CPython 性能将提升 5 倍?faster-python 项目 PEP 659 源码级解读

作者:修玉同(音弦)
在 2021 年早些时候,Python 作者 Guido van Rossum 被微软返聘继续进行 CPython 相关工作,他们提出了一个 faster-python 计划,计划在 4 年内将 CPython 的性能提升 5 倍,整个项目被开放在 GitHub 的 faster-cpython Group,通过 Activity 可见该项目的一部分 ideas 已经有了相应的代码实现和验证。
本文将就该项目中的一个重要提案 PEP 659 进行解读和源码分析,并从中学习在 bytecode level 进行虚拟机性能优化的思路和手段,希望能对大家有所启发。
提案解读
PEP 659 创建于 2021 年 4 月,全称为 Specializing Adaptive Interpreter,这里有两个关键词:Specializing 和 Adaptive,这里可以简单理解为对特定位置的代码进行适配(Adaptive),替换为特殊的代码(Specializing)从而提高特定位置操作的执行速度。比如通过观察发现某个查询 dict 的代码在多次执行过程中 dict 没有变动,那么我们可以针对这段代码进行优化,将 dict entry 的 index 直接缓存起来,这样在下次查询时就避免了 hashtable 查找的过程从而提高性能,这里的观察就对应到 Adaptive,替换代码的过程则对应到 Specializing。
上面的例子并不准确,只是帮助大家对 Specializing Adaptive Interpreter 有一个初步的印象,下面我们将摘录提案中的关键语句进行解读。
首先要明确的一点是,PEP 659 并不是一个 JIT 方案,因为它的初衷在于让那些无法直接使用 PyPy 等包含 JIT Compiler 的用户也能享受到 faster CPython 的红利。例如在 iOS 平台下,用户进程受限于 codesign 动态创建的可执行的代码页在缺页中断时会因为未包含合法签名而被拒绝,因此无法直接使用包含 JIT Compiler 的 Python 虚拟机。
看到这里可能有些人会担心,不使用 JIT 单纯从虚拟机层面进行优化的空间和收益如何呢?在 PEP 659 中作者也给出了一些解释:
Specialization is typically done in the context of a JIT compiler, but research shows specialization in an interpreter can boost performance significantly, even outperforming a naive compiler.
即研究发现仅仅在 Interpreter 层面进行 Specialization 优化也可以获得显著的性能提升,性能收益甚至可以超过一些初级的 JIT 方案,作者在这里还引用了一篇自己之前的论文,感兴趣的同学可以自行去 PEP 659 提案的参考文献部分查看。
到这里我们也就明确了 PEP 659 不包含 JIT Compiler,简单地说就是它不生成代码,它只是代码的搬运工,我们需要穷举所有可能的优化情况,并且提前准备好代码,在观察到匹配的优化条件时将字节码进行替换,当发现不满足优化条件时还必须能够优雅的退回到优化前的代码以保证程序的正确性。
为了能更好的穷举优化情况和切换代码,需要选择合适的优化粒度,提案原文是:
By using adaptive and speculative specialization at the granularity of individual virtual machine instructions, we get a faster interpreter that also generates profiling information for more sophisticated optimizations in the future.
即在虚拟机指令层面进行优化,而不是像 JIT 那样在一个区域或者函数维度进行优化,这样可以针对特定指令进行细分,例如在 CPython 中获取 globals 和 builtins 都是通过 LOAD_GLOBAL 指令,首先在 globals 中查找,查找失败后再 fallback 到 builtins 中查找,在这里可能的情况只有 2 种,因此我们可以为虚拟机新增两条指令 LOAD_GLOBAL_MODULE 和 LOAD_GLOBAL_BUILTIN,当发现某段字节码中的 LOAD_GLOBAL 一直在查找 globals 时,我们可以将其优化为前者,反之优化为后者,同时可以对 globals 和 builtins dict 的 entry index 进行缓存避免重复访问 dict 的 hashtable,当发现不满足优化条件(例如查找失败,或是 dict 被修改)时再回滚到 LOAD_GLOBAL 指令保证程序的正确性。
上述从 LOAD_GLOBAL 到 LOAD_GLOBAL_MODULE / LOAD_GLOBAL_BUILTIN 的过程实际上就是 PEP 标题中的 Specializing,而选择将指令替换为 LOAD_GLOBAL_MODULE 还是 LOAD_GLOBAL_BUILTIN 的过程其实就是 Adaptive,它的职责是观察特定代码中的指令的执行情况,以为其选择正确的优化指令,观察的过程也是虚拟机代码执行的过程,因此在这里还需要额外引入一个 Adaptive 指令 LOAD_GLOBAL_ADAPATIVE 用来执行观察和替换逻辑。
虽然说 Specializing 能够通过减少判断和增加缓存来提速,但从原始指令到 Adaptive 指令,从 Adaptive 观察得出 Specializing 指令的过程也是有损耗的,因此需要基于一定的策略进行优化,而不是无脑的尝试优化所有代码中的指令,原文中提到:
Typical optimizations for virtual machines are expensive, so a long "warm up" time is required to gain confidence that the cost of optimization is justified.
