半监督学习
半监督学习指的是结合了少量的有标记数据和大量无标记数据来完成训练的过程。

在某些特定领域,大量有标记的数据很少也很难标注。
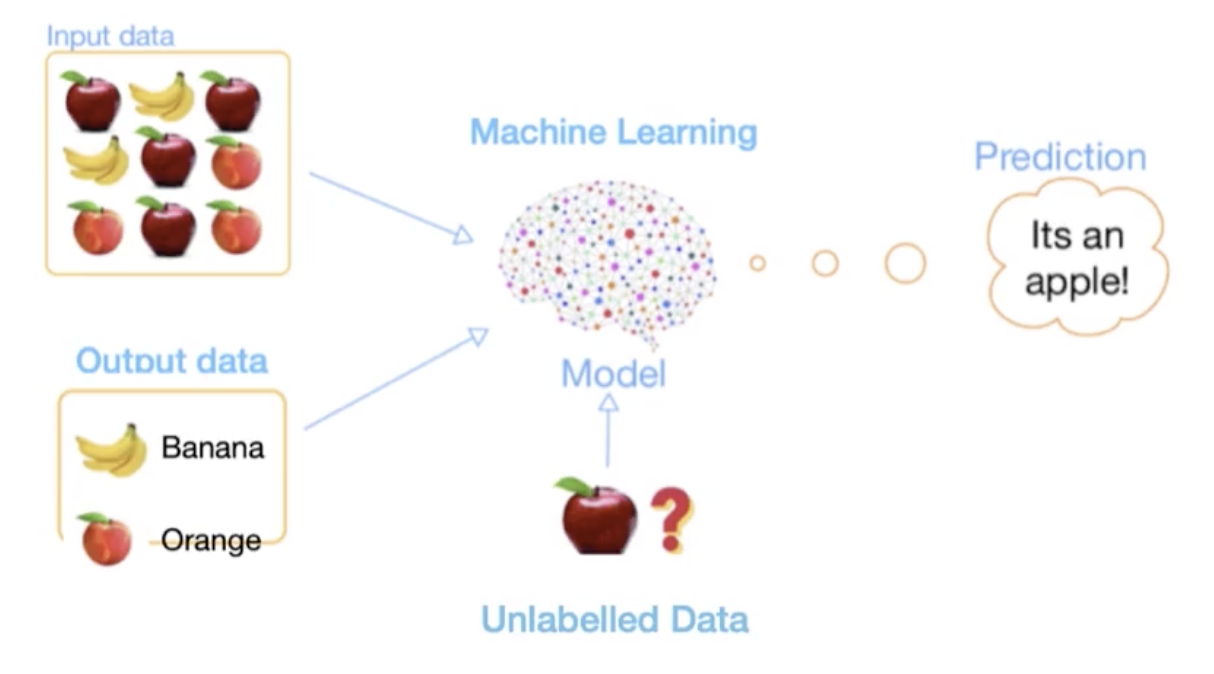
比方说,我们现在有一个公开数据集,它全部都是有标注的。此时我们可以使用有监督的学习来看一下结果,再使用10%的有标注的数据集结合剩下90%的未标注的数据来使用半监督学习的方法,我们希望半监督学习的方法也能达到有监督学习的水平。

半监督学习的应用
- 视频理解,
- 自动驾驶
- 医疗影像分割
- 心脏信号分析
半监督前提假设
- 连续性假设(Continuity Assumption):
![]()
我们用一个分类问题来举例,当我们的Input是比较接近的时候,比如说进行猫狗分类,两张猫的图片是比较接近的时候,此时output(后验概率矩阵)也必须是比较接近的。

比如说,x1和x2比较接近,x1的后验概率是0.9和0.1,明显它是分成第一个类0.9的。x2有两组输出,一个是0.85和0.15,另一个是0.55和0.45。那么我们可以看到这两组的输出虽然都是把类别分到了第一个,但是第二组输出![]() 是不满足连续性假设的,因为它和
是不满足连续性假设的,因为它和![]() 距离比较大,差的比较多。
距离比较大,差的比较多。
- 聚类假设(Cluster Assumption)

聚类假设指的是类类要内聚,类间要分开。就是说同一类的东西要非常相似,比较靠近,接近于一点。不同的类别要尽可能的分开。所以不能有模糊不清的图片,如

- 流行假设(Manifold Assumption)
- 所有数据点都可以被低维流行表达。
- 相同流行上的数据点,标签一样。
这里可以理解成降维,很多高维的数据的一些维度是不起作用的,它们的特点集中在一些低维度上。
半监督学习数学定义

上表是一个学术论文上,字符所代表的含义,x代表的是输入;y代表的是输出,它要么是个分类输出,要么是个回归输出;![]() 代表有标签的数据集;
代表有标签的数据集;![]() 代表无标签的数据集;X就是整个的数据集,包含有标签的和无标签的;L指损失函数;G是生成器,半监督学习可以用到生成式模型;D是判别器;C是分类器;H是熵,一般指交叉熵;E是期望;R是正则项,半监督学习中一般指一致性正则,当然半监督学习也可以使用传统的L1和L2正则;
代表无标签的数据集;X就是整个的数据集,包含有标签的和无标签的;L指损失函数;G是生成器,半监督学习可以用到生成式模型;D是判别器;C是分类器;H是熵,一般指交叉熵;E是期望;R是正则项,半监督学习中一般指一致性正则,当然半监督学习也可以使用传统的L1和L2正则;![]() 是指标签。
是指标签。
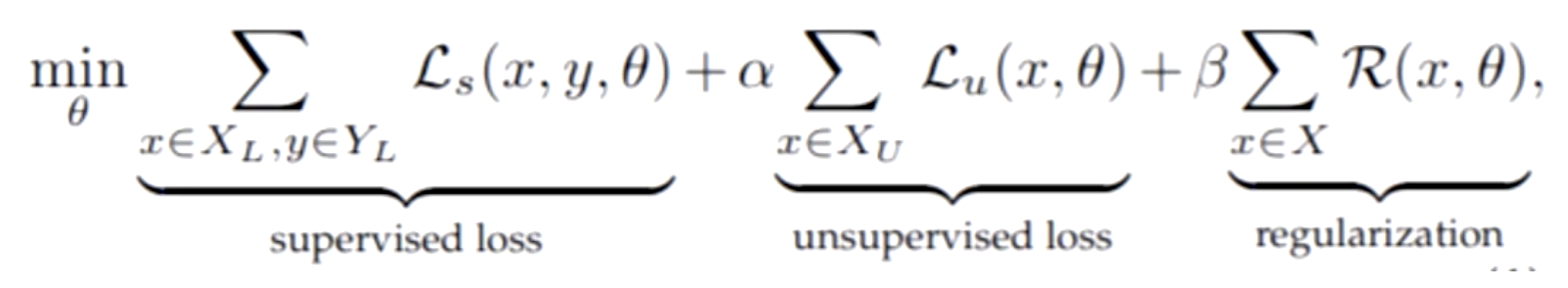
