国际财务系统基于ShardingSphere的数据分片和一主多从实践
作者:京东物流 张广治
1 背景
传统的将数据集中存储至单一数据节点的解决方案,在性能和可用性方面已经难于满足海量数据的场景,系统最大的瓶颈在于单个节点读写性能,许多的资源受到单机的限制,例如连接数、网络IO、磁盘IO等,从而导致它的并发能力不高,对于高并发的要求不满足。
每到月初国际财务系统压力巨大,因为月初有大量补全任务,重算、计算任务、账单生成任务、推送集成等都要赶在月初1号完成,显然我们需要一个支持高性能、高并发的方案来解决我们的问题。
2 我们的目标
- 支持每月接单量一亿以上。
- 一亿的单量补全,计算,生成账单在24小时内完成(支持前面说的月初大数据量计算的场景)
3 数据分配规则
现实世界中,每一个资源都有其提供服务能力的上限,当某一个资源达到最大上限后就无法及时处理溢出的需求,这样就需要使用多个资源同时提供服务来满足大量的任务。当使用了多个资源来提供服务时,最为关键的是如何让每一个资源比较均匀的承担压力,而不至于其中的某些资源压力过大,所以分配规则就变得非常重要。
制定分配规则:要根据查询和存储的场景,一般按照类型、时间、城市、区域等作为分片键。
财务系统的租户以业务线为单位,缺点为拆分的粒度太大,不能实现打散数据的目的,所以不适合做为分片键,事件定义作为分片键,缺点是非常不均匀,目前2C进口清关,一个事件,每月有一千多万数据,鲲鹏的事件,每月单量很少,如果按照事件定义拆分,会导致数据极度倾斜。
目前最适合作为分片键的就是时间,因为系统中计算,账单,汇总,都是基于时间的,所以时间非常适合做分片键,适合使用月、周、作为Range的周期。目前使用的就是时间分区,但只按照时间分区显然已经不能满足我们的需求了。
经过筛选,理论上最适合的分区键就剩下时间和收付款对象了。
最终我们决定使用收付款对象分库,时间作为表分区。
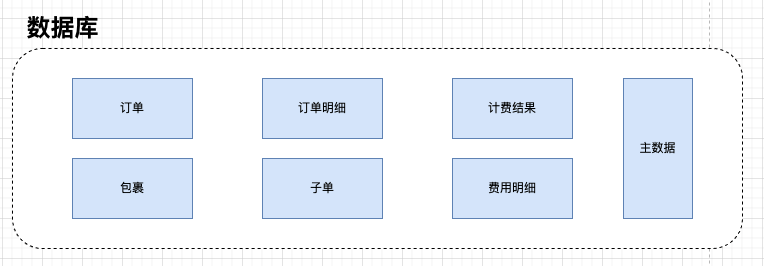
数据拆分前结构(图一):
数据水平拆分后结构(图二):
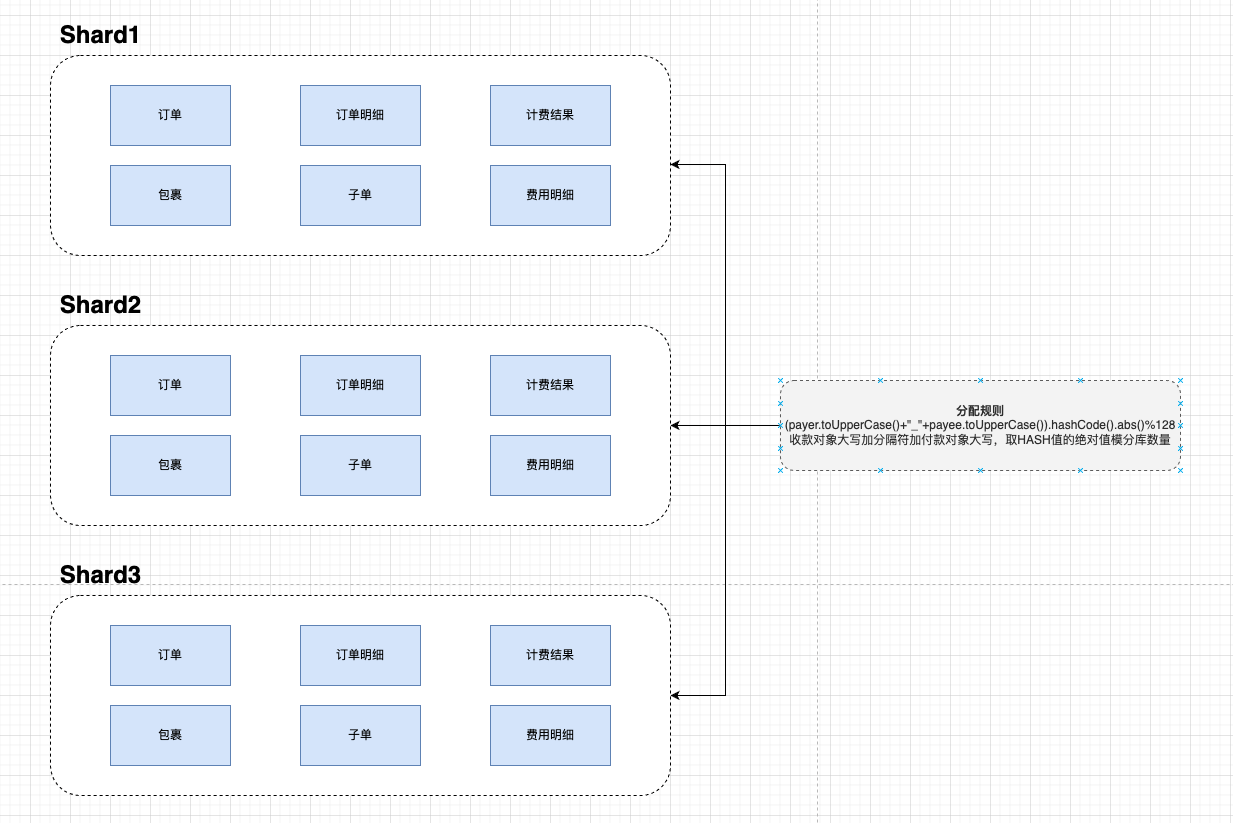
分配规则
(payer.toUpperCase()+"_"+payee.toUpperCase()).hashCode().abs()%128
收款对象大写加分隔符加付款对象大写,取HASH值的绝对值模分库数量
重要:payer和payee字母统一大写,因为大小写不统一,会导致HASH值不一致,最终导致路由到不同的库。
4 读写分离一主多从
4.1ShardingSphere对读写分离的解释
对于同一时刻有大量并发读操作和较少写操作类型的数据来说,将数据库拆分为主库和从库,主库负责处理事务性的增删改操作,从库负责处理查询操作,能够有效的避免由数据更新导致的行锁,使得整个系统的查询性能得到极大的改善。