即对虚拟机的 Specializing 优化是昂贵的,这种昂贵体现在我们需要在字节码执行的大循环中插入优化代码,甚至在每一次循环都需要额外的处理逻辑,而很多代码可能都只会执行一次,如果对他们进行优化纯属浪费时间,因此我们需要找出那些需要优化的代码,这样代码的一个主要特点是被高频调用,我们可以对每个 PyCodeObject (CPython 中保存字节码和环境信息的对象) 增加计数器,只有执行次数超过某个阈值才执行优化逻辑,这个过程被称之为 warm up。
在虚拟机层面,当某个字节码对象 PyCodeObject 被执行(可以简单理解为一段 Python 代码对应的字节码被执行)或是发生绝对跳转时,代码对象的 co_warmup 计数器会被累加,当达到阈值后这段字节码中所有可优化指令都会被替换为 Adaptive 指令进行观察和特殊化,此后这些指令只会在 Adaptive 和 Specializing 之间转换,当 Specializing 指令的优化条件被破坏时,我们不会立即回滚到 Adaptive 指令,而是允许一定次数的 miss 以防止出现优化和去优化之间的颠簸,同样的当去优化回滚到 Adaptive 指令后我们也会暂停观察和优化逻辑,让指令按照原始逻辑运行一段时间,这个过程被称为 deferred,整个过程的状态图如下:
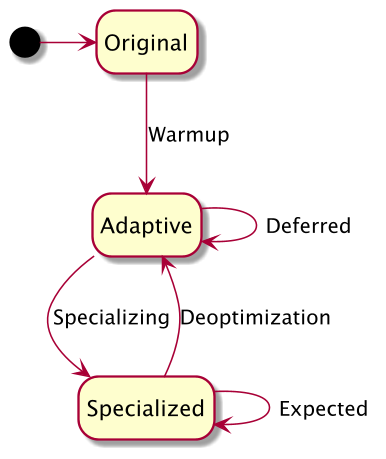
到这里我们已经对 PEP 659 的原理和大致工作过程有了了解,但为了高性能的实现这个优化器还有很多细节需要探讨,例如哪些指令需要优化,如何优雅的替换指令和还原,如何设计指令缓存等,这些具体问题单纯从理论层面分析太过枯燥和晦涩,因此接下来我们将结合 Python 3.11 中 PEP 659 的源码实现来进行讲解。
源码分析
实际上 PEP 659 的基础设施和部分优化指令已经在 CPython 3.11 的分支上有所体现,我们这里以 LOAD_GLOBAL 改造为例对上述流程进行细致分析,之所以选择 LOAD_GLOBAL 是因为它在虚拟机层面的操作较为简单,只涉及到两个命名空间的查找,优化和去优化判断也比较直接,足够清晰的说明问题又不会因为指令的晦涩给大家的阅读带来困难。
整个优化过程主要包括 Warmup, Adaptive, Specializing & Deoptimize 这几个阶段,下面我们将就各阶段的功能和核心代码做一些分析和讲解。
Warmup
如上文所述,warmup 解决的问题是找到真正高频执行的代码,避免优化那些此后再也不会被执行到的代码,这里我们不需要计算代码执行的频率,只需要设定一个阈值,并对特定的字节码对象 PyCodeObject 的执行次数计数,当达到阈值时认为完成了 warmup,因此在这里我们为 PyCodeObject 引入了一个新字段 co_warmup:
/* Bytecode object */
struct PyCodeObject {
PyObject_HEAD
// The hottest fields (in the eval loop) are grouped here at the top.
