清华自研时间序列数据库Apache IoTDB原理解析
云智慧 AIOps 社区是由云智慧发起,针对运维业务场景,提供算法、算力、数据集整体的服务体系及智能运维业务场景的解决方案交流社区。该社区致力于传播 AIOps 技术,旨在与各行业客户、用户、研究者和开发者们共同解决智能运维行业技术难题,推动 AIOps 技术在企业中落地,建设健康共赢的AIOps 开发者生态。
智能运维领域的数据特点
指标数据作为运维场景中的重要观测项,是服务可用性监控、系统健康度度量等场景的主要数据来源。从下面架构示意图中们可以看出,采集器采集服务器上各种指标数据,发往消息队列,通过实时流处理和离线计算最终存入到数据库。
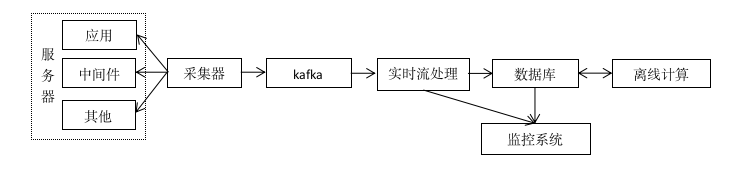
在这个上述场景中,我们往往会遇到以下几种数据挑战:
- 我们日常需要监控的指标数量超百万,峰值时甚至会达到千万级,每天沉淀下来的指标数据量达到GB级别,甚至TB级别。
- 针对指标数据的日常分析行为通常涉及到近1小时、近1天、近7天、近30天、近1年等多种时间跨度。对范围查询的性能有一定要求。
3)在数据传输过程中,由于受到网络、设备资源等原因造成短时间内出现乱序到达、缺丢点、峰谷潮、重复数据等问题
4)由于服务器或设备本身原因,采集的指标数据时间往往不够精准,导致数据粒度不齐整的问题。例如对于秒级别的指标,上一个采集的数据点的时间戳是2021-01-01 10:00:00:000下一个数据点的有可能是2021-01-01 10:00:01:015。而不同的指标相同时刻采集的数据点时间戳分别是2021-01-01 10:00:00:000和2021-01-01 10:00:00:015。
至此整体的需求基本已经明确,在做数据库选型时需要满足以下需求:
1)支持数据长时间存储;
2)支持大时间跨度的快速检索;
3)高速的数据吞吐能力;
4)高效的数据压缩比;
5)能够有效的解决数据的乱序、缺失值、粒度不齐整以及重复数据等数据质量问题。
智能运维领域的时序数据该如何存储
