【联通】数据编排技术在联通的应用

欢迎来到【微直播间】,2min纵览大咖观点,本期分享的题目是数据编排技术在联通的应用。
本次分享内容将围绕四个方面讲述Alluxio数据编排技术在联通的应用,主要围绕缓存加速、存算分离、混合负载以及轻量级分析四个不同的使用场景进行分享:
摘要
01. 在缓存加速方面的应用
为了加速Spark计算,引入了Alluxio来加速数据的读写性能,提高数据写入的稳定性,以及接管Spark Cache后提升Spark作业的稳定性。这是我们一开始采用的架构,数据编排在我们的整个架构中的定位是缓存加速层。
- 加速迭代计算:加速下游SQL读取数据速度,提升数据写⼊稳定性;
- Spark Job间共享数据,替换Spark cache;
- 内存多副本显著提⾼热数据访问速度;
- 调整数据分布策略实现负载均衡;
- Alluxio带来性能与稳定性提升;
02. 在存算分离方面的应用
- 利⽤其他业务资源满⾜计算扩容需求;
- 实现存储独⽴扩容,数据冷热分离;
03. 在混合负载领域的应用
- 利⽤Alluxio Client Cache实现缓存隔离;
- 利⽤Alluxio Fuse打通ETL与AI训练/推理;
04. 轻量级分析相关探索
Presto + Alluxio实现轻量级数据分析
1) 在⽤户集群搭建Alluxio + Presto两套系统满⾜数据分析需求,运维复杂度相对较低,纯SQL交互⽤户体验好;
2) Alluxio mount平台HDFS⽤于私有数据共享,Alluxio SDS mount 平台Hive⽤于公有数据访问及性能加速;
3) 基于Presto Iceberg connector的hadoop catalog mode,采⽤只写缓存的⽅式在本地完成ETL,最终数据持久化⾄平台HDFS;
4) Alluxio使⽤3副本策略保证缓存数据的可⽤性,可挂载独⽴存储集群持久化存储需⻓期保存的分析数据。
以上仅为大咖演讲概览,完整内容【点击观看】:
附件:大咖分享文字版完整内容可见下文

