数据科学在量化金融中的应用:指数预测(下)
回顾《数据科学在量化金融中的应用:指数预测(上)》,我们对股票指数数据进行了收集、探索性分析和预处理。接下来,本篇会重点介绍特征工程、模型选择和训练、模型评估和模型预测的详细过程,并对预测结果进行分析总结。

特征工程
在正式建模之前,我们需要对数据再进行一些高级处理 — 特征工程,从而保证每个变量在模型训练中的公平性。根据现有数据的特点,我们执行的特征工程流程大致有以下三个步骤:
- 处理缺失值并提取所需变量
- 数据标准化
- 处理分类变量
1. 处理缺失值并提取所需变量
首先,我们需要剔除包含缺失值的行,并只保留需要的变量 x_input,为下一步特征工程做准备。
x_input = (df_model.dropna()[['Year','Month','Day','Weekday','seasonality','sign_t_1','t_1_PricePctDelta','t_2_PricePctDelta','t_1_VolumeDelta']].reset_index(drop=True))
x_input.head(10)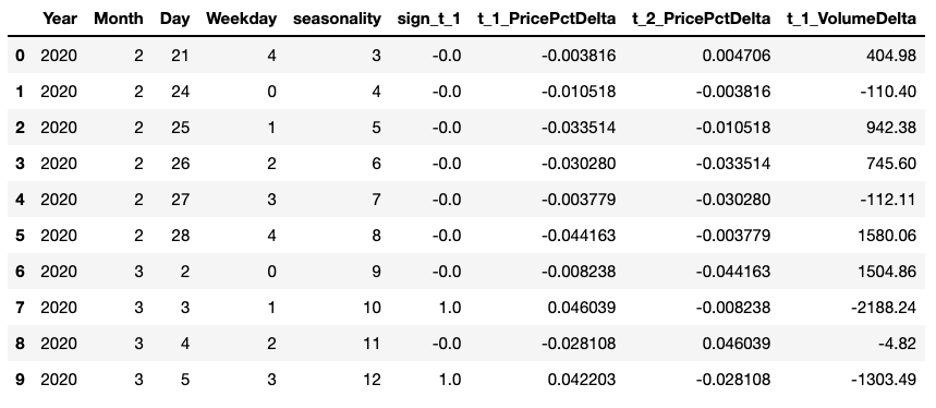
然后,再将目标预测列 y 从数据中提取出来。
y = df_model.dropna().reset_index(drop=True)['AdjPricePctDelta']2. 数据标准化
由于价格百分比差与交易量差在数值上有很大差距,如果不标准化数据,可能导致模型对某一个变量有倾向性。为了平衡各个变量对于模型的影响,我们需要调整除分类变量以外的数据,使它们的数值大小相对近似。Python 提供了多种数据标准化的工具,其中 sklearn 的 StandardScaler 模块比较常用。数据标准化的方法有多种,我们选择的是基于均值和标准差的标准化算法。这里,大家可以根据对数据特性的理解和模型类型的不同来决定使用哪种算法。比如对于树形模型来说,标准化不是必要步骤。
scaler = StandardScaler()
x = x_input.copy()
x[['t_1_PricePctDelta','t_2_PricePctDelta','t_1_VolumeDelta']]=scaler.fit_transform(x[['t_1_PricePctDelta','t_2_PricePctDelta','t_1_VolumeDelta']])3. 处理分类变量
最常见的分类变量处理方法之一是 one-hot encoding。对于高基数的分类变量,经过编码处理后,变量数量增加,大家可以考虑通过降维或更高阶的算法来降低计算压力。
x_mod = pd.get_dummies(data=x, columns=['Year','Month','Day','Weekday','seasonality'])
x_mod.columns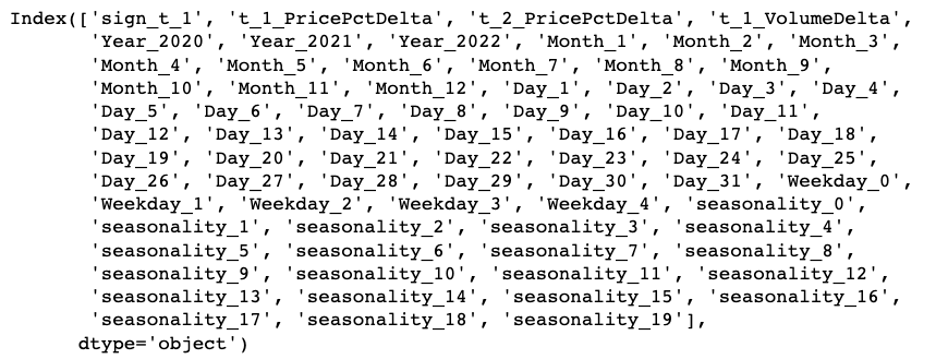
x_mod.shape
至此,我们完成了特征工程的全部步骤,处理后的数据就可以进入模型训练环节了。