对于上述的需求我们该如何选型?是传统的关系型数据库,还是通用的NoSQL数据库,亦或是专用的时序数据库?他们能否满足上述数据库选型的需求?
数据如何存储还要结合数据本身的特点。这里以一个真实场景中的案例,某运营商有约3000万的监控指标,并且采集的过程中存在空值数据、数据缺失、数据重复等情况,甚至会出现新的指标。如果一分钟采集一次指标在允许一定数据延迟的情况下,写入速率要超过50w/s,一天需要存储432亿的数据,这对关系数据库来说无论是从写入速率是在查询时效都很难满足需求。
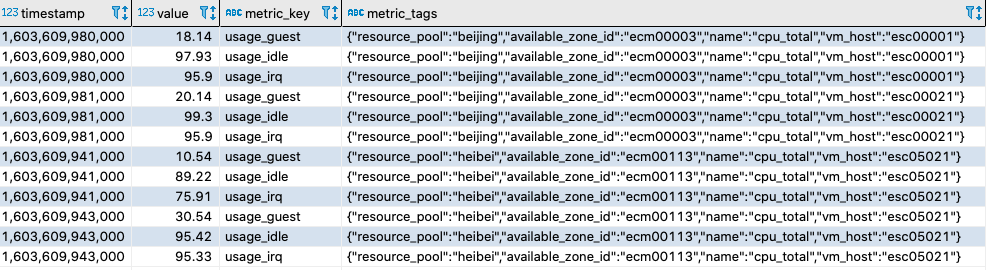
再看看通用的NoSQL数据库,首先先简单梳理一下这些指标数据的特点,我们发现这些指标数据除了有时间戳和指标值外还会有一些tag 来标识数据来自那台机器,通过采集器实际的采集数据的样例如下图所示:

在通用的NoSql 数据库虽然可以满足吞吐量性能以及查询性能,但是为了满足指标的动态变更我们只能按照一个设备一张表或者多个设备共享一张表的建模方式如下图所示。
无论是一个设备一张表还是多个设备共享一张表的存储方式,为了能够区分数据来哪个指标,我们只能把tags作为一列进行存储,不难发现这种这样建表方式会出现大量的tag数据冗余存储的问题。并且通用的NoSql数据库往往在解决数据重复的问题上并不友好,更多的是依靠一些排重策略来实现。排重策略通常有两种:一种是依靠外部的排重方式达到存储时数据已经排重,另一种是存储不排除查询时依靠sql来做排重。如果使用第一种数据排重无疑会增加系统的复杂度,如果使用第二种这会导致在处理过程的出现数据冗余存储的情况。而且通用的NoSql数据库还存在一个问题就是:没有原生操作支持粒度卡齐或者线性填充来解决数据质量差的问题。
然而我们上面的遇到的一些数据挑战实际是属于时序数据库要解决的典型问题,市面上也有许多优秀的时序数据库,例如InfluxDB、Apache IoTDB等,它们在高吞吐、低延时查询、数据去重、数据填充、数据降采样、高压缩比等功能方面皆能满足第一章中的数据存储需求。接下来我们来重点看下完全开源的Apache IoTDB它是如何设计的。
IoTDB的设计
IoTDB的架构
