StarRocks 技术内幕:向量化编程精髓
作者:康凯森,StarRocks PMC,负责查询方向的研发
本文是对我在 StarRocks 线下 MeetUp 演讲的整理,主要分为三部分:第一部分简要介绍向量化的基础知识,第二部分讲解数据库如何进行向量化,最后是 StarRocks 向量化实践后的一些粗浅思考。
#01
向量化为什么可以提升数据库性能?
—
本文所讨论的数据库都是基于 CPU 架构的,数据库向量化一般指的都是基于 CPU 的向量化,因此数据库性能优化的本质在于:一个基于 CPU 的程序如何进行性能优化。这引出了两个关键问题:
1. 如何衡量 CPU 性能
2. 哪些因素会影响 CPU 性能
第一个问题的答案可以用以下公式总结:CPU Time = Instruction Number * CPI * Clock Cycle Time
-
Instruction Number 表示指令数。当你写一个 CPU 程序,最终执行时都会变成 CPU 指令,指令条数一般取决于程序复杂度。
-
CPI 是 (Cycle Per Instruction)的缩写,指执行一个指令需要的周期。
-
Clock Cycle Time 指一个 CPU 周期需要的时间,是和 CPU 硬件特性强关联的。
我们在软件层面可以改变的是前两项:Instruction Number 和 CPI。那么问题来了,具体到一个 CPU 程序,到底哪些因素会影响 Instruction Number 和 CPI 呢?
我们知道 CPU 的指令执行分为如下 5 步:
1. 取指令
2. 指令译码
3. 执行指令
4. 内存访问
5. 结果写回寄存器
其中 CPU 的 Frontend 负责前两部分,Backend 负责后面三部分。基于此,Intel 提出了 《Top-down Microarchitecture Analysis Method》的 CPU 微架构性能分析方法,如下图所示:
