Redis 高可用篇:你管这叫主从架构数据同步原理?
高可用有两个含义:一是数据尽量不丢失,二是服务尽可能提供服务。 AOF 和 RDB 保证了数据持久化尽量不丢失,而主从复制就是增加副本,一份数据保存到多个实例上。即使有一个实例宕机,其他实例依然可以提供服务。
本篇主要带大家全方位吃透 Redis 高可用技术解决方案之一主从复制架构。
本篇硬核,建议收藏慢慢品味,我相信读者朋友会有一个质的提升。如有错误还望纠正,谢谢。关注「码哥字节」设置「星标」第一时间接收优质文章,谢谢读者的支持。
核心知识点
开篇寄语
“问题 = 机会。遇到问题的时候,内心其实是开心的,越大的问题意味着越大的机会。
任何事情都是有代价的,有得必有失,有失必有得,所以不必计较很多东西,我们只要想清楚自己要做什么,并且想清楚自己愿意为之付出什么代价,然后就放手去做吧!
”
1. 主从复制概述
“65 哥:有了 RDB 和 AOF 再也不怕宕机丢失数据了,但是 Redis 实例宕机了怎么实现高可用呢?
”
既然一台宕机了无法提供服务,那多台呢?是不是就可以解决了。Redis 提供了主从模式,通过主从复制,将数据冗余一份复制到其他 Redis 服务器。
前者称为主节点 (master),后者称为从节点 (slave);数据的复制是单向的,只能由主节点到从节点。
默认情况下,每台 Redis 服务器都是主节点;且一个主节点可以有多个从节点 (或没有从节点),但一个从节点只能有一个主节点。
“65 哥:主从之间的数据如何保证一致性呢?
”
为了保证副本数据的一致性,主从架构采用了读写分离的方式。
- 读操作:主、从库都可以执行;
- 写操作:主库先执行,之后将写操作同步到从库;
 Redis 读写分离
Redis 读写分离
“65 哥:为何要采用读写分离的方式?
”
我们可以假设主从库都可以执行写指令,假如对同一份数据分别修改了多次,每次修改发送到不同的主从实例上,就导致是实例的副本数据不一致了。
如果为了保证数据一致,Redis 需要加锁,协调多个实例的修改,Redis 自然不会这么干!
“65 哥:主从复制还有其他作用么?
”
- 故障恢复:当主节点宕机,其他节点依然可以提供服务;
- 负载均衡:Master 节点提供写服务,Slave 节点提供读服务,分担压力;
- 高可用基石:是哨兵和 cluster 实施的基础,是高可用的基石。
2. 搭建主从复制
主从复制的开启,完全是在从节点发起的,不需要我们在主节点做任何事情。
“65 哥:怎么搭建主从复制架构呀?
”
可以通过 replicaof(Redis 5.0 之前使用 slaveof)命令形成主库和从库的关系。
在从节点开启主从复制,有 3 种方式:
配置文件
在从服务器的配置文件中加入
replicaof <masterip> <masterport>启动命令
redis-server 启动命令后面加入
--replicaof <masterip> <masterport>客户端命令
启动多个 Redis 实例后,直接通过客户端执行命令:
replicaof <masterip> <masterport>,则该 Redis 实例成为从节点。
比如假设现在有实例 1(172.16.88.1)、实例 2(172.16.88.2)和实例 3 (172.16.88.3),在实例 2 和实例 3 上分别执行以下命令,实例 2 和 实例 3 就成为了实例 1 的从库,实例 1 成为 Master。
config set client-output-buffer-limit "slave 536870912 536870912 0"
“65 哥:主从库复制为何不使用 AOF 呢?相比 RDB 来说,丢失的数据更少。
”
这个问题问的好,原因如下:
- RDB 文件是二进制文件,网络传输 RDB 和写入磁盘的 IO 效率都要比 AOF 高。
- 从库进行数据恢复的时候,RDB 的恢复效率也要高于 AOF。
增量复制
“65 哥:主从库间的网络断了咋办?断开后要重新全量复制么?