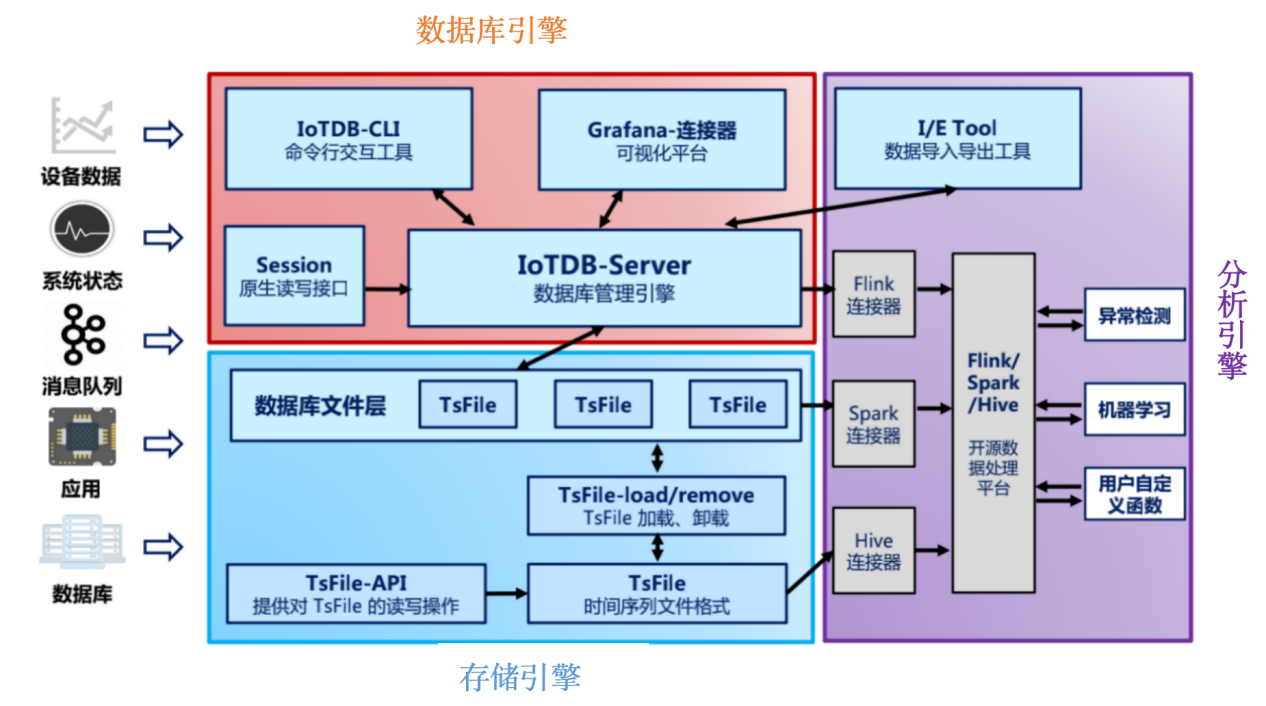
IoTDB是基于LSM-Tree(Log-Structured Merge Tree)的架构进行设计的列式存储数据库,LSMtree的核心思想就是放弃部分读的能力来换取最大的写入能力。从下图中IoTDB的整体架构图中我们可以看出IoTDB主要有三部分构成:分别是数据库引擎、存储引擎和分析引擎。
数据库引擎主要是负责sql语句的解析、数据写入、数据查询、数据删除等功能。
存储引擎主要是由TsFile来组成也是IoTDB的最具特色的设计,它不仅可以为IoTDB存储引擎使用,而且还可以直接通过链接器供分析引擎使用,同时还对外开放了TsFile的API,用户也可以自己直接通过API来获取里面的内容。
分析引擎主要是用于与开源的数据处理平台对接等。
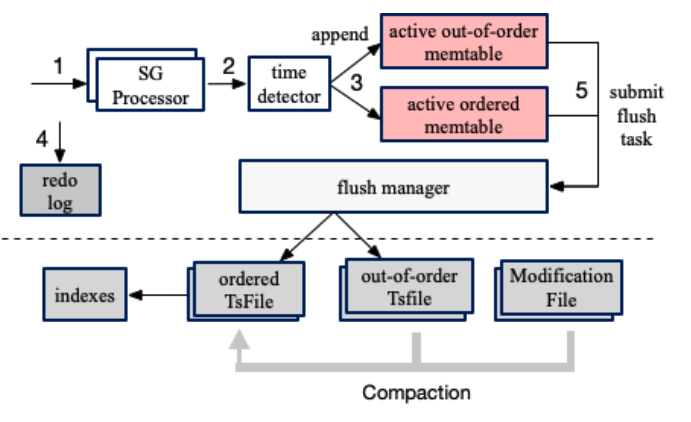
IoTDB的数据读写流程
上面提到了IoTDB是基于LSM-Tree的思想来实现的,从以下数据写入流程图中我们可以看出:数据经过time detector时会根据内存中维护的最大时间戳来判断是否数据有序,在内存缓冲区memtable中分为有序序列和乱序序列,同时为了保障在断电后数据不丢失,IoTDB也会把数据写入到WAL(Write-Ahead Logging)中,到此客户端的数据写入就已经完成。随着数据的不断写入,memtable中的数据达到一定的程度后,IoTDB通过submit flush task把memtable变成Immutable最终刷到磁盘变成Sstable即TsFile文件,同时当持久化的TsFile文件达到一定程度会触发合并。
上面介绍了IoTDB数据的写入流程后,我们再来看下IoTDB核心的查询流程。如下图所示,当客户端发送查询请求时,首先通过Antlr4进行sql 解析,然后去内存中的MemTable、ImmuTable和硬盘中TsFile中进行查询。当然,IoTDB这里会通过BloomFilter 和索引来提高数据的查询效率。我们知道BloomFilter的原理是哈希结果不存在那么一定没有此数据,如果哈希结果存在,IoTDB那么还需要继续借助索引进行进一步的查找。