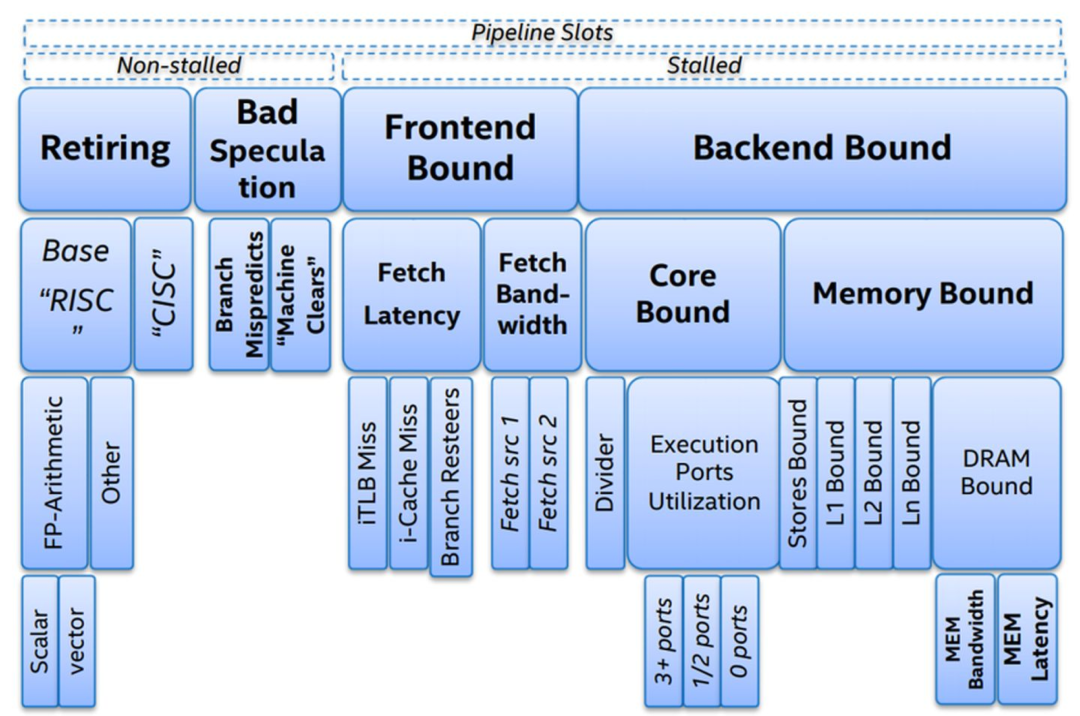
Top-down Microarchitecture Analysis Method 的具体内容大家可以参考相关的论文,本文不做展开,为了便于大家理解,我们可以将上图简化为下图(不完全准确):
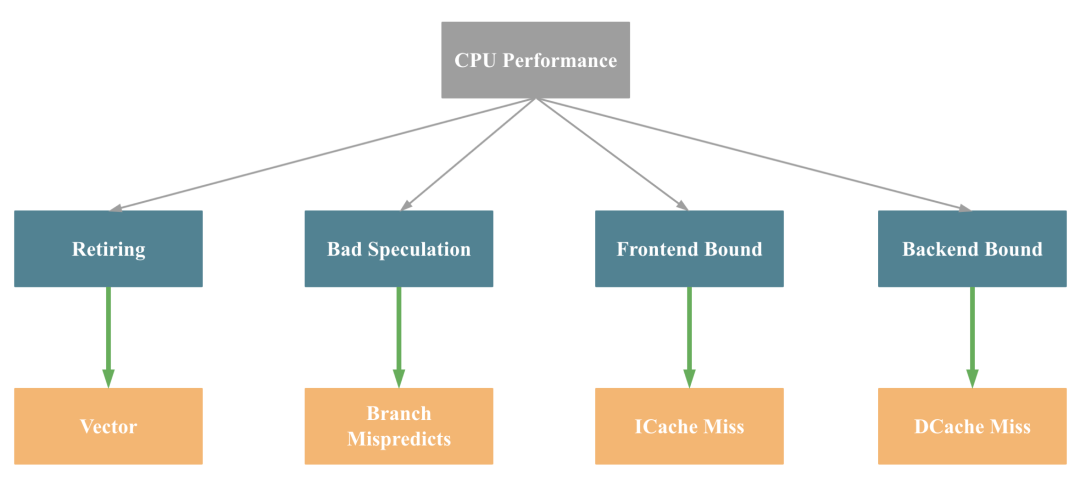
即影响一个 CPU 程序的性能瓶颈主要有4大点:Retiring、Bad Speculation、Frontend Bound 和 Backend Bound,4个瓶颈点导致的主要原因(不完全准确)依次是:缺乏 SIMD 指令优化,分支预测错误,指令 Cache Miss, 数据 Cache Miss。
再对应到之前的 CPU 时间计算公式,我们就可以得出如下结论:
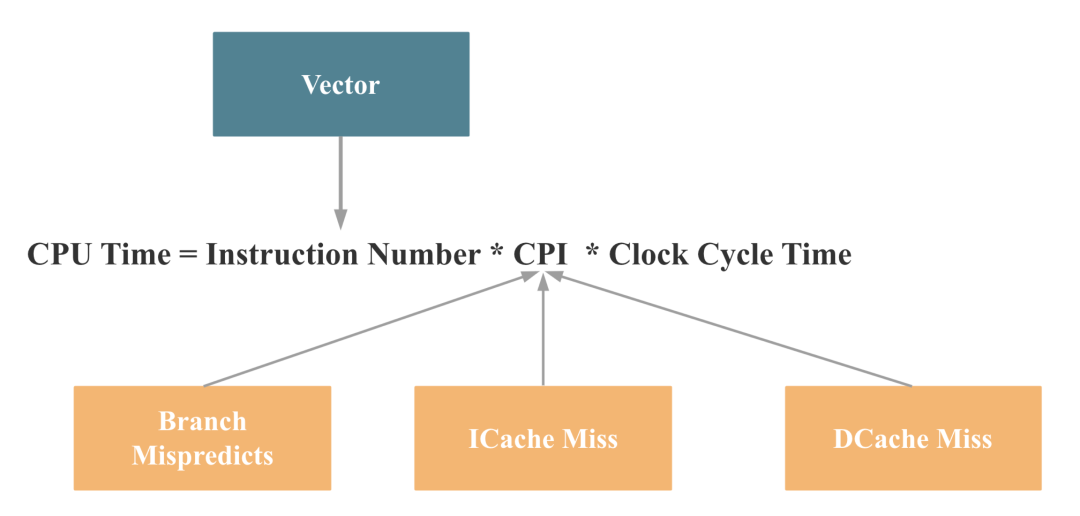
而数据库向量化对以上 4 点都会有提升,后文会有具体解释,至此,本文从原理上解释了为什么向量化可以提升数据库性能。
#02
向量化基础知识
—
在了解数据库如何向量化之前,我们先理解一些向量化的基础知识。
注意,在第二个章节里面,向量化一词可以理解为和 SIMD 等价,仅指狭义上的 CPU SIMD 向量化,与数据库领域广义的向量化含义不同。
1、SIMD 简介
SIMD 是 Single Instruction Multiple Data 的缩写,指单个指令可以操作多个数据流,与之相对的是传统的 SISD,单指令单数据流。
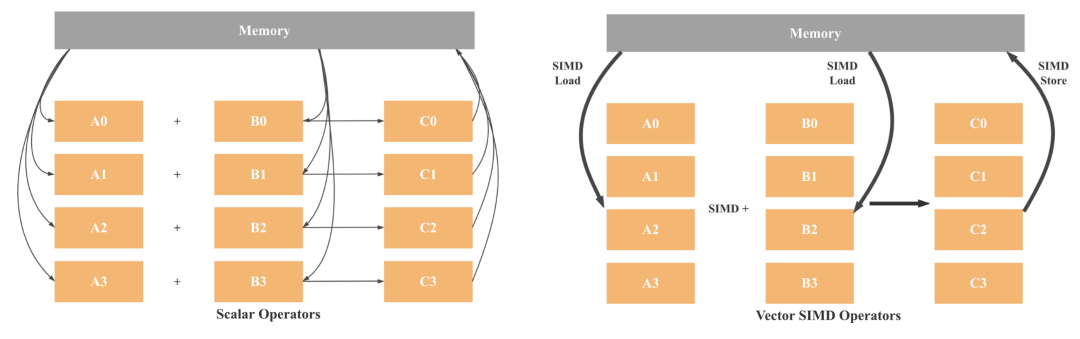
如上图所示,对于最简单的 A + B = C,假如我们要计算 4 组加法,传统的 SISD 需要执行 8 次 Load 指令 (A 和 B 分别4次)、4 次 Add 指令、4 次 Store 指令。但当我们使用 128 位宽的 SIMD, 我们只需要 2 次 Load 指令、1 次 Add 指令、1 次 Store 指令,这样理论上就可以获得 4 倍的性能提升。而目前的向量化寄存器位宽已经发展到 512 位,理论上 Int 的加法操作就可以加速 16 倍。
