vivo 容器集群监控系统架构与实践

vivo 互联网服务器团队-YuanPeng
一、概述
从容器技术的推广以及 Kubernetes成为容器调度管理领域的事实标准开始,云原生的理念和技术架构体系逐渐在生产环境中得到了越来越广泛的应用实践。在云原生的体系下,面对高度的弹性、动态的应用生命周期管理以及微服务化等特点,传统的监控体系已经难以应对和支撑,因此新一代云原生监控体系应运而生。
当前,以Prometheus为核心的监控系统已成为云原生监控领域的事实标准。Prometheus作为新一代云原生监控系统,拥有强大的查询能力、便捷的操作、高效的存储以及便捷的配置操作等特点,但任何一个系统都不是万能的,面对复杂多样的生产环境,单一的Prometheus系统也无法满足生产环境的各种监控需求,都需要根据环境的特点来构建适合的监控方法和体系。
本文以vivo容器集群监控实践经验为基础,探讨了云原生监控体系架构如何构建、遇到的挑战以及相应的对策。
二、云原生监控体系
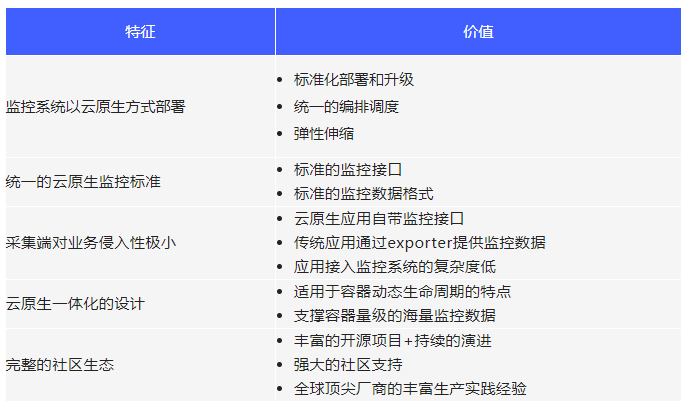
2.1 云原生监控的特征和价值
云原生监控相比于传统监控,有其特征和价值,可归纳为下表:
2.2 云原生监控生态简介
CNCF生态全景图中监控相关的项目如下图(参考https://landscape.cncf.io/),下面重点介绍几个项目:
- Prometheus(已毕业)
Prometheus是一个强大的监控系统,同时也是一个高效的时序数据库,并且具有完整的围绕它为核心的监控体系解决方案。单台Prometheus就能够高效的处理大量监控数据,并且具备非常友好且强大的PromQL语法,可以用来灵活查询各种监控数据以及告警规则配置。
Prometheus是继Kubernetes之后的第二个CNCF “毕业”项目(也是目前监控方向唯一“毕业”的项目),开源社区活跃,在Github上拥有近4万Stars。
Prometheus的Pull指标采集方式被广泛采用,很多应用都直接实现了基于Prometheus采集标准的metric接口来暴露自身监控指标。即使是没有实现metric接口的应用,大部分在社区里都能找到相应的exporter来间接暴露监控指标。
但Prometheus仍然存在一些不足,比如只支持单机部署,Prometheus自带时序库使用的是本地存储,因此存储空间受限于单机磁盘容量,在大数据量存储的情况下,prometheus的历史数据查询性能会有严重瓶颈。因此在大规模生产场景下,单一prometheus难以存储长期历史数据且不具备高可用能力。
-
Cortex(孵化中)
Cortex对Prometheus进行了扩展,提供多租户方式,并为Prometheus提供了对接持久化存储的能力,支持Prometheus实例水平扩展,以及提供多个Prometheus数据的统一查询入口。
-
Thanos(孵化中)
Thanos通过将Prometheus监控数据存储到对象存储,提供了一种长期历史监控数据存储的低成本解决方案。Thanos通过Querier组件给Prometheus集群提供了全局视图(全局查询),并能将Prometheus的样本数据压缩机制应用到对象存储的历史数据中,还能通过降采样功能提升大范围历史数据的查询速度,且不会引起明显的精度损失。
