百度小程序包流式下载安装优化
导读:文本介绍了百度小程序包下载链路的一种优化手段 —— 流式下载安装。首先引出原有方案的可优化点,接着探讨了优化方案是如何更充分地利用了网络IO、本地IO、CPU计算资源,最后介绍了代码层面的实现原理。
全文3608字,预计阅读时间10分钟
一、问题背景
小程序安装过程中涉及安装包的网络下载、保存文件、签名校验、解压解密等多个步骤,原有方案中各个步骤相互依赖串行执行,安装过程消耗时长为各个步骤之总和。
然而安装过程中各个阶段所竞争的资源不同,其中竞争网络 IO 资源的下载阶段耗时最长,且该阶段本地 IO 和 CPU 计算资源相对最闲。
理论上可以打破安装过程中各个步骤间的依赖,实现在读取网络下载流的同时,将签名校验、解密解压等步骤同时执行,尽量在网络下载阶段充分利用系统中的本地 IO 和 CPU 计算资源,以此减少网络下载之后各个步骤所消耗的额外时间。
二、解决方案
原有方案时序如下图所示,各个阶段竞争的繁忙关系分析如下:
-
下载安装包:网络 IO 最忙,CPU 计算较闲,本地 IO 较忙
-
校验安装包:无需网络 IO,CPU 计算(计算签名)最忙,本地 IO (读文件)较忙
-
提取包文件:无需网络 IO,CPU 计算(解密、解压)最忙,本地 IO (读写文件)最忙
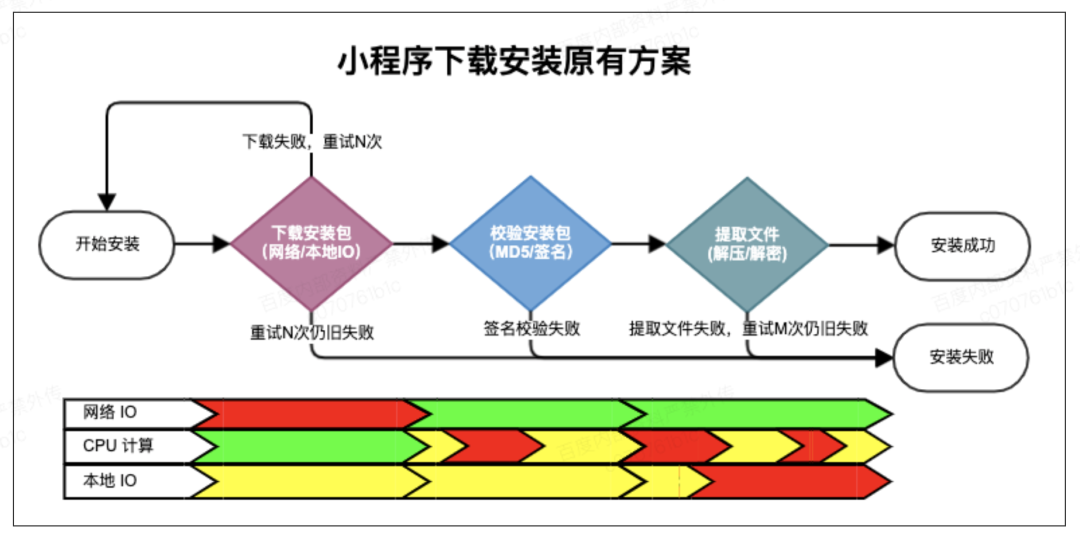
关于性能开销,已知网络 IO 耗时远高于本地 IO 和 CPU 计算。
结合以上分析可得,在读取下载流的同时可以并行完成流式解压和校验文件等处理,从而实现提高小程序下载安装阶段性能的目标,产出流式安装方案如下:
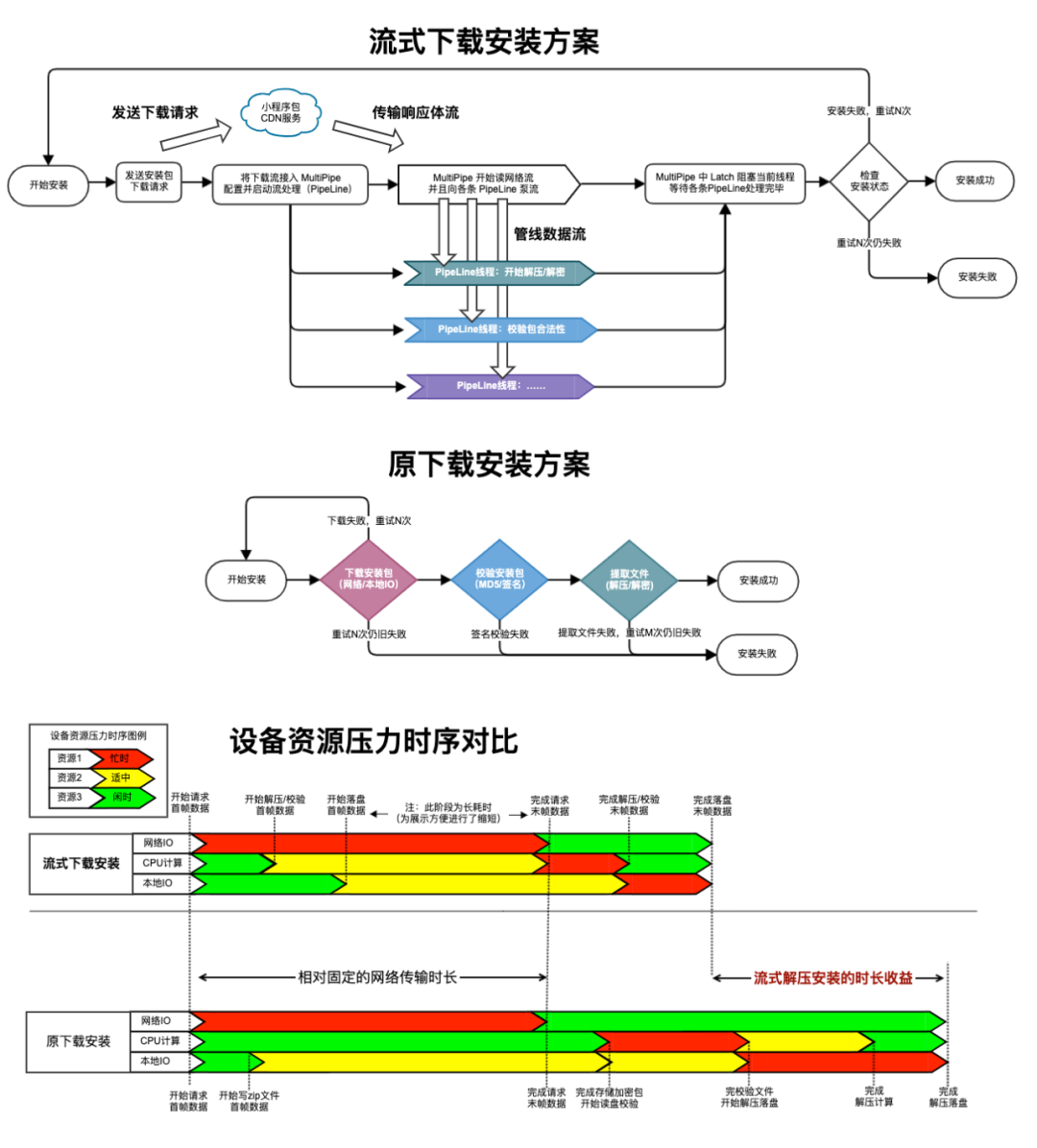
流式下载安装方案如上图所示,实现流式下载安装功能需要实现下载流(response.body)接入和处理流管线(PipeLine)派发这两个问题。
职责设计上 MultiPipe 是一个处理流的基础工具,可以将接入的一个输入流,同时泵到不同线程中的执行管线上,实现输入流的一分多,是一种类似进气歧管的构造,如下图所示:

MultiPipe 在工作过程中,会构造出若干消费者处理管线(PipeLine),由一个 executor 异步执行,同时将输入流中的数据源源不断的泵给各条 PipeLine,直到输入流结束以及所有 PipeLine 全部执行处理完毕。
以下是MultiPipe 的用例,例如输入通道是 okhttp3.ResponseBody#source 的返回结果,即网络请求响应体的二进制流,两个消费者,分别完成签名校验和解压解密的动作。
ReadableByteChannel srcChannel = ... // 例如 okhttp3.ResponseBody#source 方法的返回结果ExecutorService threadPool = Executors.newFixedThreadPool(2); // 可选参数MultiPipe multiplePipe = new MultiPipe(new Consumer<ReadableByteChannel>() { @Override public void accept(ReadableByteChannel source) { // 对整个流做md5,进行签名校验,CPU忙 }}, new Consumer<ReadableByteChannel>() { @Override public void accept(ReadableByteChannel source) { // 对整个流进行解密、解压、写入磁盘,CPU和IO忙 }}) { @Override protected ExecutorService onCreateExecutor(int consumerSize) { return threadPool; }};// 每次能从网络流中读取的最大字节数,对应 okio.Segment#SIZEmultiplePipe.setTmpBufferCapacity(MultiPipe.TMP_BUFFER_CAPACITY); // 开始传输multiplePipe.connect(srcChannel);
