数据湖架构及概念简介
👨🎓摘要:本文整理自阿里云开源大数据技术专家陈鑫伟在7月17日阿里云数据湖技术专场交流会的分享。本篇内容主要分为两个部分:
- 数据湖演进历程
- 云原生数据湖架构
一、数据湖演进历程
什么是数据湖?
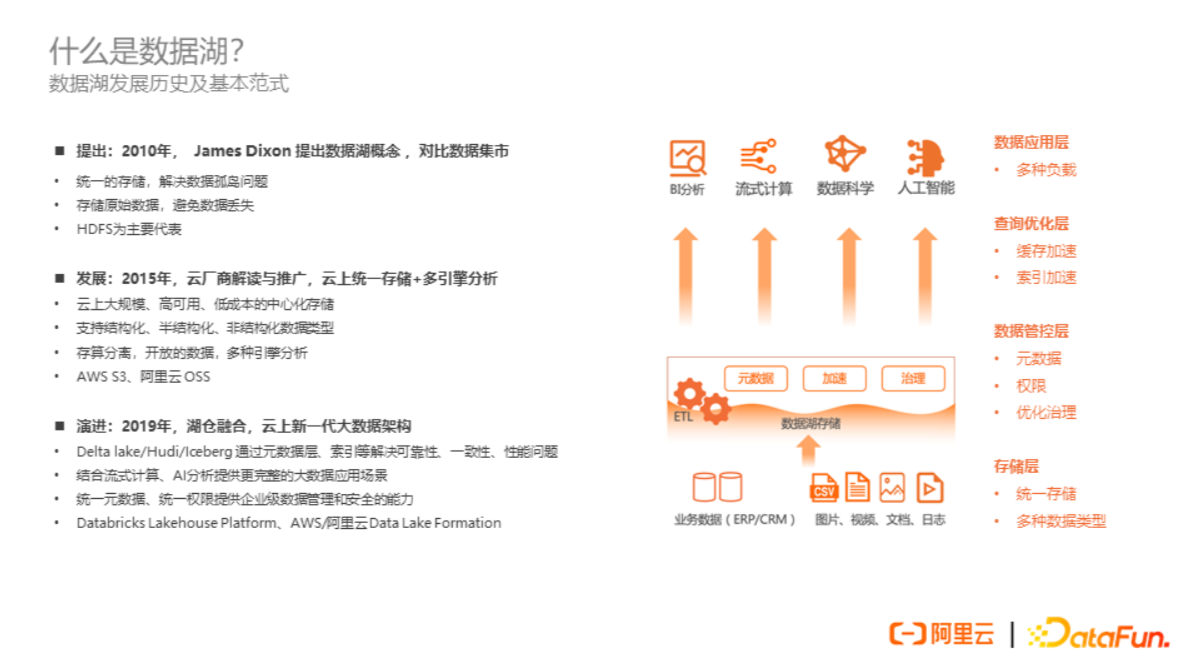
数据湖概念于 2010 年提出,其目的是解决传统数据仓库和数据集市所面临的两个问题:其一,希望通过统一的元数据存储解决数据集市之间的数据孤岛问题;其二,希望存储原始数据,而非存储数据集市建设过程中经过裁剪后的数据,以避免数据原始信息的丢失。当时,开源的 Hadoop 是数据湖的主要代表。
随着云计算的发展, 2015 年,各个云厂商开始围绕云上的对象存储重新解读和推广数据湖。云上对象存储具有大规模、高可用和低成本的优势,逐步替代了 HDFS 成为云上统一存储的主流选择。云上的对象存储支持结构化、半结构化和非结构化的数据类型,同时以存算分离的架构和更开放的数据访问方式支持多种计算引擎的分析,主要代表有 AWS S3 和阿里云的OSS。
2019年,随着 Databricks 公司和 Uber 公司陆续推出Delta Lake、Hudi 和 Iceberg 数据湖格式,通过在数据湖的原始数据之上再构建一层元数据层、索引层的方式,解决数据湖上数据的可靠性、一致性和性能等问题。同时,流式计算技术如Flink、AI 技术等也开始在数据湖上有了更广泛的应用。
同年,AWS 和阿里云也相继推出了 Data Lake Formation 等数据湖构建和管理的产品,能够帮助用户更快速地构建和管理云上数据湖。数据湖架构的不断演进和成熟也得到了更多客户的关注和选择。
数据湖架构演进
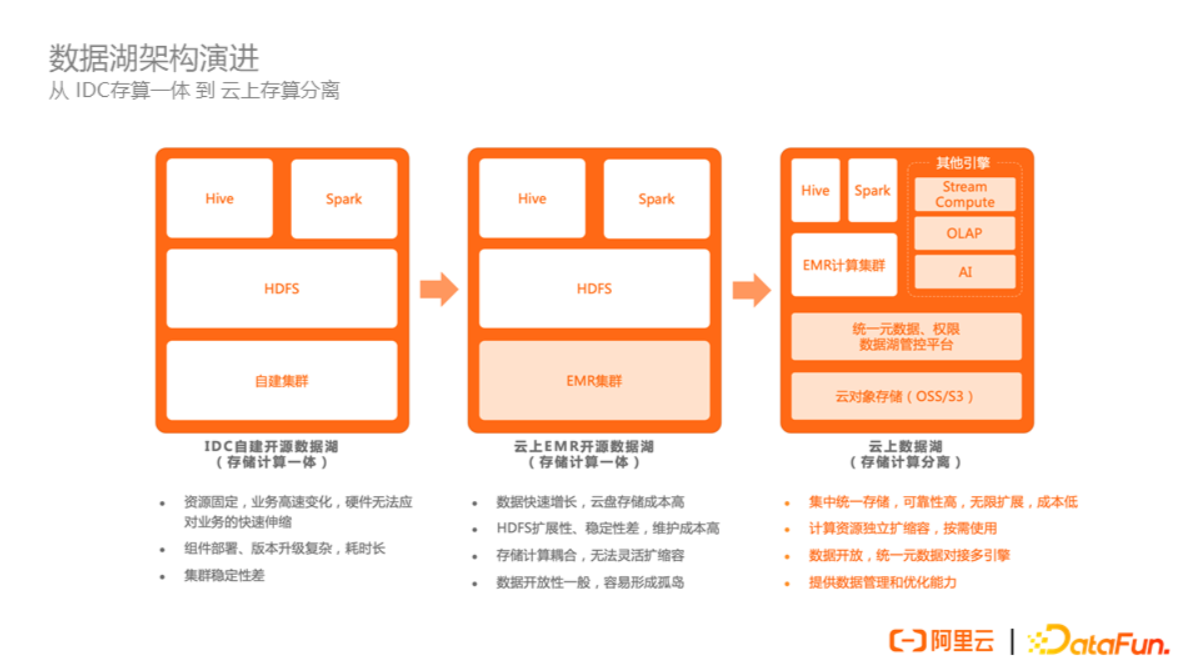
早期,用户基本在 IDC 机房里基于服务器或虚拟机建设 Hadoop 集群,主要的存储为 HDFS ,主流的计算引擎为 Hive 和 Spark 等。