模型选择和训练
首先,我们需要拆分训练集和测试集。对于不需要考虑记录顺序的数据,可以随机选取一部分数据作为训练集,剩下的部分作为测试集。而对于时间序列数据来说,记录之间的顺序是需要考虑的,比如我们想要预测2月份的价格变动,那么模型就不能接触2月份以后的价格,以免数据泄露。由于股票指数数据为时间序列,我们将时间序列前75%的数据设为训练数据,后25%的数据设为测试数据。
· 模型选择
在模型选择阶段,我们会根据数据的特点,初步确定模型方向,并选择合适的模型评估指标。
因为变量中包含历史价格和交易量,且这些变量的相关性过高(high correlation),以线性模型为基础的各类回归模型并不适合目标数据。因此,我们模型尝试的重心将放在集成方法(ensemble method),以这类模型为主。
在训练过程中,我们需要酌情考虑,选择合适的指标来评估模型表现。对于回归预测模型而言,比较流行的选择是 MSE(Mean Squared Error)。而对于股票指数数据来说,由于其时间序列的特性,我们在 RMSE 的基础上又选择了 MAPE(Mean Absolute Percentage Error),一种相对度量,以百分比为单位。比起传统的 MSE,它不受数据大小的影响,数值保持在0-100之间。因此,我们将 MAPE 作为主要的模型评估指标。
· 模型训练
在模型训练阶段,所有的候选模型将以默认参数进行训练,我们根据 MAPE 的值来判断最适合进一步细节训练的模型类型。我们尝试了包括线性回归、随机森林等多种模型算法,并将经过训练集训练的各模型在测试集中的模型表现以字典的形式打印返回。
模型评估
通过运行以下方程,我们可以根据预测差值(MAPE)的大小对各模型的表现进行排列。大家也可以探索更多种不同的模型,根据评估指标的高低择优选取模型做后续微调。
trail_result = ensemble_method_reg_trails(x_train, y_train, x_test, y_test)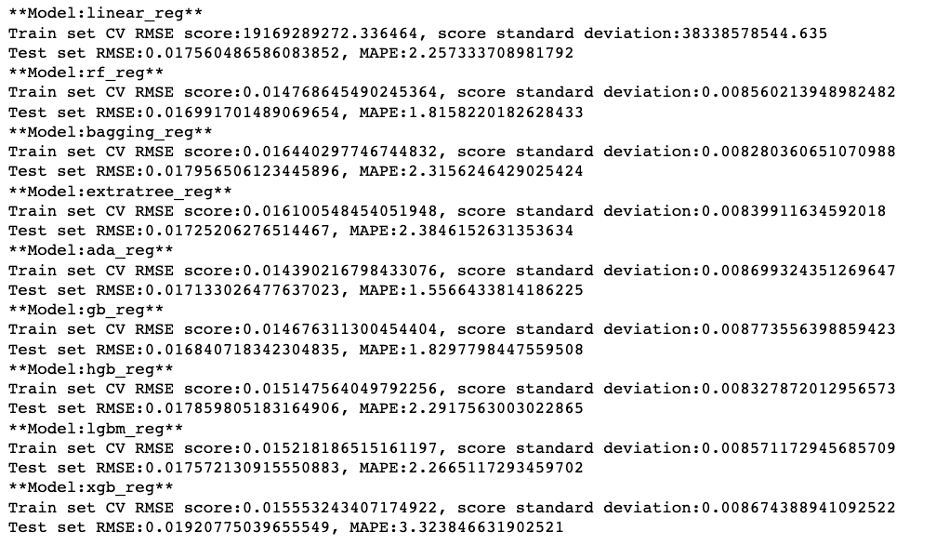
pd.DataFrame(trail_result).sort_values('model_test_mape', ascending=True)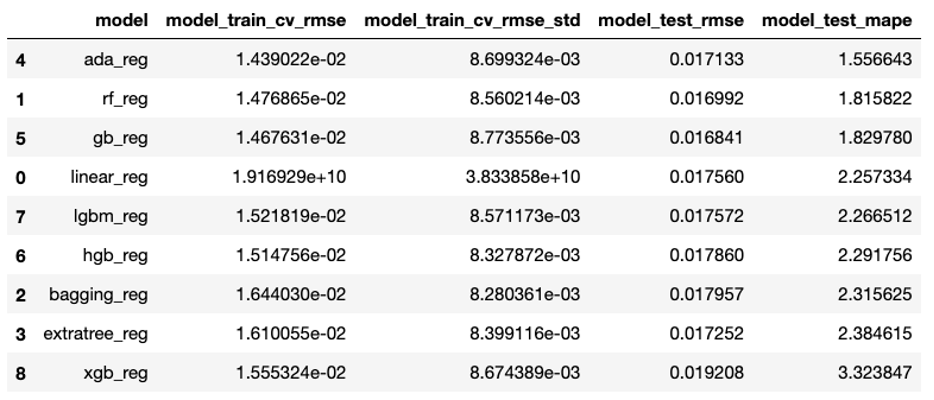
由此可以看出,在众多模型类型中,Ada Boost 在训练和测试集上的效果最好,MAPE 值最小,所以我们选择 Ada Boost 进行下一步的细节调优。与此同时,我们发现 random forest 和 gradient boosting 也有不错的预测表现。注意,Ada Boost 虽然在训练集上准确度高,但是模型的表现不是很稳定。
接下来的模型微调分为两个步骤:
- 使用 RandomizedSearchCV 寻找最佳参数的大致范围
- 使用 GridSearchCV 寻找更精确的参数
影响 Ada Boost 性能的参数大致如下:
- n_estimators
- base_estimator
- learning_rate