小结:小程序调起场景的包下载是一种高优的任务,通过优化处理主包 response.body 的方法,在读取网络流时,对每次读到的字节数组进行拷贝,再通过 Pipe 传输给各个消费者(签名校验、解密解压),从而将串行的包下载到本地、签名校验、解密解压的耗时,降为读网络流、签名校验或解密解压的三者之间的最大耗时。
收益:经过流式下载安装优化,线上包下载时长降低了 21%。
三、实现分析
MultiPipe 是一种可以将一个输入通道,分为多个输出通道的工具类,示例代码如下:
/**
* 可以将一个输入通道,分为多个输出通道的管道
*/
public class MultiPipe {
/** 临时缓存的大小 {@see okio.Segment#SIZE} */
public static final int TMP_BUFFER_CAPACITY = 8 * 1024;
/** 消费者列表 */
private final List<Consumer<ReadableByteChannel>> mConsumerList;
/** 临时缓存的大小 {@see okio.Segment#SIZE} */
private int mTmpBufferCapacity = TMP_BUFFER_CAPACITY;
/**
* 构造方法
*
* @param consumers 消费者列表
*/
@SafeVarargs
public MultiPipe(Consumer<ReadableByteChannel>... consumers) {
mConsumerList = Arrays.asList(consumers);
}
// 设置表示每次最多传输多少字节,例如 8 * 1024
// public final void setTmpBufferCapacity(int maxBytes)
// connect 方法及其依赖的方法:
// transfer、createPipeLineList、launchPipeLineList 方法
// 可供使用方重写的方法:
// setHasPipeBuffer、onStart、onCreateExecutor、onException、
// onTransferComplete、onUpdateProgress、onFinish
}
3.1 创建管线列表(PipeLineList)并连接输入通道(ReadableChannel)
使用方通过 connect 完成所有工作,在该方法中,首先根据构造方法中的消费者列表,创建管线列表和latch,再通过线程池启动各个管线,使各个任务开始工作。
(1) 根据消费者数量创建对应的管线(PipeLine),连接输入通道。latch 的作用是确保所有消费者任务都结束后,才视为执行完成,关键语句为 latch.await();
