SOFARegistry 源码|数据同步模块解析


文|宋国磊(GitHub ID:glmapper )
SOFAStack Committer、华米科技高级研发工程师
负责华米账号系统、框架治理方向的开发
本文 3024 字 阅读 10 分钟
|前言|
本文主要围绕 SOFARegistry 的数据同步模块进行了源码的解析。其中,对于注册中心的概念以及 SOFARegistry 的基础架构将不再做详细的阐述,有兴趣的小伙伴在《海量数据下的注册中心 - SOFARegistry 架构介绍》[1]一文中获取相关介绍。
本文主要的思路大致分为以下 2 个部分:
- 第一部分,借助 SOFARegistry 中的角色分类来说明哪些角色之间会进行数据同步;
- 第二部分,对数据同步的具体实现进行解析。
PART. 1——SOFARegistry 的角色分类
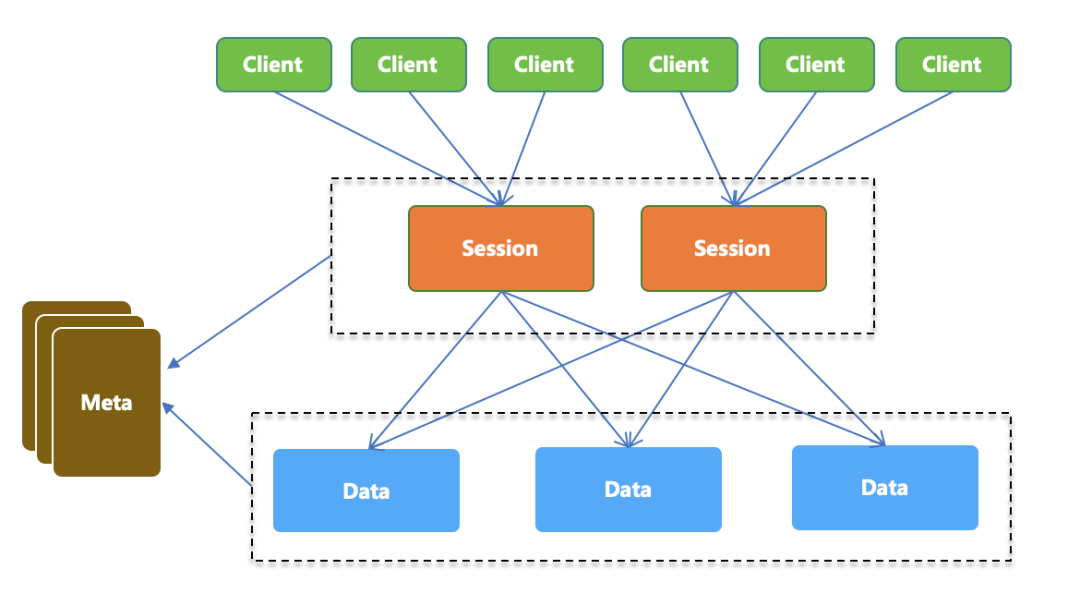
如上图所示,SOFARegistry 包含以下 4 个角色:
Client
提供应用接入服务注册中心的基本 API 能力,应用系统通过依赖客户端 JAR 包,通过编程方式调用服务注册中心的服务订阅和服务发布能力。
SessionServer
会话服务器,负责接受 Client 的服务发布和服务订阅请求,并作为一个中间层将写操作转发 DataServer 层。SessionServer 这一层可随业务机器数的规模的增长而扩容。
DataServer
数据服务器,负责存储具体的服务数据,数据按 dataInfoId 进行一致性 Hash 分片存储,支持多副本备份,保证数据高可用。这一层可随服务数据量的规模的增长而扩容。\
MetaServer
元数据服务器,负责维护集群 SessionServer 和 DataServer 的一致列表,作为 SOFARegistry 集群内部的地址发现服务,在 SessionServer 或 DataServer 节点变更时可以通知到整个集群。
