Apache Hudi X Apache Kyuubi,中国移动云湖仓一体的探索与实践
分享嘉宾:孙方彬 中国移动云能力中心 软件开发工程师
编辑整理:Hoh Xil
出品平台:DataFunTalk
导读:在云原生+大数据的时代,随着业务数据量的爆炸式增长以及对高时效性的要求,云原生大数据分析技术,经历了从传统数仓到数据湖,再到湖仓一体的演进。本文主要介绍移动云云原生大数据分析LakeHouse的整体架构、核心功能、关键技术点,以及在公有云/私有云的应用场景。
主要内容包括:
-
湖仓一体概述
-
移动云LakeHouse实践
-
应用场景
01 湖仓一体概述
1. 关于湖仓一体
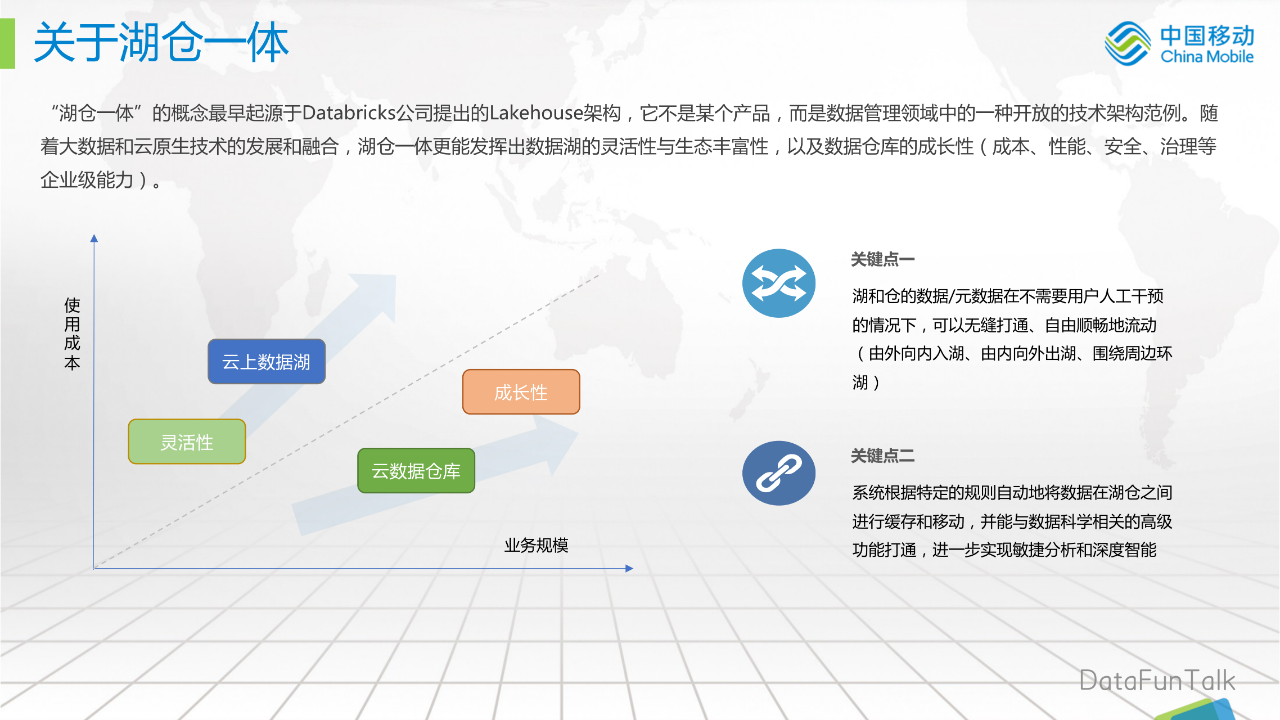
“湖仓一体”是最近比较火的一个概念,“湖仓一体”的概念最早起源于Databricks公司提出的Lakehouse架构,它不是某个产品,而是数据管理领域中的一种开放的技术架构范例。随着大数据和云原生技术的发展和融合,湖仓一体更能发挥出数据湖的灵活性与生态丰富性,以及数据仓库的成长性。这里的成长性包括:服务器的成本,业务的性能,企业级的安全、治理等特性。
大家可以看到(左图),在特定业务规模前,数据湖的灵活性有一定优势,随着业务规模的增长,数据仓库的成长性更有优势。
湖仓一体的2个关键点:
-
湖和仓的数据/元数据在不需要用户人工干预的情况下,可以无缝打通、自由顺畅地流(包括:由外向内入湖、由内向外出湖、围绕周边环湖);
-
系统根据特定的规则自动地将数据在湖仓之间进行缓存和移动,并能与数据科学相关的高级功能打通,进一步实现敏捷分析和深度智能。
2. 主要理念

随着业务数据量的爆炸式增长以及业务对高时效性的要求,大数据分析技术经历了从传统数仓到数据湖,再到湖仓一体的演进。传统基于Hadoop的大数据平台架构也是一种数据湖架构,湖仓一体的核心理念以及与当前Hadoop集群架构的区别大致如下:
-
存储多种格式的原始数据:当前Hadoop集群底层存储单一,主要以HDFS为主,对于湖仓一体来说,逐渐会演进为支持多种介质,多种类型数据的统一存储系统
-
统一的存储系统:当前根据业务分多个集群,之间大量数据传输,逐渐演进到统一存储系统,降低集群间传输消耗
-
支持上层多种计算框架:当前Hadoop架构的计算框架以MR/Spark为主,未来演进为在数据湖上直接构建更多计算框架和应用场景
