4种Kafka网络中断和网络分区场景分析
摘要:本文主要带来4种Kafka网络中断和网络分区场景分析。
本文分享自华为云社区《Kafka网络中断和网络分区场景分析》,作者: 中间件小哥。
以Kafka 2.7.1版本为例,依赖zk方式部署
3个broker分布在3个az,3个zk(和broker合部),单分区3副本
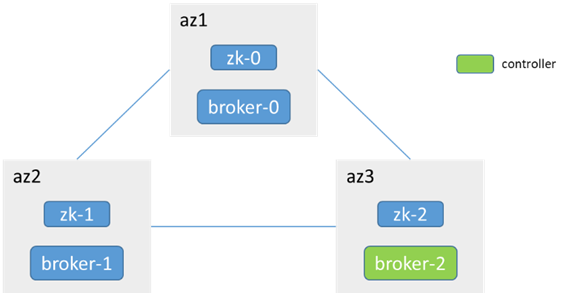
1. 单个broker节点和leader节点网络中断
网络中断前:
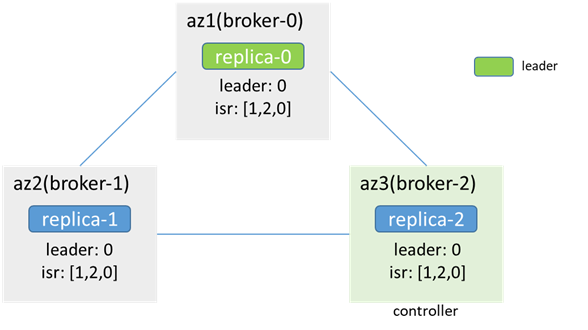
broker-1和broker-0(leader)间的网络中断后,单边中断,zk可用(zk-1为leader,zk-0和zk-2为follower,zk-0会不可用,但zk集群可用,过程中可能会引起原本连在zk-0上的broker节点会先和zk断开,再重新连接其他zk节点,进而引起controller切换、leader选举等,此次分析暂不考虑这种情况),leader、isr、controller都不变

az2内的客户端无法生产消费(metadata指明leader为broker-0,而az2连不上broker-0),az1/3内的客户端可以生产消费,若acks=-1,retries=1,则生产消息会失败,error_code=7(REQUEST_TIMED_OUT)(因为broker-1在isr中,但无法同步数据),且会发两次(因为retries=1),broker-0和broker-2中会各有两条重复的消息,而broker-1中没有;由于broker-0没有同步数据,因此会从isr中被剔除,controller同步metadata和leaderAndIsr,isr更新为[2,0]
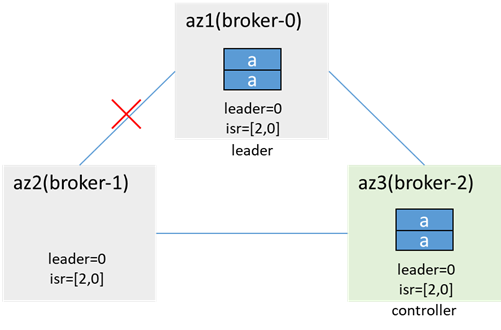
网络恢复后,数据同步,更新isr
2. 单个broker节点和controller节点网络中断
broker和controller断连,不影响生产消费,也不会出现数据不一致的情况
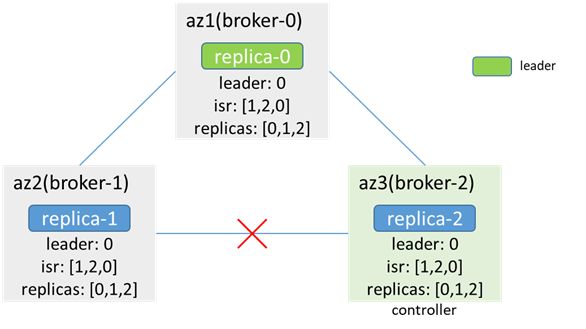