/** * 连接输入流 * * @param source 输入流 */public final void connect(ReadableByteChannel source) { onStart(source); // 回调 - 开始 // 创建管线列表 List<PipeLine> pipeLineList = createPipeLineList(); // 根据消费者数量,创建latch CountDownLatch latch = new CountDownLatch(pipeLineList.size()); // 让连接各个管线的任务开始工作 ExecutorService executorService = launchPipeLineList(pipeLineList, latch); try { transfer(source, pipeLineList); // 开始传输 onTransferComplete(latch); // 回调 - 传输完成(等待关闭,默认等待latch) } catch (IOException e) { onException(e); // 回调 - 异常处理 } finally { onFinish(source, executorService); // 回调 - 结束 }}
// 当开始连接时,回调给使用方// protected void onStart(ReadableByteChannel source)
/** * 可以由使用方重写,传输完成,处理Latch,可以选择一直等待,也可以设置为超时机制 * * @param latch CountDownLatch */protected void onTransferComplete(CountDownLatch latch) { try { latch.await(); } catch (InterruptedException ignored) { }}
/** * 可以选择是否关闭线程池 * * @param source 输入 * @param executorService 线程池 */protected void onFinish(ReadableByteChannel source, ExecutorService executorService) { closeChannel(source); executorService.shutdown();}
(2) 根据消费者数量创建管线列表
/** * 创建管道列表 * * @return 管道列表 */private List<PipeLine> createPipeLineList() { final List<PipeLine> pipeLineList = new ArrayList<>(mConsumerList.size()); for (Consumer<ReadableByteChannel> consumer : mConsumerList) { pipeLineList.add(new PipeLine(consumer, hasPipeBuffer())); } return pipeLineList;}
(3) 通过线程池启动每个管线
其中线程池可以设置为已有线程池。如果为了避免已有线程池被关闭,则需要重写 onFinish 方法,移除 executorService.shutdown(); 语句。
/** * 调起管线列表,返回执行者实例 * * @param pipeLineList 管线列表 * @param latch 用于确保所有任务一起完成 * @return 执行者实例 */private ExecutorService launchPipeLineList(List<PipeLine> pipeLineList, CountDownLatch latch) { ExecutorService executorService = onCreateExecutor(pipeLineList.size()); for (PipeLine pipeLine : pipeLineList) { pipeLine.setLaunch(latch); executorService.submit(pipeLine); } return executorService;}/** * 由使用方决定如何创建线程池,例如使用已有的线程池 * * @param consumerSize 消费者个数 * @return 可用的线程池实例 */protected ExecutorService onCreateExecutor(int consumerSize) { return Executors.newFixedThreadPool(consumerSize);}