2、如何触发向量化?
如前文所述,SIMD 指令会带来巨大的性能提升,数据库开发人员自然需要理解并掌握如何进行 SIMD 编程。
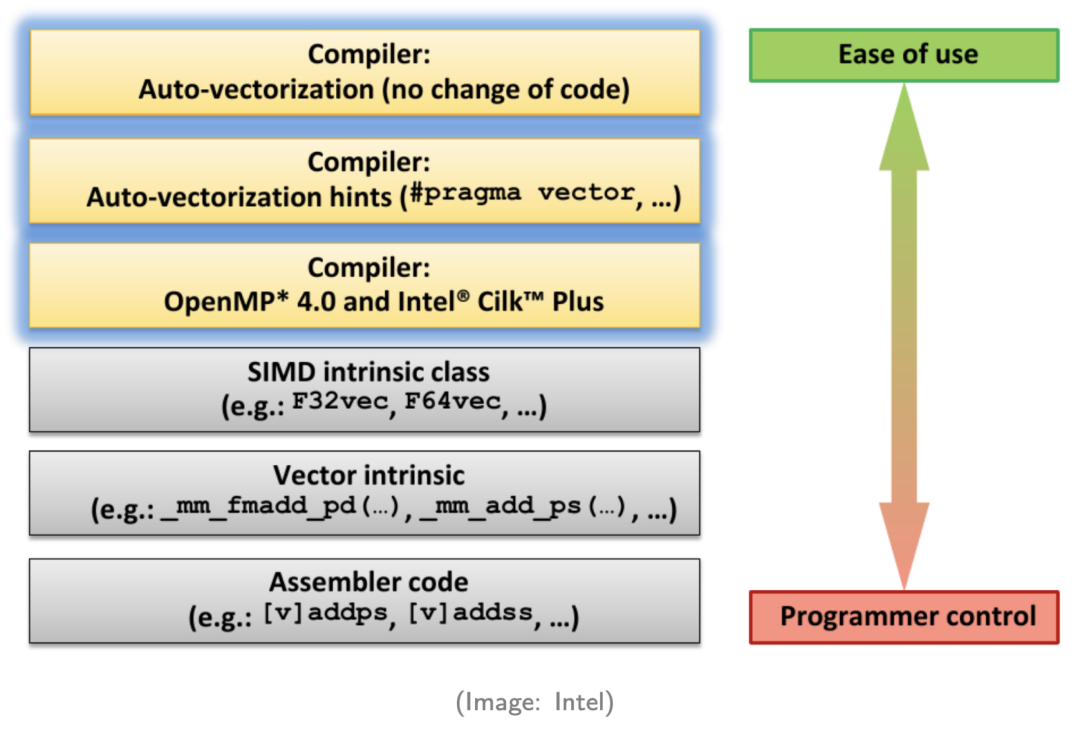
如上图所示,SIMD 触发向量化一般有 6 种方式,这 6 种方式自顶向下,对工程师的要求越来越高,需要手动编写的东西越来越多。
-
第一种是编译器自动向量化,代码不需要做特殊处理和改动,编译自动将默认的标量代码转换成向量化代码。但编译器默认只能处理比较简单的程序,具体支持的 Case 大家可以在网上搜索,资料很多;
-
第二种是我们给编译器一些 Hint,给编译器更多的信息和上下文,编译器也可以生成 SIMD 指令;
-
第三种是使用像 OpenMP 或者 Intel Cilk 这种并行编程 API,开发者可以加一些 Pragma 来生成 SIMD 指令;
-
第四种是使用一些 SIMD Intrinsics 的包装类;
-
第五种是直接使用 SIMD Intrinsics 编程;
-
最后一种是直接写汇编代码。
在 StarRocks 项目中,我们向量化的原则是尽可能触发编译器的自动向量化,也就是第一种和第二种,对于不能自动向量化但是性能又很关键的操作,我们会通过 SIMD Intrinsics 的方式手动向量化。
关于如何触发编译器的自动化,如何给编译器加 Hint 触发向量化以及如何通过 SIMD Intrinsics 的方式手动向量化大家可以参考我个人博客《数据库学习资料》向量化部分的资料,本文不再赘述。
《数据库学习资料》:https://blog.bcmeng.com/post/database-learning.html
3、如何验证程序生成了向量化代码?
