飞桨框架v2.4 API新升级!全面支持稀疏计算、图学习、语音处理等任务
大家好,今日带来的是有关于飞桨框架v2.4 AP升级的内容~快来看看是不是你所期待的新内容吧!也欢迎大家分享自己的看法哦。
2022年11月,飞桨框架2.4版本发布。相比飞桨框架2.3版本,飞桨框架v2.4增加了167个功能性API,新增稀疏计算(paddle.sparse)、图学习(paddle.geometric)和语音处理(paddle.audio)等更多领域API,同时也进一步完善了loss计算、张量计算、分布式和视觉变换等类别的API。下面我们将为大家详细介绍每一类新增API及其应用场景示例,方便大家快速了解和上手使用哦~
全面支持主流模型稀疏化训练及推理
当前越来越多的场景有稀疏计算的需求,例如3D点云图像处理和NLP中的稀疏Attention等。神经网络的稀疏化可以提高网络的性能,减少计算量及内存/显存的占用,已成为深度学习的研究热门之一。飞桨v2.4新增了如下稀疏类API,支持主流稀疏模型的训练和推理,并支持多种稀疏Tensor格式及稀疏Tensor与稠密Tensor的混合计算,同时其名称和使用方式与常规稠密Tensor的API保持一致,方便记忆且容易上手。
稀疏基础计算API:
-
一元计算: paddle.sparse.sin/sinh/tan/tanh/expm1/log1p/pow/square/sqrt/abs/cast/neg...
-
二元计算: paddle.sparse.add/substract/multiply/divide...
-
矩阵和向量计算: paddle.sparse.matmul/masked_matmul/addmm/mv...
-
数据变形: paddle.sparse.transpose/reshape...
稀疏组网API:
-
网络层: paddle.sparse.nn.Conv3D/SubmConv3D/MaxPool3D/BatchNorm...
-
激活层: paddle.sparse.nn.ReLU/ReLU6/LeakyReLU/Softmax...
覆盖稀疏计算主流应用场景
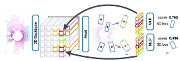
3D点云目标检测
CenterPoint是一种物体检测器,以点云作为输入,将三维物体在Bird-View下的中心点作为关键点,基于关键点检测的方式回归物体的尺寸、方向和速度。

飞桨框架v2.4完整提供了这类模型需要的稀疏SubmanifoldConv3D/Conv3D、稀疏BatchNorm和稀疏ReLU等API。模型的训练评估、动转静及推理的各项功能均已完全实现,欢迎试用。实测比业界同类竞品提速4%,训练精度提升0.2%。
- CenterPoint模型介绍
https://github.com/PaddlePaddle/Paddle3D/tree/release/1.0/docs/models/centerpoint
Sparse Transformer
稀疏Transformer与经典的稠密Transformer相比,能支持更长的输入序列,得到更好的网络性能。
稀疏Attention的核心计算逻辑为:

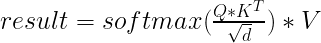
飞桨框架v2.4提供稀疏矩阵乘、稀疏softmax等运算,可完整支持SparseTransformer的运算。在高稀疏度场景下,相比使用DenseTensor提速105.75%,相比同类产品稀疏计算提速4.01%~58.55%,极致节省显存并提升性能。

支持多种稀疏Tensor格式及稀疏Tensor与稠密Tensor的混合计算
飞桨API支持最常使用的稀疏数据COO和CSR格式。COO为稀疏数据坐标格式,CSR为压缩行信息格式。不同格式的稀疏数据使用场景不同,其中SparseConv3D更适合处理COO格式的数据,SparseTransformer中有较多取整行的操作,更适合处理CSR格式的数据,能更好降低计算复杂度。虽然这些API有不同的格式倾向,但是飞桨稀疏API在设计时,每个都尽可能支持多种稀疏格式,这样在不同模型场景下处理不同的数据格式时都可以使用相同的API,不用修改代码,更灵活且更能极致提升性能。
以ReLU激活函数为例,其支持处理不同的稀疏Tensor:
# 稀疏COO Tensor
coo = paddle.sparse.sparse_coo_tensor(
indices = [[0, 1, 2],
[1, 2, 0]],
values = [1., 2., 3.],
shape = [3, 3])
out = paddle.sparse.nn.functional.relu(coo)
# 稀疏CSR Tensor
csr = paddle.sparse.sparse_csr_tensor(
crows = [0, 1, 2, 3],
cols = [1, 2, 0],
values = [1., 2., 3.],
shape = [3, 3])
