多兴趣召回模型实践|得物技术
文|QC 得物技术
MIND多兴趣召回在实践过程中,经过离线和实时两个阶段去执行最终落地,中间的步骤因此记录下来,希望你在阅读到此文能够有所收获。
具体步骤:首先经过离线召回的方式从实验数据上证明了可行性,天级别指标均置信提升:pvctr+0.36%,uvctr+0.36,dpv+0.76%,后续基于该版本开发MIND在线预估方式。最终在交易瀑布流场景取得的收益为:dpv+3.61%,人均收藏pv+2.39%,pvctr+1.95%,uvctr+0.77%。
离线召回过程中,是通过类似I2I的召回方式进行的,首先训练出模型之后,然后将单机去跑user embedding和item embedding后再通过faiss得到对应userId下的倒排召回,最终将userId作为trigger进行I2I的召回。在线预估是通过线上的实时用户行为调用neuron预估服务的模型计算user embedding后,然后通过C引擎的离线item embedding计算faiss得到召回商品,目前兴趣数设置为3,考虑到召回组件的超时时间,因此需要并发执行。
1. 多兴趣召回简介
1.1 MIND多兴趣召回
多兴趣MIND召回是一种u2i召回,其提出了一种Behavior-to-Interest (B2I)动态路由,用于自适应地将用户的行为聚合为兴趣表示向量。具体的来说,多兴趣模型的输入为用户的行为序列,该行为序列在瀑布流场景使用的是用户的点击、收藏、分享的cspuid,输出则是用户的多个兴趣向量(这个size可以定义,由网络的输出维度确定),一般而言,兴趣向量的区别集中在类目/品牌上。
多个兴趣的用户向量是该召回的一个亮点,因为用户在逛瀑布流场景时,显然不可能只有单个兴趣的,往往会集中在几个不同的兴趣,可能是鞋、服装、化妆品等等。因此单一的兴趣向量往往很难去cover住用户想要感知的。
单一兴趣的召回结果往往局限在一个类别范围下,这种召回策略扩展性较差,容易越推越窄,使得候选池中的视频头部效应越来越明显。
1.2 其他的一些多兴趣召回方法:
(1)可以对用户的长短期兴趣、用的点击item都做召回,这样便可以捕获用户过去的所有兴趣,这个也是目前线上i2i的一个策略;
(2)也可以利用用的点击/收藏/分享的item都做召回类似item2vec获取item的embedding后再进行faiss索引后取topn的方式获取用户的所有兴趣点。
2. 多兴趣召回模型
下图是MIND召回的整体网络框图:

对于模型, 每个样本的输入可以表示为一个二元组:
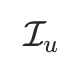
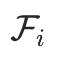
定义为目标物品 i 的一些特征,例如商品的brand_id和类目category_id等。
- 通过Mulit-Interest Extractor Layer 获取多个向量表达用户兴趣的不同方面;
- 提出了具有动态路由的多兴趣网络(MIND),利用动态路由以自适应地聚合用户历史行为到用户表达向量中,以处理用户的不同兴趣;
- 开发 Label-Aware Attention 标签感知注意力机制,用于学习具有多个兴趣向量的用户表示。
具体来说就是设计了一种基于胶囊网络机制的多兴趣提取层,适用于聚类历史行为,提取不同的兴趣。胶囊网络的核心思想就是“输出是输入的某种聚类的结果”。