当一个项目代码比较复杂时,如何确保代码触发向量化是很常见的问题。 我们可以通过两种方式来检查:
第一种是给编译器加一些编译选项,编译器会输出某些代码是否触发向量化,以及没有向量化的原因。比如 GCC 编译器,我们可以加入 -fopt-info-vec-all 或者 -fopt-info-vec-optimized,-fopt-info-vec-missed,-fopt-info-vec-note 编译选项。效果如下图所示:

第二种方法,我们可以直接查看最终执行的汇编代码,比如使用 https://gcc.godbolt.org/ 等网站或者 Perf、Vtune 等工具,如果汇编代码里面的寄存器是 xmm,ymm,zmm 或者指令以 v 开头,一般就说明代码触发了向量化。
#03
数据库向量化
—
1、数据库向量化的核心
StarRocks 的向量化引擎从写下第一行代码到成为一款成熟、稳定、世界领先的查询执行器,已经有 2 年多的时间,以我们的经验来看,数据库的向量化并不仅仅是触发 CPU 的 SIMD 向量化,而是一个巨大的、系统化的性能优化工程。
2、数据库向量化的挑战
数据库向量化的挑战主要有以下几点:
1. 全面的列式布局:在磁盘,内存,网络中全部都是列式布局,这意味存储引擎和计算引擎的完全重构
2. 所有算子、表达式和函数支持向量化:这意味数人年的工作
3. 算子和表达式计算尽可能使用 SIMD 指令:这意味着大量 Case By Case 的细致优化
4. 重新设计内存管理:因为处理的数据从一行变成了数千行
5. 重新设计数据结构:比如 Join、Aggregate、Sort 等核心算子的数据结构都需要进行改变
6. 整体性能提升 5 倍以上:所有的算子和表达式性能都要提升 5 倍以上,意味着全面地、系统地性能优化,所有重要的算子和表达式性能都不能有短板
3、算子和表达式向量化的关键点
数据库的向量化在工程上主要体现在算子和表达式的向量化,而算子和表达式的向量化的关键点就一句话:Batch Compute By Column, 如下图所示:
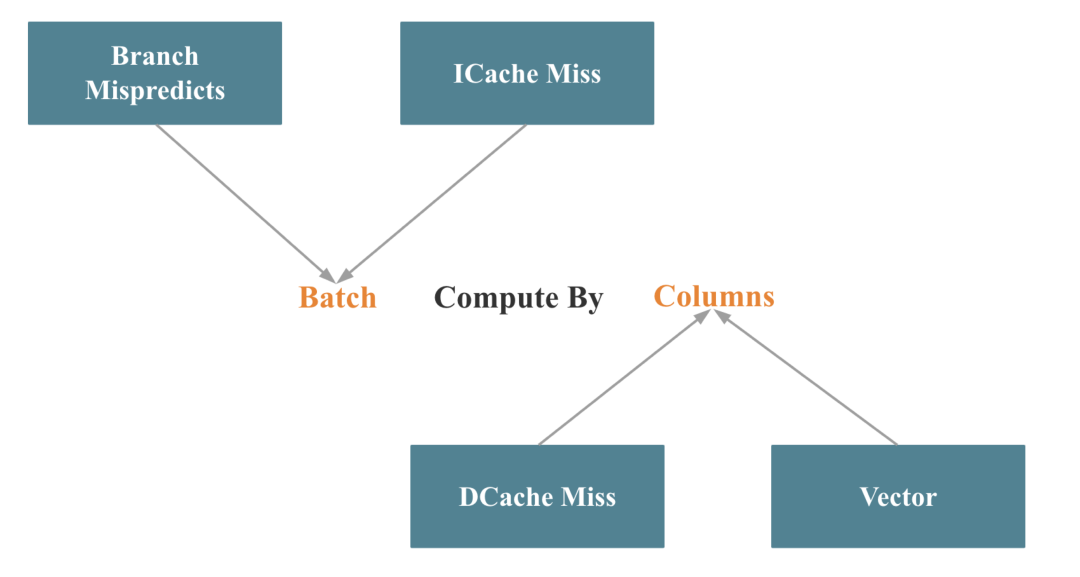
对应 Intel 的 Top-down 分析方法,Batch 优化了 分支预测错误和指令 Cache Miss,By Column 优化了 数据 Cache Miss,并更容易触发 SIMD 指令优化。
Batch 这一点其实比较好做到,难点是对一些重要算子,比如 Join、Aggregate、Sort、Shuffle 等,如何做到按列处理,更难的是在按列处理的同时,如何尽可能触发 SIMD 指令的优化。每个算子的按列处理和 SIMD 指令优化我们会在之后的 《StarRocks 查询源码解析》系列文章中详细解释。
4、数据库向量化如何进行性能优化
前面提到,数据库向量化是一个巨大的、系统的性能优化工程,两年来,我们实现了数百个大大小小的优化点。我将 StarRocks 向量化两年多的性能优化经验总结为 7 个方面 (注意,由于向量化执行是单线程执行策略,所以下面的性能优化经验不涉及并发相关):
1. 高性能第三方库:在一些局部或者细节的地方,已经存在大量性能出色的开源库,这时候,我们可能没必要从头实现一些算法或者数据结构,使用高性能第三方库可以加速我们整个项目的进度。在 StarRcoks 中,我们使用了 Parallel Hashmap、Fmt、SIMD Json 和 Hyper Scan 等优秀的第三方库。
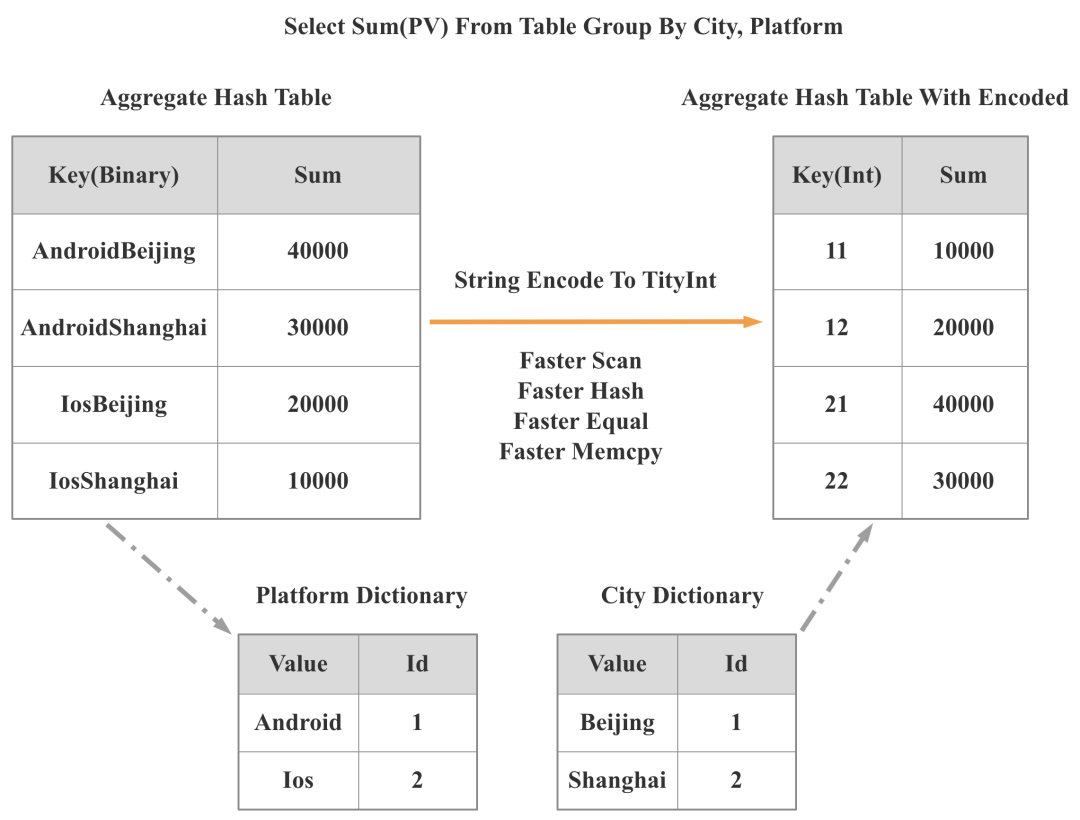
2. 数据结构和算法:高效的数据结构和算法可以直接在数量级上减少 CPU 指令数。在 StarRocks 2.0 中,我们引入了低基数全局字典,可以通过全局字典将字符串的相关操作转变成整形的相关操作。如下图所示,StarRcoks 将之前基于两个字符串的 Group By 变成了基于一个整形的 Group By,这样 Scan、Hash 计算、Equal、Memcpy 等操作都会有数倍的性能提升,整个查询最终会有 3 倍的性能提升。
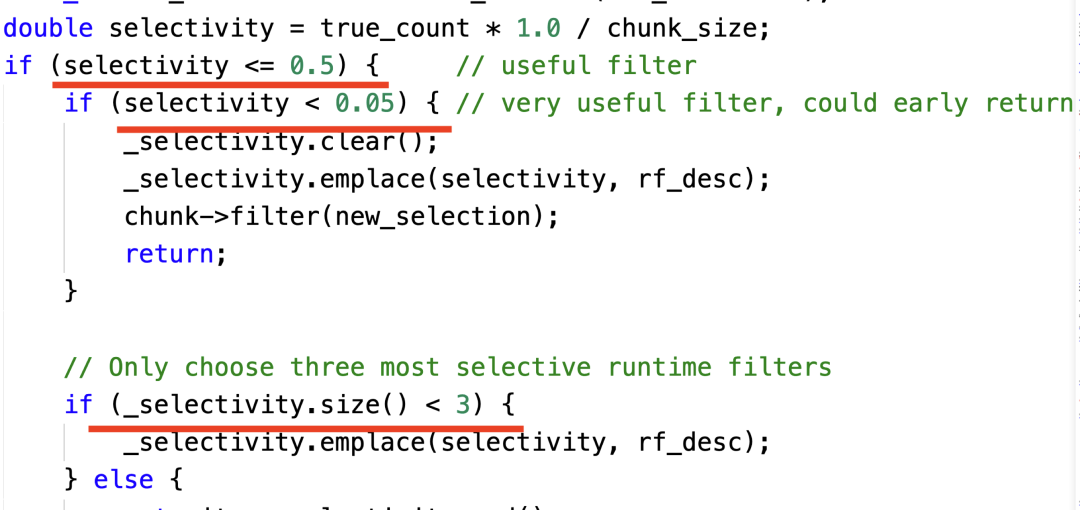
