MDAP:可观测性数据分析平台设计与实践
本文首发于微信公众号“Shopee技术团队”。
摘要
MDAP(Multiple Dimension Analysis Platform)是一个多维实时监控分析平台,能够支持业务应用侧自定义指标的监控与分析,并在自定义监控分析能力上,实现了对移动端应用性能数据的专项监控分析能力,以满足业务日益增长的数据监控分析需求。
本文作为系列文章的第一篇,将介绍 MDAP 平台如何实现移动端可观测数据监控分析,并提升监控性能与分析精准度。
1. 背景
随着 Shopee 业务不断发展,为了更加了解终端用户使用的体验,更好地决策产品优化特性,各业务团队内部涌现出大量对线上终端数据可观测的需求。例如:终端的页面转化率、用户留存率、终端的性能监控(包括 CPU 使用率、内存使用率、网络流量等),以及终端稳定性监控(崩溃、ANR)等。
而业务各项转化率、留存率等指标除了会受到产品功能、商业推广、应用模式等影响外,更多会受到应用自身的性能以及稳定性影响。亚马逊的统计显示,网页每 100 毫秒的延迟就会使他们损失 1% 的销售额;同时谷歌也指出,搜索页面生成时间多出 0.5 秒,流量就会减少 20%。所以,对线上应用的性能及稳定性监控就显得极为重要。
MDAP(Multiple Dimension Analysis Platform)作为一个多维实时监控分析平台,能够支持业务应用侧自定义指标的监控与分析,并在自定义监控分析能力上,实现了对移动端应用性能数据的专项监控分析能力,以满足业务日益增长的数据监控分析需求。本文将介绍 MDAP 平台如何实现移动端可观测数据监控分析,并提升监控性能与分析精准度。
对于应用性能管理,全球权威的 IT 研究与顾问咨询机构 Gartner 将其定义为,包含数字体验监控(DEM);应用程序发现、跟踪及诊断(ADTD); 以及面向技术人员的人工智能运维(AIOps)。
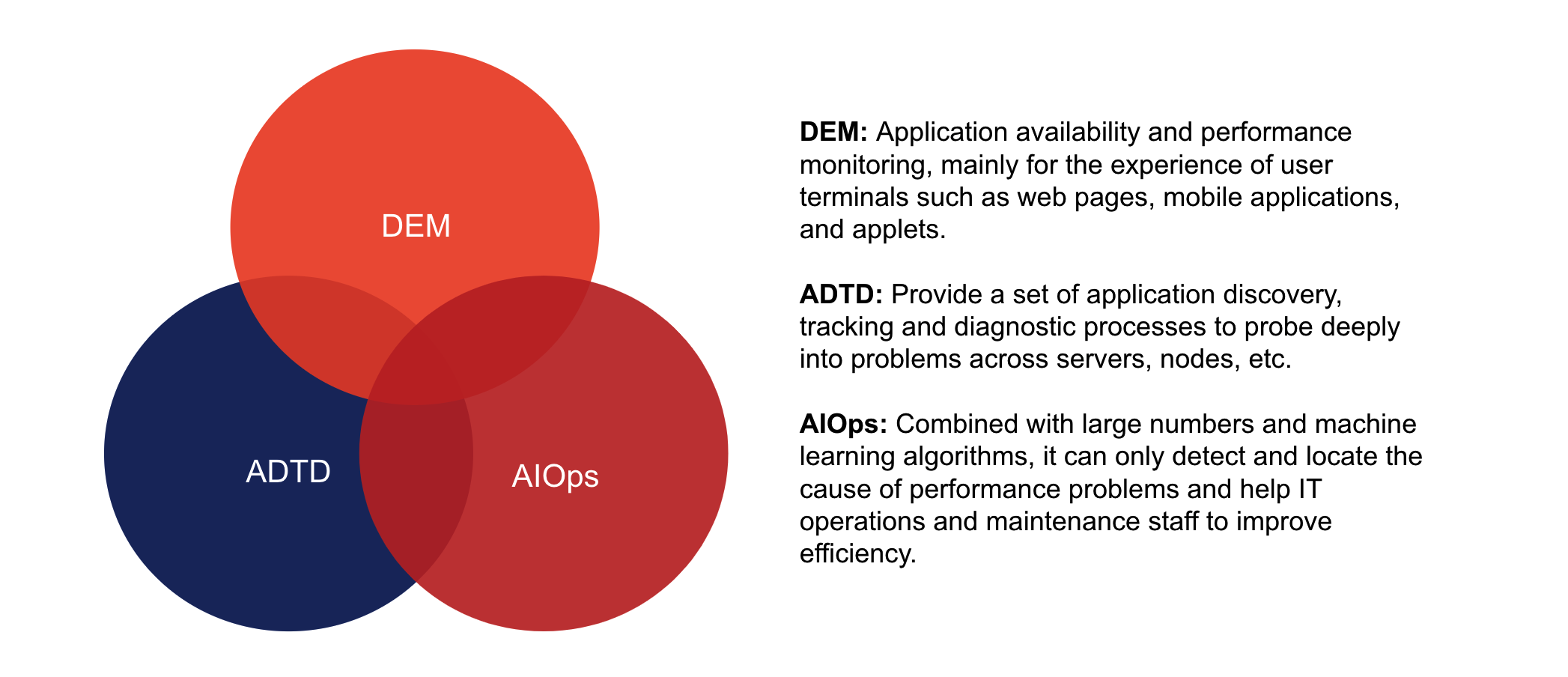
目前,业界对后台的数据监控在以上三个维度都拥有相对成熟的解决方案,例如 DEM 指标采集使用 Promethues,ADTD 使用 ELK 以及 opentracing 的方案等。
然而,终端侧并未有体系化的解决方案,能够指引行业人员构建三个维度象限下的可观测数据分析系统。如果要构建一套终端数据监控分析系统,应该如何实现?从以上三个维度出发,需要分别思考以下问题:
- 针对 DEM:采集的指标有哪些,以及这些指标的影响是什么?
- 针对 ADTD:异常指标如何转化为具体可处理的方案,如何快速找到问题模块?
- 针对 AIOps:如何实现问题分析的精准性,如何降低研发分析耗时与成本?
2. MDAP 架构介绍
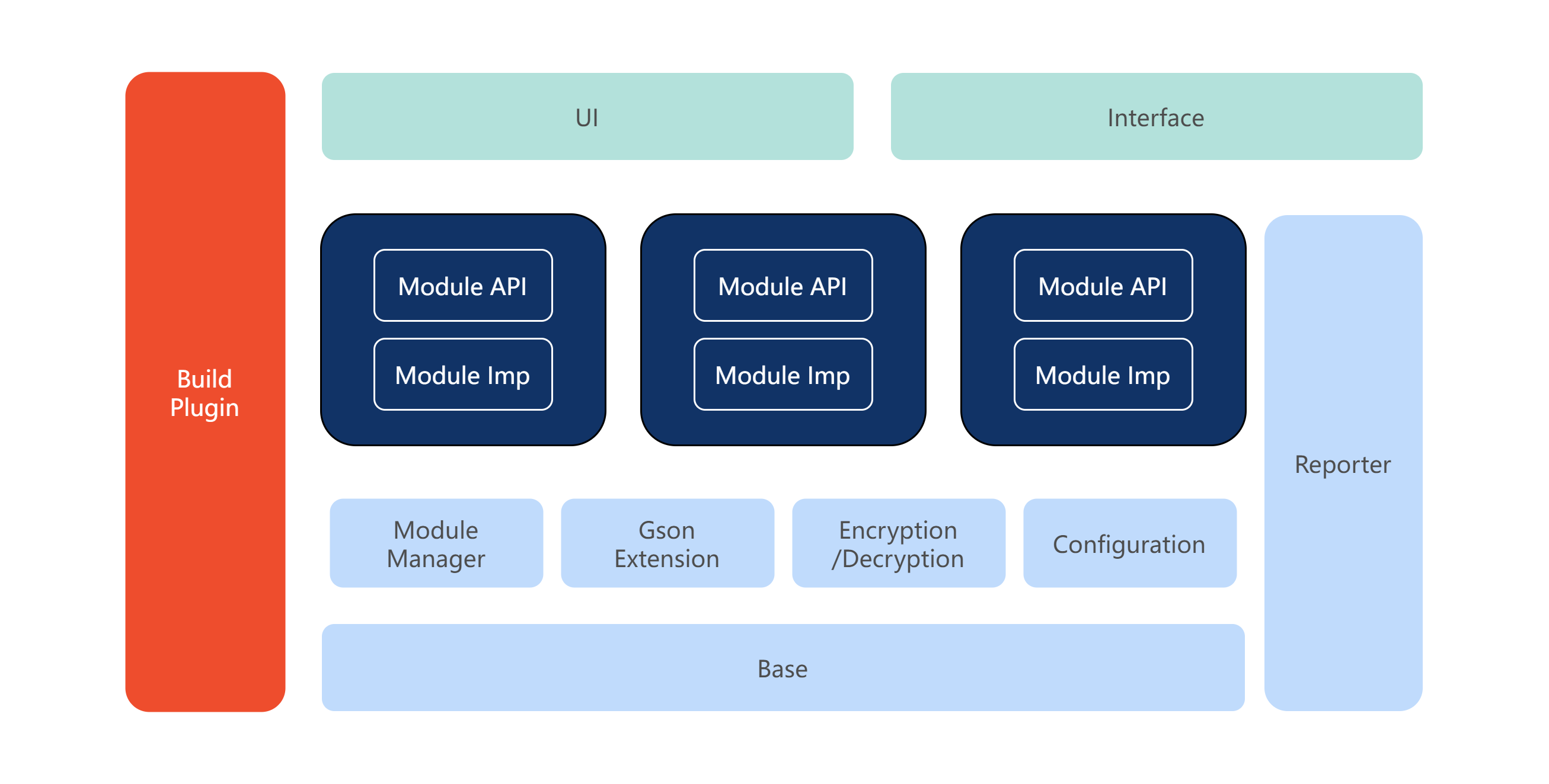
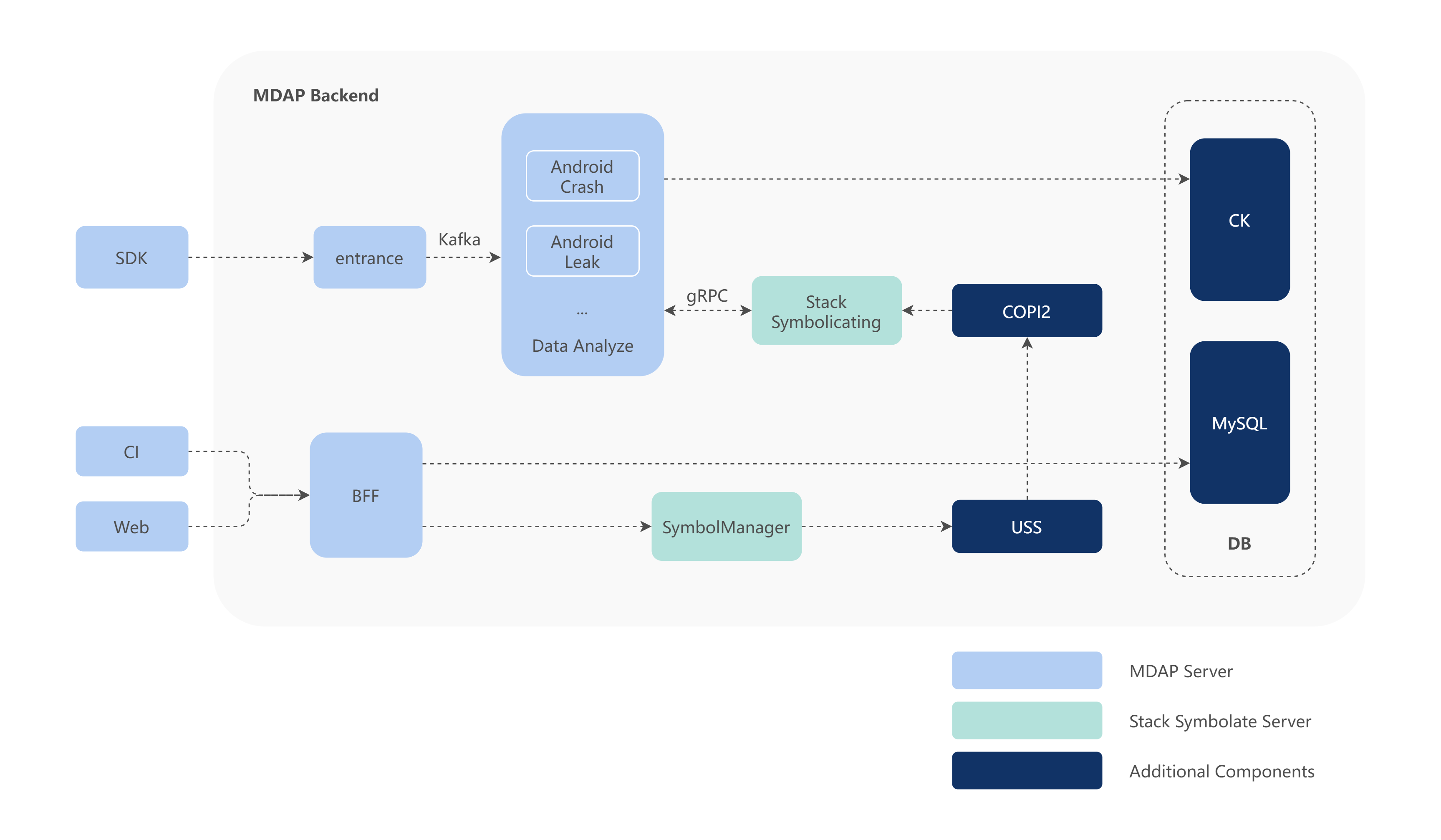
为了解决以上问题,MDAP 整体设计上包含了可观测数据的采集和后台分析处理服务。整体服务架构如下图所示,后台架构服务设计上遵照 DDD 设计思想做了微服务化设计,并能利用 Helm 实现在 K8s 集群中一键部署,从而满足一些业务快速私有化部署的需求。
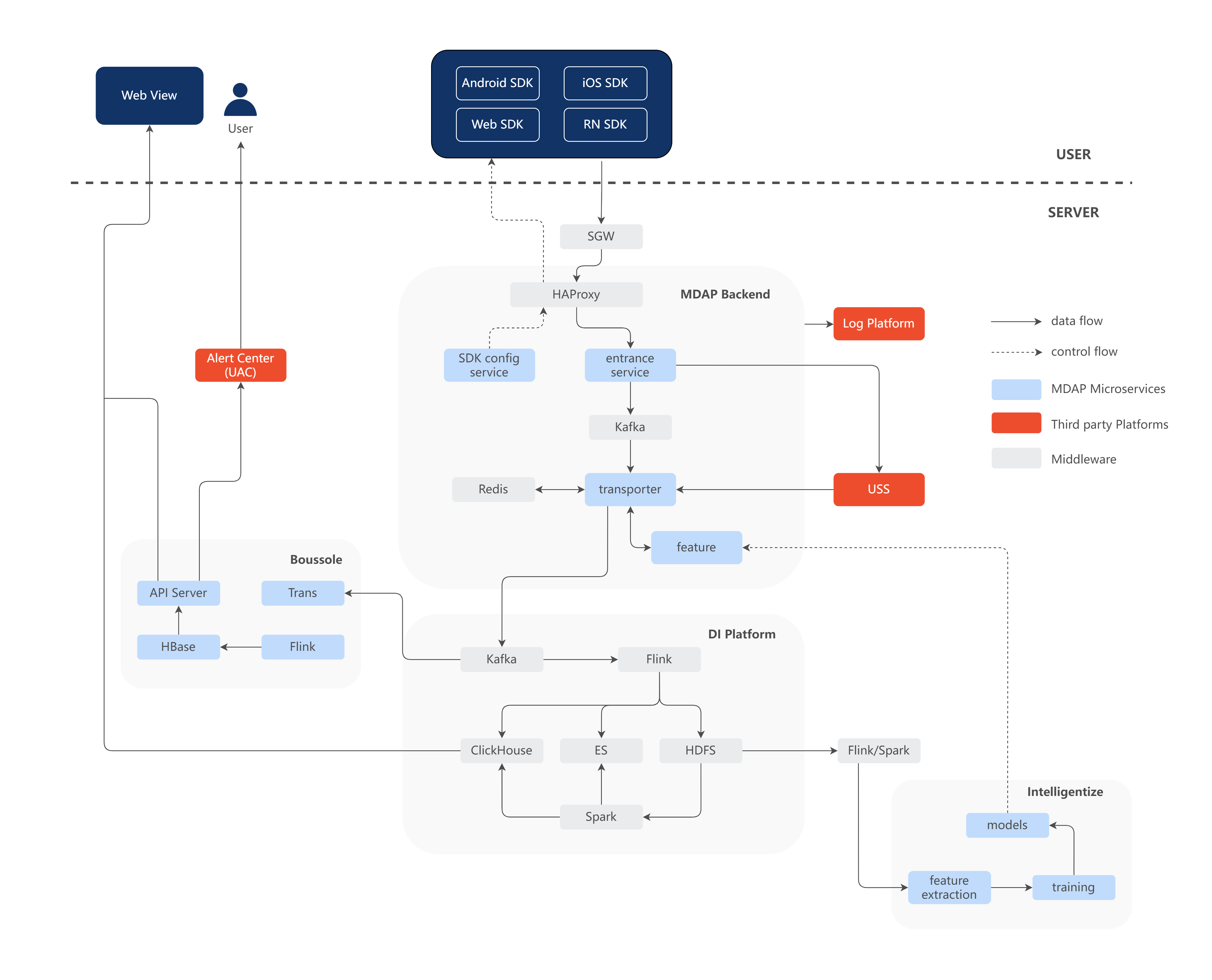