01. 在缓存加速方面的应用

首先介绍Alluxio作为分布式缓存加速大数据计算的使用场景。我们事业部存在多个数据处理与数据分析业务,这些业务分布在不同的平台。使用GreenPlum数据库的数据处理业务基于批处理存储过程完成数据加工,对计算时间有严格的要求,有明确的deadline。这些业务遇到的主要问题是GreenPlum集群规模达到几十台时遇到扩容瓶颈,进一步扩展给业务运维工程师带来很大挑战;还有一部分业务基于hive运行T+1批处理作业,遇到的主要问题是内存、CPU等资源消耗比较大,并行度不高,跑的速度比较慢;还有一些传统统计业务是跑在Oracle上,Oracle单机跑的效果不是特别好,并且Oracle比较贵,一台小型机可能就要两千多万,业务方期望能有其他数据分析平台替代Oracle。
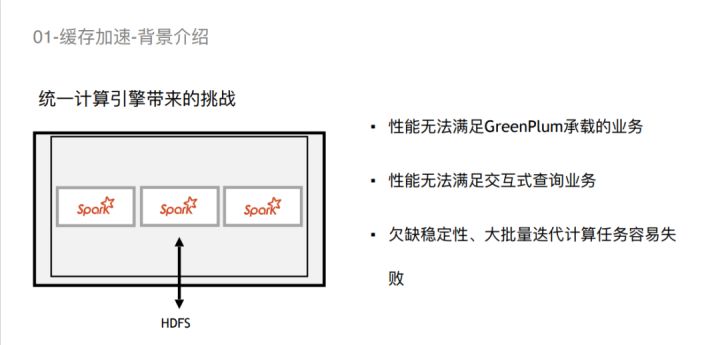
当时,我们的课题是基于Spark、Hadoop这个开源体系,去做一个统一的计算平台,把上述三个引擎承接的业务全部接过来。我们直接用Spark + HDFS遇到了一些问题:
首先,它的性能是没有办法满足GreenPlum承载的生产业务,因为GreenPlum是MPP数据库,同等体量下它会比Spark要快很多;
其次,GreenPlum承载的业务中存在伴生的交互式查询的场景,同样性能也是没有办法去满足的。
接着,对于一些批处理的业务来说,Spark + HDFS比较欠缺稳定性,批处理的业务每一次任务周期会有几千、几万个SQL去做迭代计算,任务如果经常失败的话,没有办法很好地在那之前保证去完成。
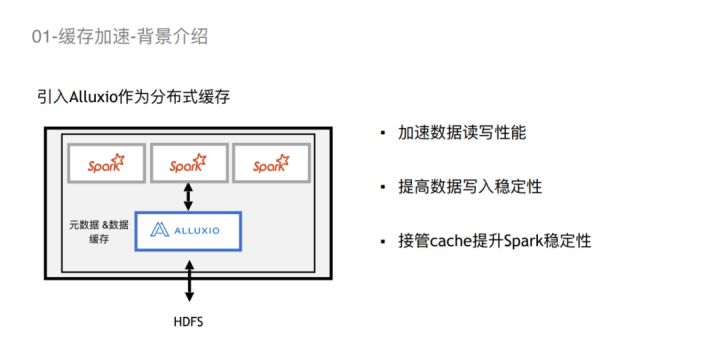
所以,为了加速Spark计算,我们引入了Alluxio来加速数据的读写性能,提高数据写入的稳定性,以及接管Spark Cache后提升Spark作业的稳定性。这是我们一开始采用的架构,数据编排在我们的整个架构中的定位是缓存加速层。
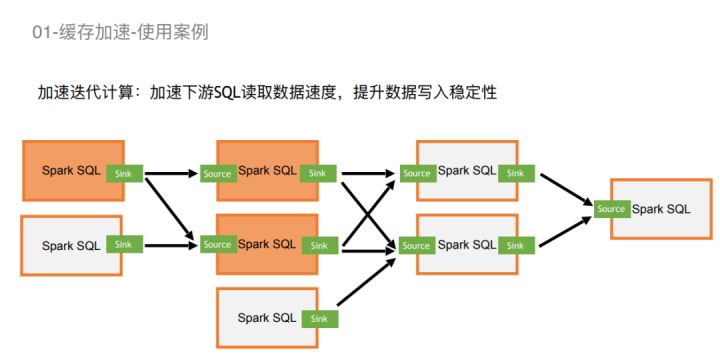
具体看一下使用案例,如果拿加速迭代计算来说,我们会把Sink直接写到Alluxio上,然后下一个SQL的Source去读这个Sink,把Source和Sink之间的串联交给Alluxio的缓存去做,这样可以比较显著提升整个pipeline的稳定性。因为不需要再和磁盘交互,可以极大降低磁盘压力。而通过内存,pipeline的稳定性得到了比较好的改善,通过直接读取内存会提高整个pipeline的运行速度。
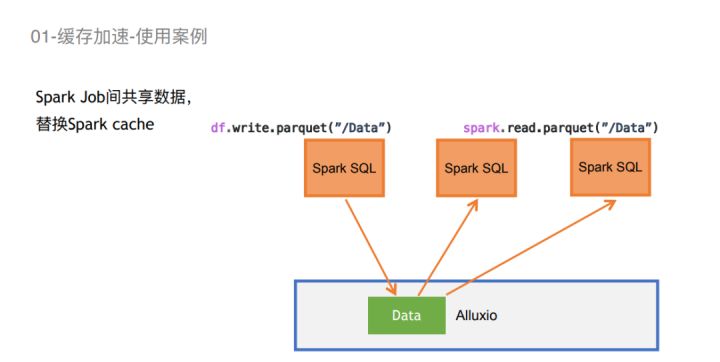