通过一主多从的配置方式,可以将查询请求均匀的分散到多个数据副本,能够进一步的提升系统的处理能力。 使用多主多从的方式,不但能够提升系统的吞吐量,还能够提升系统的可用性,可以达到在任何一个数据库宕机,甚至磁盘物理损坏的情况下仍然不影响系统的正常运行。
把数据量大的大表进行数据分片,其余大量并发读操作且写入小的数据进行读写分离,如**(图三)**:
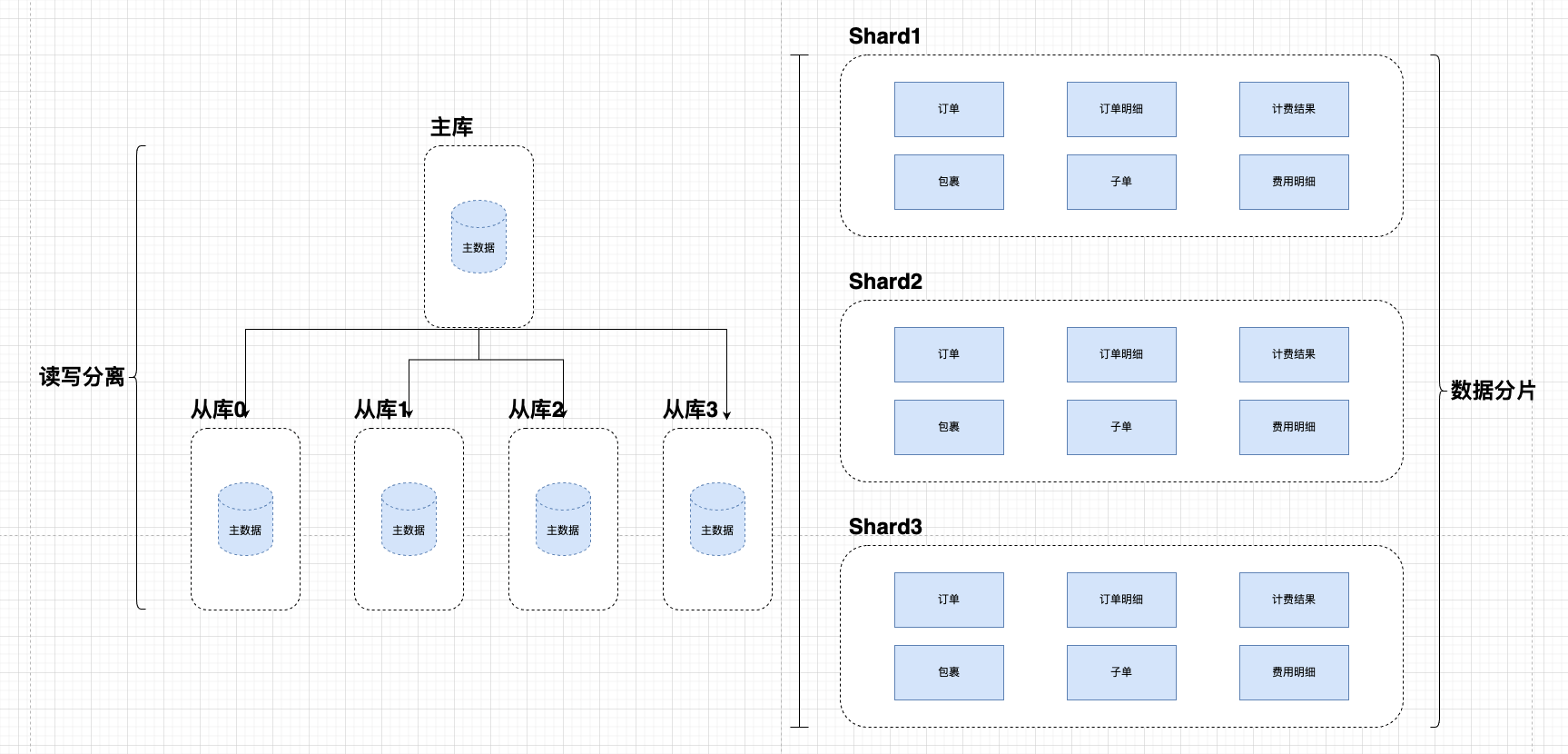
左侧为主从结构,右侧为数据分片
4.2 读写分离+数据分片实战
当我们实际使用sharding进行读写分离+数据分片时遇到了一个很大的问题,官网文档中的实现方式只适合分库和从库在一起时的场景如**(图四)**
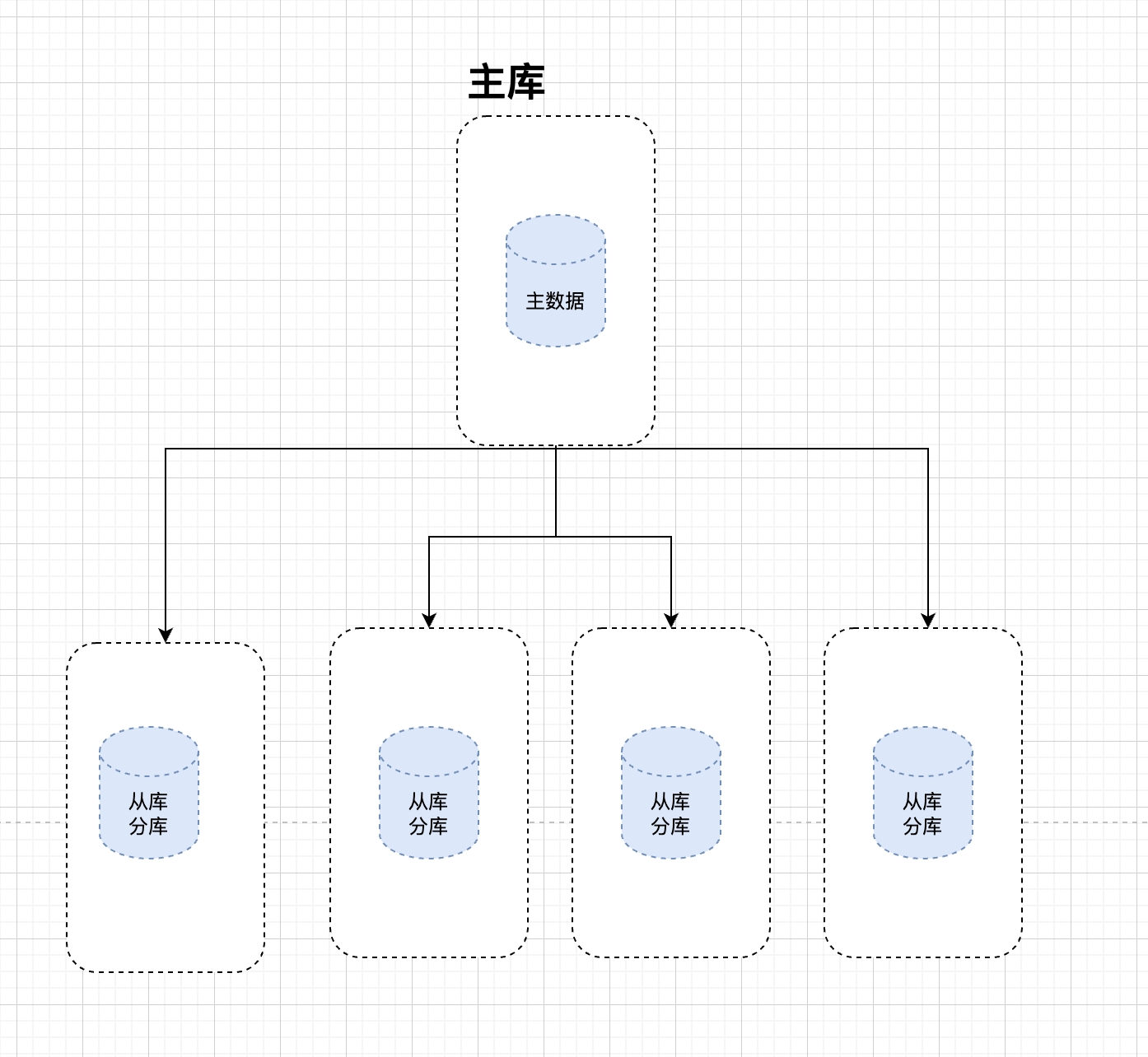
而我们的场景为**(图三)**所示,从库和分库时彻底分开的,参考官网的实现方法如下:
官网给出的读写分离+数据分片方案不能配置
spring.shardingsphere.sharding.default-data-source-name默认数据源,如果配置了,所有读操作将全部指向主库,无法达到读写分离的目的。
当我们困扰在读从库的查询会被轮询到分库中,我们实际的场景从库和分库是分离的,分库中根本就不存在从库中的表。此问题困扰了我近两天的时间,我阅读源码发现
spring.shardingsphere.sharding.default-data-source-name可以被赋值一个DataNodeGroup,不仅仅支持配置datasourceName,sharding源码如下图:
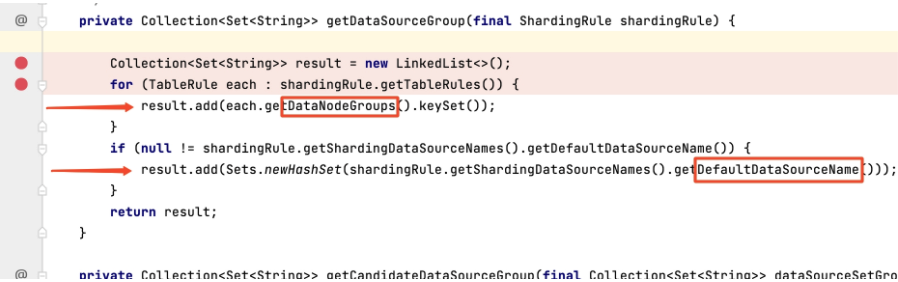
由此
spring.shardingsphere.sharding.default-data-source-name配置为读写分离的groupname1,问题解决
从库和分库不在一起的场景下,读写分离+数据分配的配置如下:
#数据源名称
spring.shardingsphere.datasource.names= defaultmaster,ds0,ds1,ds2,ds3,ds4,ds5,ds6,ds7,ds8,ds9,ds10,ds11,ds12,ds13,ds14,ds15,ds16,ds17,ds18,ds19,ds20,ds21,ds22,ds23,ds24,ds25,ds26,ds27,ds28,ds29,ds30,ds31,slave0,slave1
#未配置分片规则的表将通过默认数据源定位,注意值必须配置为读写分离的分组名称groupname1
spring.shardingsphere.sharding.default-data-source-name=groupname1
