智能计算时代 | SuperSQL基于监督学习模型的自适应计算提效能力
天穹SuperSQL是腾讯自研、基于统一SQL语言模型、面向机器学习智能调优、提供虚拟化数据和开放式计算引擎的大数据智能融合平台。在开放融合的Data Cloud上,业务方可以消费完整的数据生命周期(采集-存储-计算-分析-洞察),还能够满足位于不同数据中心、不同类型数据源的数据联合分析/即时查询的需求。
目前,SuperSQL已经迈入智能计算时代,
SuperSQL能够基于规则匹配(RBO)与代价估算(CBO),利用不同算法智能地为不同用户SQL挑选最合适的执行引擎,极大地优化SQL执行效率与大幅度降低失败计算带来的资源浪费。除此之外,SuperSQL已经能够利用强化学习模型获得历史SQL的执行结果,来决定当前用户SQL的最佳执行引擎。执行每个操作后,SuperSQL将收到机器学习算法反馈,确定所作的选择是否最优,从而实现大量小决策的自动化系统。
总的来说,SuperSQL智能自适应计算是一个自动的、面向用户透明的,后端自我学习的过程,当前为典型现网业务SQL取得了7~16倍的性能提升,也降低了日均规避30%的失败SQL。
一、为何需要自适应计算提效?
SuperSQL通过对接不同类型的外部计算(执行)引擎,来实现异构数据源之上的联邦查询和分析。例如,TDW Hive与社区Hive库表之间的Join,MySQL与PG库表的Union,等等。SuperSQL当前支持的分布式计算引擎,包括 Livy(底层对接Spark3)【1】、Hive (MapReduce)和Presto。SuperSQL用户可以通过下面的SET命令,来手动设置执行跨源查询时所使用的计算引擎:
// 支持 livy、presto和hive 三种引擎类型
// 默认为特殊值“auto”(不可通过参数设置),表示自动挑选引擎
set `supersql.execution.engine` = presto;
业务场景的复杂多样,以及各类引擎技术特性的明显区别(如下表),导致了单一引擎无法很好地满足所有用户的SQL执行需求,这也是SuperSQL设计之初引入多引擎对接框架的初衷。但很多情况下,针对具体的一条SQL语句,用户很难判断应该用哪个引擎来执行会更为高效,只能不断切换引擎重试,体验较差,使用门槛高。同时SQL执行的效率也较低(如失败、卡住、占用大量资源等)。针对这一瓶颈,SuperSQL V3.x版本新增实现了智能计算提效的优化,覆盖了SuperSQL对接的Presto、Spark与Hive MR计算引擎。
|
引擎类型
|
Presto
|
Livy(Spark3)
|
社区Hive
|
|
计算模型
|
MPP
|
DAG
|
MapReduce(暂不考虑Tez、LLAP)
|
|
适合SQL类型
|
DQL(select/with)
|
DQL,DML(insert/create-table-as-select/...)
|
DDL,元数据命令(show/desc/...)
|
|
SQL执行速度
|
快
|
介于Presto与MR之间
|
慢
|
|
支持数据量
|
中等
|
海量
|
海量
|
|
稳定性
|
一般(内存溢出、worker掉线等)
|
介于Presto与MR之间
|
好
|
|
跨源JDBC
|
缺少动态数据源添加,目前仅支持hdfs访问内部TDW/社区Hive库表
|
支持读写,如从用户MySQL导入数据到TDW,基于Spark JDBC DataSource
|
支持读取,暂不支持写入,基于Hive JDBC StorageHandler
|
二、什么是智能计算提效?
