深入理解百度在离线混部技术
【百度云原生导读】服务器资源利用率较低,TCO(IT 基础设施的总拥有成本)逐年上涨,对于拥有大量机器资源的公司来说无疑是一个头疼的问题。混部技术就是在这种情况下应运而生,目前,混部技术在业界还属于比较小众的领域,只有一些资源量级较大的公司在研究、发展混部技术,以期获得收益。
对于百度而言,通过应用混部技术,主混部集群数十万台,提升CPU利用率到40+%,累计节约了数十亿人民币。目前百度容器引擎产品 CCE 已支持在离线混部,并完成了大规模业务落地,本文将带大家深入了解百度的在离线混部技术。
1. 什么是在离线混部
混部概念中将应用类型分为在线业务和离线业务两种。

在线和离线业务如何划分?在百度内部,我们认为在线业务特点包括但不限于:运行时间长,延时敏感,对稳定向要求较高,服务不稳定业务会立马感知并且带来损失,有明显的波峰波谷,白天高,深夜低,比如广告搜索业务;而离线业务的特点包括但不限于非延时敏感,可重试,运行时间一般较短在几十分钟左右,内部一般为大数据计算,机器学习等服务。
在线业务以搜索为例,白天用户工作学习时查询量会非常大,但是当大部分用户夜间休息时,查询量相对白天就会变得非常小,此时我们就可以引入离线业务。离线业务没有严格的时间要求,随时都能跑,用户关心的是任务能不能跑完,对于什么时候跑完并没有太大的需求,同时如果单机上资源有冲突,此时我们会压制离线业务,甚至会驱逐离线业务,这对用户是无感的,计算平台重新拉起任务,继续计算。
因此,在线型业务和离线业务具备资源互补的特点,从时间上和对资源的容忍度上可以完美的结合到一起。一方面,在线业务的优先级更高,单机和调度层面会优先保障在线的资源,可能会对离线进行压制和驱逐,另一方面,对于离线任务来说,压制和驱逐对用户是无感的,只需要保证任务顺利完成,有很高的容忍度。
简单来说,将在线业务和离线任务混合混部到相同物理资源上,通过资源隔离、调度等控制手段 , 充分使用资源,同时保证服务的稳定性,我们称这样的技术为“混部”。
