇编改写做加速。目前仅实现了Intel X86架构中AVX2,AVX512指令集的适配和加速。另外,我们通过独有的因子化加速能力,在针对多表join的场景下会有非常高效的表现。这些技术细节都会有后续的文章介绍。但是总的来说我们目前距离完善的SQL能力和底层适配还有很长的路要走,这里也欢迎社区可以更多的贡献针对其他如ARM处理器架构以及更多SQL操作的汇编加速实现。
元数据层Catalog:这是存放数据库整体元数据的组件,例如Table/Schema定义等。目前Catalog还是一个临时方案,采用一个Key Value引擎存放,后续Catalog将整体迁入一个标准的OLTP引擎,提供进一步更完善的ACID能力来支撑Catalog组件。
分布式框架MatixCube:这个组件是实现NewSQL架构的分布式基础架构库,目前是一个独立的仓库。它包含两部分的功能,一个是提供复制状态机实现的共识协议部分,当前采用Multi Raft机制。另一个是提供基于Raft的副本调度机制,该调度器在代码中称为Prophet。MatrixCube是一个通用的库,它可以对接各种存储引擎,这也是目前把它放到一个独立的仓库 的原因,任何第三方开发者,都可以比较方便的采用它来实现分布式强一致的存储引擎和数据库。MatrixCube还有一个非常重要的工作,就是提供分布式事务能力,这个工作目前正在方案设计中,很快也会将方案公开给开发者参考与讨论。
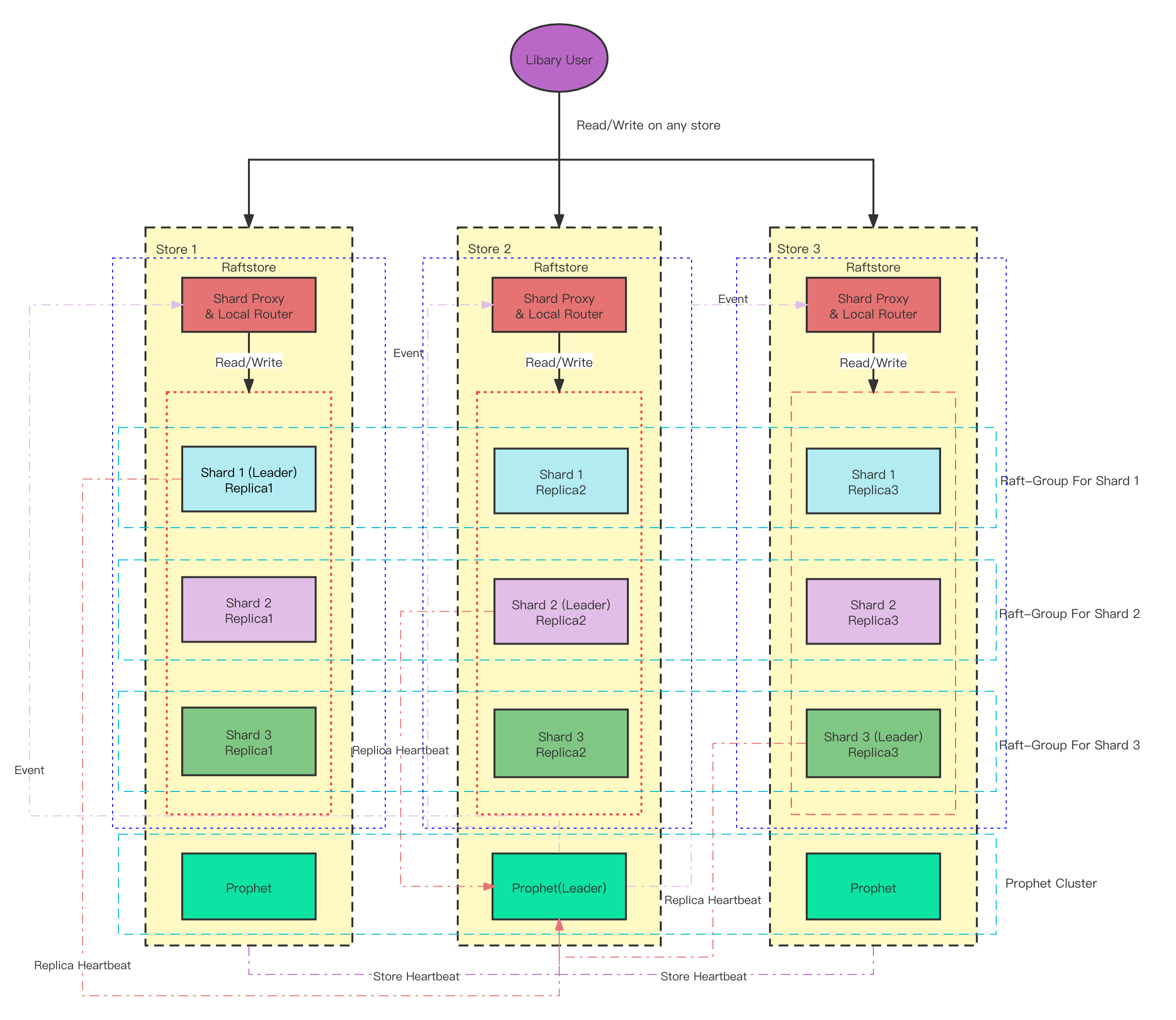
![]() 图:MatrixCube架构图
图:MatrixCube架构图
存储层Storage Engine:在MatrixOne中,存储引擎被定义为Engine,因此采用DDL创建表的时候,可以通过指定Engine,来决定用什么存储引擎来存放表数据。在当前的仓库里,只实现了一个Engine: AOE引擎。在最初的版本里,AOE的意思是Append Only Engine,这是一个Append Only的列存引擎。前面提到MatrixOne目前提供了2种存储的挂载,一个是Key Value,另一个是列存。 但是目前,Key Value还没有完成Engine的抽象,它对应的名字叫做TPE(Transaction Processing Engine),目前正在开发中,因此前述的Catalog是临时方案,待TPE完成后,Catalog将采用TPE实现。未来,不排除TPE对外暴露提供完整SQL能力的可能。AOE本质上是一个Demo存储引擎,它验证了将列存跟 NewSQL架构结合的一系列设计问题,这跟基于Key Value的NewSQL有着很大不同。目前开源的分布式数据库中,只有MatrixOne和Apache Kudu实现了基于列存的NewSQL架构。AOE的一个演进叫做TAE(Transactional Analytical Engine),这是一个基于列存的HTAP引擎,会提供完整ACID能力及强大的OLAP能力,类似于MySQL与Clickhouse整合的同时带完整分布式事务能力的数据库,目前正在紧张开发中。待完成后,MatrixOne将拥有完整的分布式 HTAP能力,完成Apache Kudu多年一直没有做到的事情:兼顾事务和高性能。
