2021 大促 AntMonitor 总结 - 云原生 Prometheus 监控实践

文|陈岸琦(花名:敖清 )
蚂蚁集团高级开发工程师
负责蚂蚁 Prometheus 监控原生功能,在蚂蚁集团的落地与产品化建设。
本文 6566 字 阅读 15 分钟
前 言
日志和指标是监控不可或缺的两种数据源,为应用系统提供完整的可观测性。
AntMonitor 作为蚂蚁的统一监控平台,是一款主要以日志方式采集监控数据的监控产品。在社区,开源的云原生监控,主要以 Metrics (指标)的方式实现监控,其中以 Prometheus 为代表。
并且 Prometheus 监控因其强大的用户功能、结合 PromQL 的数据后分析能力,在业界有广泛的用户群体。实际上已成为开源标准,广泛用于开源 Kubernetes 的集群监控。
Prometheus 本身是一款单机监控产品,在蚂蚁庞大的高可用集群场景落地,具有一定的局限性和困难,包括但不限于:
-
Prometheus 没有提供稳定的、长期的数据存储功能,无法满足蚂蚁场景下对历史数据的查询;
-
Prometheus 是有损监控,不保证数据的完整性,无法满足蚂蚁场景下对交易笔数等数据的精确性要求;
-
Prometheus 不支持日志监控。
但是为了满足用户对 Metrics 监控的需求,经过近两年的努力,我们成功地将 Prometheus 的主要功能融合进了 AntMonitor 的现有架构,提供了一套具有蚂蚁场景特色的集群化解决方案。
今年大促,我们成功地将 Sigma 集群监控(蚂蚁原生的集群管理和资源调度平台)完整迁移至 AntMonitor。配合告警和大盘,实现了 Sigma 监控的覆盖。AntMonitor 凭借 Sigma 监控的迁移,成功孵化了完善的的云原生 Prometheus 监控能力。
本文简要介绍了AntMonitor 对 Prometheus 监控功能的支持,以及 Sigma 监控的落地实践。
PART. 1 海量数据下的采集架构
以下是一段 Prometheus metrics 数据的样例:
$ curl localhost:8080/metrics #HELP go_gc_duration_seconds A summary of the pause duration of garbage collection cycles. #TYPE go_gc_duration_seconds summary go_gc_duration_seconds{quantile="0"} 7.2124e-05 go_gc_duration_seconds{quantile="0.25"} 0.000105153 go_gc_duration_seconds{quantile="0.5"} 0.000129333 go_gc_duration_seconds{quantile="0.75"} 0.000159649 