浅谈百度阅读/文库NA端排版技术

导读:当前主流的排版引擎:Gecko、Blink、Trident、Webkit/Webcore等等,虽然能实现基本的图、文排版需求,但对于复杂的版面,特别是图书类文档的排版,无法实现或者实现起来非常困难,同时排版效果不够专业,为此百度文库/百度阅读开发了一套跨平台的排版引擎。本文期望通过排版引擎的相关技术介绍,向大家展示图书(内容)排版方面的一些实现技术、技巧。
全文3680字,预计阅读时间12分钟。
一、背景
百度文库是百度旗下的在线互动式文档分享平台,在这里,用户上传、分享自己的文档,搜索、阅读、下载其他用户的文档。
在2013年后,百度文库为了满足用户在手机端阅读文档、图书资源的需要,先后推出了百度阅读app、百度文库app,期望通过精致的、专业的排版、原生的端阅读体验,打造一款小而美的阅读类app,其核心是排版引擎的实现,本文希望通过百度阅读/文库排版引擎的相关技术,向大家介绍图书(内容)排版方面的一些实现技术。
二、技术选型
在设计排版引擎之初设定了以下几个目标:
-
Android、IOS两端采用同一套排版引擎排版,两端展示效果一致,提升开发效率;
-
采用图书印刷行业的排版标准,实现图书专业级排版;
-
支持个性化阅读体验、复杂排版效果的快速迭代;
-
原生的端阅读体验,排版引擎包尽可能小;
市场上主流的几个排版引擎:Gecko、Blink、Trident、Webkit/Webcore,它们虽然能实现基本的图、文排版需求,但对于复杂的版面,比如文本框竖排标题、绕排等效果,无法实现或者实现起来非常困难;同时排版效果不够专业,不能满足未来排版效果的快速迭代,因此百度阅读决定自己实现跨平台的排版引擎。
三、技术架构
3.1 整体架构
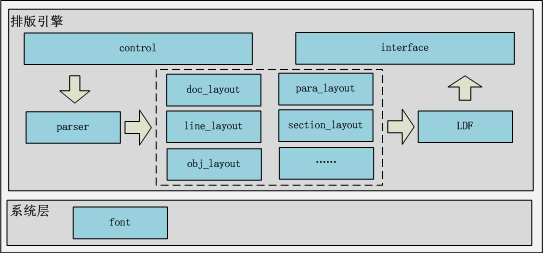
图1 百度阅读/文库排版引擎架构图
排版引擎主要由四部分构成,分别是:
Control/Interface模块:它接受外部传过来的内容,并调起、管理排版,同时排版完成后把排版结果以指令形式回传给显示层进行渲染;
Parser模块:用户阅读的内容格式是多种多样的,它可能是epub、txt、docx,也可能是各自业务线自定义的格式,针对各种格式通过parser模块统一映射到自定义的DOM树上,后续排版只需要针对这个DOM树进行处理即可,这样可提升开发效率,同时也方便未来快速扩展到更多的格式上去。
自定义的DOM树参考的是ooxml结构描述,并在此基础上进行了简化,改造,DOM树基本结构如下:
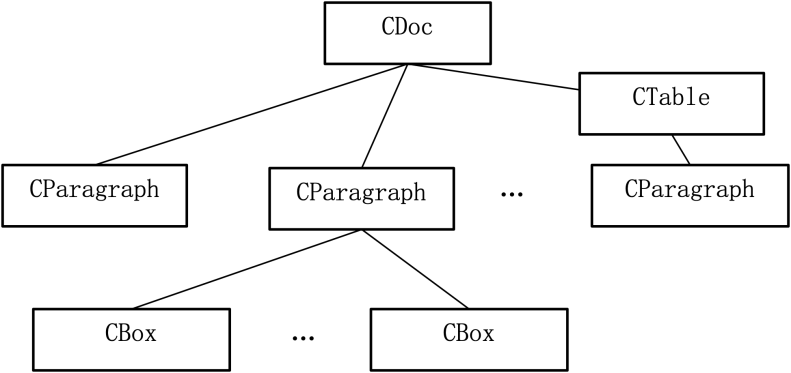
图2 抽象DOM树结构
这其中CBox节点是一个虚节点,它可能是一个字符,也可能是一个片断、一个对象,比如文本框、数学公式、拼音结构等等。它可以具有与CDoc节点相似的结构,支持无穷嵌套,从而实现对各种复杂结构的描述。
Layout模块:读取DOM树结构,遍历节点,结合版面大小,并运用各种排版规则,把文字、内容、对象布局到显示区域,结果输出成LDF。
这部分是整个排版引擎主要技术所在,后面会详细介绍。
LDF模块:排版结果描述结构。