#主库
spring.shardingsphere.datasource.defaultmaster.jdbc-url=jdbc:mysql:
spring.shardingsphere.datasource.defaultmaster.type= com.zaxxer.hikari.HikariDataSource
spring.shardingsphere.datasource.defaultmaster.driver-class-name= com.mysql.jdbc.Driver
#分库ds0
spring.shardingsphere.datasource.ds0.jdbc-url=jdbc:mysql:
spring.shardingsphere.datasource.ds0.type= com.zaxxer.hikari.HikariDataSource
spring.shardingsphere.datasource.ds0.driver-class-name= com.mysql.jdbc.Driver
#从库slave0
spring.shardingsphere.datasource.slave0.jdbc-url=jdbc:mysql:
spring.shardingsphere.datasource.slave0.type= com.zaxxer.hikari.HikariDataSource
spring.shardingsphere.datasource.slave0.driver-class-name= com.mysql.jdbc.Driver
#从库slave1
spring.shardingsphere.datasource.slave1.jdbc-url=jdbc:mysql:
spring.shardingsphere.datasource.slave1.type= com.zaxxer.hikari.HikariDataSource
spring.shardingsphere.datasource.slave1.driver-class-name= com.mysql.jdbc.Driver
#由数据源名 + 表名组成,以小数点分隔。多个表以逗号分隔,支持inline表达式。缺省表示使用已知数据源与逻辑表名称生成数据节点,用于广播表(即每个库中都需要一个同样的表用于关联查询,多为字典表)或只分库不分表且所有库的表结构完全一致的情况
spring.shardingsphere.sharding.tables.incident_ar.actual-data-nodes=ds$->{0..127}.incident_ar
#行表达式分片策略 分库策略,缺省表示使用默认分库策略
