千万级索引的聚合性能优化
当搜索引擎 ElasticSearch 面对千万级索引量的去重统计时,该如何实现快速的响应。本文将结合我们的亲身经历,为读者朋友呈现生产环境中遇到这类问题时的解决思路。
1. 背景
在数周前的某一天,交易团队的同学发现运行在某云上面的订单索引存在严重的增量同步延迟问题,且已经对业务造成了影响。所以将该索引的流量切换到自研搜索平台中,虽说自研搜索不存在增量延迟情况,但却发现查询的 RT 竟高达十几秒,依旧无法解决业务面临的困境。
当时获知该情况时还是比较错愕的,接口 RT 的增长通常是个渐进式的过程,既然存在性能问题应该在早期就有所表现,不至于突然暴涨至十几秒。进一步了解情况后,得知一年前由于当时的自研搜索平台基建不够成熟,该索引的查询流量便一直由三方云服务承接。过去这么长时间,自研搜索平台仅保留着该索引的增量功能,但从未对外提供检索服务。而如今突然将查询流量导入自研平台,不曾预料到会存在如此严重的查询性能问题。
ElasticSearch 作为一款能够轻松应对上亿规模检索的分布式搜索引擎,却发生如此“反常”的表现,下意识就觉得症结应该出在我们的使用方式上。在抓取了相关的 DSL 语句后很快便定位到了问题根源,主要由于业务场景中会对某个查询字段作去重后的计数统计,用到了 ES 中 cardinality 这一项聚合功能。这原本是个非常普通的操作,然而由于匹配到的订单索引数高达千万级,此时的聚合操作需要消耗大量的计算资源,以致RT暴涨。
2. 原因
为了证实慢查是因聚合所致,我们先后做了两次对比实验。
第一次包含去重查询,涉及数据量1450W,用时超 7 秒。
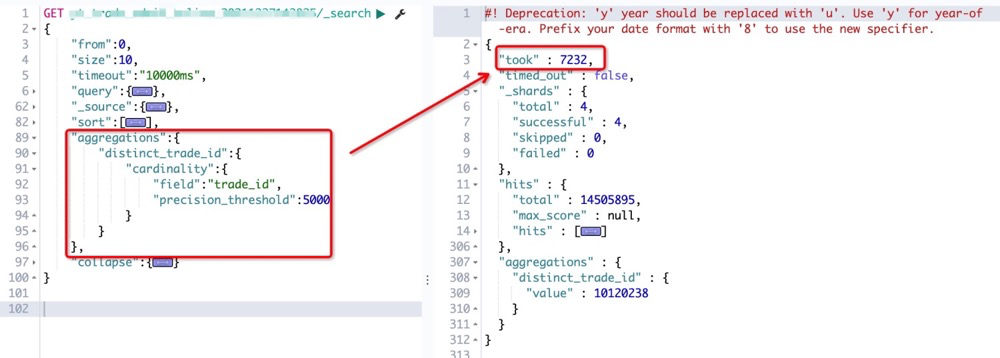
(为什么没有上文提到的超10秒?这是因为期间我们做过一次ES集群扩容,增加节点和分片数后执行效率有所提升)
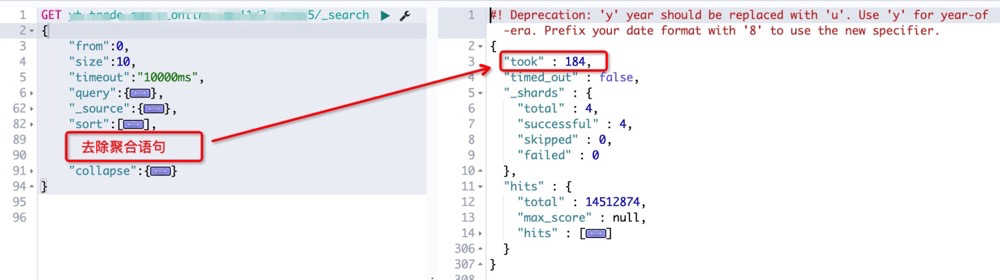
第二次移除聚合语句,此时的查询耗时仅 184 毫秒。
