助力药物研发,低成本加速AlphaFold训练从11天到67小时,11倍推理加速——开源解决方案FastFold

AlphaFold被Science和Nature评选为2021年十大科学突破之首。潞晨科技与华深智药联合开源的AlphaFold训练推理加速方案FastFold,将GPU优化和大模型训练技术引入AlphaFold的训练和推理,成功将AlphaFold总体训练时间从11天减少到67小时,且总成本更低,在长序列推理中也实现9.3 ∼ 11.6倍提升。
FastFold开源地址:https://github.com/hpcaitech/FastFold
蛋白质与AlphaFold
蛋白质是生命的物质基础,几乎支持着生命的所有功能。它们是由氨基酸链组成的大型复杂分子,而蛋白质的作用主要取决于其独特的三维结构。弄清楚蛋白质折叠成什么形状被称为 "蛋白质折叠问题",在过去的50年里一直是生物学的一个巨大挑战。

AlphaFold预测与实验测量的蛋白质结构对比
实验和计算方法都可用于预测蛋白质结构。实验方法可以获得更准确的蛋白质结构,但需要昂贵的时间和经济成本。计算方法可以用低成本进行高通量的蛋白质结构预测,所以准确的计算方法一直是学术界和工业界努力的方向。2020年,Google DeepMind 推出了最新一代AlphaFold,成功将Transformer模型引入蛋白质结构预测,并取得了巨大的精度提升。AlphaFold使用端到端的模型架构,可以获得原子级别精度的结构预测结果。
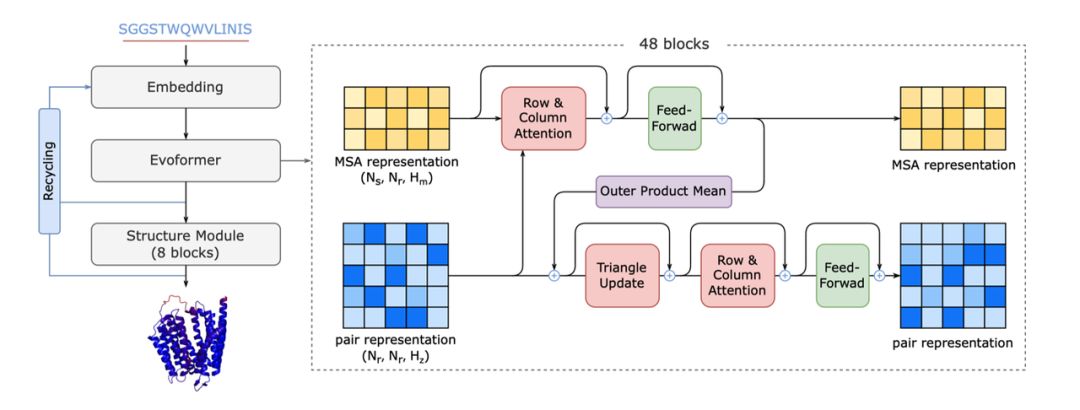
AlphaFold架构
然而,基于Transformer的AlphaFold模型也带来了诸多计算方面的挑战:
1)有限的全局批处理量,使得训练无法利用数据并行性扩展到更多的节点。据DeepMind官方披露,即便使用128个TPU去训练AlphaFold,也需要11天以上才能完成;
2)在训练过程中巨大的内存消耗,远超当前GPU硬件所能提供的显存容量。
3)在推理方面,长序列推理对GPU显存的需求更大。而且一个长序列的推理时间对于AlphaFold模型来说甚至长达到几个小时。
FastFold
为了解决上述难题,我们提出了FastFold,这是一个用于蛋白质结构预测的模型训练推理加速方案。FastFold是世界上首个系统化的针对蛋白质结构预测模型进行训练和推理的性能优化工作。FastFold成功地引入了大模型训练技术,极大降低了AlphaFold模型训练和推理的时间和经济成本。
FastFold包括了一系列基于针对AlphaFold性能特征的GPU优化。同时,通过动态轴并行和对偶异步算子,FastFold实现了很高的模型并行化扩展效率,超越了目前主流的模型并行方法。
动态轴并行。FastFold首次尝试将模型并行技术引入AlphaFold中,并根据AlphaFold的计算特征创新性地提出了动态轴并行技术。不同于传统的张量并行,动态轴并行选择在AlphaFold的特征的序列方向上进行数据划分,并使用All_to_All进行通信。动态轴并行对比张量并行有几个优势:
1)动态轴并行支持Evoformer中的所有计算模块;
2)所需的通信量比张量并行小得多;
3)动态轴并行显存消耗比张量并行低;
4)DAP给通信优化提供了更多的空间,如计算通信重叠。
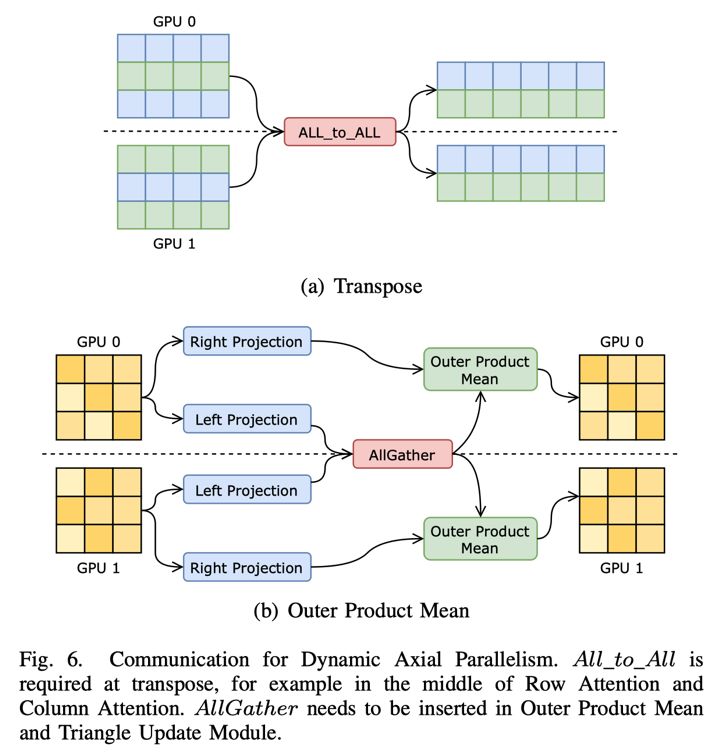
对偶异步算子。对偶异步算子由一对通信算子组成。在模型的前向传播过程中,前一个通信算子触发异步通信,然后在计算流上进行一些没有依赖性的计算,然后后一个通信算子阻塞,直到通信完成。当模型反向传播时,后一个算子将触发异步通信,前一个算子阻塞通信。利用对偶异步算子可以让我们在PyTorch这样的动态图框架上很方便的实现前向传播和反向传播中的计算和通信遮叠。