go_gc_duration_seconds{quantile="1"} 0.070438398 go_gc_duration_seconds_sum 11.413964775 go_gc_duration_seconds_count 20020 #HELP go_goroutines Number of goroutines that currently exist. #TYPE go_goroutines gauge go_goroutines 47 #HELP go_info Information about the Go environment. #TYPE go_info gauge go_info{version="go1.15.2"} 1 #HELP go_memstats_alloc_bytes Number of bytes allocated and still in use. #TYPE go_memstats_alloc_bytes gauge go_memstats_alloc_bytes 5.955488e+06
Metrics(指标)数据和日志数据拥有较大差别,包括但不限于:
第一、日志数据写在磁盘上,每条日志都有标准时间戳,而 Prometheus metrics 是存在内存里,采集时间以拉取的时间为准,因此数据的准确性对调度的准确性有较高要求。
第二、日志的每次采集均采集增量即可,每次采集的数据量有限,但是 Metrics 数据每次采集均要采集全量,数据的文本大小动辄上百 MB,因此 Metrics 数据量巨大,很容易超限。
第三、日志数据均需要按照某些固定 schema(数据表结构)作切分清洗、计算聚合,但是原生 Metrics 通常存储单机原始数据。
AntMonitor 现有的数据链路大致为由 agent 采集日志数据缓存于内存,由 Spark 计算集群从 agent 内存中拉取数据,进行聚合,存储于 CeresDB。
然而 Metrics 数据不同于日志数据,单机明细数据通常具备可观测性,具备完整的信息。因此通常 Metrics 数据,可以跳过计算步骤,直接进行存储。因此,Metrics 数据在保留单机明细数据的情况下,由 agent 内存和 Spark 拉取的方式已经不合时宜,不仅浪费了计算资源,agent 内存也无法支撑住庞大的 Metrics 数据量。
因此,我们根据用户的业务需求,提供了两条数据链路:
-
在需要保留单机明细数据的情况下,走基于网关的明细数据采集链路;
-
在需要数据聚合的情况下,走基于 Spark 的聚合数据采集。
1.1 基于网关的明细数据采集
为了使保留明细数据跳过计算集群直接存储,我们研发上线了一套专门服务 Metrics 数据的中心化采集 + push 存储的链路。
