云端技能包 | 百亿级日志之云原生实时流实战(1)
随着云原生技术的快速发展,微服务架构、容器及 Kubernetes 等技术的不断迭代,对于海量日志的管理提出了更高的要求,包括容器内磁盘是否持久化、HPA 时如何保证数据不丢失、海量日志如何进行可靠的传输、微服务数量达到一定规模时日志该如何管理、如何了解不同云商的收费策略以最大化节省成本,等等。
【云资源优化服务 SpotMax 充分利用云原生特性,基于微服务架构,可在保障用户服务稳定的同时充分利用Spot实例,实现云端降本增效。戳链接了解SpotMax】
“云原生日志流实战”将会通过实操加讲解的方式,和大家一起探讨在云背景下收集海日志的架构及实现细节。接下来为大家展示的这套架构,目前已经经过实践检验,稳定支撑了线上每日百亿至千级别的日志的收集。我们将一步步带领大家动手完成一个部署在k8s集群的日志采集器。
fluentd与Docker
市场上常用的开源日志采集工具一般有logstash、FLUME、 fluentd。其中FLUME、 fluentd的设计理念比较相像。fluentd是基于C + Ruby的一套开源工具,FLUME是分布式的、可靠、可用的Apache项目,但是相对 fluentd来说,配置较为复杂。本次课程我们主要使用的是较为轻量级的开源工具fluentd。
