以openGauss Connector下推为例剖析Connector下推机制

本次推文投稿:程一舰 中国人民大学硕士 中国光大银行总行信息科技部
1.下推是什么?
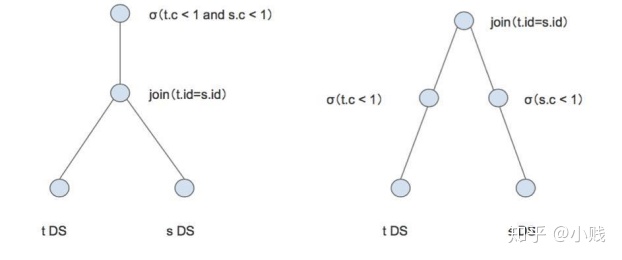
下推其实就是将查询中的谓词或算子尽可能地向查询计划树的叶子结点靠近,最理想的情况就是将谓词或算子下推至叶子结点,这样就意味着可以将它们推至数据源了,通过数据源的预处理,可以极大的减少引擎从数据源拉取的数据量,从而极大提高查询效率。最简单的如下图所示。之前也写过一篇sparksql下推的文章,有兴趣可以去看一下https://mp.weixin.qq.com/s/NgrRuKUaVi-pknVnHcK32g。
2openLooKeng引擎的Connector下推
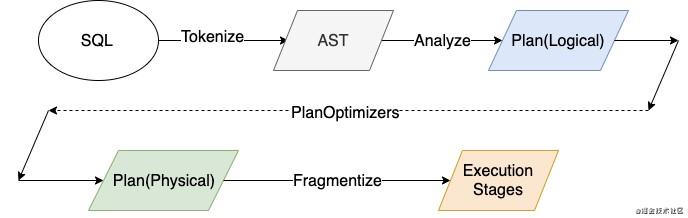
下面是一条SQL语句执行的各个环节,查询语句经过解析之后形成抽象语法树,然后经过Analyze生成逻辑计划,逻辑计划再通过一系列的优化规则来生成优化后的更高效的逻辑计划进而转成物理计划。而Connector下推就处于逻辑计划优化阶段的某一环节。
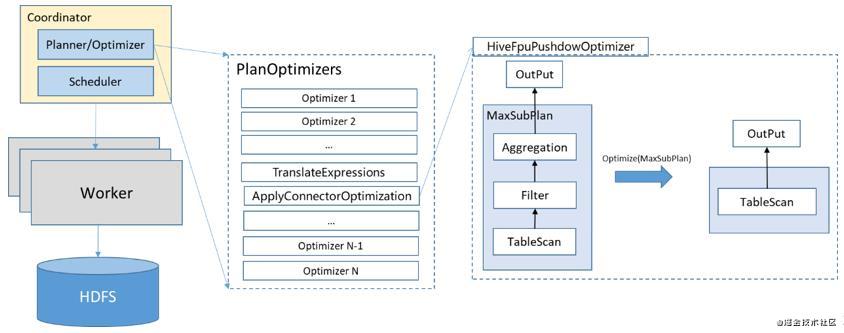