1)MDAP Backend
作为微服务集群,对上报的各个监控的数据计算转换,对脏数据过滤,或者对上报的文件做解析与分析,挖掘上报文件中的问题点。例如从内存快照中找到内存泄漏、对象重复、对象过大等内存使用异常的问题。使用 Inteillgentize 生成的数据模型,对分析出的问题类别做智能打标分类。
2)DI Platform
构建在 Shopee 的 Data Infra 上,通过 Flink 流式拉取数据清洗或做简单的预计算后落入存储中,并通过 Spark 对存储的详细数据按照小时、天或者周的维度做上卷聚合,输出维度指标数据,提供页面指标实时查询使用。
3)Intelligentize
作为智能运算服务,利用 Spark ML 等大数据分析套件,对 DI Platform 中经过预处理的数据做半监督或无监督学习,生成数据模型,提供给微服务集群作为标签分类的依据。
4)Boussole
作为实时分析引擎,从数据源拉取数据并经过前置清洗,通过用户在平台中定义的指标和维度以及汇聚方式实时聚合后,将产生的结果数据落入持久化存储,用户通过平台前端配置的相关视图及 Dashboard 实时观测这些最新汇聚出的数据结果,这些结果做为告警的数据源,降低反复查询 ClickHouse 等数据库的频度,减少对页面访问的干扰影响。详情可以参考文章《Boussole Engine:针对多维时序数据实现的实时分析引擎》。
3. 指标采集与钻取
3.1 采集数据类型
在采集数据前先要划分数据的类型与用途,不同用途的数据采集方式、存储方式、产品形态各有不同的方案。参照分布式监控,监控的数据可以分为 Metrics、Logging、Tracing 三类,用维恩图(Venn diagram)可以表现为下图形式。
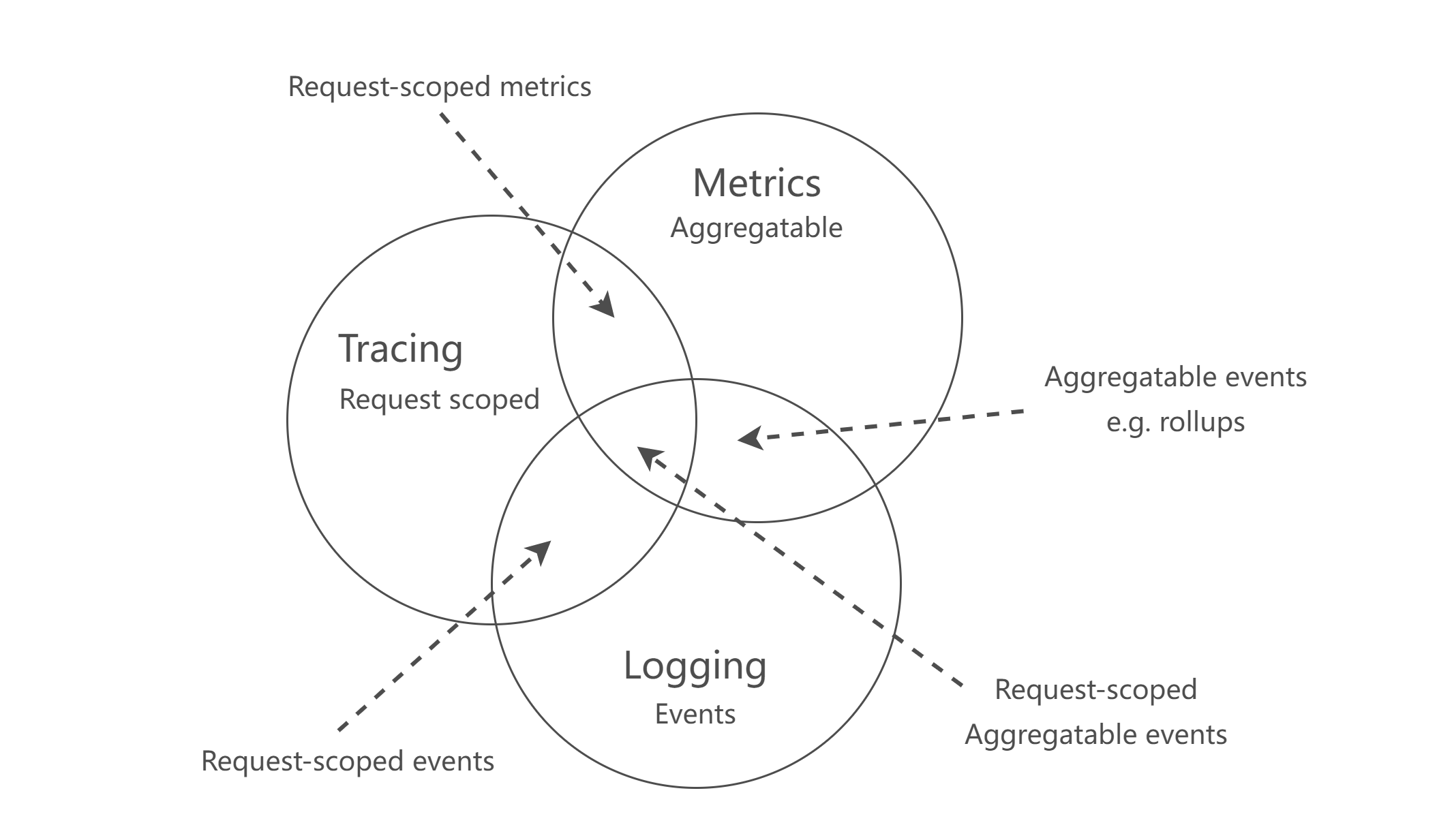
1)Metric
Metric 作为监控指标是原子的,每个都是一个逻辑计量单元,大多作为时序数据。在终端中,Metric 可以包含 CPU 使用率、内存使用率、网络流量等系统或者业务指标。
针对其时序数据的数据,MDAP 使用 ClickHouse 来做存储,方便数据做实时查询分析。提供趋势图、日环比、周环比、维度数据、统计报表。分布图等分析面板能够协助用户快速找到问题维度,进而做单维度的下钻分析,缩小问题的排查范围。另外,数据指标可以作为告警的来源,作为发版后或者日常指标监控的标准。
2)Logging
作为一些离散的(不连续的)事件,Logging 包含着事件内部的详细信息内容,作为主要问题排查途径和方法。在终端中,Logging 包含终端日志、内存快照、瞬时堆栈等信息,这些信息的属性一般为文本型。为了能够提供模糊查询、分词搜索能力,MDAP 使用 ElasticSearch 做为存储,达到快速协助指标异常或告警发生时的问题定位、提供解决思路的作用,即可用于后续 ADTD 处理。
3)Tracing
单个请求或者会话过程中的链路信息,包含请求或者会话的上下文、调用信息等,用于做模块之前的影响评估、问题追踪等用途。在终端中,Tracing 包含网络请求报文追踪、用户行为追踪、应用运行追踪等。这些信息的属性通常也是文本型的,需要对上下文做联合搜索,MDAP 参考后台 Jaeger 的设计思想,使用 ElasticSearch 来存储查询。