第二个使用案例,是我们通过Alluxio去共享整个Job之间的数据,而避免使用Spark Cache。通过Spark Cache方式会对整个Executor JVM造成比较大的压力。性能测试结果表明在数据量达到一定规模的情况下,Spark Cache的性能是要比Alluxio差一些。而且Alluxio随着Spark中间数据的增大,它对性能的影响是可以预测的,是线性而不是指数性上涨的。所以说,我们选择用Alluxio做中间数据的共享层。
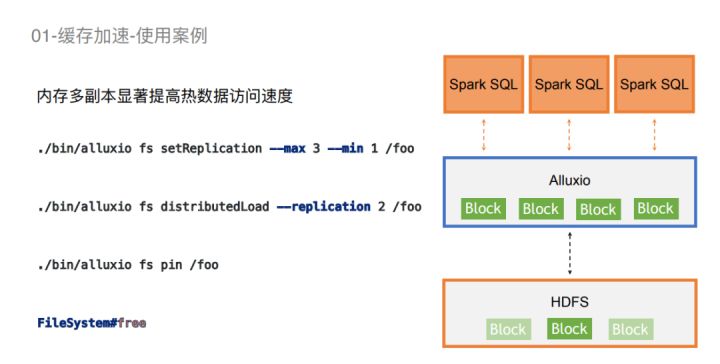
为了增强数据读取的性能,可以显示的为每个路径去配置副本浮动范围。而且Alluxio还支持了数据预加载的功能--distributedLoad.这个在2021年的时候,社区也是花了很多的精力在上面,目前是做的十分完善的工具了。我们可以在执行一些固定任务之前,提前先把数据加载到内存。这样可以提高整个pipeline的运行速度。此外,Alluxio还支持一些内存操作工具,比如pin和free,这样的话能方便我们更好地去管理内存。就是按照我们既定的一个pipeline可以使整个内存布局得到最好的优化。
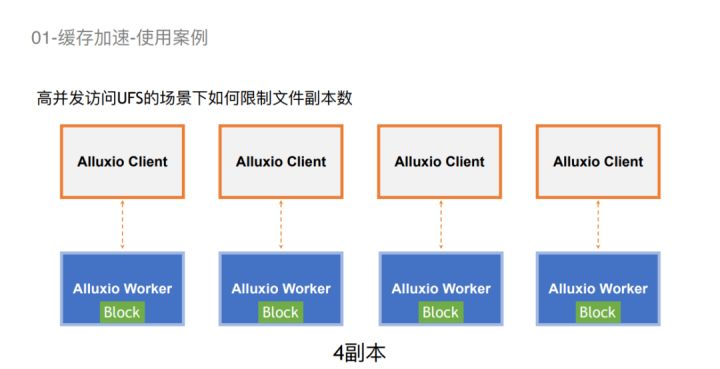
接下来是跟Alluxio数据编排Policy有关的例子。比如我们一个Spark任务去读一个数据,它可能会在每个worker上都拉起一些副本,比如重复使用的一些数据。这种情况可能会迅速把缓存占满。对于这种情况,Alluxio可以提供一个叫确定性哈希的策略。这个策略可以使我们在固定的某几个worker上去读。这样可以把整个集群的副本数加起来,能更有效地去使用空间。
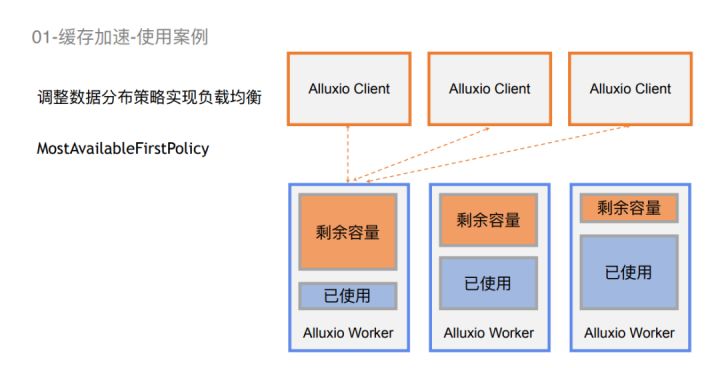
除此之外,针对大量场景,它还支持一些跟负载均衡相关的策略。比如最高可控策略,它会选择整个集群内空间剩余量最大的一个worker去读。这样可以使所有worker的使用比较均衡。但是,它也有一些问题,当大量Alluxio Client 在Spark Executor这边如果大量去挤兑一个Alluxio Worker的话,那么可能会导致这个worker的使用量瞬间打满,出现性能降级的情况。
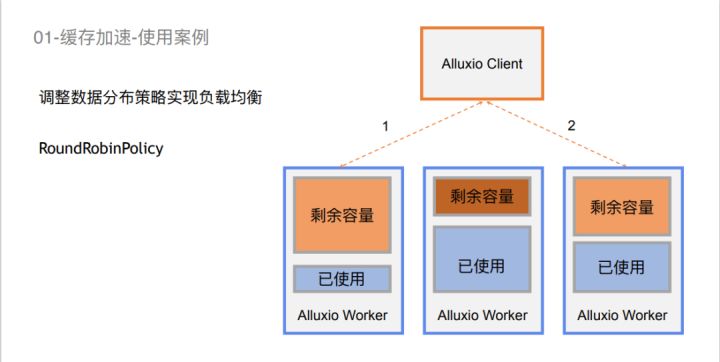
针对这种情况,我们可以去选择一个轮循策略,在若干有剩余量的work之间去轮循使用,这样可以比较好地去实现集群的负载均衡。
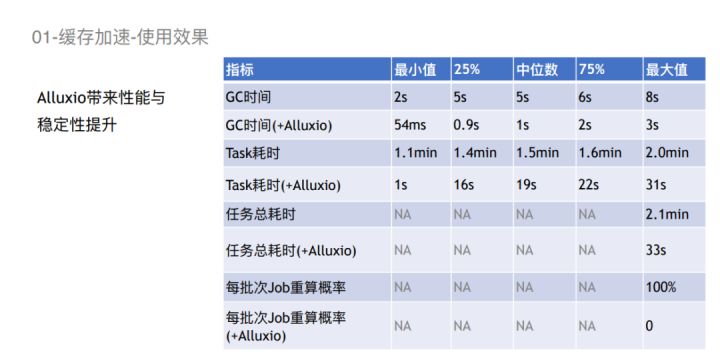
从总的使用效果来看,Alluxio还带来了比较大的性能与稳定性的提升。这里是一个比较典型的Spark Task统计,Alluxio对整个GC的时间优化,还有整个任务总耗时的优化的收益是比较显著的。它最大的优点是可以显著降低每批次Job的重算概率,从而使整个过程更加稳定,更加可预测。