在这 4 个角色中,MetaServer 作为元数据服务器本身不处理实际的业务数据,仅负责维护集群 SessionServer 和 DataServer 的一致列表,不涉及数据同步问题。
Client 与 SessionServer 之间的核心动作是订阅和发布,从广义上来说,属于用户侧客户端与 SOFARegistry 集群的数据同步,详情可以见:
https://github.com/sofastack/sofa-registry/issues/195,因此不在本文讨论范畴之内。
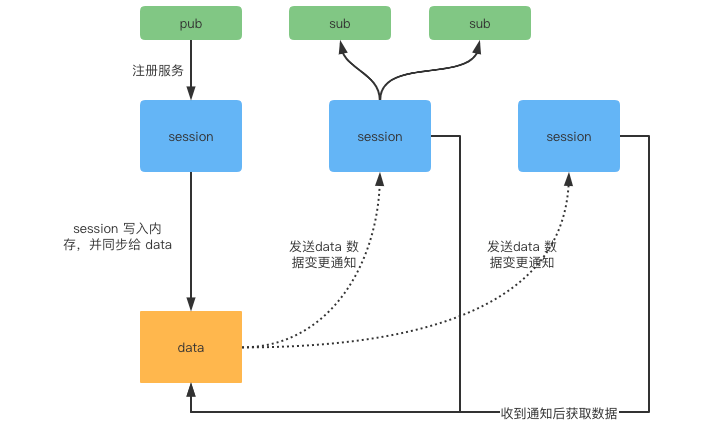
SessionServer 作为会话服务,它主要解决海量客户端连接问题,其次是缓存客户端发布的所有 pub 数据。Session 本身不持久化服务数据,而是将数据转写到 DataServer。DataServer 存储服务数据是按照 dataInfoId 进行一致性 Hash 分片存储的,支持多副本备份,保证数据高可用。
从 SessionServer 和 DataServer 的功能分析中可以得出:
SessionServer 缓存的服务数据需要与 DataServer 存储的服务数据保持一致。
DataServer 支持多副本来保证高可用,因此 DataServer 多副本之间需要保持服务数据一致。
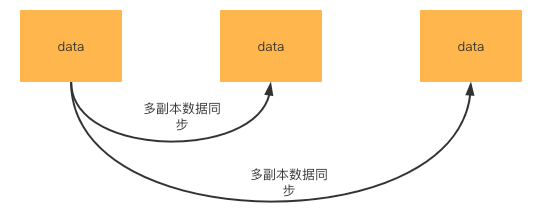
SOFARegistry 中,针对上述两个对于数据的一致性保证就是通过数据同步机制来实现的。
PART. 2——数据同步的具体实现
了解了 SOFARegistry 的角色分类之后,我们开始深入数据同步具体的实现细节。我将主要围绕 SessionServer 和 DataServer 之间的数据同步,以及 DataServer 多副本之间的数据同步两块内容来展开。