随着云计算的发展,很多用户为了解决 IDC 机房在资源扩缩容和运维方面的困难,开始选择在云上构建自己的数据湖平台。可以选择云上提供的大数据构建平台,比如EMR,来帮助快速建设和部署多个集群。
但大部分早期用户选择直接将云下的架构搬到云上,依然以 HDFS为主要的存储,因此 HDFS 的问题依然存在,比如 NameNode 的扩展性问题、稳定性问题;比如计算资源和存储资源的耦合问题等;数据也存储于集群内部,跨集群、跨引擎的数据访问也会存在问题。
而现在更主流的选择是数据湖架构,基于云上对象存储如OSS做统一存储。在存储之上,有一套管控平台进行统一的元数据管理、权限管理、数据的治理。再上层会对接更丰富的计算引擎或计算产品,除了 Hadoop、Hive、Spark 等离线分析引擎,也可以对接流式的引擎比如 Flink,Olap引擎如 ClickHouse、Doris、StarRocks 等。
二、云原生数据湖架构
阿里云数据湖发展历程

阿里云在数据湖方向已经经过了很多年的发展。最早期的 OSS 发布于2011年,彼时数据湖的应用场景还很少。直到 2015 年,阿里云发布了云上 EMR 产品,开始将 Hive 和Spark 放至 EMR 集群,再将数据放至OSS,存算分离的架构开始流行。
2018年和 2019 年,阿里云相继推出了数据湖分析DLA和数据湖构建DLF两款专门面向数据湖的产品。 2022 年推出的数据湖存储(OSS-HDFS)以及 EMR Data Lake 集群,数据湖解决方案的产品矩阵逐步形成。
整个历程中,有三个标志性事件:2019年,阿里云发布了《阿里云云原生数据湖白皮书》,很多业内伙伴都基于这份白皮书开始研究学习和建设自己的数据湖;同年阿里云也打通数据湖和自研的 MaxCompute 云原生数仓,推出了湖仓一体架构; 2022 年,阿里云成为首批通过通信院的云原生数据湖测评认证的企业。
数据湖建设思路及挑战