排版引擎排完一页内容后,并没有调用绘制指令,直接绘制显示,而是输出成LDF数据,缓存在内存中管理。这么处理是出于两个方面的考虑:一是性能和内存考虑,用户在阅读当前页时,排版引擎会在后台把它前、后几页内容进行排版,缓存,在用户翻页时异步绘制;二是提供交互操作需要的数据基础,它在LDF上进行区域、数据计算,快速定位到指定的节点,提取相应的内容。
当然提前准备多少页排版结果,提前预绘多少页,可由各自业务依据自身需要和设备情况进行动态设置,以达到最优的阅读体验效果。
LDF数据结构更多的倾向于版面描述,其结构如下:
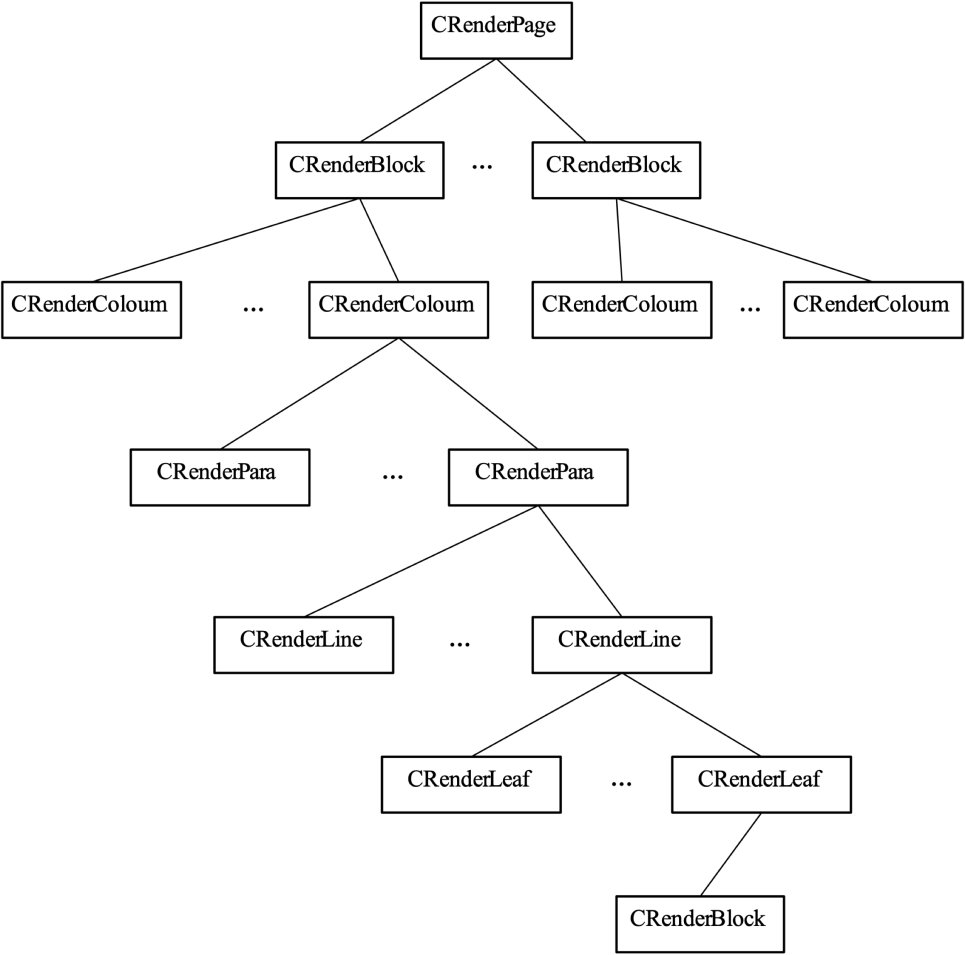
图3 LDF结构
LDF数据定义涵盖了版面的所有元素,包括页、块、分栏、段落、行、内容片断,通过嵌套实现各种复杂效果展示。
3.2 主要技术
排版过程涉及到很多技术细节和处理技巧,比如glyph处理、标点禁则、行拉压对齐处理、块排版等等,本文阐述几个主要的排版技术,其它技术、处理技巧可参考开源的排版引擎,它们在很多细节处理技术上是相通、相似的。
3.2.1 基本排版
排版过程可简单理解成把文档逻辑结构(DOM树)通过一些技术手段映射成版面结构(LDF),排版过程涉及到文档逻辑结构和版面结构,基本排版处理包括:
- 段落排版(para_layout):
段落排版处理段落属性,比如段前距、段后距、段首缩进、段落悬挂等等,并调用行排版。
- 行排版(line_layout):
内容最终在显示时,展现的是一行行内容,它是排版中常用的一个处理,其它排版引擎均提供了行排版的接口。
行排版处理行间距等属性,并调用片断排版,排版完成后依据段落对齐属性进行x方向的调整和y方向对齐调整。
- 片断排版(section_layout):
在某些效果下,一行内容是由多个小区域组成,比如文字两端绕排图片,文字阅读顺序设定为通栏从左到右,此时一行是由图片两边两个片断组成,在选中内容时光标走位是穿过图片选中两端文字。
片断排版计算当前片断可排区域、传递段落、内容属性,并调用对象排版。
- 对象排版(obj_layout):
对象排版是排版引擎的基本单元,它包括字符排版、结构排版,它依据对象的属性、类型进行特定的、分别的处理。
3.2.2 复用与抽象
(对象)内容的类型有很多种,从普通的中英文字符到数学公式、拼音结构、块结构等等,甚至对象嵌套对象,这就需要排版引擎对所有的对象进行抽象,通过递归调用、基础的排版处理复用,实现各类复杂效果的实现。
复杂对象,从结构上来看,它是由一段或多段内容组成,在这个意义上,它可以理解成CDoc节点,即它是一个子文档(而对于对象嵌套对象结构,可以理解成子文档嵌套子文档),通过数据结构抽象,从而实现的排版的复用。
一个对象的排版,即子文档在子区域内的排版,它同样经过基本的段落、行、片断、内容排版,并依据对象进行特定的位置修正(比如拼音排版,上下两个子盒子分别排版,y方向位置调整,x方向居中对齐),最终实现对象的排版。
3.2.3 相对排版
排版最终结果就是把字符、图元或图片定位到屏幕指定位置,即给内容赋予x/y坐标值,在处理纯文字内容的排版时,非常简单,排完一个字符,计算下一个字符的x坐标,依此类推,直到当前行排不下内容为止。