这里有一个优点:如果把与用户兴趣各种相关的信息都压缩成为一个表达向量,这会成为用户多样兴趣表达的瓶颈,在推荐召回阶段召回候选集时,对用户不同兴趣的所有信息混合在一起使用,会导致召回Item 的相关性大大降低。因此,采用多个向量来表达用户不同的兴趣,将用户的历史行为分组到多个 interest capsules 的过程, 期望属于同一个capsules 的相关Item 共同表达用户兴趣的一个特定方面。
通过多兴趣提取层,多个兴趣胶囊从用户行为embedding建立。在训练期间,通过一个标签意识注意力层让标签物品选择使用过的兴趣胶囊。特别的,对于每一个标签物品,我们计算兴趣胶囊和标签物品embedding之间的相似性,并且计算兴趣胶囊的权重和作为目标物品的用户表示向量,通过相应的兼容性确定一个兴趣胶囊的权重,这里和DIN中的Attention几乎一样,但key与value的含义不同。其中目标物品是query,兴趣胶囊既是keys也是values。
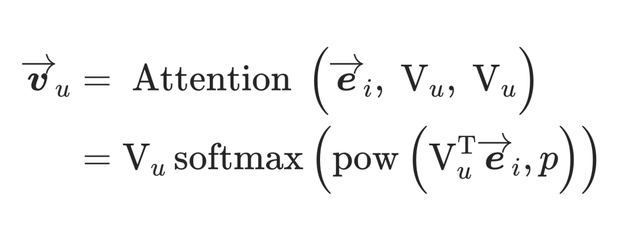
其中pow定义每个元素的指数级操作,是一个可调节的参数来调整注意力分布。当接近0,每一个兴趣胶囊都得到相同的关注。当大于1时,随着大小的增加,具有较大值得点积将获得越来越多的权重。考虑极限情况,当趋近于无穷大时,注意机制就变成了一种硬注意,选关注最大的值而忽略其他值。
2.1 user embedding计算部分
MIND的核心任务是学习一个从用户行为序列映射到多兴趣向量表示的函数,用户表示定义为:
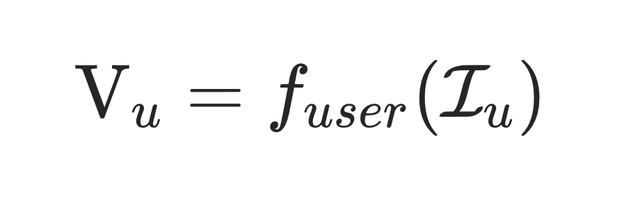
其中
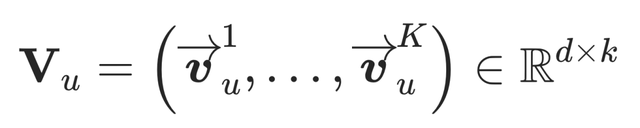
为用户u的多兴趣向量表示,d 为embedding的维度,本网络设定的维度 d 和DSSM一样是32,K 是表示兴趣向量的数量。若K=1,即其他模型(如Youtube DNN)的Embedding表示方式。
2.2 item embedding计算部分
目标商品的embedding函数为:

其中
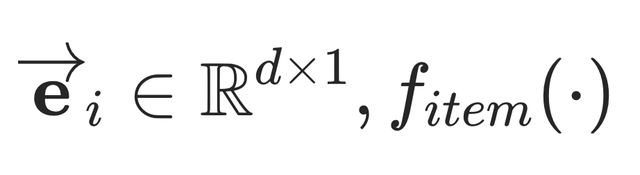
表示一个Embedding&Pooling层。
2.3 Loss function
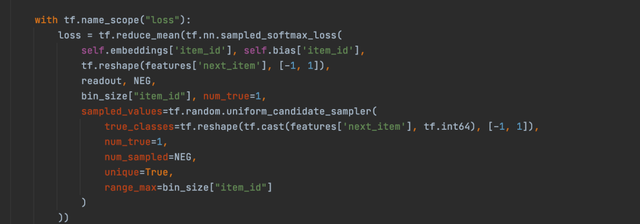
2.4 负采样的方式
负采用是均匀采样了若干个cspu_id作为负样本,这里的cspu_id是当时做样本是筛选出来的,都是包含点击行为的。
3. 多兴趣召回的实现和部署
多兴趣的召回实现具体包含odps、C++引擎、dpp和neuron预估服务端。
3.1 odps部分
其中odps主要执行训练样本的构建、模型训练以及模型离线监控,样本包含了两个版本,其中第一版本是采用了算法侧的用户行为表,第二版本考虑了第一版存在延时上报导致的线上线下不一致的问题,因此采用了dump下来的点击、收藏和分享序列,这里只用到了cspu_id作为特征,还没有使用商品的原有信息,比如淘宝使用了brand_id和category_id,这部分的会在后续的迭代中使用。
这里采用了是窗口式的构建样本方式,均使用了过去三天的数据。然后经过可推池进行筛选。此外,由于模型里面采用的embedding_lookup的方式进行查找cspu_id的embedding,因此样本里面还单独构建了一份cspu_id和hash_id的映射表。然后会进行模型训练
3.2 C++引擎部分
C++引擎存储cspu_id和hash_id的映射表、向量集群存储item embedding表。线上使用的过程中,需要获取用户的clklist画像,然后基于clklist保存的cspu_id去正排请求C++引起的映射表获取hash_id,然后构建neuron的特征。这里只需要hash_id的序列和长度,传输给neuron后便可以实现预估user embedding。