「SessionServer 和 DataServer 之间的数据同步」
SessionServer 和 DataServer 之间的数据同步,是基于如下推拉结合的机制:
推: DataServer 在数据有变化时,会主动通知 SessionServer,SessionServer 检查确认需要更新 (对比 version) 后主动向 DataServer 获取数据。
拉: 除了上述的 DataServer 主动推以外,SessionServer 每隔一定的时间间隔,会主动向 DataServer 查询所有 dataInfoId 的 version 信息,然后再与 SessionServer 内存的 version 作比较。若发现 version 有变化,则主动向 DataServer 获取数据。这个“拉”的逻辑,主要是对“推”的一个补充,若在“推”的过程中出现错漏的情况可以在这个时候及时弥补。
推和拉两种模式检查的 version 会有一些差异,这部分内容详见下面“推模式下的数据同步”和“拉模式下的数据同步”中的具体介绍。
「推模式下的数据同步流程」
推模式是通过 SyncingWatchDog 这个守护线程不断 loop 执行来实现数据变更检查和通知发起的:
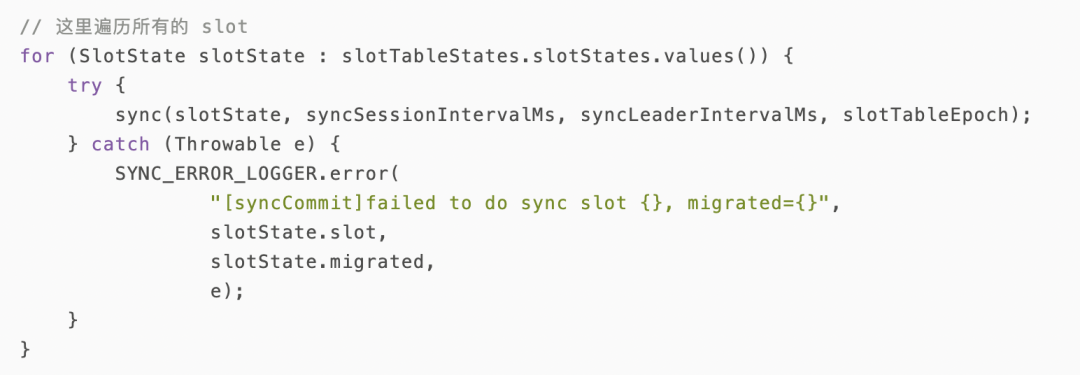
根据 slot 分组汇总数据版本。data 与每个 session 的连接都对应一个 SyncSessionTask,SyncSessionTask 负责执行同步数据的任务,核心同步逻辑在:
com.alipay.sofa.registry.server.data.slot.SlotDiffSyncer#sync 方法中完成,大致流程如下时序图所示:
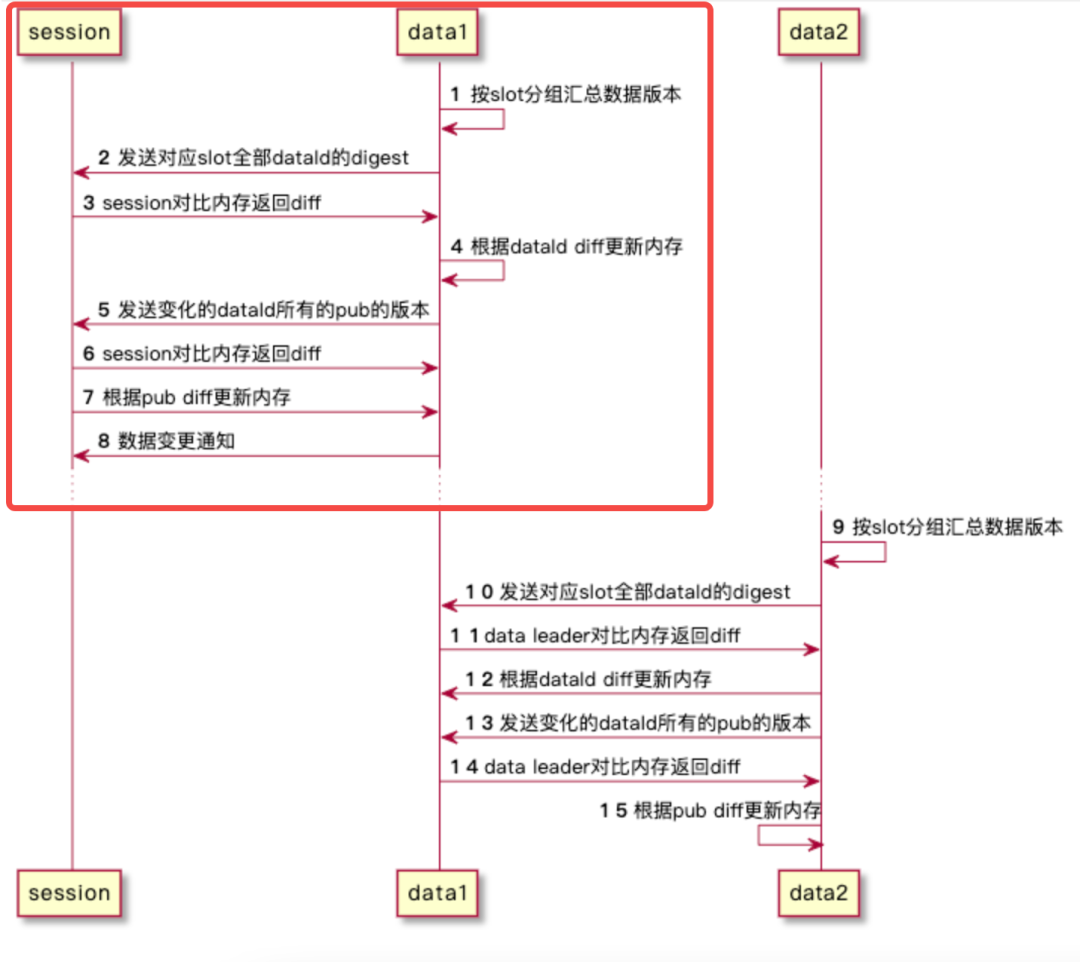
