用 AI 给向量检索加 buff,Milvus 亮相数据库顶会 VLDB

2021,数据库领域的研究有哪些突破?
本月举行的全球数据库顶会 VLDB 上,Zilliz 与哈佛大学、卡内基梅隆大学、清华大学、微软等多家高校与企业受邀介绍最新研究进展,分享了将机器学习方法应用到数据库系统的经验。Zilliz 高级研究员易小萌介绍了开源向量数据库 Milvus 的开发背景、设计思路,以及开发过程中遇到的挑战与技术创新点。
VLDB 与 SIGMOD 和 ICD 是数据库领域久负盛名的三大顶会。此前,由 Zilliz 研发团队贡献的研究成果 Milvus: A Purpose Built Vector Data Management System 就因过硬的底层功能和完善的业务场景,被 SIGMOD 评委会相中收录为今年 21 篇工业界论文之一。
Milvus 专为分析和检索海量特征向量而设计,提供完整的向量数据更新、索引与查询框架,在满足动态数据实时搜索的同时,也能满足实际业务中多样化的查询需求。目前,Milvus 已经发布 1.0 单机版与 2.0 分布式版,所有代码完全开源,试验性能大幅超越同 类向量检索系统。
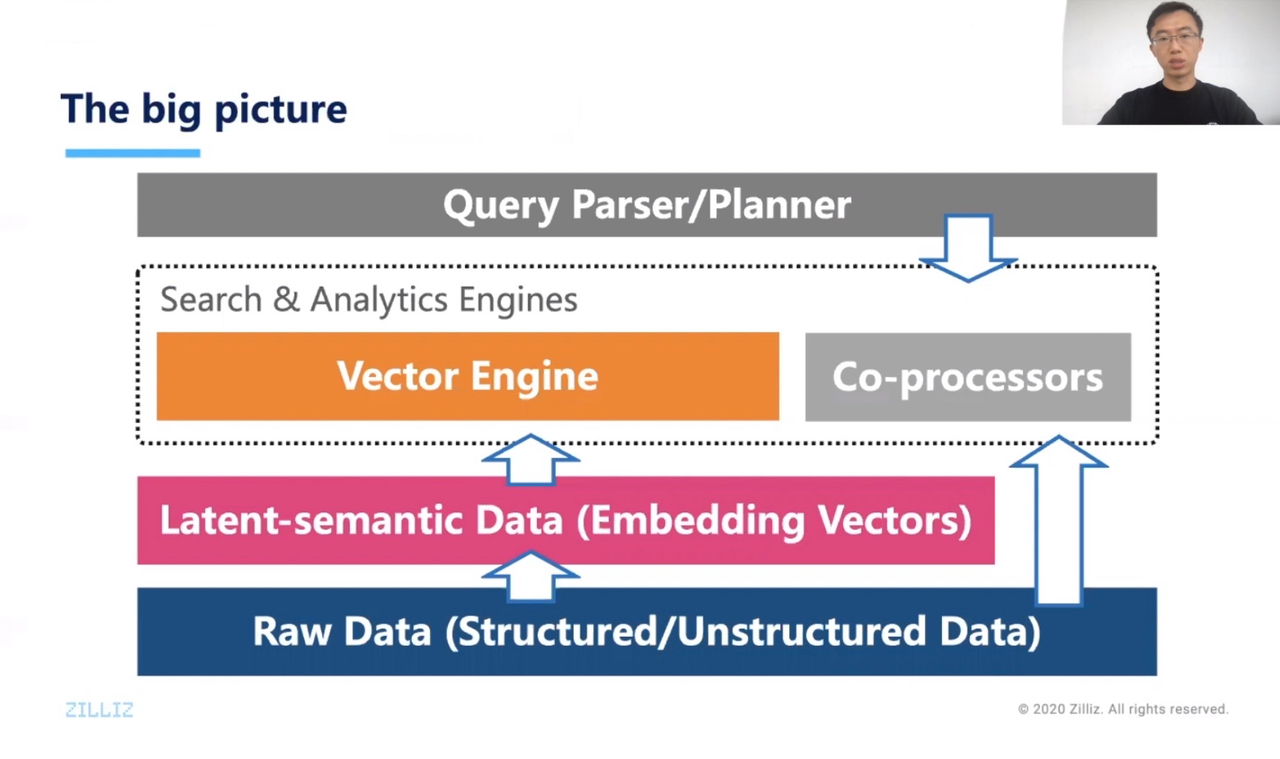
“俗话说万物皆 embedding,拜机器学习所赐,我们能够用神经网络提取复杂数据中的语义,从而建立我们的向量数据库”, 易小萌在分享中说。向量数据库与传统数据库有哪些不同?优势体现在哪里?让我们一起来看看吧:
1. 我们为什么要使用向量数据库?

