史上最简单的日志告警方案,没有之一
如果你在意生产环境的稳定性,希望自己的服务出问题时及时发现,大概率就有日志监控告警的需求,比如发现日志中有 Error 或 Exception 关键字就告警,比如通过日志统计某个服务的 95 分位延迟数据,延迟过高就告警,比如通过日志统计某个服务的 status code,出现多个 5xx 就告警,等等。
日志可能存储在 ElasticSearch、Loki、ClickHouse 等系统中,告警系统的核心逻辑也比较清晰,就是根据用户配置的查询语句,周期性查询这些存储,并对查询结果做阈值判定,如果达到阈值就触发告警。比如统计 5 分钟内出现的 Error 数量,如果大于 10 就告警。
市面上提供日志告警的产品也有不少,比如 Elastalert、Grafana、FlashDuty 等,其中 FlashDuty 是最省事的,SaaS 产品,直接用就好,不需要自己搭建和维护。下面我以 FlashDuty 为例,介绍如何配置日志告警。
FlashDuty 是一个告警事件中心,其产品介绍地址:https://flashcat.cloud/product/flashduty/ 。核心提供两个能力:1)告警事件中心,可以把夜莺、Zabbix、Prometheus、云监控、蓝鲸等各类监控系统的告警汇聚在一个地方,做统一的告警收敛、聚合降噪、排班、认领、升级、派发、协作;2)FlashDuty 也直接提供告警引擎的能力,可以对接 VictoriaMetrics、M3DB、Prometheus、ClickHouse、MySQL、Oracle、Postgres、Loki、ElasticSearch 等数据源,直接查询数据源的数据做告警判定,不需要额外的监控系统,告警事件的产生和分发,FlashDuty 一肩挑。
1. 注册账号
首先需要免费注册一个 FlashDuty 账号,注册地址:https://console.flashcat.cloud/。注册之后会引导你自动创建一个协作空间,用于接收各类监控系统的告警事件,根据引导下一步下一步就行。这个是免费的,自动会有 14 天全功能试用期,如果到期了,手工转成免费套餐也可以继续使用。
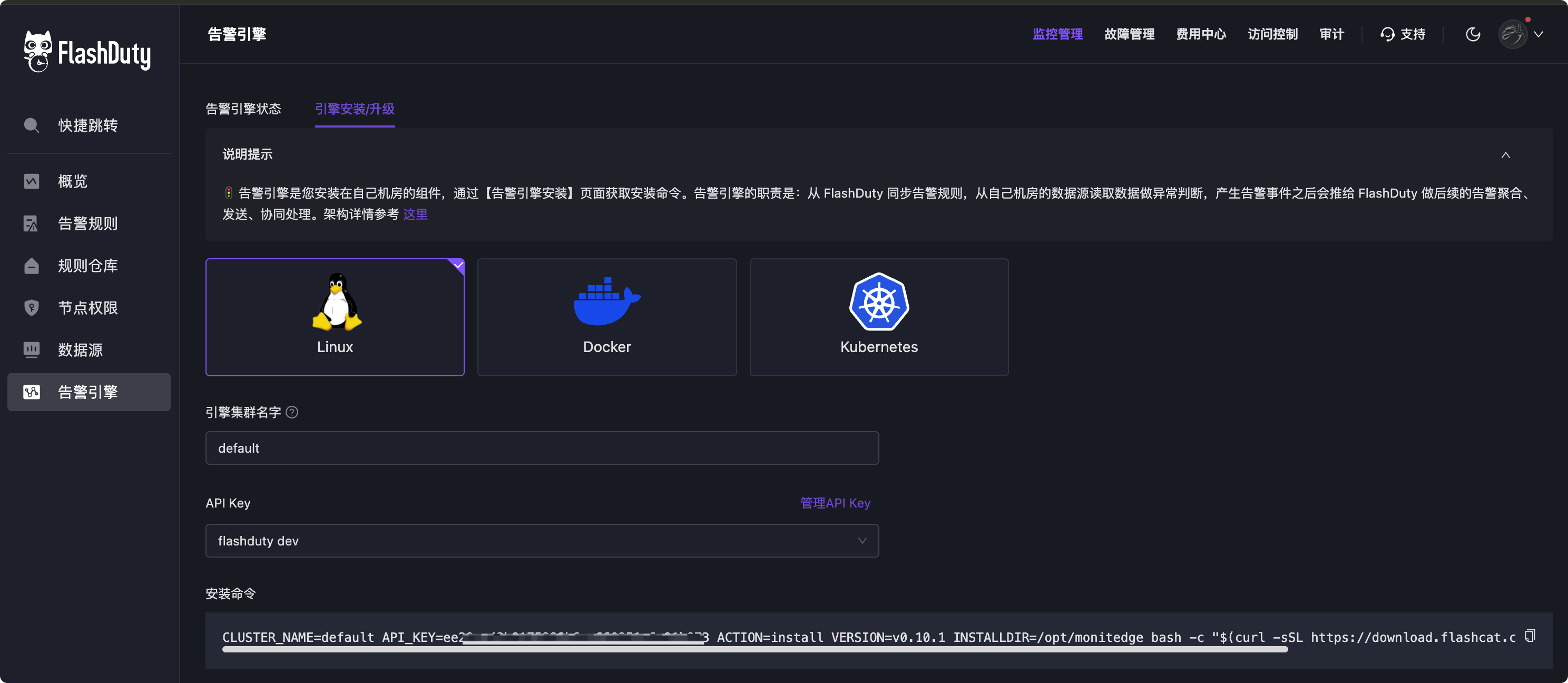
2. 安装告警引擎
FlashDuty 做告警判定的组件称为告警引擎,需要安装在你的数据中心,最好是和要监控的日志库在同一个数据中心,这样可以减少网络延迟。从这里获取安装命令,一行命令搞定:
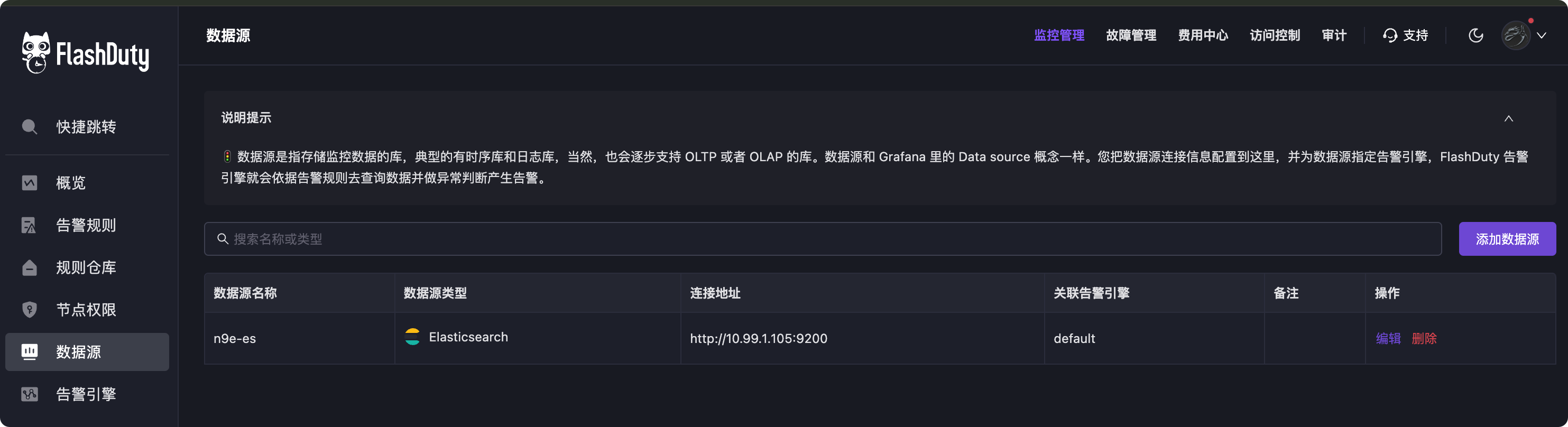
3. 配置数据源
以 ElasticSearch 举例,你的 ElasticSearch 的地址在哪里,得告诉 FlashDuty,配置为内网 IP 就行,虽然 FlashDuty 是 SaaS 的,但是告警引擎部署在你的数据中心,实际查询数据做告警判定都是由告警引擎完成的,所以数据源的地址配置为告警引擎可以访问的地址,我配置了一个 ElasticSearch 数据源,如下图所示:
4. 配置告警规则
现在就可以配置告警规则了,告警规则未来可能会有很多,这里使用树形分组做分门别类的管理。在告警规则管理页面,右键创建一个节点:
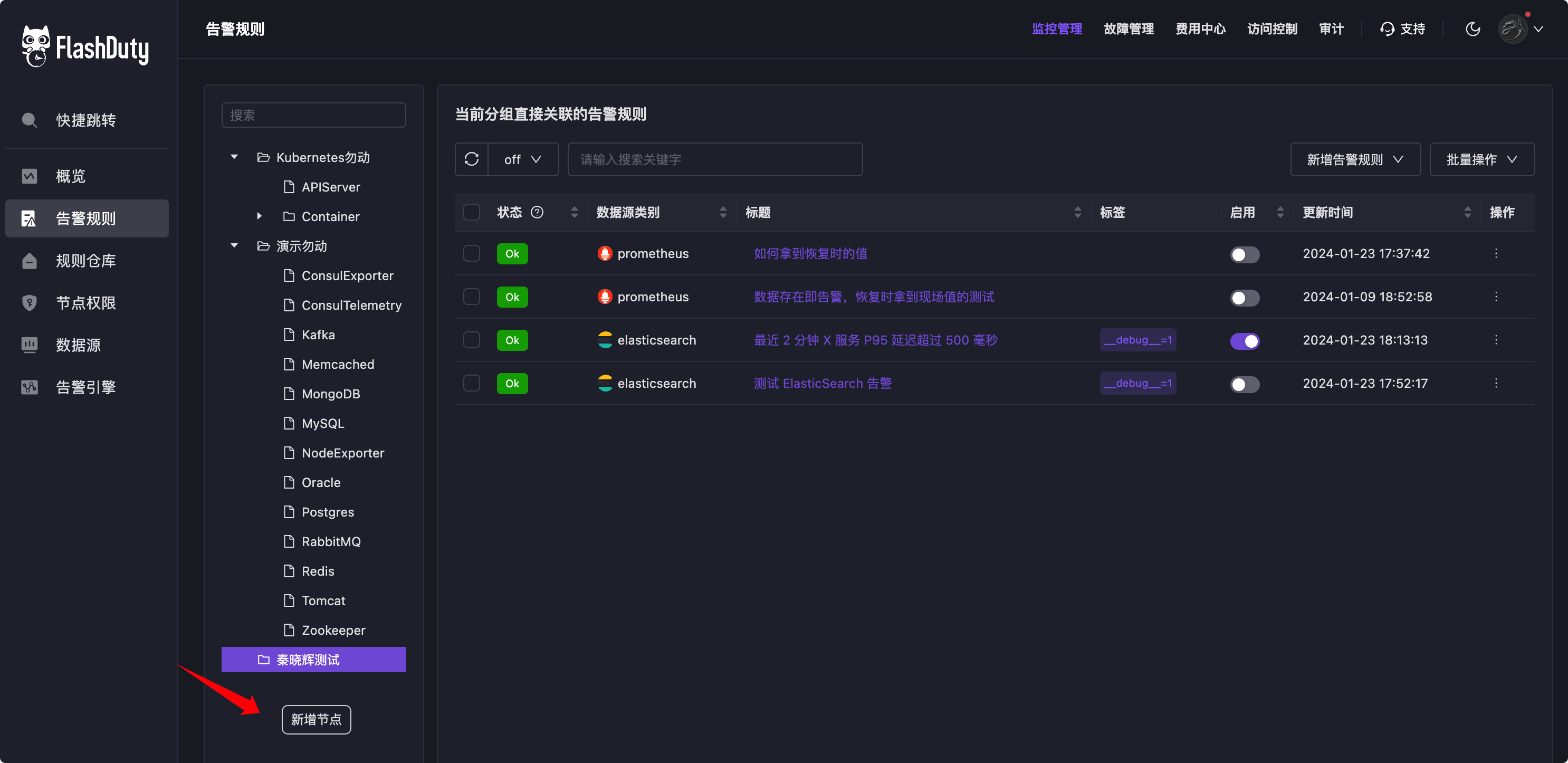
然后在这个节点下创建告警规则就可以了。我给大家举两个例子,一个是统计某个服务 5 分钟内出现的 Error 数量,如果大于 0 就告警,另一个是统计某个服务的 95 分位延迟,超过 500 毫秒就告警。
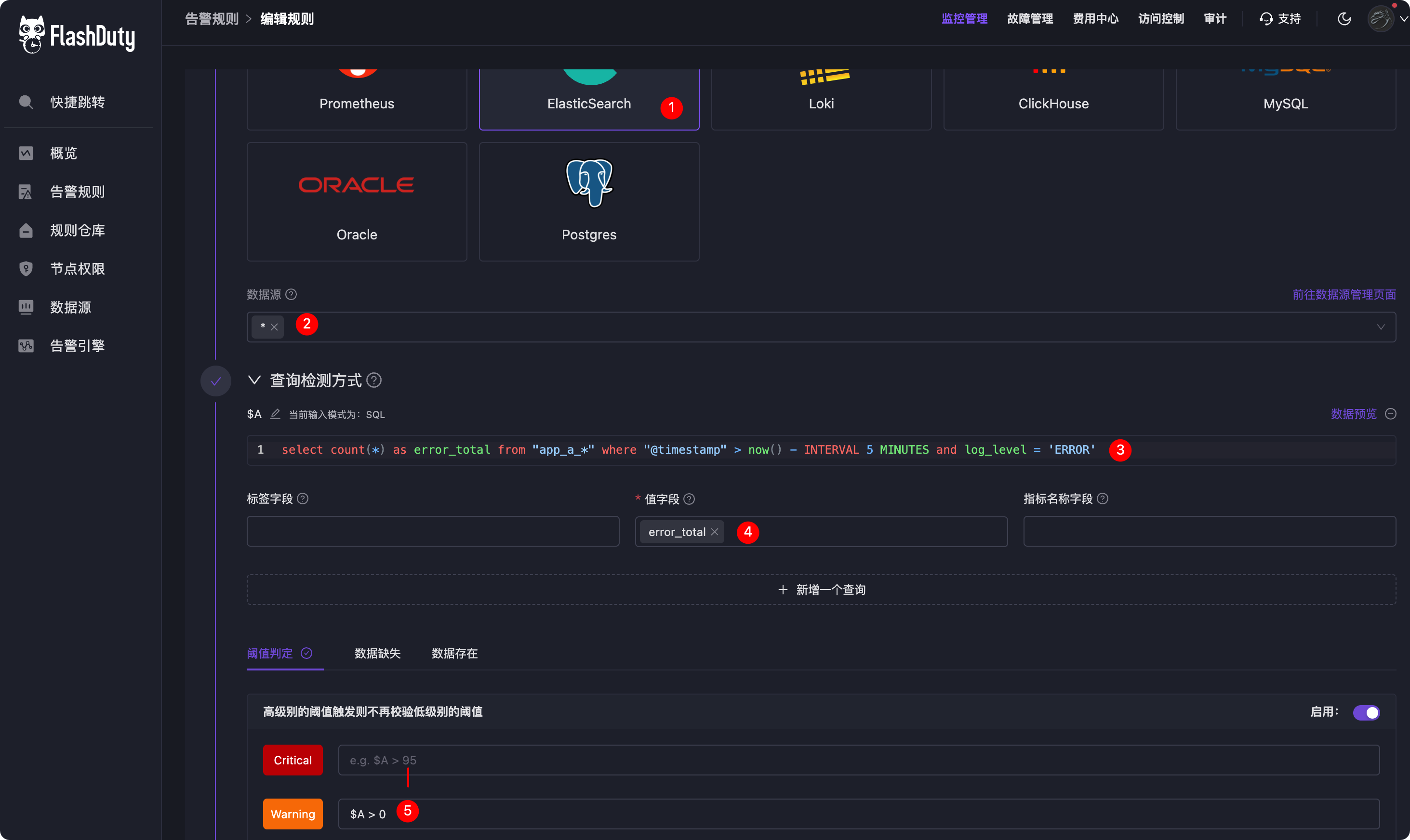