要了解背后的差异,我们需要先对cardinality建立认知。它是基于 HyperLogLog++ (HLL)算法实现的一种近似度量算法。这涉及到对输入条件作 hash 运算,然后根据哈希运算的结果中的 bits 做概率估算从而得到基数。
HLL 本身便是一种非常高效的算法,可毕竟还是需要对全量的数据集合都做一遍 hash 运算。如果是几万、几十万的统计量,用户对于由此产生额外的几十毫秒,甚至上百毫秒性能开销是不太敏感的。可倘若统计量达到百万级,乃至千万级,计算时长增加了几十倍,上百倍,慢查的体感则非常明显。
至此,我们可以得出一个结论:引发慢查的直接原因是由于需要参与 hash 运算的数据集合过于庞大。
3. 步入误区
找到原因后,便可以对症下药。不过很遗憾,当时我们采取的第一个解决方案不仅没有获得预期的效果,反而引发了其他问题。
起初我们认为,既然导致慢查的直接原因是参与 hash 运算的数据量太多了,那我们是否可以在保证不改变召回结果的前提下,通过减少参与聚合统计的数据量来改善性能。
虽然这种聚合方式会导致统计结果失真,但由于系统本就要求召回结果限制在1万以内( 比如匹配查询条件的索引数有2万条,但系统提供的分页能力最多查询前1万条索引),这意味着只需针对排序的前1万条记录作聚合也是可被接受的。
顺着这个思路,我从 ES 文档中找到了 terminate_after。该属性会限制查询请求在每个索引分片中召回的记录数,缓解了因匹配索引数过多而引发的资源开销。
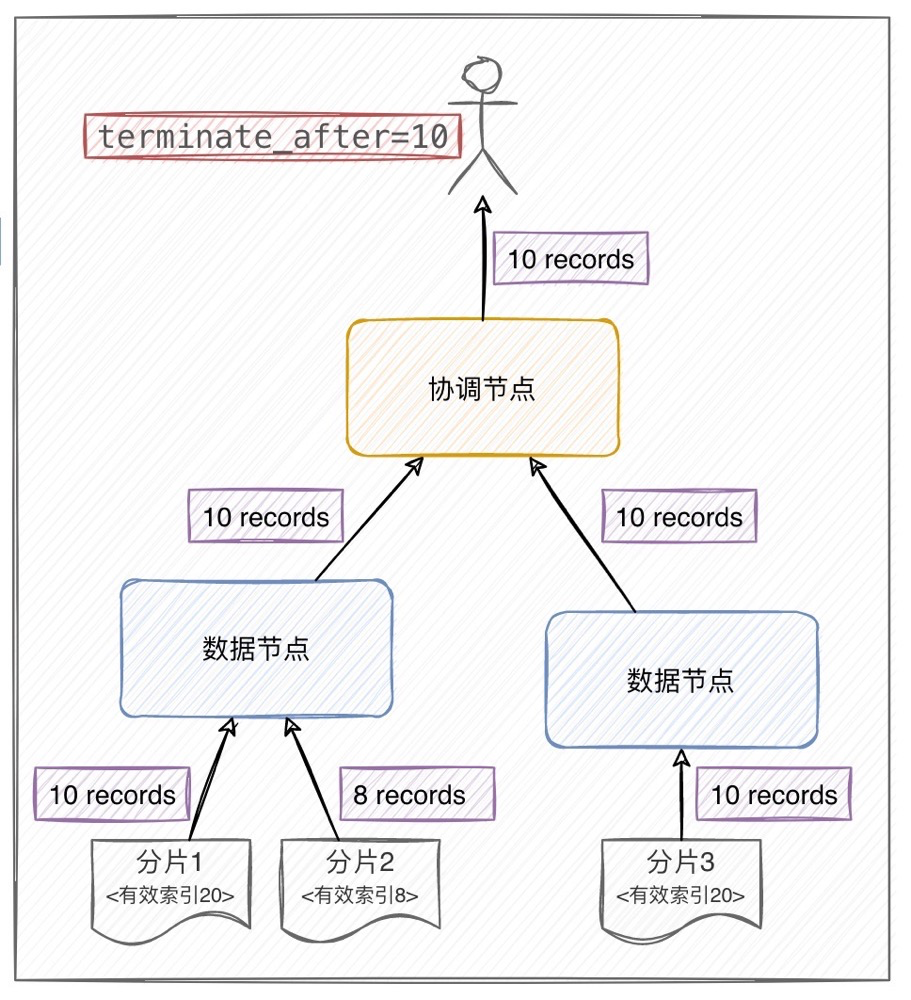
乍一看这确实是我们需要的解决方案,可是上线后才发现使用 terminate_after之后召回的结果不是“最佳”匹配,仅仅是符合过滤条件而已,最直观的表现便是排序效果失效,因此不得已只能弃用该方案。
4. 寻找正解
既然无法减少聚合数据集,我们便只能从节省 hash 运算开销这个方向入手。幸运的是, ElasticSearch 已经为此提供了很好的解决方案,即:hash预运算。
这是一种将 Hash 运算的过程从查询阶段的实时计算,前置到索引创建阶段的策略。在创建索引的同时,计算出待聚合字段的 hash 值并写入索引文件,查询环节便可直接对 hash 进行统计。该策略尤为适用读多写少,且聚合基数庞大的场景。
