ChunJun Meetup演讲分享 | 基于袋鼠云开源框架的数仓一体化建设探索
8月27日,ChunJun社区联合OceanBase社区举办开源线下Meetup,围绕「构建新型的企业级数仓解决方案」主题,多位技术大牛和现场爱好者汇聚一堂,畅所欲言。
会上,袋鼠云大数据引擎开发专家莫问精心准备了一场主题为「袋鼠云开源框架基于数仓的一体化建设探索」的分享,通过“如何围绕数仓一体化建设进行探索”,“引进开源框架后如何解决建设难题”、“开源框架能够带来的收益”三个开发者极其关心的问题,助力快速了解袋鼠云开源框架在数仓一体化方面的能力。
秉持一直以来开源开放的初心,本文根据莫问演讲全文整理而来,欢迎分享给更多的开发者和爱好者共同学习、探讨。
开源框架诞生的背景
袋鼠云开源框架源于公司一站式数据服务产品-数栈。本着“取之开源,馈之开源”的决心,我们从基础设施、数据开发、任务运维三大方向分别开源了Taier、ChunJun以及ChengYing框架。
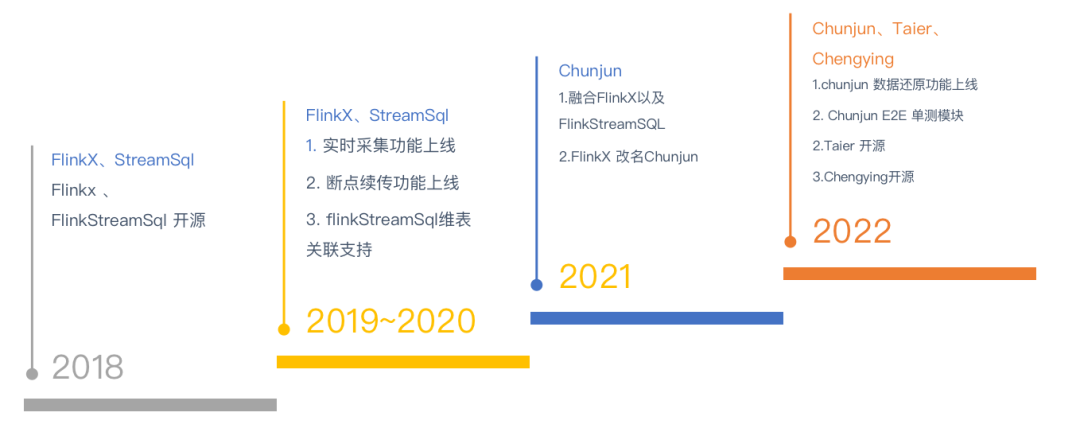 (开源框架事件时间线)
(开源框架事件时间线)
ChunJun——一种稳定、高效、易用的数据集成框架
• 稳定:接受过在上百家企业的生产环境下的长期考验
• 高效:大幅度降低用户的数据同步时常,使得每日tb级数据能够在数小时内同步完成
• 易用:开箱即用,无需额外的安装步骤
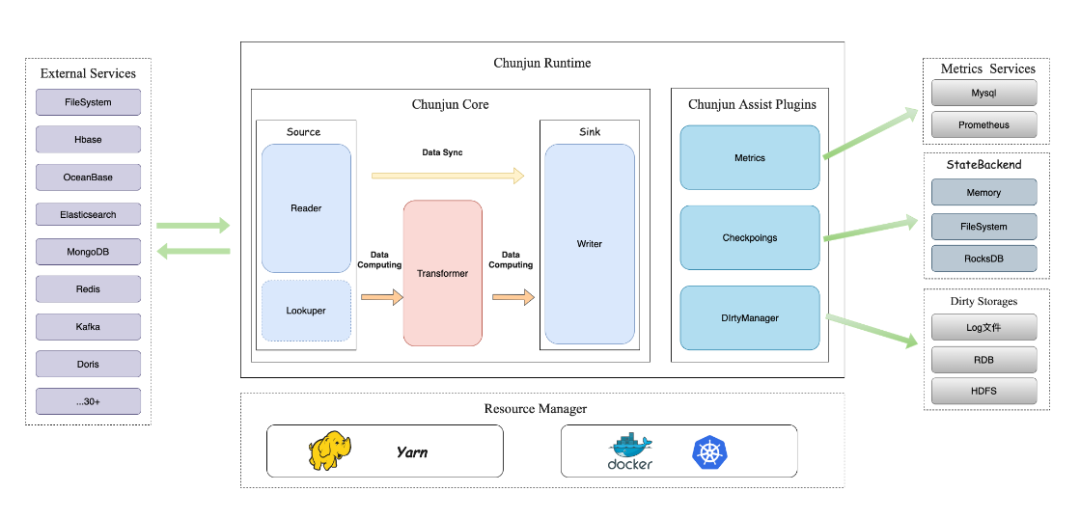 (ChunJun系统架构图)
(ChunJun系统架构图)
Taier——一种分布式可视化的DAG任务调度框架
• 稳定性:通过HA+过载处理,降低了单点故障的同时增强了框架的高负载处理能力
• 易于扩展:从部署架构层面,可横向扩展集群增下框架调度能力;从引擎层面,支持自定义任务类型,满足非原生任务调度
• 界面可视化:可视化工作流配置以及任务监控管理
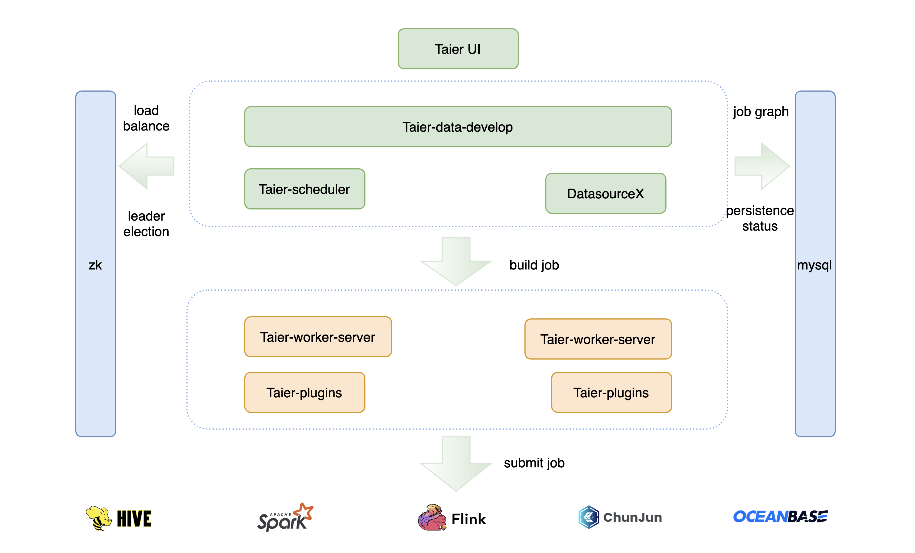 (Taier系统架构图)