湖仓一体的产品形态大致有两类:
-
基于公有云上数据湖架构的产品和解决方案(例如:阿里云MaxCompute湖仓一体、华为云FusionInsight智能数据湖)
-
基于开源Hadoop生态的组件(DeltaLake、Hudi、Iceberg)作为数据存储中间层(例如:Amazon智能湖仓架构、Azure Synapse Analytics)
02 移动云LakeHouse实践
下面介绍移动云LakeHouse的整体架构及对湖仓一体的探索和实践:
1. 整体架构
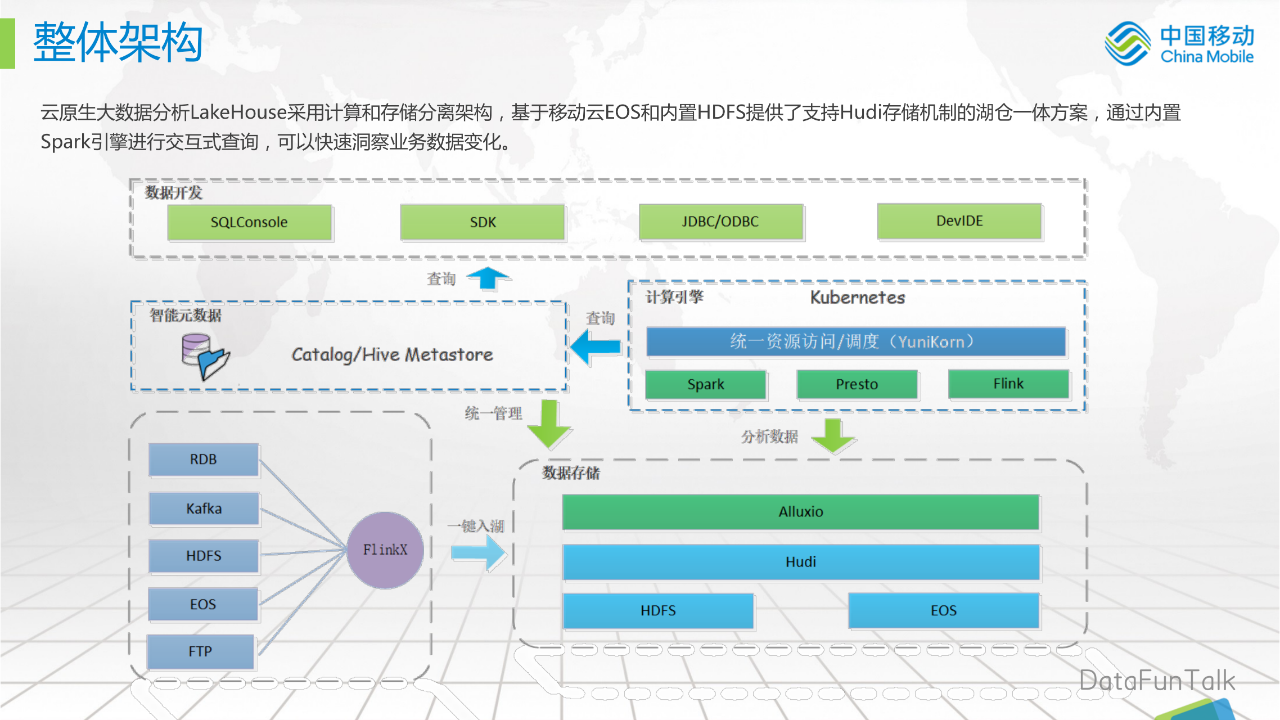
上图是我们的整体架构图,名字叫云原生大数据分析LakeHouse。云原生大数据分析LakeHouse采用计算和存储分离架构,基于移动云对象存储EOS和内置HDFS提供了支持Hudi存储机制的湖仓一体方案,通过内置Spark引擎进行交互式查询,可以快速洞察业务数据变化。
我们的架构具体包括:
-
数据源:包括RDB、Kafka、HDFS、EOS、FTP,通过FlinkX一键入湖
-
数据存储(数据湖):我们内置了HDFS和移动云的EOS,借助Hudi实现Upsert能力,达到近实时的增量更新,我们还适当地引入Alluxio,进行数据缓存,来达到数据分析的SQL查询加速能力。
-
计算引擎:我们的计算引擎都是Severless化的,跑在Kubernetes中。我们引入了统一资源访问/调度组件YuniKorn,类似于传统Hadoop生态体系中YARN的资源调度,会有一些常见的调度算法,比如共性调度,先进先出等常见的调度
-
智能元数据:智能元数据发现,就是将我们数据源的数据目录转化成内置存储中的一个Hive表,统一进行元数据管理
-
数据开发:SQLConsole,用户可以直接在页面上编写SQL进行交互查询;还有SDK的方式,以及JDBC/ODBC接口;后续我们会支持DevIDE,支持在页面上的SQL开发
2. 核心功能

核心功能主要有以下四方面:
① 存储和计算分离:
-
存储层与计算层分离部署,存储和计算支持独立弹性扩缩容,相互之间没有影响
-
存储支持对象存储和HDFS,HDFS存储结构化数据,提供高性能存储,对象存储存储非结构化、原始数据、冷数据,提供高性价比
-