注意,RandomizedSearchCV 和 GridSearchCV 都会使用交叉验证来评估各个模型的表现。在前文中我们提到,时间序列是需要考虑顺序的。对于已经经过转换来适应机器学习模型的时间序列,每条记录都有其相对应的时间信息,训练集中也没有测试集的信息。训练集中记录的顺序可以按照特定的交叉验证顺序排列(较为复杂),也可以被打乱。这里,我们认为训练集数据被打乱不影响模型训练。
base_estimator 是 ada boost 提升算法的基础,我们需要提前建立一个 base_estimator 的列表。
l_base_estimator = []
for i in range(1,16):
base = DecisionTreeRegressor(max_depth=i, random_state=42)
l_base_estimator.append(base)
l_base_estimator += [LinearSVR(random_state=42,epsilon=0.01,C=100)]1. 使用 RandomizedSearchCV 寻找最佳参数的大致范围
使用 RandomSearchCV,随机尝试参数。这里,我们尝试了500种不同的参数组合。
randomized_search_grid = {'n_estimators':[10, 50, 100, 500, 1000, 5000],
'base_estimator':l_base_estimator,
'learning_rate':np.linspace(0.01,1)}search = RandomizedSearchCV(AdaBoostRegressor(random_state=42),
randomized_search_grid,
n_iter=500,
scoring='neg_mean_absolute_error',
n_jobs=-1,
cv=5,
random_state=42)
result = search.fit(x_train, y_train)可以看到,500种参数组合中表现最佳的是:
result.best_params_
result.best_score_
2. 使用 GridSearchCV 寻找更精确的参数
根据 Randomized Search 的结果,我们再使用 GridSearchCV 进行更深一步的微调:
- n_estimators: 1-50
- base_estimator: Decision Tree with max depth 9
- learning_rate: 0.7左右
search_grid = {'n_estimators':range(1,51),
'learning_rate':np.linspace(0.6,0.8,num=20)}
GridSearchCV 的结果如下:

根据 GridSearchCV 的结果,我们保留最佳模型,让其在整个训练集上训练,并在测试集上进行预测,对结果进行评估。
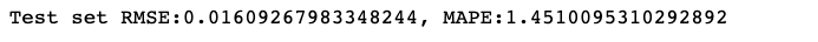