PyObject *co_consts; /* list (constants used) */
PyObject *co_names; /* list of strings (names used) */
// ...
int co_warmup; /* Warmup counter for quickening */
// ...
/* Quickened instructions and cache, or NULL
This should be treated as opaque by all code except the specializer and
interpreter. */
union _cache_or_instruction *co_quickened;
};在 PyCodeObject 对象被创建时,co_warmup 的初始值被设定为 QUICKENING_WARMUP_DELAY,它是一个负值,每当 PyCodeObject 被执行或是在代码内发生绝对跳转时 co_warmup 会 +1,当达到阈值 0 后则进入优化逻辑:
#define QUICKENING_WARMUP_DELAY 8
/* We want to compare to zero for efficiency, so we offset values accordingly */
#define QUICKENING_INITIAL_WARMUP_VALUE (-QUICKENING_WARMUP_DELAY)
static void
init_code(PyCodeObject *co, struct _PyCodeConstructor *con) {
// ...
co->co_warmup = QUICKENING_INITIAL_WARMUP_VALUE;
co->co_quickened = NULL;
}Adaptive
当 co_warmup 被累加到 0 后,会走到 _Py_Quicken 函数执行优化逻辑,由于涉及到字节码调整,官方在这里为原始字节码 co_code 拷贝了一份副本存放在 quickened 中,此后的所有修改都发生在 quickened 中:
/* Bytecode object */
struct PyCodeObject {
PyObject_HEAD
// The hottest fields (in the eval loop) are grouped here at the top.
PyObject *co_consts; /* list (constants used) */
PyObject *co_names; /* list of strings (names used) */
_Py_CODEUNIT *co_firstinstr; /* Pointer to first instruction, used for quickening. */
// ...
PyObject *co_code; /* instruction opcodes */
/* Quickened instructions and cache, or NULL
This should be treated as opaque by all code except the specializer and
interpreter. */
union _cache_or_instruction *co_quickened;
};
typedef uint16_t _Py_CODEUNIT;
int
_Py_Quicken(PyCodeObject *code) {
if (code->co_quickened) {
return 0;
}
Py_ssize_t size = PyBytes_GET_SIZE(code->co_code);
int instr_count = (int)(size/sizeof(_Py_CODEUNIT));
if (instr_count > MAX_SIZE_TO_QUICKEN) {
code->co_warmup = QUICKENING_WARMUP_COLDEST;
return 0;
}
int entry_count = entries_needed(code->co_firstinstr, instr_count);
SpecializedCacheOrInstruction *quickened = allocate(entry_count, instr_count);
if (quickened == NULL) {
return -1;
}
_Py_CODEUNIT *new_instructions = first_instruction(quickened);
memcpy(new_instructions, code->co_firstinstr, size);
optimize(quickened, instr_count);
code->co_quickened = quickened;
code->co_firstinstr = new_instructions;
return 0;
}看到上面的代码你可能会疑惑为什么 quickened 包含了除去字节码以外的额外空间,实际上仅仅通过指令替换是难以实现优化的,我们还需要对指令操作的对象尽可能进行缓存,以 LOAD_GLOBAL 为例,最坏情况我们需要查 2 次字典,第一次查 globals,第二次查 builtins,在 CPython 中字典底层是 hashtable,因此在发生 hash 碰撞时它的复杂度是大于 O(1) 的。为了优化变动不频繁的字典,我们可以将 key 对应的 hashtable index 进行缓存,显然这些缓存和指令是一一对应的,因此 quickened 的额外空间的作用就是存储优化后指令的额外信息。
quickened 是一个双向数组,左边存放是 cache,右边存放字节码,在数组的最左端额外分配了一个 cache entry 用来存储 cache count,通过 cache count 我们可以快速定位到字节码数组,前面看到的 first_instruction 就是通过 cache_count 从 quickened 定位到 instr 0 的:
/* We layout the quickened data as a bi-directional array: * Instructions upwards, cache entries downwards. * first_instr is aligned to a SpecializedCacheEntry. * The nth instruction is located at first_instr[n] * The nth cache is located at ((SpecializedCacheEntry *)first_instr)[-1-n] * The first (index 0) cache entry is reserved for the count, to enable finding * the first instruction from the base pointer. * The cache_count argument must include space for the count. * We use the SpecializedCacheOrInstruction union to refer to the data * to avoid type punning. Layout of quickened data, each line 8 bytes for M cache entries and N instructions: <cache_count> <---- co->co_quickened <cache M-1> <cache M-2> ... <cache 0> <instr 0> <instr 1> <instr 2> <instr 3> <--- co->co_first_instr <instr 4> <instr 5> <instr 6> <instr 7> ... <instr N-1> */
每条被优化的指令都需要独立的 cache entries,我们需要一种手段 O(1) 的从指令索引到 cache,在 Python 3 中每条指令包括 8 bit 的 opcode 和 8 bit 的 operand,官方选择使用 offset + operand 构建二级索引,这里的 offset 用来确定索引的块范围(这里有点像页表搜索,offset 代表 PAGE,operand 代表 PAGEOFF), operand 用来修正 offset,被索引覆盖的 operand 则存放在 cache 中,上述设计在 PEP 659 中的原文如下:
For instructions that need specialization data, the operand in the quickened array will serve as a partial index, along with the offset of the instruction, to find the first specialization data entry for that instruction.