计算支持多引擎,Spark、Presto、Flink均实现serverless化,即开即用,满足不同查询场景
② 一键入湖:
-
支持连接移动云云上云下多种数据库、存储、消息队列
-
入湖流程自动化,降低用户的配置成本
-
降低对数据源的额外负载,控制在10%以内,支持根据数据源的实例规格自动调整连接数(比如在MySQL同步数据时,会在MySQL负载允许的情况下,自动调整连接数)
-
支持增量更新(通过Hudi实现增量更新)
③ 智能元数据发现:
-
基于特定的规则,智能识别结构化、半结构化文件的元数据,构建数据目录
-
自动感知元数据变化
-
统一元数据,提供类HiveMeta API,针对不同计算引擎访问底层数据
-
智能数据路由和权限统一管控(借助移动云的账号体系和Ranger实现的)
④ 按量计算:
-
存储资源按照使用量计费
-
计算资源支持多种计费模式
-
支持弹性调整租户集群资源规格,快速扩缩容
3. 基于RBF的逻辑视图
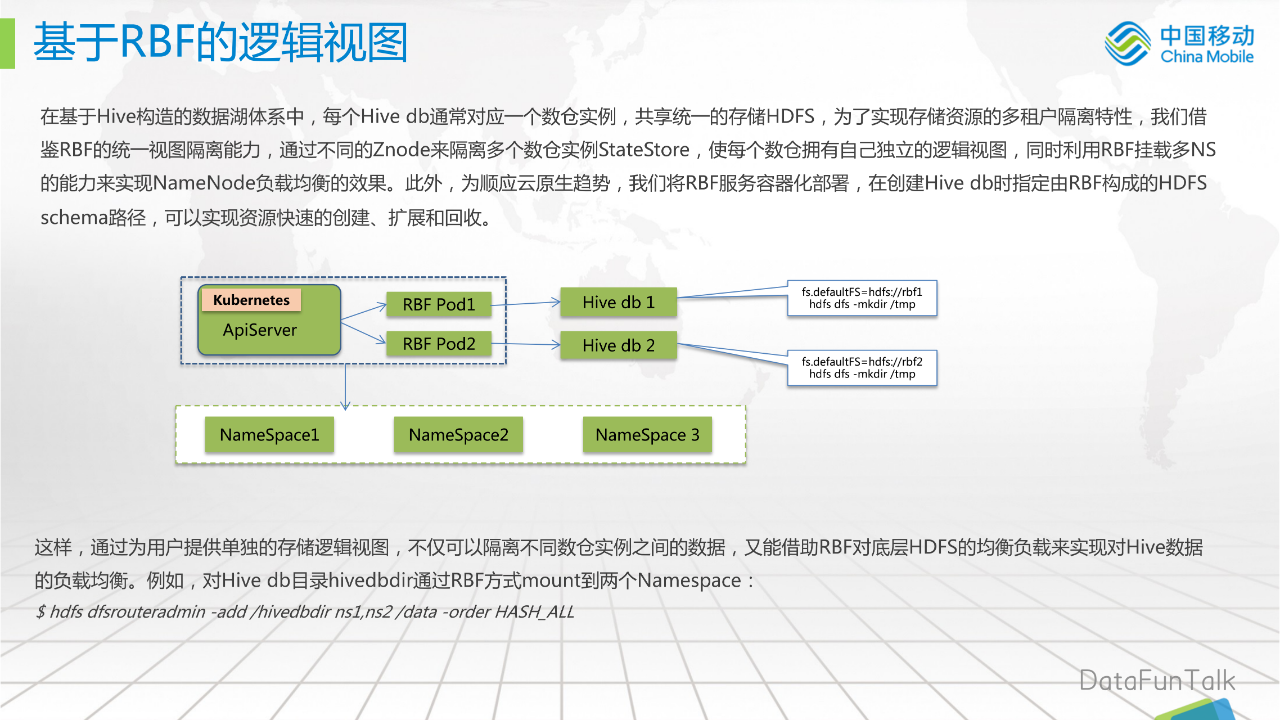
在基于Hive构造的数据湖体系中,每个Hive db通常对应一个数仓实例,共享统一的存储HDFS,为了实现存储资源的多租户隔离特性,我们借鉴RBF的统一视图隔离能力,通过Zookeeper上不同的Znode来隔离多个数仓实例StateStore,使每个数仓拥有自己独立的逻辑视图,同时利用RBF挂载多NameSpace的能力来实现NameNode负载均衡的效果。此外,为顺应云原生趋势,我们将RBF服务容器化部署,在创建Hive db时指定由RBF构成的HDFSschema路径,可以实现资源快速的创建、扩展和回收。
上图是我们的一个简单的架构图,RBF以Pod的形式部署在Kubernetes中,然后Hivedb分别映射为一个RBF的schema路径。然后,下面是借助了NameSpace的负载均衡能力。
这样,通过为用户提供单独的存储逻辑视图,不仅可以隔离不同数仓实例之间的数据,又能借助RBF对底层HDFS的负载均衡来实现对Hive数据的负载均衡能力。
例如,对Hive db目录hivedbdir通过RBF方式mount到两个Namespace,挂载命令如下:
$ hdfs dfsrouteradmin -add/hivedbdir ns1,ns2 /data -order HASH_ALL4. Hive在对象存储的多租户实现