上图圈红部分的逻辑第四步,根据 dataInfoId diff 更新 data 内存数据,可以看到这里仅处理了被移除的 dataInfoId,对于新增和更新的没有做任务处理,而是通过后面的第 5-7 步来完成。这么做的主要原因在于避免产生空推送而导致一些危险情况发生。
第 5 步中,比较的是所有变更 dataInfoId 的 pub version,具体比较逻辑可以参考后面 diffPublisher 小节中的介绍。
「数据变更的事件通知处理」
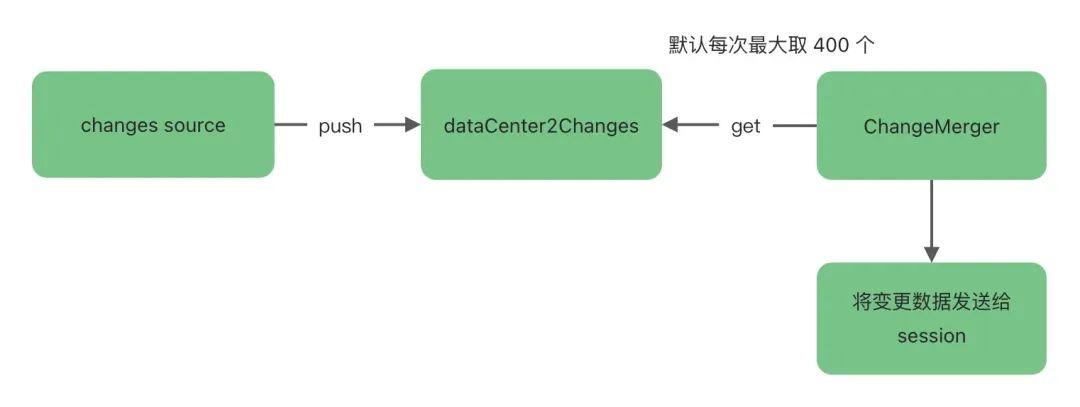
数据变更事件会被收集在 DataChangeEventCenter 的 dataCenter2Changes 缓存中,然后由一个守护线程 ChangeMerger 负责从 dataCenter2Changes 缓存中不断的读取,这些被捞到的事件源会被组装成 ChangeNotifier 任务,提交给一个单独的线程池 (notifyExecutor) 处理,整个过程全部是异步的。
「拉模式下的数据同步流程」
拉模式下,由 SessionServer 负责发起,
com.alipay.sofa.registry.server.session.registry.SessionRegistry.VersionWatchDog
默认情况下每 5 秒扫描一次版本数据,如果版本有发生变更,则主动进行一次拉取,流程大致如下:
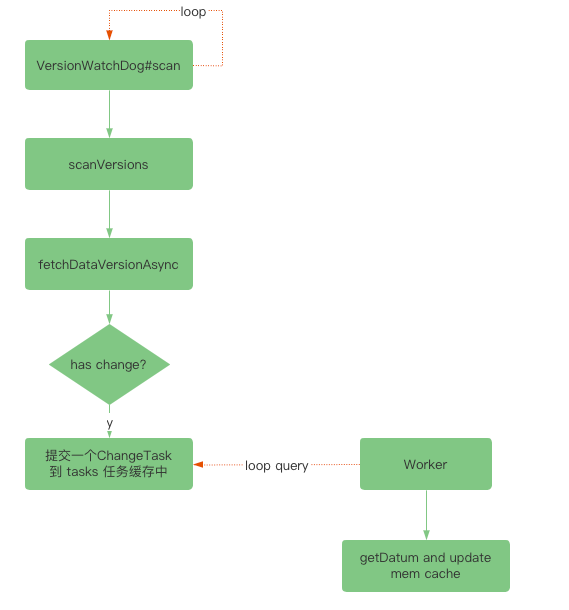
需要注意的是,拉模式对推送流程的补充,这里的 version 是每个 sub 的 lastPushedVersion, 而推模式的 version 是 pub 的数据的 version。关于 lastPushedVersion 的获取可以参考:
com.alipay.sofa.registry.server.session.store.SessionInterests#selectSubscribers