(Taier系统架构图)
ChengYing——一种全自动化的大数据运维工具
• 快捷部署:支持服务的一键式部署,降低人工的重复操作以及失误率
• 统一资源管理:支持对集群中所有产品包、主机以及集群资源管理
• 服务监控以及告警:支持各服务实例运行状态、健康检查、服务性能等指标检测,并能够将结果进行可视化、告警通知等操作
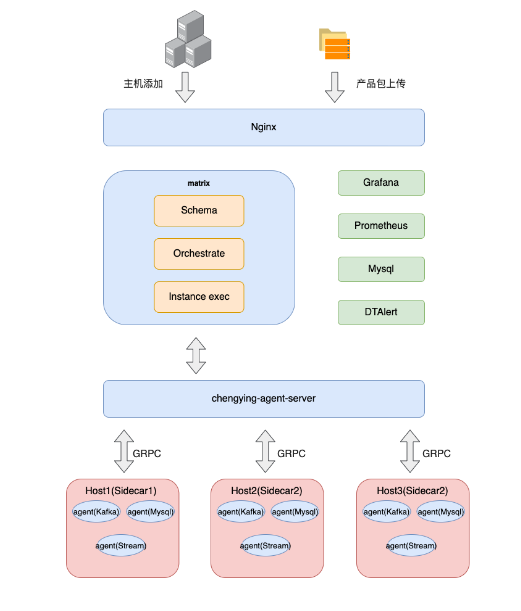 (ChengYing项目架构图)
(ChengYing项目架构图)
数据仓库一体化探索之路
前期软硬件准备阶段
硬软件准备阶段是一个比较耗时的过程,而通过开源框架ChengYing,我们可以添加对应的需要被ChengYing管控的主机以及将要安装在这些主机上相关服务的产品包。
随后通过ChengYing统一进行主机配置,并一键式快捷部署。当安装好对应的服务之后,可通过Prometheus以及Granfan监控各个主机的cpu、io、memory指标以及告警。
除此之外,还能够对所安装的服务进行滚动重启以及健康状态监控,从添加机器到软件安装完毕,整个过程大大降低了人工的投入成本以及失误操作。
建设阶段——实时
实时数据处理的需求在飞速增长,在各行各业均已得到证实。而我们同时也看到,各行业、企事业单位对于实时数据处理的需求,与其目前的项目开发方式和配套工具不适配的问题也在逐渐凸显。
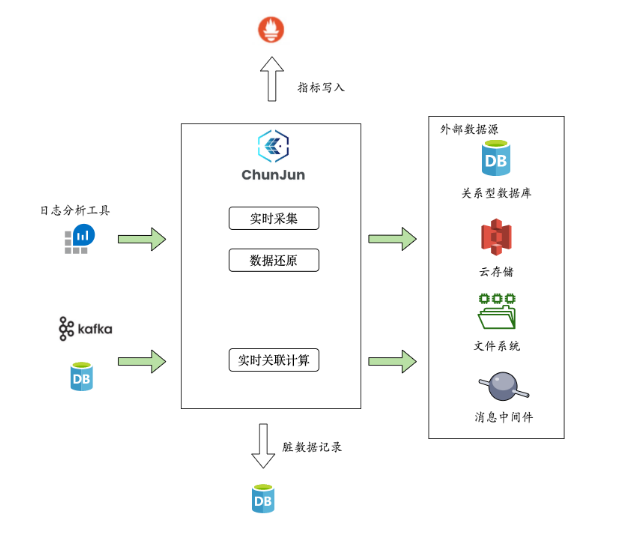
因此,我们引入实时数仓理念,通过ChunJun的实时采集、数据还原以及实时关联计算功能对实时数据进行处理和分层计算来满足日常的实时业务场景。
建设阶段——离线
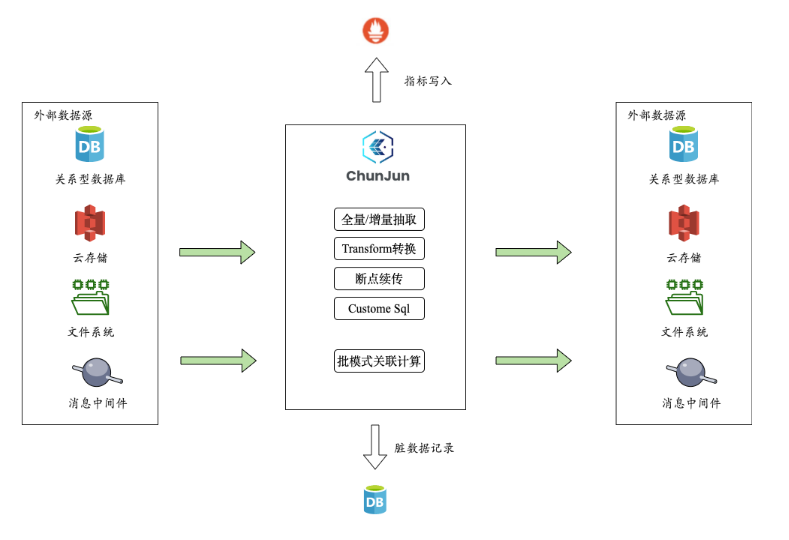
实时计算是为了让我们能够做更快的决策,而离线计算是为了对数据进行分析,挖掘出潜在的价值。因此将数据从业务数据库每日定时同步到OLAP数仓中进行清洗、转换以及计算是对数据进行挖掘的基础。