”
在 Redis 2.8 之前,如果主从库在命令传播时出现了网络闪断,那么,从库就会和主库重新进行一次全量复制,开销非常大。
从 Redis 2.8 开始,网络断了之后,主从库会采用增量复制的方式继续同步。
增量复制:用于网络中断等情况后的复制,只将中断期间主节点执行的写命令发送给从节点,与全量复制相比更加高效。
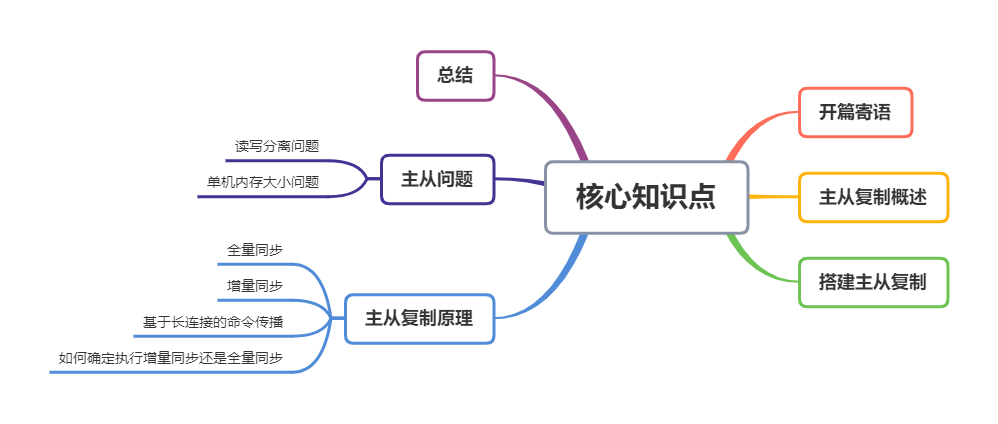
repl_backlog_buffer
断开重连增量复制的实现奥秘就是 repl_backlog_buffer 缓冲区,不管在什么时候 master 都会将写指令操作记录在 repl_backlog_buffer 中,因为内存有限, repl_backlog_buffer 是一个定长的环形数组,如果数组内容满了,就会从头开始覆盖前面的内容。
master 使用 master_repl_offset记录自己写到的位置偏移量,slave 则使用 slave_repl_offset记录已经读取到的偏移量。
master 收到写操作,偏移量则会增加。从库持续执行同步的写指令后,在 repl_backlog_buffer 的已复制的偏移量 slave_repl_offset 也在不断增加。
正常情况下,这两个偏移量基本相等。在网络断连阶段,主库可能会收到新的写操作命令,所以 master_repl_offset会大于 slave_repl_offset。
 repl_backlog_buffer
repl_backlog_buffer
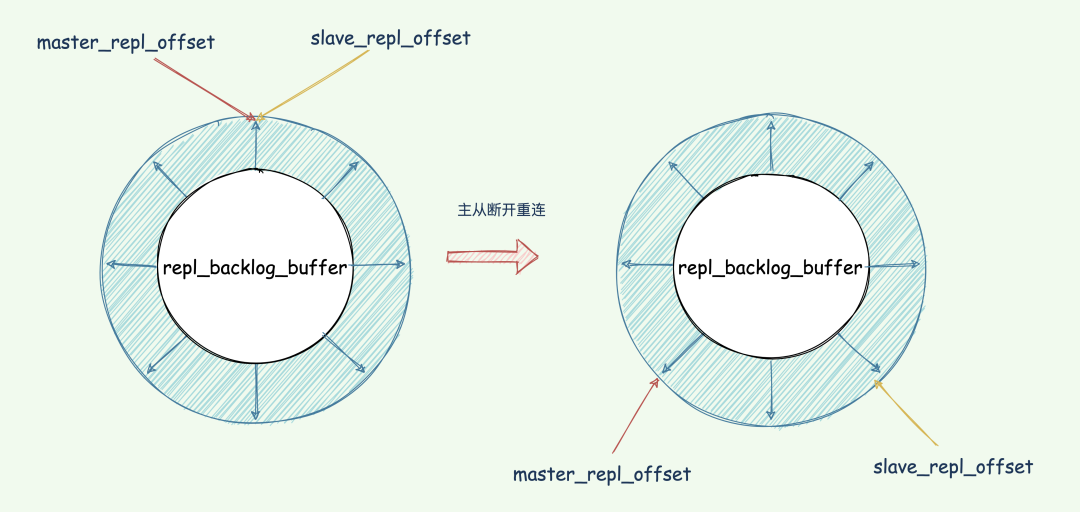
当主从断开重连后,slave 会先发送 psync 命令给 master,同时将自己的 runID,slave_repl_offset发送给 master。
master 只需要把 master_repl_offset与 slave_repl_offset之间的命令同步给从库即可。
增量复制执行流程如下图:
 Redis增量复制
Redis增量复制
“65 哥:repl_backlog_buffer 太小的话从库还没读取到就被 Master 的新写操作覆盖了咋办?