3.2 将每次读到的内容传输给各个管线(PipeLine)
在读取输入通道时,将每次读到的字节缓冲区,传输给各个消费者。
通过 ByteBuffer 接收每次可以读到的内容,再遍历消费者列表,将 ByteBuffer 中的内容写入管线的 sink 通道。
最后,将各消费者管线的 sink 通道关闭。
通过 onUpdateProgress 方法可以回调当前进度给使用方。
/** * 传输 * * @param source 输入流/输入通道 * @param pipeLineList 管线列表 */private void transfer(ReadableByteChannel source, List<PipeLine> pipeLineList) throws IOException { long writeBytes = 0; // 累计写出的字节数 onUpdateProgress(writeBytes); // 通知使用方当前的传输进度 try { final ByteBuffer buf = ByteBuffer.allocate(mTmpBufferCapacity); long reads; while ((reads = source.read(buf)) != -1) { buf.flip(); // 开始读取buf中的内容 for (PipeLine pipeLine : pipeLineList) { if (pipeLine.mSink.isOpen() && pipeLine.mSource.isOpen()) { buf.rewind(); // 重读Buffer中的所有数据 pipeLine.mSink.write(buf); // 向管线中传输内容 } } buf.clear(); writeBytes += reads; onUpdateProgress(writeBytes); // 通知使用方当前的传输进度 } } finally { for (PipeLine pipeLine : pipeLineList) { closeChannel(pipeLine.mSink); // 需要关闭,否则会陷入阻塞 } }}
3.3 管线(PipeLine)的实现
每个消费者任务对应一个管线(PipeLine),在传输网络流的过程中,将每次读到的字节缓冲写入每个管线的 sink 通道,再将管线的 source 通道提供给消费者任务。
其中管线的实现可以基于 java.nio.channels.Pipe,也可以使用带缓冲区的 okio.Pipe。
带缓冲区会增加传输耗时,但可以规避极端情况下消费过慢导致读取速度变慢的问题:例如消费者解码耗时过长,导致TCP误判网络不好,而频繁超时重传。
/** * 管线,也作为工作任务将流导给消费者 */private static class PipeLine implements Runnable { /** 管线消费者 */ final transient Consumer<ReadableByteChannel> mConsumer; /** pipe.source */ final transient ReadableByteChannel mSource; /** pipe.sink */ final transient WritableByteChannel