Prometheus on CeresDB 演进之路

文|刘家财(花名:尘香 )
蚂蚁集团高级开发工程师 专注时序存储领域
校对|冯家纯
本文 7035 字 阅读 10 分钟
CeresDB 在早期设计时的目标之一就是对接开源协议,目前系统已经支持 OpenTSDB 与 Prometheus 两种协议。Prometheus 协议相比 OpenTSDB 来说,非常灵活性,类似于时序领域的 SQL。
随着内部使用场景的增加,查询性能、服务稳定性逐渐暴露出一些问题,这篇文章就来回顾一下 CeresDB 在改善 PromQL 查询引擎方面做的一些工作,希望能起到抛砖引玉的作用,不足之处请指出。
PART. 1 内存控制
对于一个查询引擎来说,大部分情况下性能的瓶颈在 IO 上。为了解决 IO 问题,一般会把数据缓存在内存中,对于 CeresDB 来说,主要包括以下几部分:
-
MTSDB:按数据时间维度缓存数据,相应的也是按时间范围进行淘汰
-
Column Cache:按时间线维度缓存数据,当内存使用达到指定阈值时,按时间线访问的 LRU 进行淘汰
-
Index Cache:按照访问频率做 LRU 淘汰

上面这几个部分,内存使用相对来说比较固定,影响内存波动最大的是查询的中间结果。如果控制不好,服务很容易触发 OOM 。
中间结果的大小可以用两个维度来衡量:横向的时间线和纵向的时间线。

控制中间结果最简单的方式是限制这两个维度的大小,在构建查询计划时直接拒绝掉,但会影响用户体验。比如在 SLO 场景中,会对指标求月的统计数据,对应的 PromQL 一般类似 sum_over_time(success_reqs[30d]) ,如果不能支持月范围查询,就需要业务层去适配。
要解决这个问题需要先了解 CeresDB 中数据组织与查询方式,对于一条时间线中的数据,按照三十分钟一个压缩块存放。查询引擎采用了向量化的火山模型,在不同任务间 next 调用时,数据按三十分钟一个批次进行传递。
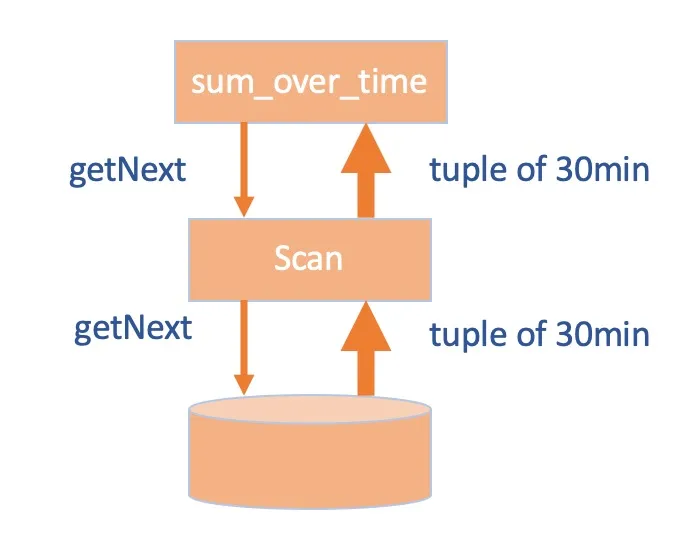
在进行上述的 sum_over_time 函数执行时,会先把三十天的数据依次查出来,之后进行解压,再做一个求和操作,这种方式会导致内存使用量随查询区间线性增长。如果能去掉这个线性关系,那么查询数量即使翻倍,内存使用也不会受到太大影响。
为了达到这个目的,可以针对具备累加性的函数操作,比如 sum/max/min/count 等函数实现流式计算,即每一个压缩块解压后,立即进行函数求值,中间结果用一个临时变量保存起来,在所有数据块计算完成后返回结果。采用这种方式后,之前 GB 级别的中间结果,最终可能只有几 KB。
PART. 2 函数下推
不同于单机版本的 Prometheus ,CeresDB 是采用 share-nothing 的分布式架构,集群中有主要有三个角色:
-
datanode:存储具体 metric 数据,一般会被分配若干分片(sharding),有状态
-
proxy:写入/查询路由,无状态
-
meta:存储分片、租户等信息,有状态。
一个 PromQL 查询的大概执行流程:
1.proxy 首先把一个 PromQL 查询语句解析成语法树,同时根据 meta 中的分片信息查出涉及到的 datanode
2.通过 RPC 把语法树中可以下推执行的节点发送给 datanode
3.proxy 接受所有 datanode 的返回值,执行语法树中不可下推的计算节点,最终结果返回给客户端
sum(rate(write_duration_sum[5m])) / sum(rate(write_duration_count[5m])) 的执行示意图如下:

为了尽可能减少 proxy 与 datanode 之间的 IO 传输,CeresDB 会尽量把语法树中的节点推到 datanode 层中,比如对于查询 sum(rate(http_requests[3m])) ,理想的效果是把 sum、rate 这两个函数都推到 datanode 中执行,这样返回给 proxy 的数据会极大减少,这与传统关系型数据库中的“下推选择”思路是一致的,即减少运算涉及的数据量。
按照 PromQL 中涉及到的分片数,可以将下推优化分为两类:单分片下推与多分片下推。
单分片下推
对于单分片来说,数据存在于一台机器中,所以只需把 Prometheus 中的函数在 datanode 层实现后,即可进行下推。这里重点介绍一下 subquery【1】 的下推支持,因为它的下推有别于一般函数,其他不了解其用法的读者可以参考 Subquery Support【2】。
subquery 和 query_range【3】 接口(也称为区间查询)类似,主要有 start/end/step 三个参数,表示查询的区间以及数据的步长。对于 instant 查询来说,其 time 参数就是 subquery 中的 end ,没有什么争议,但是对于区间查询来说,它本身也有 start/end/step 这三个参数,怎么和 subquery 中的参数对应呢?
假设有一个步长为 10s 、查询区间为 1h 的区间查询,查询语句是 avg_over_time((a_gauge == bool 2)[1h:10s]) ,那么对于每一步,都需要计算 3600/10=360 个数据点,按照一个小时的区间来算,总共会涉及到 360*360=129600 的点,但是由于 subquery 和区间查询的步长一致,所以有一部分点是可以复用的,真正涉及到的点仅为 720 个,即 2h 对应 subquery 的数据量。
可以看到,对于步长不一致的情况,涉及到的数据会非常大,Prometheus 在 2.3.0 版本后做了个改进,当 subquery 的步长不能整除区间查询的步长时,忽略区间查询的步长,直接复用 subquery 的结果。这里举例分析一下:
假设区间查询 start 为 t=100,step 为 3s,subquery 的区间是 20s,步长是 5s,对于区间查询,正常来说:
1.第一步
需要 t=80, 85, 90, 95, 100 这五个时刻的点
2.第二步
需要 t=83, 88, 83, 98, 103 这五个时刻的点
可以看到每一步都需要错开的点,但是如果忽略区间查询的步长,先计算 subquery ,之后再把 subquery 的结果作为 range vector 传给上一层,区间查询的每一步看到的点都是 t=80, 85, 90, 95, 100, 105…,这样就又和步长一致的逻辑相同了。此外,这么处理后,subquery 和其他的返回 range vector 的函数没有什么区别,在下推时,只需要把它封装为一个 call (即函数)节点来处理,只不过这个 call 节点没有具体的计算,只是重新根据步长来组织数据而已。
call: avg_over_time step:3
└─ call: subquery step:5
└─ binary: ==
├─ selector: a_gauge
└─ literal: 2
在上线该优化前,带有 subquery 的查询无法下推,这样不仅耗时长,而且还会生产大量中间结果,内存波动较大;上线该功能后,不仅有利于内存控制,查询耗时基本也都提高了 2-5 倍。
多分片下推
对于一个分布式系统来说,真正的挑战在于如何解决涉及多个分片的查询性能。在 CeresDB 中,基本的分片方式是按照 metric 名称,对于那些量大的指标,采用 metric + tags 的方式来做路由,其中的 tags 由用户指定。