据 IDC 白皮书预测,2018 年到 2025 年之间,全球产生的数据量将会从 33 ZB 增长到 175 ZB,其中超过 80%的数据都会是处理难度较大的非结构化数据,如图像、视频、音频等。然而,传统的数据库只能存放有限的、经过提取和加工后的数据,例如数字、文本等。数据量的激增与数据类型的巨变给传统的数据仓库带来巨大挑战。
2018年,Zilliz 开发团队嗅到了数据改革的趋势,工程师们设想了一种可能:尽管数据具有不同的类型,在语义(Semantics)层面上可以用向量对数据进行统一的标识。如果使用 AI 神经网络模型提取数据类型的语义,将其以向量的形式呈现,就可以针对向量数据构建运算系统,许多数据处理逻辑可以直接在向量上执行。向量数据库的优势在于,用统一的形式呈现所有类型的数据,降低了底层数据处理系统的复杂性。

以图像搜索为例,机器学习的方式可以将图片映射到向量空间中,在这个空间中,相似图片的向量是接近的。当用户发起一个以图搜图的查询,数据库将查询的图像转化为向量,在向量空间中进行向量相似度搜索,再将结果向量对应的图片返回给用户 —— 目前,Milvus 已经实现了这个功能,并经过了全球 1000 家用户的实践验证。
2. Milvus 2.0 版本设计理念与亮点功能
Milvus 1.0 版本实现了对向量数据的增删改查和持久化存储。
去年年底,分布式的 Milvus 2.0 版本发布。新版本基于以下五点考量:
Milvus 系统需要快速演进。新兴领域的系统软件,每天都面对新的功能需求,其迭代速度决定了软件的生命力。一个足够开放、解耦的架构,可以避免快速演进过程中的复杂度失控。
尽管 Milvus 2.0 版本是为分布式处理数据设计的,我们依然希望在不同环境下的部署都能有稳定的表现。
成本-效益对于向量数据很关键。向量数据和 AI 模型内部有大量的矩阵、向量运算,通常是计算密集和内存密集的,所以系统的弹性机制和资源调度机制对于成本影响很大。
我们还希望 Milvus 具有多样化的负载特征。不同负载下对于系统不同模块的压力区别非常大,为了有效的适应不同负载,比如混合数据的插入、更新和查询,系统需要有组件级的弹性能力。
Milvus 需要有灵活的协处理器机制以应对复杂的 Query。随着用户的查询场景越来越复杂,向量引擎需要和其它类型的分析引擎紧密合作,从而实现比较复杂的文本查询,或是结构数据的谓词运算。