3. 自适应优化:很多时候,如果我们拥有更多的上下文或者更多的信息,我们就可以做出更多针对性的优化,但是这些上下文或者信息有时只能在查询执行时才可以获取,所以我们必须在查询执行时根据上下文信息动态调整执行策略,这就是所谓的自适应优化。下图展示了一个根据选择率动态选择 Join Runtime Filter 的例子,有 3 个关键点:
a. 如果一个 Filter 几乎不能过滤数据,我们就不选择;
b. 如果一个 Filter 几乎可以把数据过滤完,我们就只保留一个 Filter;
c. 最多只保留 3 个有用的 Filter
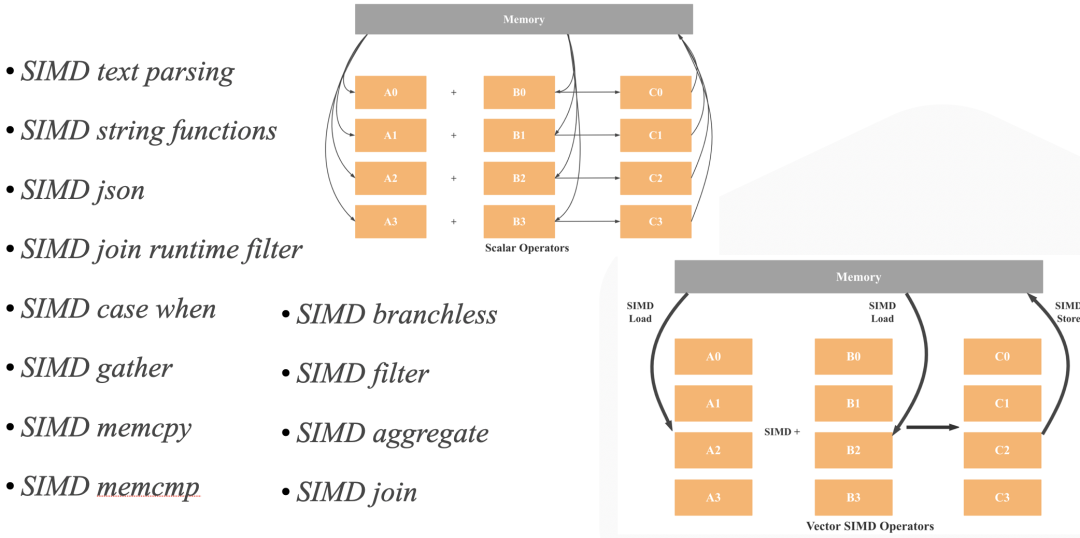
4. SIMD 优化:如下图所示,StarRcoks 在算子和表达式中大量使用了 SIMD 指令提升性能。
5. C++ Low Level 优化:即使是相同的数据结构、相同的算法,C++ 的不同实现,性能也可能相差好几倍,比如 Move 变成了 Copy,Vector 是否 Reserve,是否 Inline, 循环相关的各种优化,编译时计算等等。
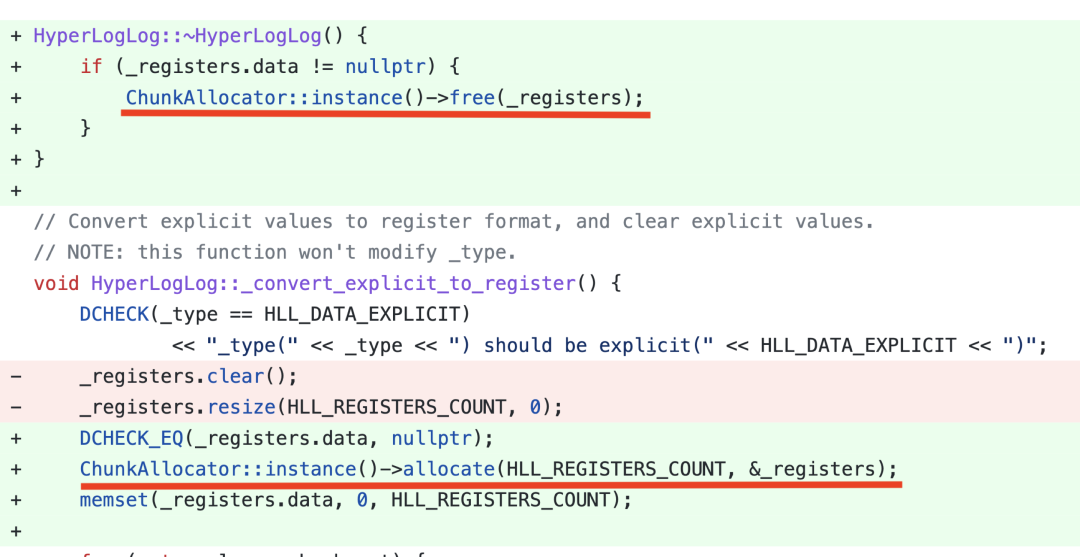
6. 内存管理优化:当 Batch Size 越大、并发越高,内存申请和释放越频繁,内存管理对性能的影响越大。我们实现了一个 Column Pool,用来复用 Column 的内存,显著优化了整体的查询性能。下图是一个 HLL 聚合函数内存优化的代码示意,通过将 HLL 的内存分配变成按 Block 分配,并实现复用,将 HLL 的聚合性能直接提升了 5 倍。
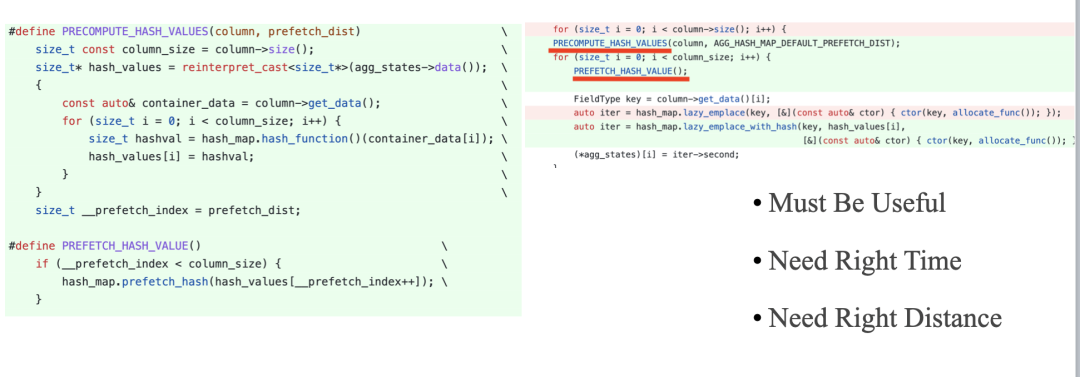
7. CPU Cache 优化:做性能优化的同学都应该对下图的数据了熟于心,清楚 CPU Cache Miss 对性能的影响是十分巨大的,尤其是我们启用了 SIMD 优化之后,程序的瓶颈就从 CPU Bound 变成了 Memory Bound。同时我们也应该清楚,随便程序的不断优化,程序的性能瓶颈会不断转移。