SuperSQL智能计算提效,
简单来讲就是系统智能选择计算引擎,以达到自动SQL提效的目的。具体地说,结合SQL语句的语法特征、访问库表的数据量、引擎的技术特性与实例负载等因素,
SuperSQL智能地为不同的用户SQL,实时挑选最合适的计算引擎来执行,免去用户手动挑选的过程。这是一个多因子决策决策的过程,通过智能计算优化,用户不需要预先了解底层基础设施的状况和大数据计算引擎的知识,极大地降低了使用门槛,促进大数据服务的普及化。同时缩短SQL执行的时间(如小SQL使用Presto),和增强SQL执行的可靠性(如海量大SQL使用Spark)。
没有引入计算提效优化之前,SuperSQL默认的跨源计算引擎是Livy(Spark3),而单源SQL则是TDW Hive(THive)中的Spark 2.x。由于Spark Yarn资源申请的开销,不少轻量级、访问较小TDW库表的用户SQL,执行时间较为缓慢,用户体验不好。
使用Presto引擎来自动加速这部分SQL,是当前SuperSQL计算提效的重点任务。
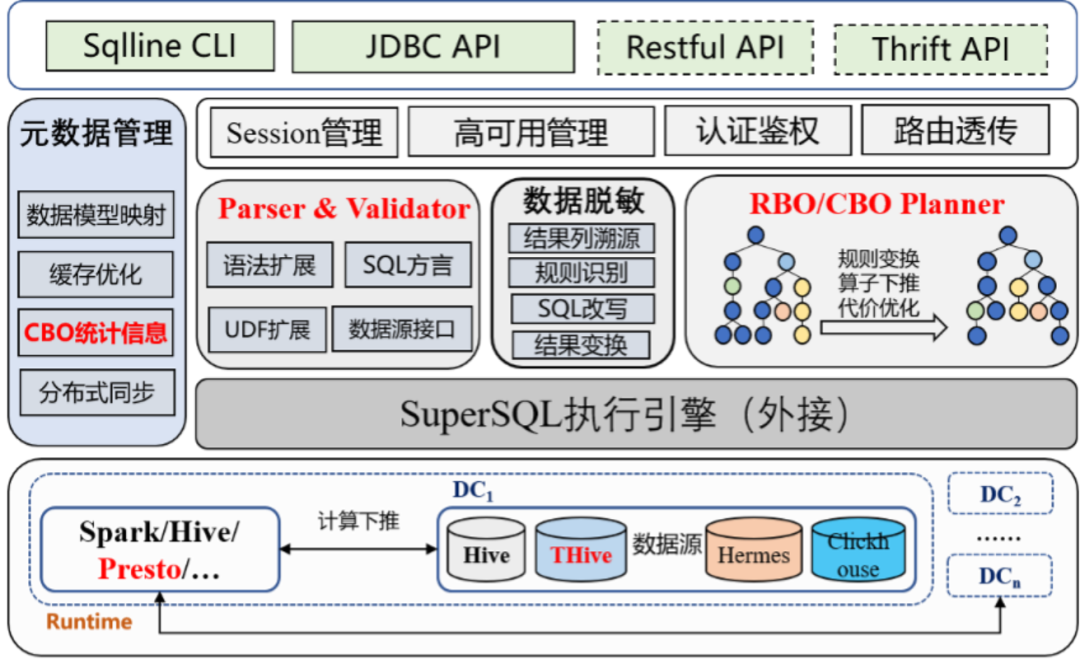
SuperSQL的整体系统架构与技术沙盘如上图,其中计算提效主要涉及的功能点高亮显示,具体包括:
1.语法兼容
:为实现计算提效的
用户透明性
,SuperSQL扩展了其支持的SQL语法(Parser/Validator),兼容了绝大部分非ANSI标准的TDW SQL特殊语法。用户之前在IDEX、US等上层业务平台上保存的、以TDW语法书写、提交THive执行的SQL脚本,可以不用修改直接通过SuperSQL转发Presto执行,语法改写和适配由SuperSQL来完成。这里技术挑战主要在于TDW与Presto UDF语法或语义上的不匹配性、TDW部分表列名为SuperSQL保留字等。
2.提效判定
:通过对某个SQL对应的
最优物理计划树
进行一系列的RBO匹配与检测,以及对执行计划树中的Scan或Join节点进行CBO大小估算,
这类SQL会自动回退Livy + Spark3(跨源)或者THive(单源)执行。这里技术难点主要是RBO规则的选定与CBO算子的代价(输出字节数)估算。
3.Presto扩展
:社区Presto版本,其SQL语法与部分算子/UDF的计算结果,均与THive不相兼容。为此我们增强了Presto的兼容性,主要包括隐式类型转换和mapjoin/partition语法支持等。
三、如何实现计算提效?