卓越性能
FastFold对比目前所有的AlphaFold的实现版本都有显著的性能优势:
在训练方面,FastFold可以将训练时间减少到2.81天。与AlphaFold需要11天的训练相比,训练提升3.91倍。与OpenFold(来自剑桥大学的AlphaFold复现版本)相比,训练提升2.98倍,经济成本降低20%。我们将FastFold扩展到拥有512个A100 GPU的超算集群上,聚合峰值性能达到了6.02PetaFLOPs,扩展效率达到90.1%。

在推理方面,FastFold在短序列,长序列,超长序列均有明显的性能优势:
1)在不超过1K的短序列推理的情况下,FastFold与AlphaFold和OpenFold相比,单GPU推理性能分别提升2.01 ∼ 4.05倍和1.25 ∼ 2.11倍。
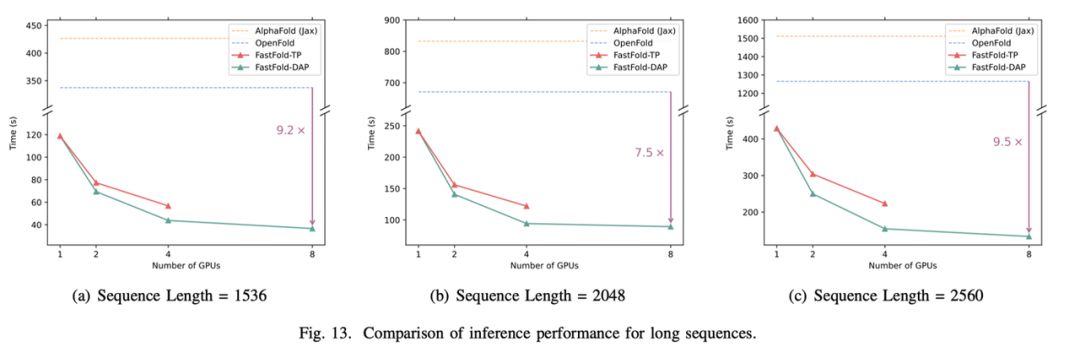
2)在长度为1K ~ 3K的长序列推理中,FastFold可以使用分布式推理大幅度降低推理时间,对比OpenFold提升7.5 ∼ 9.5倍,对比AlphaFold相提升9.3 ∼ 11.6倍。
3)对于长度超过3K的超长序列推理,OpenFold和AlphaFold都因为爆显存而无法推理。FastFold因为支持分布式推理,可以利用多个GPU的计算和显存资源完成超长序列推理的任务。
解决蛋白质结构预测模型训练和推理的在计算上的挑战,对其在结构生物学的广泛应用有重要意义。FastFold大幅度降低了AlphaFold模型训练和推理的时间成本和经济成本,将极大促进新一代药物研发,蛋白质设计,抗体设计等应用场景的革命创新和发展。
背后功臣
FastFold项目的成功,得到了开源AI基础设施Colossal-AI的大力支持。大规模并行AI系统Colossal-AI ,通过高效多维并行、大规模优化库、自适应任务调度、消除冗余内存等方式,旨在打造一个高效的分布式AI系统,作为深度学习框架的内核,帮助用户便捷实现最大化提升AI部署效率,同时最小化部署成本。
Colossal-AI开源地址:https://github.com/hpcaitech/ColossalAI
传送门
FastFold论文地址:https://arxiv.org/abs/2203.00854
FastFold项目地址:https://github.com/hpcaitech/FastFold
Colossal-AI项目地址:https://github.com/hpcaitech/ColossalAI
参考链接
|








- 上一条: 测试在项目流程中的那些事儿 2022-03-18
- 下一条: 2021“科创中国”开源创新榜单公告,openLooKeng入选年度优秀开源产品 2022-03-18
- 推理加速性能超越英伟达FasterTransformer 50%,开源方案打通大模型落地关键路径 2022-05-31
- GTC 2022:GPU推理加速在OPPO NLP场景的优化落地 2022-04-07
- 霸榜GitHub热门第一多日后,Colossal-AI正式版发布 2022-04-07
- 助力双 11 个性化会场高效交付:Deco 智能代码技术揭秘 2021-11-08
- 无缝支持Hugging Face社区,Colossal-AI低成本轻松加速大模型 2022-07-13