综上,三个维度可以再划分两类数据,数值型数据(Metric)和文本型数据(Logging/Tracing)。其中,数值型用于做趋势分析,文本型用于做单例问题详细分析,MDAP 在采集数据时也是针对这两个类别进行采集。

3.2 终端采集能力
有了以上采集数据的指导,就可以依据各个平台端的通用问题做数据采集 SDK。依据各端的特性以及对性能与稳定性排查指标的需要,可以将各个终端可采集的数据划分如下:

SDK 层面为了实现最小功能接入能力,在设计开发上实现采集功能的模块化,各个应用可以根据自身需要选择性引用功能模块,从而保证监控 SDK 对应用的包体积以及性能达到最小影响。
SDK 除了提供原子的监控采集能力外,还有许多基础能力要实现。例如为了能够符合金融行业的合规性要求,MDAP 在上报数据时候做了加密处理;为了能够对线上应用实时采集功能开关控制以及问题阈值调整,MDAP 实现了对 SDK 采集功能的配置下发控制;为了应用能够在灰度期间验证采集功能,MDAP 对 SDK 实现了动态采样以及黑白名单能力。
MDAP 在提供采集的 SDK 之外,为了应用 0 代码接入 SDK、SDK 性能提升以及应用 CICD 绑定关联,MDAP 提供了编译插件(例如 Android 的 Gradle 插件、Web 的 Webpack 插件等)利用编译器插桩或编译器生命周期来实现符号信息自动上传、应用启动生命周期插桩监控等能力。
3.3 数据下钻与定位
数据指标和问题详情之间也不是相互孤立的,他们之间存在着数据的联动。例如可以通过值指标数据的维度(版本、地域、机型等)下钻关联到一类问题详情,就可以来解决该维度下的指标问题;反过来,对于研发侧,依照问题详情修复后的效果也可以在数据指标中体现出来。
MDAP 在页面展示层和后台功能层对数据做了处理,以满足数据指标和问题详情之间实现联动,实现对指标问题的定位与分析。功能层将在下文详细介绍,此处不做赘述。
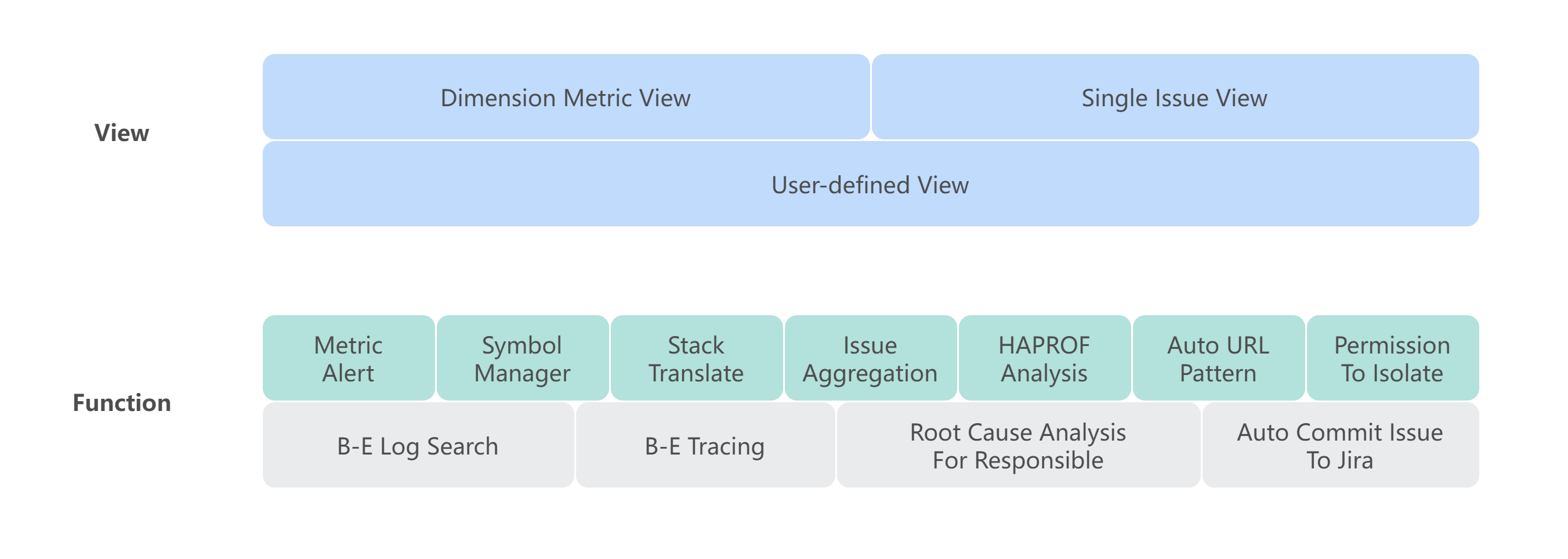
在视图层面,MDAP 提供三种视图来满足业务对数据展示的需求。
1)多维指标视图
用于展示采集到的数据指标,在通用分析维度下的一系列报表面板,可通过时序折线图表示趋势,通过饼图表示分布情况,通过分位图表示长尾问题,通过地图表示地域分布等。
2)单例视图
用于展示问题发生时刻的详细信息,通过堆栈详情、运行态代码 tracing 等来提供问题时刻的代码运行情况;通过展示问题发生时刻的应用日志片段,提供应用逻辑上下文信息等。
3)自定义视图
由于多维指标视图和单例视图是从最佳实践经验出发定制化了一套解决问题的面板,具有通用和普遍性,能够让普通应用开发者简单快速地分析处理问题。
对于产品和数据分析侧,可能会想在多维视图基础上构建一套结合业务特性的定制化的视图面板,用于日报周报面板或性能基准面板。例如:通用的网络请求耗时多维指标视图中,提供的是应用全量请求的平均耗时指标,而业务重点关注的是部分 API 请求的耗时统计,那么就可以通过该自定义面板来配置指标。
4. 问题分析的精准与高效
为了能够在单例视图对问题做有效定位,降低研发对数据分析的成本,需要对采集上报的数据做清洗预处理。考虑到移动端的性能问题,MDAP 只在 SDK 中嵌入了轻量的分析处理能力,主要利用后台的服务计算能力完成复杂的分析处理服务。下文将从几个案例来介绍 MDAP 在高效精准的数据分析处理上的实现。