-
Grafana
Grafana是一个开源的度量分析与可视化套件,主要在监控领域用于时序数据的图标自定义和展示,UI非常灵活,有丰富的插件和强大的扩展能力,支持多种不同的数据源(Graphite, InfluxDB, OpenTSDB, Prometheus, Elasticsearch, Druid等等)。Grafana还提供可视化的告警定制能力,能够持续的评估告警指标,发送告警通知。
此外,Grafana社区提供了大量常用系统/组件的监控告警面板配置,可以一键在线下载配置,简单便捷。
-
VictoriaMetrics
VictoriaMetrics是一个高性能、经济且可扩展的监控解决方案和时序数据库,可以作为Prometheus的长期远程存储方案,支持PromQL查询,并与Grafana兼容,可用于替换Prometheus作为Grafana的数据源。具有安装配置简单、低内存占用、高压缩比、高性能以及支持水平扩展等特性。
-
AlertManager
AlertManager是一个告警组件,接收Prometheus发来的告警,通过分组、沉默、抑制等策略处理后,通过路由发送给指定的告警接收端。告警可以按照不同的规则发送给不同的接收方,支持多种常见的告警接收端,比如Email,Slack,或通过webhook方式接入企业微信、钉钉等国内IM工具。
2.3 如何搭建一套简单的云原生监控系统
上文了解了云原生监控领域的常用工具后,该如何搭建一套简单的云原生监控系统?下图给出了Prometheus社区官方提供的方案:
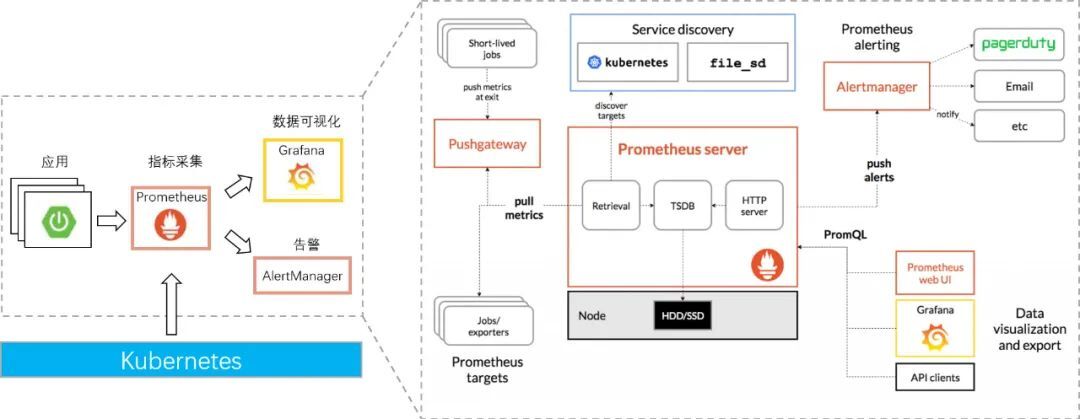
(出处:Prometheus社区)
上述系统展开阐述如下:
- 所有监控组件都是以云原生的方式部署,即容器化部署、用Kubernetes来统一管理。
- Prometheus负责指标采集和监控数据存储,并可以通过文件配置或Kubernetes服务发现方式来自动发现采集目标。
- 应用可以通过自身的Metric接口或相应的exporter来让Prometheus拉取监控数据。
- 一些短暂的自定义采集指标,可以通过脚本程序采集并推送给Pushgateway组件,来让Prometheus拉取。
- Prometheus配置好告警规则,将告警数据发送给Alertmanager,由Alertmanager按照一定规则策略处理后路由给告警接收方。
- Grafana配置Prometheus作为数据源,通过PromQL查询监控数据后,做告警面板展示。
2.4 如何构建能力开放、稳定高效的云原生监控体系
上文展示了社区官方给出的监控系统搭建方案,但该方案在生产环境应用时存在的主要问题:
- Prometheus单机无法存储大量长期历史数据;
- 不具备高可用能力;
- 不具备横向扩展能力;
- 缺少多维度的监控统计分析能力。
那么对于大规模复杂生产环境,如何构建能力开放、稳定高效的云原生监控体系?