因此对于 CeresDB 来说,多分片查询可以分为两类情况:
1.涉及一个 metric,但是该 metric 具备多个分片
2.涉及多个 metric,且所属分片不同
单 metric 多分片
对于单 metric 多分片的查询,如果查询的过滤条件中携带了分片 tags,那么自然就可以对应到一个分片上,比如(cluster 为分片 tags):
up{cluster="em14"}
这里还有一类特殊的情况,即
sum by (cluster) (up)
该查询中,过滤条件中虽然没有分片 tags,但是聚合条件的 by 中有。这样查询虽然会涉及到多个分片,但是每个分片上的数据没有交叉计算,所以也是可以下推的。
这里可以更进一步,对于具备累加性质的聚合算子,即使过滤条件与 by 语句中都没有分片 tags 时,也可以通过插入一节点进行下推计算,比如,下面两个查询是等价的:
sum (up)
# 等价于
sum ( sum by (cluster) (up) )
内层的 sum 由于包括分片 tags ,所以是可以下推的,而这一步就会极大减少数据量的传输,即便外面 sum 不下推问题也不大。通过这种优化方式,之前耗时 22s 的聚合查询可以降到 2s。
此外,对于一些二元操作符来说,可能只涉及一个 metric ,比如:
time() - kube_pod_created > 600
这里面的 time() 600 都可以作为常量,和 kube_pod_created 一起下推到 datanode 中去计算。
多 metric 多分片
对于多 metric 的场景,由于数据分布没有什么关联,所以不用去考虑如何在分片规则上做优化,一种直接的优化方式并发查询多个 metric,另一方面可以借鉴 SQL rewrite 的思路,根据查询的结构做适当调整来达到下推效果。比如:
sum (http_errors + grpc_errors)
# 等价于
sum (http_errors) + sum (grpc_errors)
对于一些聚合函数与二元操作符组合的情况,可以通过语法树重写来将聚合函数移动到最内层,来达到下推的目的。需要注意的是,并不是所有二元操作符都支持这样改写,比如下面的改写就不是等价的。
sum (http_errors or grpc_errors)
# 不等价
sum (http_errors) or sum (grpc_errors)
此外,公共表达式消除技巧也可以用在这里,比如 (total-success)/total 中的 total 只需要查询一次,之后复用这个结果即可。
PART. 3 索引匹配优化
对于时序数据的搜索来说,主要依赖 tagk->tagv->postings 这样的索引来加速,如下图所示:
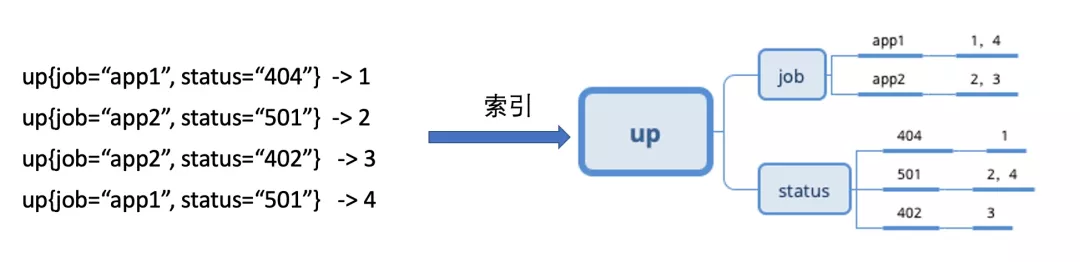
对于 up{job="app1"} ,可以直接找到对应的 postings (即时间线 ID 列表),但是对于 up{status!="501"} 这样的否定匹配,就无法直接找到对应的 postings,常规的做法是把所有的两次遍历做个并集,包括第一次遍历找出所有符合条件的 tagv ,以及第二次遍历找出所有的 postings 。
但这里可以利用集合的运算性质【4】,把否定的匹配转为正向的匹配。例如,如果查询条件是 up{job="app1",status!="501"} ,在做合并时,先查完 job 对应的 postings 后,直接查 status=501 对应的 postings ,然后用 job 对应的 postings 减去 cluster 对应的即可,这样就不需要再去遍历 status 的 tagv 了。