最终效果是我们从之前GreenPlum迁移过来的核心业务的规模已经有接近70倍的增长,并且承接的用户数相比之前提高了100%,业务总体提速了26个小时。交互式查询业务目前日常数据已经达到60TB,如使用Spark单表2.5tb数据,查询耗时也是分钟级别。原先Oracle业务迁移到Spark后可以做用户级的计算,这对于他们来讲是具有很大的价值。
02. 在存算分离方面的应用
接下来是我们针对集群继续发展的特点,做了在存算分离方面的一些建设。存算分离的背景大概是什么样的?
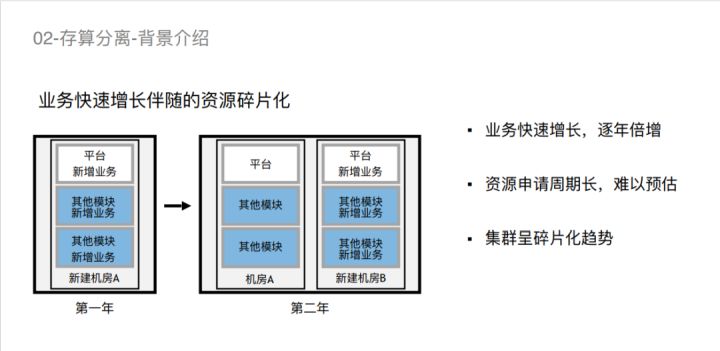
这主要是跟整个集群的发展有一定的关系。首先在我们这边的平台建设是跟着业务走。随着业务快速增长,会出现资源碎片化的情况。如图所示,第一年新建一个机房,我们占用了一部分机架,其他业务或部门也会占用一些机架。到第二年的时候,第一年的机房就满了,第二年新建的机房大家可以各自去申请一些。这就导致整个机器不具有连续性,可能会跨机房,甚至可能会跨楼,有时候甚至还会跨数据中心。与之伴随的就是业务快速增长,基本上处于逐年倍增的情况,而且资源申请周期非常长,至少需要一年的时间才能交付,最后导致的情况就是集群呈现碎片化。