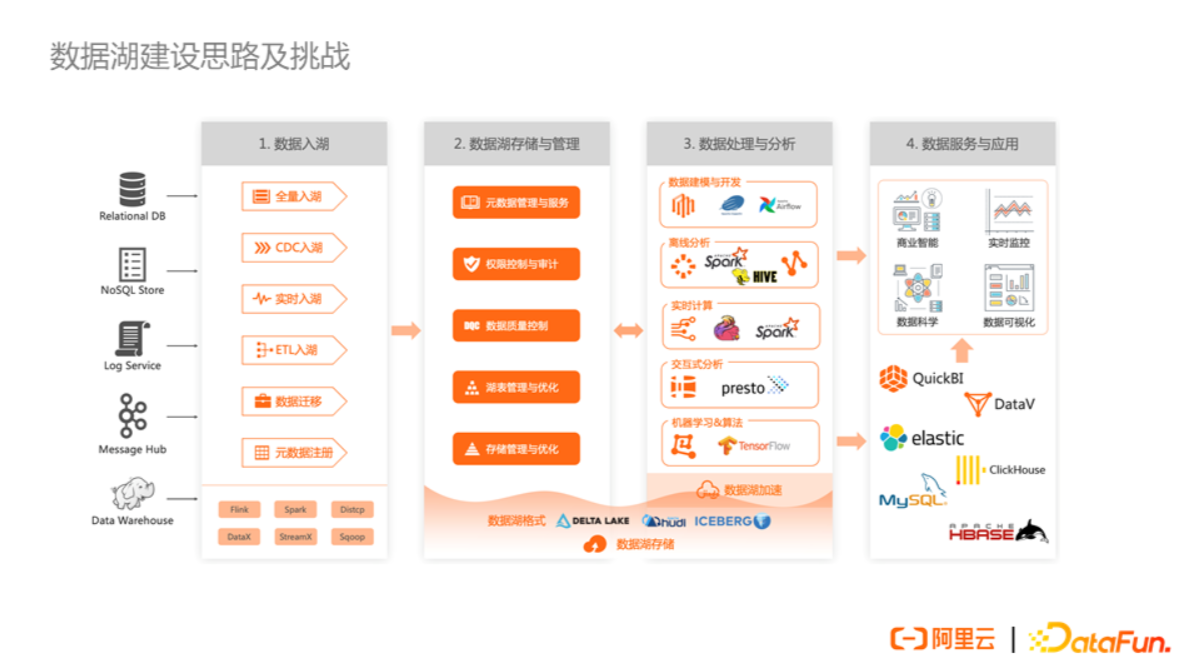
经过多年沉淀,阿里云在数据湖的建设上也积累了一定的经验和思路。我们认为数据湖的建设主要包括四个阶段。
第一阶段:数据入湖。
通过各种各样的入湖方式将数据导入数据湖。入湖方式可以根据自己的业务需求和场景进行选择,比如全量入湖、CDC更新入湖、实时追加写入以及整个 Hadoop 集群搬迁上云等。
第二阶段:数据湖存储与管理。
帮助用户更好地管理发现和高效使用数据湖里的数据。此阶段主要包括以下几个方面:
① 数据目录与检索:一方面能够提供元数据的服务,另一方面能够提供数据的快速检索能力。
② 权限控制与审计:因为数据湖本身是相对开放和松散的体系,需要有比较强的权限管控的能力来保证企业数据的安全性。
③ 数据质量控制:避免数据湖发展成数据沼泽的关键手段。
④ 湖表管理与优化:管理优化数据湖格式。
⑤ 存储管理与优化:对象存储提供了数据冷热分层的特性,但这些特性落地时还需要辅以自动化的手段以进行存储管理优化。
第三阶段:数据处理与分析。
可以根据实际场景选择多种数据处理和分析方式,比如做离线分析、实时计算、交互式分析、AI训练等。
第四阶段:数据服务与应用。
数据湖较为开放,因此可以直接用 BI 系统、可视化系统连接数据湖上的引擎,进行实时分析或可视化的数据展示等。另一方面,数据湖里的数据也可以再进一步同步或 Sink 到更专业的数据系统中,比如到 ES 里进行进一步数据检索,比如到ClickHouse/Doris/StarRocks等做更丰富的多元分析。
阿里云云原生数据湖解决方案
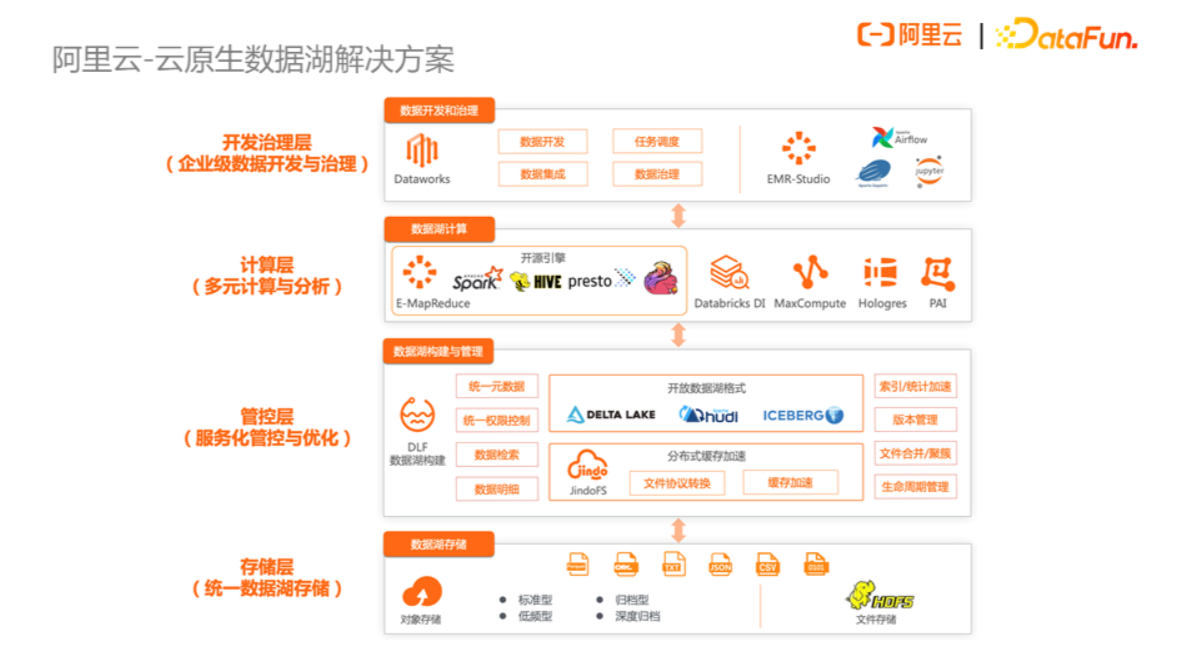
经历了多年的摸索后,阿里云推出了一个较为完整的云原生数据湖解决方案,整体架构如上图所示:
底层是存储层:统一存储各类数据,并对外提供文件访问的接口和协议。
第二层是管控层:可以理解为服务化的管控与优化,一方面提供统一的元数据、统一权限管控,另一方面提供智能化数据湖管理、快速数据检索等能力。