而当发生leader和isr变化时,controller无法将leader和isr的变化更新给broker,导致元数据不一致

broker-0故障时,controller(broker-2)感知,并根据replicas选举新的leader为broker-1,但因为和broker-1网络中断,无法同步给broker-1,broker-1缓存的leader依然是broker-0,isr为[1,2,0];当客户端进行生产消费时,如果从broker-2拿到metadata,认为leader为1,访问broker-1会返回NOT_LEADER_OR_FOLLOWER;如果从broker-1拿到metadata,认为leader为0,访问broker-0失败,都会导致生产消费失败
3. 非controller节点所在az被隔离(分区)
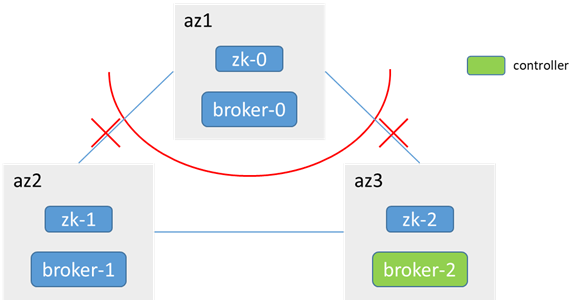
zk-0和zk-1、zk-2不通,少于半数,az1内zk不可用,broker-0无法访问zk,不会发生controller选举,controller还是在broker-1
网络恢复后,broker-0加入集群,并同步数据
3.1 三副本partition(replicas:[1,0,2]),原leader在broker-1(或broker-2)
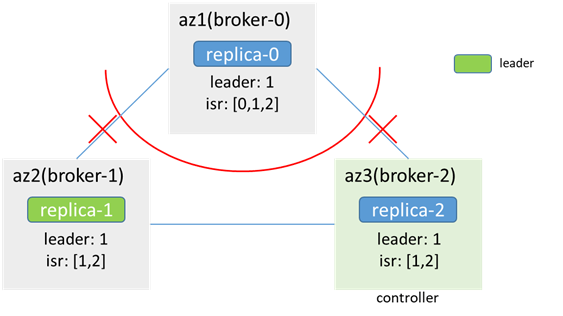
az1内:
broker-0无法访问zk,感知不到节点变化,metadata不更新(leader:1,isr:[1,0,2]),依然认为自己是follower,leader在1;az1内的客户端无法生产消费
az2/3内:
zk可用,感知到broker-0下线,metadata更新,且不发生leader切换(isr:[1,0,2] -> [1,2],leader:1);az2和az3内的客户端可正常生产消费
3.2 三副本partition(replicas:[0,1,2]),原leader在broker-0

az1内:
zk-0和zk-1、zk-2连接中断,少于一半,az1内zk集群不可用,Broker-0连不上zk,无法感知节点变化,且无法更新isr,metadata不变,leader和isr都不变;az1内客户端可以继续向broker-0生产消费