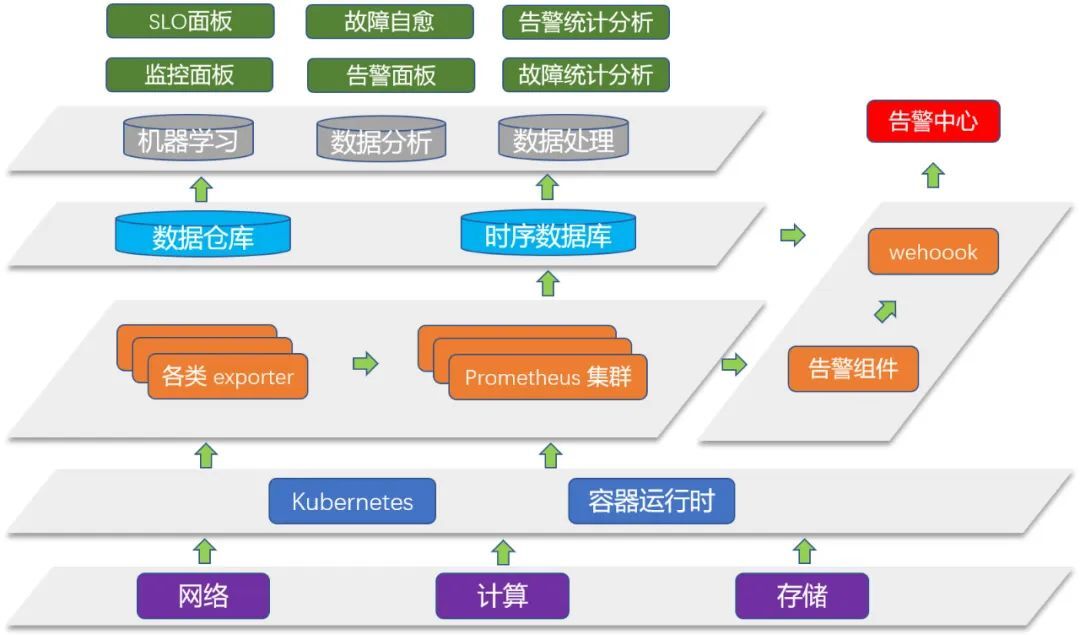
综合vivo自身容器集群监控实践经验、各类云原生监控相关文档以及技术大会上各家厂商的技术架构分享,可以总结出适合大规模生产场景的云原生监控体系架构,下图展示了体系架构的分层模型。
- 通过云原生方式部署,底层使用Kubernetes作为统一的控制管理平面。
- 监控层采用Prometheus集群作为采集方案,Prometheus集群通过开源/自研高可用方案来保证无单点故障以及提供负载均衡能力,监控指标则通过应用/组件的自身Metric API或exporter来暴露。
- 告警数据发给告警组件按照指定规则进行处理,再由webhook转发给公司的告警中心或其他通知渠道。
- 数据存储层,采用高可用可扩展的时序数据库方案来存储长期监控数据,同时也用合适的数仓系统存储一份来做更多维度的监控数据统计分析,为上层做数据分析提供基础。
- 数据分析处理层,可以对监控数据做进一步的分析处理,提供更多维度的报表,挖掘更多有价值的信息,甚至可以利用机器学习等技术实现故障预测、故障自愈等自动化运维目的。
三、vivo容器集群监控架构
任何系统的架构设计一定是针对生产环境和业务需求的特点,以满足业务需求和高可用为前提,在综合考虑技术难度、研发投入和运维成本等综合因素后,设计出最符合当前场景的架构方案。因此,在详解vivo容器集群监控架构设计之前,需要先介绍下背景:
- 生产环境
vivo目前有多个容器化生产集群,分布在若干机房,目前单集群最大规模在1000~2000节点。
-
监控需求
需要满足生产高可用,监控范围主要包括容器集群指标、物理机运行指标和容器(业务)指标,其中业务监控告警还需要通过公司的基础监控平台来展示和配置。