拿到user embedding后通过dpp构建三个并发请求去调用faiss获取每个兴趣对应的召回结果,然后拼接去重再传输给后续层。
3.2.1 一些小坑
- embedding的生成时间不确定,然后中间又没有同步机制,因此neuron模型和faiss的emebdding不一致会导致效果下跌。
- 构建embedding的任务在一个集群内是串行执行的,那么后续如果u2i的召回多了,会导致任务卡着。
3.3 neuron预估部分
neuron预估部分需要去构建服务,具体的说需要写一个neuron_script脚本,用于dpp在调用neuron过程中,neuron根据这个脚本然后去进行特征处理,然后构建模型的feed,再通过起一个tf-servering服务拉起模型,最后便输出用户向量返回到dpp。
4. 多兴趣召回模型的稳定性
线上服务的模型不仅仅是要有效果,同时需要保证其运行的稳定性,因此线上模型是需要额外的添加相应的离线监控加对应的阻断机制,以及模型服务的在线监控,其中离线监控和阻断机制是当模型进行天级别离线训练的时候,如果离线指标(包含auc、pcoc、loss)不符合预期时,及时的进行阻断并且告警出来,作为一个前置阻断,防止影响该路召回的线上效果。模型服务的在线监控的实现判断召回空置率、召回qps、召回漏斗的召回数和对应渠道的pvctr、uvctr等指标来进行线上监控,并且通过同环比的方式进行配置,作为后置监控,一旦出现很大的波动则会告警,然后快速响应进行相应的回滚和处理。
模型的监控利用odps实现,主要是模型训练过程中会将loss落表,然后利用规则来进行长短期的监控
4.1 模型离线指标的监控
长期监控是获取过去30天的90%分位数和1.1倍的最大值,然后判断如果loss小于90%的分位数则可能训练得有点过拟合,兴趣不够发散会进行阻断,如果大于1.1倍的最大值,则可能模型没有完全train好,召回的结果可能太发散,会有一些bad case 。
短期监控主要是计算过去14天的均值和方差,然后loss要在(均值-3*方差,均值+3*方差)之间,如果不在则阻断。
监控的SQL代码:
SELECT CUR_LOSS,MIN_LOSS,MAX_LOSS,IF (CUR_LOSS<MIN_LOSS or CUR_LOSS>MAX_LOSS,1,0) FROM (
(
SELECT loss AS CUR_LOSS ,1 as rn1 FROM deal_pai_model_mind_recall_check
where ds=(select(regexp_replace(substr(date_sub(FROM_UNIXTIME(UNIX_TIMESTAMP()),1),1,10),'-','')))
) a
LEFT JOIN
(
SELECT (avg(loss)-2*STDDEV(loss)) AS MIN_LOSS ,1 as rn2 FROM deal_pai_model_mind_recall_check
where ds<(select(regexp_replace(substr(date_sub(FROM_UNIXTIME(UNIX_TIMESTAMP()),1),1,10),'-','')))
and ds>(select(regexp_replace(substr(date_sub(FROM_UNIXTIME(UNIX_TIMESTAMP()),14),1,10),'-','')))
) b
on a.rn1=b.rn2
