索引下推,yyds!
索引的问题,已经跟大家聊了两篇文章了~今天再聊一个索引下推问题,也是非常有意思!
索引下推是从 MySQL5.6 开始引入一个特性,英文是 index condition pushdown,一般简称为 ICP,索引下推通过减少回表的次数,来提高数据库的查询效率。
有的小伙伴可能也看过一些关于 ICP 的概念,但是我觉得,概念比较简单,说一下很容易懂,但是在实际应用中,各种各样的情况非常多。所以接下来的内容我想通过几个具体的查询分析来和大家分享 ICP 到底是怎么一回事。
1. 索引下推
为了给大家演示索引下推,我用 docker 安装了两个 MySQL,一个是 MySQL5.5.62,另一个是 5.7.26,因为索引下推是 MySQL5.6 中开始引入的新特性,所以这两个版本就可以给大家演示出索引下推的特点(不懂 docker 的小伙伴可以在公众号后台回复 docker,有松哥写的入门教程)。
1.1 准备工作
首先我有如下一张表:
CREATE TABLE `user2` (
`id` int(11) unsigned NOT NULL AUTO_INCREMENT,
`username` varchar(255) COLLATE utf8mb4_unicode_ci DEFAULT NULL,
`age` int(11) DEFAULT NULL,
`address` varchar(255) COLLATE utf8mb4_unicode_ci DEFAULT NULL,
PRIMARY KEY (`id`),
KEY `username` (`username`(191),`age`)
) ENGINE=InnoDB AUTO_INCREMENT=100001 DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_unicode_ci;
我在 MySQL5.5 和 MySQL5.7 中分别执行如上 SQL,确保两个 MySQL 中都有这样一张表。这张表中有一个由 username 和 age 组成的复合索引,索引名字就叫 username,在本文接下来的内容中,我说 username 索引就是指该复合索引。
表创建成功后,各自添加一些模拟数据,这个我就不演示了,通过存储过程或者 Java 代码都能添加模拟数据,这个小伙伴们自行解决即可。
OK,这样我们的准备工作就算完成了。
1.2 MySQL 5.5
先来给小伙伴们演示一个 MySQL5.5 中的查询案例。
为了方便后文的表述,我给每一条 SQL 都取一个标记:
来看如下 SQL(SQL1):
select * from user2 where username='1' and age=99;
根据 username 和 age 查询一条记录,我们来看看这条 SQL 的执行计划(为了小伙伴们阅读方便,我加了 \G 把数据用列的形式展示):
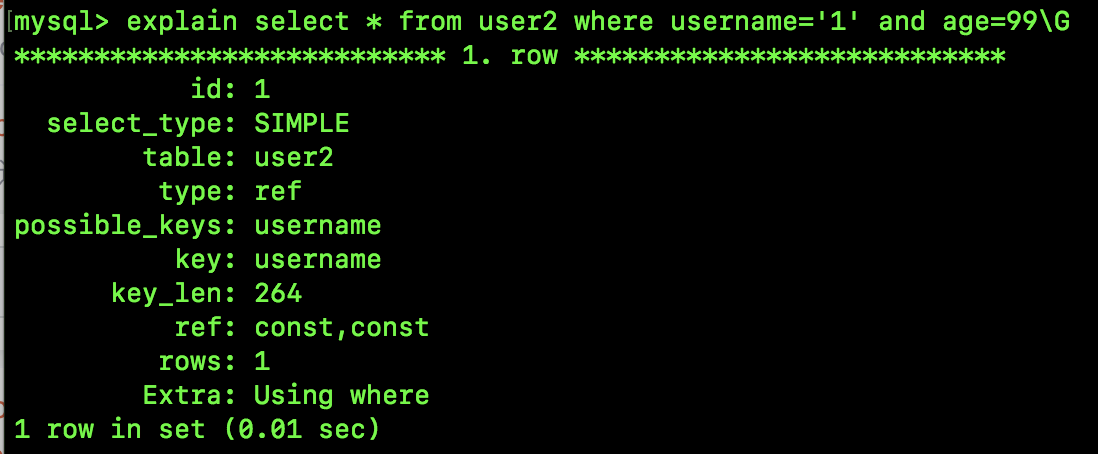
大致瞅一眼,我们发现这个是用了索引的,但是具体是怎么用的,我来和大家说道说道!