但对于复杂结构又该如何处理了?以数学公式
首先排第一个元素,此时排版引擎不用关注该元素入口的x/y坐标是多少,而是采用相对原点坐标(0,0)排版这个二次公式。
但这个二次公式又是由分子、分母组成,在排版分子、分母时,依旧采取相对排版原则,从(0,0)坐标原点开始排版,分别得到分子、分母排版结果,此时把分子和分母排版结果分别当作一个黑块,依据上下分式排版规则,调整分子、分母,使之中线对齐、上下位置合适。
调整完二次公式后,把它的排版结果当作一个黑块,参与到矩阵排版和位置调整中,此时二次公式内部内容相对位置不再变化。
相对位置排版,即每个子对象先不用关注入口位置坐标,而采用相对原点坐标进行排版,排版完成后依据对象特点、入口坐标信息,调用correct_xy,统一修正x/y坐标,一层层递归,最终实现复杂对象和整页的排版。
3.2.4 多方向排版
不同语言有着不同的排版方向,比如汉字是正向横排,古籍书是反向竖排,蒙文正向竖排,维文是反向横排,如何统一这些排版,从而支持所有语言排版?
先来看下反向模排,下图是模拟了正向横排和反向横排的效果图:

图4 正、反向横排效果图
从上图可以看出,反向横排其实就是正向横排相对于版心中轴线的镜像,理解了这一点,反向横排就变成了正向横排完后再做一次x坐标镜像处理,至于正向竖排、反向竖排也可以采用类似方式处理,甚至在排版层不处理,而在绘制时做坐标矩阵转换。当然各语言有各自的特点,细节可能需要微调下。
四、总结和展望

图5 效果展示
百度阅读/文库排版引擎未来发展的方向:
-
依据内容以及属性,精准的排出指定的效果,支持更多对象的排版,并不断完善排版标准和体验;
-
理解内容,理解设备,智能排版,提供更佳的阅读体验;
比如对于期刊类文档,摘要、关键词可采用不同的字体、字号,设置一定的段左、右距排版。
比如对于大屏显示和图文绕排内容,图片尽可能排到九宫位置,而对于小屏,动态调整图片尺寸,甚至取消图文绕排等等。
各排版引擎本质上区别不大,没有好坏之分,百度阅读/文库自研排版引擎更多的是出于自身业务需要,所用到的排版技术既有通用性,也有自己的特点,文章的目的是一起探索排版底层的技术,一起去挖掘排版技术的发展。
推荐阅读:
---------- END ----------
百度Geek说
百度官方技术公众号上线啦!
技术干货 · 行业资讯 · 线上沙龙 · 行业大会
招聘信息 · 内推信息 · 技术书籍 · 百度周边
欢迎各位同学关注
|








- 上一条: 密码学系列之:bcrypt加密算法详解 2021-09-16
- 下一条: 跨语言编程的探索 | 龙蜥技术 2021-09-16
- 百度文库新一代文档阅读器!核心技术点全解析! 2021-12-07
- 跨平台技术实战!百度文库跨平台技术快速落地全过程 2022-01-11
- 百度CTO王海峰:AI大生产平台再升级 助力中国科技自立自强 2021-12-30
- 百度直播iOS SDK平台化输出改造 2022-07-01
- 深入理解百度在离线混部技术 2021-12-30