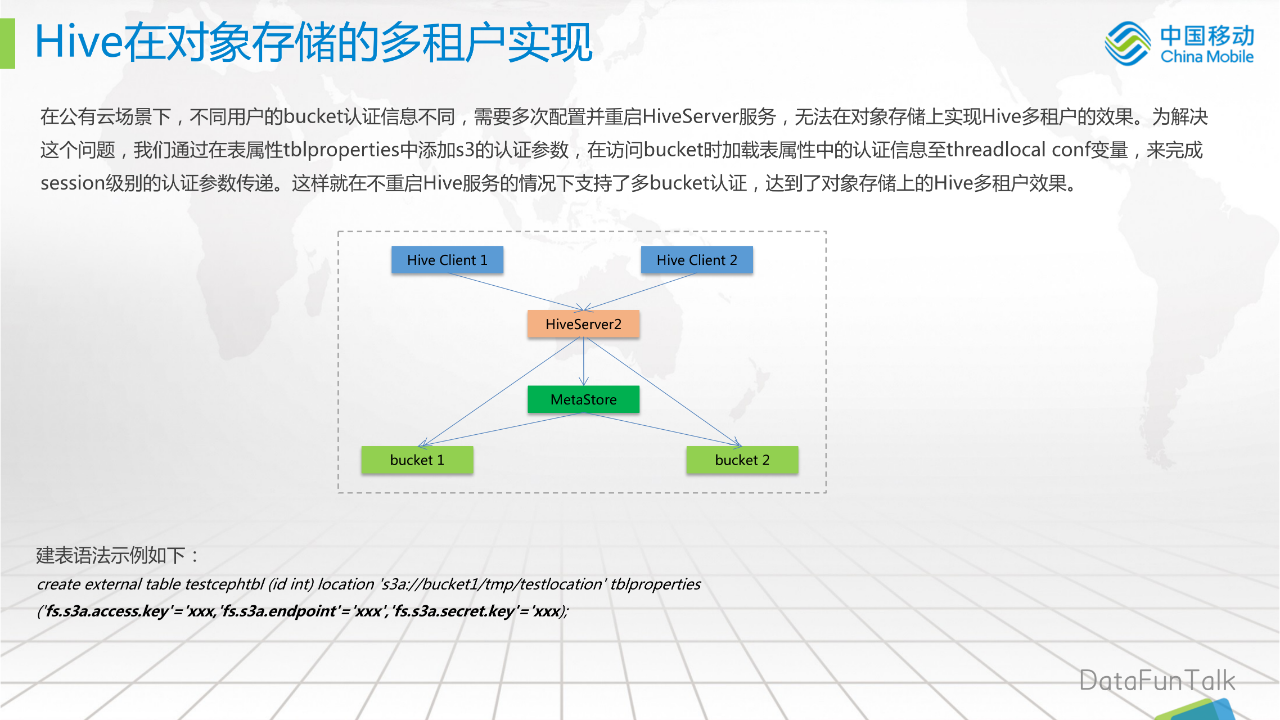
在公有云场景下,不同用户的bucket认证信息不同,需要多次配置并重启HiveServer服务,无法在对象存储上实现Hive多租户的效果。为解决这个问题,我们通过修改Hive源码在表属性tblproperties中添加s3的认证参数,在访问bucket时加载表属性中的认证信息至threadlocal conf变量,来完成session级别的认证参数传递。这样就在不重启Hive服务的情况下支持了多bucket认证,达到了对象存储上的Hive多租户效果。
如图所示,如果在服务端为用户配置不同的参数,就需要重启服务,这时不能够接受的。经过我们的改造之后,建表语法就变成了下面这种格式:
create external table testcephtbl(id int) location 's3a://bucket1/tmp/testlocation' tblproperties('fs.s3a.access.key'='xxx,'fs.s3a.endpoint'='xxx','fs.s3a.secret.key'='xxx);5.优化引擎访问对象存储
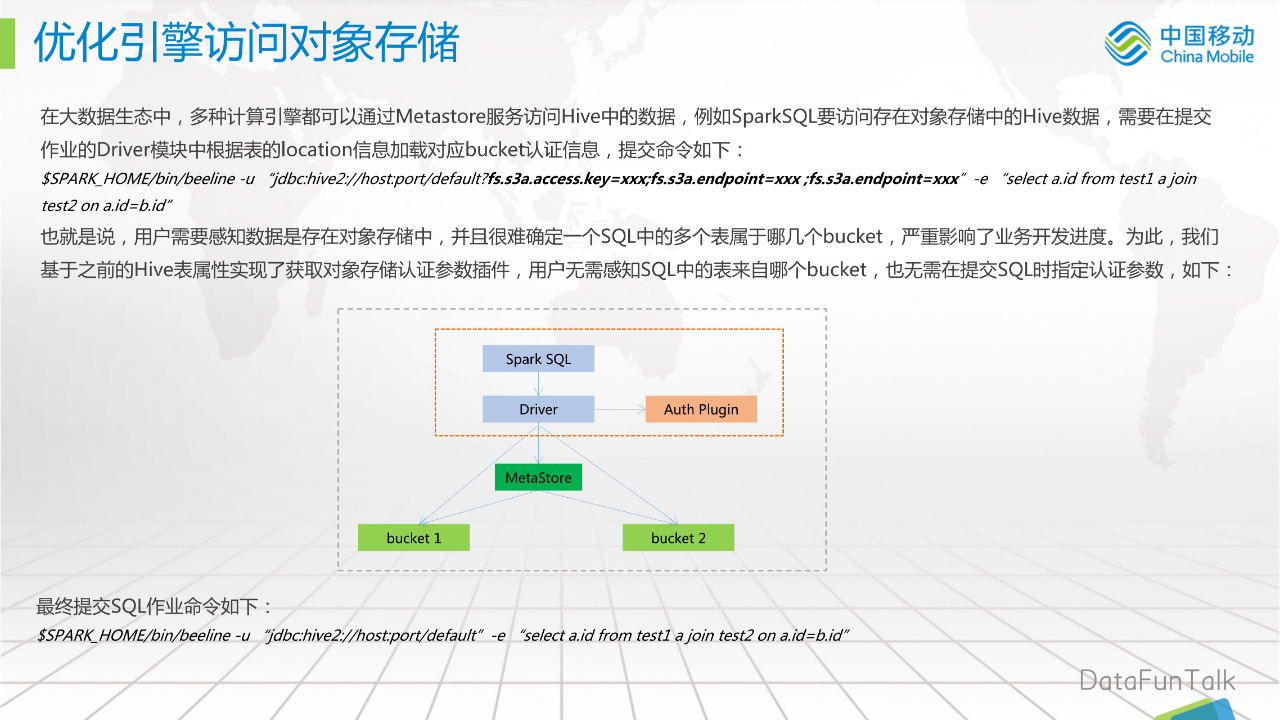
在大数据生态中,多种计算引擎都可以通过Metastore服务访问Hive中的数据,例如SparkSQL要访问存在对象存储中的Hive数据,需要在提交作业的Driver模块中根据表的location信息加载对应bucket认证信息,SQL提交命令如下:
$SPARK_HOME/bin/beeline-u “jdbc:hive2://host:port/default?fs.s3a.access.key=xxx;fs.s3a.endpoint=xxx;fs.s3a.endpoint=xxx”-e “selecta.id from test1 a join test2 on a.id=b.id”也就是说,用户需要感知数据是存在对象存储中,并且很难确定一个SQL中的多个表属于哪几个bucket,严重影响了业务开发进度。为此,我们基于之前的Hive表属性实现了获取对象存储认证参数插件,用户无需感知SQL中的表来自哪个bucket,也无需在提交SQL时指定认证参数。如上图橙色框所示,Spark SQL在Driver中实现参数,来匹配认证参数信息。对MetaStore来说是一个统一的访问视图。