4.1 精准的流畅度分析
目前业界对终端的流程率的监控指标有卡顿率和 FPS 两种维度,而以上两种方式都难以非常客观地表现用户在终端的使用体验。
1)卡顿率
如果通过卡顿阈值来获取卡顿率,会依赖卡顿阈值的设定,只能两段式地了解阈值以上和以下的用户分布情况,没法细化了解用户的详细分布以及优化效果。例如:阈值设置为 300ms,那么对于一个 200ms 的影响,卡顿就难以被感知到。此外,如果研发侧将一个 1s 的卡顿优化为 400ms 后,也无法从卡顿率指标中体现出来。
2)FPS
该指标没法真实反馈用户对卡顿的体验感受,如下图所示,两个相同的 FPS 指标的情况,在用户侧会有不同的感受,在 A 场景下用户可能还是能够体验相对流畅的交互,而在 B 场景下用户就会有一个明显卡顿的体验。

针对以上问题,MDAP 侧将捕获的页面绘制数据分为 9 个桶信息,分别表示一次屏幕绘制消耗的帧数,从 1 帧、2 帧到大于 32 帧的消耗。下图展示了上图中 A、B 两个场景分桶后的分布情况。
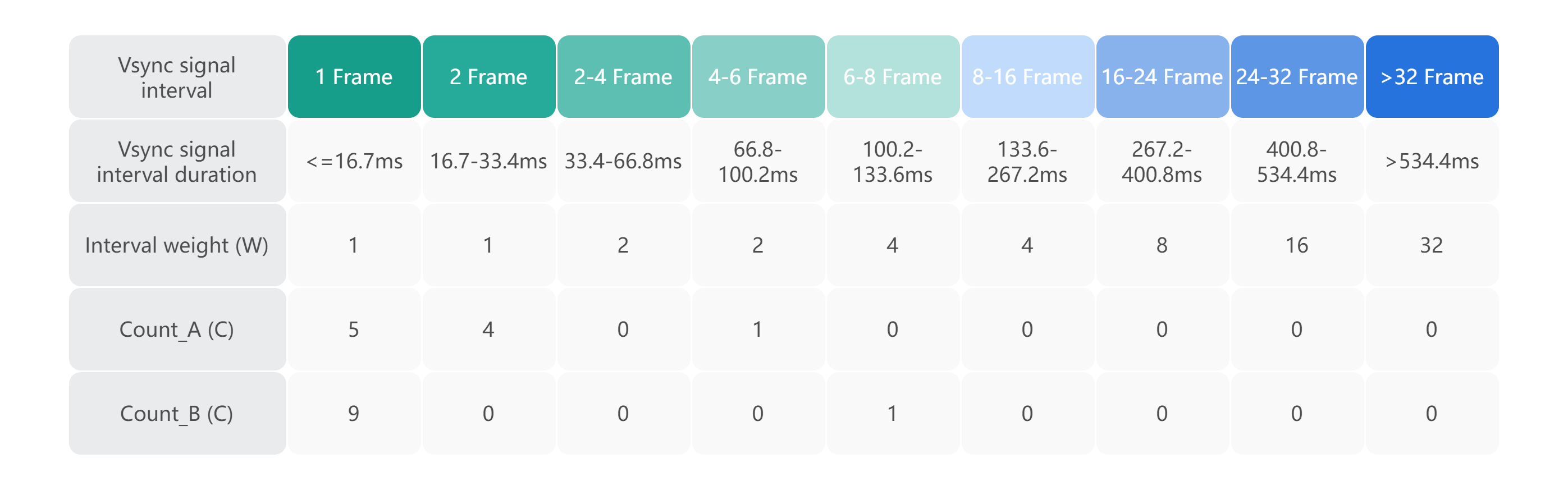
分好桶后,依照对用户体验的影响程度从低到高,对各个桶设置了权重,例如对于用户体验影响最小的 1 帧和 2 帧绘制给了的最小的权重 1。通过如下公式来计算相关的流畅率。
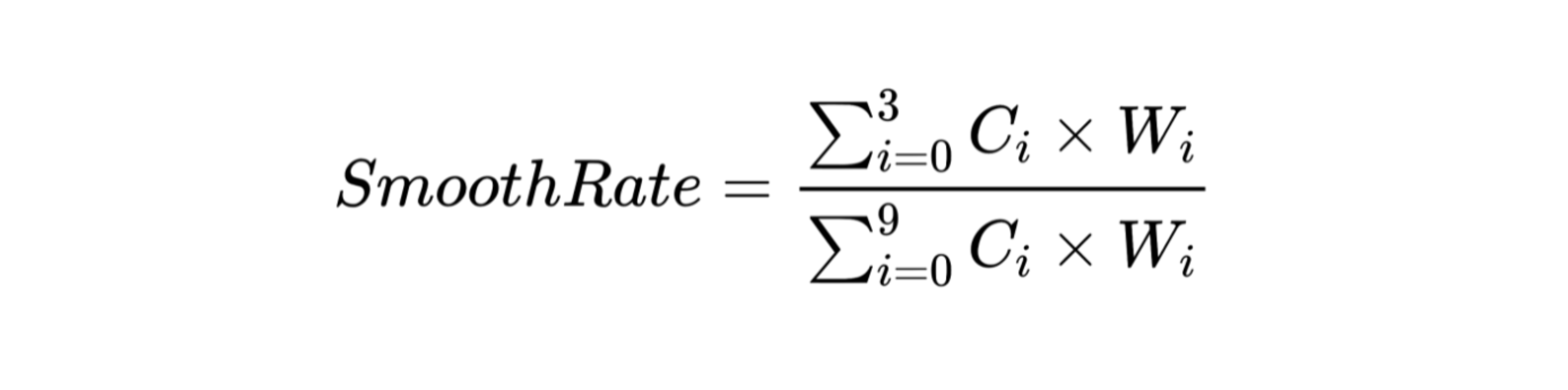
那么可以得到 A 和 B 在流畅率计算下的值:A 场景的流畅率为 81.8%,B 场景为 69.2%。由此得知,B 场景的用户流畅感受是比 A 场景差的,与直观体验相符合。这样,业务研发也就可以对该指标做相关的告警配置。
应用侧流畅率低于阈值时候,研发就可以收到告警信息。此时,进入流畅率面板查看应用在各个维度的流畅率信息,通过维度分析找到导致流畅率低的维度,就可以在该维度下钻查看异常问题列表。例如,这里可以对流畅率在 90.27% 的版本做下钻分析。
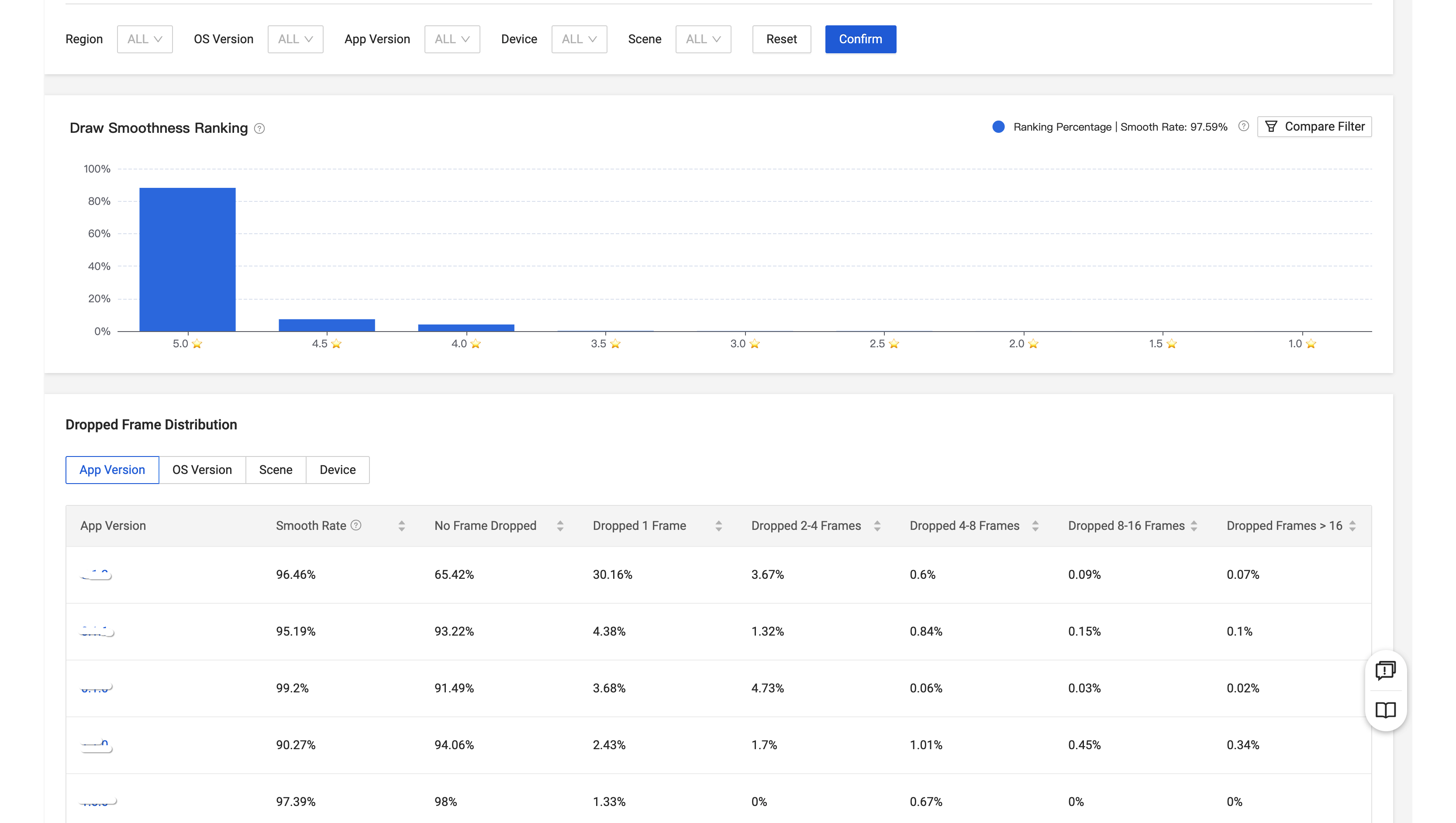
问题列表页面会根据已有的模型标签将问题聚合展示。通过 detail 按钮可以展开该模型的详细问题列表。可以依据影响的用户或者设备范围来决定类型影响范围,选取影响范围最大的类别做展开分析,这里选择影响 top 1 类别做展开分析。
4.2 高性能的内存快照解析
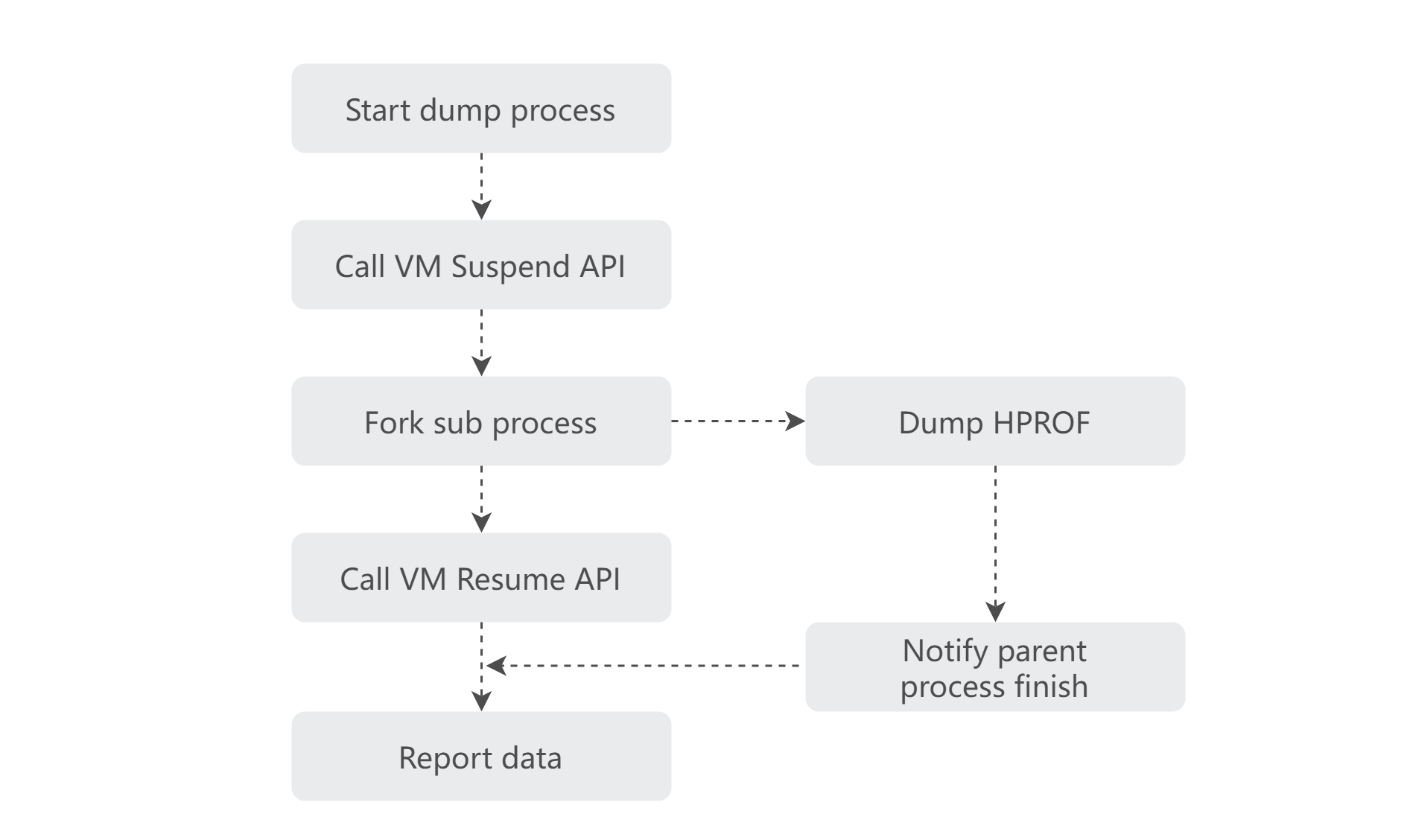
对于 Android 侧线上的内存问题,往往会想到通过内存快照来查看,但是 Android 在内存快照时是通过调用 Debug.dumpHprofData 来对运行内存做快照。此时在 Android 系统内部会挂起全部线程,即下图 ScopedSuspenAll 中的调用,就会导致内存快照 dump 期间卡死应用运行,如果需要 dump 的内存较大的话,那么还可能导致线上应用 OOM。下方代码为系统的 DumpHeap 代码片段。
// If "direct_to_ddms" is true, the other arguments are ignored, and data is
// sent directly to DDMS.