spring.shardingsphere.sharding.tables.incident_ar.database-strategy.inline.sharding-column= dept_no
#分片算法行表达式,需符合groovy语法
spring.shardingsphere.sharding.tables.incident_ar.database-strategy.inline.algorithm-expression=ds$->{dept_no.toUpperCase().hashCode().abs() % 128}
#读写分离配置
spring.shardingsphere.sharding.master-slave-rules.groupname1.master-data-source-name=defaultmaster
spring.shardingsphere.sharding.master-slave-rules.groupname1.slave-data-source-names[0]=slave0
spring.shardingsphere.sharding.master-slave-rules.groupname1.slave-data-source-names[1]=slave1
spring.shardingsphere.sharding.master-slave-rules.groupname1.load-balance-algorithm-type=round_robin
可以看到读操作可以被均匀的路由到slave0、slave1中,分片的读会被分配到ds0,ds1中如下图:
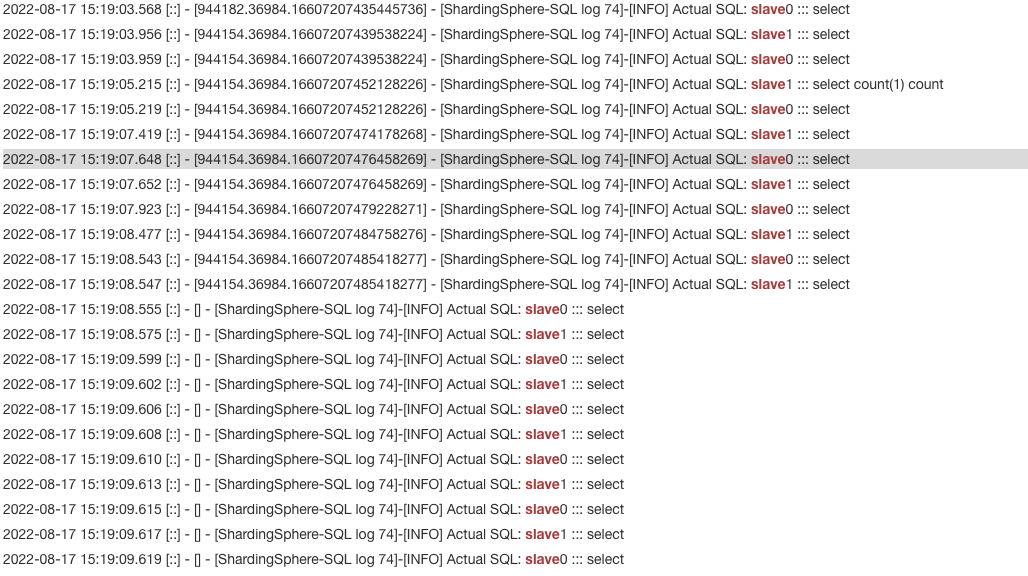
4.3 实现自己的读写分离负载均衡算法
Sharding提供了SPI形式的接口
org.apache.shardingsphere.spi.masterslave.MasterSlaveLoadBalanceAlgorithm实现读写分离多个从的具体负载均衡规则,代码如下:
import lombok.Getter;
import lombok.RequiredArgsConstructor;
import lombok.Setter;
import org.apache.shardingsphere.spi.masterslave.MasterSlaveLoadBalanceAlgorithm;
import org.springframework.stereotype.Component;
import java.util.List;
import java.util.Properties;
@Component
@Getter
@Setter
@RequiredArgsConstructor
