Greenplum 是如何实现更新分片键的?

在 Greenplum 数据库中,允许用户更新元组的分片键,使得数据从当前节点转移到另一个节点,而这项能力是绝大多数分布式数据库所不支持的,例如 MongoDB 一旦设置了分片键,便无法进行修改和删除。实际上,Greenplum 非常巧妙的利用了 Motion Node 可以在节点之间进行数据传输的特性,以及 PostgreSQL 的火山模型,实现了更新分片键的特性。
1.
Split Update
在 PostgreSQL 中并没有任何的一个执行器节点能够完成分布式数据的更新,因此,Greenplum 引入了一个新的执行器节点 SplitUpdate。SplitUpdate 的原理其实非常简单,其过程和 PostgreSQL 中更新数据类似,只不过两者的出发点不同而已。
PostgreSQL 并没有使用 undo log 来实现 MVCC,而是在存储层将一份数据存储多份,并由 Vacuum 机制定期清除不再需要的 Dead Tuple。因此,当我们执行 update 语句时,并不会原地更新数据,而是先插入一条更新后的数据,再删除旧数据。
而 Greenplum 所实现的 Split Update 并不会执行 ExecUpdate() 函数,而是主动地将更新操作分裂成 INSERT 和 DELETE:
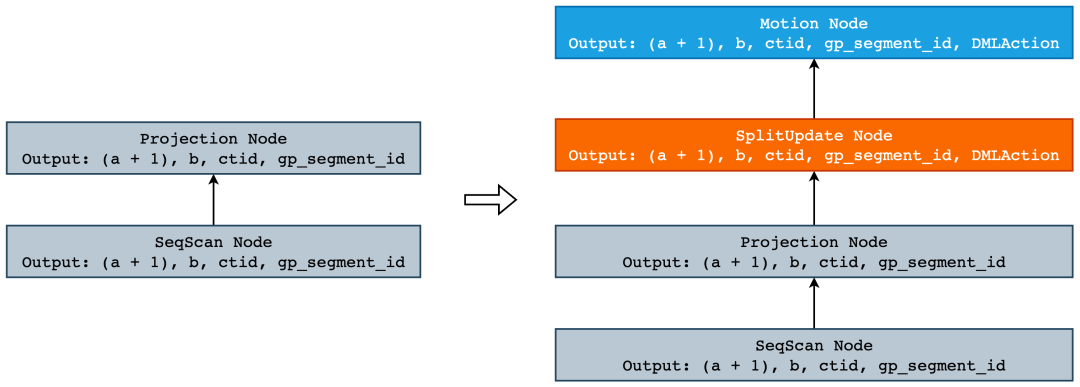
postgres=# create table t (a int, b int);postgres=# insert into t values (1), (2), (3);postgres=# select gp_segment_id, * from t; -- ①gp_segment_id | a | b---------------+---+---1 | 1 |0 | 2 |0 | 3 |(3 rows)postgres=# explain (verbose, costs off) update t set a = a + 1;QUERY PLAN--------------------------------------------------------------------Update on public.t -- ⑤-> Explicit Redistribute Motion 3:3 (slice1; segments: 3) -- ④Output: ((a + 1)), b, ctid, gp_segment_id, (DMLAction)-> SplitOutput: ((a + 1)), b, ctid, gp_segment_id, DMLAction -- ③-> Seq Scan on public.tOutput: (a + 1), b, ctid, gp_segment_id -- ②Optimizer: Postgres query optimizer(8 rows)postgres=# update t set a = a + 1;UPDATE 3postgres=# select gp_segment_id, * from t; -- ⑥gp_segment_id | a | b---------------+---+---0 | 3 |0 | 4 |0 | 2 |(3 rows)
如上例所示,从 ① 中我们可以看到数据目前是分布在 segment-0 和 segment-1 上的,当我们更新分布键 a 以后,数据全部分布在了 segment-0 上,如 ⑥ 所示。在 ② 中我们可以看到,除了返回表 t 所有的定义列以及 ctid 以外,还额外返回了当前 tuple 的所处的 segment 的 segment_id,这是因为 Greenplum 是分布式数据库,必须由 (gp_segment_id, ctid) 两者才能唯一确定一个 tuple。而在 Split 节点中,输出列又多了一个 DMLAction,这一列将会保存 Split 节点向上输出的两个 tuple 中,哪一个执行插入,哪一个执行删除。Motion 节点则将数据发送至正确的 segment 上进行执行,并根据 DMLAction 的值决定执行插入还是删除。

2.