// If "fd" is >= 0, the output will be written to that file descriptor.
// Otherwise, "filename" is used to create an output file.
void DumpHeap(const char* filename, int fd, bool direct_to_ddms) {
CHECK(filename != nullptr);
Thread* self = Thread::Current();
// Need to take a heap dump while GC isn't running. See the comment in Heap::VisitObjects().
// Also we need the critical section to avoid visiting the same object twice. See b/34967844
gc::ScopedGCCriticalSection gcs(self,
gc::kGcCauseHprof,
gc::kCollectorTypeHprof);
ScopedSuspendAll ssa(__FUNCTION__, true /* long suspend */);
Hprof hprof(filename, fd, direct_to_ddms);
hprof.Dump();
}
为了能够捕获到线上的内存快照,MDAP 在 SDK 利用内存“写时复制”的机制,通过父子进程的模式,在子进程中做线程挂起和内存快照的操作,这样就不会卡死主进程的执行,且能将内存快照对应用的平均损耗从 10s 降低到 0.1s,从而实现线上对内存采集快照的要求。
同时,在快照期间还能通过 hook read 和 write 函数对 HPROF 文件做裁剪(例如系统堆空间、原始对象数组等),从而降低快照大小,节省上传报文流量。
在后台对 Android 内存快照文件能通过 HaHa 和 Shark 两个开源库做解析处理,但是这两个库在 MDAP 上使用会存在一些问题:
- 它们基于 Java 或 Kotlin 编写,而 MDAP 后台基于 Go 编写,会出现命令行调用模式,进程反复启动导致性能消耗;
- 两个库只实现了对内存泄漏的检测,而实际内存使用不当的模式有很多,例如过大的内存对象分配、重复对象分配而没有做缓存池、图片未压缩过大超过屏幕分辨率等内存使用不合理现象;
- 两个库存在性能的问题,例如 HAHA 库对文件的全量加载大致 gc 频繁、Shark 库对对象数过大的快照文件解析耗时过高等问题。
对于以上问题,我们通过 Go 实现了 Shark 的能力,在 MDAP 内部命名为 go-shark 模块,该模块利用 Go 的协程特性,充分利用并发能力,实现多分析功能的并行减低了分析时长;在 GC Root 分析的 BFS 期间对 JavaFrame、MonitorUser 类型做了剪枝操作;对泄漏期间也做了优化操作,例如对基本类型,基本数据结构做了搜索忽略的优化等。使得整体服务在 4C8G 的资源下单文件解析平均消耗在 3s 左右。
同时,go-shark 也扩展了内存解析的类型,除了内存泄漏的解析外还做了重复对象分析、重复字符串分析、图片过大分析、图片重复分析、对象过大分析等。
例如:对某个图片加载重复的问题,就可以通过服务解析后,通过页面看到图片尺寸、图片大小、图片解析模式甚至图片的内容,这样研发在定位问题时就能更直观了解问题所在。
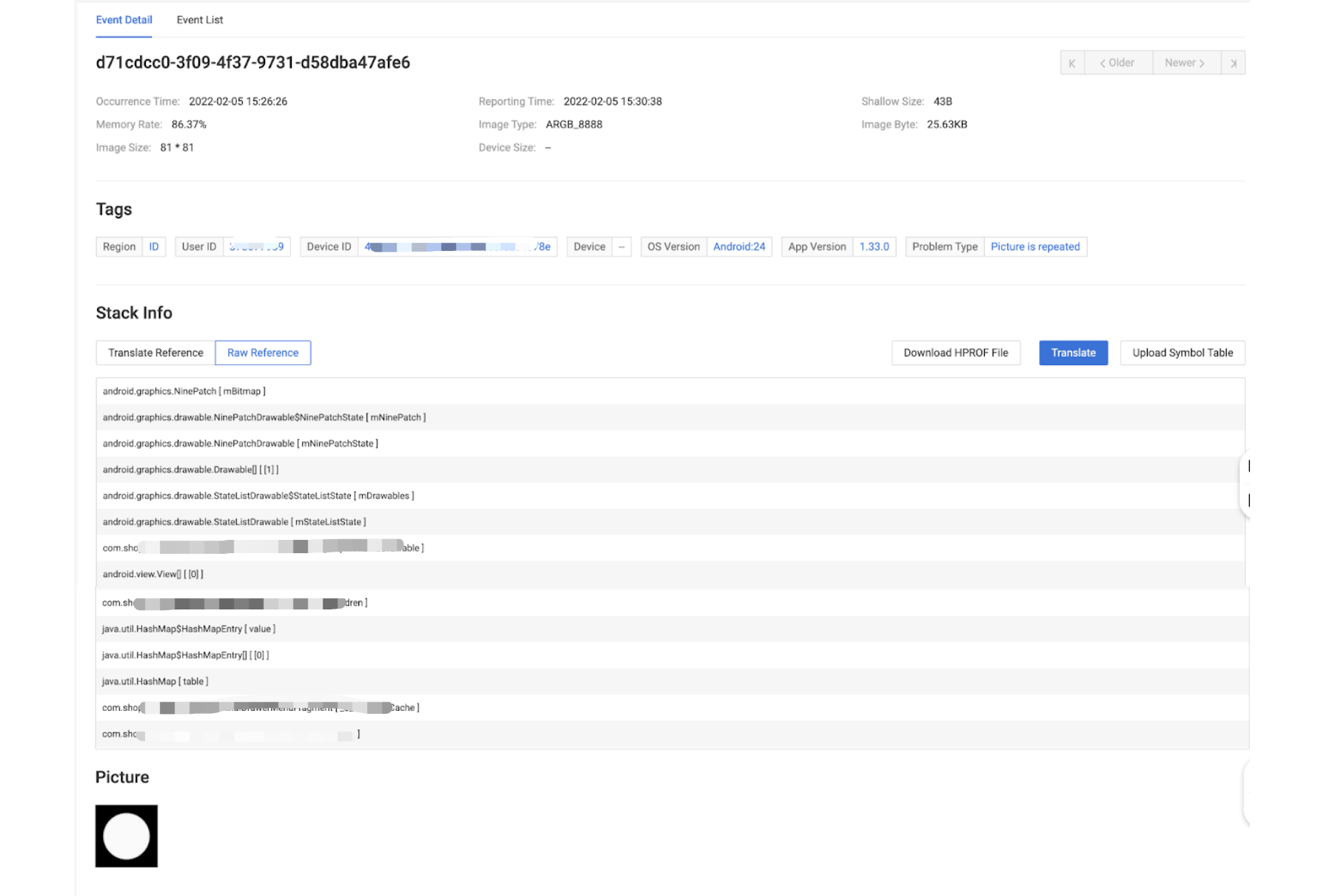
4.3 高效的堆栈还原分析