az2/3内:
zk-1和zk-2连通,zk可用,集群感知到broker-0下线,触发leader切换,broker-1成为新的leader(时间取决于 zookeeper.session.timeout.ms),并更新isr;az2/3内的客户端可以向broker-1生产消费
此时,该分区出现了双主现象,replica-0和replica-1均为leader,均可以进行生产消费
若两个隔离域内的客户端都生产了消息,就会出现数据不一致的情况
示例:(假设网络隔离前有两条消息,leaderEpoch=0)
网络隔离前:
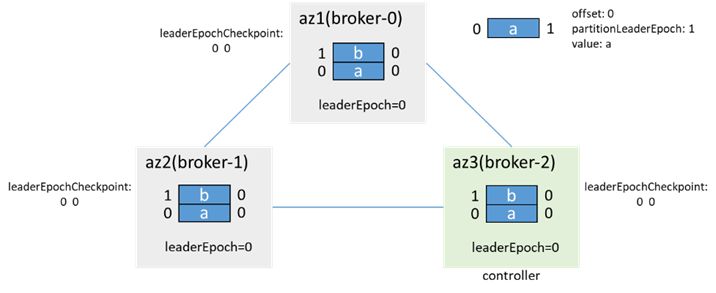
az1隔离后,分区双主,az1内的客户端写入3条消息:c、d、e,az2/3内的客户端写入2条消息:f、g:
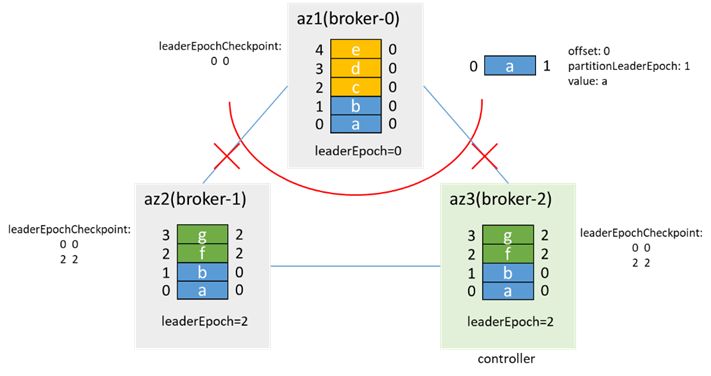
这里leaderEpoch增加2,是因为有两次增加leaderEpoch的操作:一次是PartitionStateMachine的handleStateChanges to OnlinePartition时的leader选举,一次是ReplicationStateMachine 的 handleStateChanges to OfflineReplica 时的removeReplicasFromIsr
网络恢复后:
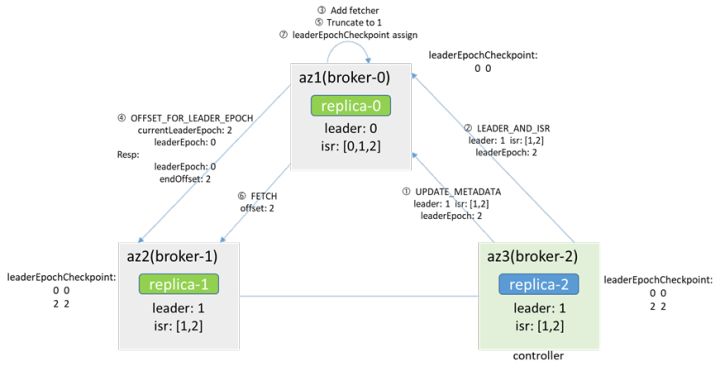
由于controller在broker-2,缓存和zk中的leader都是broker-1,controller会告知broker-0 makerFollower,broker-0随即add fetcher,会先从leader(broker-1)获取leaderEpoch对应的endOffset(通过OFFSET_FOR_LEADER_EPOCH),根据返回的结果进行truncate,然后开始FETCH消息,并根据消息中的leaderEpoch进行assign,以此和leader保持一致