最终提交SQL作业命令如下:
$SPARK_HOME/bin/beeline -u “jdbc:hive2://host:port/default”-e “select a.id from test1 a join test2 ona.id=b.id”6. Serverless实现

这里以Spark为例,通过RBF的多租户实现,Spark进程运行在安全隔离的K8S Namespace中,每个Namespace根据资源规格对应不同的计算单元(例如:1CU=1 core * 4GB)。对于微批的场景,使用SQL Console每提交一个task,engine模块会启动一个Spark集群,为Driver和Executor按特定的算法申请相应的计算资源来运行计算任务,任务结束后资源即刻回收;对于即席ad-hoc的场景,可以使用JDBC提交task,engine模块通过Kyuubi服务启动一个session可配置的spark集群,长驻一段时间后回收资源;所有的SQL task只有在运行成功后按实际的资源规格计费,如果不使用是不收费的。
逻辑视图如上,我们的Kubernetes通过每个Namespace把资源进行隔离;上面是一个统一调度的YuniKorn进行Capacity Management/Job Scheduling的调度。再往上是SQL Parser组件,会把SparkSQL和HiveSQL语法进行兼容;最上方,我们还提供了Spark JAR的方式,能够支持分析HBase或者其它介质中结构化/半结构化的数据。
通过Serverless的实现,我们大大的降低了用户的使用流程。
没有用Serverless时的流程:
① 购买服务器,构建集群
② 部署一套开源大数据基础组件:HDFS、Zookeeper、Yarn、Ranger、Hive等
③ 利用不同工具导入数据
④ 编写查询SQL计算,输出结果
⑤ 各种繁琐的运维
使用Sercerless后的流程:
① 注册移动云账号,订购LakeHouse实例
② 创建数据同步任务
③ 编写查询SQL计算,输出结果
④ 服务全托管,全程无运维
7. 元数据管理与发现