# 常规计算方式
{1, 4} ∩ {1, 3} = {1}
# 取反,再相减的方式
{1, 4} - {2, 4} = {1}
与上面的思路类似,对于 up{job=~"app1|app2"} 这样的正则匹配,可以拆分成两个 job 的精确匹配,这样也能省去 tagv 的遍历。
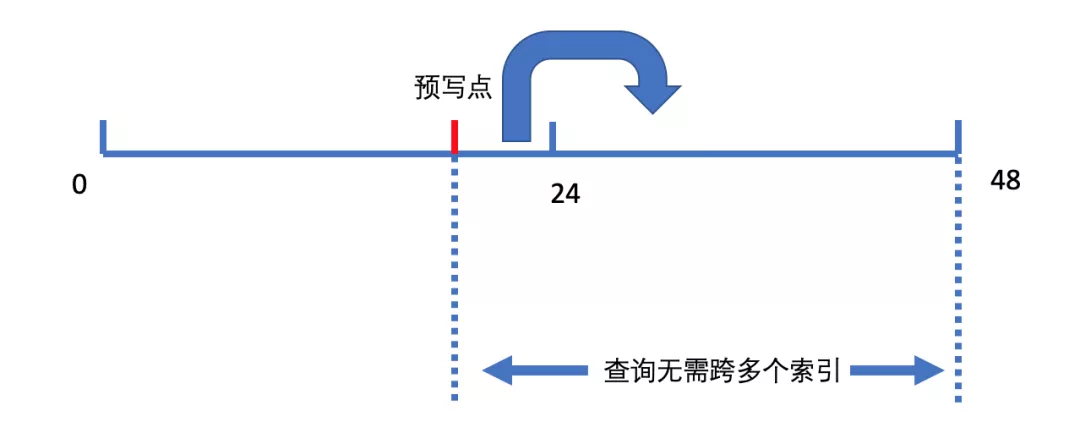
此外,针对云原生监控的场景,时间线变更是频繁发生的事情,pod 的一次销毁、创建,就会产生大量的新时间线,因此有必要对索引进行拆分。常见的思路是按时间来划分,比如每两天新生成一份索引,查询时根据时间范围,做多份索引的合并。为了避免因切换索引带来的写入/查询抖动,实现时增加了预写的逻辑,思路大致如下:
写入时,索引切换并不是严格按照时间窗口,而是提前指定一个预写点,该预写点后的索引会进行双写,即写入当前索引与下一个索引中。这样做的依据是时间局部性,这些时间线很有可能在下一个窗口依然有效,通过提前的预写,一方面可以预热下一个索引,另一方面可以减缓查询扩分片查询的压力,因为下一分片已经包含上一分片自预写点后的数据,这对于跨过整点的查询尤为重要。
PART. 4 全链路 trace
在实施性能优化的过程中,除了参考一些 metric 信息,很重要的一点是对整个查询链路做 trace 跟踪,从 proxy 接受到请求开始,到 proxy 返回结果终止,此外还可以与客户端传入的 trace ID 做关联,用于排查用户的查询问题。
说来有趣的是,trace 跟踪性能提升最高的一次优化是删掉了一行代码。由于原生 Prometheus 可能会对接多个 remote 端,因此会对 remote 端的结果按时间线做一次排序,之后合并时就可以用归并的思路,以 O(n*m) 的复杂度合并来自 n 个 remote 端的数据(每个 remote 端假设有 m 条时间线)。但对于 CeresDB 来说,只有一个 remote 端,因此这个排序是不需要的,去掉这个排序后,那些不能下推的查询基本提高了 2-5 倍。
PART. 5 持续集成
尽管基于关系代数和 SQL rewrite rule 等有一套成熟的优化规则,但还是需要用集成测试来保证每次开发迭代的正确性。CeresDB 目前通过 linke 的 ACI 做持续集成,测试用例包括两部分:
-
Prometheus 自身的 PromQL 测试集【5】
-
CeresDB 针对上述优化编写的测试用例
在每次提交 MR 时,都会运行这两部分测试,通过后才允许合入主干分支。
PART. 6 PromQL Prettier
在对接 Sigma 云原生监控的过程中,发现 SRE 会写一些特别复杂的 PromQL,肉眼比较难分清层次,因此基于开源 PromQL parser 做了一个格式化工具,效果如下:
Original:
topk(5, (sum without(env) (instance_cpu_time_ns{app="lion", proc="web", rev="34d0f99", env="prod", job="cluster-manager"})))
Pretty print:
topk (
5,
sum without (env) (
instance_cpu_time_ns{app="lion", proc="web", rev="34d0f99", env="prod", job="cluster-manager"}
)
)
下载、使用方式见该项目 README【6】。
「总 结」