下面的代码展示了我们利用 Prefetch 优化 Cache Miss 的示例,我们需要知道,Prefetch 应该是最后一项优化 CPU Cache 的尝试手段,因为 Prefetch 的时机和距离比较难把握,需要充分测试。
#04
StarRocks 向量化工程的粗浅思考
—
其一,很多事物的底层原理是相似的:当我深入了解到 CPU 的微架构后,发现 CPU 的微架构和数据库的整体架构也很类似,比如 CPU 和 StarRocks 都分 Frontend 和 Backend, CPU 的 Frontend 负责指令的取码和编解码,Backend 负责指令的执行和数据的交互, StarRocks的 Frontend 负责 SQL 的 Parse 和 Plan, Backend 负责 SQL 的执行和存储的交互。当你了解的系统、架构越多,你的这种感受会越深刻。
其二,打造一个高性能的数据库,需要的不仅是优秀合理的架构,还需要极致优秀的工程细节。这一点看似十分显然,其实并不是,如果你认可这一点,当你想打造一个极致性能的数据库时,你就不会像 ClickHouse 一样 Bottom-Up 地从细节和算法层面出发去设计整个系统,也不会选择 Java 或者 Go 等语言去实现查询执行层和存储层。

其三,向量化和查询编译的融合。我们知道,向量化和查询编译是查询执行的两大类方式,是正交的,并不冲突,只是目前业界大多数开源的数据库选择了向量化的做法,其实我们完全可以通过查询编译的方式,结合上下文信息,生成更强大的向量化代码。而且,近几年查询编译的本身诸多缺点业界也一直在改进。
其四,尝试 GPU、FPGA 等新硬件。我们知道,假如一件事情,做到 80 分,需要一个月的时间,那么从 80 分做到 90 分,可能就需要 1 年的时间,从 90 分做到 99 分,可能就需要 2 年的时间。虽然目前基于 CPU 架构下的性能还没到极限,但是取得大的突破可能需要比较大的精力,我们或许可以考虑在新的硬件开辟新的赛道和战场。