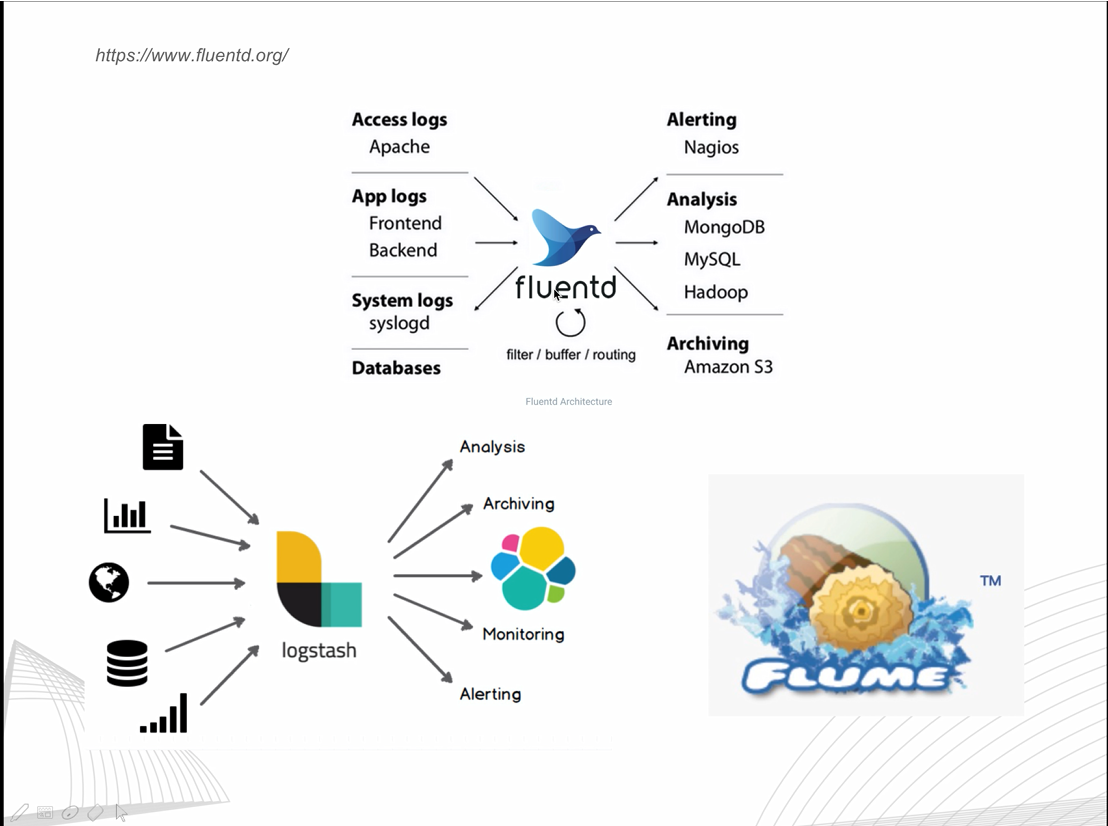
fluentd配置简单,对日志的预处理也非常简单方便。我们来看一下fluentd官网的document(docs.fluentd.org):
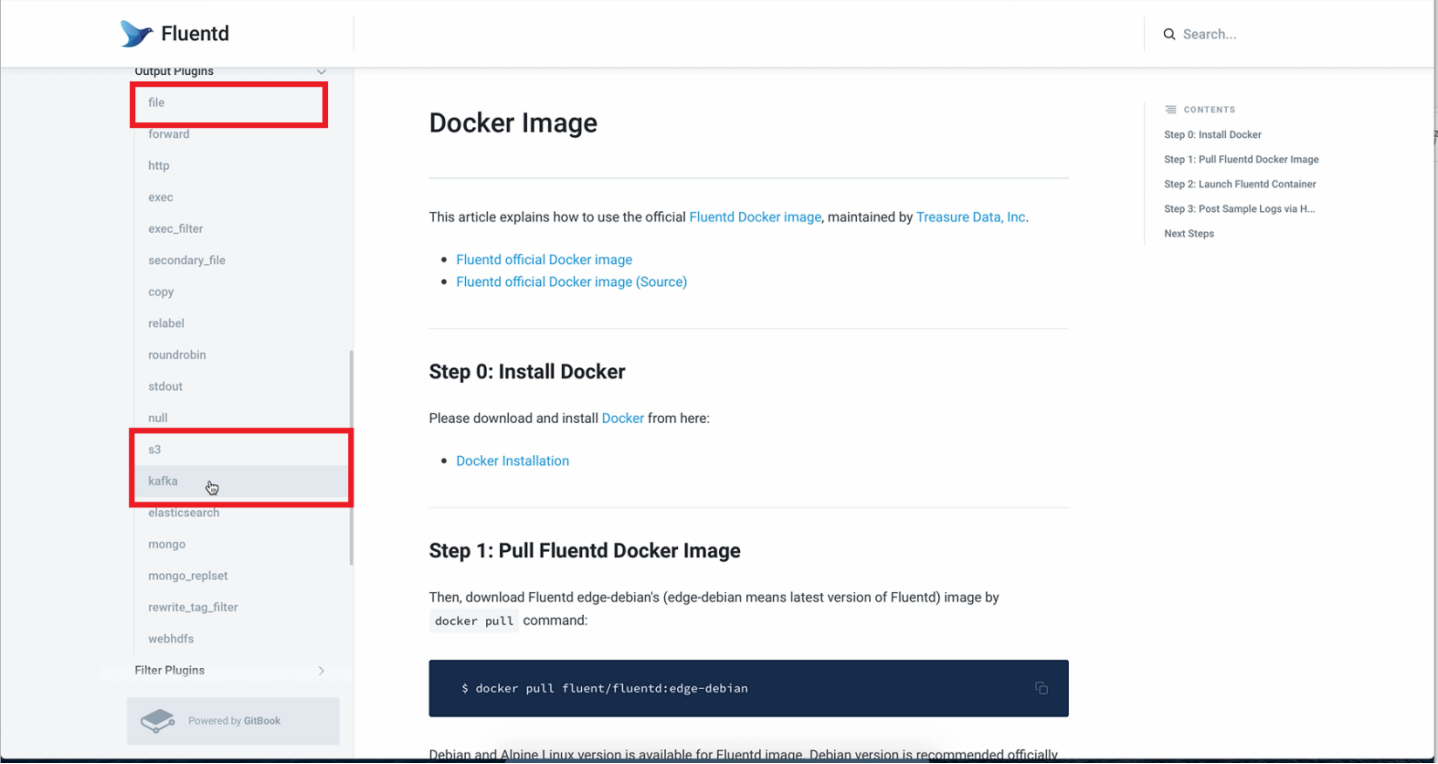
首先来看input、output插件。使用input插件,我们可以从本地、或者通过tcp、udp流获取到日志,然后我们会给每一个日志打tag,后面通过match 该tag可以做进一步的处理:如过滤、格式化等。最终我们可以通过Output插件完成落地。 例如落到本地文件,或者存到亚马逊的s3,或打到kafka,等等。