可以看到,结合训练集的交叉验证结果,最佳模型在测试集中的表现与模型选择和训练阶段的结果相比,准确度略有提升。最佳模型平衡了训练集和测试集表现,可以更有效地防止过拟合的情况出现。
在确定模型以后,因为之前的模型都只接触过训练集,为了预测未来的数据,我们需要将模型在所有数据上重新训练一遍,并以 pickle 文件的格式保存这个最佳模型。
best_reg.fit(x_mod, y)
该模型在全量数据的预测结果中MAPE值为:
m_forecast = best_reg.predict(x_mod)
mean_absolute_percentage_error(y, m_forecast)
模型预测
与传统的 ARIMA 模型不同,现有模型的每次预测都需要将预测信息重新整合,输入进模型后才能得到新的预测结果。输入数据的重新整合可以用以下方程进行开发,方便适应各种应用场景的需求。
def forecast_one_period(price_info_adj_data, ml_model, data_processor):
# Source data: Data acquired straight from source
last_record = price_info_adj_data.reset_index().iloc[-1,:]
next_day = last_record['Date'] + relativedelta(days=1)
next_day_t_1_PricePctDelta = last_record['AdjPricePctDelta']
next_day_t_2_PricePctDelta = last_record['t_1_PricePctDelta']
next_day_t_1_VolumeDelta = last_record['Volume_in_M'] - last_record['t_1_VolumeDelta']
if next_day_t_1_PricePctDelta > 0:
next_day_sign_t_1 = 1
else:
next_day_sign_t_1 = 0
# Value -99999 is a placeholder which won't be used in the following modeling process
next_day_input = (pd.DataFrame({'Date':[next_day],
'Volume_in_M':[-99999],
'AdjPricePctDelta':[-99999],
't_1_PricePctDelta':[next_day_t_1_PricePctDelta],
't_2_PricePctDelta':[next_day_t_2_PricePctDelta],
't-1volume': last_record['Volume_in_M'],
't-2volume': last_record['t-1volume'],
't_1_VolumeDelta':[next_day_t_1_VolumeDelta],
'sign_t_1':next_day_sign_t_1}).set_index('Date'))