第三层是多元的计算与分析层:可以通过很多开源或阿里云自研的分析引擎对湖内数据进行加工和处理。
最上层是数据开发治理层:提供了面向湖和仓完善的数据开发体系以及数据治理平台。
由此可见,数据湖的建设不仅仅是大数据相关技术的集成和应用,同时也是一个复杂的系统工程,需要有成熟的方法论以及平台型的基础设施做支撑,才能建设出安全可靠、功能完善、成本可控的企业级数据湖。
了解更多:
[1] 数据湖构建Data Lake Formation:https://www.aliyun.com/product/bigdata/dlf
[2] 开源大数据平台EMR: https://www.aliyun.com/product/emapreduce
[3] 数据湖揭秘—Delta Lake: https://developer.aliyun.com/article/909818
[4] 数据湖构建—如何构建湖上统一的数据权限: https://developer.aliyun.com/article/918403
[5] 关于 Data Lake 的概念、架构与应用场景介绍:https://developer.aliyun.com/article/944650
欢迎钉钉扫码加入数据湖交流群
获取数据湖最新资讯和最佳行业实践~

|








- 上一条: 从原理剖析带你理解Stream 2022-09-01
- 下一条: YOLOX-PAI: 加速 YOLOX, 比 YOLOV6 更快更强 2022-09-01
- JuiceFS 在数据湖存储架构上的探索 2022-05-05
- 实时数据湖在字节跳动的实践 2022-06-06
- 如何打造一款极速数据湖分析引擎 2022-03-09
- 怎么提高自己的系统架构水平 2021-07-21
- 基于开源大数据调度系统Taier的Web前端架构选型及技术实践 2022-06-20