在 MySQL5.5 中,由于没有索引下推,所以上面这个 SQL 的执行流程是这样的:
- 首先 MySQL 的 server 层调用存储引擎获取 username='1' 的第一条记录。
- 存储引擎找到 username='1' 的第一条记录后,在 B+Tree 的叶子结点中保存着主键 id,此时通过回表操作,去主键索引中找到该条记录的完整数据,并返回给 server 层。
- server 层拿到数据之后,判断该条记录的 age 是否为 99,如果 age=99,就把该条记录返回给客户端,如果 age!=99,那就就丢弃该记录。
- 由于 username+age 组成的复合索引只是一个普通索引,并不是唯一索引(如果是唯一索引,那么这个查询就到此结束了),所以还需要继续去搜索有没有满足条件的记录。
但是注意第四步的搜索方式,不是直接去 B+Tree 中搜索了。由于在 username 索引中,username 字段的存储是有序的,即 username='1' 的记录都是挨着的,而 B+Tree 的叶子结点之间通过双向链表关联,通过一个叶子结点就能找到下一个叶子结点(或者上一个叶子结点),第二步返回的数据中有一个 next_record 属性,该属性就直接指向二级索引的下一条记录,找到下一条记录后,回表拿到所有数据并返回给 server 层,然后重复 3、4 步。
我们看看上面的执行计划,和我们的分析是一致的:
- 前面的 type 为 ref 表示通过索引查找数据,一般出现等值匹配的时候,type 会为 ref。
- 最后的 Extra 为 Using where 表示数据在 server 层还进行了过滤操作。
再来看一个 SQL(SQL2):
select * from user2 where username like 'j%' and age=99;
这跟前面那个 SQL1 其实很像,唯一的差别在于 username 用了模糊匹配 'j%',在上篇文章中松哥已经和大家分享过了,这种情况其实也是能用上索引的,具体大家可以参考:其实 MySQL 中的 like 关键字也能用索引!。