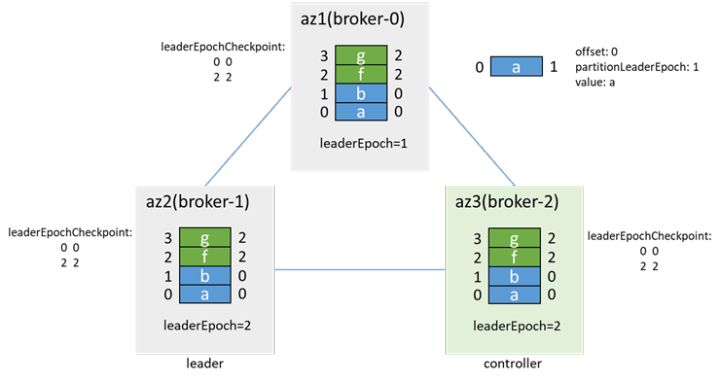
待数据同步后,加入isr,并更新isr为[1,2,0]。之后在触发preferredLeaderElection时,broker-0再次成为leader,并增加leaderEpoch为3
在网络隔离时,若az1内的客户端acks=-1,retries=3,会发现生产消息失败,而数据目录中有消息,且为生产消息数的4倍(每条消息重复4次)
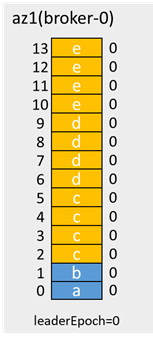
有前面所述可知,网络恢复后,offset2-13的消息会被覆盖,但因为这些消息在生产时,acks=-1,给客户端返回的是生产失败的,因此也不算消息丢失
因此,考虑此种情况,建议客户端acks=-1
4. Controller节点所在az被隔离(分区)
4.1 Leader节点未被隔离

网络中断后,az3的zk不可用,broker-2(原controller)从zk集群断开,broker-0和broker-1重新竞选controller
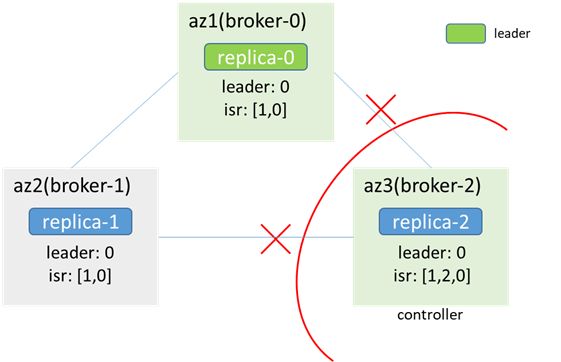
最终broker-0选举为controller,而broker-2也认为自己是controller,出现controller双主,同时因连不上zk,metadata无法更新,az3内的客户端无法生产消费,az1/2内的客户端可以正常生产消费
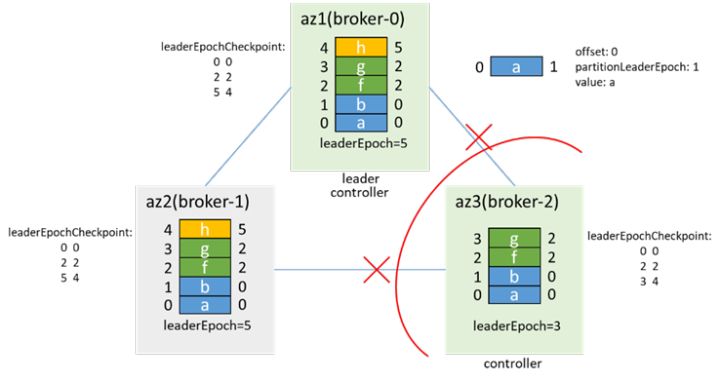
故障恢复后,broker-2感知到zk连接状态发生变化,会先resign,再尝试竞选controller,发现broker-0已经是controller了,放弃竞选controller,同时,broker-0会感知到broker-2上线,会同步LeaderAndIsr和metadata到broker-2,并在broker-2同步数据后加入isr

4.2 Leader节点和controller为同一节点,一起被隔离
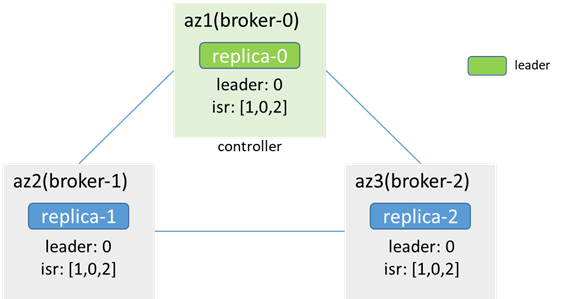
隔离前,controller和leader都在broker-0:
隔离后,az1网络隔离,zk不可用,broker-2竞选为controller,出现controller双主,同时replica-2成为leader,分区也出现双主
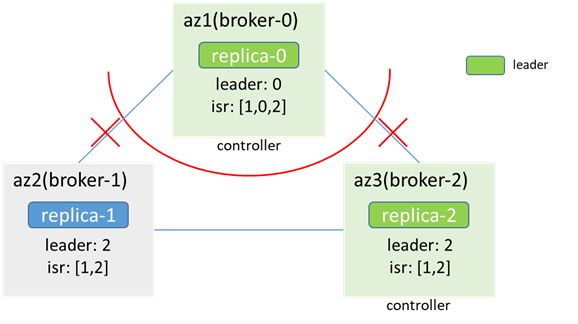
此时的场景和3.2类似,此时生产消息,可能出现数据不一致
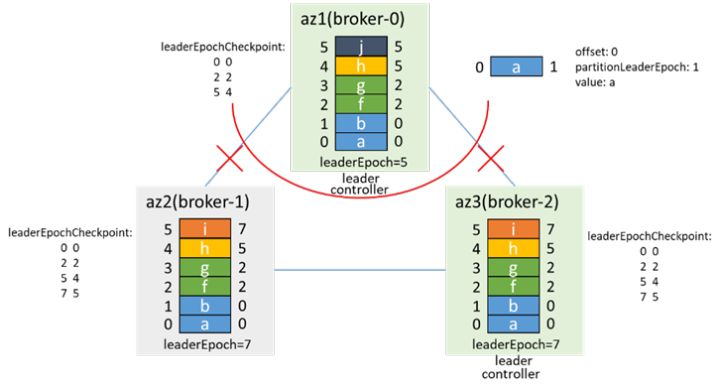
网络恢复后的情况,也和3.2类似,broker-2为controller和leader,broker-0根据leaderEpoch进行truncate,从broker-2同步数据
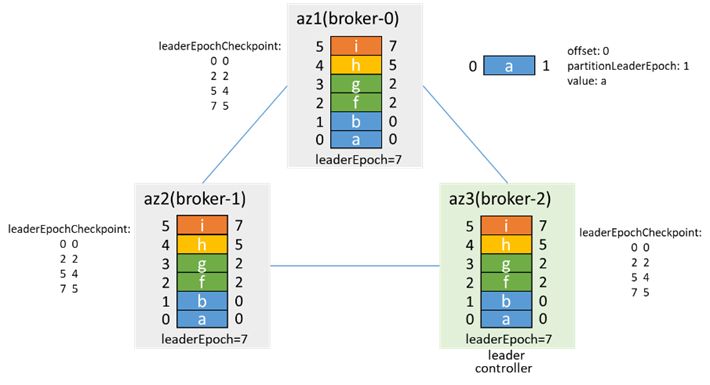
加入isr,然后通过preferredLeaderElection再次成为leader,leaderEpoch加1
5. 补充:故障场景引起数据不一致
5.1 数据同步瞬间故障
初始时,broker-0为leader,broker-1为follower,各有两条消息a、b:
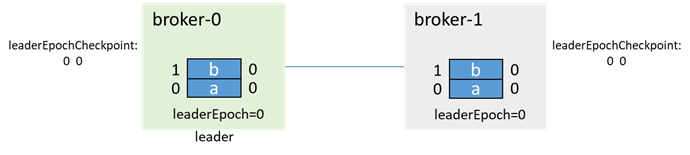
leader写入一条消息c,还没来得及同步到follower,两个broker都故障了(如下电):
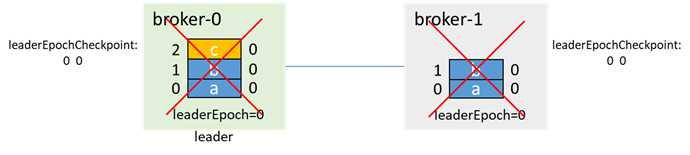
之后broker-1先启动,成为leader(0和1都在isr中,无论unclean.leader.election.enable是否为true,都能升主),并递增leaderEpoch:
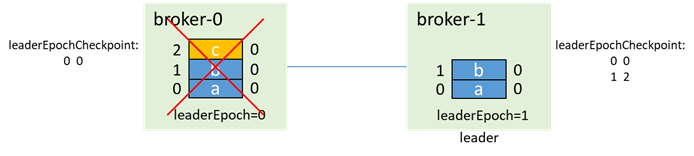
然后broker-0启动,此时为follower,通过OFFSET_FOR_LEADER_EPOCH从broker-1获取leaderEpoch=0的endOffset

broker-0根据leader epoch endOffset进行truncate:

之后正常生产消息和副本同步:
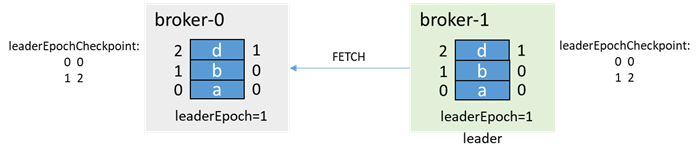
该过程,如果acks=-1,则生产消息c时,返回客户端的是生产失败,不算消息丢失;如果acks=0或1,则消息c丢失