中心化采集相对于传统的 agent 采集,不再需要依赖于部署在每台物理机,而是只通过 HTTP 请求的方式采集 Metrics 数据。中心化采集对 Metrics 的采集配置进行结构化的下发和调度,以此满足了 Metrics 采集对时间戳调度精确性的要求。并且,中心采集对采集到的数据不存内存,而是直接以 push 的方式推送给 PushGateway,由 gateway 直接存储至底层 CeresDB。
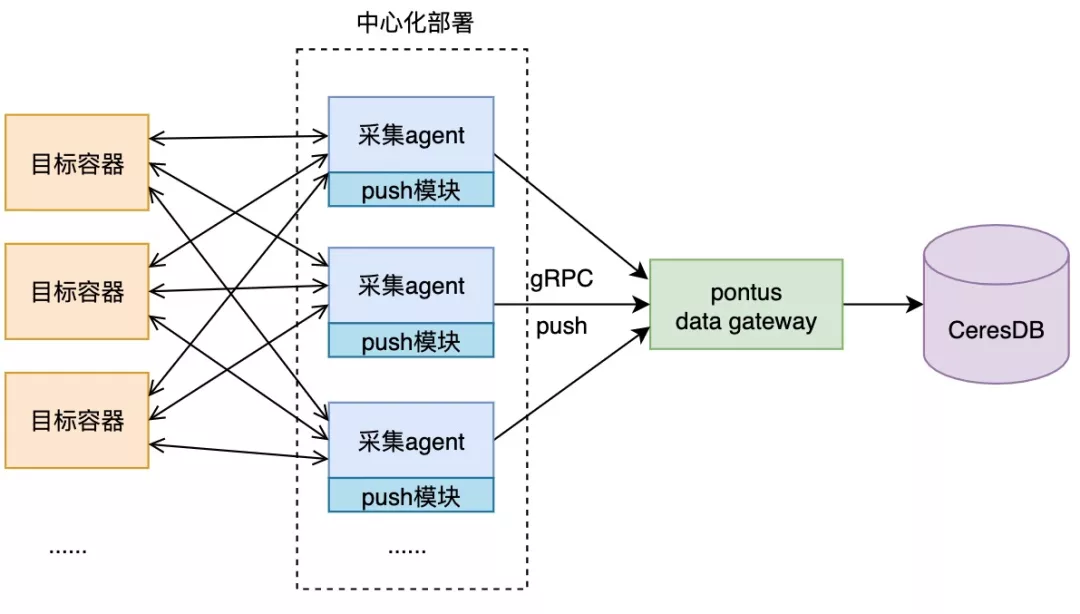
这套采集方案,满足了 Metrics 对时间精度和存储单机数据的要求。并且将 Metrics 数据采集与现有的日志采集接耦,使二者互不干扰,解放了对 agent 内存和计算资源的高消耗。
该套方案已经成功用于蚂蚁 Sigma 等多个技术栈和基础设施的 Prometheus 采集,目前每分钟处理上亿条指标数据。
1.2 基于 Spark 的聚合数据采集
以 Sigma 为代表的基础设施监控,对单机明细数据有较大需求。但是保留明细数据也有较大的缺点,例如:数据量庞大,对存储消耗较高;数据查询时,耗时和数据读取量巨大。
但是对于一些业务应用用户,对单机明细数据并不关注,只关注于一些维度的聚合数据。例如,以机房维度、集群维度等。因此在这种场景下,存储明细数据,会造成较大的存储浪费,并且在数据查询时,会带来很差的用户体验。因此在这种场景下,我们保留了目前 AntMonitor 传统的日志链路,对采集的 Metrics 单机明细数据进行了聚合进行存储。在业务不关注单机明细数据的场景下,这条链路拥有明显的好处,节省了存储空间,提升了用户查询的速度。

但是不同于日志监控的数据聚合,必须由用户配置聚合规则,由于 Metrics 数据本身就包含 schema 信息,我们通过自动化的配置项,自动对 Gauge、Counter、Histogram 等 metric type 自动为用户生成了聚合配置,免去了用户手动配置聚合的繁琐:

下图总结对比了数据聚合与不聚合的区别和优劣:

PART. 2 维表体系下的元数据统一
原生 Prometheus 提供多种服务发现机制,如 K8s 服务发现通过 apiserver 可以自动获取发现采集的 targets。但是,AntMonitor 作为一个蚂蚁统一监控系统,显然是不能通过 apiserver 自动发现监控目标。
AntMonitor 在日志监控的现有基础上,建设有一套较为完善的元数据维表体系,包含了 SOFA、Spanner、OB 等多个蚂蚁技术栈元数据。元数据告诉我们去哪里采集监控数据,对应原生的服务发现机制。为了拉齐原生功能,我们对部分维表进行了必要改造,此处我们以 Sigma 监控的落地实践为例,简要介绍下我们的元数据同步流程。
2.1 Sigma 元数据同步
AntMonitor 进行 Sigma 监控的前提是要获取元数据,元数据告诉我们去哪里采集监控数据。
为此,我们设计了基于 RMC(蚂蚁的统一元数据平台) 的 “全量同步+增量同步” 元数据同步方案。前者保证元数据齐全可靠,后者基于 AntQ 实现,保证了元数据的实时性。