-
告警需求
告警需要可视化的配置方式,需要发送给公司的告警中心,并有分级分组等策略规则需求。
-
数据分析需求
有各类丰富的周、月度、季度统计报表需求。
3.1 监控高可用架构设计
结合上文说明的环境和需求特点,vivo当前监控架构的设计思路:
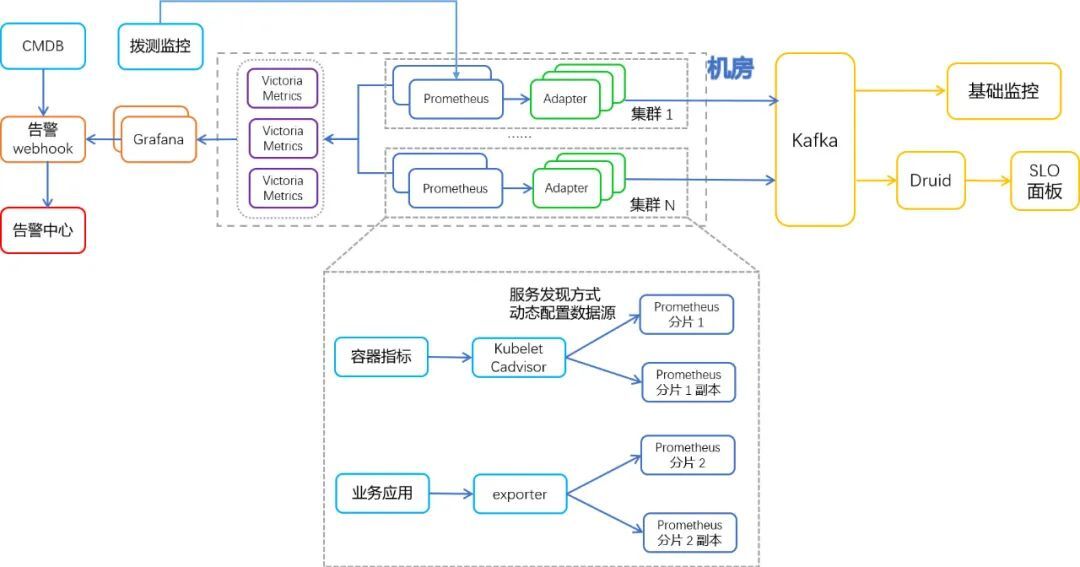
- 每个生产集群都有独立的监控节点用于部署监控组件,Prometheus按照采集目标服务划分为多组,每组Prometheus都是双副本部署保证高可用。
- 数据存储采用VictoriaMetrics,每个机房部署一套VictoriaMetrics集群,同一机房内集群的Prometheus均将监控数据remote-write到VM中,VM配置为多副本存储,保证存储高可用。
- Grafana对接Mysql集群,Grafana自身做到无状态,实现Grafana多副本部署。Grafana使用VictoriaMetrics作为数据源。
- 通过拨测监控实现Prometheus自身的监控告警,在Prometheus异常时能及时收到告警信息。
- 集群层面的告警使用Grafana的可视化告警配置,通过自研webhook将告警转发给公司告警中心,自研webhook还实现了分级分组等告警处理策略。
- 容器层面(业务)的监控数据则通过自研Adapter转发给Kafka,进而存储到公司基础监控做业务监控展示和告警配置,同时也存储一份到Druid做更多维度的统计报表。
前文介绍了社区的Cortex和Thanos高可用监控方案,这两个方案在业界均有生产级的实践经验,但为什么我们选择用Prometheus双副本+VictoriaMetrics的方案?