数据的按需同步以及容错性是我们更为关心的一点。
实施运行阶段
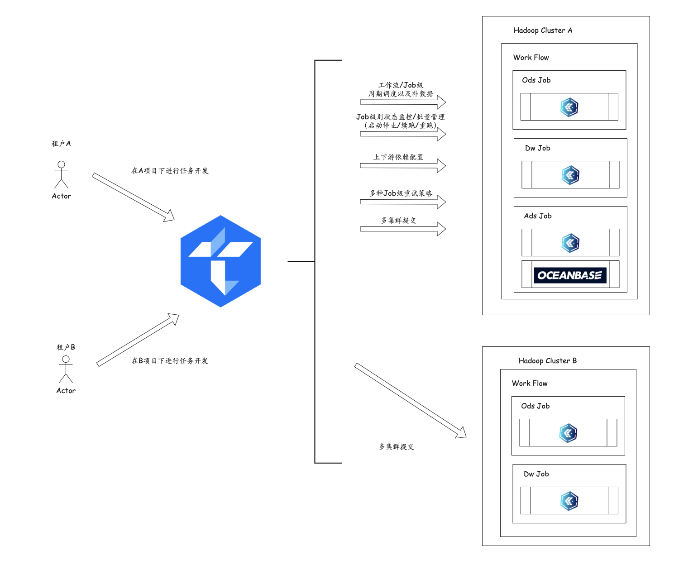
在数据仓库实施运行阶段,我们则选择Taier来支持我们数仓任务的调度。它能为我们提供任务的批量管理的同时,让我们对整个项目的任务运行情况了如指掌。对于失败的任务,我们能够按需配置任务的失败重试策略,减少我们对任务上线后的运维成本。
另外,考虑多会有不同的角色在不同的集群进行开发,我们正好可以利用Taier多租户多集群资源隔离的特性,来实现不同用户在一套Taier集群上分别运行不同的任务在各自Hadoop集群上。
业务规模
经过上述对数据仓库一体化的探索,目前的业务规模已经达到以下数字:
• 数仓相关任务数量:2000+个
• 单日任务最高实例数量:60000+个
• Tb级数据同步:3小时以内
• 每日处理增量数据:20亿
• 统一管控的机器规模数量:40台
开源框架在探索路上的演进过程
业务痛点
在数据仓库一体化的这条探索之路上,结合具体业务,我们也遇到了一些痛点亟待解决:
● Kerberos认证
Kerberos是hadoop安全的解决方案,越来越多的客户在hadoop集群中选择开启kerberos。而Kerberos部署、配置过程的复杂性、client的认证如何续期以及多kdc场景下是对接hadoop的第一道屏障。
● 数据读写性能
金融行业的历史行为数据通常是tb甚至pb级别的,即使每日的增量数据也有10亿行+。当通过Chunjun对数据进行全量/增量同步时,反馈运行时常达不到预期,以致影响对业务的决策时间。
● 批流一体
不论是基于lambda架构的流批独立还是基于kappa的纯实时架构在运行久了之后缺点也会逐渐暴露出来;比如lambda架构的开发维护成本日益增高以及kappa架构的实时计算任务因极端数据乱序导致计算数据不准确从而面临数据质量上的问题。
Kerberos认证支持