2. 资源利用率为何不高?
纯在线业务集群的平均利用率普遍不高,百度应用混部技术之前,在线业务集群CPU利用率普遍在20%左右,造成这种现象主要由一下几种原因:
2.1 潮汐现象和冗余
在线业务在申请资源的时候,一般是按照最高峰值评估资源去申请资源,同时还会上调一些,这就导致了业务对资源预估不准,申请的资源远大于实际使用资源。甚至可能会部署多个副本作为灾备。
此时的低峰时利用率就会非常低,导致整体利用率不高。
2.2 在离线分池
一般来说机房规划的时候有一个非常大的特点,就是离线机房与在线机房分离做规划。举个例子,假如我们在宁夏做一个机房,这个时候肯定会考虑做一个离线机房,因为在线机房需要考虑网民请求地域分布的问题,要获得最好的访问优化体验以及访问速度,势必需要在一些访问热点上去做自己的在线机房规划,比如北京、上海、广州等。
而对于离线机房来说不用关心这些,它最在乎的是如何提升计算和储存的资源和基础设施的规模,所以在线业务和离线业务本身的资源需求和特点不一样,资源利用率非常不均衡。常态表现就是在线利用率低,离线利用率高,且常态资源不足。

针对以上场景,我们通过在离线混部技术将在离线资源统一资源池,把离线作业部署在在线资源池节点上,充分利用机器资源,达到了提升资源利用率的目的。
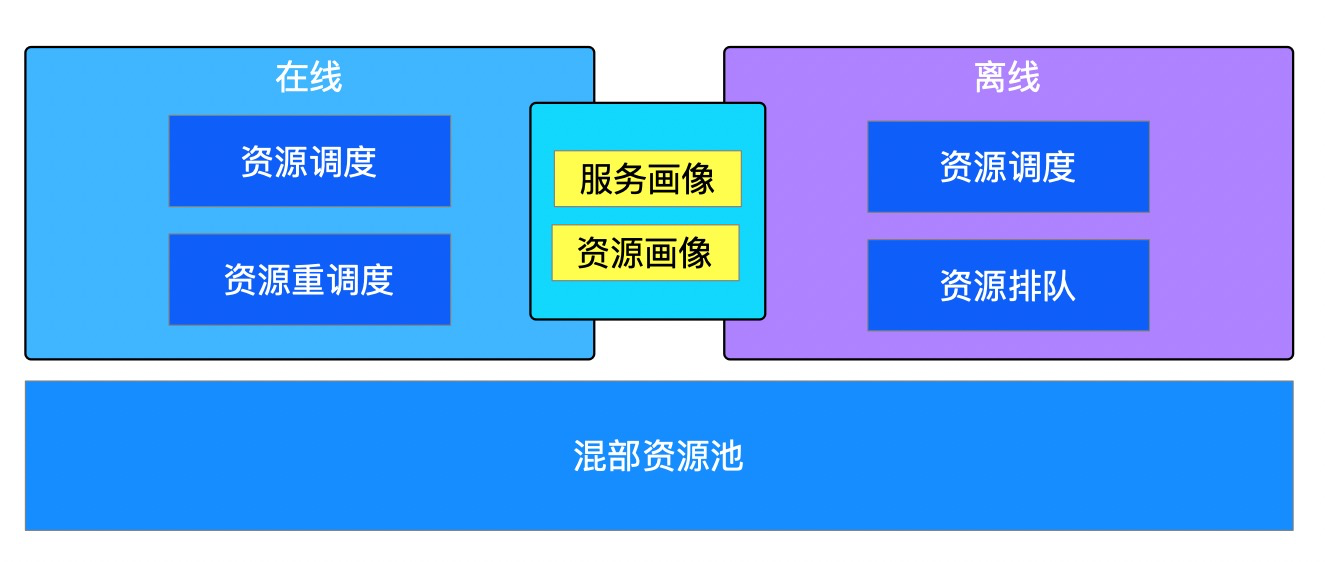
3.百度云原生混部详解
随着 Kubernetes(以下简称「K8s」) 生态的蓬勃发展,百度很多业务已经搭建并且运维了自己的诸多 K8s 集群,同时也遇到了一些问题,比如上面所说的资源利用率不高。我们根据内部积累混部经验对 K8s 进行在离线混部原生化改造,做到了零入侵K8s,可移植,可支持大规模集群。
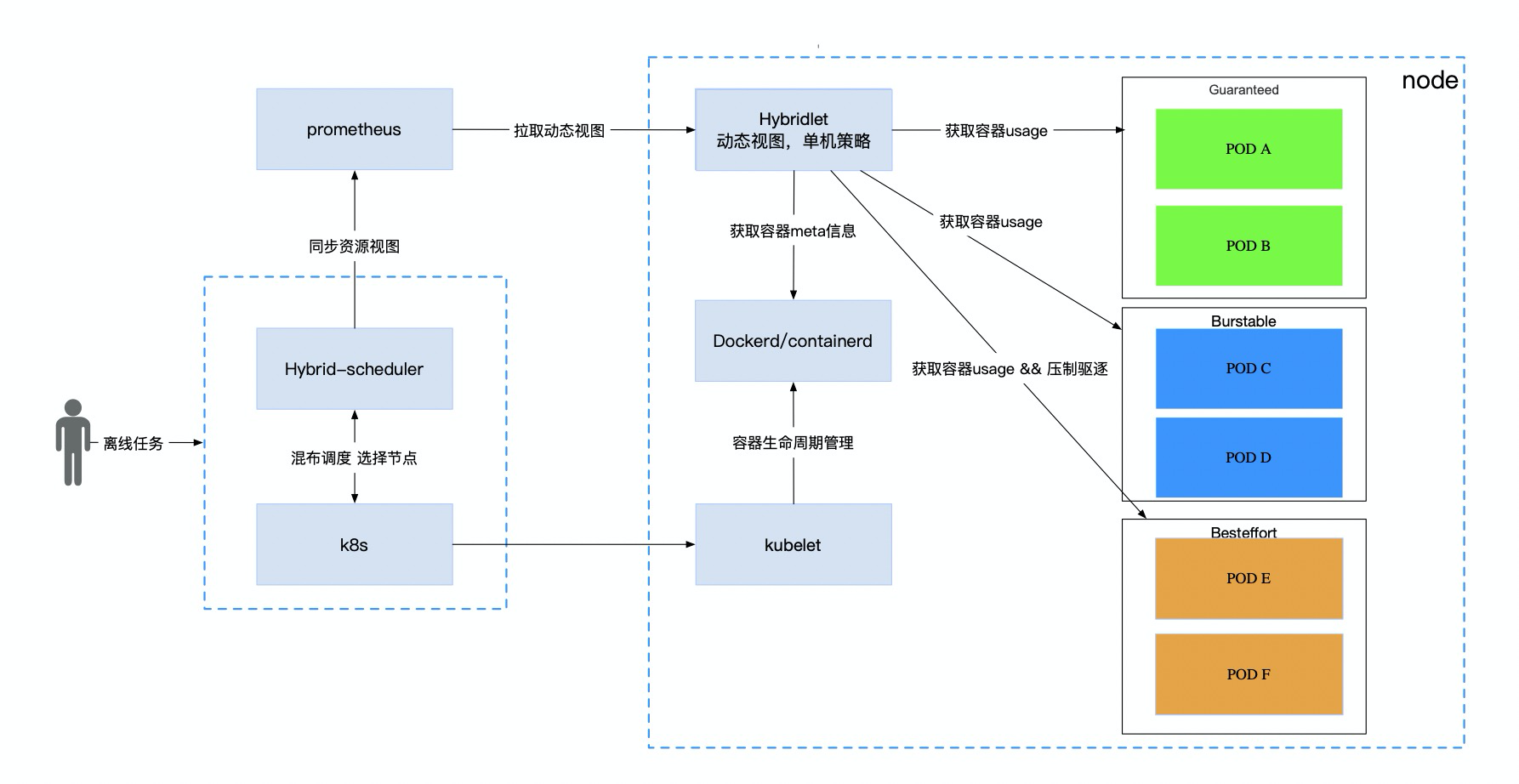
混部系统架构图
3.1 如何做到资源复用?