对于 LOAD_GLOBAL 而言,需要缓存的主要是 dict 的版本信息以及 key index,此外还有一些优化器所需的额外信息,具体如下:
- 字典键值对的版本 dk_version,由于这里同时涉及到 globals 和 builtins,我们需要缓存两个 dk_version,每个 dk_version 都是一个 uint32_t,所以加起来 dk_version 需要一个 8B,也就是一个 cache entry;
- key 对应的 index,它是一个 uint16_t,由于我们已经占用了一个 cache entry,这里只能再使用一个额外的 cache entry;
- 由于原来的 operand 被用来做 partial index,我们还需要额外的一个 uint8_t 来存储 original_oparg,这个可以和 2 中的 uint16_t 合并存储;
- 在提案解读部分我们提到在 Adaptive, Specilization 和 Deoptimize 之间转换需要一个计数器缓冲来避免颠簸,需要一个 counter,官方在这里使用了一个 uint8_t。
综合上述分析,LOAD_GLOBAL 需要两个 cache entry,第一个存储 orignal_oparg + counter + index,第二个存储 globals 和 builtins 的 dk_version:
typedef struct {
uint8_t original_oparg;
uint8_t counter;
uint16_t index;
} _PyAdaptiveEntry;
typedef struct {
uint32_t module_keys_version;
uint32_t builtin_keys_version;
} _PyLoadGlobalCache;分析到这里其实实施 Adaptive 策略已经水到渠成了,对于 LOAD_GLOBAL 而言无外乎查找 globals 和 builtins,当某个 LOAD_GLOBAL 在 Adaptive 逻辑中命中 globals 时,我们将其优化为 LOAD_GLOBAL_MODULE,缓存好 index 和 module_keys_version 即可;当某个 LOAD_GLOBAL 没有命中 globals 时,我们需要同时缓存 module_keys_version 和 builtin_keys_version,这是因为当 globals 发生变化后可能导致下次 LOAD_GLOBAL 不再命中 builtins,在这里我们将其优化为 LOAD_GLOBAL_BUILTIN,这个优化选择和缓存的过程实际上就是 Adaptive。
Specializing & Deoptimize
如上文所述,字节码对象 PyCodeObject 在经过了 Warmup 和 Adaptive 过程之后其中可优化指令均已变成了 Specialized 形式,例如 LOAD_GLOBAL 已经全部以 LOAD_GLOBAL_MODULE 或 LOAD_GLOBAL_BUILTIN 的形式存在(这里先不考虑 Deoptimize),用大白话说就是字节码中的指令完成了对当前环境的最优适配,下面我们来看看这些适配的代码是怎样的。
其实经过上面的分析,相信大家已经把适配代码猜个八九不离十了,下面我们以较为复杂的 LOAD_GLOBAL_BUILTIN 为例分析一下源码:
TARGET(LOAD_GLOBAL_BUILTIN) {
// ...