public final class LoadAlgorithm implements MasterSlaveLoadBalanceAlgorithm {
private Properties properties = new Properties();
@Override
public String getType() {return "loadBalance";}
@Override
public String getDataSource(final String name, final String masterDataSourceName, final List<String> slaveDataSourceNames) {
//自己的负载均衡规则
return slaveDataSourceNames.get(0);
RoundRobinMasterSlaveLoadBalanceAlgorithm 实现为所有从轮询负载
RandomMasterSlaveLoadBalanceAlgorithm 实现为所有从随机负载均衡
4.4 关于某些场景下必须读主库的解决方案
某些场景比如分布式场景下写入马上读取的场景,可以使用hint方式进行强制读取主库,Sharding源码使用ThreadLocal实现强制路由标记。
下面封装了一个注解可以直接使用,代码如下:
@Documented
@Target({ElementType.METHOD})
@Retention(RetentionPolicy.RUNTIME)
public @interface SeekMaster {
}
import lombok.extern.slf4j.Slf4j;
import org.apache.shardingsphere.api.hint.HintManager;
import org.aspectj.lang.ProceedingJoinPoint;
import org.aspectj.lang.annotation.Around;
import org.aspectj.lang.annotation.Aspect;
import org.springframework.stereotype.Component;
/**
* ShardingSphere >读写分离自定义注解>用于实现读写分离时>需要强制读主库的场景(注解实现类)
*
* @author zhangguangzhi1
**/
@Slf4j
@Aspect
@Component
public class SeekMasterAnnotation {
@Around("@annotation(seekMaster)")