半监督学习最核心的其实就是它的损失函数,它一般包含三个部分,第一部分就是有监督的loss(supervised loss),第二部分就是无监督的loss(unsupervised loss)以及第三部分正则项(regularization)。因为半监督学习有少量的有标签的数据,那么第一部分就是这些有标签数据的loss;当然还有大量的未标注的数据,第二部分就是这些未标注数据的loss;第三部分可以用L1、L2正则,也可以是一致性正则。
第一部分的loss跟之前是一样的,一般是交叉熵损失函数,最主要的就是设计后面两部分的损失函数。
半监督学习实施方法
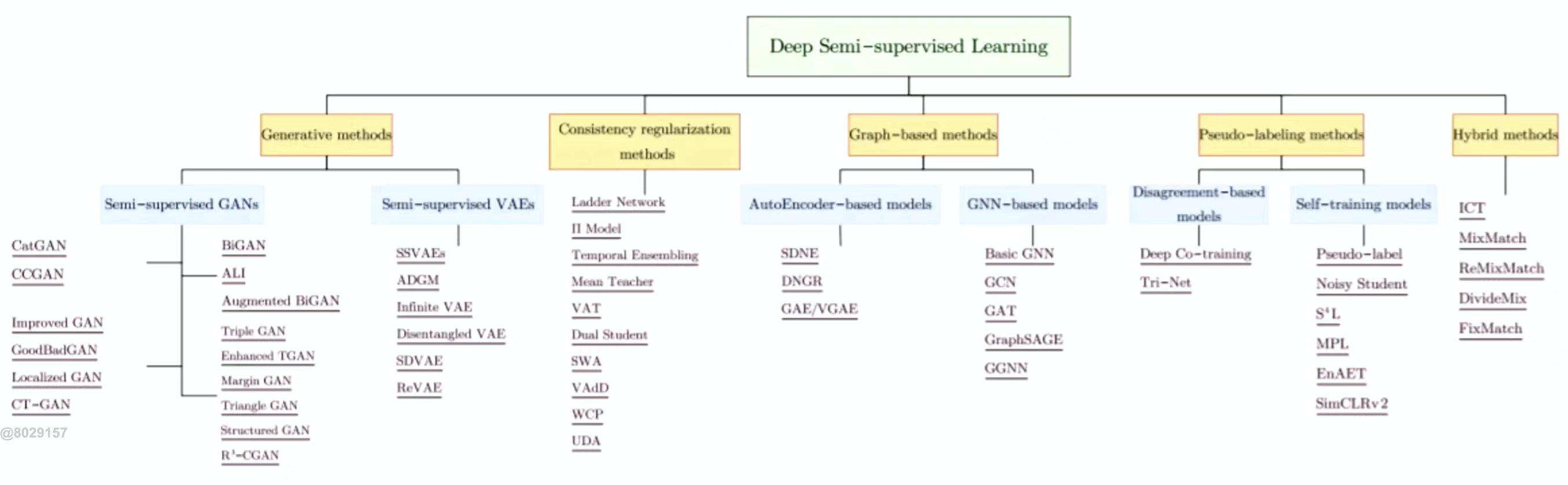
半监督学习模型可以分为五大方法,第一个是生成式模型,第二个是一致性损失正则,第三个是图神经网络,第四个是伪标签的方法,第五个是混合方法。现在用的最多的是混合方法,它可以结合前面四种方法的优点。
- Generative Based:基于生成式网络
1、重用判别器(Re-using Discriminator)
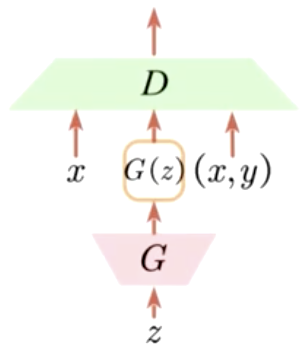
在我们使用GAN的时候,我们知道,鉴别器充当的是二分类器的功能,对输入的真实的图片或者生成的图片来判定是真是假。重用鉴别器在半监督学习中是一个K分类的分类器,它不仅仅是对有标签的数据(x,y)进行分类,还有生成的数据(G(z))和未标注的数据x进行分类。通过这三块的损失来构建我们的K类别的分类器。这样就达到了我们的目的,联合了未标注的数据和有标签的数据。
2、用于正则化分类器的生成样本(Generated samples to regularize a classifier)

这里的鉴别器D依然是一个二分类器,生成器G生成数据的时候的输入包含了未标注数据x,还包含了某一分布的随机初始矩阵z,来共同生成![]() ,再由
,再由![]() 生成
生成![]() ,生成
,生成![]() 的公式如下
的公式如下
![]()
这里的m是一个二值化的掩膜,即一个和x一样大的矩阵,它的值只有0和1。0乘以x中的像素点直接置为0,而1会保留x中的像素点的值。最后联合x和![]() 一同送入鉴别器D中来判别它们是否是一致的。我们希望我们的判别结果是一致的,这就意味着能驱动判别器D来识别到图片的某一块的特征。一旦该模型训练完备之后,就可以单独将鉴别器提取出来用在别的分类器中去。也可以用于构建别的loss设计的一部分,相当于一个表征或特征抽取器。
一同送入鉴别器D中来判别它们是否是一致的。我们希望我们的判别结果是一致的,这就意味着能驱动判别器D来识别到图片的某一块的特征。一旦该模型训练完备之后,就可以单独将鉴别器提取出来用在别的分类器中去。也可以用于构建别的loss设计的一部分,相当于一个表征或特征抽取器。
3、推理模型(inference model)
这是一个统称,不是指具体某一个模型的名字,有很多。
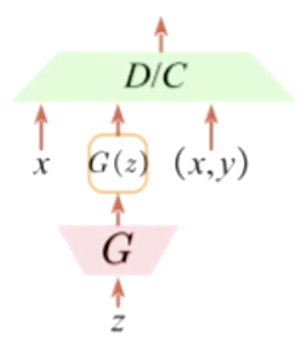
它跟第一种重用判别器很像,多了一个C(类别)。前面的步骤是相同的,只是在最后在判别器D这里多了一个类别,不是K个类别而是K+1个类别。多出来的这个类别就是生成器生成的G(z)的类别,它需要跟真实的K个类别的某一个类别要接近,这就是它的目的。