out = paddle.sparse.nn.functional.relu(csr)
除了支持不同的稀疏格式外,对于二元计算及矩阵向量计算等API,还支持多种稀疏格式和常规的稠密格式(Dense Tessor)的混合计算,网络可以部分使用传统组网,部分使用稀疏,更方便已有模型的优化:
# COO与Dense矩阵乘,返回稠密Tensor
coo = paddle.sparse.sparse_coo_tensor(
indices = [[0, 1, 2],
[1, 2, 0]],
values = [1., 2., 3.],
shape = [3, 3])
dense = paddle.rand([3, 2])
out = paddle.sparse.matmul(coo, dense)
# CSR与Dense矩阵乘,返回稠密Tensor
csr = paddle.sparse.sparse_csr_tensor(
crows = [0, 1, 2, 3],
cols = [1, 2, 0],
values = [1., 2., 3.],
shape = [3, 3])
dense = paddle.rand([3, 2])
out = paddle.sparse.matmul(csr, dense)
# Dense与Dense矩阵乘,返回稀疏Tensor
x = paddle.rand([3, 5])
y = paddle.rand([5, 4])
mask = paddle.sparse.sparse_csr_tensor(
crows = [0, 2, 3, 5],
cols = [1, 3, 2, 0, 1],
values= [1., 2., 3., 4., 5.],
shape = [3, 4])
out = paddle.sparse.masked_matmul(x, y, mask)
名称和使用方式与常规稠密Tensor的API保持一致,方便记忆且容易上手
一般模型中使用的API都是处理稠密数据(Dense Tensor)的API。飞桨SparseAPI在设计之初就考虑尽可能降低理解成本,与常规处理稠密数据(Dense Tensor)的API保持风格一致,方便用户快速上手。
以模型中一段ResNet稀疏网络的代码为例:
import paddle
from paddle import sparse
from paddle.sparse import nn
class SparseBasicBlock(paddle.nn.Layer):
def __init__(
self,
in_channels,
out_channels,
stride=1,
downsample=None,
):
super(SparseBasicBlock, self).__init__()
self.conv1 = nn.SubmConv3D(
in_channels,
out_channels,
kernel_size=3,
stride=stride,
padding=1)
self.bn1 = nn.BatchNorm(out_channels, epsilon=1e-3, momentum=0.01)
self.relu = nn.ReLU()
self.conv2 = nn.SubmConv3D(
out_channels,
out_channels,
kernel_size=3,
stride=stride,
padding=1)
self.bn2 = nn.BatchNorm(out_channels, epsilon=1e-3, momentum=0.01)
self.downsample = downsample
def forward(self, x):
identity = x
out = self.conv1(x)
out = self.bn1(out)
out = self.relu(out)
out = self.conv2(out)
out = self.bn2(out)
if self.downsample is not None:
identity = self.downsample(x)
out = sparse.add(out, identity)
out = self.relu(out)
return out
可以看到,ResNet稀疏网络的代码和常规ResNet网络代码几乎没有差别,只需要通过paddle.sparse.*替代paddle.*即可,源于飞桨Sparse系列API在整体使用上与Dense系列API高度一致。如果能够增加import路径替换,甚至原网络代码都无需改动。例如通过frompaddle.sparseimportnn,则可保持与原来的nn.*写法完全一致,更易于上手。
新增图学习类API,支持高效图学习计算
近几年,图学习相关研究发展迅速,在自然语言处理、计算机视觉、推荐系统、生物化学等领域具有较为广泛的应用和发展。图学习逐渐成为机器学习领域的关键技术,本次飞桨框架v2.4新增paddle.geometric图学习类API,提供更好的图学习建模和高效图学习计算体验。