更为糟糕的是在业务增长过程中,其实它的资源需求是不平衡的,主要是存储与计算之间的不平衡。
首先,一个客观事实是历史数据的存储需求是逐年递增的。之前业务只需要保留1至2个月的数据。但是现在因为一些历史的趋势分析或是各方面测算,一些主要业务的数据需要保存12至24个月。业务数据每个周期之间的环比涨幅大概是10%,涨幅大时甚至有5~10倍的情况,主要是跟业务逻辑变化相关。
其次,存储规模的涨幅大概是计算规模涨幅的5到6倍,这也是存储计算发展不平衡的情况。
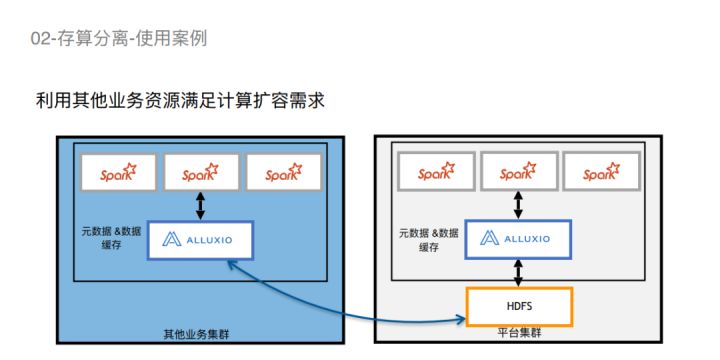
我们使用了存算分离的技术来解决这些问题。
首先解决计算资源的问题。我们向其他的业务租借了一个现有的集群,利用该集群空闲的夜间完成数据加工作业。我们在上面部署了一套Spark,以及Alluxio和我们集群的HDFS构成一套存算分离的数据分析系统。为什么不在该集群部署Hadoop?原因是租借的业务集群已经搭建了一套Hadoop,我们不被允许二次搭建Hadoop,也不允许去使用他们的Hadoop。所以,我们就用该业务集群的Alluxio去挂载我们平台的HDFS。挂载HDFS之后就跟我们自己平台保持一样的命名空间,这样看起来都是一样的,基本上做到用户无感知。
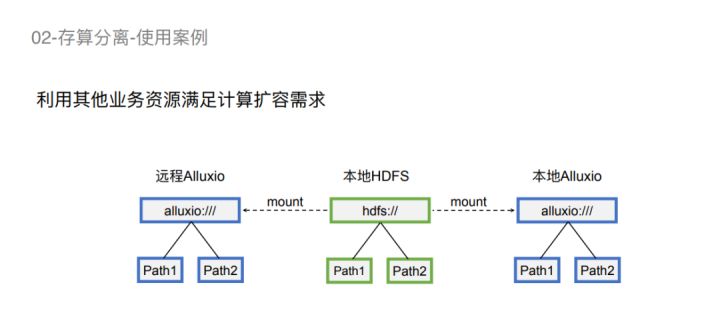
更详细的如此图所示,就是对于2个Alluxio来说,看到的Path都是一样的,都是映射到HDFS的一个Path,所以用户认为这两个Path都是一样的。我们在读写不同Path的时候,会让不同的Alluxio分别执行读写操作。比如远程Alluxio对Path1是只读的,它会去写Path2,本地Alluxio会写Path1,但只会去读Path2,这样就避免了两个Alluxio相互之间冲突。
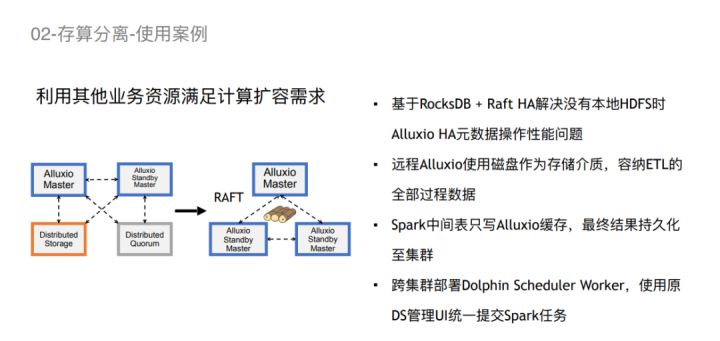
在具体落实方案上,我们还使用了一些自己的设计,来避免存算分离会遇到的一些问题。
首先,我们在远程业务集群这块,是基于RocksDB+Raft HA 的方式来解决没有本地HDFS时Alluxio HA元数据操作性能的问题。因为我们的HDFS在我们的集群,中间有一定的网络消耗。如果我们直接还是采用原来的zookeeper ha,首先我们需要在他们的集群搭一套zookeeper ha,以及把元数据放在我们自己集群的HDFS上,跨网络元数据交互可能会带来很多的不确定性。比如带宽打满了,或者是因为其他网络波动的因素,会导致Alluxio本身的性能抖动,甚至可能出现因为数据写入或者读取超时导致整个Alluxio挂掉的情况。所以,我们选择了Alluxio 2.x之后不断去建设去完善的RocksDB+Raft HA的方式来解决这个问题。
其次,我们在业务集群这边因为要满足所有中间数据的存储,提升整个计算性能,所以我们使用HDD作为存储介质。Spark作业的中间过程数据直接存储在缓存磁盘里,不会与UFS有任何交互,所以对于用户来说,这种模式的性能是不受影响的。
第三,最终结果还可以持久化至集群。因为最终结果的数量也不是特别大,所以它的耗时还是可以接受的。最后对于用户来说,他可能需要跨集群部署任务,我们是在租借的业务集群之内搭建了一个Dolphin Scheduler Worker,通过Dolphin的调度策略,帮助用户把他的特定任务起在这个Worker上面。通过Worker的选择来控制它提交到不同的集群。对于用户来说只是配置上做了变更,作业提交入口以及管理入口都是相同的,解决了跨集群作业管理的问题。
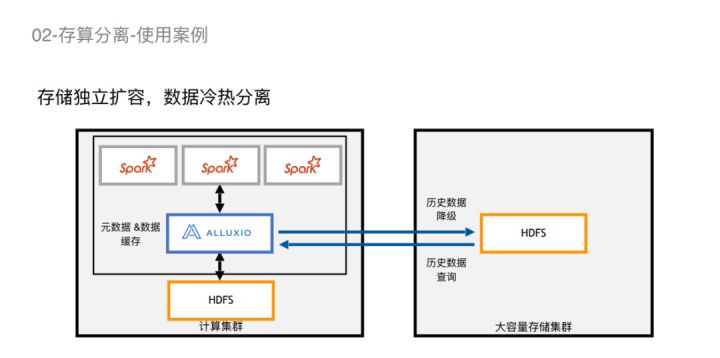
实现计算混合部署之后,我们又接到了大量的数据存储需求。但是我们的集群短时间内没有办法扩容了,所以我们申请了一批大容量存储,然后把大容量存储mount到Alluxio,将历史数据自动化降级到大容量存储上,查询的时候就经由Alluxio透明访问。我们会把前2个月至前12个月的历史数据降级到大容量存储上,本地集群只保留最近几个月会频繁参与计算的数据。对于用户来说,访问的路径跟之前还是一样的,我们通过mount方式屏蔽了历史数据分层管理的差异性。对于我们的好处是单位服务器的存储容量显著提高了,大容量存储可以独立扩容,对于我们来说缓解了很大的存储压力。
以下是我们做完存算分离以后的实际效果。