4、生成数据(Generate Data)
生成网络可以用在数据增强,生成更多的数据来。因为我们未标记的数据有很多,那我们干脆直接训练一个生成器,让它造更多数据出来。
- Consistency Regularization:一致性正则
这种方式是半监督学习的核心。
设计思路:
![]()
这里θ是指模型参数,也就是模型。x是未标注的数据,![]() 指的是标签。
指的是标签。
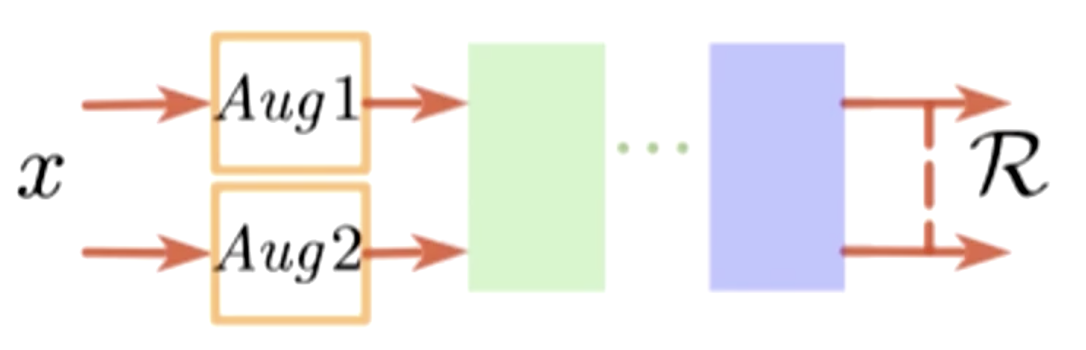
上图中,未标注数据x经过两种不同的随机数据增强Aug1和Aug2,也就是随机的翻转,旋转,平移,光照等等。然后送入模型中,让模型进行识别,会得到一个后验概率或者特征,我们希望输出的两个值是接近的。因为我们的输入是接近的,虽然x经过两种不同的扰动,但输出应该要接近。用公式表示为
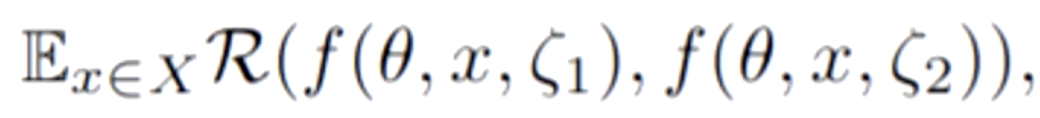
这里的ζ指的是随机数据增强。ζ1和ζ2是两种不同的随机数据增强。
每个训练的epoch,![]() 会被前向推理两次,这两次虽然输入经过不同的随机增广,但是输出应该具有一致性。
会被前向推理两次,这两次虽然输入经过不同的随机增广,但是输出应该具有一致性。
其实这种扰动不单单是可以用随机数据增强,还可以使用很多的方法。
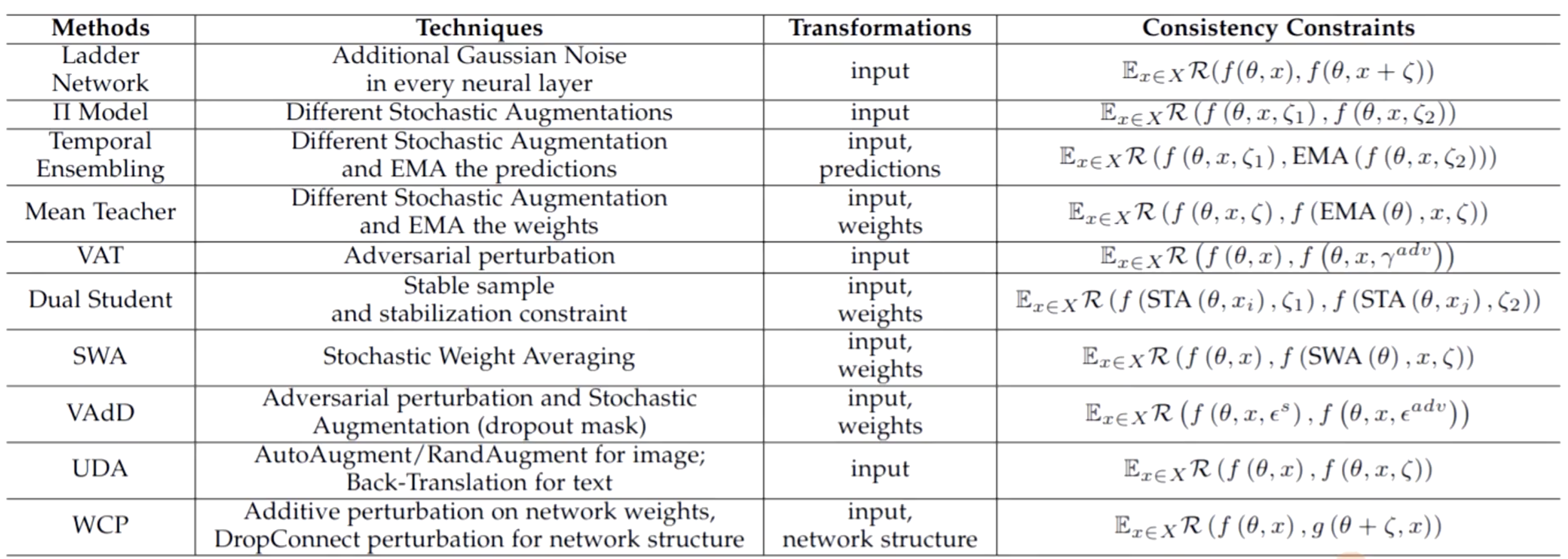
上表中是半监督学习经常刷榜的模型,它们的核心都在一致性正则上。比如说第三个,对于两种扰动,第二个扰动加了EMA(指数平均);第四个是在第二种扰动中对模型参数加了EMA;最后一个对于同样的模型,不增广,而是直接在模型上加了扰动。
- Pseudo-label:伪标签
半监督学习的大量数据是没有标签的,那么我们使用模型来预测一个标签,然后再送进模型训练。
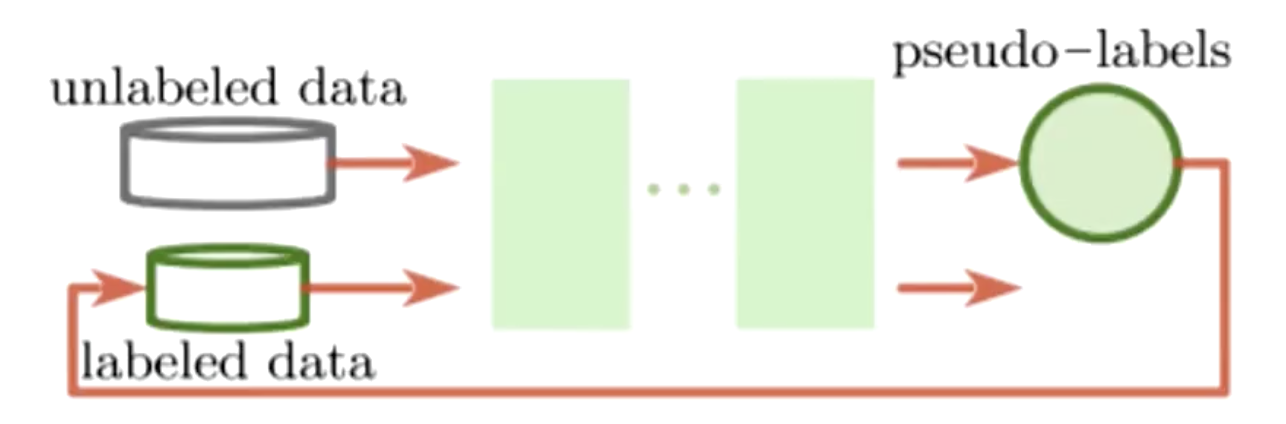
伪标签的损失函数如下
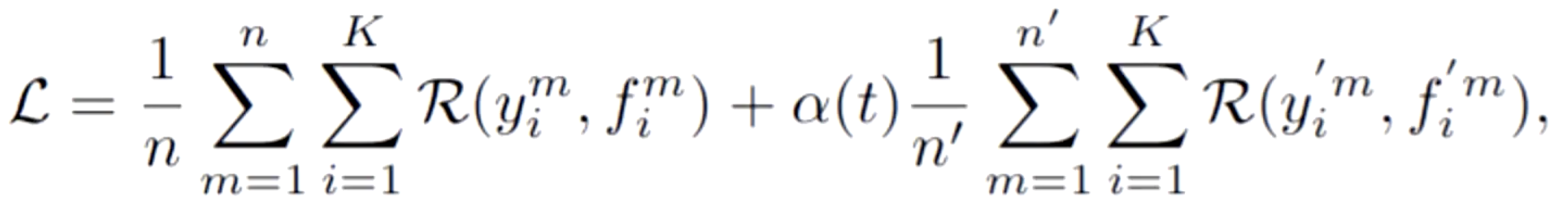
其中第一部分是有标记数据的损失,![]() 是真实的标签,
是真实的标签,![]() 是有标记数据的前向推理值。第二部分是未标注数据的损失,
是有标记数据的前向推理值。第二部分是未标注数据的损失,![]() 是伪标签,也就是预测出来的标签,
是伪标签,也就是预测出来的标签,![]() 是未标记数据的前向推理值。伪标签看似是一个简单的思路,但其实涉及到的方法也很多,它可能跟一致性正则一样,在结构上做设计,或者在训练的流程上做设计以及伪标签预测的方法上做设计。
是未标记数据的前向推理值。伪标签看似是一个简单的思路,但其实涉及到的方法也很多,它可能跟一致性正则一样,在结构上做设计,或者在训练的流程上做设计以及伪标签预测的方法上做设计。
伪标签有一个弊端
- 伪标签选择不太容易,在模型训练初期,可能是一个不太好的模型,预测出来的标签极有可能是不正确的。如果此时再将预测出来的标签送进模型训练可能会引起进一步的崩溃。
- 在伪标签损失函数中第二部分有一个