”
我们要想办法避免这个情况,一旦被覆盖就会执行全量复制。我们可以调整 repl_backlog_size 这个参数用于控制缓冲区大小。计算公式:
REPLCONF ACK <replication_offset>
其中 replication_offset 是从服务器当前的复制偏移量。发送 REPLCONF ACK 命令对于主从服务器有三个作用:
- 检测主从服务器的网络连接状态。
- 辅助实现 min-slaves 选项。
- 检测命令丢失, 从节点发送了自身的 slave_replication_offset,主节点会用自己的 master_replication_offset 对比,如果从节点数据缺失,主节点会从
repl_backlog_buffer缓冲区中找到并推送缺失的数据。 注意,offset 和 repl_backlog_buffer 缓冲区,不仅可以用于部分复制,也可以用于处理命令丢失等情形;区别在于前者是在断线重连后进行的,而后者是在主从节点没有断线的情况下进行的。
如何确定执行全量同步还是部分同步?
在 Redis 2.8 及以后,从节点可以发送 psync 命令请求同步数据,此时根据主从节点当前状态的不同,同步方式可能是全量复制或部分复制。本文以 Redis 2.8 及之后的版本为例。
关键就是 psync的执行:
 增量与全量复制判断
增量与全量复制判断
- 从节点根据当前状态,发送
psync命令给 master: - 如果从节点从未执行过
replicaof,则从节点发送psync ? -1,向主节点发送全量复制请求; - 如果从节点之前执行过
replicaof则发送psync <runID> <offset>, runID 是上次复制保存的主节点 runID,offset 是上次复制截至时从节点保存的复制偏移量。
- 如果从节点从未执行过
- 主节点根据接受到的
psync命令和当前服务器状态,决定执行全量复制还是部分复制: - runID 与从节点发送的 runID 相同,且从节点发送的
slave_repl_offset之后的数据在repl_backlog_buffer缓冲区中都存在,则回复CONTINUE,表示将进行部分复制,从节点等待主节点发送其缺少的数据即可; - runID 与从节点发送的 runID 不同,或者从节点发送的 slave_repl_offset 之后的数据已不在主节点的
repl_backlog_buffer缓冲区中 (在队列中被挤出了),则回复从节点FULLRESYNC <runid> <offset>,表示要进行全量复制,其中 runID 表示主节点当前的 runID,offset 表示主节点当前的 offset,从节点保存这两个值,以备使用。
- runID 与从节点发送的 runID 相同,且从节点发送的
一个从库如果和主库断连时间过长,造成它在主库 repl_backlog_buffer的 slave_repl_offset 位置上的数据已经被覆盖掉了,此时从库和主库间将进行全量复制。
总结下
每个从库会记录自己的 slave_repl_offset,每个从库的复制进度也不一定相同。
在和主库重连进行恢复时,从库会通过 psync 命令把自己记录的 slave_repl_offset发给主库,主库会根据从库各自的复制进度,来决定这个从库可以进行增量复制,还是全量复制。
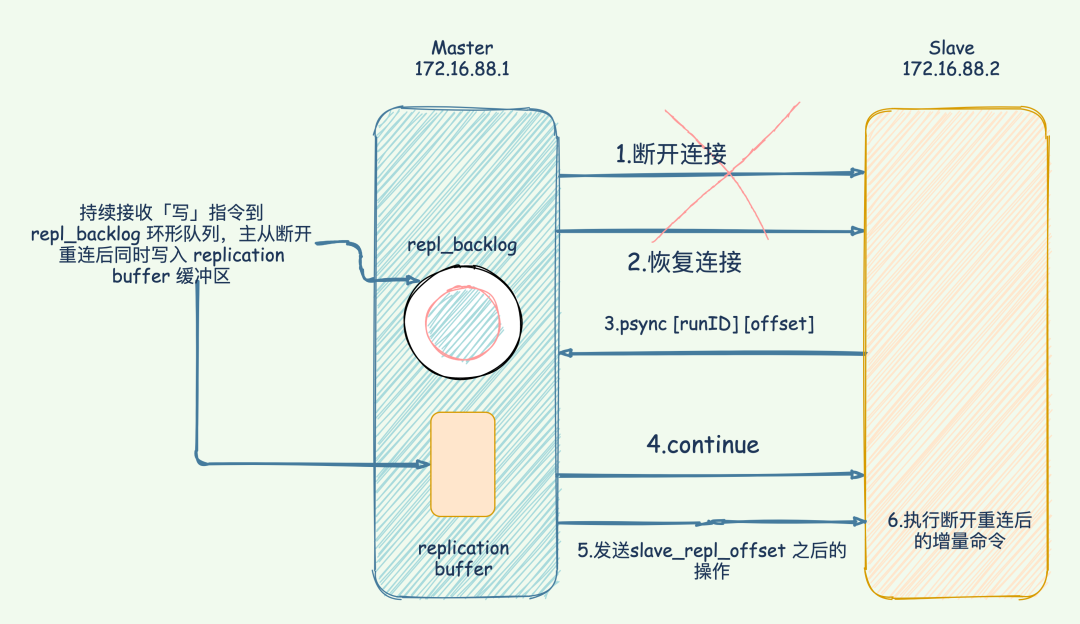
replication buffer 和 repl_backlog
- replication buffer 对应于每个 slave,通过