PyDictObject *mdict = (PyDictObject *)GLOBALS();
PyDictObject *bdict = (PyDictObject *)BUILTINS();
SpecializedCacheEntry *caches = GET_CACHE();
_PyAdaptiveEntry *cache0 = &caches[0].adaptive;
_PyLoadGlobalCache *cache1 = &caches[-1].load_global;
DEOPT_IF(mdict->ma_keys->dk_version != cache1->module_keys_version, LOAD_GLOBAL);
DEOPT_IF(bdict->ma_keys->dk_version != cache1->builtin_keys_version, LOAD_GLOBAL);
PyDictKeyEntry *ep = DK_ENTRIES(bdict->ma_keys) + cache0->index;
PyObject *res = ep->me_value;
DEOPT_IF(res == NULL, LOAD_GLOBAL);
STAT_INC(LOAD_GLOBAL, hit);
Py_INCREF(res);
PUSH(res);
DISPATCH();
}我们先忽略 DEOPT_IF 看一下主逻辑,首先取出当前命令的 cache entries,第一个 entry 记录了 index,第二个 entry 记录了 globals 和 builtins 的 dk_version,在缓存命中的情况下我们只需要从 builtins dict 的 hashtable[index] 取出键值对,将它的 value 返回即可,相比于原来先查 globals dict 再查 builtins dict 着实快了不少。
但是先不要高兴太早,该少的减少其实一个都少不了,我们知道只有 globals 找不到的时候才会去找 builtins,如果 globals 变了那缓存必然会失效,此外我们的 index 缓存前提也是 builtins dict 不能改变,综合上述两点我们必须先确认两个字典的 dk_version 都没变才能继续执行,这其实也是 Deoptimize 的触发条件之一,这正是 DEOPT_IF 所做的事情:
#define DEOPT_IF(cond, instname) if (cond) { goto instname ## _miss; }
#define JUMP_TO_INSTRUCTION(op) goto PREDICT_ID(op)
#define ADAPTIVE_CACHE_BACKOFF 64
static inline void
cache_backoff(_PyAdaptiveEntry *entry) {
entry->counter = ADAPTIVE_CACHE_BACKOFF;
}
LOAD_GLOBAL_miss:
{
STAT_INC(LOAD_GLOBAL, miss);
_PyAdaptiveEntry *cache = &GET_CACHE()->adaptive;
cache->counter--;
if (cache->counter == 0) {
next_instr[-1] = _Py_MAKECODEUNIT(LOAD_GLOBAL_ADAPTIVE, _Py_OPARG(next_instr[-1]));
STAT_INC(LOAD_GLOBAL, deopt);
cache_backoff(cache);
}
oparg = cache->original_oparg;
STAT_DEC(LOAD_GLOBAL, unquickened);
JUMP_TO_INSTRUCTION(LOAD_GLOBAL);
}DEOPT_IF 做的事情是跳到指令的 cache miss 分支,对于 LOAD_GLOBAL 是 LOAD_GLOBAL_miss,miss 分支做的事情非常固定,首先可以明确的是它会 fallback 到常规的 LOAD_GLOBAL 分支(底部的 JUMP_TO_INSTRUCTION),但它永远不会将指令回滚到 LOAD_GLOBAL,只会在 Adaptive 和 Specialized 指令之间转移。为了避免缓存颠簸,上面的代码会在 counter 递减到 0 时才退化到 Adaptive 指令,在此之前会一直尝试先访问缓存。
到这里整个优化和去优化过程我们就分析完了,整个流程还是比较复杂的,但具有明显的套路,只要构建好 Cache 和 Adaptive 基础设施,对其他指令的改造就比较容易了。通过这种方式进行指令加速的一个难点是如何设计缓存以减少分支,因为 DEOPT_IF 的存在我们很难直接减少前置的条件判断,只能将其转化为更高效的形式。
关注【阿里巴巴移动技术】微信公众号,每周 3 篇移动技术实践&干货给你思考!
|








- 上一条: 理解python异步编程与简单实现asyncio 2022-01-17
- 下一条: Python3 cpython优化 实现解释器并行 2022-02-25
- 用100行代码提升10倍的性能 2021-07-05
- Python3 cpython优化 实现解释器并行 2022-02-25
- 用好组合索引,性能提升10倍不止! 2021-07-22
- 性能提升了200% 2021-08-01
- 性能提升1400+倍,快来看MySQL Volcano模型迭代器的谓词位置优化详解 2021-10-22