Split Update的具体实现
在 PostgreSQL 中,一个执行节点对应着一个 Plan Node,而一个 Plan Node 则是由最优的 Path 所构成的。因此,我们需要实现 Split Path 和 Split Plan,Motion Path 和 Motoin 已经被实现了,我们可以直接拿过来复用。
Split Path 其实非常简单,我们只需要在其返回的列中添加一个名叫 DMLAction 的标志位即可,它既 表示在执行 Modify Table 时执行的是 Split Update,同时也可以保存对于当前 tuple 是执行插入还是删除。接下来我们就来看下在 PostgreSQL 中新增一个 Path 有多么的简单。
首先,我们要决定 Split Update Path 中到底需要什么,或者说有哪些信息是需要该节点保存的。首先,Split Update Path 只会有一个 SubPath,不存在左右子树的情况,如 WindowAggPath。其次,我们最好是在 Split Update Path 中保存我们到底更新的是哪一张表,这样一来方便 Motion Path 打开这张表并获取 Distributed Policy,从而决定到底需不需要添加 Motion 节点。如果被更新表是随机分布或者是复制表的话,那么就不需要 Motion 节点了。因此,我们就得到了如下 Path 结构:
typedef struct SplitUpdatePath {Path path;Path *subpath; /* 子 Path,通常都是 ProjectionPath */Index resultRelation; /* 被更新表在 RTE 链表中的下标(从 1 开始) */} SplitUpdatePath;
紧接着,我们需要一个函数,来创建我们的 SplitUpdatePath 结构,这个函数的作用也非常简单,只需要把 SplitUpdatePath 添加到下层路径之上,并将标志位添加至 PathTarget 中即可:
typedef struct DMLActionExpr {Expr xpr;} DMLActionExpr;static SplitUpdatePath *make_splitupdate_path(PlannerInfo *root, Path *subpath, Index rti) {RangeTblEntry *rte;PathTarget *splitUpdatePathTarget;SplitUpdatePath *splitupdatepath;DMLActionExpr *actionExpr;/* Suppose we already hold locks before caller */rte = planner_rt_fetch(rti, root);/* 创建 DMLAction 列 */actionExpr = makeNode(DMLActionExpr);splitUpdatePathTarget = copy_pathtarget(subpath->pathtarget);/* 将 DMLAction 插入到 target list 的尾部,在执行阶段取出 */add_column_to_pathtarget(splitUpdatePathTarget, (Expr *) actionExpr, 0);/* populate information generated above into splitupdate node */splitupdatepath = makeNode(SplitUpdatePath);/* Split Path 的节点类型为 T_SplitUpdate */splitupdatepath->path.pathtype = T_SplitUpdate;/* 它们具有相同的 RelOptInfo */splitupdatepath->path.parent = subpath->parent;/* 替换 pathtarget,即返回列必须多出 DMLAction 列 */splitupdatepath->path.pathtarget = splitUpdatePathTarget;/* 预估的 tuple 数量,由于 split update = delete + insert,所以会有 2 条数据 */splitupdatepath->path.rows = 2 * subpath->rows;/* 其余参数照抄即可 */splitupdatepath->path.param_info = NULL;splitupdatepath->path.parallel_aware = false;splitupdatepath->path.parallel_safe = subpath->parallel_safe;splitupdatepath->path.parallel_workers = subpath->parallel_workers;splitupdatepath->path.startup_cost = subpath->startup_cost;splitupdatepath->path.total_cost = subpath->total_cost;splitupdatepath->path.pathkeys = subpath->pathkeys;splitupdatepath->path.locus = subpath->locus;/* 包裹 ProjectionPath,使其成为子节点 */splitupdatepath->subpath = subpath;splitupdatepath->resultRelation = rti;/* 这里也只是在原有的 path 下面加了一个一个属性而已 */return splitupdatepath;}
当有了 SplitUpdatePath 以后,剩下的就是将 Path 转换成 Plan,由于我们并没有其它可供竞争的 Path,因此直接构建即可:
/* SplitUpdate Plan Node */typedef struct SplitUpdate {Plan plan;AttrNumber actionColIdx; /* DMLAction 在 targetlist 中的位置,便于快速访问 */AttrNumber tupleoidColIdx; /* ctid 在 targetlist 中的位置,便于快速访问 */List *insertColIdx; /* 执行 Insert 时需要使用到的 target list */List *deleteColIdx; /* 执行 Delete 时需要使用到的 target list *//* 下面的字段就是 Distributed Policy,在更新以哈希分布的表时会使用,主要用来计算* Insert 的 tuple 到哪个 segment,Delete 的话直接用本 segment 的 gp_segment_id* 即可。*/int numHashAttrs;AttrNumber *hashAttnos;Oid *hashFuncs; /* corresponding hash functions */int numHashSegments; /* # of segs to use in hash computation */} SplitUpdate;
接下来就是在 create_splitupdate_plan() 函数中填充 SplitUpdate 计划节点中的字段,主要就是一些索引 List 和 Distributed Policy,这些内容流程比较简单,但是又没有现成的通用函数来完成,因此会有些繁琐:
static Plan * create_splitupdate_plan(PlannerInfo *root, SplitUpdatePath *path) {Path *subpath = path->subpath;Plan *subplan;SplitUpdate *splitupdate;Relation resultRel;TupleDesc resultDesc;GpPolicy *cdbpolicy;int attrIdx;ListCell *lc;int lastresno;Oid *hashFuncs;int i;/* 获取更新表的 Distributed Policy */resultRel = relation_open(planner_rt_fetch(path->resultRelation, root)->relid, NoLock);resultDesc = RelationGetDescr(resultRel);cdbpolicy = resultRel->rd_cdbpolicy;/* 递归构建 subpath 的 Plan */subplan = create_plan_recurse(root, subpath, CP_EXACT_TLIST);/* Transfer resname/resjunk labeling, too, to keep executor happy */apply_tlist_labeling(subplan->targetlist, root->processed_tlist);splitupdate = makeNode(SplitUpdate);splitupdate->plan.targetlist = NIL; /* filled in below */splitupdate->plan.qual = NIL;splitupdate->plan.lefttree = subplan;splitupdate->plan.righttree = NULL;copy_generic_path_info(&splitupdate->plan, (Path *) path);lc = list_head(subplan->targetlist);/* 遍历目标更新表的所有属性 */for (attrIdx = 1; attrIdx <= resultDesc->natts; ++attrIdx) {TargetEntry *tle;Form_pg_attribute attr;tle = (TargetEntry *) lfirst(lc);lc = lnext(lc);attr = &resultDesc->attrs[attrIdx - 1];/* 构建 Insert 和 Delete 列表,其中 deleteColIdx 仅仅只是为了满足格式要求,无实际作用 */splitupdate->insertColIdx = lappend_int(splitupdate->insertColIdx, attrIdx);splitupdate->deleteColIdx = lappend_int(splitupdate->deleteColIdx, -1);splitupdate->plan.targetlist = lappend(splitupdate->plan.targetlist, tle);}lastresno = list_length(splitupdate->plan.targetlist);/* ....... */splitupdate->plan.targetlist = lappend(splitupdate->plan.targetlist,makeTargetEntry((Expr *) makeNode(DMLActionExpr),++lastresno, "DMLAction", true));/* 构建 Distributed Policy 相关,例如哈希函数、分片键等等 */hashFuncs = palloc(cdbpolicy->nattrs * sizeof(Oid));for (i = 0; i < cdbpolicy->nattrs; i++) {AttrNumber attnum = cdbpolicy->attrs[i];Oid typeoid = resultDesc->attrs[attnum - 1].atttypid;Oid opfamily;opfamily = get_opclass_family(cdbpolicy->opclasses[i]);hashFuncs[i] = cdb_hashproc_in_opfamily(opfamily, typeoid);}splitupdate->numHashAttrs = cdbpolicy->nattrs;splitupdate->hashAttnos = palloc(cdbpolicy->nattrs * sizeof(AttrNumber));memcpy(splitupdate->hashAttnos, cdbpolicy->attrs, cdbpolicy->nattrs * sizeof(AttrNumber));splitupdate->hashFuncs = hashFuncs;splitupdate->numHashSegments = cdbpolicy->numsegments;relation_close(resultRel, NoLock);root->numMotions++;return (Plan *) splitupdate;}