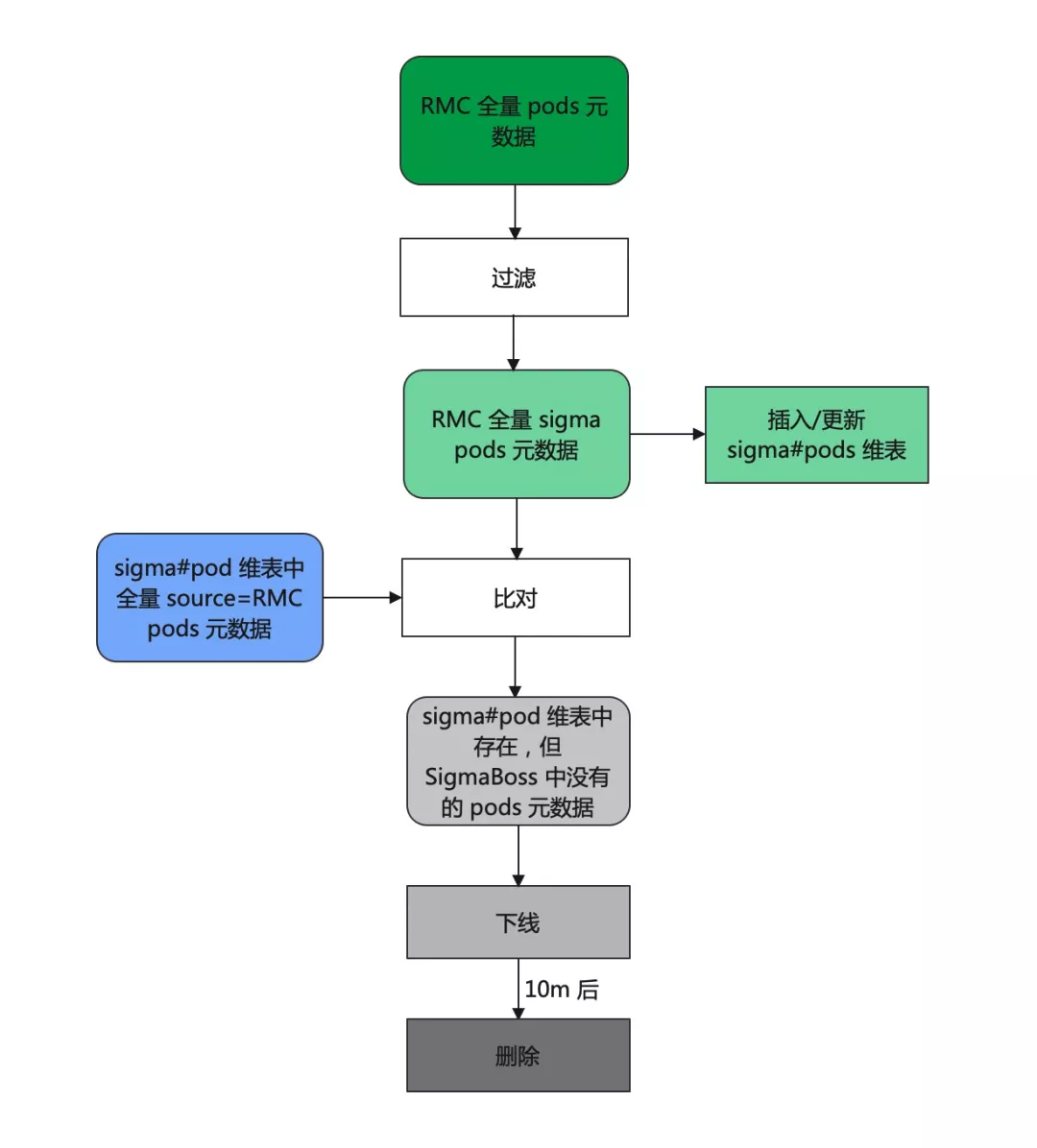
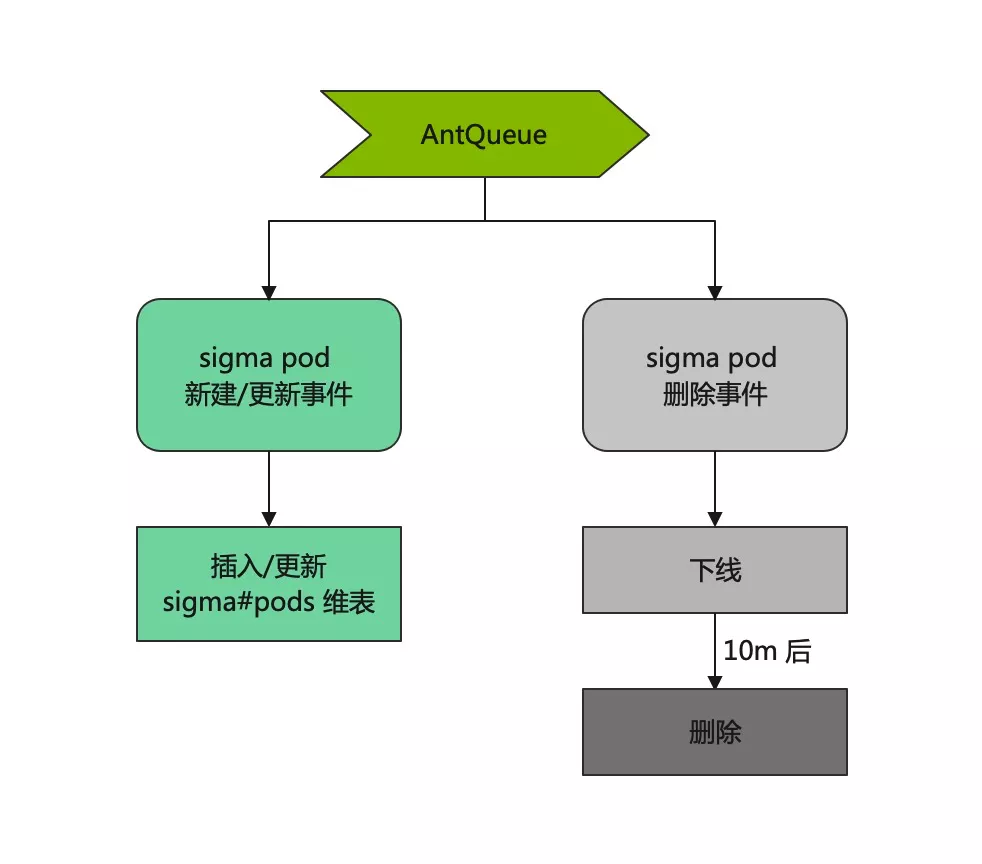
从图中可以看到,为了对齐原生的 staleness 功能,Sigma pod 元数据统一添加了下线 (offline) 这个中间状态。
原生 Prometheus 通过 relabeling 功能实现采集目标过滤等,还可以通过 metric relabeling 对拉取到的数据进行编辑。Sigma 元数据同步还记录了一些必要的 Sigma pod labels,并支持在采集配置时,通过这些 label 设置黑白名单;支持附加 label,实现了类 Prometheus relabling 及 metric relabeling 的功能。迎合云原生监控配置体验。
PART. 3 分布式架构下的存储集群
我们以 Sigma 业务为例,因为 Sigma 的 Metrics 数据需要存储单机明细数据,并且很多主要组件均是 15s 级,因此数据写入量巨大,目前数据量写入量每秒数百万数据点。因此导致数据查询时,经常超出限制,无法产出数据结果。因此 CeresDB 针对这种数据量巨大的情景,按 label 标签进行了分区。例如 Sigma 的 Metrics 数据,通常带有 cluster 集群标签,CeresDB 按 cluster 维度对 Sigma 数据进行了分区。在通过 PromQL 查询数据时,会将查询按 cluster 维度拆分下推至所在 data 节点进行执行,再由每个 data 节点产出的结果,在 proxy 节点产出最终查询结果,返回至用户。
不同于单机版本的 Prometheus ,CeresDB 是采用 share-nothing 的分布式架构,集群中有主要有三个角色:
-
datanode:存储具体 Metric 数据,一般会被分配若干分片(sharding),有状态
-
proxy:写入/查询路由,无状态
-
meta:存储分片、租户等信息,有状态。
一个 PromQL 查询的大概执行流程:
-
proxy 首先把一个 PromQL 查询语句解析成语法树,同时根据 meta 中的分片信息查出涉及到的 datanode
-
通过 RPC 把语法树中可以下推执行的节点发送给 datanode
-
proxy 接受所有 datanode 的返回值,执行语法树中不可下推的计算节点,最终结果返回给客户端
我们以这个 PromQL 查询为例,执行示意图如下:
java sum(rate(write_duration_sum[5m])) / sum(rate(write_duration_count[5m]))
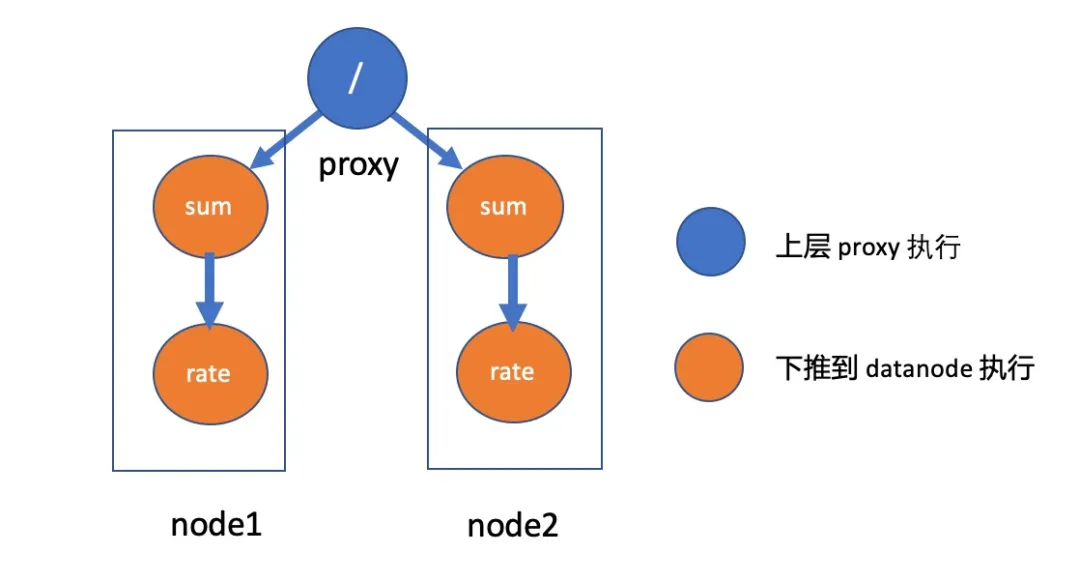
这样的分片算法,加上 CeresDB 做的其他计算优化,使得 Sigma 的查询数据效率有极大提升。现对于原生 prometheus + thanos 架构,大部分高耗时查询,效率提升了 2-5 倍。