「DataServer 多副本之间的数据同步」
主要是 slot 对应的 data 的 follower 定期和 leader 进行数据同步,其同步逻辑与 SessionServer 和 DataServer 之间的数据同步逻辑差异不大;发起方式也是一样的;data 判断如果当前节点不是 leader,就会进行与 leader 之间的数据同步。

「增量同步 diff 计算逻辑分析」
不管是 SessionServer 和 DataServer 之间的同步,还是 DataServer 多副本之间的同步,都是基于增量 diff 同步的,不会一次性同步全量数据。
本节对增量同步 diff 计算逻辑进行简单分析,核心代码在:
com.alipay.sofa.registry.common.model.slot.DataSlotDiffUtils (建议阅读这部分代码时直接结合代码中的测试用例来看) 。
主要包括计算 digest 和 publishers 两个。
diffDigest
用 DataSlotDiffUtils#diffDigest 方法接收两个参数:
- targetDigestMap 可以理解为目标数据
- sourceDigestMap 可以理解为基线数据
核心计算逻辑如下代码分析:

那么根据上述 diff 计算逻辑,这里有如下几种场景 (假设基线数据集数据中 dataInfoId 为 a 和 b) :
1. 目标数据集为空:返回 dataInfoId 为 a 和 b 两项作为新增项;
2. 目标数据集与基线数据集相等,新增项、待更新项与待移除项均为空;
3. 目标数据集中包括 a、b、c 三个 dataInfoId,则返回 c 作为待移除项;
4. 目标数据集中包括 a 和 c 两个 dataInfoId,则返回 c 作为待移除项,b 作为新增项
diffPublisher
diffPublisher 与 diffDigest 计算稍有不同,diffPublisher 接收三个参数,除了目标数据集和基线数据集之外,还有一个 publisherMaxNum (默认 400) ,用于限制每次处理的数据个数;这里同样给出核心代码解释:


这里同样对几种场景做一下分析 (下面指的是更新 dataInfoId 对应的 publisher,registerId 与 publisher 一一对应) :
1. 目标数据集与基线数据集相同,且数据没有超过 publisherMaxNum,返回的待更新和待移除均为空,且没有剩余未处理数据;
2. 需要移除的情况: 基线中不包括目标数据集 dataInfoId 的 registerId (移除的是 registerId,不是 dataInfoId)
3. 需要更新的情况: - 目标数据集中存在基线数据集不存在的 registerId - 目标数据集和基线数据集存在的 registerId 的版本不同
PART. 3——总结
本文主要介绍了 SOFARegistry 中的数据同步模块。在整个过程中,我们首先从 SOFARegistry 角色分类阐述不同角色之间存在的数据同步问题,并针对其中 SessionServer 与 DataServer 之间的数据同步 和 DataServer 多副本之间的数据同步进行了展开。
在 SessionServer 与 DataServer 数据同步分析中,着重分析了推和拉两种场景下数据同步的整体流程。最后对 SOFARegistry 中数据增加的 diff 计算逻辑进行了介绍,并结合相关核心代码描述了具体的场景。
整体来看,SOFARegistry 在数据同步上的处理上有如下三点可以对我们有所启发:
1. 在一致性方面,SOFARegistry 基于 ap,满足了最终一致性,并在实际的同步逻辑处理上,结合事件机制,基本都是异步化完成的,这样一来就有效弱化了数据同步对于核心流程的影响;
2. 在拉模式和数据变更通知两个部分,内部采用了类似“生产-消费模型”,一方面是对于生产和消费逻辑的解耦,从代码上更独立;另一方面通过缓存或者队列来消除生产和消费速度不同而导致的相互阻塞的问题;
3. 拉模式对推模式的补充;我们知道推模式是 server -> client,发生在数据变更时,如果出现一些异常,导致某条 server -> client 链路推送失败,则会导致不同 client 持有的数据不一致的情况;拉模式的补充,让 client 能主动去完成对于数据一致性的检查。
【参考链接】
[1]《海量数据下的注册中心 - SOFARegistry 架构介绍》:https://www.sofastack.tech/blog/sofa-registry-introduction/
项目原文地址:https://www.sofastack.tech/projects/sofa-registry/code-analyze/code-analyze-data-synchronization/
了解更多
SOFARegistry Star 一下✨:
https://github.com/sofastack/sofa-registry
本周推荐阅读
SOFARegistry 源码|数据分片之核心-路由表 SlotTable 剖析
探索 SOFARegistry(一)|基础架构篇

MOSN 构建 Subset 优化思路分享

Nydus —下一代容器镜像探索实践


|








- 上一条: 我把整个研发中台拆分过程的一些心得总结 2022-06-28
- 下一条: 揭秘百度智能测试在测试自动执行领域实践 2022-06-29
- SOFARegistry 源码|数据分片之核心-路由表 SlotTable 剖析 2022-04-20
- 一文带你认识 SOFARegistry 之基础架构篇 2022-03-01
- 基于开源流批一体数据同步引擎ChunJun数据还原—DDL解析模块的实战分享 2022-06-30
- openGauss数据库源码解析系列文章——存储引擎源码解析(三) 2021-12-22
- ⭐openGauss数据库源码解析系列文章—— 角色管理⭐ 2021-10-29