原生 K8s 基于静态视图分配
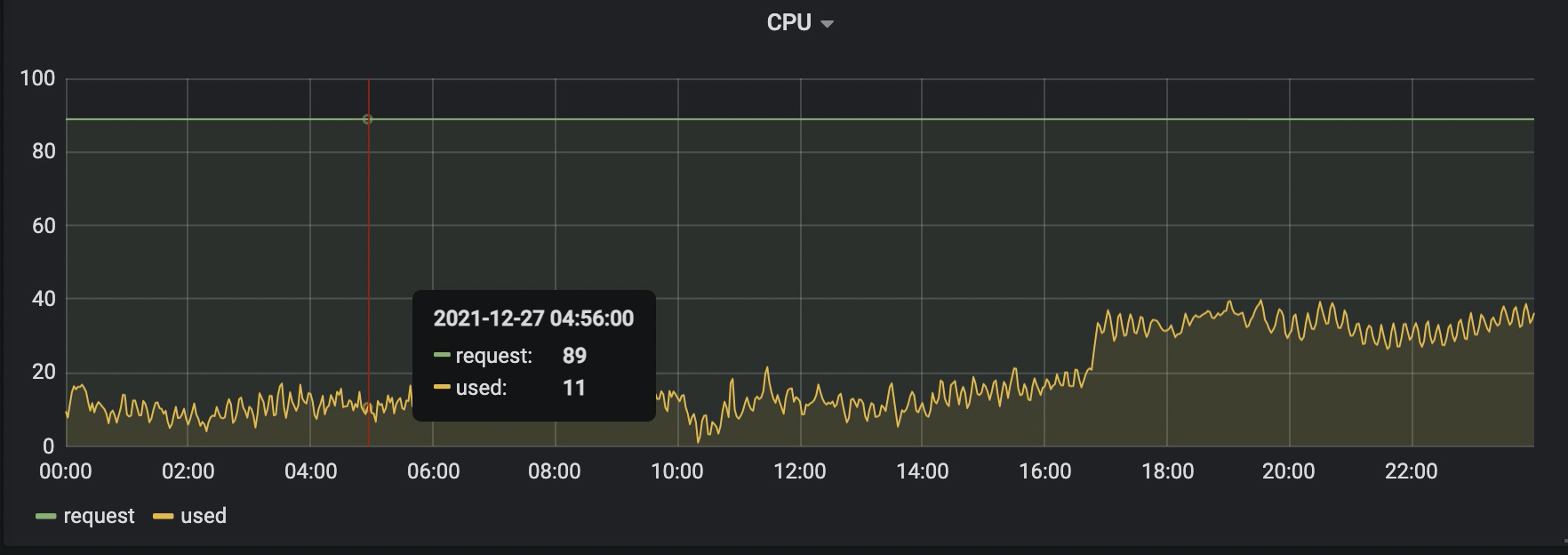
上图显示了一个节点的 CPU 使用率和分配率,分配率为89%, 使用率在0-16点之间都在20%以下,17点开始是用量高峰,在30-40%之间。可以看出 request 和 used 之间有大量的资源处于闲置状态,如果想让这部分资源可以重复利用起来,就需要调度更多的 Pod 上去,但是从 K8s 调度器视角来看,已经没有更多的 CPU 分给 Pod了。
如果部署 request 和 limit 都不填写的 Pod,此时它可以被调度,但是 K8s 针对这种 BestEffort 的 Pod 不会根据用量调度,可能会被调度到一个实际很繁忙的节点上,非但无法起到提升使用率的效果,可能还会加剧节点上服务的延迟。
动态资源视图
针对 K8s 无法根据资源使用量分配资源,我们引入了动态资源视图。
在混部调度中,在线和离线使用相同的物理资源,在线看到的资源视图和离线看到的资源视图相互独立。在线业务看到的可用资源依旧为整机资源进行静态分配,离线看到的可用资源为整机资源减去在线作业已经使用的资源。
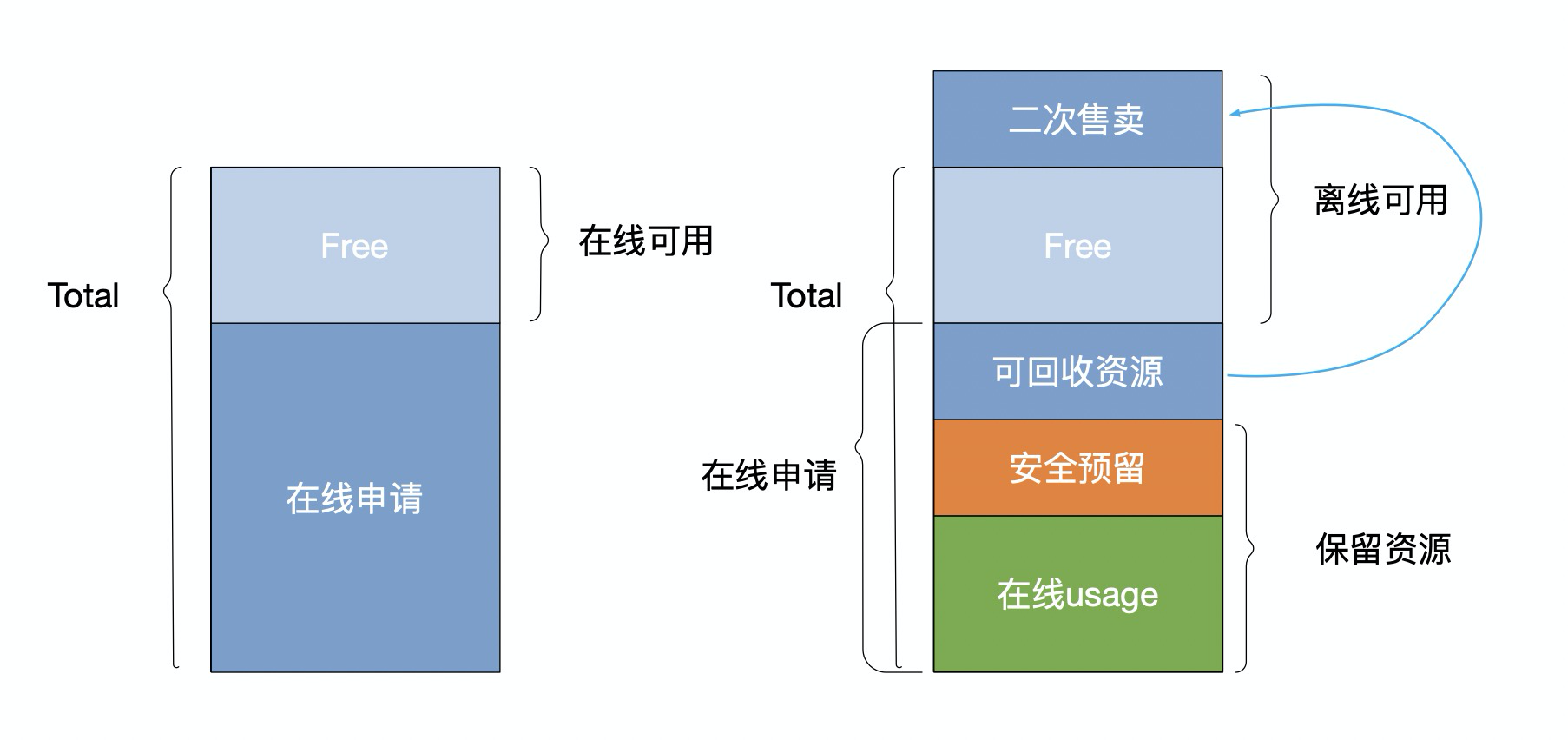
从图中可以看出,在线申请用量和在线usage之间存在很大的差异,主要是由于研发同学部署业务选择容器资源规格时,带有一定的盲目性,申请量高于实际使用资源量或者按照超出峰值用量申请。混部离线可以复用这部分可回收资源,通过快速填充离线作业,把这部分资源利用起来。
高中优(在线)为静态分配 ∑High request + ∑Medium request <= Host Quota
动态计算低优(离线)可用量 Low Quota = Host Quota - ∑High used - ∑Medium used
注:以上是理想情况下的公式,实际应用中需要对离线使用量设置一个上限,此处排除了上限造成的影响。下面会有单机资源管理的说明。
由于 K8s 是静态分配,在 K8s 的 QOS 模型中 BestEffort 是不占用 request 的,即使一个 node 上即使资源已经分配完,但是 BestEffort 类型的资源依然可以调度上去,所以我们复用了 BestEffort 模型给离线任务使用,如上文架构图所示,这样有以下的优点:
-
解决了在离线视图冲突问题,离线使用的 BestEffort 模型,对在线不可见
-
兼容社区组件,比如 cadvisor 可以直接使用
-
无需修改已有组件,包括 kubelet containerd runc,侵入性小,可以直接安装混部系统,享受混部带来的资源效能提升。
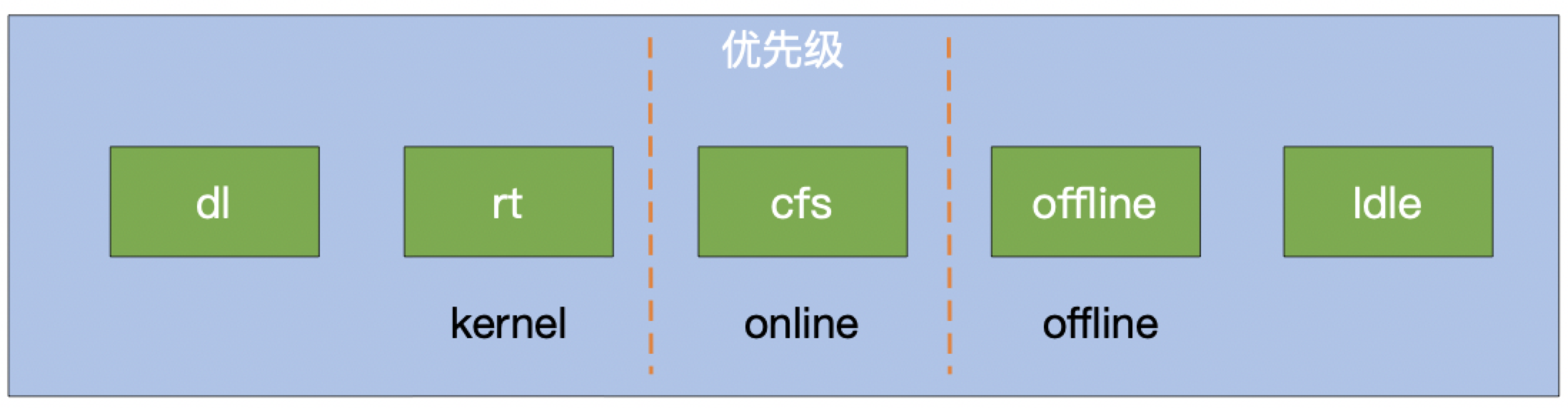
3.2 优先级
由于在离线业务同时部署在相同节点上可能会产生干扰,我们从调度和单机两个方面对在线离线做了优先级区分。
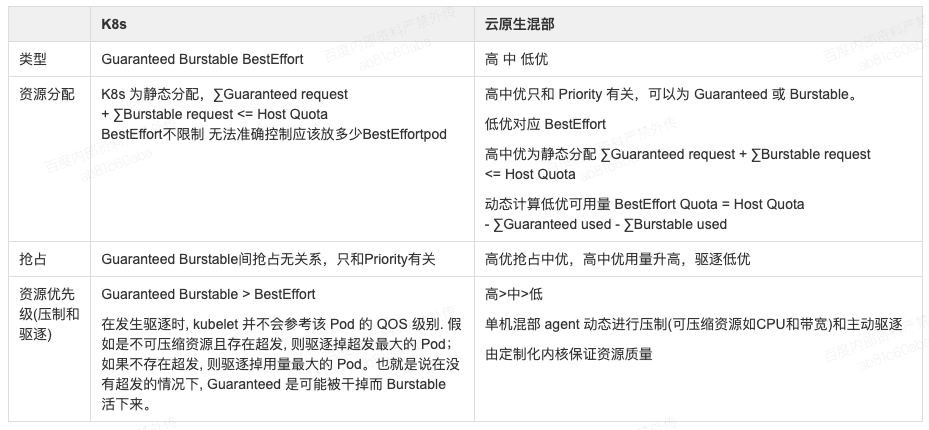
大的优先级分为(高,中,低)三种,其中高优中优为在线业务,低优为离线业务。每个优先级优化分若干小优先级。
首先看一下 K8s 的 QOS 模型
-
Guaranteed : 当 Pod 中所有 Container 的 request == limit 时
-
Burstable : 当 Pod 中存在 Container 的 request != limit 时
-
BestEffort : 当 Pod 中所有 Container 均未设置 request, limit 时
对比 K8s 模型,百度混部调度器做了如下扩展:
3.3 资源隔离
由于在离线混部是将在线业务和离线任务混合混部到相同物理资源上,所以在离线业务由于流量激增,出现资源争抢时,如何保证在线的SLA不受影响,并且在保证在线服务的SLA时,也要保证离线任务的整体质量,保证离线作业的成功率和耗时。
CPU
cpuset 编排
针对于需要绑核的在线业务,单机上可以感知到 CPU 拓扑,不需要 kubelet 开启绑核机制,可以直接进行绑核,会将在线业务尽量绑在同一 NUMA node 上,避免跨 node 通信延迟。
NUMA 调度
NUMA 是一种内存管理技术,在 NUMA 架构下 CPU 被划分为多个 node,每个 node 都有各自的 CPU core 和 local memory,node core 中的进程访问 local memory 和 remote memory 的代价是不一样的。节点的所有内存对于本节点所有的 CPU 都是等同的,对于其他节点中的所有 CPU 都不同。因此每个 CPU 可以访问整个系统内存,但是访问本地节点的内存速度最快(不经过互联模块),访问非本地节点的内存速度较慢(需要经过互联模块),即CPU 访问内存的速度与节点的距离有关。