RBO/CBO提效框架
SuperSQL计算提效决策算法:在前序Calcite RBO/CBO VolcanoPlanner/HepPlanner【2】变换生成最优物理计划树之后,新增的一个独立优化阶段,与前序阶段无耦合。下表概括了SuperSQL当前判定Presto计算提效所使用的规则匹配和代价估算算法。这里RBO/CBO的决策的输出结果是:用户的SQL是否
无法
使用Presto进行计算提效。
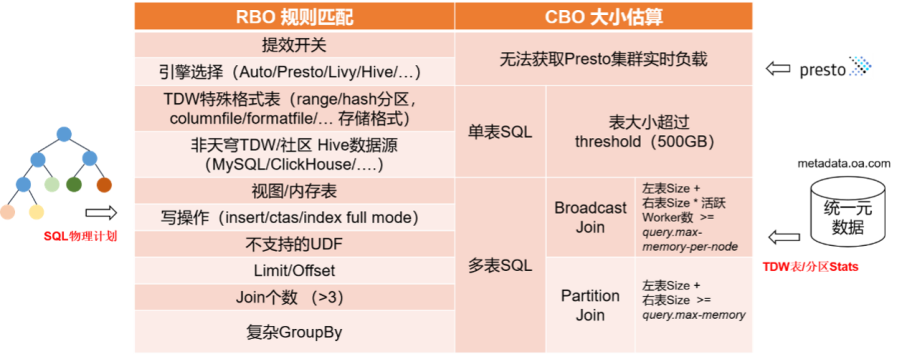
RBO中所使用的规则定义,是基于开发测试经验总结归纳,目的是过滤Presto语法不兼容或没有执行性能优势的SQL。例如,SQL中包含Presto无法访问的Thive特殊格式表或Hive视图、Join的数量超过阈值(目前为3)、写操作等。由于Presto目前无法像THive那样确保LIMIT时返回最新分区的最新数据,含LIMIT/OFFSET的SQL当前还无法自动提效,这个功能我们正在实现。
CBO的作用是估算并过滤Scan(单表SQL)或Join(多表SQL)输入大小超过系统定义阈值的情况,避免单条SQL Presto执行过程中的内存溢出,或者占用大量系统资源影响其它SQL的执行。每次CBO提效检测之前,SuperSQL会通过JDBC API从对应的Presto集群获取实时负载信息,包括active worker节点数、单查询最大内存配置
query.max-memory
和
query.max-memory-per-node
参数值等。TDW库表或分区对应的统计信息(Stats),包含行数、字节数等,SuperSQL通过定制的Stats API从元数据库中获取。结合两者,CBO通过经验公式进行Scan/Join大小估算,并与阈值(经验值)对比。
目前SuperSQL的决策树算法正在迭代优化中,一是因为Presto资源是共享的,避免作业饿死的情况,二是Presto对THive兼容性度还在不断提升中
。当前集合中的规则会不断迭代更新,后续越来越多的SQL走Presto计算提效。
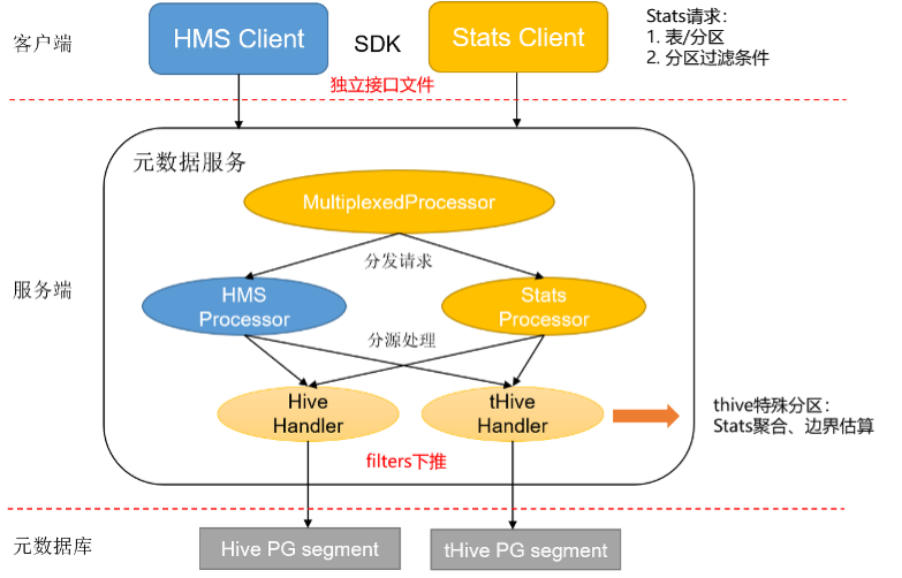
TDW Stats获取
为支持SuperSQL实时获取THive或Hive库表的CBO统计信息(TDW Stats),我们扩展了统一元数据库的服务端处理器与客户端SDK,目的是把这块专有逻辑与之前的HMS(Hive Metastore Service)通用标准实现隔离,从而不影响现网其它使用服务使用元数据。其中客户端基于独立的thrift接口定义文件开发,而服务端针对thive特殊分区格式(range/hash/多级list)开发了基于聚合与边界切分的分区过滤条件Stats估算,即支持SuperSQL输入一个或多个分区字段之上的Filter条件,计算输出该条件对应的Stats估算值。
失败failover
当Presto提效SQL因异常原因执行失败时,为降低对用户的影响,SuperSQL实现了自动切换其它引擎重试执行(failover)的机制,减轻用户手动变换引擎的负担,具体规则如下:
1.THive SQL
:如果用户SQL中访问的所有库表都是THive表,提交THive Server重试。THive会先用其Spark 2.x引擎重新执行该SQL,如果再次失败则转用MR。
2.Thive + Hive SQL
:如果用户SQL同时访问了THive和社区Hive库表,或者只访问了社区Hive库表,提交Livy + Spark3重试。
四、提效效果
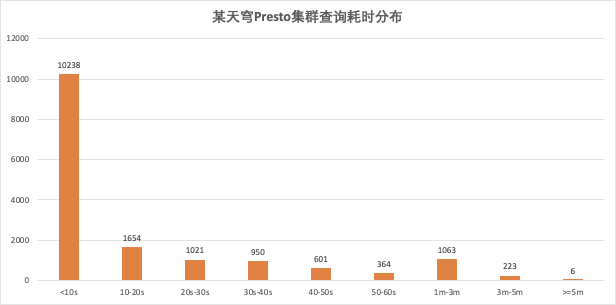
目前天穹Presto现网集群日均执行SQL数10W+查询。以其中某一集群为例,每日约1.6W+次查询,P65的SQL查询耗时在10s以内,P90的查询耗时为50s,每日查询涉及到约5000张TDW Hive表、处理数据量约1.8PB、记录数约44W亿。在目前比较温和的决策树算法下,根据典型业务流水统计, 25%的查询SQL会路由到Presto,完成计算加速,性能提升多达7倍。
Presto vs Hive
下图显示了当前内部某业务的提效效果。典型的不同类型的业务SQL,在SuperSQL计算提效加持下,取得平均多达16倍的性能提升。

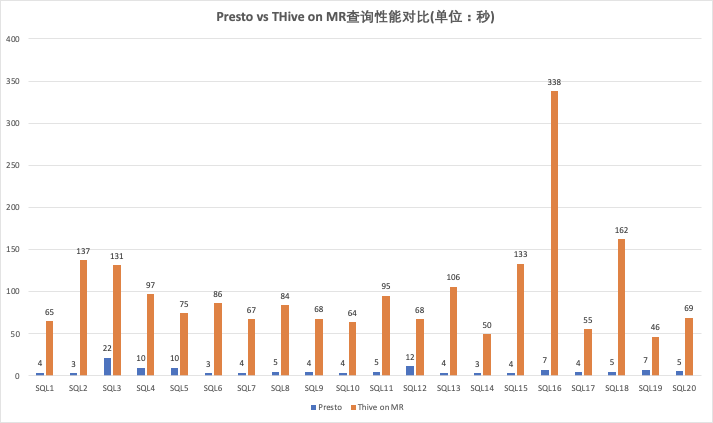
Presto vs THive
通过Presto及THive执行的部分现网业务SQL的查询性能对比,Presto相比THive on Spark、THive on MR分别能有7倍、18倍的平均性能提升(均去掉2个最高值和2个最低值)

五、总结
Presto的监督学习决策树算法实现了SuperSQL在智能引擎选择方向上从0到1的突破。2022年年初,我们已经在集团内部利用强化学习模型(HBO)实现更复杂的执行优化,实现提效降本的目标【3】。
未来我们会在机器学习的方向上持续演进,通过检测大数据计算过程中的每一步操作,提升引擎选择框架的灵活性(规则模板)、可扩展性(规则可热拔插)与通用性(公共引擎适配层),进一步深化SuperSQL在大数据计算领域的智能化。
六、联系我们
如果你对SuperSQL感兴趣,欢迎联系我们探讨技术。同时我们长期热烈欢迎大数据人才加入,欢迎咨询。联系方式:yikonchen@tencent.com
参考
【1】 Apache Livy
【2】 ApacheCalcite
【3】 <即将发布>
|








- 上一条: 16台服务器达成1000万tpmC!挑战分布式数据库性能极限 2022-04-07
- 下一条: 《Mybatis 手撸专栏》第3章:实现映射器的注册和使用 2022-04-07
相关文章
- 第4章 计算机系统的应用 ·4.4 人工智能与专家系统 2021-07-15
- 第4章 计算机系统的应用 ·4.1 计算机网络 2021-07-15
- 第3章 计算机系统的软件·3.1 计算机软件概述 2021-07-11
- 计算机接口技术 2021-07-19
- 第4章 计算机系统的应用 ·4.6 计算机信息安全与职业道德 2021-07-15
热度排行