- 1、选择数据源类型,目前支持 Prometheus Like、ElasticSearch、Loki、ClickHouse、Oracle 等多种数据源类型,这里选择 ElasticSearch。
- 2、数据源,选择上一步配置的 ElasticSearch 数据源,支持通配符,我这里直接写成了
*,表示生效到所有 ElasticSearch 数据源。 - 3、查询语句,ElasticSearch 支持 DSL 和 SQL 两种查询方式,目前版本支持的是 SQL 查询方式,后面再解释这个 SQL 的含义。
- 4、SQL 语句查询到的结果是一个二维表格,具体哪一列是监控数值,哪一列是作为标签,是需要我们告诉 FlashDuty 的,在标签字段、值字段这里配置。
- 5、告警阈值评估表达式,上例中配置的是 A 这个查询语句得到的结果,只要大于 0 就告警。
select count(*) as error_total from "app_a_*" where "@timestamp" > now() - INTERVAL 5 MINUTES and log_level = 'ERROR'
这个 SQL 语句的含义是:统计 5 分钟内,所有 app_a_* 开头的索引中,log_level 字段为 ERROR 的日志数量。
SQL 里放置 Table Name 的地方,写索引名,支持通配符,"@timestamp" > now() - INTERVAL 5 MINUTES 表示查询最近 5 分钟内的数据,now() 函数大家应该不陌生,INTERVAL 5 MINUTE 表示 5 分钟的时间区段,我的日志里表示时间的字段是 @timestamp,因为是 @ 开头的,比较特殊,用双引号括起来了,log_level 是日志中的某个字段,使用这个字段做过滤,只统计 ERROR 级别的日志。如果想直接统计日志原文中的关键字,也可以使用 log_message like '%ERROR%' 这样的语法。或者使用 MATCH 函数、QUERY 函数,跟 Kibana 里查询是一个道理。
更多匹配函数可以参考 ElasticSearch 官网文档:
https://www.elastic.co/guide/en/elasticsearch/reference/7.17/sql-functions-search.html
再给大家举个例子,统计某个服务的 95 分位延迟,如果超过 500 毫秒就告警,SQL 语句如下:
select PERCENTILE(request.request_time, 95) as "p95" from "log_restful__20*" where "@timestamp" > now() - INTERVAL 2 MINUTES
我的日志中 request.request_time 这个字段表示延迟数据,PERCENTILE 是分位函数,95 表示 95 分位,log_restful__20* 是索引名,我这个索引的命名有点奇葩,大家忽略,知道是怎么回事就行,我的原始数据长这样:
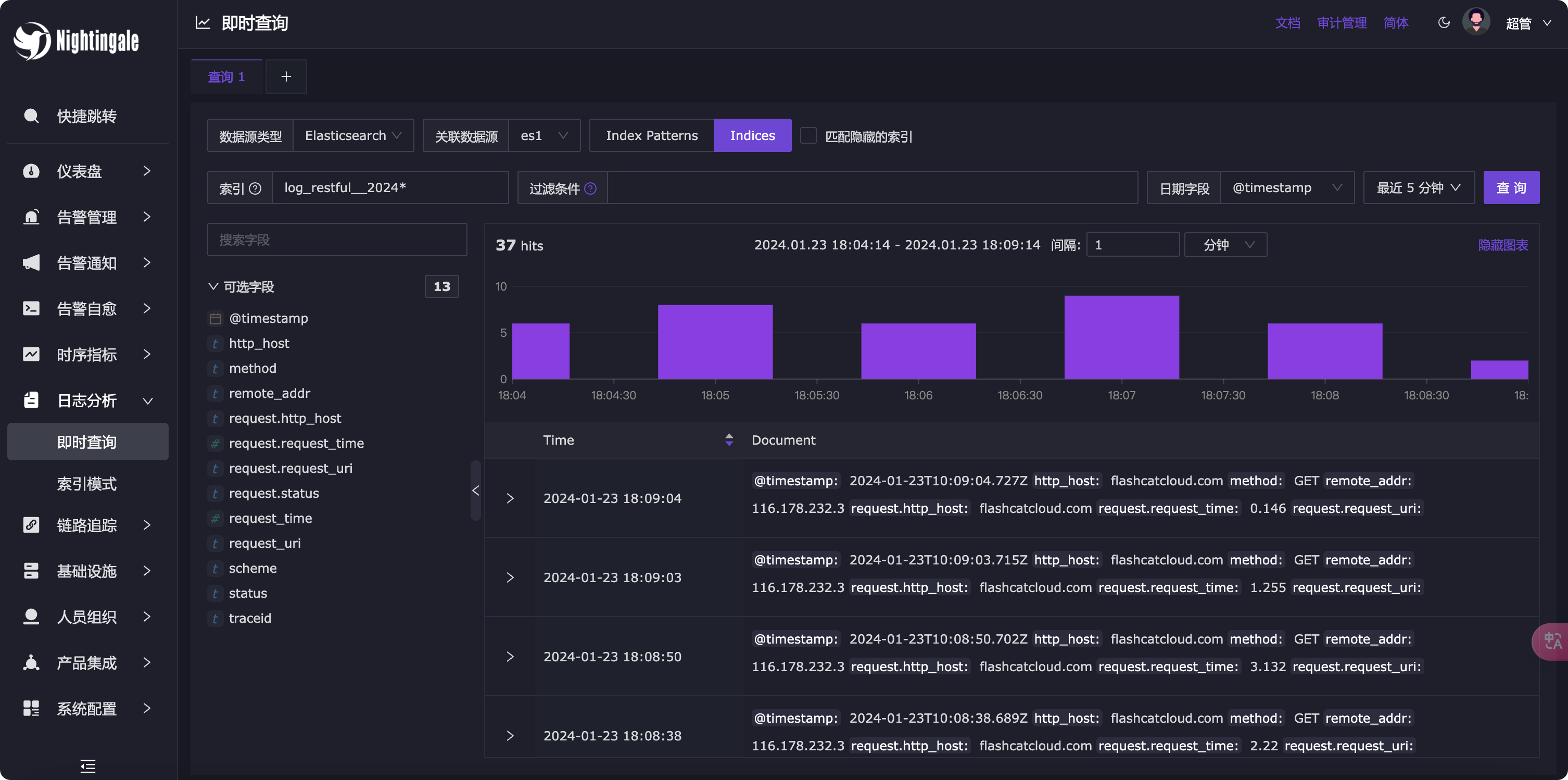
上图是在 Nightingale 里查询的日志原文。里边可以看到 request.request_time 字段。
5. 配置事件分发方式
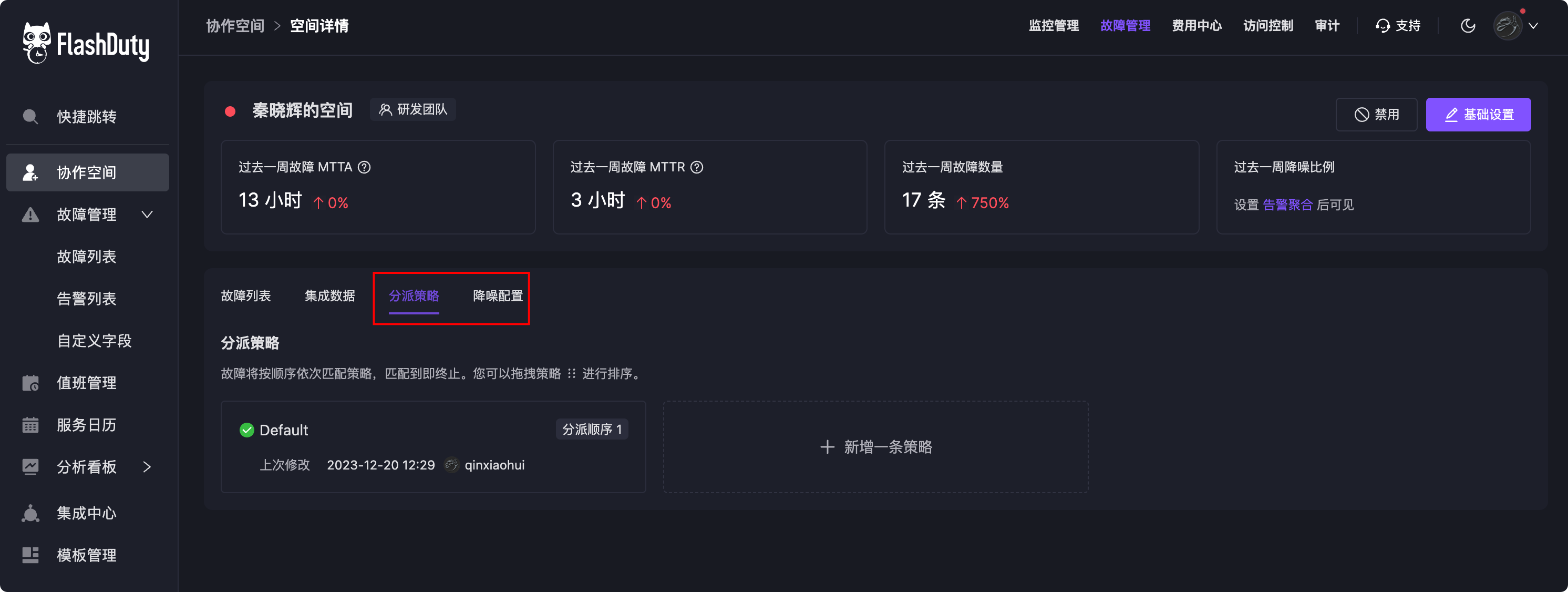
告警规则最下面,有个配置叫【事件推送给 FlashDuty 的协作空间】,配置成你的协作空间就行,这样告警事件就会推送到你配置的协作空间,你就可以在协作空间里看到告警事件了。当然,你也可以做更精细化配置,不同的告警分发给不同的值班人,以及告警降噪的配置等等,这里就不展开了,入口在下面位置(某个协作空间的详情页面)。
总结
如上,我们演示了使用 FlashDuty 做日志告警的全流程,FlashDuty 的告警引擎功能当前是公测阶段,可以免费使用。注册地址:https://console.flashcat.cloud/。
欢迎加我好友,交流可观测性相关话题或了解我们的商业产品,我的微信号:picobyte,加好友请备注您的公司、姓名、来意 🤝
扩展阅读:
|








- 上一条: 史上最全知识图谱建模实践(下):多元关系架构 2024-02-02
- 下一条: 社区供稿 | Mixtral-8x7B Pytorch 实现 2024-02-04
- 史上最强代码自测方法,没有之一! 2022-02-28
- 最简单的服务响应时长优化方法,没有之一 2021-12-29
- 网安学习路线!最详细没有之一!看了这么多分享网安学习路线的一个详细的都没有! 2021-08-28
- 详解CCE服务:一站式告警配置和云原生日志视图 2023-11-27
- 简单易用的监控告警系统 | HertzBeat 在 Rainbond 上的使用分享 2022-12-21