PART. 4 Grafana Component
AntMonitor 的可视化主要为日志监控设计,而社区普遍使用 Grafana 来解决云原生监控的可视化问题。我们对比之后发现,AntMonitor 原有的可视化无法承载以 PromQL 为主的可视化能力。为此,我们需要寻找到既能嵌入原有架构,又能满足云原生可视化需求的方案。
Grafana 的前端代码主要由 AngularJS 1.x + React 写成,AngularJS 主要承担 bootstrap 的功能。并且,部分公共的 service 类也由 AngularJS 承担,React 主要承担渲染层以及新功能的编写。
早期接触过 SPA 应用的朋友应该知道,AngularJS 1.x 作为第一代全功能的前端框架,存在代码耦合严重,无法灵活嵌入其他框架的问题。我们通过魔改 AngularJS 的源码,使其具备重复 bootstrap 的能力,以方便嵌入其他框架来解决这个问题。并且,我们为 Grafana 编写了一套新的 React Component 库,方便与其他业务整合。目前,我们已经成功将此功能输出到多个场景使用。
在有了前端之后,我们便不需要整套的 Grafana 组件也不需要整套的 Grafana 后端 API,我们用 SOFABoot 实现了 Grafana 部分必要的 API 例如 dashboard、query、annotation,结合我们组件化的 component 提供给用户使用。
PART. 5 分布式架构下的 Rule 执行引擎
原生 Prometheus 提供了 Recording Rules (RR) 和 Alerting Rules (AR) 功能,将一些指标预计算并存储,方便日常查询。这是一个 Prometheus metrics 独有的功能,可以解决上文提到的实时查询耗时较长的问题。
基于此,我们定制开发了与 Antmonitor Prometheus 监控配套的 Rule 执行引擎,兼容了原生的 YAML 编辑、导入、下发 RR/AR 的操作体验,并通过 alertmanager 接入各类告警网关进行告警分发。这套 RR/AR Rule 执行引擎已经成功应用于 Sigma 监控、Antmonitor SLO 服务、系统监控等业务。
5.1 Antmonitor SLO 服务接入实践
Antmonitor SLO 服务需要计算服务各项指标不同时间段内的表现,如:一天、一周、一个月成功率和耗时等。这些可以作为 RR 交给我们的 Rule 执行引擎预计算并存储,供用户查询,同时还可以将 "SLO+阈值" 作为 AR 计算告警,并交给告警网关发送出去。
SLO 的 RR 具有一定规律,大部分是 sum_over_time() 形式。针对这一特点,Rule 执行引擎实现了基于滑动窗口的计算方式,并克服了由此因为滑动引发的各种计算误差问题,有效降低了下游计算压力。