针对开启了 NUMA 的节点,我们感知 NUMA 架构,将在线业务绑在同一 NUMA 上,提升在线业务的性能,并且感知 NUMA 节点的负载,当 node 之间出现明显的不平衡时,进行重调度。
离线调度器
在线业务要求实时性高,延迟低;为了保证低延迟,CPU 负载不会打的特别高,当 CPU 负载升高时,在线间干扰会导致延时增大。而离线业务一般 CPU 利用率高,但是重吞吐不重延时。所以如果能满足在线的延时保障,在线和离线跑在一个核上不会对在线造成干扰,那么可以极大的提升资源利用率。
按照现在通用的 Linux 内核调度器调度算法,无法给在线服务做 CPU 的强保障,无法区分在离线业务,会导致在线无法抢占离线 CPU,并且在负载均衡时,因为无法区分在离线业务,可能在线业务会分配到相同的核上,无法打散。导致性能下降。
离线调度器是一种离线任务专用的CPU调度算法,从调度器上分开,在线调度器看不到离线任务。在线调度器先于离线调度器进行任务调度,存在在线任务时,离线得不到调度。所以对于在线任务来说,可以达到混部前相近的CPU 质量。
内存
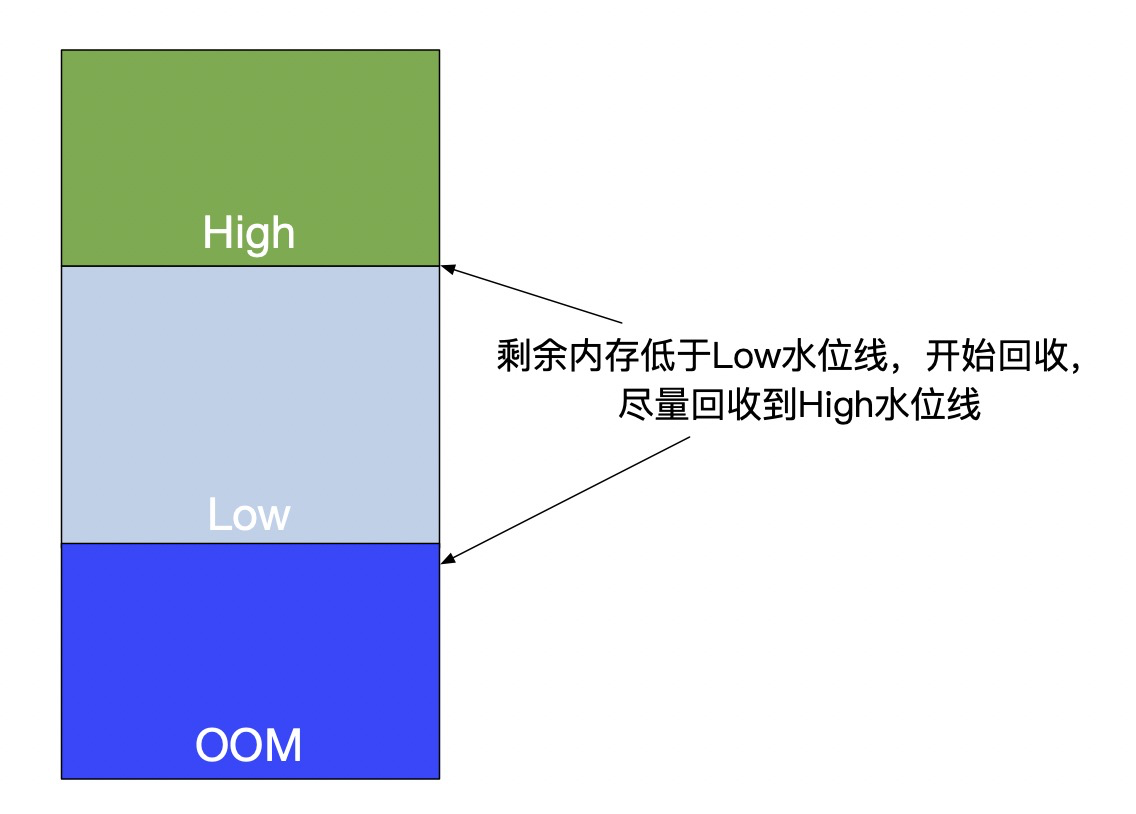
Linux 系统会经常执行一些写日志、生成备份文件的工作,当这些文件比较大时相应的 cache 就会占用大量的系统内存,而且这些类型的 cache 并不会被经常访问,所以系统会定期将这些 cache flush 到磁盘中。Linux 会通过cache 回收算法进行回收。这会造成两个问题:
1.容器的 page cache 得不到回收,它依赖于容器管理 page cache 的机制是需要才去回收的方式,即没有后台回收,每次都是分配时候发现到达 limit 了,在 alloc 的时候出发回收,如果业务压力较大,分配的速度大于回收的速度,就可能出现 OOM 的问题
2.cache 回收时并不会区分在线离线业务,会导致在线业务的 cache 可能会被先于离线 cache 回收掉,如果在线有大量的读 cache 行为,会造成 cache 命中降低,直接进行读盘操作,会导致在线业务的性能下降,甚至会导致IO 夯住。
