分布式数据库DDL的编译与执行

DDL是数据定义语言,用于定义和管理SQL 数据库中的所有对象的语言,常用的命令有:create,drop,alter等。通常来说,浪潮云溪数据库DDL语句的流程主要分为四个部分,分别是逻辑计划生成,物理计划生成,计划执行和schemachange。本文主要介绍逻辑计划生成,物理计划生成和计划执行。
- 逻辑计划生成 -
逻辑计划生成主要是生成一个planNode逻辑计划节点,每一条SQL都会有自己的planNode,以create table为例,该SQL生成的planNode中包含有CREATETABLE statement信息例如表名,有该表所属数据库的信息,还有该表的列的信息等。planNode生成后将其记录到planner的curplan(curplan有当前计划的属性,包含抽象语法树,planNode,子查询计划等)里,主要流程如下图所示。

以create table语句为例,构建逻辑计划主要是进行memo的构建以及RBO和CBO优化(memo是用来存储查询计划森林的一种数据结构)。首先会初始化一个优化计划的上下文optPlanningCtx,里面会初始化优化器并记录是否使用memo cache进行memo的缓存复用,而这也是DDL与DML语句之间的区别,DDL语句不会复用memo。
构建memo会调用builder的build()方法,对于不同的DDL语句,会调用不同的方法去构建逻辑计划。Create table语句会调用buildCreateTable,构建outScope,主要是生成语句的表达式expr记录在outScope里,最终记录到memo里面。而对于其他的DDL语句则会调用tryBuildOpaque,然后通过ConstructOpaqueDDL函数构建memo的expr。
Memo构建完以后就是进行优化,通过Optmize()函数进入进行RBO和CBO优化,而DDL语句不会进行优化,这也是与DML语句的区别,DML会将优化完的memo加入缓存。然后就是进行逻辑计划planNode的构建,DDL语句中,create语句会执行buildCreateTable进行ConstructCreateTable构建createTableNode,而drop和alter语句则会执行buildOpaque,通过ConstructOpaque返回所对应的planNode,最后将构建好的planNode封装到planTop里面,并且如果是DDL语句会在planTop的flags里面置planFlagIsDDL。
- 物理计划生成 -
逻辑计划生成后,就会根据逻辑计划生成物理计划,主要的流程如下图所示。
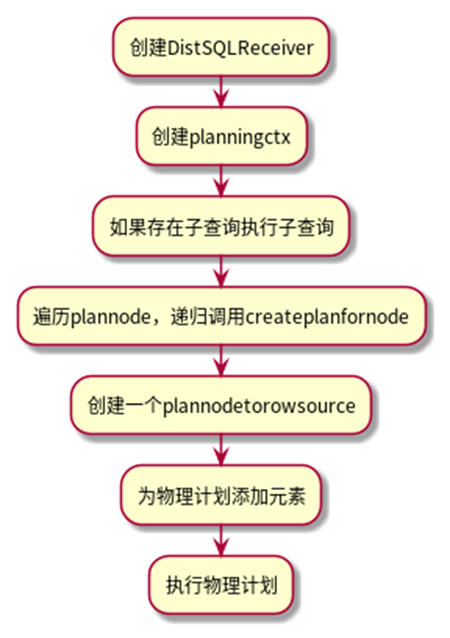
在生成物理计划之前会先判断语句是否需要分布式执行,DDL不会进行分布式执行,会生成一个本地的PlanningCtx(PlanningCtx 包含在单个查询的整个规划过程中使用和更新的数据)。如果SQL语句有子句的话,则会调用PlanAndRunSubqueries函数先执行子句。DDL语句会进入到wrapPlan进行物理计划的生成。在wrapPlan中会深度优先遍历planNode树,找到第一个支持DistSQL processor的planNode然后在该planNode上递归DistSQL优化,如果有等效的 DistSQL 处理器调用createPlanForNode生成物理计划。