元数据管理模块基于特定规则,智能识别结构化、半结构化文件的元数据来构建数据目录,通过周期性的元数据爬取实现自动感知元数据变化,并提供多种优化策略来降低爬取时对数据源的负载;同时,提供类Hive Metastore的API供多种计算引擎直接对表进行访问:
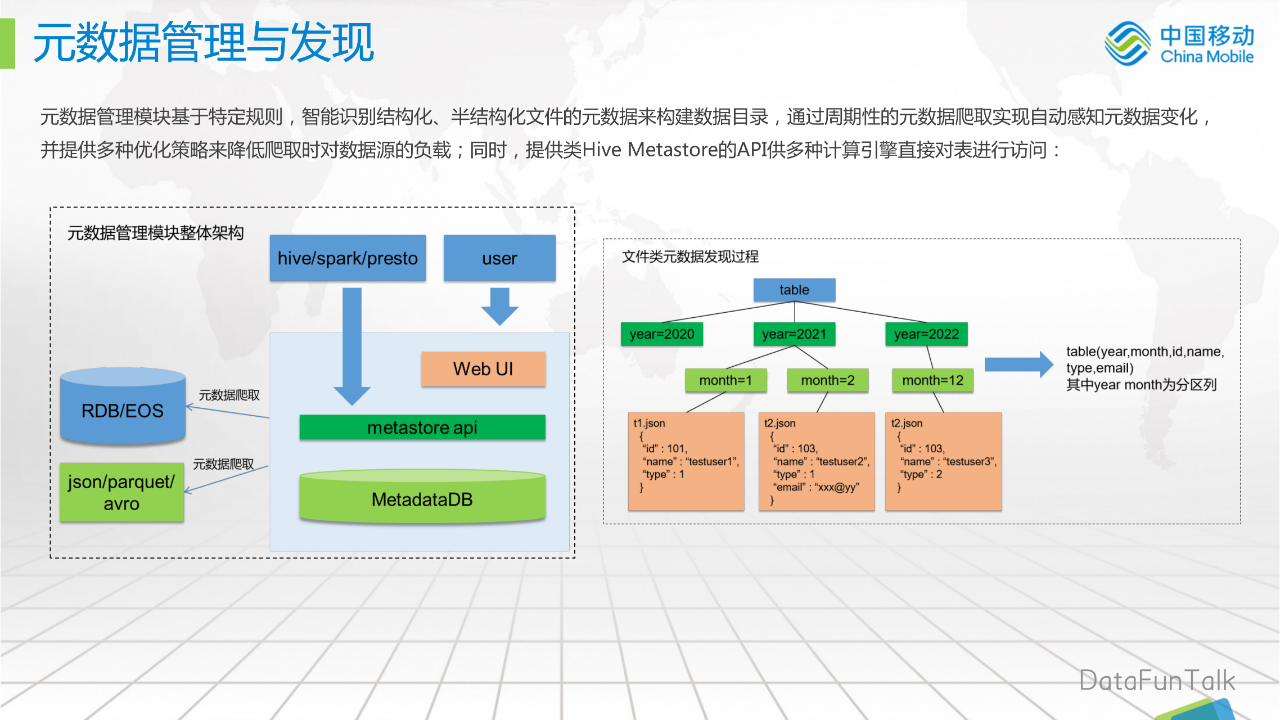
元数据管理模块整体架构如左图所示:通过元数据爬取RDB/EOS数据,格式有json/parquet/avro等常见的半结构化数据,然后是Hive MetaStore统一访问层,计算引擎hive/spark/presto可以通过类metastore api来访问存在湖中的数据,用户通过Web UI进行目录映射。
文件类元数据发现过程,如右图所示:有一张表,下面有几个目录,比如按year分开的,然后在某个具体目录有两个子目录,对于它的元数据发现过程,就会出现3行的数据,id、name和type,就会映射成同一张表,然后不同的目录是按不同的字段进行分区。
8. Serverless一键入湖
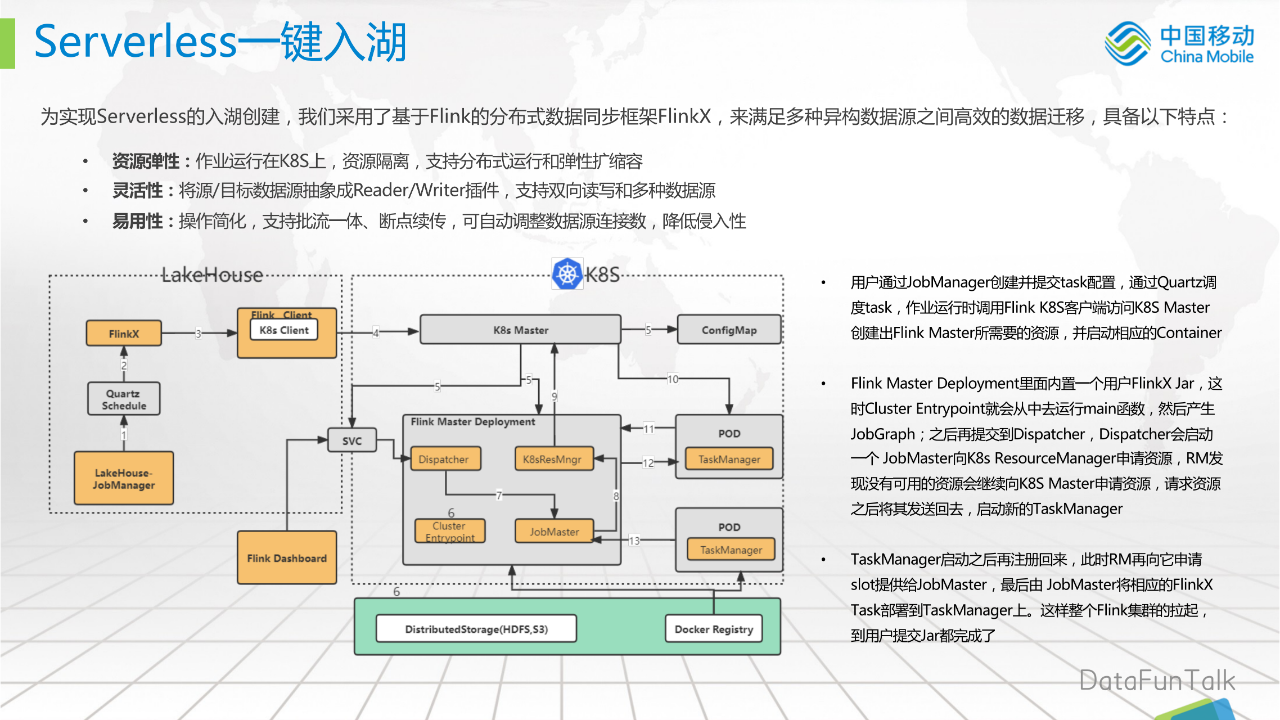
为实现Serverless的入湖创建,我们采用了基于Flink的分布式数据同步框架FlinkX,来满足多种异构数据源之间高效的数据迁移,具备以下特点:
-
资源弹性:作业运行在Kubernetes上,资源隔离,支持分布式运行和弹性扩缩容
-
灵活性:将源/目标数据源抽象成Reader/Writer插件,支持双向读写和多种数据源
-
易用性:操作简化,支持批流一体、断点续传,可自动调整数据源连接数,降低侵入性
上图是我们通过FlinkX进行调度任务的流程:
-
用户通过JobManager创建并提交task配置,通过Quartz调度task,作业运行时调用Flink Kubernetes客户端访问Kubernetes Master创建出Flink Master所需要的资源,并启动相应的Container;
-
Flink Master Deployment里面内置一个用户FlinkX Jar,这时Cluster Entrypoint就会从中去运行main函数,然后产生JobGraph;之后再提交到Dispatcher,Dispatcher会启动一个 JobMaster向KubernetesResourceManager申请资源,RM发现没有可用的资源会继续向Kubernetes Master申请资源,请求资源之后将其发送回去,启动新的TaskManager;