为了解决以上的问题,我们新增了背景回收机制,背景回收指的是异步回收 cache,根据在线离线的 QOS 不同,设置不同的背景回收水位,优先回收离线业务的 cache。
-
每个容器后台周期自动回收自己产生的 page cache
-
每个容器都可以设置开关和自己的高低水位线
网络层面我们也开发了容器级别的出入网带宽限制和流量打标等 Cgroup 子系统,可以对离线进行流量限制。
更多的内核隔离见下图:

基于 eBPF 的动态策略
现有的内核隔离策略都是基于 QOS,创建容器时进行 cgroup 配置,由内核进行统一的资源管理,但是某些高敏业务在最高优先级的 QOS 下也无法保证其特定资源,或者需要某一纬度的资源需要高优保证,此时通用隔离策略无法满足。
另外由于隔离调度策略是全局统一的策略,业务如果想根据自身特点修改一些隔离能力,只能由业务反馈平台,平台对底层进行修改,周期较长,并且全局应用的隔离能力可能会对离线或者其他业务造成误伤,所以把隔离提升到用户态更符合业务需求。
针对这样的场景,由于 eBPF 稳定,安全,高效,并有可热加载/卸载 eBPF 程序,无需重启 Linux 系统的特性,我们基于 eBPF 开发了定制策略,可以实时下发,实时生效,侵入性小,不需要对业务既有服务和平台侧进行修改。可以在用户态针对某些业务进行定制化隔离策略更新,达到服务可以无差别混部的目标。
单机资源管理
在混部时,离线可以占用多少资源一直是一个问题。机型不同,在线服务的敏感度不同,离线业务占用的资源多少对在线造成的影响也不尽相同,针对这种情况,我们对集群纬度,池(具有相同特性的一批机器)纬度,节点纬度对离线可用资源上限做了限制,其中粒度最小优先级最高。
以 CPU 为例,如下图:
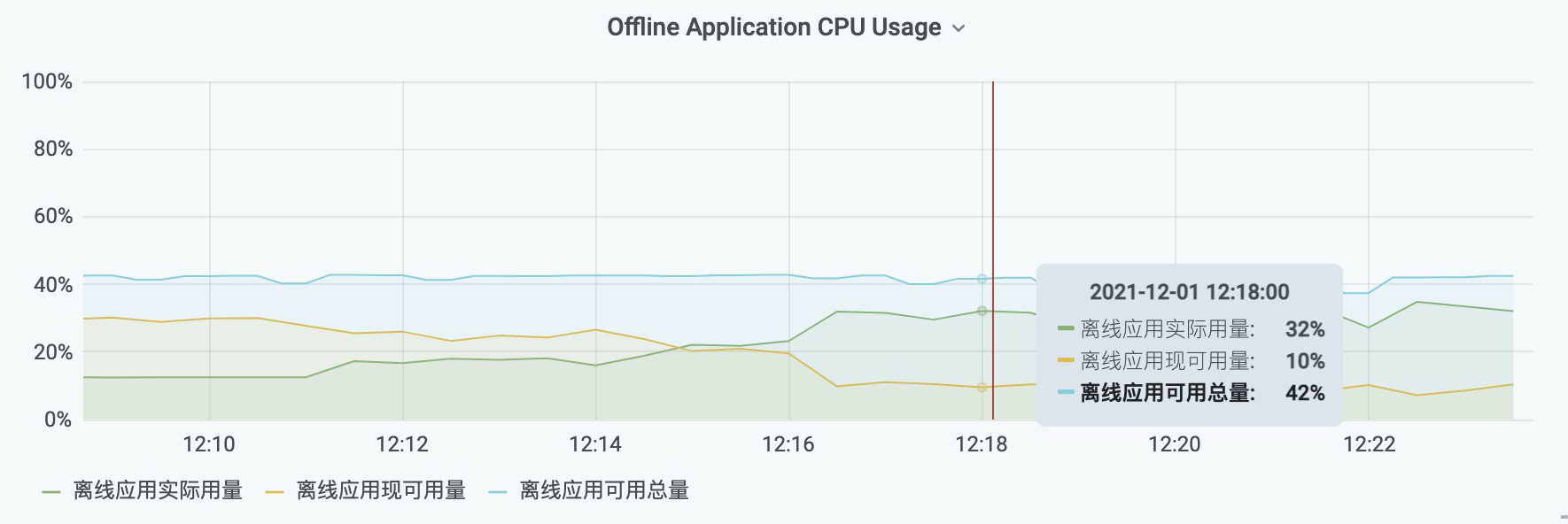
我们设置了整机的 CPU 阀值X,当整机 CPU 用量趋近或超过一定用量,比如X=50%时,会压缩离线使用的CPU资源。
列举一个简单的公式:
Offline Quota = Host Quota * X - ∑NotOffline Used
Offline Free = Offline Quota - ∑Offline used