public Object doInterceptor(ProceedingJoinPoint joinPoint, SeekMaster seekMaster) throws Throwable {
Object object = null;
Throwable t = null;
try {
HintManager.getInstance().setMasterRouteOnly();
log.info("强制查询主库");
object = joinPoint.proceed();
} catch (Throwable throwable) {
t = throwable;
} finally {
HintManager.clear();
if (t != null) {
throw t;
}
}
return object;
使用时方法上打SeekMaster注解即可,方法下的所有读操作将自动路由到主库中,方法外的所有查询还是读取从库,如下图:

4.5 关于官网对读写分离描述不够明确的补充说明
版本4.1.1

经实践补充说明为:
同一线程且同一数据库连接且一个事务中,如有写入操作,以后的读操作均从主库读取,只限存在写入的表,没有写入的表,事务中的查询会继续路由至从库中,用于保证数据一致性。
5 关于分库的JOIN操作
方法1
使用default-data-source-name配置默认库,即没有配置数据分片策略的表都会使用默认库。默认库中表禁止与拆分表进行JOIN操作,此处需要做一些改造,目前系统有一些JOIN操作。(推荐使用此方法)
方法2
使用全局表,广播表,让128个库中冗余基础库中的表,并实时改变。
方法3
分库表中冗余需要JOIN表中的字段,可以解决JOIN问题,此方案单个表字段会增加。
6 分布式事务
6.1 XA事务管理器参数配置

XA是由X/Open组织提出的分布式事务的规范。 XA规范主要定义了(全局)事务管理器(TM)和(局 部)资源管理器(RM)之间的接口。主流的关系型 数据库产品都是实现了XA接口的。
分段提交
XA需要两阶段提交: prepare 和 commit.
第一阶段为 准备(prepare)阶段。即所有的参与者准备执行事务并锁住需要的资源。参与者ready时,向transaction manager报告已准备就绪。
第二阶段为提交阶段(commit)。当transaction manager确认所有参与者都ready后,向所有参与者发送commit命令。
ShardingSphere默认的XA事务管理器为Atomikos,在项目的logs目录中会生成xa_tx.log, 这是XA崩溃恢复时所需的日志,请勿删除。
6.2 BASE柔性事务管理器(SEATA-AT配置)