static TupleTableSlot * ExecSplitUpdate(PlanState *pstate) {SplitUpdateState *node = castNode(SplitUpdateState, pstate);PlanState *outerNode = outerPlanState(node);SplitUpdate *plannode = (SplitUpdate *) node->ps.plan;TupleTableSlot *slot = NULL;TupleTableSlot *result = NULL;/** processInsert 的初始值为 true,也就是说同一个 tuple 在第一次执行 ExecSplitUpdate 时,会进入到下面的分支,从外层* 路径中获取 tuple,然后调用 SplitTupleTableSlot 对 deleteTuple 和 insertTuple 进行赋值,上层节点将执行 delete。* 第二次进入该函数时将会直接返回 node->insertTuple,那么也就实现了"从下面拿上来一个 tuple,使用多次"的需求。* */if (!node->processInsert) {result = node->insertTuple;node->processInsert = true;}else {/* Creates both TupleTableSlots. Returns DELETE TupleTableSlots.*/slot = ExecProcNode(outerNode);if (TupIsNull(slot))return NULL;/* `Split' update into delete and insert */slot_getallattrs(slot);Datum *values = slot->tts_values;bool *nulls = slot->tts_isnull;ExecStoreAllNullTuple(node->deleteTuple);ExecStoreAllNullTuple(node->insertTuple);/* 在 SplitTupleTableSlot 中即将 slot 一分二位,保存在 deleteTuple 和 insertTuple 中 */SplitTupleTableSlot(slot, plannode->plan.targetlist, plannode, node, values, nulls);result = node->deleteTuple;node->processInsert = false;}return result;}
static TupleTableSlot *ExecModifyTable(PlanState *pstate) {switch (operation) {case CMD_INSERT:/* ...... */case CMD_UPDATE:if (!AttributeNumberIsValid(action_attno)) {/* normal non-split UPDATE */slot = ExecUpdate(node, tupleid, oldtuple, slot, planSlot,segid,&node->mt_epqstate, estate, node->canSetTag);}else if (DML_INSERT == action) {slot = ExecSplitUpdate_Insert(node, slot, planSlot, estate, node->canSetTag);}else /* DML_DELETE */ {slot = ExecDelete(node, tupleid, segid, oldtuple, planSlot,&node->mt_epqstate, estate,false,false /* canSetTag */,true /* changingPart */ ,true /* splitUpdate */ ,NULL, NULL);}break;}}
其中 action 就是我们在 targetlist 末尾添加的 DMLAction 表达式的值,在这里判断其值并选择执行 ExecSplitUpdate_Insert 还是 ExecDelete。
至此,Greenplum Split Update 的整个过程就分析完毕,期间其实省略了非常多的细节,这部分内容就留给读者细心探索了,比如连接优化器和执行器的函数和结构体是什么,Motion 节点是如何分发 Insert 和 Delete Tuple 的,等等。
作者简介
李正龙
VMware Greenplum内核研发工程师
Greenplum Committer,Pythonista/Gopher,有多年系统设计相关经验,现专注于数据与分布式系统相关研究。
个人主页: https://github.com/SmartKeyerror
点击文末“ 阅读原文 ”,获取Greenplum中文资源。

 来一波 “在看”、“分享”和 “赞” 吧!
来一波 “在看”、“分享”和 “赞” 吧!
本文分享自微信公众号 - Greenplum中文社区(GreenplumCommunity)。
如有侵权,请联系 support@oschina.cn 删除。
本文参与“OSC源创计划”,欢迎正在阅读的你也加入,一起分享。
|








- 上一条: 袋鼠云思枢:数栈DTinsight,创新升级,全新出发,驶入数智转型新赛道 2022-08-24
- 下一条: 深入解析Flutter下一代渲染引擎Impeller 2022-08-24
- 分布式数据库--ZBConverter数据转换工具 2022-03-23
- ReplacingMergeTree:实现Clickhouse数据更新 2021-11-05
- MySQL 是如何实现 ACID 的? 2021-09-18
- StratoVirt 的中断处理是如何实现的? 2022-01-26
- 说说Redis分布式锁是如何实现的! 2021-07-24