同样,对于 Memory,IO和网络我们也做了同样的限制。这样我们可以根据不同的机型和业务很方便的调整离线的用量,避免在线用量升高时性能受到影响。
3.4 高性能调度器
在线和离线业务的调度需求是不一样的,在线一般为常驻服务,不会频繁变更,对调度器要求较低。但是离线任务由于具有运行时间短(几分钟到几小时),任务多的特点,以 K8s 默认调度器的调度性能不足以支撑离线任务的调度。所以我们开发了高性能的离线调度器,计算可以达到5000 ops。
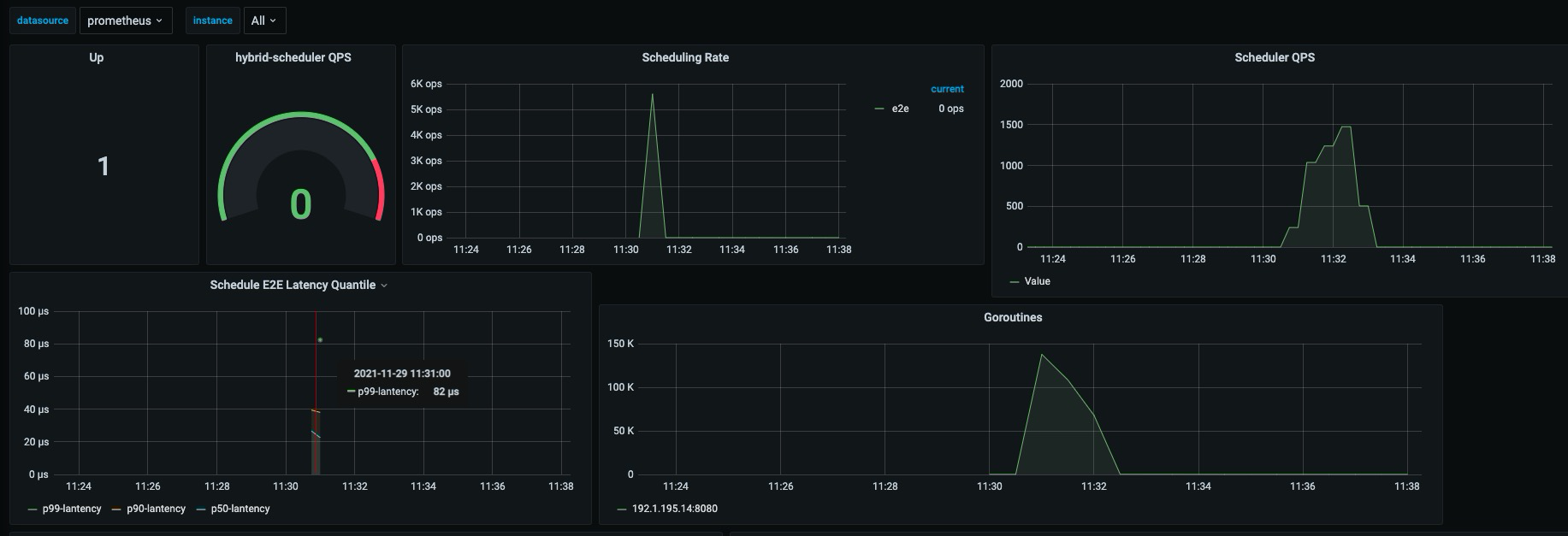
如上图所示,我们调度了15W个 Pod,计算性能可以达到5k ops, 为了防止调度速度过快,对 ETCD 和整个集群造成压力,我们限制了binding速度为1500 ops。
3.5 资源画像
单机资源隔离是针对已经调度到节点上的任务进行隔离,如果检测到离线任务对在线产生一定的影响后,会很快响应对离线任务进行压制和驱逐的操作。这样会影响离线任务的稳定性。针对这种场景,如果在调度时可以预测到节点上未来一段时间的在线使用量,可以针对性的调度离线任务。
对比实时计算的资源模型,假设离线作业的运行时间为1小时,如果资源模型使用实时的资源视图,如果在线作业会在半个小时候用量升高,那么当离线作业运行半个小时之后,资源被在线压制,运行质量受影响。
我们预测了未来1小时窗口内的在线资源用量,调度适当的离线任务上去,即可确保任意离线作业运行过程中资源不受任何压制,从而达到提升运行质量的目的。

如何提供更稳定的超发资源,则取决于我们资源预测的准确度是什么样的。
不仅离线调度需要资源画像,在线调度也需要资源画像,通过资源画像可以有效的避免热点产生。
-
对于在线调度来说,调度的主要目标是提升服务的可用性,在调度时使用资源画像来预测未来一个周期内的用量,可以避免热点问题(某一纬度的资源用量过高),并且在重调度时也可以规避热点问题。
-
对于离线调度来说,调度的主要目标是提升集群的吞吐,降低作业的排队时间和执行时间,所以资源画像可以提升离线作业的稳定性,避免驱逐重新调度和资源压制导致执行时间过长。
4.未来展望
百度目前混部规模数十万台,它的混部集群 CPU 利用率比在线利用率提升 40%—80%,累计节省近10万台服务器。
未来百度混部的主要目标是继续扩大混部的规模,更大规模地节约资源成本,可以支持更多的负载类型,不局限于在离线混部,要做到无差别混部。