Seata是一款开源的分布式事务解决方案,提供简单易用的分布式事务服务。随着业务的快速发展,应用单体架构暴露出代码可维护性差,容错率低,测试难度大,敏捷交付能力差等诸多问题,微服务应运而生。微服务的诞生一方面解决了上述问题,但是另一方面却引入新的问题,其中主要问题之一就是如何保证微服务间的业务数据一致性。Seata 注册配置服务中心均使用 Nacos。Seata 0.2.1+ 开始支持 Nacos 注册配置服务中心。
- 按照seata-work-shop中的步骤,下载并启动seata server。
- 在每一个分片数据库实例中执创建undo_log表(以MySQL为例)
CREATE TABLE IF NOT EXISTS `undo_log`
(
`id` BIGINT(20) NOT NULL AUTO_INCREMENT COMMENT 'increment id',
`branch_id` BIGINT(20) NOT NULL COMMENT 'branch transaction id',
`xid` VARCHAR(100) NOT NULL COMMENT 'global transaction id',
`context` VARCHAR(128) NOT NULL COMMENT 'undo_log context,such as serialization',
`rollback_info` LONGBLOB NOT NULL COMMENT 'rollback info',
`log_status` INT(11) NOT NULL COMMENT '0:normal status,1:defense status',
`log_created` DATETIME NOT NULL COMMENT 'create datetime',
`log_modified` DATETIME NOT NULL COMMENT 'modify datetime',
PRIMARY KEY (`id`),
UNIQUE KEY `ux_undo_log` (`xid`, `branch_id`)
) ENGINE = InnoDB
AUTO_INCREMENT = 1
DEFAULT CHARSET = utf8 COMMENT ='AT transaction mode undo table';
3.在classpath中增加seata.conf
client {
application.id = example ## 应用唯一id
transaction.service.group = my_test_tx_group ## 所属事务组
}
6.3 Sharding-Jdbc默认提供弱XA事务
官方说明:
完全支持非跨库事务,例如:仅分表,或分库但是路由的结果在单库中。
完全支持因逻辑异常导致的跨库事务。例如:同一事务中,跨两个库更新。更新完毕后,抛出空指针,则两个库的内容都能回滚。