Milvus 的架构逻辑分为四层:
协调服务 Coordinators - 负载最轻的控件,负责整体系统的协调控制。总共有四类协调者角色,分别为 root coord、data coord、query coord 和 index coord。
日志序列 Log Broker - 日志序列记录了系统中所有的“写入”操作,如表的创建和删除、数据的追加和更新。所有执行数据分析任务的系统组件都需要订阅日志序列,以便与最新的系统状态同步。接入层 Access Layer 包含了一组对等的 proxy 节点,是暴露给用户的统一 endpoint,负责转发请求并收集执行结果。
日志订阅 Log Subscribers - 当需要扩展系统整体分析能力的时候,就构建新的日志订阅者,并在其中实现这些功能。执行节点(Worker Node)只负责被动执行协调服务发起的命令,响应接入层发起的读写请求。目前有三类执行节点,即 data node、query node 和 index node。
存储服务 Storage - 整体系统数据的持久化存储,Milvus 依赖三类存储:元数据存储、消息存储和对象存储。
Milvus 2.0 作为一款开源分布式向量数据库产品,始终将产品的易用性放在系统设计的第一优先级。一款数据库的使用成本不仅包含了运行态的资源消耗成本,也包含了运维成本和接入学习成本。Milvus 新版本支持了大量降低用户使用成本的功能,具有以下六大亮点:
持续可用 Fail cheap, fail small, fail often. 存储计算分离架构,使得节点失败恢复的处理十分简单,且代价很低;分而治之的思想,使得每个协调服务仅处理读/写/增量/历史数据中的一个部分,设计被大大简化;混沌测试的引入,通过故障注入模拟硬件异常、依赖失效等场景,加速问题在测试环境被发现的概率。
向量/标量混合查询 混合查询帮助用户找出符合过滤表达式的近似邻,目前 Milvus 支持等于、大于、小于等关系运算以及 NOT、AND、OR 、IN 等逻辑运算,解决了结构化数据和非结构化数据的割裂问题。
多一致性 Milvus 2.0 是基于消息存储构建的分布式数据库,遵循 PACELC 定理所定义的,必须在一致性和可用性/延迟之间进行取舍。绝大多数 Milvus 场景在生产中不应过分关注数据一致性的问题,原因是接受少量数据不可见对整体召回率的影响极小,但对于性能的提升帮助很大。尽管如此,我们认为强一致性、有界一致性、会话一致性等一致性保障语义依然有其独特的应用场景。比如,在功能测试场景下,用户可能期待使用强一致语义保证测试结果的正确性,因此 Milvus 支持请求级别的可调一致性级别。
时间旅行: 数据工程师经常会因为脏数据、代码逻辑等问题需要回滚数据。Milvus 对所有数据增删操作维护了一条时间轴,用户查询时可以指定时间戳以获取某个时间点之前的数据视图。基于 Time Travel,Milvus 还可以很轻量地实现备份和数据克隆功能。
ORM Python SDK: 对象关系映射(Object Relational Mapping)技术使用户更加关注于业务模型而非底层的数据模型,便于开发者维护表、字段与程序之间的关联关系。为了弥补 AI 算法概念验证(Proof of concept)到实际生产部署之间的缺口,我们设计了 Milvus ORM API,而其背后的实现可以是通过嵌入式的 Library、单机部署、分布式集群,也可能是云服务。通过统一的 API 提供一致的使用体验,避免云端两侧重复开发、测试与上线效果不一致等问题。
丰富的周边支持: Milvus 使用 Milvus Insight 图形化管理界面,支持基于 helm 和 docker-compose 的一键部署,Milvus 2.0 使用开源时序数据库 Prometheus 存储性能和监控数据,同时依赖 Grafana 进行指标展示。
如有兴趣了解更多 Milvus 2.0 的相关内容,请参阅完整的Milvus 2.0 发版说明:https://github.com/milvus-io/milvus/releases。
3. 开发挑战与可能的 AI 解决方案
在开发 Milvus 2.0 过程中,开发团队遇到了不少挑战。
第一个挑战是索引的选择和相关的参数配置。配置索引是高效查询的必经之路,我们为用户提供多种类型的索引,使用不同的索引类型和参数配置可以在成本、准确性和性能之间获得不同的平衡点。然而,索引类型太多,用户不免有“选择困难症”。我们目前的解决方法是利用机器学习中的 BOHB 算法来实现自动(超参数)调优。BOHB 依赖 HB(Hyperband)来决定每次跑多少组参数和每组参数分配多少资源,其基本思想是对潜在的良好配置进行抽样,并在 Milvus 中对其进行评估,直到预算资源用完为止。虽然这种方法比随机搜索和纯贝叶斯优化方法更有效,但由于评估新配置时的高指数构建成本,这个方案仍然很耗时。Milvus 团队希望进一步寻求方法,比如允许先在小数据集上进行评估,再将结果转移到大数据集,让机器学习已有的数据集,并应用它来指导新数据集进行配置。
Milvus 遇到的第二个挑战是数据压缩。向量搜索算法需要在主内存中保留索引和数据,耗费大量成本,所以我们希望能够以较低的维度表示数据。如果使用传统的 PCA 技术进行压缩,精度会下降 10% 以上。机器学习或许可以改进向量搜索,团队考虑使用神经网络将向量编码到低维空间,为不同的查询选择合适的策略,从而尽量保留向量之间的相似性、提高查询性能。
在 AI 和数据库的交叉领域,我们期待用 AI 为向量检索赋能,解锁更多非结构化数据的隐藏价值。
易小萌
易小萌,Zilliz 高级研究员、研究团队负责人,华中科技大学计算机系统结构博士。主要工作领域为向量近似搜索算法和分布式系统的资源调度,相关研究成果在 IEEE Network Magazine、IEEE/ACM TON、ACM SIGMOD、IEEE ICDCS、ACM TOMPECS 等计算机领域国际顶级会议与期刊上发表。
📖 Milvus docs
Milvus 文档链接奉上: https://milvus.io/cn/docs/home
🚀 Milvus Roadmap
关于 Milvus 的未来的更多规划,欢迎大家通过 Roadmap 项目来了解:https://milvus.io/docs/v2.0.0/roadmap.md
🙏Thank you contributors!
最后感谢 Milvus 社区的 147 位贡献者 ❤️ 有了他们才有了今日的 Milvus 2.0。也欢迎大家开 issue 吐槽,或是加入社区一起贡献:https://milvus.io/community
|








- 上一条: openGauss数据库源码解析系列文章—— 执行器解析(三) 2021-08-27
- 下一条: 用AI给向量检索加buff!Milvus亮相数据库顶会VLDB 2021-08-27
- 用AI给向量检索加buff!Milvus亮相数据库顶会VLDB 2021-08-27
- 13 种高维向量检索算法全解析!数据库顶会 VLDB 2021 论文作者干货分享 2021-09-29
- 用 AI 识别基因,从向量化 DNA 序列开始 2021-08-19
- 顶会VLDB'22论文解读:多元时序预测算法METRO 2021-10-25
- 深度 | 数据大变革,向量数据库大牛揭秘设计理念 2021-09-16