在对问题详情的采集中,堆栈信息尤为关键,通过堆栈信息可以快速定位到代码行。但是,线上运行时的程序为了安全和安装包体大小等因素,会对代码进行混淆或者压缩,所以获取到的堆栈文本是混淆压缩后的堆栈信息。为了使开发人员直观快速地理解堆栈含义,这就需要使用相关的符号文件来对混淆或者压缩的代码信息做还原处理。

对于各端应用,原生侧就有相关的工具提供做混淆/压缩后的还原能力。如下图所示:
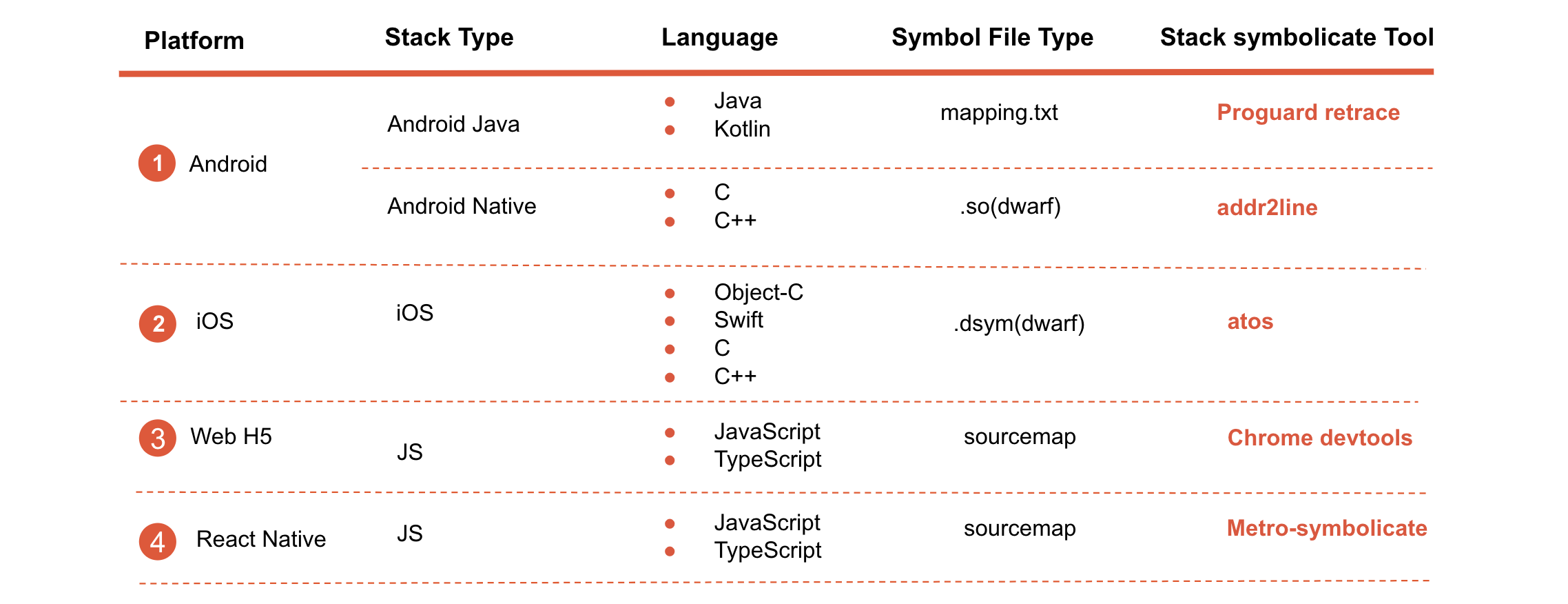
这些还原虽然能够做到精准的还原能力,但是结合在服务侧自动处理上就会带来一系列问题。
1)低性能
因为各个端提供的是命令行工具,所以需要在服务内部通过命令行调用,这种启动子进程的方式会带来大量的进程创建和销毁的性能损耗。此外,因为需要启动命令行子进程处理,处理跨进程通信也会带来较大的性能开销;通过命令行每次调用都要重复读取解析符号文件,带来了额外的性能开销。
2)难维护
因为命令行是通过子进程处理,无法管理命令行子进程的状态,对命令行的异常的定位解决带来了复杂性;不同端的工具会依赖不同语言和运行环境,例如 iOS 的 atos 通过 C++ 实现并且需要运行在 MacOS 环境下,这个对服务的统一部署非常不友好。
针对以上问题,MDAP 使用 Golang 实现了各个端侧的符号解析,保证各个符号信息只做一次解析,并转为 KV 结构形式缓存处理。统一语言后也能降低程序运维复杂性,并服务 docker 容器化的需求。
MDAP 在实现标准的函数还原的同时,也解决了部分工具在内联函数解析的问题,能够更精准高效地处理内联函数的解析场景。
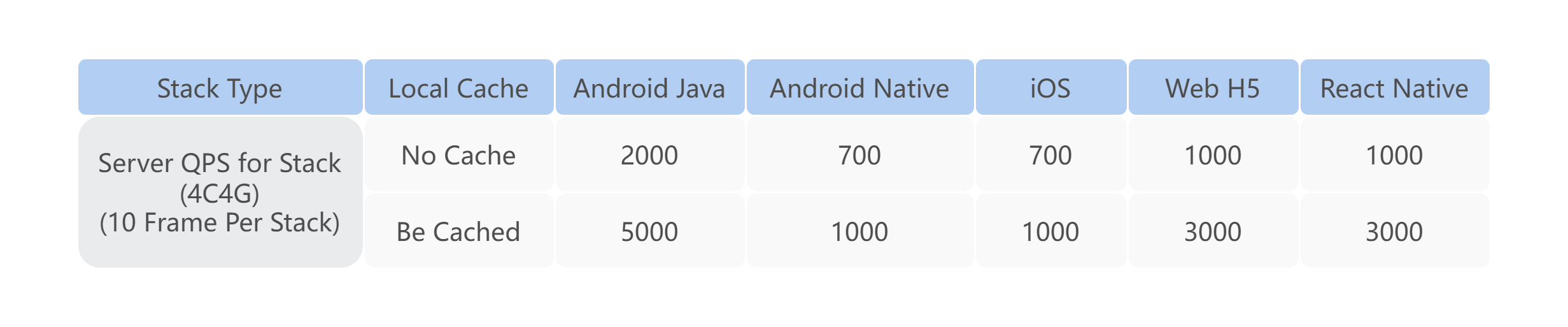
目前,符号还原服务已作为 MDAP 中一个重要分析服务,为各个业务提供稳定统一的还原解析能力。QPS(4C4G 下)最高可以达到 5000。
4.4 精准的问题聚合分析
对于上报的问题详情,MDAP 每天都会接受来自各个应用异常检测的详细信息上报,每个应用每日可能存在十万到百万级别的数据量。此外,还存在同一处问题多次上报的情况。例如,对于线上同一崩溃问题,不同用户都会上报同样的异常类型和堆栈数据等信息。如果这些上报的问题信息通过列表一一罗列的话,通过人工逐一排查是不可能的,这将严重降低研发人员排查问题的效率。
为了提升解决问题的效率,就需要对问题聚合归类,在页面上做聚合展示或者问题的告警,降低对同一问题重复定位评估的消耗。
在每个异常上报中,除了基础元信息外,还包括异常类型、异常消息、异常堆栈等运行时内容,特备是堆栈信息,能够有效地协助研发去识别异常点。那么我们就可以依据堆栈和异常类型来做聚合。
简单来说,可以按照堆栈信息做 hash 比对来去重,虽然该方案能够大幅减少重复异常,但还是会存在大量同类问题归结为不同类别的情况,例如在递归情况下的异常,递归深度不同就会导致 hash 结果不一致。
如下图,左右两侧堆栈是同类问题,如果用 hash 就会归结为不同类别,那么无论是告警推送还是归类展示上就会存在两个类别,导致研发重复定位分析消耗人力,或者告警不精准的问题。

总的来说,归类不精准、归类错误会带来的问题有两点:
- 低效性:如果利用人工对堆栈的内容进行识别,效率较低。同时,对于堆栈的识别需要一定的基础知识,人力成本较高;
- 误报重复量大:在这些来自各个应用的报错堆栈中,实际上有许多堆栈由同一种错误引起。如果对这些堆栈进行重复处理,显然是没有必要的。
因此,我们希望设计一种算法,能够自动化识别来自各个应用的堆栈,对相似的堆栈进行同样的处理。达到节省人力,提高堆栈处理效率的目的。