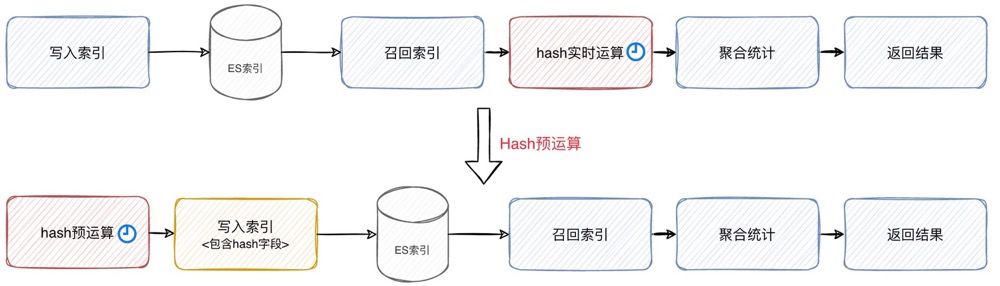
而要启用该策略,我们还需要对ES集群和搜索工程做一些调整。具体如下:
-
在ES集群中安装
mapper-murmur3插件并重启服务。sudo bin/elasticsearch-plugin install mapper-murmur3 -
修改索引模板,为聚合字段设置 hash field。
{ "mappings": { "trade_id": { "type" : "keyword", "fields" : { "hash" : { "type" : "murmur3" } } } } } -
改写查询时的DSL语句,采用
<聚合字段>.hash的形式查询。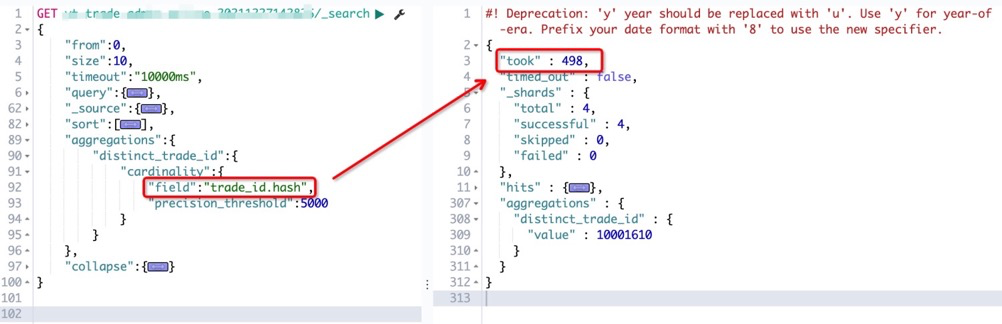
通过 hash 预运算的方式,我们可以看到查询性能由原先的 7 秒多骤降至不到500ms,几乎可以算是完美解决了聚合的性能问题。
5. 思考
虽说本次遇到的问题算是得到了圆满的解决,但是在我看来 hash 预运算也只能作为阶段性方案。假设我们需要统计的数据集合高达数亿、数十亿、百亿,届时我们依旧陷入了因量变而导致质变的局面。
所以,我认为最终的解决方案还是需要在数据的统计量上作出妥协,回归到一开始误入的那条“歧途“。只不过目前还未找到一种即保留排序效果,又能限制聚合索引数量的最优解。如对此有研究的朋友,欢迎留言交流。
|








- 上一条: 运维的线上系统故障总结 2021-12-30
- 下一条: ☕【权限设计系列】「认证授权专题」微服务架构的登陆认证问题 2021-12-30
- 用好组合索引,性能提升10倍不止! 2021-07-22
- 性能提升了200% 2021-08-01
- 记某百亿级mongodb集群数据过期性能优化实践 2021-07-06
- 千亿级高并发MongoDB集群在某头部金融系统中的应用及性能优化实践(上) 2022-05-23
- 千万级并发架构下,关系型数据库应该如何优化?大厂是如何做分库分表的! 2021-10-24