首先,某核心用户租借算力占平台分配算力的82%,这个是比较大的提升。承接新业务使用租借算力占比达到50%,Alluxio管理ETL过程数据达到148TB,算是非常庞大的数字了。因为Alluxio其实作为缓存来讲并不会去管理特别大量的数据。管理100至200TB这个数据量,我们跟社区一起做了很多工作,包括worker启动超时等优化,以满足中间数据存储的需求。单独扩容的大容量存储给我们带来的好处是单台服务器的存储容量提升5倍,计算集群采用的计算型服务器存储容量比较小,大容量存储单台机器就能存储90TB数据,服务器台数相同的情况下,容量提升比较明显,所以历史数据存储显著降低,扩容成本是降低了83%。
03. 在混合负载领域的应用

当集群向后继续发展的时候,我们引入了更多的计算引擎来适配更多的业务场景以得到更好的效果。其中比较典型的场景是我们在一个平台上同时提供Spark和Presto,Spark主要用于ETL,Presto提供即席查询服务。它们共用Alluxio时会遇到一些问题:首先,Alluxio System Cache不支持Quota,没有办法隔离Spark跟Presto之间的用量,由于Spark ETL作业写入的数据较大,数据直接写入Alluxio作为pipeline下一个节点的读取加速。这种情况下内存冲刷比较频繁,会一次性占用较多的内存。这样Presto刚完成数据加载,想查数据的时候发现缓存中没有了,Presto查询的缓存利用率不是特别高。

第二个情况是一些用户使用TensorFlow做自然语言处理或者时间序列分析的AI计算。在AI计算之前,用户首先基于Spark做分布式ETL,然后想把ETL结果直接拿给TensorFlow使用,在这种情况下,用户很难把分布式的数据和本地数据联系到一起。第三方框架比如TensorFlow on Spark一般都会封装一些标准模型。用户使用的模型不是主流模型,但实际效果较好,这种情况没有办法套用现用的第三方框架,直接将Spark DataFrame转换成TensorFlow的数据模型直接使用。这样TensorFlow还是一种读取本地文件的模式,就是不是很好的能把Spark与TensorFlow联动起来。