近十年来,在堆栈去重领域,已有大量论文致力于该方面的研究。其中比较有影响力的几篇包括 《ReBucket: A Method for Clustering Duplicate Crash Reports Based on Call Stack Similarity》《TraceSim: An Alignment Method for Computing Stack Trace Similarity》《DURFEX: A Feature Extraction Technique for Efficient Detection of Duplicate Bug Reports》。这些论文都是通过堆栈距离、TF-IDF 等手段对堆栈的内容进行解析,然后利用相应的公式来计算两个堆栈之间的相似性。
以上算法与技术在这一领域中得到了广泛应用并取得了良好的效果。下图显示的是 ReBucket 的堆栈距离的思想,通过堆栈栈帧与栈顶距离以及堆栈之间相同栈帧的距离来计算相似性。
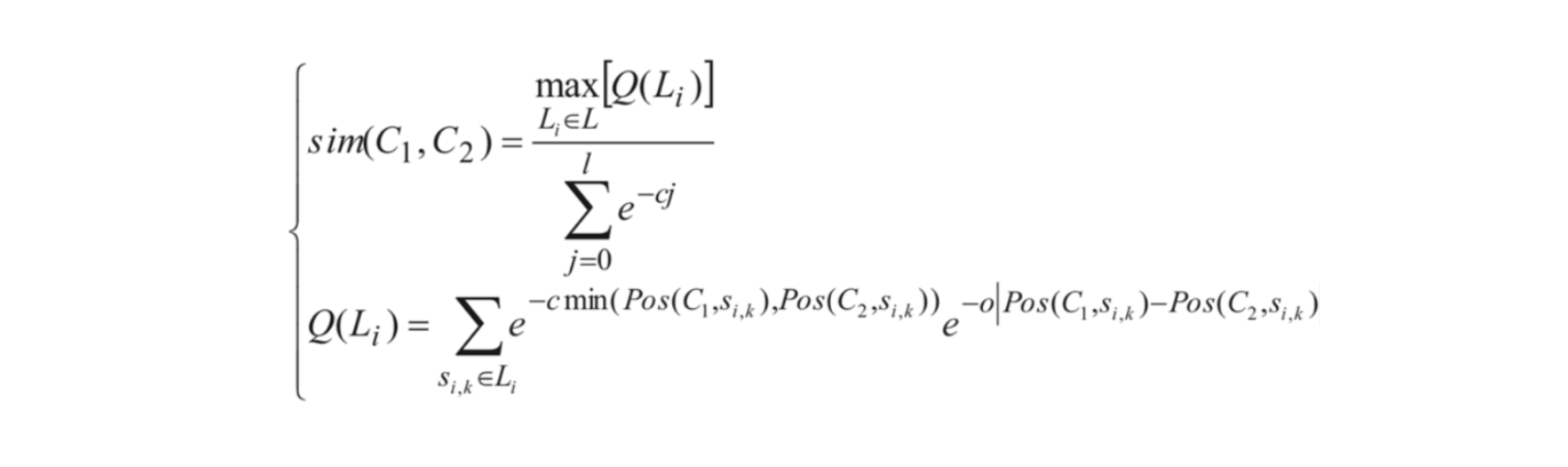
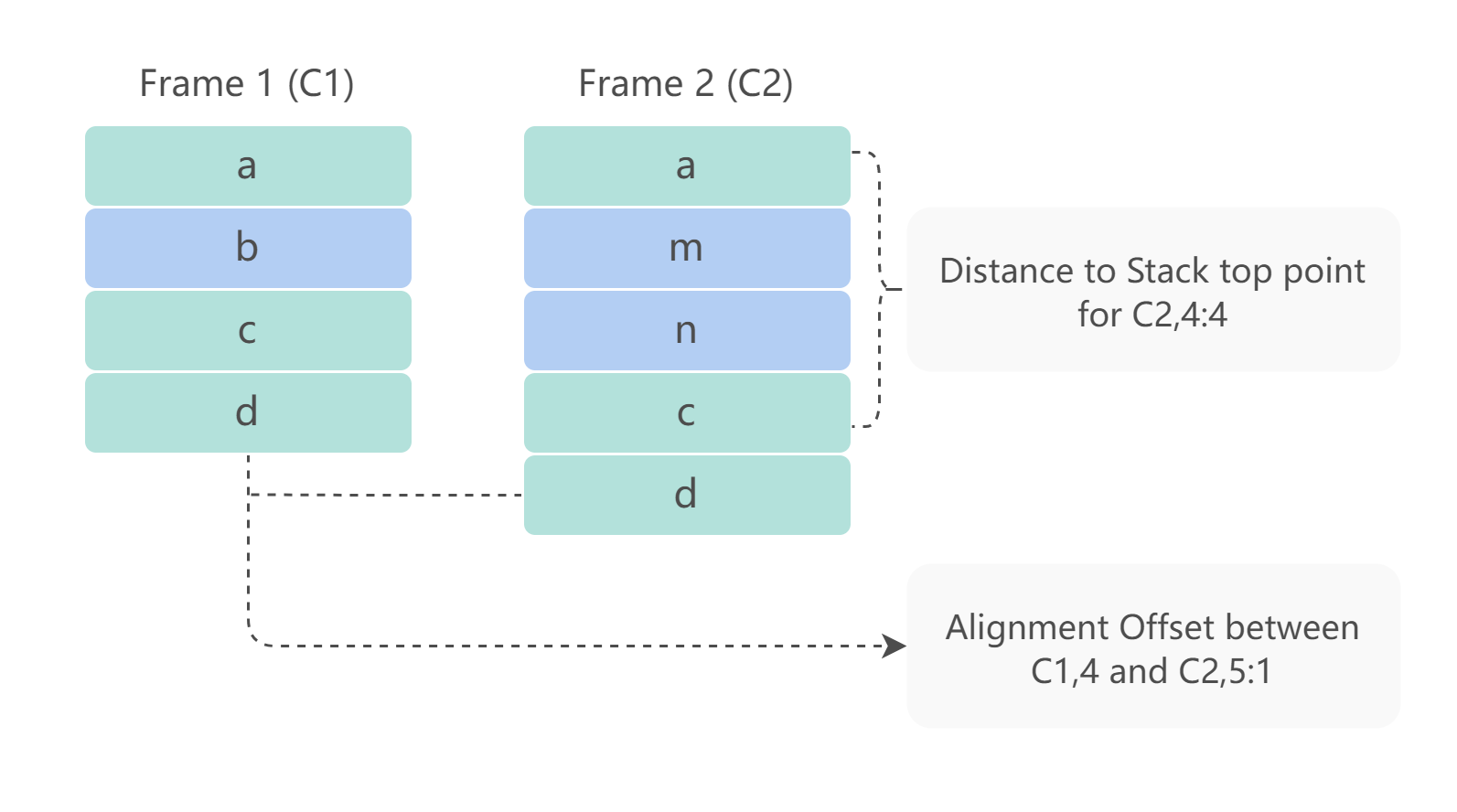
MDAP 基于对相关论文的阅读并分析了论文的不足之处,提出了一种新的衡量堆栈相似度的算法,称为 WESTSD(WEight based Trace Similartiy Detection)。该算法主要利用 TF-IDF 以及机器学习技术,对 DURFEX 论文进行了缺陷的补充,融合了 traceSim 论文中帧相对位置对重要性的影响。
结果显示,该算法在两个数据集上的表现都超过了之前几种比较流行的算法,为衡量堆栈相似性提供了更好的标准。后续我们会对 WESTSD 算法发表文章,做更详细的介绍。
在 Netbeans 数据集和 Eclipse 数据集上对比了 MDAP 的 WESTSD 算法与几个最新的堆栈相似度算法的精度。结果显示,我们提出的算法在各个层面上精度都有显著的提升。
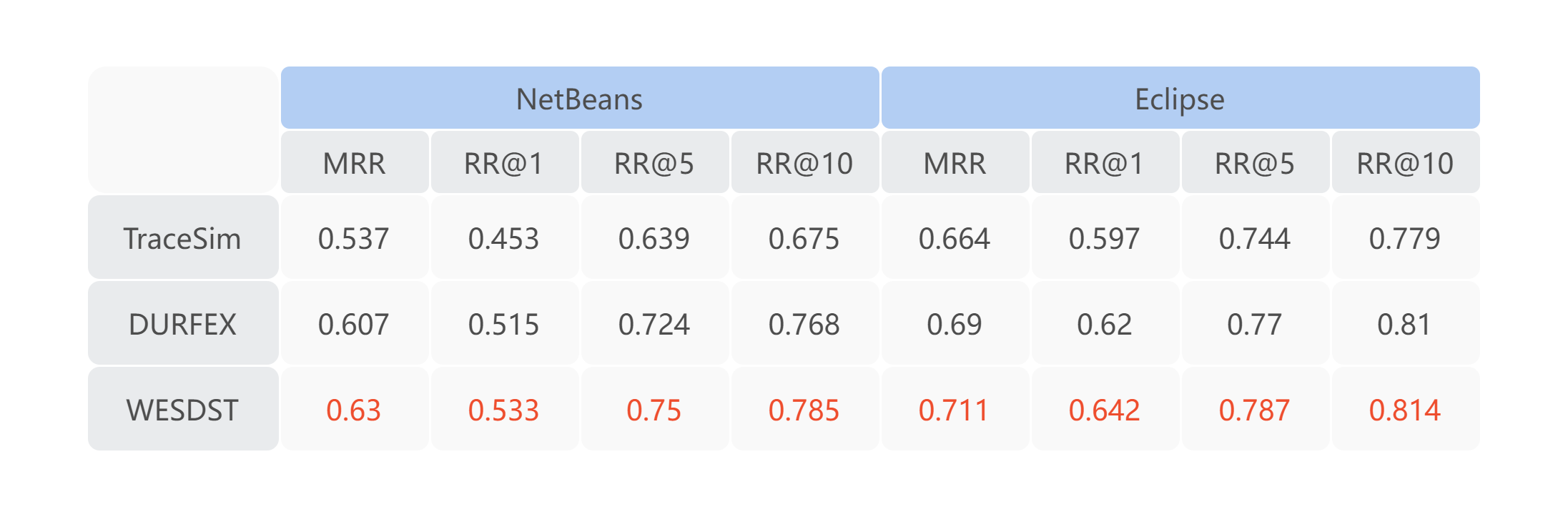
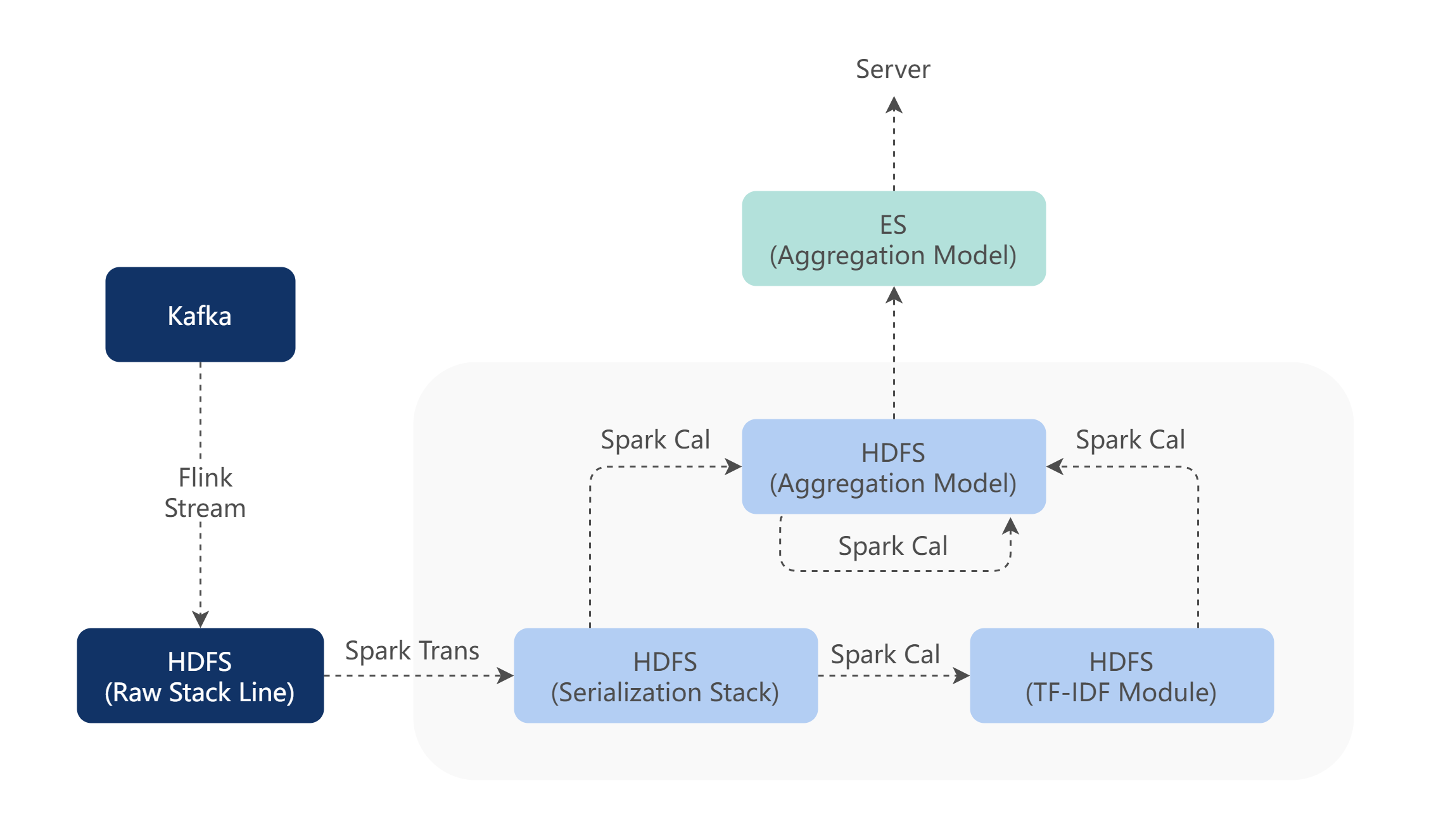
根据算法设计的数据架构调用图如下,通过该架构模式可以离线生成对应的分类模型,提供给服务做实时分类处理。
该聚合算法对上报的异常打标后,就可以在页面上对打标的数据做聚合展示,如下图所示。
4.5 URL 自动模板化
无论移动端或 Web 端在网络请求分析时候,都会按照具体的 URL 进行统计分析,在面对一个应用可能会访问成千上万条 URL 时,不能明显地标识出应用访问的哪些 URL 存在潜在问题。特别是面对大量的 REST 风格的 API 时,尤其显著。例如,对于如下的统计,业务研发更期望看到右侧的统计指标,因为该指标能够更直观反应某一个 API 接口的响应耗时情况。
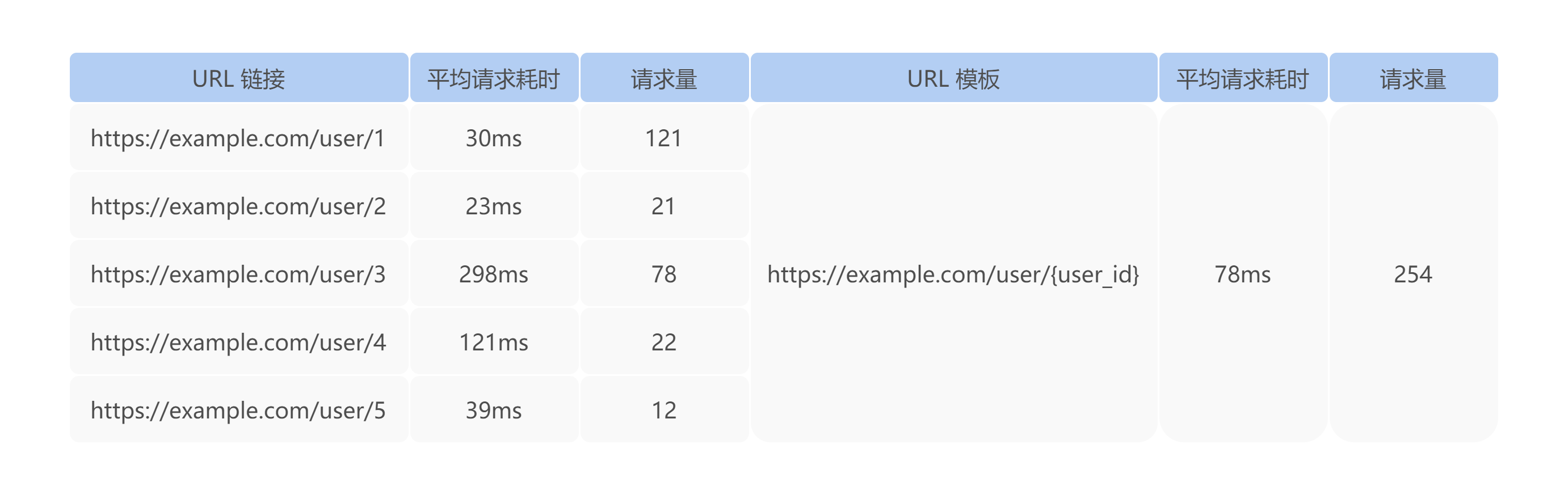
综上,对于 URL 统计聚合,目前有如下两个方案:
- 按照字符串 hash 聚合,则会存在大量散列的 URL,降低了分析的效率,同时聚合后的统计指标只能反馈请求的状态,而不能反馈 API 类别的状态。
- 依照用户配置模板聚合,那么对于大型系统的成百上千的 API,需要大量的人力运维成本,容易缺漏,配置更新的时效性不能保证,且对模板的正则不同 API 风格可能不一致。
针对以上问题,MDAP 平台依据 URL 的特性,将 URL 按照路径、查询条件先做了结构格式的归一化。然后参照论文《A Pattern Tree-based Approach to Learning URL Normalization Rules》通过两层算法实现:
- 统计各个层级的词频,通过高斯分布算法,将熵最小的键的值按照其频次进行倒序排序,并对计算相邻的两个值之间的频次下降速度,切分出高频词与低频词,通过保留高频词,模板归一化低频词来做到自动模板化;
- 对于部分 URL 中没法显著切分高低频词的情况,通过马尔可夫链和密度函数进行剪枝处理,来标识显著值和离散值,通过保留显著值,模板归一化离散值来实现模板。例如
/something/aGVsbG8K中的aGVsbG8K等其他非人类语言为离散值,就会被替换为通用符号。