-
TaskManager启动之后再注册回来,此时RM再向它申请slot提供给JobMaster,最后由 JobMaster将相应的FlinkX Task部署到TaskManager上。这样整个Flink集群的拉起,到用户提交Jar都完成了。
我们的Flink集群其实也是一种serverless的实现。
9. JDBC支持

为了提升不同用户的数据分析体验,我们基于Apache Kyuubi来支持多租户、多种计算引擎的JDBC连接服务,Kyuubi具有完整的认证和授权服务,支持高可用性和负载均衡,并且提供两级弹性资源管理架构,可以有效提高资源利用率。
在接触Kyuubi前,我们尝试使用了原生的Spark thrift server来实现,但是它有一定的局限性,比如不支持多租户,单点的不具备高可用,资源是长驻的,资源调度需要自己来管理。我们通过引入Kyuubi来支持多租户和高可用,通过engine动态申请释放,并且Kyuubi支持Yarn和Kubernetes资源调度。
在使用过程中,为了适配移动云的账号体系以及LakeHouse架构,我们对Kyuubi相应的模块进行了优化和改造,部分如下:
-
用户认证:基于移动云AccessKey,SecretKey对接移动云认证体系。
-
资源管理:Kyuubi原生只支持用户指定资源,基于云原生适配后禁止用户指定资源,统一由Lakehouse进行资源调度和分配。
-
权限管控:适配Lakehouse底层权限管理体系,实现细粒度权限的管控。
-
云原生部署:基于Helm3的kyuubi server云原生部署,支持高可用和负载均衡
-
对象存储:支持对象存储表识别和动态ak,sk权限认证
10. 增量更新
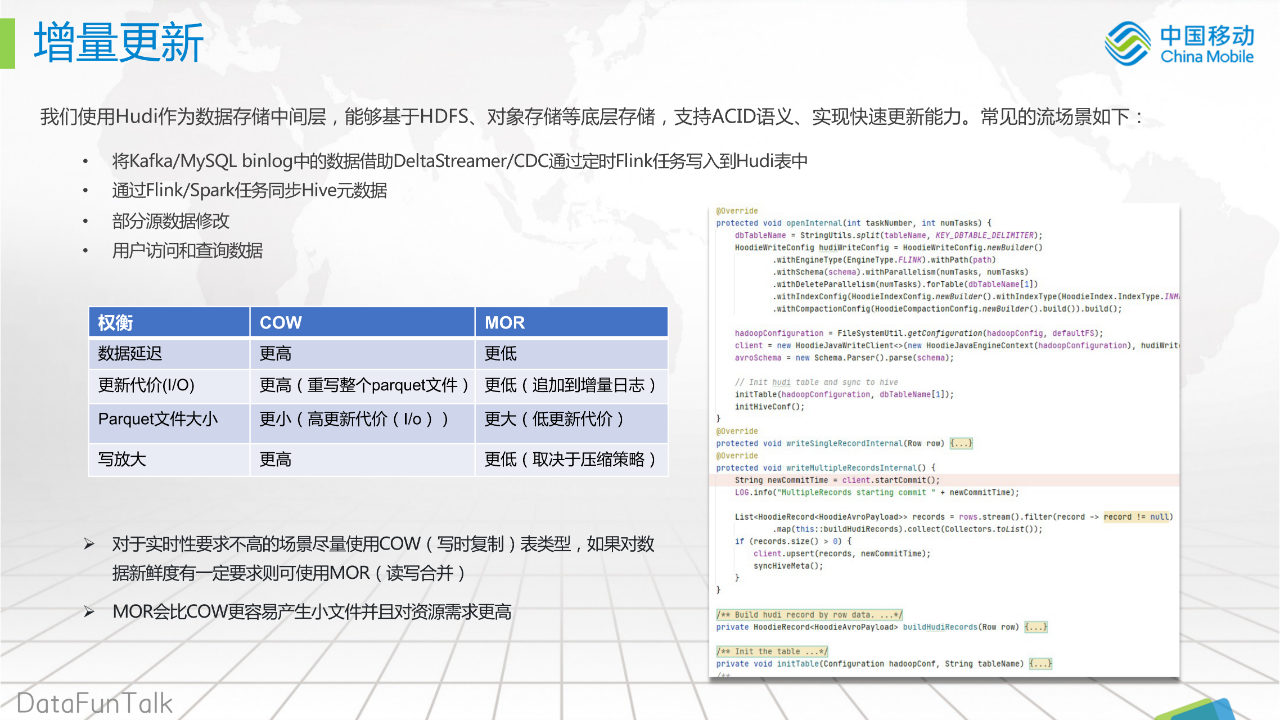
我们使用Hudi作为数据存储中间层,能够基于HDFS、对象存储等底层存储,支持ACID语义、实现快速更新能力。常见的流场景如下:
-
将Kafka/MySQL binlog中的数据借助DeltaStreamer/CDC通过定时Flink任务写入到Hudi表中
-
通过Flink/Spark任务同步Hive元数据
-