通过ChengYing部署Hadoop服务以及KDC服务并配置好相关权限生成Keytab文件以及Krb5文件。用户只需要关心是否从以配置好kerberos的hadoop集群将用户对应权限的keytab、krb5文件一键上传到Taier集群中。
后面经过Taier调度的ChunJun任务都会从集群中下载上传的kerberos认证相关信息,随后进行kerberos认证以及自动续期。使得用户不用在写大量kerberos认证代码以及浪费更多的时间在kerberos上,既保证了数据的安全也保证了开发效率。

数据读写性能-自定义序列化格式
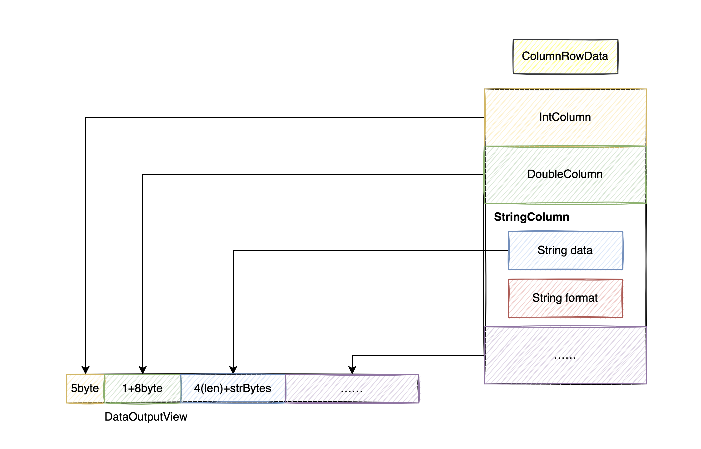
在经过我们多次对ChunJun性能的测试以及火焰图的分析之后,我们发现数据的序列化/以及反序列化是对读写性能损耗最大的一块,通过对Kryo序列化的研究,我们实现了自己的序列化格式:ColumnRowData。
相较于kryo序列化,ColumnRowData具有更为密集的存储,兼容null值以及减少不必要的数据传输等优势。
批流一体支持
当数据被采集到指定的存储层后,会结合存储类型以及业务时效性对数据进行常规的业务计算。ChunJun Sql能支持流批计算的能力来源于对元数据的统一管理以及在DataStream API上支持批执行模式。这样增强了作业的可复用性和可维护性,使得ChunJun作业可以在流和批两种执行模式之间自由进行切换并只需要维护一套代码,无需重新写任何代码。
除此之外,任务批流模式之间的切换计算也大幅度提升了数据最终的质量度以及准确性。
总结展望
引入开源框架后的收益
•引入ChunJun后业务开发周期缩短,开发人员只需专注于业务开发,无需关注底层的技术实现。大幅度降低了业务开发的整个生命周期
• 引入Taier后,技术同学专注业务开发,任务开发完毕后,不用关心任务错综复杂的依赖关系与底层的大数据平台的架构实现,将工作的重心更多地聚焦在业务之中