不支持因网络、硬件异常导致的跨库事务。例如:同一事务中,跨两个库更新,更新完毕后、未提交之前,第一个库死机,则只有第二个库数据提交。
6.4 分布式事务场景
1.保存场景
推荐使用第三种弱XA事务,尽量设计时避免跨库事务,目前设计为事件和事件数据为同库(分库时,将一个线索号的事件和事件数据HASH进入同一个分库),尽量避免跨库事务。
事件和计费结果本身设计为异步,非同一事务,所以事件和对应的结果不涉及跨库事务。
保存多个计费结果,每次保存都属于一个事件,一个事件的计费结果都属于一个收付款对象,天然同库。
弱XA事务的性能最佳。
2.更新场景
对一些根据ID IN的更新场景,根据收付款对象分组执行,可以避免在所有分库执行更新。
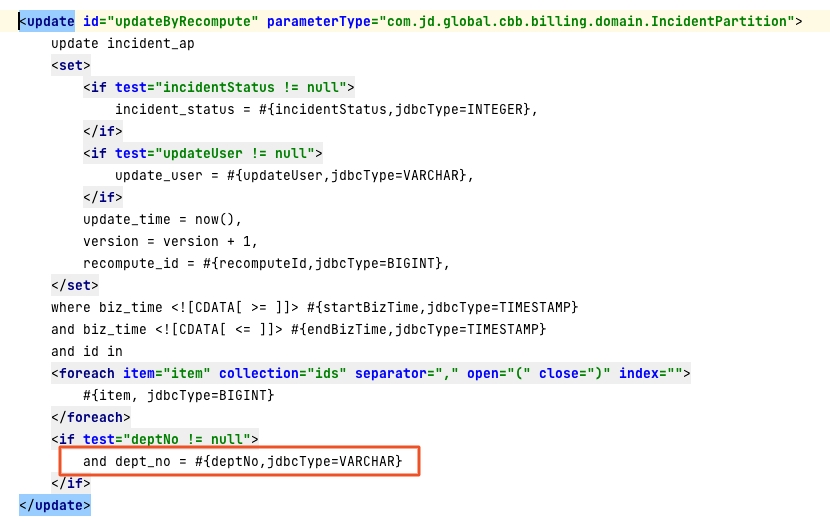
3.删除场景
无,目前都是逻辑删除,实际为更新。
7 总结
1.推荐使用Sharding-Sphere进行分库,分表可以考虑使用MYSQL分区表,对于研发来讲完全是透明的,可以规避JOIN\分布式事务等问题。(分区表需要为分区键+ID建立了一个联合索引)MYSQL分区得到了大量的实践印证,没有BUG,包括我在新计费初期,一直坚持推动使用的分表方案,不会引起一些难以发现的问题,在同库同磁盘下性能与分表相当。
2.对于同一时刻有大量并发读操作和较少写操作类型的数据来说,适合使用读写分离,增加多个读库,缓解主库压力,要注意的是必须读主库的场景使用SeekMaster注解来实现。
3.数据分库选择合适的分片键非常重要,要根据业务需求选择好分库键,尽力避免数据倾斜,数据不均匀是目前数据拆分的一个共同问题,不可能实现数据的完全均匀;当查询条件没有分库键时会遍历所有分库,查询尽量带上分库键。
4.在我们使用中间件时,不要只看官网解释,要多做测试,用实际来验证,有的时候官网解释话术可能存在歧义或表达不够全面的地方,分析源码和实际测试可以清晰的获得想要的结果。
|








- 上一条: 大规模即时云渲染技术,追求体验与成本的最佳均衡 2023-02-16
- 下一条: 利用DUCC配置平台实现一个动态化线程池 2023-02-16
- ICDE 2022|Apache ShardingSphere:一个功能全面和可插拔的数据分片平台 2022-04-01
- ShardingSphere 5.0.0-beta 重要特性介绍 2021-06-24
- 国际化多版本环境如何用 Zadig + Migrate 统一数据和代码变更 2022-12-26
- ShardingSphere 分片利器 AutoTable:为用户带来「管家式」分片配置体验 2021-09-15
- Apache ShardingSphere 首篇论文被 ICDE 收录,全球数据库发展迎来新局面 2022-03-29


