自然语言处理——文本向量化(二)
一. 摘要
本次分享内容是基于上篇文本向量方法的继续,上次内容中,主要分享了文本向量化的两种方法:词袋模型表示方法和基于深度学习词向量方法。词袋模型虽然能够很简单的将词表示为向量,但会造成维度灾难,并且不能够利用到文本中词顺序等信息。NNLM模型的目标是构建一个语言概率模型,但是在nnlm模型求解的过程中,从隐藏层到输出层的权重计算是非常费时的一步。下面我们将了解下C&W模型、CBOW模型和Skip-gram模型。
二. C&W模型
C&W模型是一个以生成词向量为目标的模型。在之前的NNLM模型中我们了解到了他那难于计算的权重是一个非常大的障碍。这里的C&W模型没有采用语言模型的方式去求解词语上下文的条件概率,而是直接对n元短语打分。采用的是一种更为快速高效的获取词向量的方式。C&W模型的核心思想是:如果n元短语在语料库中出现过,那么模型就会给该短语打出较高的分数;对于在语料库中未出现过或出现次数很少的短语则会得到较低的分数。C&W模型结构图如下:
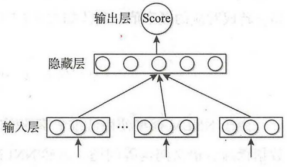
图1:C&W模型结构图
相对于整个语料库来说,C&W模型需要优化的目标函数为:
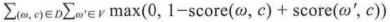
图2:C&W模型目标函数
其中,(w,c)为从语料中抽取的n元短语,为保证上下文词数量的一致性,所以n为奇数;w是目标词;c表示目标词的上下文语境;w’是从词典中随机抽取出的一个词语。C&W模型采用的是成对词语的方式对目标函数进行优化。通过图2中的表达式可知,目标函数期望正样本的得分比负样本至少高1分。这里的(w,c)表示正样本,这些样本来自语料库;(w’,c)表示的负样本,负样本是将正样本序列的中间词替换成其它词得到的。通常情况是,用一个随机的词语替换正确文本序列的中间词,由此得出的新的文本序列基本就是不符合语法习惯的序列,因此这种构造负样本的方法是合理的。并且负样本是仅仅修改了正样本序列中某一个中间词得到的,所以整体的语境是没有改变的,因此也不会对分类效果造成很大效果。
与NNLM模型的目标词在输出层不同,C&W模型的输出层就包含了目标词,其输出层也变成一个节点,并且该节点的输出值大小代表着元短语的打分高低。相应的C&W模型的最后一层的运算次数为|h|,远低于NNLM模型中的|V|×|h|次。在权重计算量方面,相较NNLM模型,C&W模型可降低运算量。
三. CBOW模型和Skip-gram模型
为了能够提高获取词向量的效率,通过不断地尝试总结,在NNLM和C&W模型的基础上,得出了CBOW(Continuous Bag of-Words)模型和Skip-gram模型。
CBOW模型是使用一段文本的中间词当作目标词,并且在结构上,去掉了隐藏层,这样可以使运行的速率大幅度的提升,节省掉很多的权重矩阵计算。此外CBOW模型使用上下文各词的词向量平均值代替NNLM模型各个拼接的词向量。由于CBOW模型去除掉了隐藏层,所以其输入层就是语义上下文的表示。
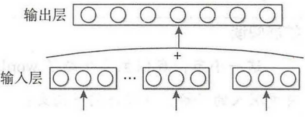
图3:CBOW模型结构图
CBOW模型对目标词的条件概率计算表达式为:
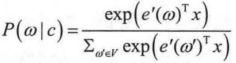
图4:CBOW概率计算表达式
CBOW模型基于神经网络的一般形式:
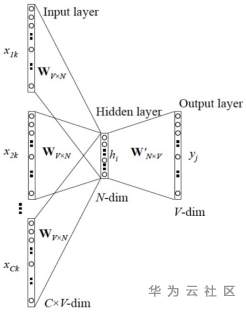
图5:CBOW模型一般形式
CBOW模型的目标函数与NNLM模型类似,具体为最大化式:
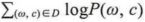
图6:模型最大化部分
Skip-gram模型的结构同样也是没有隐藏层。和CBOW模型不同的是输入上下文的平均词向量。Skip-gram模型是从目标词w的上下文中选择一个词,将其词向量组成上下文的表示。
图7:Skip-gram模型结构图
Skip-gram模型基于神经网络的一般形式:
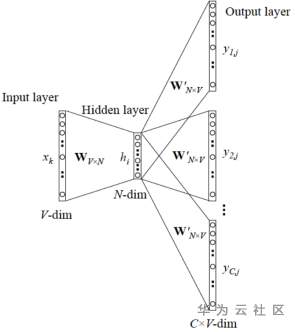
图8:Skip-gram模型一般形式
对于整个语料库来说,Skip-gram模型的目标函数表达式为:

图9:Skip-gram模型目标函数表达式
Skip-gram模型和CBOW模型实际上属于word2vec两种不同策略的实现方法:其中的CBOW的策略是根据上下文输入来预测当前词语的概率,并且上下文中的所有的词对当前词出现概率的影响的权重是相同的,因此也叫continuous bag-of-words模型。就类似从一个袋子中取词,取出数量足够的词就可以了,而对于取出的顺序是没有要求的。Skip-gram模型则刚好相反,它的策略和目的是将当前词当作输入,用来预测上下文概率。
总结
本次内容中的两个模型思想都属于word2vec范围。在NLP中,如过将x看作一个句子中的一个词语,y是这个词语的上下文,那么我们需要一个语言模型f(),这个模型的使命就是判断(x,y)这个样本是否符合自然语言的规则。Word2vec并不注重将这个语言模型训练的多么精确,而是关心模型训练后得到的模型参数,并将这些参数作为x的向量化表示,这便是词向量的形成。基于此,便衍生了上面CBOW模型和Skip-gram模型。
|








- 上一条: StratoVirt 的中断处理是如何实现的? 2022-01-26
- 下一条: hdfs——nn的启动优化 2022-01-26
- 基于机器学习和TFIDF的情感分类算法,详解自然语言处理 2022-01-05
- StarRocks 技术内幕:向量化编程精髓 2022-08-22
- 系统召回太慢?上 Milvus × PaddleRec 双剑合璧大法! 2021-10-08
- PaddleFSL:基于飞桨的小样本学习工具包 2021-11-08
- 千万量级图片视频快速检索,轻松配置设计师的灵感挖掘神器 2021-09-28