• 引入ChengYing后,运维部署成本降低,通过ChengYing,我们能够将原来手动部署Hadoop的时间从数小时缩短至6分钟;并能够对各个服务进行界面化监控以及管理,降低运维部署成本。
开源框架未来的规划
ChunJun:领先、稳定、高效
• 多版本数据源共存
• 类型转换统一规范化
• 数据还原功能更加完善
• E2E单测体系建立
• 全量&增量实时采集
• 数据湖生态完善
• 存储层批流统一
Taier:部署多样化、功能完善、多系统对接
• 新增其他任务类型支持
• 同时支持yarn/k8s
• 支持 Schedule/Worker整合与分离部署
• 支持交易日历、事件驱动
• 外部系统对接(Azkban、Control-M、DS)等
ChengYing:自动化、简便易用、告警类型丰富
• 支持基于主机角色与服务类型自动编排
• 支持通过集群开启Kerberos认证以及票据的生成与下载
• 自定义部署产品包流水线顺序
• 支持基于PromQL的自定义告警设置,丰富告警类型
袋鼠云开源框架钉钉技术交流群(30537511),欢迎对大数据开源项目有兴趣的同学加入交流最新技术信息,开源项目库地址:https://github.com/DTStack
|








- 上一条: 读完 RocketMQ 源码,我学会了如何优雅的创建线程 2022-09-08
- 下一条: FlyFish 开发者说|开源低代码平台的体验与思考 2022-09-08
- 基于开源流批一体数据同步引擎ChunJun数据还原—DDL解析模块的实战分享 2022-06-30
- 开源交流丨批流一体数据集成框架ChunJun数据传输模块详解分享 2022-08-24
- 开源交流丨批流一体数据集成框架ChunJun数据传输模块详解分享 2022-08-24
- 袋鼠云批流一体分布式同步引擎ChunJun(原FlinkX)的前世今生 2022-04-26
- 开源交流丨批流一体数据集成工具ChunJun同步Hive事务表原理详解及实战分享 2022-07-13