config set client-output-buffer-limit slave设置。 repl_backlog_buffer是一个环形缓冲区,整个 master 进程中只会存在一个,所有的 slave 公用。repl_backlog 的大小通过 repl-backlog-size 参数设置,默认大小是 1M,其大小可以根据每秒产生的命令、(master 执行 rdb bgsave) +( master 发送 rdb 到 slave) + (slave load rdb 文件)时间之和来估算积压缓冲区的大小,repl-backlog-size 值不小于这两者的乘积。
总的来说,replication buffer 是主从库在进行全量复制时,主库上用于和从库连接的客户端的 buffer,而 repl_backlog_buffer 是为了支持从库增量复制,主库上用于持续保存写操作的一块专用 buffer。
repl_backlog_buffer是一块专用 buffer,在 Redis 服务器启动后,开始一直接收写操作命令,这是所有从库共享的。主库和从库会各自记录自己的复制进度,所以,不同的从库在进行恢复时,会把自己的复制进度(slave_repl_offset)发给主库,主库就可以和它独立同步。
如图所示:
 repl_backlog与repl_buffer区别
repl_backlog与repl_buffer区别
4. 主从应用问题
4.1 读写分离的问题
数据过期问题
“65 哥:主从复制的场景下,从节点会删除过期数据么?
”
这个问题问得好,为了主从节点的数据一致性,从节点不会主动删除数据。我们知道 Redis 有两种删除策略:
- 惰性删除:当客户端查询对应的数据时,Redis 判断该数据是否过期,过期则删除。
- 定期删除:Redis 通过定时任务删除过期数据。
“65 哥:那客户端通过从节点读取数据会不会读取到过期数据?
”
Redis 3.2 开始,通过从节点读取数据时,先判断数据是否已过期。如果过期则不返回客户端,并且删除数据。
4.2 单机内存大小限制
如果 Redis 单机内存达到 10GB,一个从节点的同步时间在几分钟的级别;如果从节点较多,恢复的速度会更慢。如果系统的读负载很高,而这段时间从节点无法提供服务,会对系统造成很大的压力。
如果数据量过大,全量复制阶段主节点 fork + 保存 RDB 文件耗时过大,从节点长时间接收不到数据触发超时,主从节点的数据同步同样可能陷入全量复制->超时导致复制中断->重连->全量复制->超时导致复制中断……的循环。
此外,主节点单机内存除了绝对量不能太大,其占用主机内存的比例也不应过大:最好只使用 50% - 65% 的内存,留下 30%-45% 的内存用于执行 bgsave 命令和创建复制缓冲区等。
总结
- 主从复制的作用:AOF 和 RDB 二进制文件保证了宕机快速恢复数据,尽可能的防止丢失数据。但是宕机后依然无法提供服务,所以便演化出主从架构、读写分离。
- 主从复制原理:连接建立阶段、数据同步阶段、命令传播阶段;数据同步阶段又分为 全量复制和部分复制;命令传播阶段主从节点之间有 PING 和 REPLCONF ACK 命令互相进行心跳检测。
- 主从复制虽然解决或缓解了数据冗余、故障恢复、读负载均衡等问题,但其缺陷仍很明显: 故障恢复无法自动化;写操作无法负载均衡;存储能力受到单机的限制;这些问题的解决,需要哨兵和集群的帮助,我将在后面的文章中介绍,欢迎关注。
|








- 上一条: 详解Redis主从复制原理 2021-07-18
- 下一条: RocketMQ调优心得总结 2021-07-23
- 详解Redis主从复制原理 2021-07-18
- 十二问!带你走进redis6.0新特性 2021-07-13
- Redis 实战篇:巧用Bitmap 实现亿级海量数据统计 2021-08-24
- Redis 6.0 新特性:带你 100% 掌握多线程模型 2021-07-27
- Redis 实战篇:GEO助我邂逅附近女神 2021-08-10