通过以上使用概率统计和机器学习的方案,将若干条相似的 URL 归一化成同一条规则模型,例如把 http://example.com/users/1, http://example.com/users/2 归一成 http://example.com/users/* 模型,然后基于该规则模型进行相关统计分析,从而提高了基于 URL 的客户端监控分析的可用性及准确性。
如下优化前去重后的 URL 进行统计分析约 8110条,在模板化后能够收归到 60 条左右。在检测到某个 API 模式慢请求情况下,可以进一步通过页面下钻查看该模式下的全部详细的 URL 请求指标。
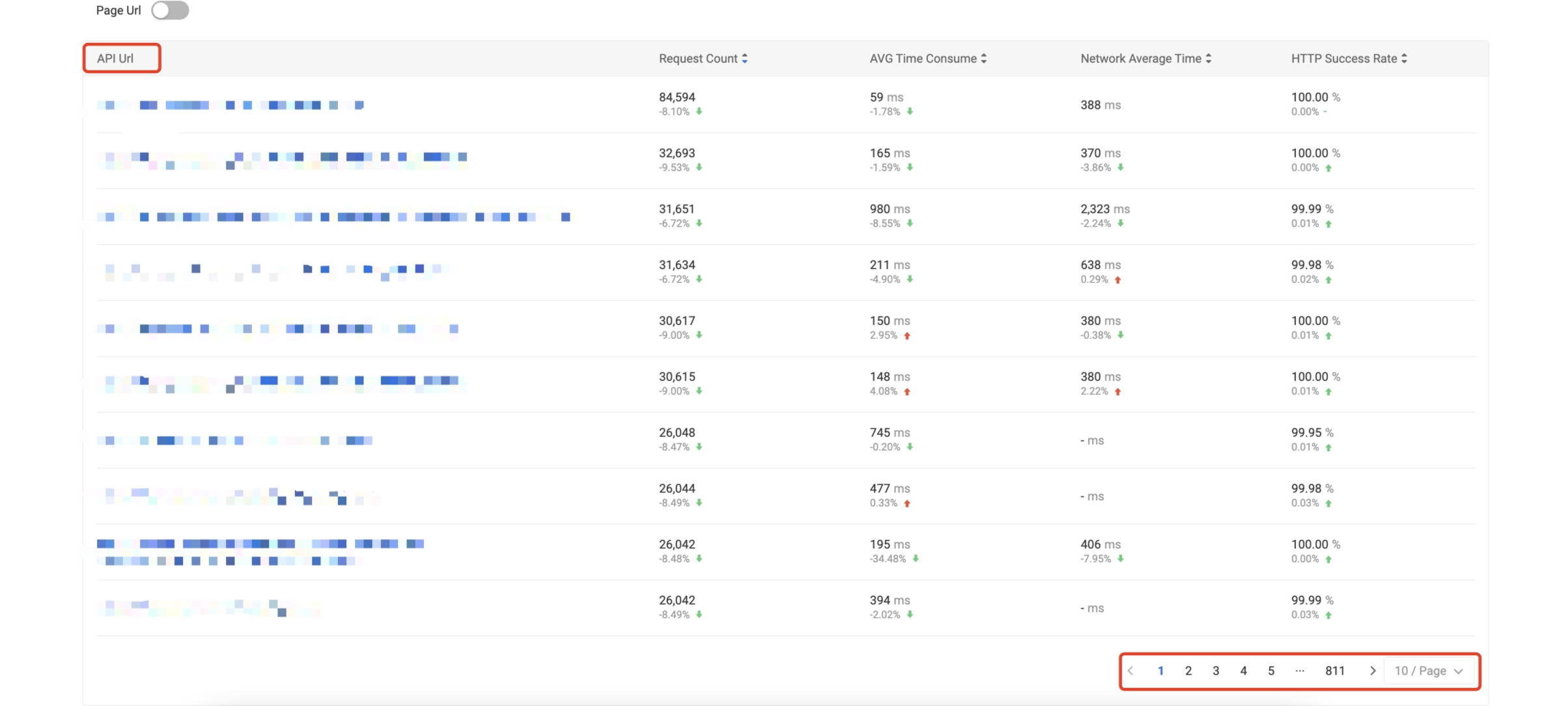
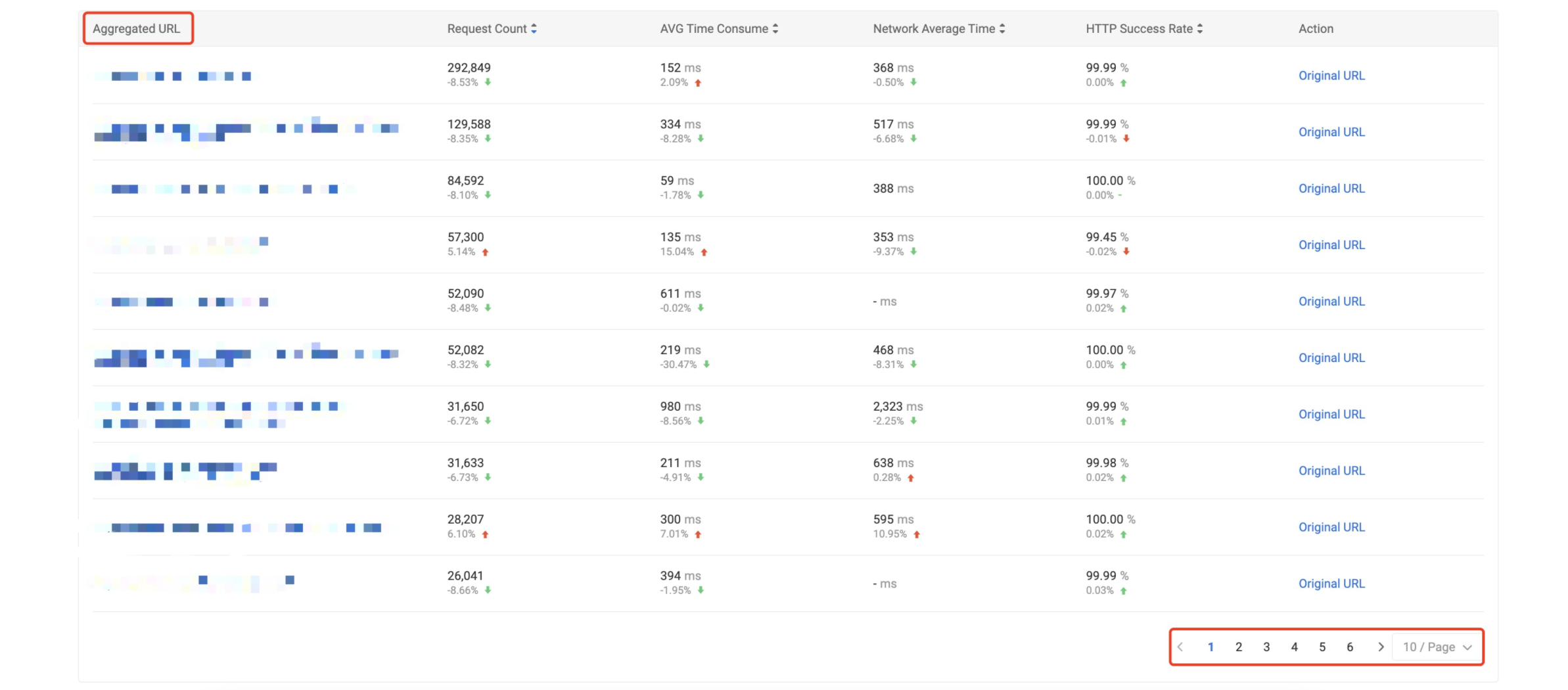
后续我们也会对该算法做详细的文章介绍。
5. 未来规划
目前 MDAP 已接入并运行在 Shopee 多个业务应用中,已协助业务监控发现了各自应用中的问题。后续 MDAP 将在对齐业界 Gartner 等权威机构确立的标准来完善自身能力。
1)端到端的数据联动
终端的问题并非孤立存在,它可能会受到后端的服务质量影响,双端的数据联通与关联能够为业务构建起完整的应用质量地图。后续 MDAP 将与后台监控、后台日志团队在数据服务上做联动,为应用服务提供一站式的全景监控服务能力。
2)智能分析能力
本着数据驱动的理念,以及高效挖掘并利用已有数据的思路。MDAP 后续将通过结合研发期间的数据,通过发布信息、代码变更信息、测试案例等,构建研发流程画像,同时结合线上观测数据与问题详情构建的线上质量画像,做到研发内问题提前预警,以及线上问题的在代码和责任人层面的根因分析,降低研发排查问题的时间消耗以及人员沟通成本。
🔗 参考资料
- Amazon Found Every 100ms of Latency Cost them 1% in Sales
- Gartner Glossary Application Performance Monitoring
- Systems and Methods for End-User Experience Monitoring
- ReBucket: A Method for Clustering Duplicate Crash Reports Based on Call Stack Similarity
- TraceSim: An Alignment Method for Computing Stack Trace Similarity
- DURFEX: A Feature Extraction Technique for Efficient Detection of Duplicate Bug Reports
- A Pattern Tree-based Approach to Learning URL Normalization Rules
本文作者
Huaxing,MDAP 项目组负责人,来自 Shopee Engineering Infrastructure 团队。
|








- 上一条: CSS Houdini:用浏览器引擎实现高级CSS效果 2022-07-11
- 下一条: 搭上数字化列车,带你看看智能运维的新景象 2022-07-11
- 基于AutoTagging技术实践 构建统一的可观测性数据平台 2022-05-07
- golang的优劣与前景分析 2021-06-27
- All in one:如何搭建端到端可观测体系 2021-12-17
- 深度解析|基于 eBPF 的 Kubernetes 一站式可观测性系统 2022-02-24
- 【万字长文】Apache ShenYu集成Apache RocketMQ实现海量日志采集的原理与实践 2022-03-11