高效图消息传递
现有的大多数图学习框架在进行图模型设计时,通常采用图消息传递机制的经典范式。飞桨框架v2.4新增图学习消息传递API,支持高效图消息传递。其中,新增的send_u_recv、send_ue_recv、send_uv共计3个API,通过实现原子级别的消息发送与接收,大大减少了冗余的中间显存变量占用,从而带来显著的显存收益。在稠密图场景下,GCN、GAT等经典图神经网络模型可节省50%+的显存,并可进一步提升训练速度约20%。各个send_recv系列API支持sum、mean、max、min共计4个消息聚合方式,在节点特征与边特征交互时则支持add、sub、mul、div共计4种计算方式。使用方式示例如下:
import paddle
x = paddle.to_tensor([[0, 2, 3], [1, 4, 5], [2, 6, 7]], dtype="float32")
y = paddle.to_tensor([1, 1, 1, 1], dtype="float32")
indexes = paddle.to_tensor([[0, 1], [1, 2], [2, 1], [0, 0]], dtype="int32")
src_index, dst_index = indexes[:, 0], indexes[:, 1]
out = paddle.geometric.send_ue_recv(x, y, src_index, dst_index, message_op="add", reduce_op="sum")
高性能图采样
图采样步骤对于图采样模型特别是在大图场景下是非常有必要的,但同时也是图模型训练的性能瓶颈。本次新增了高性能图采样API,支持高并发图采样,加快图采样模型采样和训练效率,经典图模型Graphsage的采样速度可提升32~142倍,训练速度可提升12~57倍。除了支持纯GPU采样和CPU采样之外,还可以支持借助UVA(Unified Virtual Addressing,统一虚拟寻址)技术,将图结构放置在内存中进行GPU采样,该实现方式在大图场景下非常有效。简单示例如下:
import paddle
from paddle.fluid import core
row = np.array([3, 7, 0, 9, 1, 4, 2, 9, 3, 9, 1, 9, 7])
colptr = np.array([0, 2, 4, 5, 6, 7, 9, 11, 11, 13, 13])
row = core.eager.to_uva_tensor(row)
colptr = core.eager.to_uva_tensor(colptr)
nodes = paddle.to_tensor([0, 8, 1, 2])
sample_size = 2
# 邻居采样API的输入要求图结构信息为CSC格式
neighbors, neighbor_count = paddle.geometric.sample_neighbors(row, colptr, nodes, sample_size=sample_size)
# 生成重编号后的边
reindex_src, reindex_dst, out_nodes = paddle.geometric.reindex_graph(nodes, neighbors, neighbor_count)
新增语音领域类API
近几年,智能语音领域快速迅速,深度学习领域产生了很多语音训练处理基础能力的需求。本次飞桨框架v2.4新增paddle.audio类API提供了语音基础处理能力,提升了语音建模和学习便捷性。
高效的特征提取模块
特征提取模块是深度学习语音领域最基础的模块,特别在大规模数据训练和推理过程中,其速度为一个性能瓶颈。本次新增MFCC、Spectrogram、LogMelSpectrogram等特征提取API,支持GPU计算,相比CPU实现处理性能提升15倍以上,可大幅提升语音模型训练GPU利用率,达到快速训练和推理的效果。使用示例如下:
import paddle
from paddle.audio.features import LogMelSpectrogram
#设置音频相关参数
sample_rate = 16000
wav_duration = 0.5
num_channels = 1
num_frames = sample_rate * wav_duration
wav_data = paddle.linspace(-1.0, 1.0, num_frames) * 0.1
waveform = wav_data.tile([num_channels, 1])
#设置特征提起器相关参数
feature_extractor = LogMelSpectrogram(sr=sample_rate, n_fft=512, window = 'hann', power = 1.0)