5.2 可回放的 Recording Rules
Rule 执行引擎除了支持实时的 RR 计算外,还支持历史 RR 重计算,可以自动检测历史计算结果并重计算覆盖。主要应对以下场景:
1)异常数据修复:Rule 执行引擎在运行过程中,难免会因为各种原因(如:源数据异常、底层依赖服务 pontus、CeresDB 偶发故障等)导致 RR 计算异常,而出现异常数据。异常数据可能会造成哭笑不得的体验(成功率>100%)、错误传递(SLO 场景下,一个时间点的数据异常会通过 sum_over_time 函数持续传递下去)、持续误警等。由此可见,需要一种机制能快速恢复异常数据。
2)当一个新的 RR 集合接入 Rule 执行引擎,一般而言用户只能得到接入时刻开始的 RR 计算结果,用户需要等待一段时间才能得到一个趋势图,如果用户想看的趋势图时间跨度很大,这个等待的时间成本太高了。历史 RR 重计算可以很好的解决这一痛点,可以直接重计算接入时刻前任意区间的 RR 计算结果。
PART. 6 功能展望
今年我们成功地将 Sigma 监控在 AntMonitor 落地,建设了基础设施能力,积累了业务实践经验。明年我们将将工作重点转移到服务 C 端用户,为 C 端用户提供极致顺畅的监控体验。目前 C 端用户(业务用户)在 AntMonitor 的 Metrics 监控能力还较为零散,我们明年将致力于 Prometheus 能力的整合,提供顺畅的一站式体验。
【特别致谢】
特别致谢项目业务方,Sigma SRE 团队提出的宝贵建议和意见,和对开发过程中所遇到困难的包容和理解。
特别致谢项目元数据合作方 RMC 团队,对项目的友情支持。
也特别致谢每一位 AntMonitor 云原生监控项目组的每一位成员对本项目的鼎力相助。
【参考链接】
-【Prometheus 官方文档】
-【Prometheus on CeresDB 演进之路】
https://mp.weixin.qq.com/s/zrxDgBjutbdvROQRYa3zrQ
本周推荐阅读
深入 HTTP/3(一)|从 QUIC 链接的建立与关闭看协议的演进

|








- 上一条: 产品力?概念包装?急功近利?中美开源差距究竟在哪 2022-01-25
- 下一条: StratoVirt 的中断处理是如何实现的? 2022-01-26
- 百度可观测系列 | 基于 Prometheus 的大规模线上业务监控实践 2021-12-09
- 百度可观测系列 | 采集亿级别指标,Prometheus 集群方案这样设计 2022-02-23
- 618 大促来袭,浅谈如何做好大促备战 2022-06-09
- GoFrame 框架:添加 Prometheus 监控中间件 2021-12-30
- 小游戏如何应对大流量?Shopee Shake 的大促实践 2021-09-13