TsFile结构
上一节IoTDB的读写流程都离不开TsFile,那我们看看IoTDB最核心TsFile是怎样一个结构。从下面的TsFile 结构示意图中可以看出TsFile整体分为两部分:一部分是数据区,另一部分是索引区。
数据区主要包括Page 数据页、Chunk数据块和ChunkGroup数据组。其中Page 由一个 PageHeader 和一段数据(time-value 编码的键值对)组成,Chunk数据块由多个Page和一个Chunk Header组成,ChunkGroup 存储了一个实体(Entity) 一段时间的数据,它由若干个 Chunk, 一个字节的分隔符 0x00 和一个ChunkFooter组成。
索引区主要包括TimeseriesIndex、IndexOfTimeseriesIndex和BloomFilter,其中TimeseriesIndex包含1个头信息和数据块索引(ChunkIndex)列表,头信息记录文件内某条时间序列的数据类型、统计信息(最大最小时间戳等);数据块索引列表记录该序列各Chunk在文件中的 offset,并记录相关统计信息(最大最小时间戳等);IndexOfTimeseriesIndex用于索引各TimeseriesIndex在文件中的 offset;BloomFilter针对实体(Entity)的布隆过滤器。下图中TsFile包括两个实体 d1、d2,每个实体分别包含三个物理量 s1、s2、s3,共 6 个时间序列,每个时间序列包含两个 Chunk。
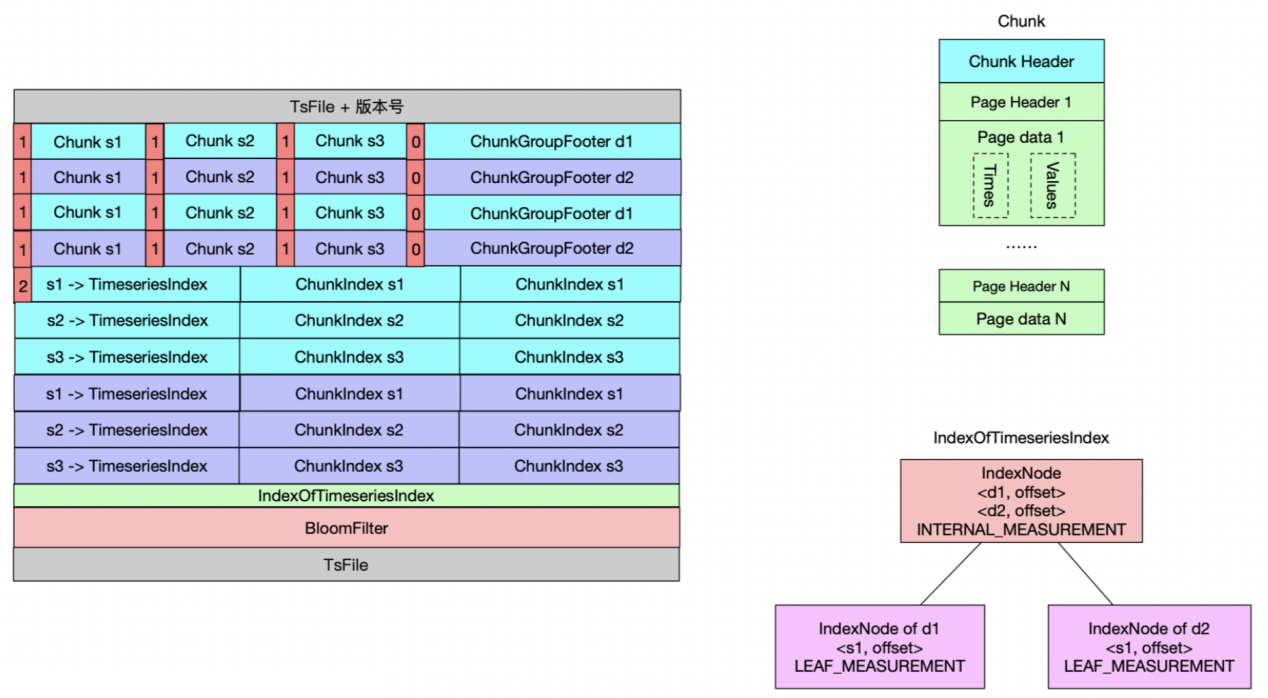
TsFile索引构建
TsFile中所有的索引节点构成一棵类B+树结构的多叉索引树,这棵树由两部分组成:实体索引部分和物理量索引部分。下面举一个例子来展示索引树的构成:假设我们设置树的度为10,我们有150个设备每个设备有150个测点共计22500条时间序列,这时我们需构建一个深度为6的索引树即可,这时我们查询数据所在位置需做6次磁盘的IO,具体如下图所示。