函数首先判断当前planNode的类型,调用对应的函数为planNode创建物理计划(如indexJoinNode会调用createPlanForIndexJoin),DDL则会递归调用wrapPlan将planNode包起来继续处理(wrapPlan只包装节点本身而不包括孩子节点)。然后,调用shouldPlanTestMetadata函数判断是否需要进行元数据处理,如果需要则添加相关信息)。然后再进行创建planNodeToRowSource(该结构体),如果被包裹的planNode是flow中的第一个node,且语句类型是RowsAffected(返回受影响行的计数的语句)则可以使用fast path,planNode子树若支持DistSQL优化会在被优化后连接到wrapper。返回wrapper后,为物理计划添加LocalProcessor和LocalProcessorIndexes的元素,LocalProcessors数组包含了所有的planNodeToRowSource,即被包裹的planNode,记录物理计划的ResultTypes。
每当添加新的PhysicalPlan时,都需要覆写ResultRouters,我们将只需要一个result router,由于local processor不是分布式的,确保p.ResultRouters只有一个元素,最后填充计划的endpoints就进入执行流程。
- 执行 -
执行过程的主要流程如下图所示。
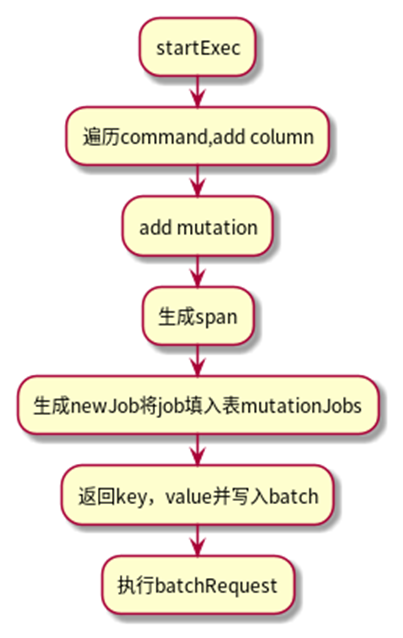
StartExec是具体执行planNode的方法,根据构建的物理计划对表描述符进行操作。StartExec会先对commend遍历(以alter table为例,commend是一个表修改操作的切片),在遍历中获取集群版本信息,检查在当前版本中是否支持添加列的类型,若支持则为true,反之报错;接着按照计划中的列定义信息生成列描述符,若添加的列是主键或含有唯一性约束,还会生成索引描述符,将这些描述符会包装成一个个mutation并添加到表描述符的Mutations字段里;然后根据表、mutation等信息创建一个job,job也是通过系统表system.jobs进行维护,这个job是用来触发及跟踪schema change执行,接着将含有mutations的表描述通过batch更新到系统表"descriptor"里。
执行流程中最主要的结构体就是batch,表描述符会存在batch里面,通过writeTableDescToBatch函数,在该函数里面,首先判断这个表如果不是一个新的表,需要将表的version+1,然后会验证表描述符格式是否良好,调用addUncommittedTable函数,这允许事务在绕过表租赁机制的情况下查看自己的修改,最后是将表描述符的KV写入到batch里面。batch构建完以后就执行batchRequest。
在执行流程结束后,如果需要数据回填的话,则进入到online schema change流程回填数据然后写入系统表完成执行流程,如果不需要的话,则在执行算子的时候就将数据写入到系统表中完成执行流程。
|








- 上一条: 浪潮云溪分布式数据库协议代码解析(2) 2022-05-26
- 下一条: openGauss 版本升级指南 2022-05-30
- 分布式数据库排序及优化 2022-03-07
- 分布式事务的十大神坑 2021-07-18
- 灵活运用分布式锁解决数据重复插入问题 2021-07-27
- 每一个程序员,都渴望成为一名分布式系统架构师 2021-07-11
- 分布式数据库跨版本升级数据迁移方案 2022-07-14