我们来看一下下面这张图,openLooKeng新下推框架的主要思想是把执行计划子树暴露给connector,让connector提供PlanOptimizers(基于visitor模式的)给执行优化引擎,这样可以让connector引入任意的优化。这张图展示了Connector下推在整个查询优化缓环节的位置,其实不难看出,真正触发这个过程的就是ApplyConnectorOptimization这条优化规则,它也仅仅是众多优化规则中的一条规则。只是这条规则会把关于该Connector相关的最大子查询计划(maxsubplan)推给Connector去优化,该Connector针对本数据源进行一系列的定制优化。
3openGauss Connector下推优化实践
上面说了这么多,到底怎么来具体实现一个Connector的下推优化呢,我们接下来以openGauss Connector为例。这个Connector顾名思义,就是用来连接GaussDB数据库的,它本身继承或复用了postgresql和basejdbc的一些类,所以在进行下推实现的时候,我们也可以继续去复用一些类。
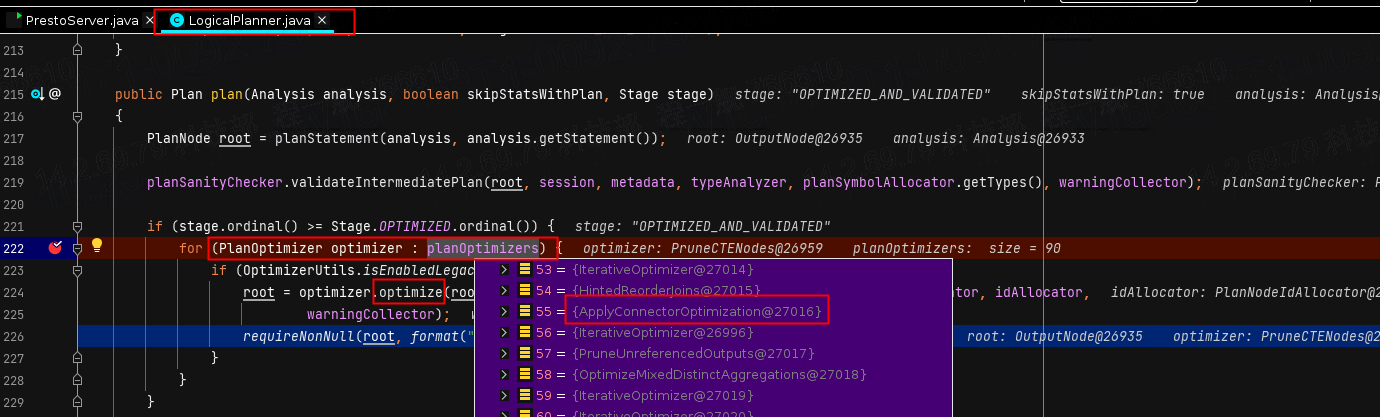