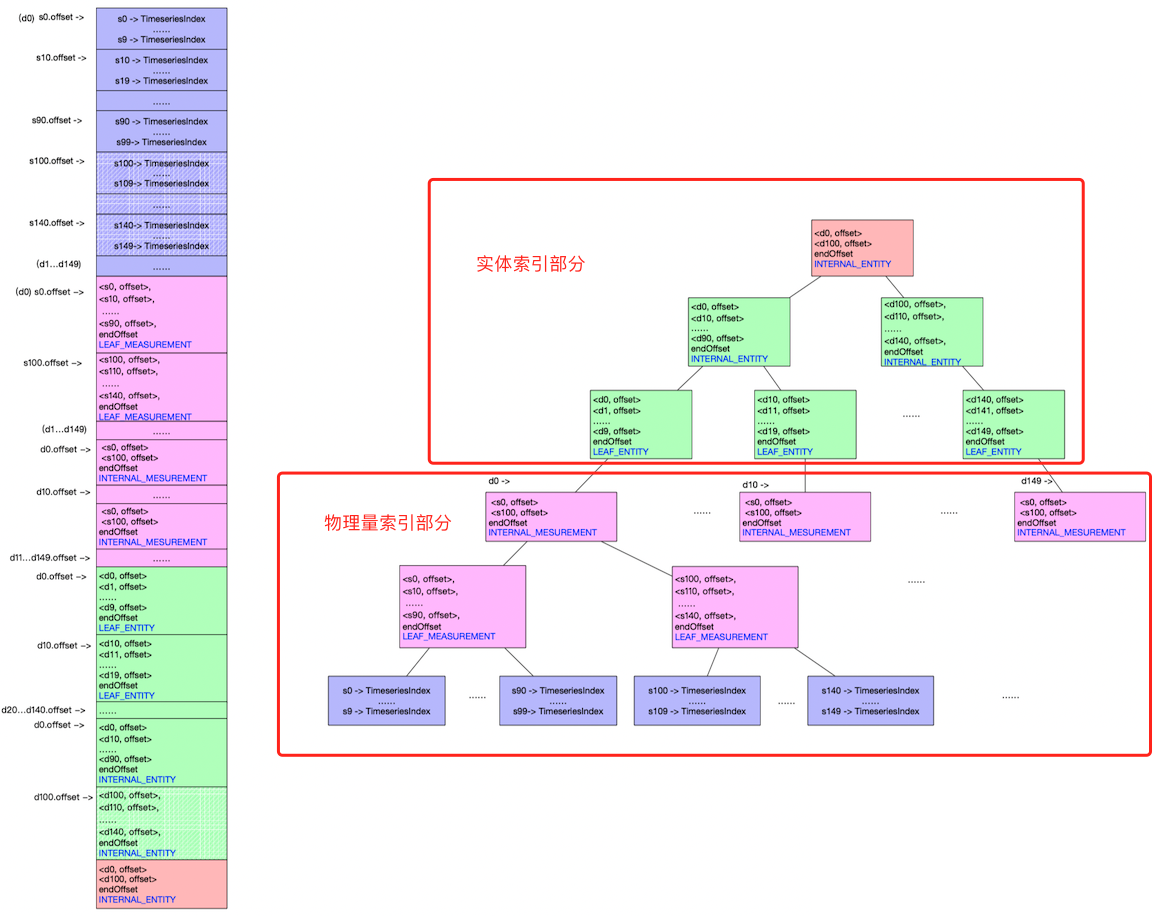
上面这种方式看似磁盘IO次数比较多,这是由于我们设置的树的度比较小从而导致整体树的深度比较大。如果我们把树的度增大到300,在实体索引部分一个高度为2的子树即可实现90000个设备存储,同理一个高度为2个物理量索引部分也可存放90000个物理量,最终形成的整个索引树可存放81亿条时间序列。这时我们再读取数据只需要做4次磁盘IO即可定位到我们需要的数据位置。
TsFile查询流程
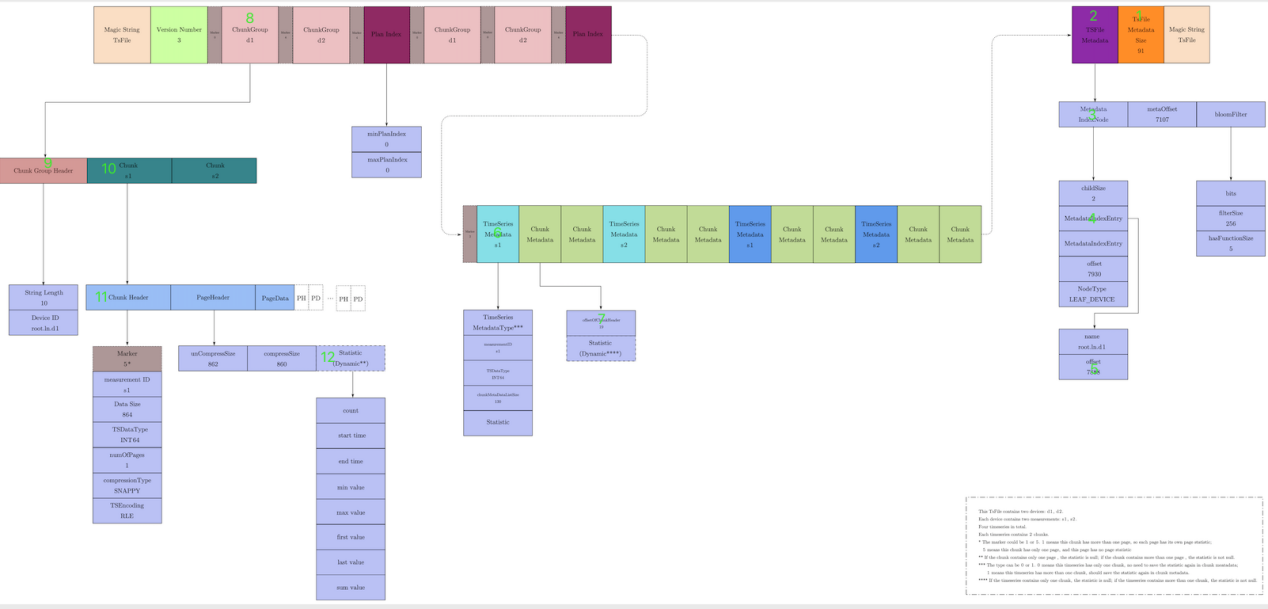
在了解了TsFile的结构以及索引的构建,那么IoTDB是如何在TsFile内部完成一次查询的,下面用一个具体查询例如select s1 from root.ln.d1 where time>100 and time<200,来演示在TsFile中是如何定位到所需数据。他的具体步骤以及示意图如下所示:
1)读取TsFile MetadataSize信息
2)根据TsFile MetadataSize和offset获取TsFile MetaData的位置
3)读取Metadata IndexNode中的数据,通过MetadataIndexEntry中的name定位到设备root.ln.d1
4)读取到设备root.ln.d1中的offset偏移量,根据偏移量找到TimeSeries Metadata 中的信息进而找到s1
5)通过ChunkMetadata记录的统计信息startTime和endTime与我们查询的区间(100,200)对比获取到root.ln.d1设备下面测点s1的偏移量
6)根据s1中的偏移量可以直接获取到ChunkGroup
7)依次通过ChunkGroupHeader、ChunkHeader定位到Chunk数据依次读取Page中的PageHeader,如果时间区间在(100,200)中那么我们就直接读取PageData数据。
总结
本文抛砖引玉简单的介绍了IoTDB的读写以及TsFile的核心文件的设计,实际上IoTDB整体设计和实现还是比较杂,里面涉及了很多的细节这里就不再展开介绍了。