-
在单机隔离方面,支持更多的业务进入混布,在检测冲突和资源隔离方面做的更好。
-
调度方面做更有计划的调度,资源画像更加精细化,调度时可以更精准的预测热点概率,优化调度能力,减少热点率。
并在以下方向投入更多的力量:
-
内核可编程技术:
通过 eBPF 可观测技术的创新,实现混部容器负载性能的近距离观察,达到进一步无损高密度混
利用 eBPF 热加载/卸载的特性,可以用户态下发隔离策略,快速的解决高敏的资源质量问题
-
异构:更好的支持GPU等异构资源混部,提高异构资源效能与弹性,大幅降低GPU成本。
-
容器虚机融合:解决高密机型共享内核混部的瓶颈。
-
多云混部:结合公有云进行极致的弹性,例如结合弹性竞价实例,基于用户对价格的敏感度设置,自动纳入或者摘除竞价实例,用于离线业务运行或混部,实现多云弹性混部。
关于百度容器引擎 CCE
百度容器引擎产品 CCE 提供 Docker 容器生命周期管理、大规模容器集群运维管理、业务应用一键式发布运行等功能,无缝衔接百度智能云其他产品。弹性、高可用的云端Kubernetes 容器运行平台,助力系统架构微服务化、DevOps运维、AI应用深度学习容器化等场景。
目前百度 CCE 已支持在离线混部,并完成了大规模业务落地,详情了解可点击这里
---------- END ----------
进群!聊聊混部
扫码添加小助手即可申请加入,一定要备注:名字-公司/学校-地区,根据格式备注,才能通过且邀请进群。

了解更多微服务、云原生技术的相关信息,请关注我们的微信公众号【百度云原生】!

|








- 上一条: 大型集团企业云管平台建设参考架构 2021-12-30
- 下一条: 接口文档自动更改?百度程序员开发效率MAX的秘诀 2021-12-30
- BaikalDB在百度统计的应用实践 2021-09-25
- 百度混部实践系列 | 如何提高 K8S 集群资源利用率? 2021-09-15
- Volcano:在离线作业混部管理平台,实现智能资源管理和作业调度 2022-03-31
- 百度CTO王海峰:AI大生产平台再升级 助力中国科技自立自强 2021-12-30
- 深入理解RabbitMQ与AMQP协议 2021-11-11