针对使用案例刚才讲到的一些问题,我们做了一些改进。首先,Presto这边我们放弃了使用Alluxio System Cache,而是使用Alluxio Local Cache缓存数据,这样跟Spark使用的Alluxio System Cache进行隔离。我们会为每个Presto Worker去开辟一个独立的缓存。这个缓存是放在Ramdisk上面,官方推荐放到SSD里边也是可以的。缓存不占用Presto Worker的JVM空间,不会对GC造成额外负担。除此之外,因为我们有一些磁盘场景,所以跟社区一起完善了基于RockDB的缓存实现。以上是我们在缓存隔离上做的一些设计。
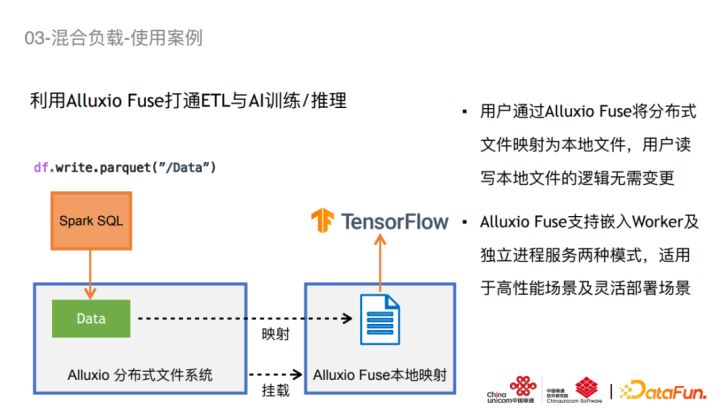
在AI这边,我们利用Alluxio Fuse打通了ETL与AI训练和推理。Alluxio Fuse首先做了本地文件跟分布式系统挂载,这样就可以把分布式文件映射到本地文件。然后用户可以直接使用读写本地文件的方式操作一个分布式系统中的文件,与笔记本上开发的读写本地代码的逻辑完全相同。这样就成功地打通了Spark ETL跟TensorFlow的计算。Alluxio目前是提供两种Fuse挂载模式,首先提供为每个Worker创建一个Fuse的挂载目录。这种方式可以更好地提高数据访问性能,我们目前使用的是这种模式。还有一种是单独起一个Fuse进程,这样就不需要在本地区部署Alluxio集群,这种方式有助于灵活部署。大家可以按照自己需要去选择不同的部署模式。

目前使用的效果,Presto因为引入了Cache,查询性能提升了50%左右,相比OS Cache更加稳定。如果我们都用OS Cache性能是最快的,但因为集群支撑的是数据密集型的负载,所以OS Cache不是特别稳定,容易被刷下去。相比没有Cache加速时,它的查询性能有不错的提升。大数据AI集成方面,用户可以用TensorFlow去训练推理的代码不需要做任何改动,就可以跟Spark ETL做集成,目前首批业务是完成了60万用户的接入,整个过程基于Dolphin Scheduler实现大数据+AI全流程自动化调度,用户的运维复杂度非常低。这里帮Alluxio的邱璐做个广告,她目前是Alluxio Fuse的负责人。Alluxio Fuse已经在微软、Boss直聘、哔哩哔哩、陌陌等公司的生产训练中完成了部署。
04. 轻量级分析相关探索

现状一,目前联通在大力推动数字化转型,之前很多跟数据分析没有关系的业务,如一些传统业务,也想做数据分析。利用之前沉淀的数据,想做预测或者是原因定位。目标用户更多是业务工程师,更喜欢关系型数据库以及SQL。
现状二,不同的业务之间同时需要访问平台运营的公有数据,以及访问、管理业务私有数据。这些私有数据的业务口径由业务方制定,并按照自己的开放策略向其他业务方提供。因此共享私有数据需要数据提供方授权,公有数据只需要平台授权就可以。
现状三,服务器资源增量目前低于业务的需求量,因为数据分析需求上涨很厉害,而且不可预测,很多需求不在总体规划里。与此同时,业务自有服务器在空闲时间段负载比较低,一般主要是白天比较忙。这样的话,他们的现有资源其实是能够去支撑新增的一些数据分析业务的。
所以,考虑到平台在扩容的时候是没有办法跟上业务的发展脚步的。为了能尽快满足业务数字化建设需求,我们计划为这些业务做私有化部署,基于Spark做私有化部署的时候,我们遇到一些问题。