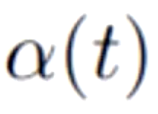 ,它的意思代表伪标签损失值占整个损失函数多大的比重。而这个
,它的意思代表伪标签损失值占整个损失函数多大的比重。而这个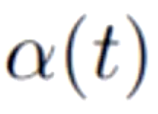 的权重值也是很难确定的。如果太小,则未标注数据就失去了作用;太大,如果预测出来的伪标签是不正确的,会导致损失结果难以收敛。
的权重值也是很难确定的。如果太小,则未标注数据就失去了作用;太大,如果预测出来的伪标签是不正确的,会导致损失结果难以收敛。
MixMatch半监督学习
MixMatch结合了之前说的几种方法,用了单个loss,将这几种方式进行合并,如一致性正则,最小化熵,传统正则。它有一个很重要的方法叫MixMatch,包含了标签的猜测以及锐化(Sharpening),

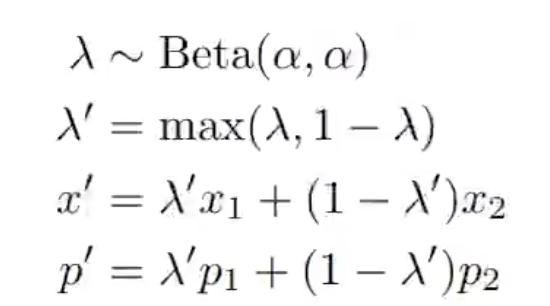
它取的有标记数据和无标记数据的BatchSize是一样大的,不过无标记数据会经过K个增强。首先会对有标记数据进行增强,再对无标记数据进行K次增强,再将增强后的无标记数据送入模型,每一种增强的无标记数据会预测一个结果,将结果取均值,然后再锐化。之后会得到有标记的数据,和无标记数据以及猜测出的标记,然后将这两种数据给拼接(concat)起来,组合成一个大的数据,再随机打乱与有标记数据和带猜测标签的无标记数据进行混合。最后再送入模型,求损失函数。
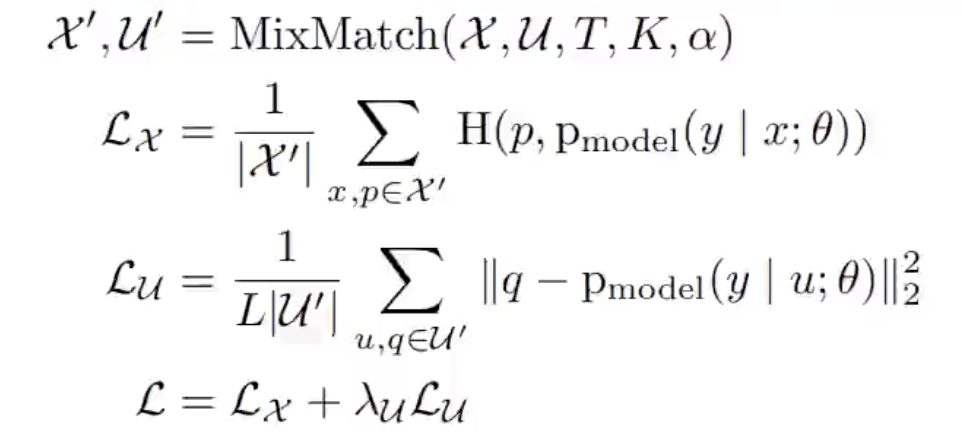
代码实现
超参数设置
import torch # ################################################################ # HyperParameters # ################################################################ # semi-supervised learning: # 1. model structure # 2. hype setting are important! class Hyperparameters: # ################################################################ # Data # ################################################################ device = 'cuda' if torch.cuda.is_available() else 'cpu' # cuda for training, cpu/cuda for inference classes_num = 10 # 分类数 n_labeled = 250 # 已标记数据总数 seed = 1234 # ################################################################ # Model # ################################################################ T = 0.5 # 锐化温度项(sharpen temperature) K = 2 # 数据增强次数 alpha = 0.75 # 伪标签损失权值 lambda_u = 75. # 一致性损失权值 # ################################################################ # Exp # ################################################################ batch_size = 8 init_lr = 0.002 epochs = 1000 verbose_step = 300 save_step = 300 HP = Hyperparameters()
数据集,这里使用的是cifar10数据集
import numpy as np from torchvision import transforms import torchvision import torch class TransformTwice: def __init__(self, transform): self.transform = transform def __call__(self, inp): out1 = self.transform(inp) out2 = self.transform(inp) return out1, out2 def get_cifar10(root, n_labeled, transform_train=None, transform_val=None, download=True): # 获取cifar10数据集 base_dataset = torchvision.datasets.CIFAR10(root, train=True, download=download) # 将该数据集拆分成有标记的训练数据集,无标记的训练数据集和验证集 train_labeled_idxs, train_unlabeled_idxs, val_idxs = train_val_split(base_dataset.targets, int(n_labeled / 10)) # datasset->dataload train_labeled_dataset = CIFAR10_labeled(root, train_labeled_idxs, train=True, transform=transform_train) train_unlabeled_dataset = CIFAR10_unlabeled(root, train_unlabeled_idxs, train=True, transform=TransformTwice(transform_train)) val_dataset = CIFAR10_labeled(root, val_idxs, train=True, transform=transform_val, download=True) test_dataset = CIFAR10_labeled(root, train=False, transform=transform_val, download=True) print(f"#Labeled: {len(train_labeled_idxs)} #Unlabeled: {len(train_unlabeled_idxs)} #Val: {len(val_idxs)}") return train_labeled_dataset, train_unlabeled_dataset, val_dataset, test_dataset def train_val_split(labels, n_labeled_per_class): labels = np.array(labels) train_labeled_idxs = [] train_unlabeled_idxs = [] val_idxs = [] for i in range(10): idxs = np.where(labels == i)[0] np.random.shuffle(idxs) train_labeled_idxs.extend(idxs[:n_labeled_per_class]) train_unlabeled_idxs.extend(idxs[n_labeled_per_class:-500]) val_idxs.extend(idxs[-500:]) np.random.shuffle(train_labeled_idxs) np.random.shuffle(train_unlabeled_idxs) np.random.shuffle(val_idxs) return train_labeled_idxs, train_unlabeled_idxs, val_idxs cifar10_mean = (0.4914, 0.4822, 0.4465) # equals np.mean(train_set.train_data, axis=(0,1,2))/255 cifar10_std = (0.2471, 0.2435, 0.2616) # equals np.std(train_set.train_data, axis=(0,1,2))/255 def normalise(x, mean=cifar10_mean, std=cifar10_std): x, mean, std = [np.array(a, np.float32) for a in (x, mean, std)] x -= mean*255 x *= 1.0/(255*std) return x def transpose(x, source='NHWC', target='NCHW'): return x.transpose([source.index(d) for d in target]) def