首先,我们从逻辑计划开始,LogicalPlanner类是对刚刚解析出来的抽象语法树(AST)进行逻辑计划生成的类,在生成逻辑计划的同时,他还会做一件很重要的事就是对逻辑计划进行优化,我们可以从222行看到,这里的planOptimizers包含了几十条优化规则,而我们上面提到的ApplyConnectorOptimization就在第55条规则中,当循环遍历到这条规则的时候,其实也就是Connector逻辑优化的开始了。
然后,就如上面我所介绍的,当遍历到ApplyConnectorOptimization规则的时候,就会调用对应的Connector 的 Optimizer,在这里我们可以清晰地看到,因为我查询的catalog是一个GaussDB表,所以这个Optimizer就是JdbcPlanOptimizer(按理说应该是opengaussPlanOptimizer,但是上面说到过,因为openGauss Connector很多功能都是复用了Jdbc,这里也不意外),这个优化器中包含的一个比较重要的成员变量就是queryGenerator,因为正是通过他来进行后续的sql语句的生成。
这里我们可以看到这个具体的Generator是opengaussQueryGenerator,为了方便,在具体实现这个类的时候,里面也是复用了BaseJdbcQueryGenerator类中的内容
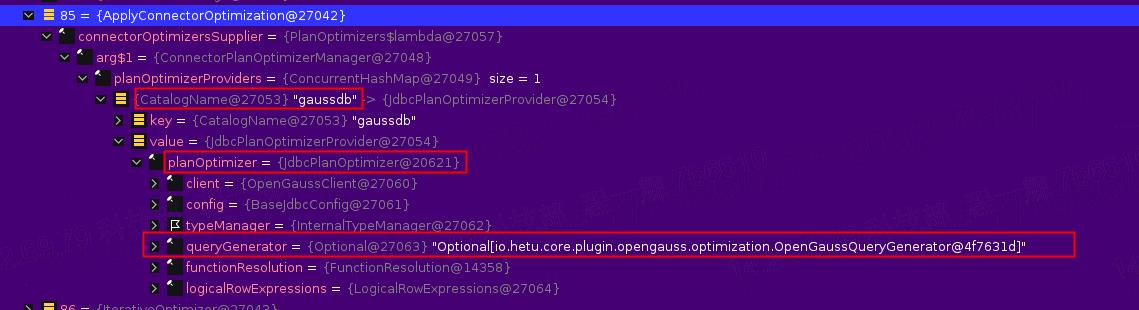
那接下来我们就看看JdbcPlanOptimizer做了哪些具体的优化。首先我们看到它会调用自己的optimize方法,来对推下来的maxSubPlan进行优化,具体的执行就通过调用accept方法来调用Visitor这个类来进行具体的节点遍历。
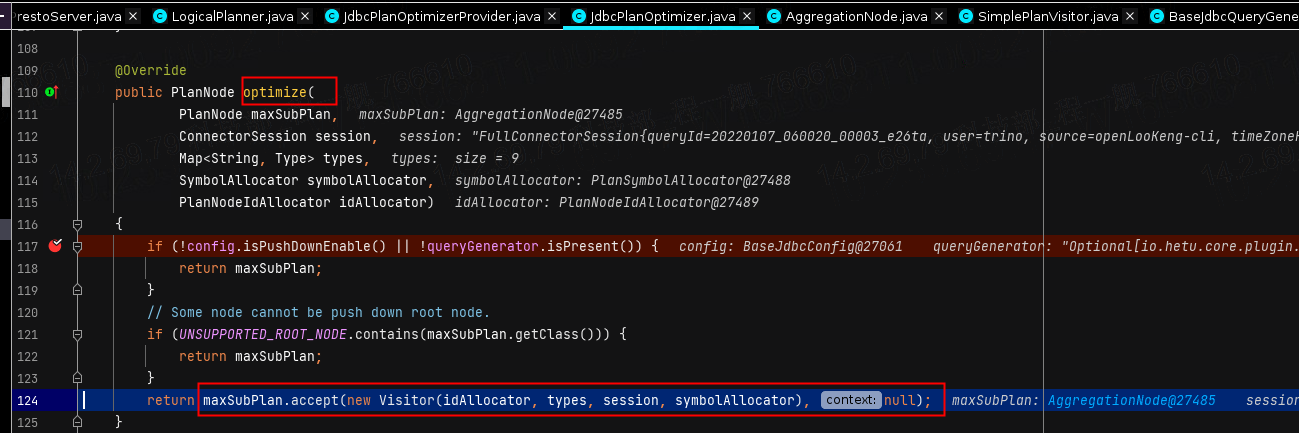
然后就是通过调用visitPlan来进行算子的转换,如下图就是主备对聚合算子AggregationNode进行相关操作。

tryCreatingNewScanNode会调用queryGenerator对象来进行算子的重写(其实就是把能推下去的通过重写SQL的方式把该算子加进去)。
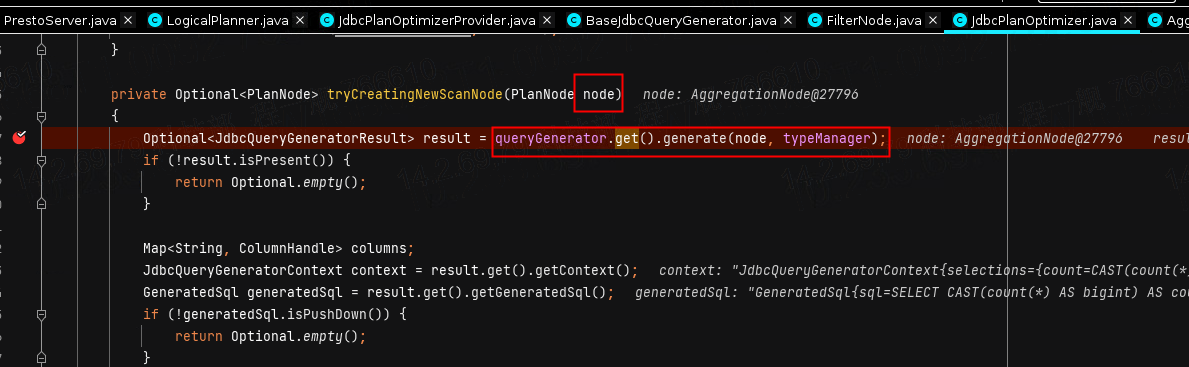
我们看到这里开始准备重写,就进入到了BaseJdbcQueryGenerator类中来了(其实是进入到了openGaussQueryGenerator类,只是我复用了BaseJdbc,所以最后实在这里来做的),这里是调用的visitAggregation方法,主要就是来进行聚合算子的提取工作,