本文介绍了随着使用场景的增加 Prometheus on CeresDB 做的一些改进工作,目前 CeresDB 的查询性能,相比 Thanos + Prometheus 的架构,在大部分场景中有了 2-5 倍提升,对于命中多个优化条件的查询,可以提升 10+ 倍。CeresDB 已经覆盖 AntMonitor (蚂蚁的内部监控系统)上的大部分监控场景,像 SLO、基础设施、自定义、Sigma 云原生等。
本文罗列的优化点说起来不算难,但难在如何把这些细节都做对做好。在具体开发中曾遇到一个比较严重的问题,由于执行器在流水线的不同 next 阶段返回的时间线可能不一致,加上 Prometheus 特有的回溯逻辑(默认 5 分钟),导致在一些场景下会丢数据,排查这个问题就花了一周的时间。
记得之前在看 Why ClickHouse Is So Fast?【7】 时,十分赞同里面的观点,这里作为本文的结束语分享给大家:
“ What really makes ClickHouse stand out is attention to low-level details.”
招 聘
我们是蚂蚁智能监控技术中台的时序存储团队,我们正在使用 Rust 构建高性能、低成本并具备实时分析能力的新一代时序数据库。
蚂蚁监控风险智能团队持续招聘中,团队主要负责蚂蚁集团技术风险领域的智能化能力及平台建设,为技术风险几大战场(应急,容量,变更,性能等)的各种智能化场景提供算法支持,包含时序数据异常检测,因果关系推理和根因定位,图学习和事件关联分析,日志分析和挖掘等领域,目标打造世界领先的 AIOps 智能化能力。
欢迎投递咨询 :jiachun.fjc@antgroup.com
「参 考」
· PromQL Subqueries and Alignment
【1】subquery:
https://prometheus.io/docs/prometheus/latest/querying/examples/#subquery
【2】Subquery Support:
https://prometheus.io/blog/2019/01/28/subquery-support/
【3】query_range https://prometheus.io/docs/prometheus/latest/querying/api/#range-queries
【4】运算性质
https://zh.wikipedia.org/wiki/%E8%A1%A5%E9%9B%86
【5】PromQL 测试集
https://github.com/prometheus/prometheus/tree/main/promql/testdata
【6】README
https://github.com/jiacai2050/promql-prettier
【7】Why ClickHouse Is So Fast? https://clickhouse.com/docs/en/faq/general/why-clickhouse-is-so-fast/
本周推荐阅读

|








- 上一条: AGPL“失效” 2021-11-16
- 下一条: 华为推送新利器,完美契合用户体验 2021-11-17
- 2021 大促 AntMonitor 总结 - 云原生 Prometheus 监控实践 2022-01-26
- Prometheus源码 - memSeries 2021-08-30
- GoFrame 框架:添加 Prometheus 监控中间件 2021-12-30
- gorilla/mux 框架(rk-boot):添加 Prometheus 监控中间件 2022-02-09
- 百度可观测系列 | 采集亿级别指标,Prometheus 集群方案这样设计 2022-02-23