首先,如果按照我们自己标准的模式为每个用户去独立部署一个Spark on Yarn的话,管理复杂度就太高了。我们可能会管很多个集群的Spark on Yarn,这样的管理成本是无法支撑的。另外,部分用户服务器已经部署了HBase on Hadoop,这些集群不允许我们部署Hadoop也不允许我们在上面部署Hbase,而且不能使用已有的Hadoop。这样就给Spark体系增加了很多难度。并且,业务用户希望使用这种纯SQL分析数据,如果是这样,我们会需要添加类似于Kyuubi的工具,我们需要为了满足一个需求添加很多组件,这样的话多个集群的管理复杂度会非常高。还有一种方式就是我们不采用on Yarn的方式,采用Spark Standalone模式,其实部署起来相对还好,只使用Spark + Alluxio还不错。
但这种方式的问题是,如果我们采用Spark per job作业模式,它的并发度是有限的。如果我们给一个通用值,它并发度是一个查询起一个job,并发度是比较低的,可能同时只能并发几个。而且Spark配置复杂度偏高,对于SQL用户来说不是很友好,还需要配置内存大小,executor数目,或者Dynamic allocate限制参数。如果不采用Spark per job采用单Session的模式,又没有办法在多任务间做优先级隔离,无法对一个业务的多个SQL进行编排。
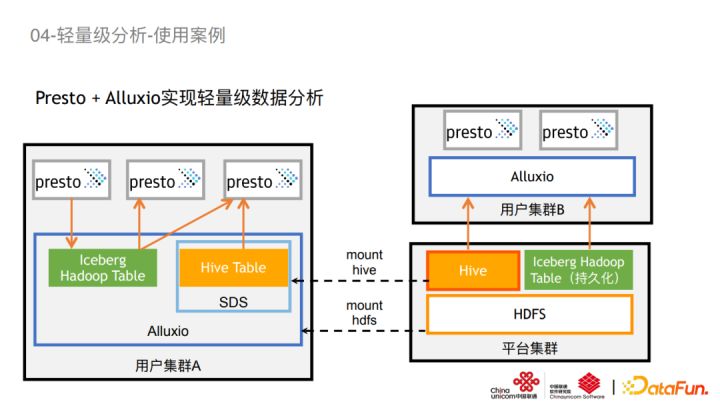
我们的思路是希望使用Presto+Alluxio做一个轻量级的数据分析,基于Presto Iceberg native connector,直接去操作存储在Alluxio上面的Hadoop catelog表,只需要加Presto + Alluxio两个组件,我们就可以完成整个ETL的过程。我们用了两套mount系统:第一套是比较传统的Alluxio直接去mount平台的HDFS;第二套是Alluxio structure data service(结构化数据服务)mount hive表,对于用户集群来说,他看到的hive表跟平台这边的hive表是一样的。Mount的好处是可以将数据透明地映射到Alluxio命名空间之内,通过Hive Table load提前把数据加载至Alluxio缓存中,增加数据读取性能。所有的中间过程只需要Presto以must cashe的方式写入Alluxio本地,加工完之后,就可以把这个数据最后的结果数据写回平台的hive。整个架构比较简单的,只需要两个组件,每台机只要起两个进程,没有额外的负担。
而且用户可以通过JDBC或者是Command line两种形式访问Presto,并且用户可以通过选择性的persist Iceberg Hadoop table来授权给其他集群用户访问中间数据。通过Alluxio的统一命名空间设计,用户看到的hive table、Iceberg table是完全一致的,实现了多个集群之间的透明管理。

在这个轻量级数据分析栈内,我们只需要在用户集群搭建两个组件就可以满足需求。因为用户基于Presto以纯SQL的方式完成数据分析,体验比较好。目前我们用户喜欢用JDBC的方式去连接,所以暂时不需要提供更多可视化工具。如果需要,只要在我们现有的可视化工具里配置链接就行。Alluxio mount平台HDFS用于私有化数据共享,SDS mount平台Hive用于共有数据访问及性能加,基于Presto Iceberg connector的hadoop catalog mode这种模式,可以采用只写缓存的方式在本地完成ETL。Alluxio全部使用的挂载磁盘的方式来保证缓存空间足够容纳数据分析中间数据,最终数据持久化至平台HDFS。Alluxio在写入的时候会使用三副本的策略,保证缓存数据的可用性。
分享嘉宾
张策 联通软件研究院 大数据工程师
嘉宾介绍:毕业于北京交通大学,2018年加入联通软件研究院,主要负责大数据平台的建设与维护,同时在Alluxio社区担任PMC Member。
想要获取更多有趣有料的【活动信息】【技术文章】【大咖观点】,请关注[Alluxio智库]:

|








- 上一条: 大厂钟爱的全链路压测有什么意义?四种压测方案详细对比分析 2022-09-13
- 下一条: Python图像处理丨带你认识图像量化处理及局部马赛克特效 2022-09-13
- 服务网格在联通的落地实践 2022-01-26
- RPC 技术及其框架 Sekiro 在爬虫逆向中的应用,加密数据一把梭! 2022-02-22
- 数字人技术在直播场景下的应用 2022-09-08
- Apache Kyuubi 在小米大数据平台的应用实践 2022-08-31
- 情感分析技术在美团的探索与应用 2021-10-26