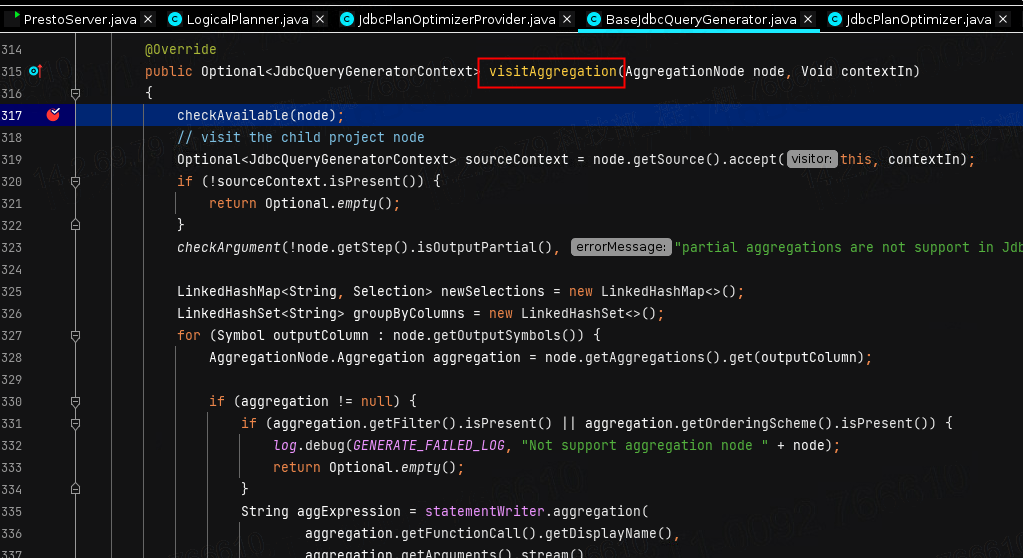
进一步,buildSql方法顾名思义,将提取出来的算子进行推到重写的SQL中,如下所示
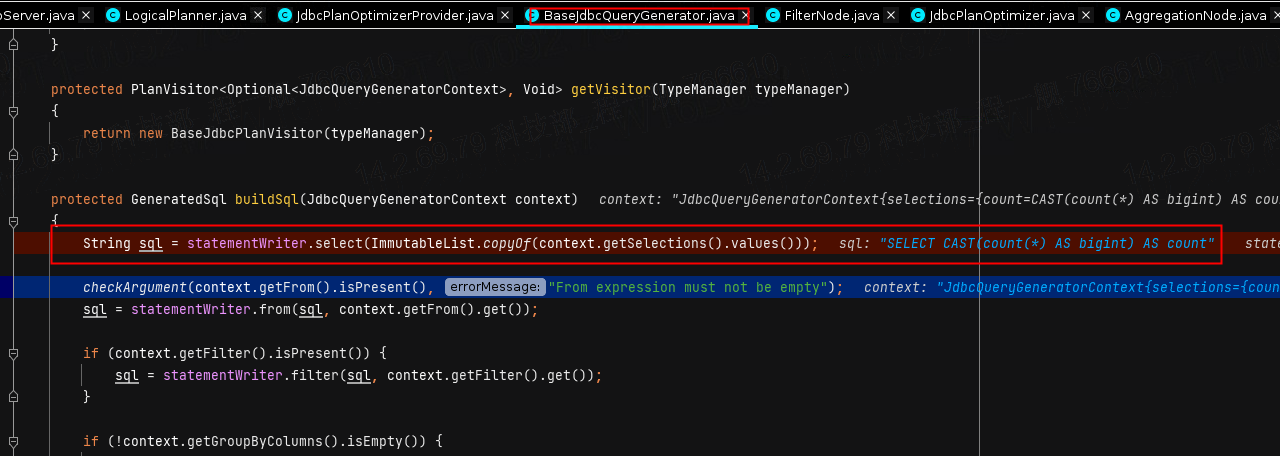
最后重写完成,又回到了JdbcPlanOptimizer进行下一步的操作。毕竟优化器只是将子计划进行重新优化,所以最后还是要返回一个PlanNode的,所以我们看到接下来我们在上面重写的sql会被用来进行封装,最后封装成了TableScanNode里被返回。

其实到了这里就已经完成了具体的opengauss Connector的下推了,但是我们如果跳出来,看看它在整个执行过程中的位置,回想一下前面我们提到的,这也仅仅是我们完成了ApplyConnectorOptimization这一条优化规则的任务,如果你忘了我再重新贴一下图。
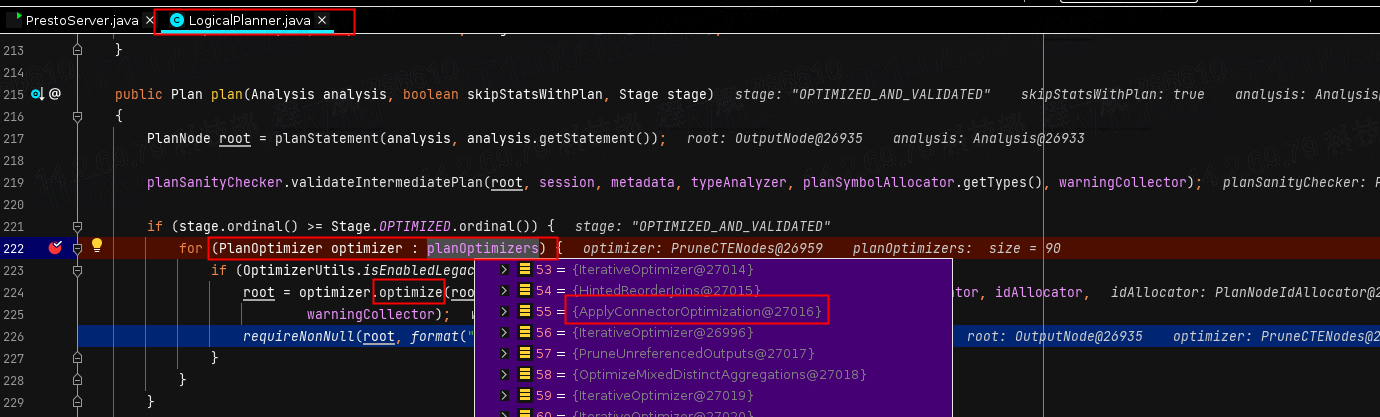
所以接下来,还会把我们刚刚返回的封装好的子查询计划继续应用其他规则。
再往后,引擎其实还会在全局的角度对整个查询进行一个重写,也就是在BaseJdbcClient这里所做的。
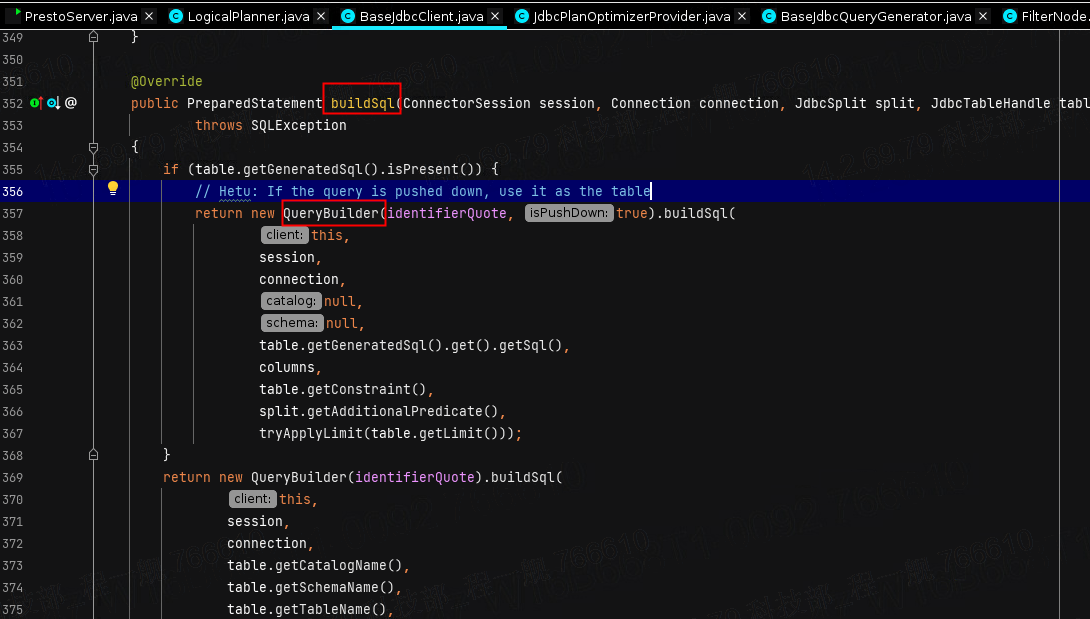