pad(x, border=4): return np.pad(x, [(0, 0), (border, border), (border, border)], mode='reflect') class RandomPadandCrop(object): """Crop randomly the image. Args: output_size (tuple or int): Desired output size. If int, square crop is made. """ def __init__(self, output_size): assert isinstance(output_size, (int, tuple)) if isinstance(output_size, int): self.output_size = (output_size, output_size) else: assert len(output_size) == 2 self.output_size = output_size def __call__(self, x): x = pad(x, 4) h, w = x.shape[1:] new_h, new_w = self.output_size top = np.random.randint(0, h - new_h) left = np.random.randint(0, w - new_w) x = x[:, top: top + new_h, left: left + new_w] return x class RandomFlip(object): """Flip randomly the image. """ def __call__(self, x): if np.random.rand() < 0.5: x = x[:, :, ::-1] return x.copy() class GaussianNoise(object): """Add gaussian noise to the image. """ def __call__(self, x): c, h, w = x.shape x += np.random.randn(c, h, w) * 0.15 return x class ToTensor(object): """Transform the image to tensor. """ def __call__(self, x): x = torch.from_numpy(x) return x class CIFAR10_labeled(torchvision.datasets.CIFAR10): def __init__(self, root, indexs=None, train=True, transform=None, target_transform=None, download=False): super(CIFAR10_labeled, self).