MatirxOne代码结构
介绍完MatrixOne的架构之后,想必小伙伴们已经对MatrixOne有了一个整体的了解。接下来我们会整体介绍一下MatrixOne的代码仓库结构,方便各位小伙伴对感兴趣的部分进行深入研究或者参与贡献。
MatrixOne的内核代码全在"matrixone/pkg/ "文件夹下。与上述架构图中对应的模块代码库位置:
- SQL Frontend: frontend/
- SQL Parser: sql/parser
- MPP SQL Execution: sql/
- 向量化: vectorize/ - Catalog: catalog/
- MatrixCube: MatrixCube目前为单独仓库「https://github.com/matrixorigin/matrixcube」
- Storage Engine: vm/engine,这里vm的意思是虚拟机,这里借用了SQLite的概念,类似整个MatrixOne的runtime,整个存算逻辑包装在vm中,提供对物理资源的抽象,方便进行资源管理。
- AOE: vm/engine/aoe
- TPE: vm/engine/tpe
我们在github上有一个完整的good-first-issue列表,相对于MatrixOne这个庞大系统,这些任务相对比较容易上手和实现,期待各位开发者来认领参与~
![]() 图 :MatrixOne good-first-issue列表
图 :MatrixOne good-first-issue列表
惊喜预告!MatrixOne即将发布第一期系统built-in函数新手任务,其中需要修改的代码主要在builtin与vectorize当中,欢迎社区开发者的参与!
欢迎加入MatrixOne社区
源码:github.com/matrixorigin/matrixone
Slack:matrixoneworkspace.slack.com
知乎 | CSDN | 墨天轮 | OSCHINA | InfoQ:MatrixOrigin
|








- 上一条: 详解4种微服务框架接入Istio方案 2022-03-18
- 下一条: Helm Charts 开发完整示例 2022-03-20
- MatrixOne 0.2.0 发布 | 最快的SQL计算引擎来了~ 2022-02-23
- NoOps 来了,是否意味着 DevOps 时代的终结? 2021-10-29
- 在浏览器中,把 Vite 跑起来了! 2022-01-10
- 7. 堪比JMeter的.Net压测工具 - Crank 总结篇 - crank带来了什么 2022-04-22
- 公司新来了一个质量工程师,说团队要保证 0 error,0 warning 2021-08-26