LEFT JOIN
(
SELECT (avg(loss)+3*STDDEV(loss)) AS MAX_LOSS ,1 as rn3 FROM deal_pai_model_mind_recall_check
where ds<(select(regexp_replace(substr(date_sub(FROM_UNIXTIME(UNIX_TIMESTAMP()),1),1,10),'-','')))
and ds>(select(regexp_replace(substr(date_sub(FROM_UNIXTIME(UNIX_TIMESTAMP()),14),1,10),'-','')))
) c
on a.rn1=c.rn3
);
4.3 模型阻断机制
精排模型更新是利用odps的shell部署脚本实现的。而neuron是在跳板机定时执行部署脚本,判断路径下是否生成了模型文件,因此这里可以构建两个路径,一个是固定生产路径,一个是给neuron的模型文件路径,如果模型被阻断,也就是不会将模型push到neuron的模型文件路径即可。
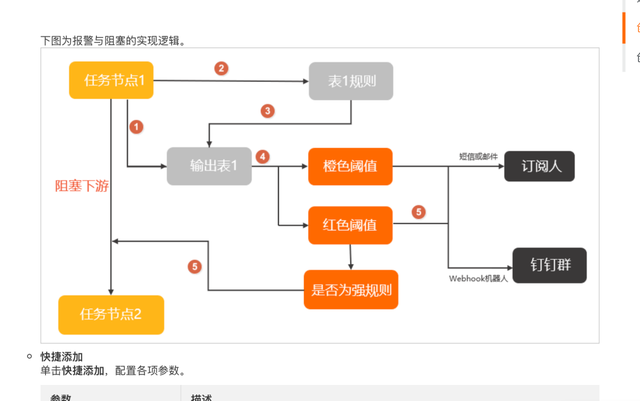
这里是采用了dataworks的数据质量方法,通过规则的方式一旦不符合规则则进行阻断。阻断的流程图如下:官方配置文档【1】
正常Normal时按照正常流程走,如果异常则阻碍下游节点,使得线上模型不更新来确保模型质量。
5. 多兴趣召回模型总结&后期优化点
5.1 总结
MIND多兴趣召回的核心是基于原先应用于图像的胶囊网络然后用于推荐,然后通过动态路由算法来捕捉用户的多个兴趣,对应的多个兴趣去召回不同的商品来cover用户想要感知的,并且在线预估会不断的提取用户的行为更加准确的捕捉用户后续的兴趣点,这也是为什么在线预估会比离线预估效果要好很多的原因。
5.2 后期优化点
- 在用户点击/分享/收藏行为序列内加入cspu_id的原有信息,便于冷启动以及可以获取到更多商品的表示信息来生成item embedding;
- 工程侧的优化 ,并发索引放在C引擎处进行,用于增加召回兴趣量;
- 负采样的优化,采用类似DSSM的负样本构建方式,而不是均为点击过的样本去做均匀采样。
引用
【1】官方配置文档 https://help.aliyun.com/document_detail/73829.html?spm=a2c4g.11186623.6.1184.3d4b583az2xhTe
【2】https://arxiv.org/pdf/1904.08030.pdf
【3】CIKM2019|MIND---召回阶段的多兴趣网络模型
*文/QC
关注得物技术,每周一三五晚18:30更新技术干货
要是觉得文章对你有帮助的话,欢迎评论转发点赞~
限时活动:
即日起至6月30日,公开转发得物技术任意一篇文章到朋友圈,就可以在「得物技术」公众号后台回复「得物」,参与得物文化衫抽奖。
|








- 上一条: 乘风破浪,探索数据可视化开发平台 FlyFish 开源背后的秘密! 2022-06-10
- 下一条: Zadig v1.12.0 推出 VS Code 插件,全面支持 GitOps ,好工具就要到最后一公里 2022-06-12
- 基于DataWorks的时效仿真平台|得物技术 2022-06-28
- 得物前端唤端业务场景和技术精讲 2022-07-11
- 得物客服热线的演进之路 2022-08-22
- 得物App数据模拟平台的探索和实践 2022-06-22
- 得物App直播复杂页面架构实践 2022-07-11