__init__(root, train=train, transform=transform, target_transform=target_transform, download=download) if indexs is not None: self.data = self.data[indexs] self.targets = np.array(self.targets)[indexs] self.data = transpose(normalise(self.data)) def __getitem__(self, index): """ Args: index (int): Index Returns: tuple: (image, target) where target is index of the target class. """ img, target = self.data[index], self.targets[index] if self.transform is not None: img = self.transform(img) if self.target_transform is not None: target = self.target_transform(target) return img, target class CIFAR10_unlabeled(CIFAR10_labeled): def __init__(self, root, indexs, train=True, transform=None, target_transform=None, download=False): super(CIFAR10_unlabeled, self).__init__(root, indexs, train=train, transform=transform, target_transform=target_transform, download=download) self.targets = np.array([-1 for i in range(len(self.targets))]) transform_train = transforms.Compose([ RandomPadandCrop(32), RandomFlip(), ToTensor(), ]) transform_val = transforms.Compose([ ToTensor(), ])
|








- 上一条: 案例分享|金融业数据运营运维一体化建设 2022-07-04
- 下一条: 开源之夏专访|Apache IoTDB社区 新晋Committer谢其骏 2022-07-04
- 技术+案例详解无监督学习Autoencoder 2021-11-10
- 智能计算时代 | SuperSQL基于监督学习模型的自适应计算提效能力 2022-04-07
- 论文解读丨无监督视觉表征学习的动量对比 2021-11-17
- 3种基于深度学习的有监督关系抽取方法 2022-02-16
- 机器学习和深度学习的区别 2022-02-18