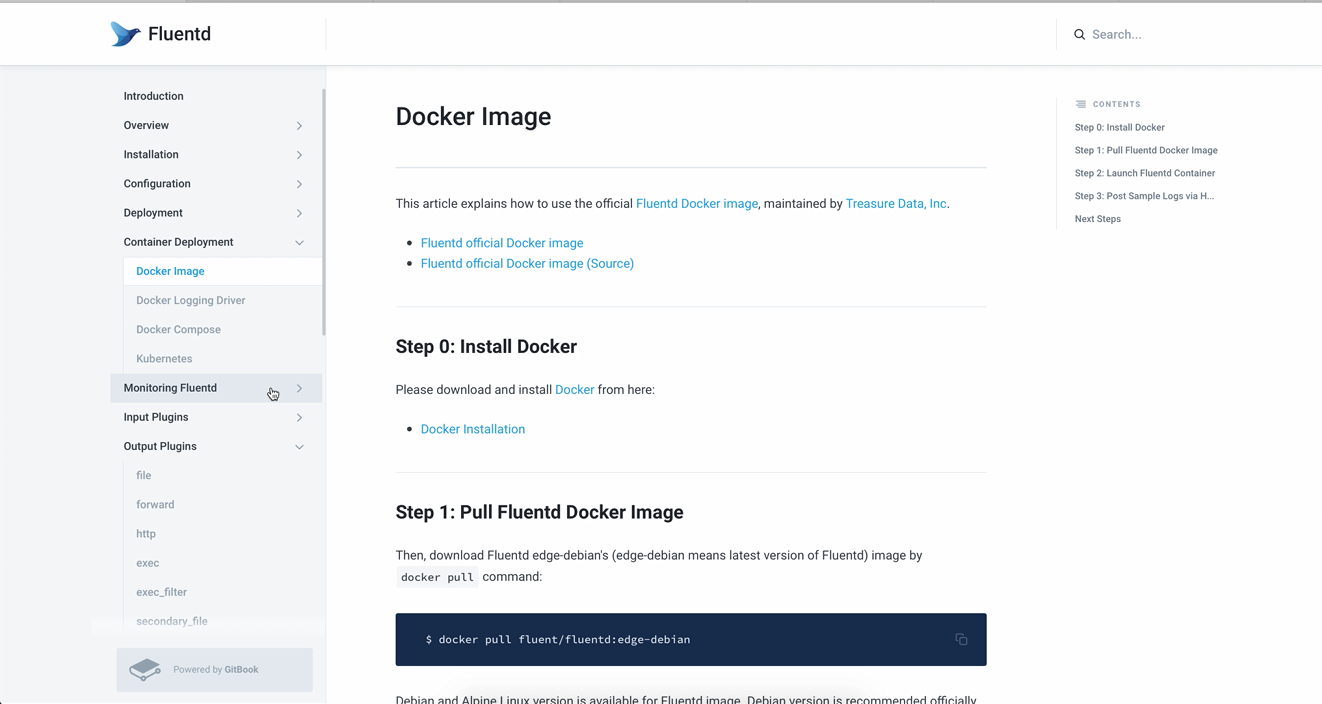
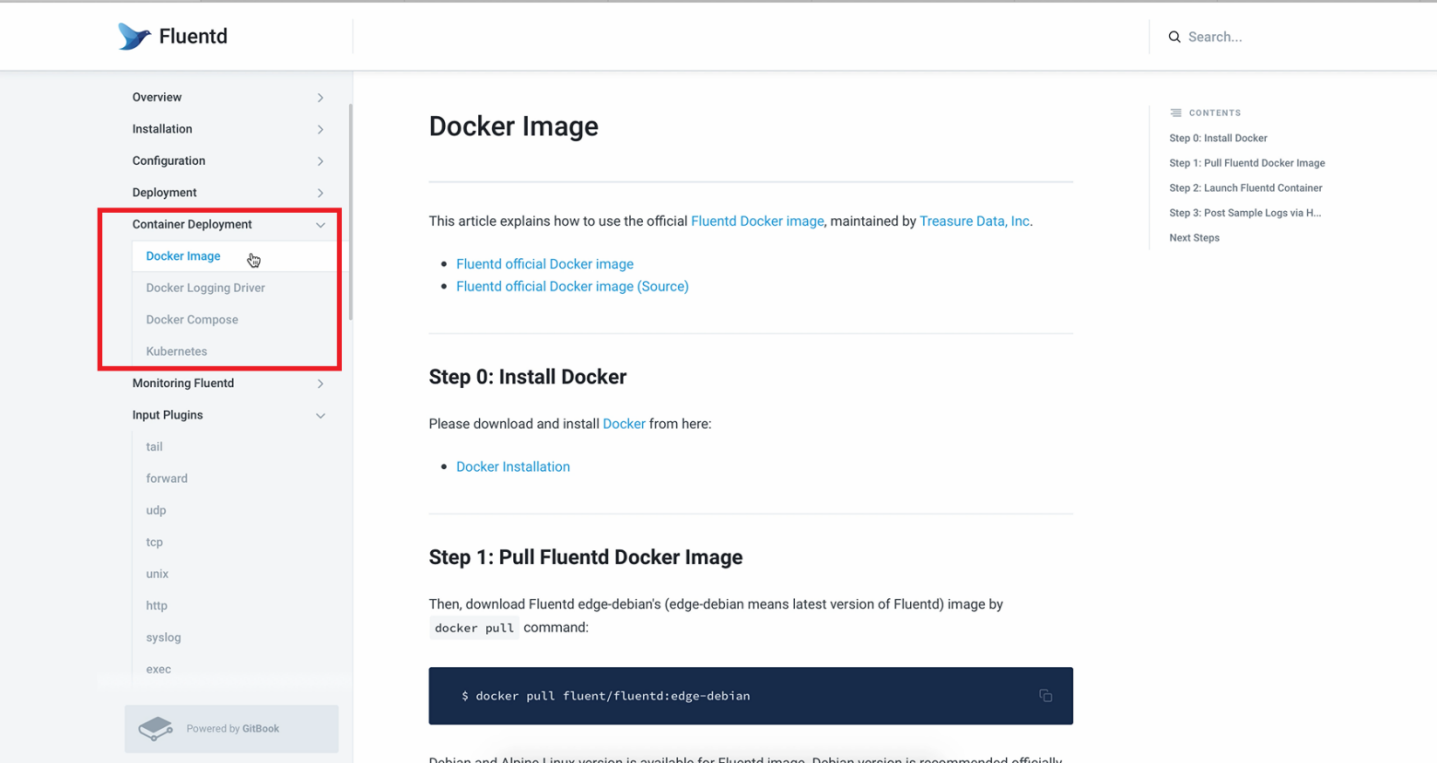
左侧菜单栏中可见container deployment,其中有docker image——这就是docker的一个基础镜像。我们在后面的实操中会从这里获取到基础镜像,来生成一个容器。
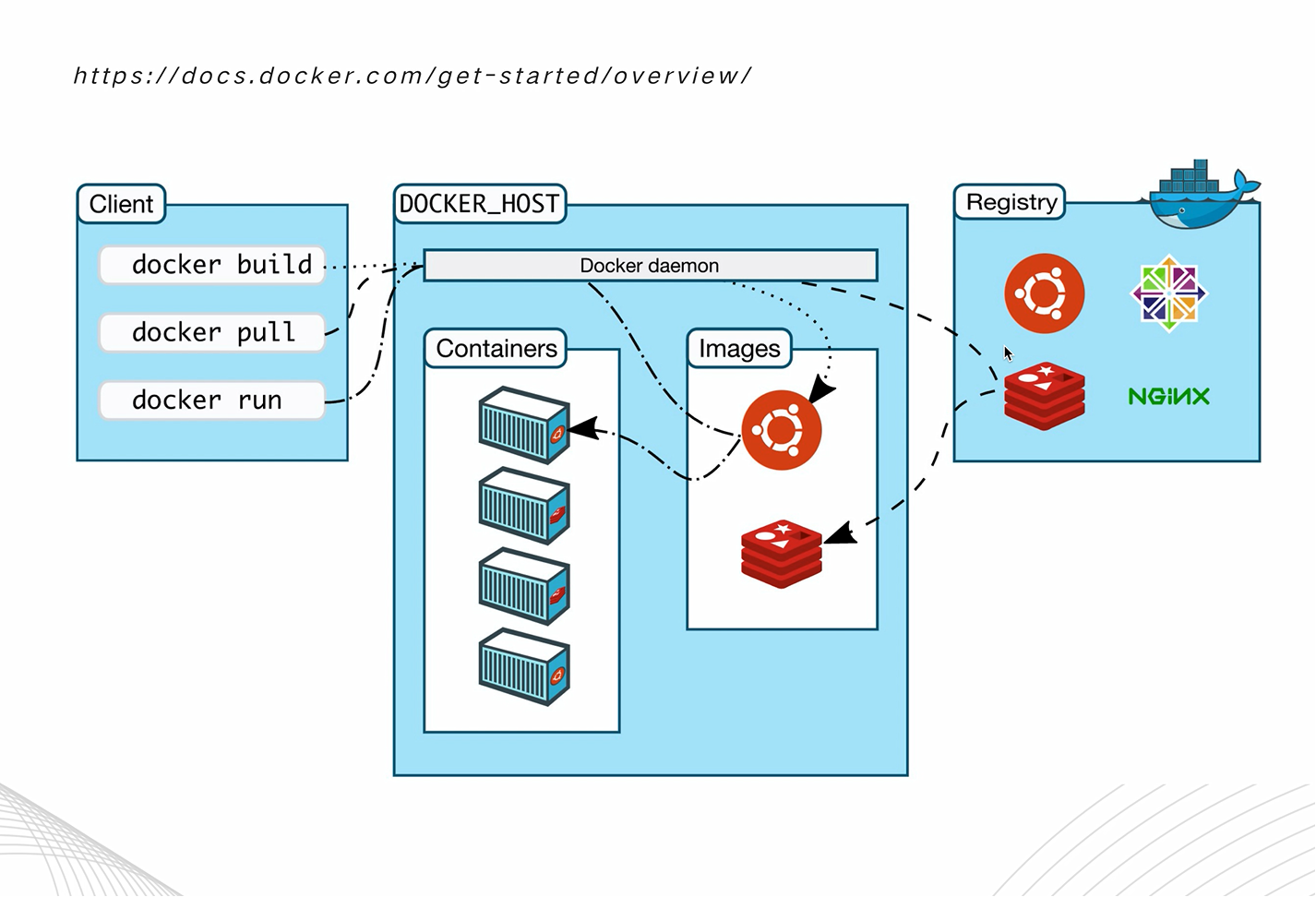
简单介绍一下Docker的特性:docker采用的是沙盒机制,即每个运行的程序是做资源隔离的,不同程序之间不会互相影响。