这里会通过QueryBuilder来重新梳理出一条sql语句,最终推给数据源。如下图所示,其实我们前面做的那么多,在全局看来只是一个table,别名为pushdown。
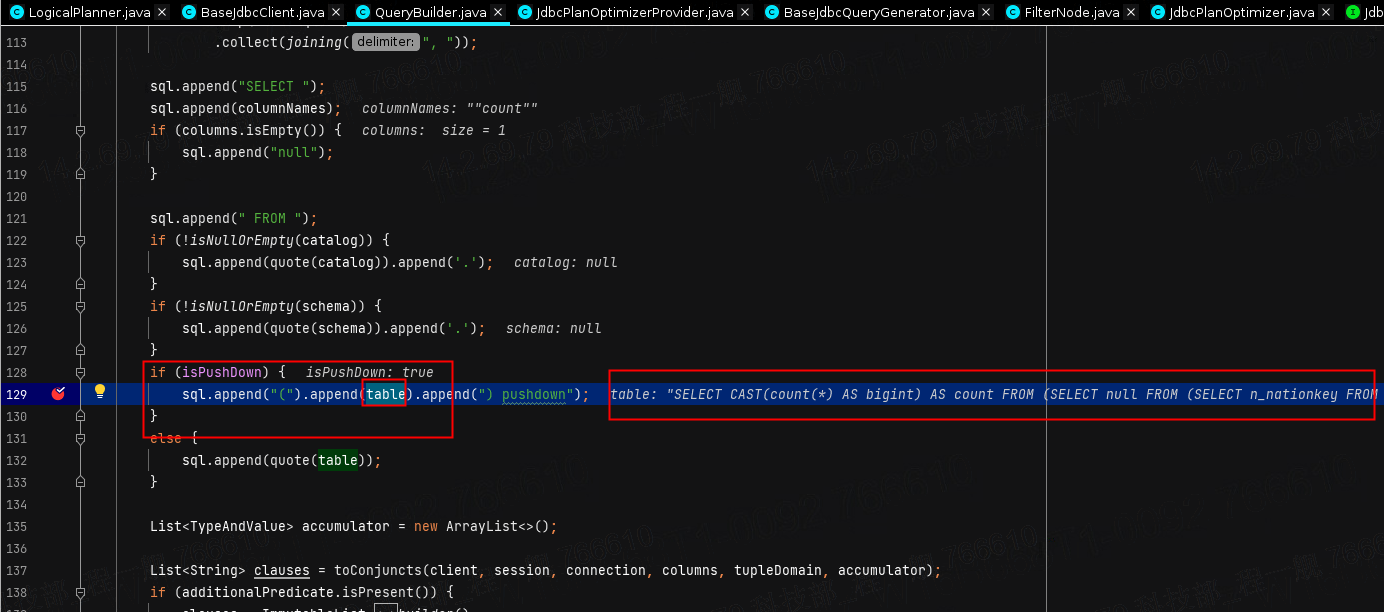
这里再次重写完的SQL,其实就是最终我们推给数据源执行的SQL了。
4优化效果
通过查看执行计划,我们来看(下推)优化与不优化的效果对比
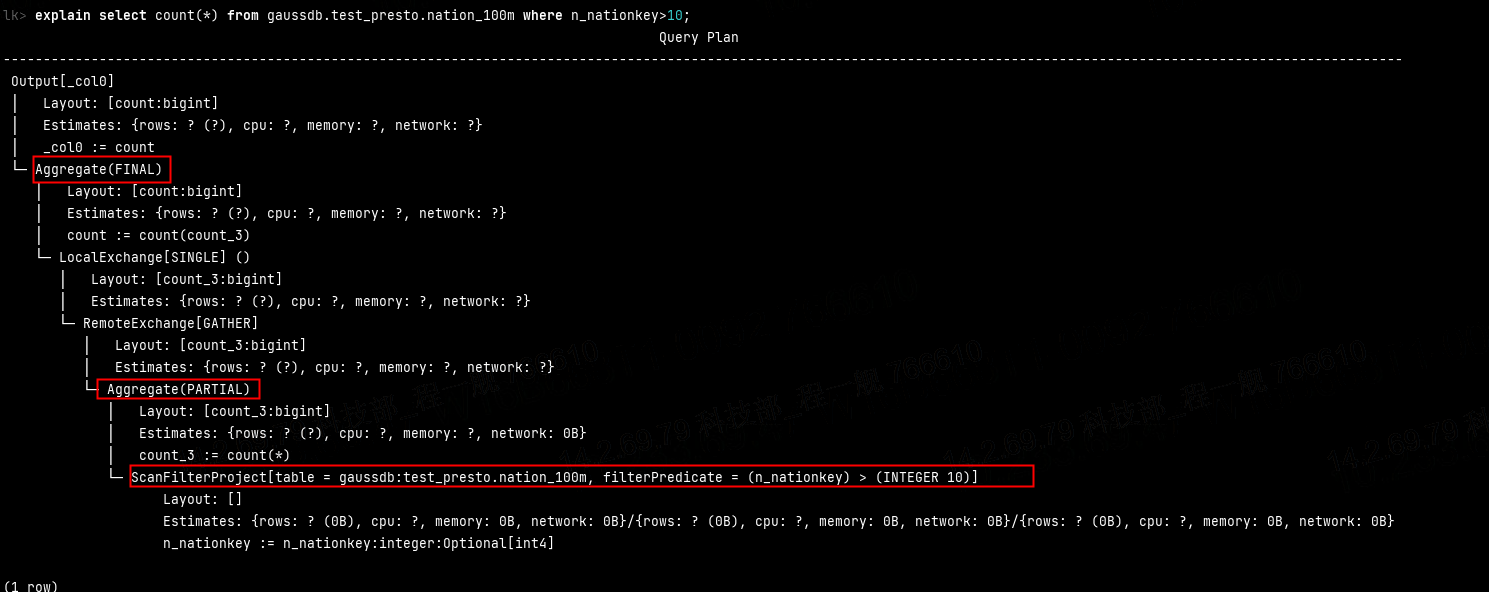

即使不标明,我相信你也应该能看出哪一个是进行优化的效果了。第一张图片,我们可以看到正常情况下会从数据源读取数据,然后进行过滤、聚合、shuffle再聚合,而第二张图片我们看到Connector直接将条件和聚合算子推给了数据源,最后只接收一个聚合结果,从而大大解放了Connector,减少了数据的传输等效率损耗,从而提高查询性能。
5openGauss Connector下推优化实践
通过本篇文章,我相信你已经大致对Connecor下推以及查询下推的原理有了一个比较形象的了解了,如果你想继续深入了解,可以再次按照这个思路去捋一捋源码,其他情况的话,相信这篇文章已经足够能够解答你的疑惑了。opengauss connector下推的PR我已经提到社区了https://gitee.com/openlookeng/hetu-core/pulls/1354,欢迎交流。
openLooKeng
如果您在使用openLooKeng过程中,有任何疑问与建议, 请在社区代码仓中提Issue,或加小助手微信(openLooKengoss)进入专属交流群
openLooKeng代码仓地址:
https://gitee.com/openlookeng
https://github.com/openlookeng
社区公众号|openLooKeng
社群小助手|openLooKengoss
|








- 上一条: 070]M] 7ySQL 主从复制数据不一致,怎么办? 2022-03-18
- 下一条: MySQL 主从复制数据不一致,怎么办? 2022-03-19
- 索引下推,yyds! 2022-01-24
- openGauss数据库源码解析系列文章——存储引擎源码解析(五) 2021-08-02
- Debezium的基本使用(以MySQL为例) 2022-08-22
- 记mysql-connector-java:8.0.28的bug排查,你可能也踩坑了 2022-06-21
- openGauss数据库源码解析系列文章—— 事务机制源码解析(二) 2021-08-10