这条 SQL 的执行流程,跟第一条 SQL1 的执行流程也基本上是一致的,我这里就不赘述了,我们来看看这条 SQL 的执行计划:
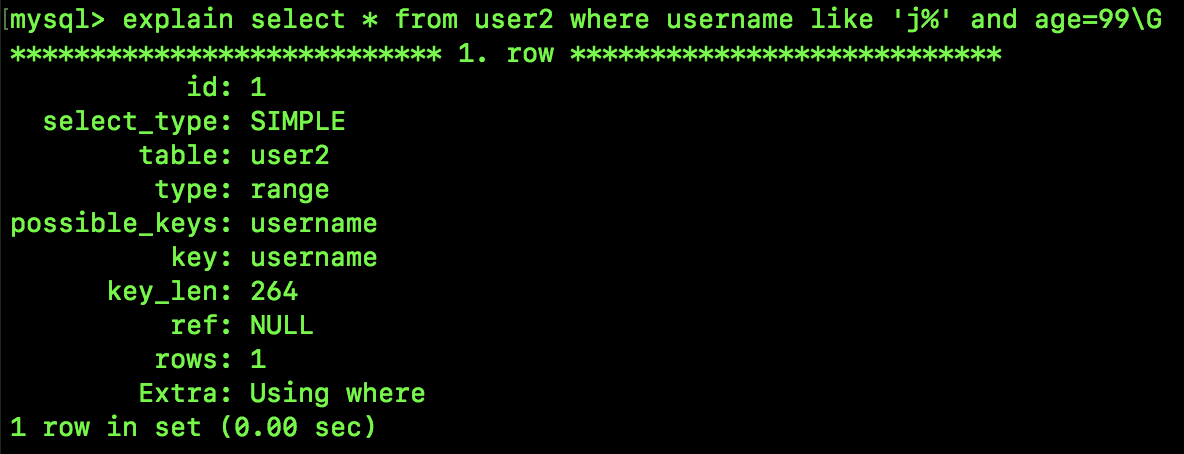
跟上面的执行计划相比,主要是 type 变为 range 了,表示按照范围搜索,因为 'j%' 其实就代表了一个扫描区间,不懂 'j%' 代表扫描区间的小伙伴,戳上篇文章。
前面两个 SQL,由于查询的时候是 select *,所以都是需要回表操作的,虽然是复合索引,索引中既有 username 又有 age,但是查询条件中只能传入 username 到存储引擎中,从存储引擎中回表拿到一行数据的完整记录后,再返回给 server 层,再在 server 层判断 age 是否满足条件。我们肉眼其实都能看到这样查询效率比较低,明明索引中有 age 的值,但是却不在索引中比较 age,而是要回表,取一行的完整记录出来,返回给 server 层,再去和 age 比较,要是比较不通过,这条记录就被丢掉了。如果我们能够把 age 直接传入存储引擎,在存储引擎中直接去判断 age 是否满足条件,满足条件了,再去回表,不满足条件就到此结束,这样就可以减少回表的次数,进而提高查询效率。
从 MySQL5.6 开始引进的索引下推技术,做的就是这事。
1.3 MySQL 5.7
我们在 MySQL5.7 中也来看下上面两条 SQL 的执行,先来看第一个(SQL3):
select * from user2 where username like 'j%' and age=99;
来看下查询计划:
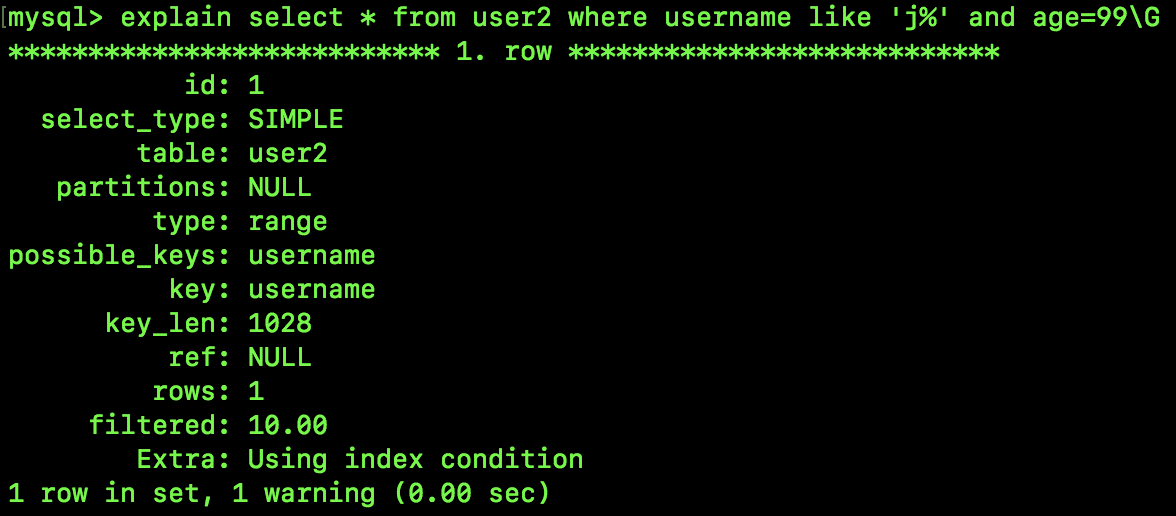
可以看到,这个查询计划和 SQL2 的查询计划相比,主要是最后的 Extra 为 Using index condition,这是啥意思呢?