如下图所示,docker采用了一种远程管理方式。这里有两个概念:image镜像、container容器,他们的关系就像一个类和对象的关系一样,一个image可以生成多个container。
我们可以通过dockerbuild的方式来build一个镜像,可以通过docker pull/push的方式,以及dockerhub(类似github)做一个远程的提交,也可以用docker run指定一个镜像,运行一个容器。
日志采集器架构
首先,我们看一下采集器的简单架构,假设我们有一个http的服务,产生了一个日志。一般的情况下,我们会在本地部署一个crontab做一个定时任务的压缩上传,也可能会把它打到一个实时的kafka队列。
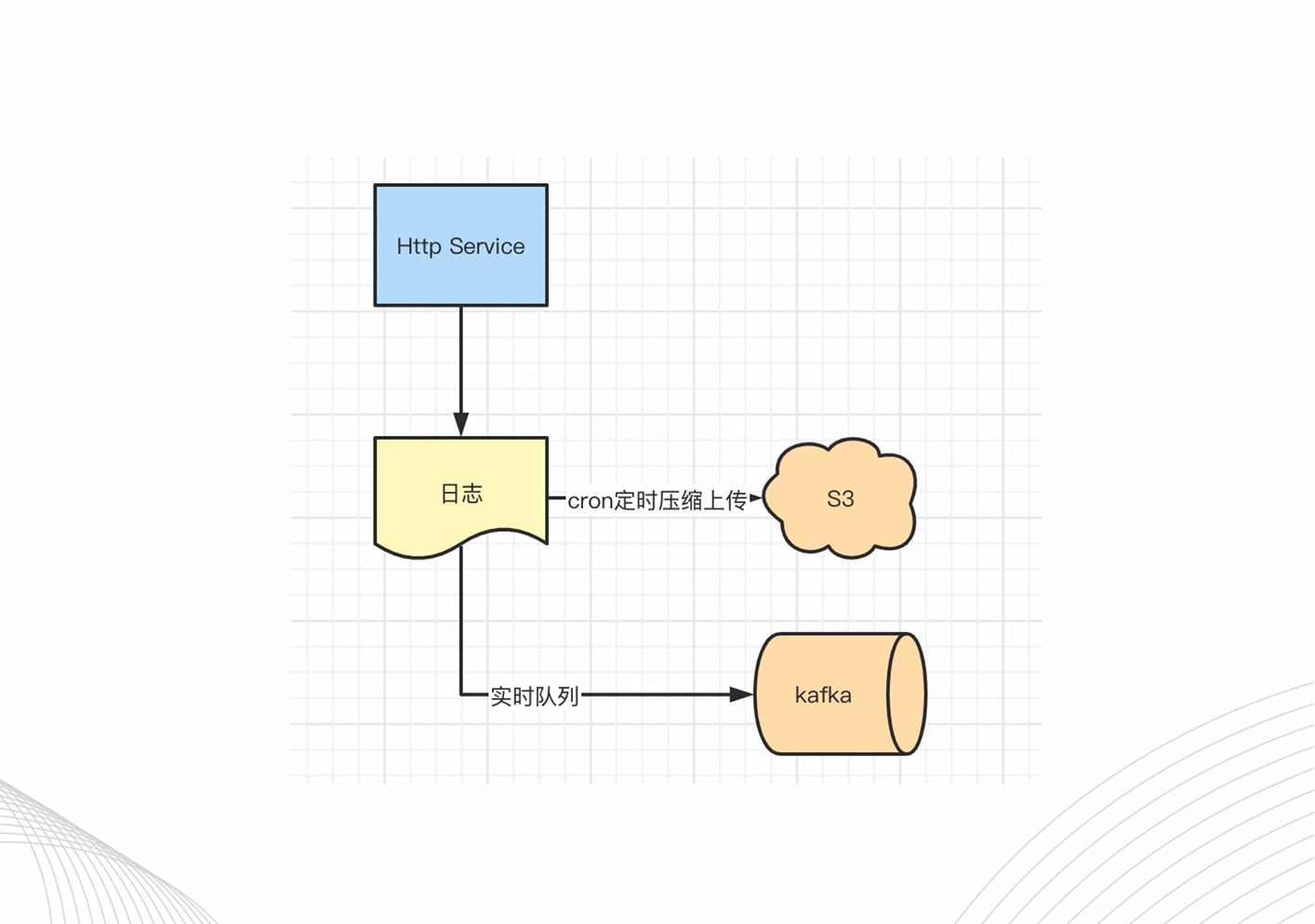
一般情况下这么处理,是没有问题的,但假如我们的服务性能足够好,产生了大量的日志,会发生什么?
如下是CPU的负载图:我们看到每小时都有一个尖峰,因为每小时我们做一个压缩,上传的时候会占一定的CPU,因此非常不利于抗流量服务,做hpa(自动伸缩)。此外,处理日志的程序,跟业务机耦合在一起,也会占一定的资源。

那么,怎么解决这个问题?
假如我们面对的是海量日志,对数据的一致性要求没有那么高,我们就会想到:能不能先把日志通过实时的方式传到另外一个集群,由该集群做支持处理?