其五,挑战不可能。创业两年来,我们团队从零实现了向量化引擎、CBO 优化器、Pipeline 并行引擎……看着一个又一个突破和成绩,我最大的一个感受就是我们应该永远坚信自己,挑战不可能。最后我向大家推荐一本书 《像火箭科学家一样思考:将不可能变为可能》,这本书比较完美地诠释了 StarRocks 团队的价值观:在 Think Big、敢想敢干的同时,如何攻坚克难、快速迭代,将一个又一个宏大的想法落地。
本期 StarRocks 技术内幕到这就结束了,好学的你肯定学会了一些新东西,或者又产生了一些新困惑,不妨扫描下方用户群二维码加入 StarRocks 社区一起交流!
关于 StarRocks
StarRocks 创立两年多来,一直专注打造世界顶级的新一代极速全场景 MPP 数据库,帮助企业建立“极速统一”的数据分析新范式,助力企业全面数字化经营。
当前已经帮助腾讯、携程、顺丰、Airbnb 、滴滴、京东、众安保险等超过 110 家大型用户构建了全新的数据分析能力,生产环境中稳定运行的 StarRocks 服务器数目达数千台。
2021 年 9 月,StarRocks 源代码开放,在 GitHub 上的星数已超过 3100 个。StarRocks 的全球社区飞速成长,至今已有超百位贡献者,社群用户突破 5000 人,吸引几十家国内外行业头部企业参与共建。

|








- 上一条: 业务数据迁移上云的一些技术思考 2022-08-22
- 下一条: 【云原生】如何快速部署Kubernetes 2022-08-22
- StarRocks2.0发布,新一年,新启航,新极速! 2022-01-05
- StarRocks 技术内幕:查询原理浅析 2022-04-26
- 行如蜗牛,决定入海 | 访 StarRocks 社区大使流木 2022-07-12
- Learning by contributing!访 StarRocks Committer 周康、冯浩桉 2022-04-02
- StarRocks 社区架构出炉,等你通关升级! 2022-07-15