这就是从 MySQL5.6 开始引入了索引下推 ICP,我们一起来看下具体操作流程:
- MySQL 的 server 层首先调用存储引擎定位到第一个以 j 开头的 username。
- 找到记录后,存储引擎并不急着回表,而是继续判断这条记录的 age 是否等于 99,如果 age=99,再去回表,如果 age 不等于 99,就不去回表了,直接继续读取下一条记录。
- 存储引擎将读取到的数据行返回给 server 层,此时如果还有其他非索引的查询条件,server 层再去继续过滤,在我们上面的案例中,此时没有其他查询条件了。假设 server 层还有其他的过滤条件,并且这个过滤条件把刚刚查到的记录过滤掉了,那么就会通过记录的 next_record 属性读取下一条记录,然后重复第二步。
这就是索引下推(index condition pushdown,ICP),有效的减少了回表次数,提高了查询效率。
有时候我们看一下老版本的 MySQL,会觉得特别莫名其妙,索引下推,多么理所应当顺理成章的功能呀,可惜当时就是没有!还好,该有的最终都会有。
我们再来看一个特殊情况,来看如下 SQL(SQL4):
select * from user2 where username='1' and age=99;
和前面的相比,这里的查询条件都变成等值比较了,来看看它的执行计划,如下:
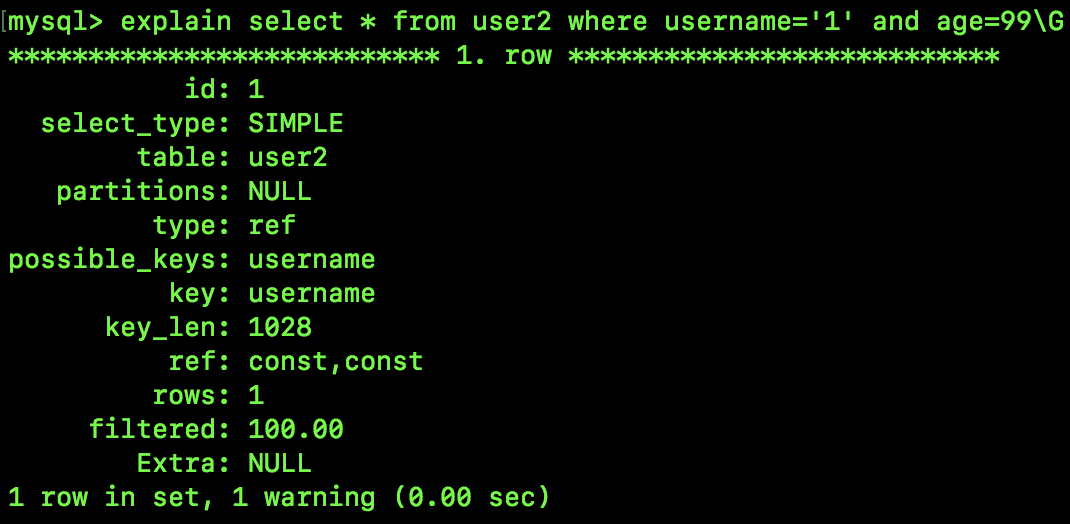
可以看到,这个查询计划和 SQL1 的查询计划相比,主要是最后的 Extra 为 null,没有额外操作了,其实这只是一个特殊处理而已,利用搜索条件 username='1' and age=99 从存储引擎中找到数据之后,没有再去重复判断了而已(SQL3 中索引下推的时候不仅判断 age 的值也判断 username 的值)。
2. 小结
好啦,通过 MySQL5.5 和 MySQL5.7 的对比,现在大家明白什么是索引下推了吧?其实一句话:在搜索引擎中提前判断对应的搜索条件是否满足,满足了再去回表,通过减少回表次数进而提高查询效率。
|








- 上一条: 如何实现一个任务调度系统 2022-01-24
- 下一条: Netty核心概念之ChannelHandler&Pipeline&ChannelHandlerContext 2022-01-24
- 用好组合索引,性能提升10倍不止! 2021-07-22
- 以openGauss Connector下推为例剖析Connector下推机制 2022-03-18
- 前缀索引,中看也中用! 2022-02-11
- 什么是走索引? 2022-06-15
- MySQL索引的坑,谁踩谁知道…… 2021-12-06