# If forecast period is post Feb 15, 2020, input data starts from 2020-02-16,
# as our model is dedicated for market under Covid Impact.
# Another model could be used for pre-Covid market forecast.
if next_day > datetime.datetime(2020, 2, 15):
price_info_adj_data = price_info_adj_data[price_info_adj_data.index > datetime.datetime(2020, 2, 15)]
price_info_adj_data_next_day = pd.concat([price_info_adj_data, next_day_input])
# Add new record to original data for modeling preparation
input_modified = processor.data_modification(price_info_adj_data_next_day)
# Prep for modeling
x,y = data_processor.data_modeling_prep(input_modified)
next_day_x = x.iloc[-1:]
forecast_price_delta = ml_model.predict(next_day_x)
# Consolidate prediction results
forecast_df = {'Date':[next_day], 'price_pct_delta':[forecast_price_delta[0]], 'actual_pct_delta':[np.nan]}
return pd.DataFrame(forecast_df)我们读取之前保存的模型,对未来一个工作日的价格变动进行预测。输出的结果中,actual_pct_delta 是为未来价格发布后保存真实结果所预留的结构。

根据预测结果,我们认为2022年11月1日这天标普指数会有轻微的上升。
分析预测结果
根据近两年的数据走向,我们有了这样的预测结果:标普指数会有轻微的上升。但当我们查看2022年11月1日发布的实际数据时发现,指数在当天是下降的。这意味着外界的某种信息,可能是经济指标抑或是政策风向的改变,导致市场情绪有所变化。搜索相关新闻后,我们发现了以下信息:

“Stocks finished lower as data showing a solid US labor market bolstered speculation that Federal Reserve policy could remain aggressively tight even with the threat of a recession.”
在经济面临多重考验的同时,招聘市场职位数量上升的信息释出,导致投资者认为招聘市场表现稳健,美联储不会考虑放宽当下的经济政策;这种负面的展望在股票市场上得到了呈现,导致当日指数收盘价下降。
模型在实际应用中不仅仅充当着预测的工作,在本文的案例中,指数价格变动的预测更类似于一种 “标线”。通过模型学习历史数据,模型的结果代表着如果按照历史记录的信息,没有外部重大干扰的情况下,我们所期待的变动大致是怎样的,即当日实际发生的变动是“系统”层面的变动,还是需要深度挖掘的非“系统”因素所造成的变动。在模型的基础上,我们可以将这些结果举一反三,开发出各式各样的功能,让数据尽可能地发挥其价值。
总结
回顾上下两篇文章的全部内容,标普500股票指数的价格预测思路总结如下:
- 确定预测目标:反映北美股票市场的指数 — 标普500 ;
- 数据收集:从公共金融网站下载历史价格数据;
- 探索性数据分析:初步了解数据的特性,数据可视化,将时间序列信息以图像的形式呈现;
- 数据预处理:将时间转换为变量,更改价格数据,寻找周期和季节性,根据周期调整交易量数据;
- 数据工程:处理缺失值并提取所需变量,数据标准化,处理分类变量;
- 模型选择和训练:拆分训练集和测试集,确定模型方向和评估指标,尝试训练各种模型;
- 模型评估:根据指标选定最优模型,使用 RandomizedSearchCV 寻找最佳参数的大致范围,再使用 GridSearchCV 寻找更精确的参数;
- 模型预测:整合输入数据,预测未来一个工作日的价格变动;
- 分析预测结果:结合当日的实际情况,理解市场变动,发挥模型价值。
参考资料:
- Time series into supervised learning problem
- Tuning Ada Boost
- S&P 500 historical data
- Bloomberg News
- 阿布(2021)。《量化交易之路 用Python做股票量化分析》。机械工业出版社。
|








- 上一条: 数据科学在量化金融中的应用:指数预测(上) 2023-01-12
- 下一条: #HarmonyOS小课堂# 速览<HarmonyOS第一课> 课程精华第二期:应用程序框架 2023-01-13
- 数据科学在量化金融中的应用:指数预测(上) 2023-01-12
- 千亿级高并发MongoDB集群在某头部金融系统中的应用及性能优化实践(上) 2022-05-23
- “神算子”上线!EasyDL时序预测模型零门槛轻松上手 2021-11-10
- 码住!基于深度学习的时间序列预测方法总结 2022-06-05
- 火山引擎云原生大数据在金融行业的实践 2022-12-01