主要原因有以下几点:
- Cortex在网上能找到的相关实践文档较少。
- Thanos需要使用对象存储,实际部署时发现Thanos的配置比较复杂,参数调优可能比较困难,另外Thanos需要在Prometheus Pod里部署其SideCar组件,而我们Prometheus部署采用的是Operator自动部署方式,嵌入SideCar比较麻烦。另外,在实测中对Thanos组件进行监控时发现,Thanos因为Compact和传输Prometheus数据存储文件等原因,时常出现CPU和网络的尖峰。综合考虑后认为Thanos的后期维护成本较高,因此没有采用。
- VictoriaMetrics部署配置比较简单,有很高的存储、查询和压缩性能,支持数据去重,不依赖外部系统,只需要通过Prometheus配置remote-write写入监控数据即可,并且与Grafana完全兼容。既满足我们长期历史数据存储和高可用需求,同时维护成本很低。从我们对VictoriaMetrics自身组件的监控观察来看,运行数据平稳,并且自生产使用以来,一直稳定运行无故障。
3.2 监控数据转发层组件高可用设计
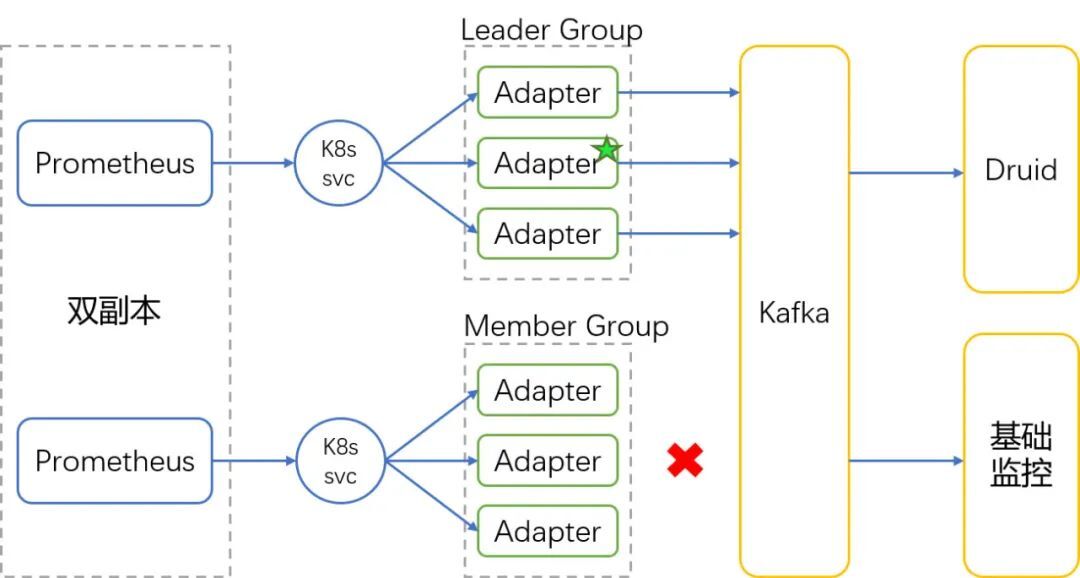
由于Prometheus采用双副本部署高可用方案,数据存储如何去重是需要设计时就考虑的。VictoriaMetrics本身支持存储时去重,因此VictoriaMetrics这一侧的数据去重得到天然解决。但监控数据通过Kafka转发给基础监控平台和OLAP这一侧的去重该如何实现?
我们设计的方案,如下图,是通过自研Adapter “分组选举”方式实现去重。即每个Prometheus副本对应一组Adapter,两组Adapter之间会进行选主,只有选举为Leader的那组Adapter才会转发数据。通过这种方式既实现了去重,也借用K8s service来支持Adapter的负载均衡。
此外,Adapter具备感知Prometheus故障的能力,当Leader Prometheus发生故障时,Leader Adapter会感知到并自动放弃Leader身份,从而切换到另一组Adapter继续传输数据,确保了“双副本高可用+去重”方案的有效性。
四、 容器监控实践的挑战和对策
我们在容器集群监控实践的过程中,遇到的一些困难和挑战,总结如下:

五、未来展望
监控的目标是为了更高效可靠的运维,准确及时的发现问题。更高的目标是基于监控实现自动化的运维,甚至是智能运维(AIOPS)。
基于目前对容器集群监控的经验总结,未来在监控架构上可以做的提升点包括:
- Prometheus自动化分片及采集Target自动负载均衡;
- AI预测分析潜在故障;
- 故障自愈;
- 通过数据分析设定合适的告警阈值;
- 优化告警管控策略。
没有一种架构设计是一劳永逸的,必须要随着生产环境和需求的变化,以及技术的发展来持续演进。我们在云原生监控这条路上,需要继续不忘初心,砥砺前行。
|








- 上一条: 隐私计算FATE-模型训练 2022-06-20
- 下一条: 浅析如何基于ZooKeeper实现高可用架构|得物技术 2022-06-20
- vivo服务端监控架构设计与实践 2022-02-21
- vivo 全球商城:优惠券系统架构设计与实践 2021-08-09
- vivo 全球商城:商品系统架构设计与实践 2021-11-08
- vivo 敏感词匹配系统的设计与实践 2021-12-06
- vivo统一告警平台设计与实践 2021-11-22