mSink; /** 用来做线程同步 */ transient CountDownLatch mLatch; /** * 构造方法 * * @param hasBuffer 是否带缓冲区 * @param consumer 消费者 */ public PipeLine(Consumer<ReadableByteChannel> consumer, boolean hasBuffer) { mConsumer = consumer; if (hasBuffer) { // 带缓冲区的Pipe okio.Pipe okioPipe = new okio.Pipe(getPipeMaxBufferBytes()); mSink = okio.Okio.buffer(okioPipe.sink()); mSource = okio.Okio.buffer(okioPipe.source()); } else { // 无缓冲区的Pipe try { java.nio.channels.Pipe pipe = java.nio.channels.Pipe.open(); mSource = pipe.source(); mSink = pipe.sink(); } catch (IOException e) { throw new IllegalStateException(e); } } } @Override public void run() { try { mConsumer.accept(mSource); } finally { closeChannel(mSink); closeChannel(mSource); if (mLatch != null) { mLatch.countDown(); } } }}
其中 getPipeMaxBufferBytes 方法可以参考以下实现,基于当前可用内存考虑,返回一个安全的缓冲区容量。
/** 可用内存的比例 */
private static final float FACTOR = 0.75F;
/**
* 返回缓冲区的最大容量
*
* @return 基于实际内存考虑,避免OOM 的可用内存字节数
*/
private static long getPipeMaxBufferBytes() {
Runtime r = Runtime.getRuntime();
long available = r.maxMemory() - r.totalMemory() + r.freeMemory();
return (long) (available * FACTOR);
}
四、总结与展望
总结:本文描述了百度小程序包下载链路中的一种优化手段,即流式下载安装方案。全文以充分利用网络IO、本地IO、CPU资源的目标为线索,分析了原有方案的可优化点,并将优化方案与原有方案进行对比,最后对其核心实现进行了代码分析,介绍了一种支持将一个输入通道,分为多个输出通道的实现方式。
展望:流式下载安装方案需要解压整个小程序包,展望未来,探索一种渐进式的资源加载方案,可以利用这种共享流的方式,尽可能使低优先级的资源下载异步化。
推荐阅读:
|








- 上一条: 使用 Elastic GPU 管理 Kubernetes GPU 资源 2022-04-20
- 下一条: 深度 | 字节跳动微服务架构体系演进 2022-04-20
- 使用百度开发者工具 4.0 搭建专属的小程序 IDE 2022-07-13
- 百度智能小程序巡检调度方案演进之路 2022-05-24
- 开源 | 多端小程序日志采集方案 2021-11-12
- 浅谈小程序开源业务架构建设之路 2022-04-27
- 百度可观测系列 | 如何构建亿级指标的高可用 TSDB 存储集群? 2022-03-31