写在最后
近年来,在AIOps领域快速发展的背景下,IT工具、平台能力、解决方案、AI场景及可用数据集的迫切需求在各行业迸发。基于此,云智慧在2021年8月发布了AIOps社区, 旨在树起一面开源旗帜,为各行业客户、用户、研究者和开发者们构建活跃的用户及开发者社区,共同贡献及解决行业难题、促进该领域技术发展。
社区先后 开源 了数据可视化编排平台-FlyFish、运维管理平台 OMP 、云服务管理平台-摩尔平台、 Hours 算法等产品。
可视化编排平台-FlyFish:
项目介绍:https://www.cloudwise.ai/flyFish.html
Github地址: https://github.com/CloudWise-OpenSource/FlyFish
Gitee地址: https://gitee.com/CloudWise/fly-fish
行业案例:https://www.bilibili.com/video/BV1z44y1n77Y/
部分大屏案例:

请您通过上方链接了解我们,添加小助手(xiaoyuerwie)备注:飞鱼。加入开发者交流群,可与业内大咖进行1V1交流!
也可通过小助手获取云智慧AIOps资讯,了解云智慧FlyFish最新进展!

|








- 上一条: T3 出行 Apache Kyuubi Flink SQL Engine 设计和相关实践 2022-03-30
- 下一条: 汪源做客阿里云大咖说,论道 PolarDB 数据库开源与存储生态 2022-04-01
- 普通开发者,如何成为Apache顶级项目的commiter ?| 人物专访 2022-01-20
- 一文解析Apache Avro数据 2021-12-31
- Promise.race() 原理解析及使用指南 2021-09-08
- Promise.allSettled() 原理解析及使用指南 2021-09-06
- ⭐openGauss数据库源码解析系列文章—— AI查询时间预测⭐ 2021-09-24