feats = feature_extractor(waveform)
音频处理基础模块
深度学习语音领域,除了传统的经典模型外,还有很多语音前端处理的实验需要进行,定制化语音特征的需求应运而生。本次新增窗函数、离散余弦变换等特征提取基础API,方便用户自定义语音特征提取,方便完成定制化需求。使用示例如下:
import paddle
#cosine窗函数示例
n_fft = 512
cosine_window = paddle.audio.functional.get_window('cosine', n_fft)
#高斯窗函数
std = 7
gaussian_window = paddle.audio.functional.get_window(('gaussian',std), n_fft)
#离散余弦变换示例
n_mfcc = 23
n_mels = 257
dct = paddle.audio.functional.create_dct(n_mfcc, n_mels)
语音IO模块
对各种语音数据进行读取是音频处理的基础。现实场景中语音的编码格式各式各样,所以需要IO模块灵活地支持多种格式。飞桨框架v2.4新增语音IO模块,提供2种音频I/Obackend,支持6种编解码,便捷地实现语音数据的加载。使用示例如下:
import os
import paddle
#设置相关参数,生成示例音频
sample_rate = 16000
wav_duration = 0.5
num_channels = 1
num_frames = sample_rate * wav_duration
wav_data = paddle.linspace(-1.0, 1.0, num_frames) * 0.1
waveform = wav_data.tile([num_channels, 1])
base_dir = os.getcwd()
filepath = os.path.join(base_dir, "test.wav")
#保存和提取音频信息
paddle.audio.save(filepath, waveform, sample_rate)
wav_info = paddle.audio.info(filepath)
#wav_info中会有sample_rate, num_frames, num_channels等信息
语音分类数据集
在训练深度学习语音模型的时候,方便地下载处理数据集会为模型训练带来便捷。飞桨框架v2.4新增TESS、ESC50语音分类数据集。用户不必进行复杂的预处理,可以方便地启动训练流程,便捷地完成训练。用户也可以依照此代码,方便定制自己的数据集。使用示例如下:
import paddle
mode = 'dev'
esc50_dataset = paddle.audio.datasets.ESC50(mode=mode,
feat_type='raw')
for idx in range(5):
audio, label = esc50_dataset[idx]
# do something with audio, label
print(audio.shape, label)
# [audio_data_length] , label_id
esc50_dataset = paddle.audio.datasets.ESC50(mode=mode,
feat_type='mfcc',
n_mfcc=40)
for idx in range(5):
audio, label = esc50_dataset[idx]
# do something with mfcc feature, label
print(audio.shape, label)
# [feature_dim, length] , label_id
其它新增的API
除了以上描述的几类新增API,飞桨框架v2.4还对已有的一些API类别进行了扩充。
loss计算API
为了更方便地支持各种组网的loss计算需求,飞桨框架v2.4扩充了多个loss计算的API,包括:
-
paddle.nn.functional.cosine_embedding_loss根据label类型,计算2个输入之间的CosineEmbedding损失。
-
paddle.nn.functional.soft_margin_loss计算输入和label间的二分类softmargin损失。
-
paddle.nn.functional.multi_label_soft_margin_loss计算输入和label间的多分类最大熵损失。
-
paddle.nn.functional.triplet_margin_loss和**paddle.nn.functional.triplet_margin_with_distance_loss**计算输入与正样本和负样本之间的相对相似性,后者可自定义距离计算函数。
张量计算API
飞桨框架2.3之前的版本实现了很多基础的张量计算API,飞桨框架2.4版本基于这些基础API,通过组合的方式扩充了张量计算API,方便用户直接使用,包括:
-
新增**paddle.sgn**取复数的单位值和实数的符号。
-
新增**paddle.count_nonzero**沿给定的轴统计输入张量中非零元素的个数。
-
新增**paddle.take**将输入张量视为一维,返回指定索引上的元素集合。
-
新增**paddle.bucketize**根据给定的一维桶划分,得到输入张量对应的桶索引。
-
新增**paddle.triu_indices和paddle.tril_indices**分别取二维张量(矩阵)中上/下三角矩阵元素的行列坐标。
-
新增**paddle.heaviside**计算赫维赛德阶跃函数。
-
新增**paddle.nanmedian和paddle.nanquantile**忽略张量中的nan值,分别计算出中位数和分位数值。
分布式API
新增10个分布式通信API,如paddle.distributed.communication.stream.all_gather等,支持在主计算流上做通信,降低了在流切换、事件等待时的性能开销,能够使分布式GPT3模型训练提速11.35%。

视觉变换API
基于飞桨基础API,扩充了paddle.vision.transforms中视觉变换API,包括:
-
paddle.vision.transforms.affine和**paddle.vision.transforms.RandomAffine**对图像进行仿射变换,后者使用随机产生的仿射变换矩阵参数。
-
paddle.vision.transforms.erase和**paddle.vision.transforms.RandomErasing**使用给定的值擦除输入图像中的像素,前者是选定区域,后者是随机区域。
-
paddle.vision.transforms.perspective和**paddle.vision.transforms.RandomPerspective**对图像进行透视变换,前者是选定区域,后者是随机区域,两者都可以选择插值方法。
除了上面的介绍外,飞桨框架v2.4还扩充了一些组网类(如paddle.nn.ChannelShuffle)、辅助类(如paddle.iinfo)等API,详细列表可点击下方链接参考Release Note。
- Release Note地址
https://github.com/PaddlePaddle/Paddle/releases
结语
飞桨框架的建设除了来自百度的工程师外,还有一批热爱飞桨、热爱开源的开发者,他们正在用自己的方式参与飞桨框架的建设,与飞桨共同成长。在飞桨框架v2.4中,有约三分之一的新增API由社区开发者贡献,飞桨的繁荣离不开广大开发者的使用与支持。
飞桨框架v2.4逐步形成了成熟的API开发范式,框架的开发难度持续降低。配合官方提供的标准开发环境,飞桨社区开发者可以更加顺畅地完成飞桨API开发与贡献。具体体现在:
-
简化API开发步骤:飞桨框架v2.4完成了基础框架算子体系重构,构造高可复用的PHI算子库(Paddle HIgh reusability operator library),支持基于已有的算子内核以及Kernel Primitives API组合实现新的算子,支持插件式接入新硬件或者新加速库。PHI算子库的成熟,提升了飞桨API的开发效率,并形成了通用的API开发流程,使得开发者可以更加简洁流畅地参与飞桨API的开发与贡献。
-
发布标准API贡献指南:飞桨框架v2.4形成了标准的API贡献指南,包括贡献流程与操作指南、API设计文档模板、API代码模板、API文档写作规范,为飞桨社区开发者提供清晰的文档指引与辅助,使得开发者可以快速上手。
-
提供标准开发环境:飞桨AIStudio平台推出标准开发环境,为开发者提供飞桨镜像环境、在线IDE与专属GPU算力,登录即可开发调试,免去环境配置与算力限制,随时随地参与飞桨框架的开发与贡献。
飞桨框架v2.4提供了更加丰富的API体系,不仅更好地支持深度学习稀疏计算、图学习、语音领域的快速迭代和创新,而且不断扩展对3D点云、Sparse Transformer等场景应用的支持,同时也不断优化飞桨API的使用体验,更好地支持业界论文中模型的实现,加速创新,让基于深度学习的应用开发更简单!
|








- 上一条: 文心ERNIE 3.0 Tiny新升级!端侧压缩部署“小” “快” “灵”! 2023-02-15
- 下一条: 如何在 NGINX 中安全地分发 SSL 私钥 2023-02-15
- 飞桨联邦学习框架PaddleFL新升级,实现纯两方安全计算协议 2021-10-20
- Rancher v2.6.4 社区版新特性解读 2022-04-06
- 大赛报名|来自飞桨黑客松的邀请函 2021-09-27
- 机器人自主学习新进展,百度飞桨发布四足机器人控制强化学习新算法 2021-10-08
- 百度智能云飞桨一体机全新发布,云智一体破解AI落地“最后一公里”难题 2021-09-18