部分源数据修改
-
用户访问和查询数据
如右图所示,我们封装了Hudi自带的DeltaStreamer / CDC,自定义FlinkX的Reader / Writer特性,实现serverless入湖和数据同步。
如左图所示,我们比较了两种数据格式:
-
对于实时性要求不高的场景尽量使用COW(写时复制)表类型,如果对数据新鲜度有一定要求则可使用MOR(读写合并)
-
MOR会比COW更容易产生小文件并且对资源需求更高
以上就是移动云Lakehouse实现的细节。
03 应用场景

最主要的场景是构建云原生大数据分析平台:LakeHouse支持多样化数据来源,包括但不限于应用自身产生的数据、采集的各类日志数据、数据库中抽取的各类数据,并提供离线批处理、实时计算、交互式查询等能力,节省了搭建传统大数据平台需投入的大量软硬件资源、研发成本及运维成本。
另外,在私有云场景下,在充分利用现有集群架构的前提下,以新增组件方式引入Lakehouse能力;引入数仓能力,适配多种数据统一存储和管理;统一元数据,形成湖仓一体的元数据视图:
-
Hadoop平台视图:Lakehouse作为Hadoop平台上一个组件,能够提供SQL查询能力,并支持多种数据源
-
湖仓视图:基于LakeHouse提供数据湖仓平台,HDFS/OceanStor提供存储,计算云原生,多种服务统一元数据管理。
今天的分享就到这里,谢谢大家。
分享嘉宾:

|








- 上一条: 大促活动如何抵御大流量 DDoS 攻击? 2022-09-06
- 下一条: Apache Hudi X Apache Kyuubi,中国移动云湖仓一体的探索与实践 2022-09-06
- 字节跳动基于 Apache Hudi 的多流拼接实践方案 2022-03-30
- 应用实践 | Apache Doris 整合 Iceberg + Flink CDC 构建实时湖仓一体的联邦查询分析架构 2022-06-23
- Apache Kyuubi(Incubating):网易对 Serverless Spark 的探索与实践 2021-08-27
- 基于MRS-Hudi构建数据湖的典型应用场景介绍 2021-12-09
- T3 出行 Apache Kyuubi Flink SQL Engine 设计和相关实践 2022-03-30