因此,我们演化出这样的一个架构:
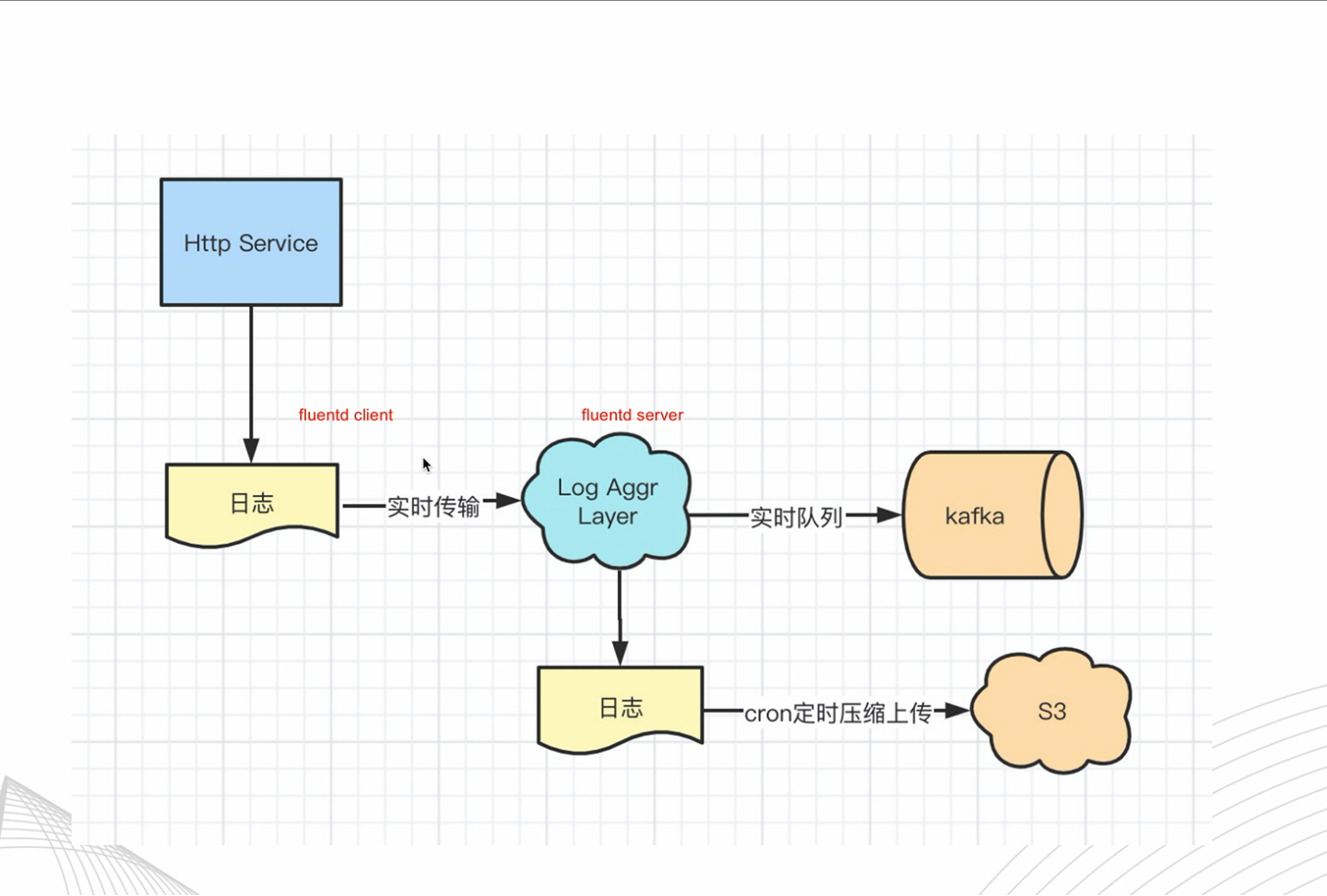
可以看到,该架构中多了一个日志聚合层的集群。我们可以在抗流量服务机器上部署fluentd的client端,在聚合层部署fluentd的server端。这样,我们就可以把日志通过TCP、UDP实时传输到日志聚合层,由聚合层做一个处理。
因此,我们要带领大家完成的,就是如何把日志聚合层,打包成一个产品,最终部署到k8s集群上。 下一期,我们将带领大家完成简单的实操演示。
|








- 上一条: 链路分析 K.O “五大经典问题” 2021-12-17
- 下一条: All in one:如何搭建端到端可观测体系 2021-12-17
- 云端技能包 | 百亿级日志之云原生实时流实战(2) 2021-12-23
- 【云端技能包】k8s 知识- 模块化方式认识Statefulset和Deployment 2021-12-16
- 解析WeNet云端推理部署代码 2021-12-14
- 一文详解Java日志框架JUL 2022-04-27
- Redis 在 vivo 推送平台的应用与优化实践 2022-02-14