5.2 unclean.leader.election.enable=true引起的数据丢失
还是这个例子,broker-0为leader,broker-1为follower,各有两条消息a、b,此时broker-1宕机,isr=[0]
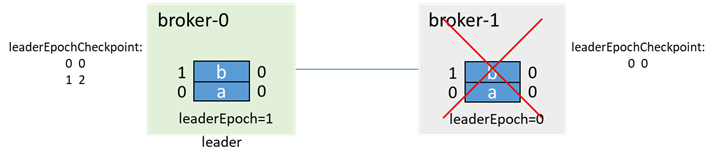
在broker-1故障期间,生产消息c,因为broker-1已经不在isr中了,所以即使acks=-1,也能生产成功
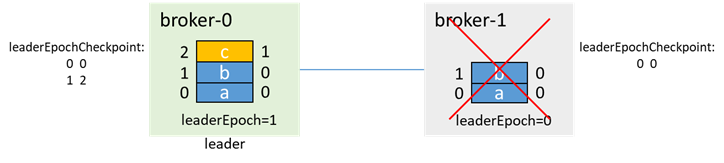
然后broker-0也宕机,leader=-1,isr=[0]
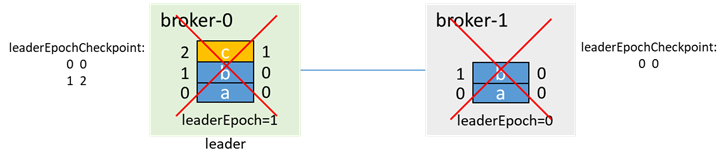
此时broker-1先拉起,若 unclean.leader.election.enable=true,那么即使broker-1不在isr中,因为broker-1是唯一活着的节点,因此broker-1会选举为leader,并更新leaderEpoch为2
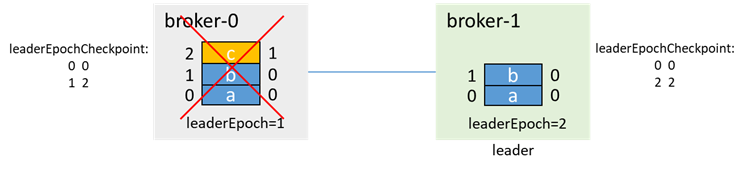
这时,broker-0再拉起,会先通过 OFFSET_FOR_LEADER_EPOCH,从broker-1获取epoch信息,并进行数据截断
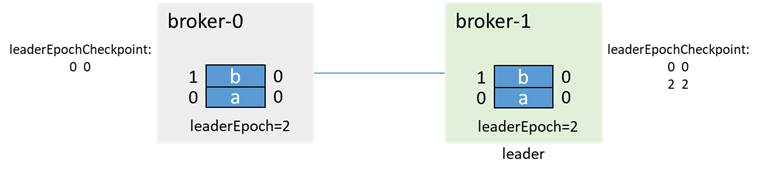
再进行生产消息和副本同步
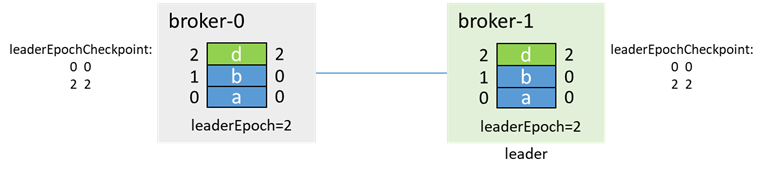
消息c丢失
|








- 上一条: Redis如何实现多可用区? 2022-07-05
- 下一条: RocketMQ之消费者启动与消费流程 2022-07-12
- 一次“不负责任”的 K8s 网络故障排查经验分享 2021-06-27
- 手绘模型图带你认识Kafka服务端网络模型 2022-04-02
- Kafka分区分配策略详解 2022-01-24
- 第4章 计算机系统的应用 ·4.1 计算机网络 2021-07-15
- 【Kafka核心原理解析】之分区分配策略详解 2022-01-25


